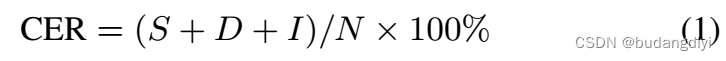Java八股文の算法
- 算法
算法
- 逆序输出字符串
题目描述:输入一个字符串,要求逆序输出。
public static String reverseString(String s) {
StringBuilder sb = new StringBuilder();
for (int i = s.length() - 1;i >= 0;i--) {
sb.append(s.charAt(i));
}
return sb.toString();
}
- 找出数组中的最大值和最小值
题目描述:给定一个整数数组,找出数组中的最大值和最小值。
public static void findMaxAndMin(int[] arr) {
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int num : arr) {
max = Math.max(max, num);
min = Math.min(min, num);
}
System.out.println("Max: " + max);
System.out.println("Min: " + min);
}
- 判断一个数是否为质数
题目描述:给定一个整数,判断该数是否为质数。
public static boolean isPrime(int num) {
if (num <= 1) {
return false;
}
for (int i = 2; i <= Math.sqrt(num); i++) {
if (num % i == 0) {
return false;
}
}
return true;
}
- 链表反转
题目描述:反转一个单链表。
public static ListNode reverseList(ListNode head) {
ListNode prev = null;
ListNode curr = head;
while (curr != null) {
ListNode next = curr.next;
curr.next = prev;
prev = curr;
curr = next;
}
return prev;
}
- 在一个有序数组中查找指定的目标值
题目描述:给定一个有序数组和目标值,返回目标值在数组中的索引,若不存在目标值则返回-1。
public static int binarySearch(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}
- 实现一个堆排序
题目描述:给定一个数组,使用堆排序算法对数组进行排序。
public static void heapSort(int[] arr) {
int n = arr.length;
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
for (int i = n - 1; i > 0; i--) {
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
heapify(arr, i, 0);
}
}
private static void heapify(int[] arr, int n, int i) {
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
if (largest != i) {
int swap = arr[i];
arr[i] = arr[largest];
arr[largest] = swap;
heapify(arr, n, largest);
}
}
- 判断两个字符串是否是Anagram
题目描述:给定两个字符串,判断它们是否是Anagram(由颠倒字母顺序而构成的单词,例如:listen和silent)。
public static boolean isAnagram(String s, String t) {
if (s.length() != t.length()) {
return false;
}
int[] count = new int[26];
for (int i = 0; i < s.length(); i++) {
count[s.charAt(i) - 'a']++;
count[t.charAt(i) - 'a']--;
}
for (int num : count) {
if (num != 0) {
return false;
}
}
return true;
}
- 实现快速排序
题目描述:给定一个数组,使用快速排序算法对数组进行排序。
public static void quickSort(int[] arr, int left, int right) {
if (left < right) {
int pivotIndex = partition(arr, left, right);
quickSort(arr, left, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, right);
}
}
private static int partition(int[] arr, int left, int right) {
int pivot = arr[right];
int i = left - 1;
for (int j = left; j < right; j++) {
if (arr[j] <= pivot) {
i++;
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
int temp = arr[i + 1];
arr[i + 1] = arr[right];
arr[right] = temp;
return i + 1;
}
- 判断链表是否有环
题目描述:给定一个链表,判断链表中是否有环。
public static boolean hasCycle(ListNode head) {
ListNode slow = head;
ListNode fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) {
return true;
}
}
return false;
}
- 求一个整数的平方根
题目描述:给定一个非负整数,求该整数的平方根,返回结果向下取整。
public static int sqrt(int x) {
if (x == 0) {
return 0;
}
long left = 1;
long right = x;
while (left < right) {
long mid = left + (right - left) / 2;
if (mid * mid <= x && (mid + 1) * (mid + 1) > x) {
return (int) mid;
} else if (mid * mid > x) {
right = mid - 1;
} else {
left = mid + 1;
}
}
return (int) left;
}
- 实现斐波那契数列
题目描述:实现斐波那契数列(即当前数字是前两个数字之和)。
public static int fibonacci(int n) {
if (n <= 1) {
return n;
}
int a = 0;
int b = 1;
for (int i = 2; i <= n; i++) {
int temp = a + b;
a = b;
b = temp;
}
return b;
}
- 统计一个字符串中出现最多的字符及其次数
题目描述:给定一个字符串,统计字符串中出现最多的字符及其出现次数。
public static void findMostFrequentChar(String s) {
int[] count = new int[256];
for (char c : s.toCharArray()) {
count[c]++;
}
int maxCount = 0;
char maxChar = ' ';
for (int i = 0; i < count.length; i++) {
if (count[i] > maxCount) {
maxCount = count[i];
maxChar = (char) i;
}
}
System.out.println("Most frequent char: " + maxChar);
