节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。
合集在这里:《大模型面试宝典》(2024版) 正式发布!
LLM 时代流传着一个法则:Scaling Law,即通过某种维度的指数上升可以带来指标的线性提升。
如下图所示,在 Compute、Data、Parameter 三个维度上的指数上升可以带来在 test loss 上的线性下降。

MoE(Mixture of Experts,混合专家模型)从本质上来说就是一种高效的 scaling 技术,用较少的 compute 实现更大的模型规模,从而获得更好的性能。
目前 LLM 的天花板 GPT-4 也使用了 MoE 技术,Mistral 7B /w 8 experts 的 checkpoint 释出,彻底引爆了 AI 社区对 MoE 的热情。
模型规模是提升模型性能的关键因素之一。在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
MoE 的一个显著优势是它们能够在远少于稠密模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。
喜欢本文,记得收藏、关注、点赞,文末提供技术交流群。
MoE结构和原理
作为一种基于 Transformer 架构的模型,MoE 主要由两个关键部分组成:
-
稀疏 MoE 层: 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”(例如 8 个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。
-
门控网络或路由: 这个部分用于决定哪些 token 被发送到哪个专家。一般 input Token 会被 router 分配到一个或多个 expert 上做处理。如果是多个 expert 处理同一个 input token,那么不同 expert 的输出会再做一次 aggregate,作为 input token 的最终 output。
例如,在下图中,“More”这个 token 被发送到第二个专家,而“Parameters”这个 token 被发送到第一个专家。
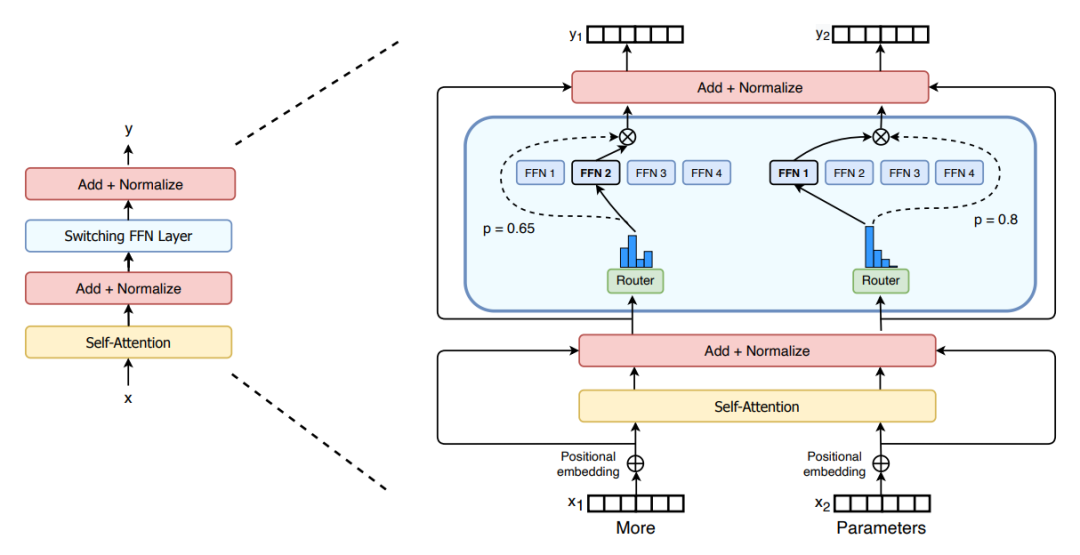
Token 的 router 方式是 MoE 使用中的一个关键点,因为 router 由可学习的参数组成(一般是由一个 Linear 层和一个 Softmax 层组成),并且与网络的其他部分一同进行预训练。
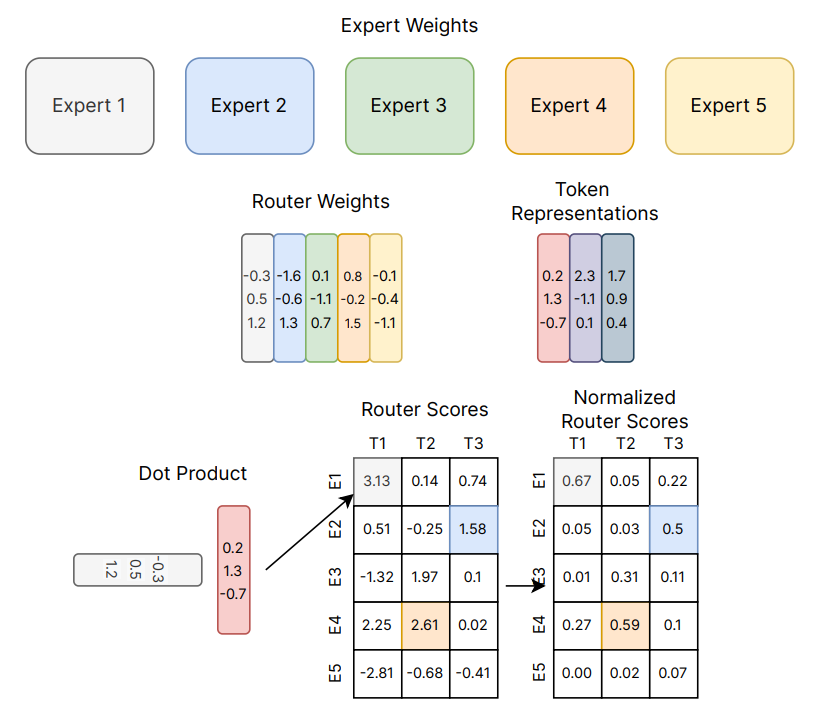
下图是一个更加直观的例子解释 router 是如何为 input token 指定 expert 的。第 个 token 的表示 维度是 (h, 1),其中 h 是模型 hidden dim。router 的权重矩阵 的维度是 (h, e),其中 e 是 expert 的数量。则 router scores 由 决定,从中选择 scores 值最大的 top-k 个 expert 处理该 token。
在下图中,如果采用 top-1 的 router 策略,则 T1、T2、T3 三个 token 分别 router 到的 expert 为 E1、E4、E2。
MoE的优点
-
任务特异性: 采用混合专家方法可以有效地充分利用多个专家模型的优势,每个专家都可以专门处理不同的任务或数据的不同部分,在处理复杂任务时取得更卓越的性能。各个专家模型能够针对不同的数据分布和模式进行建模,从而显著提升模型的准确性和泛化能力,因此模型可以更好地适应任务的复杂性。
-
灵活性: 混合专家方法展现出卓越的灵活性,能够根据任务的需求灵活选择并组合适宜的专家模型。模型的结构允许根据任务的需要动态选择激活的专家模型,实现对输入数据的灵活处理。这使得模型能够适应不同的输入分布和任务场景,提高了模型的灵活性。
-
高效性: 由于只有少数专家模型被激活,大部分模型处于未激活状态,混合专家模型具有很高的稀疏性。这种稀疏性带来了计算效率的提升,因为只有特定的专家模型对当前输入进行处理,减少了计算的开销。
-
表现能力: 每个专家模型可以被设计为更加专业化,能够更好地捕捉输入数据中的模式和关系。整体模型通过组合这些专家的输出,提高了对复杂数据结构的建模能力,从而增强了模型的性能。
-