System.out.println("Count: " + maxCount);
}
- 实现LRU缓存算法
题目描述:实现Least Recently Used(LRU)缓存算法,保证最近使用的元素被保留,老旧元素被移除。
public class LRUCache {
private LinkedHashMap<Integer, Integer> cache;
public LRUCache(int capacity) {
cache = new LinkedHashMap<>(capacity, 0.75f, true) {
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
};
}
public int get(int key) {
return cache.getOrDefault(key, -1);
}
public void put(int key, int value) {
cache.put(key, value);
}
}
- 实现二叉树的前序遍历
题目描述:给定一个二叉树,返回其前序遍历结果。
public static List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode node = root;
while (node != null || !stack.isEmpty()) {
while (node != null) {
result.add(node.val);
stack.push(node);
node = node.left;
}
node = stack.pop();
node = node.right;
}
return result;
}
- 判断一个字符串是否是回文串
题目描述:给定一个字符串,判断该字符串是否是回文串。
public static boolean isPalindrome(String s) {
int left = 0;
int right = s.length() - 1;
while (left < right) {
while (left < right && !Character.isLetterOrDigit(s.charAt(left))) {
left++;
}
while (left < right && !Character.isLetterOrDigit(s.charAt(right))) {
right--;
}
if (Character.toLowerCase(s.charAt(left)) != Character.toLowerCase(s.charAt(right))) {
return false;
}
left++;
right--;
}
return true;
}
- 实现大整数相加
题目描述:给定两个字符串表示的非负整数,返回它们的和。
public static String addStrings(String num1, String num2) {
StringBuilder sb = new StringBuilder();
int carry = 0;
int i = num1.length() - 1;
int j = num2.length() - 1;
while (i >= 0 || j >= 0 || carry != 0) {
int sum = carry;
if (i >= 0) {
sum += num1.charAt(i) - '0';
i--;
}
if (j >= 0) {
sum += num2.charAt(j) - '0';
j--;
}
sb.append(sum % 10);
carry = sum / 10;
}
return sb.reverse().toString();
}
- 实现有效的括号
题目描述:给定一个只包含字符 ‘(’, ‘)’, ‘{’, ‘}’, ‘[’ 和 ‘]’ 的字符串,判断字符串是否有效。
public static boolean isValid(String s) {
Stack<Character> stack = new Stack<>();
for (char c : s.toCharArray()) {
if (c == '(' || c == '{' || c == '[') {
stack.push(c);
} else {
if (stack.isEmpty()) {
return false;
}
char top = stack.pop();
if (c == ')' && top != '(') {
return false;
}
if (c == '}' && top != '{') {
return false;
}
if (c == ']' && top != '[') {
return false;
}
}
}
return stack.isEmpty();
}
- 实现LRU缓存算法(不使用Java自带的数据结构)
题目描述:实现Least Recently Used(LRU)缓存算法,保证最近使用的元素被保留,老旧元素被移除,不能使用Java自带的LinkedHashMap或类似的数据结构。
class ListNode {
int key;
int value;
ListNode prev;
ListNode next;
public ListNode(int key, int value) {
this.key = key;
this.value = value;
}
}
class LRUCache {
private final int capacity;
private final Map<Integer, ListNode> cache;
private ListNode head;
private ListNode tail;
public LRUCache(int capacity) {
this.capacity = capacity;
cache = new HashMap<>();
head = new ListNode(-1, -1);
tail = new ListNode(-1, -1);
head.next = tail;
tail.prev = head;
}
private void addToFront(ListNode node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
private void removeNode(ListNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(ListNode node) {
removeNode(node);
addToFront(node);
}
public int get(int key) {
ListNode node = cache.get(key);
if (node == null) {
return -1;
}
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
ListNode node = cache.get(key);
if (node != null) {
node.value = value;
moveToHead(node);
} else {
if (cache.size() == capacity) {
ListNode tailNode = tail.prev;
removeNode(tailNode);
cache.remove(tailNode.key);
}
ListNode newNode = new ListNode(key, value);
addToFront(newNode);
cache.put(key, newNode);
}
}
}
- 实现二叉树的层序遍历
题目描述:给定一个二叉树,返回其层序遍历结果。
public static List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if (root == null) {
return result;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
int levelSize = queue.size();
List<Integer> currLevel = new ArrayList<>();