可解释性: 由于每个专家模型相对独立,因此模型的决策过程更易于解释和理解,为用户提供更高的可解释性,这对于一些对模型决策过程有强解释要求的应用场景非常重要。
-
适应大规模数据: 混合专家方法是处理大规模数据集的理想选择,能够有效地应对数据量巨大和特征复杂的挑战,可以利用稀疏矩阵的高效计算,利用GPU的并行能力计算所有专家层,能够有效地应对海量数据和复杂特征的挑战。
MoE的问题
尽管混合专家模型 (MoE) 提供了若干显著优势,例如更高效的预训练和与稠密模型相比更快的推理速度,但它们也伴随着一些挑战:
-
训练复杂性: 虽然 MoE 能够实现更高效的计算预训练,但其训练相对复杂,尤其是涉及到门控网络的参数调整。为了正确地学习专家的权重和整体模型的参数,反而可能需要更多的训练时间。另外在微调阶段往往面临泛化能力不足的问题,长期以来易于引发过拟合现象。
-
超参数调整: 选择适当的超参数,特别是与门控网络相关的参数,以达到最佳性能,是一个复杂的任务。这可能需要通过交叉验证等技术进行仔细调整。
-
专家模型设计: 专家模型的设计对模型的性能影响显著。选择适当的专家模型结构,确保其在特定任务上有足够的表现力,是一个挑战。
-
稀疏性失真: 在某些情况下,为了实现稀疏性,门控网络可能会过度地激活或不激活某些专家,导致模型性能下降。需要谨慎设计稀疏性调整策略,以平衡效率和性能。
-
动态性问题: 在处理动态或快速变化的数据分布时,门控网络可能需要更加灵活的调整,以适应输入数据的变化。这需要额外的处理和设计。
-
对数据噪声的敏感性: 混合专家模型对于数据中的噪声相对敏感,可能在一些情况下表现不如其他更简单的模型。
-
通信宽带瓶颈: 在分布式计算环境下可能面临通信宽带瓶颈的问题。这主要涉及到混合专家模型的分布式部署,其中不同的专家模型或门控网络可能分布在不同的计算节点上。在这种情况下,模型参数的传输和同步可能导致通信开销过大,成为性能的一个瓶颈。
-
推理挑战: MoE 模型虽然可能拥有大量参数,但在推理过程中只使用其中的一部分,这使得它们的推理速度快于具有相同数量参数的稠密模型。然而,这种模型需要将所有参数加载到内存中,因此对内存的需求非常高。
对于推理挑战,以 Mixtral 8x7B 这样的 MoE 为例,需要足够的 VRAM 来容纳一个 47B 参数的稠密模型。之所以是 47B 而不是 8 x 7B = 56B,是因为在 MoE 模型中,只有 FFN 层被视为独立的专家,而模型的其他参数是共享的。此外,假设每个token只使用两个专家,那么推理速度 (以 FLOPs 计算) 类似于使用 12B 模型 (而不是 14B 模型),因为虽然它进行了 2x7B 的矩阵乘法计算,但某些层是共享的。
示例代码
MoE 的 Pytorch 示例代码如下,大家可以自己学习并运行一下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
# 创建一些随机数据(替换为真实数据)
num_samples = 1000
num_features = 300 # 假设文本已经转换为固定大小的向量
num_classes = 10 # 假设有10个类别
# 随机生成数据和标签
X = np.random.randn(num_samples, num_features)
y = np.random.randint(0, num_classes, num_samples)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义 Dataset
class TextDataset(Dataset):
def __init__(self, features, labels):
self.features = features
self.labels = labels
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return torch.tensor(self.features[idx], dtype=torch.float), torch.tensor(self.labels[idx], dtype=torch.long)
# 创建 DataLoader
train_dataset = TextDataset(X_train, y_train)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataset = TextDataset(X_test, y_test)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
###模型定义
class TopKGating(nn.Module):
def __init__(self, input_dim, num_experts, top_k=2):
super(TopKGating, self).__init__()
# 初始化线性层作为门控机制
self.gate = nn.Linear(input_dim, num_experts)
# 设置要选择的顶部专家数量
self.top_k = top_k
def forward(self, x):
# 计算每个专家的分数
gating_scores = self.gate(x)
# 选取分数最高的 top_k 个专家,并返回它们的索引和 softmax 权重
top_k_values, top_k_indices = torch.topk(F.softmax(gating_scores, dim=1), self.top_k)
return top_k_indices, top_k_values
class Expert(nn.Module):
def __init__(self, input_dim, output_dim):
super(Expert, self).__init__()
# 为每个专家定义一个简单的神经网络
self.net = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, output_dim)
)
def forward(self, x):
# 通过专家网络传递输入数据
return self.net(x)
class MoE(nn.Module):
def __init__(self, input_dim, num_classes, num_experts, top_k=2):
super(MoE, self).__init__()
# 设置专家数量
self.num_experts = num_experts
# 设置类别数量
self.num_classes = num_classes
# 初始化 TopK 门控层
self.gating = TopKGating(input_dim, num_experts, top_k)
# 创建专家网络的列表,每个专家是一个 Expert 实例
self.experts = nn.ModuleList([Expert(input_dim, num_classes) for _ in range(num_experts)])
def forward(self, x):
# 获取批量大小
batch_size = x.size(0)
# 通过门控层获得 top_k 专家的索引和门控权重
indices, gates = self.gating(x) # 形状 indices:[batch_size, top_k], gates:[batch_size, top_k]
# 准备收集选定专家的输出
expert_outputs = torch.zeros(batch_size, indices.size(1), self.num_classes).to(x.device)
# 遍历每个样本和其对应的 top_k 专家
for i in range(batch_size):
for j in range(indices.size(1)):
expert_idx = indices[i, j].item() # 获取专家的索引
expert_outputs[i, j, :] = self.experts[expert_idx](x[i].unsqueeze(0))
# 将门控权重扩展到与专家输出相同的维度
gates = gates.unsqueeze(-1).expand(-1, -1, self.num_classes) # 形状:[batch_size, top_k, num_classes]
# 计算加权的专家输出的和
output = (gates * expert_outputs).sum(1)
return output, gates.sum(0) # 返回模型输出和门控使用率以用于负载平衡损失计算
import torch.nn.functional as F
def moe_loss(output, target, gating_weights, lambda_balance=0.1):
# 标准损失(例如交叉熵损失)
# output 是模型的输出,target 是真实的标签
standard_loss = F.cross_entropy(output, target)
# 负载平衡损失
# gating_weights 是门控权重,表示每个专家的使用率
# 使用标准差来衡量各专家使用率的平衡程度
balance_loss = torch.std(gating_weights)
# 总损失
# 结合标准损失和负载平衡损失,lambda_balance 是一个超参数,用于控制负载平衡损失在总损失中的比重
total_loss = standard_loss + lambda_balance * balance_loss
return total_loss
# 初始化模型
model = MoE(input_dim=num_features, num_classes=num_classes, num_experts=4, top_k=2)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环
num_epochs = 1
for epoch in range(num_epochs):
model.train()
total_loss = 0
for features, labels in train_loader:
optimizer.zero_grad()
outputs, gating_weights = model(features)
loss = moe_loss(outputs, labels, gating_weights)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {total_loss/len(train_loader)}')
def evaluate(model, data_loader):
model.eval()
predictions, true_labels = [], []
with torch.no_grad():
for features, labels in data_loader:
s = time.time()
outputs, _ = model(features)
e = time.time()
print(e-s)
predicted = torch.argmax(outputs, dim=1)
predictions.extend(predicted.tolist())
true_labels.extend(labels.tolist())
return accuracy_score(true_labels, predictions)
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:技术交流
用通俗易懂方式讲解系列
- 《大模型面试宝典》(2024版) 正式发布!
- 《大模型实战宝典》(2024版)正式发布!
- 大模型面试准备(一):LLM主流结构和训练目标、构建流程
- 大模型面试准备(二):LLM容易被忽略的Tokenizer与Embedding
- 大模型面试准备(三):聊一聊大模型的幻觉问题
- 大模型面试准备(四):大模型面试必会的位置编码
- 大模型面试准备(五):图解 Transformer 最关键模块 MHA
- 大模型面试准备(六):一文讲透生成式预训练模型 GPT、GPT2、GPT3
- 大模型面试准备(七):ChatGPT 的内核 InstructGPT 详细解读
- 大模型面试准备(八):一文详解国产大模型导师 LLaMA v1和v2
相关参考和推荐阅读:
[1] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
[2] A Review of Sparse Expert Models in Deep Learning
[3] https://zhuanlan.zhihu.com/p/674698482
[4] https://zhuanlan.zhihu.com/p/671434414
[5] https://zhuanlan.zhihu.com/p/673048264







![[机器学习]练习闵可斯基距离](https://img-blog.csdnimg.cn/direct/07a732525cb646da8393979e0fa5826d.png)