for (int i = 0; i < levelSize; i++) {
TreeNode node = queue.poll();
currLevel.add(node.val);
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
result.add(currLevel);
}
return result;
}
- 实现二叉树的最大深度
题目描述:给定一个二叉树,计算其最大深度(根节点到最远叶子节点的距离)。
public static int maxDepth(TreeNode root) {
if (root == null) {
return 0;
}
return 1 + Math.max(maxDepth(root.left), maxDepth(root.right));
}
- 两数之和
题目描述:给定一个整数数组和一个目标值,找出数组中和为目标值的两个数的索引。
public static int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
if (map.containsKey(complement)) {
return new int[] { map.get(complement), i };
}
map.put(nums[i], i);
}
return new int[0];
}
- 买卖股票的最佳时机
题目描述:给定一个整数数组,其中第 i 个元素表示第 i 天的股票价格,计算能够获得的最大利润。
public static int maxProfit(int[] prices) {
int minPrice = Integer.MAX_VALUE;
int maxProfit = 0;
for (int price : prices) {
if (price < minPrice) {
minPrice = price;
} else if (price - minPrice > maxProfit) {
maxProfit = price - minPrice;
}
}
return maxProfit;
}
- 实现字符串的全排列
题目描述:给定一个字符串,返回其所有可能的全排列。
public static List<String> permute(String str) {
List<String> result = new ArrayList<>();
backtrack(str.toCharArray(), result, 0);
return result;
}
private static void backtrack(char[] chars, List<String> result, int start) {
if (start == chars.length - 1) {
result.add(new String(chars));
} else {
for (int i = start; i < chars.length; i++) {
swap(chars, start, i);
backtrack(chars, result, start + 1);
swap(chars, start, i);
}
}
}
private static void swap(char[] chars, int i, int j) {
char temp = chars[i];
chars[i] = chars[j];
chars[j] = temp;
}
- 反转字符串:给定一个字符串,将其原地反转。
要对字符串进行原地反转,可以使用双指针法来实现。
首尾两个指针分别指向字符串的首尾位置,然后不断交换两个指针所指向的字符,直到两个指针相遇。
下面是用Java代码实现字符串原地反转的示例:
public class StringReverse {
public static void reverseString(char[] s) {
int left = 0;
int right = s.length - 1;
while (left < right) {
// 交换首尾字符
char temp = s[left];
s[left] = s[right];
s[right] = temp;
// 移动指针
left++;
right--;
}
}
public static void main(String[] args) {
// 示例
char[] s = "Hello World".toCharArray();
System.out.println("原字符串:" + String.valueOf(s));
reverseString(s);
System.out.println("反转后的字符串:" + String.valueOf(s));
}
}
运行上述代码,将会输出:
原字符串:Hello World
反转后的字符串:dlroW olleH
在这个示例中,我们使用了两个指针left和right分别指向字符串的首位字符。
通过交换首尾字符,并依次向中间移动指针来完成字符串的原地反转。
最终将反转后的字符数组转换为字符串后输出。
这个算法的时间复杂度为O(n),其中n是字符串的长度。
原地反转意味着我们不需要使用额外的空间来存储临时字符串,所以空间复杂度为O(1)。
- 字符串压缩:给定一个字符串,将其压缩成重复字符和出现次数的形式,如果压缩后得到的字符串长度大于或等于原字符串,则返回原字符串。
要实现字符串压缩,需要使用两个指针来记录当前字符和计数器。
遍历字符串,如果当前字符与前一个字符不同,则将前一个字符和计数器加入结果字符串,并重置计数器为1;
如果相同,则计数器加1。
最后判断压缩后的字符串长度是否大于或等于原字符串,如果是,则返回原字符串。
下面是用Java代码实现字符串压缩的示例:
public class StringCompression {
public static String compressString(String s) {
StringBuilder compressed = new StringBuilder();
int count = 1;
for (int i = 1; i < s.length(); i++) {
if (s.charAt(i) != s.charAt(i - 1)) {
compressed.append(s.charAt(i - 1));
compressed.append(count);
count = 1;
} else {
count++;
}
}
// 处理最后一个字符
compressed.append(s.charAt(s.length() - 1));
compressed.append(count);
// 判断压缩后的字符串长度是否大于或等于原字符串
if (compressed.length() >= s.length()) {
return s;
} else {
return compressed.toString();
}
}
public static void main(String[] args) {
// 示例
String s = "aabcccccaaa";
System.out.println("原字符串:" + s);
System.out.println("压缩后的字符串:" + compressString(s));
}
}
运行上述代码,将会输出:
原字符串:aabcccccaaa
压缩后的字符串:a2b1c5a3
在这个示例中,我们使用两个指针来遍历字符串。
通过比较当前字符与前一个字符是否相同,来确定是否需要加入结果字符串。
同时使用计数器count来统计相同字符的出现次数。
最后判断压缩后的字符串长度是否大于或等于原字符串,然后返回结果。
这个算法的时间复杂度为O(n),其中n是字符串的长度,因为我们只需一次遍历字符串。
压缩后的字符串的空间复杂度取决于压缩后的字符串的长度,而不是原字符串的长度。
所以压缩后的空间复杂度为O(m),其中m是压缩后的字符串的长度。
- 说一下你对时间复杂度和空间复杂度的理解
时间复杂度是衡量算法执行时间随输入规模增长而增长的程度。
简单来说,它是表示算法运行时间与问题规模之间关系的一种度量。
通常用大O符号来表示时间复杂度,例如O(n)表示线性时间复杂度,O(n^2)表示平方时间复杂度等。
时间复杂度可以用来比较不同算法的效率,可以帮助我们选择最优算法来解决问题。
一般情况下,我们希望时间复杂度越小越好,即算法的执行时间随输入规模的增长而增长得越慢越好。
空间复杂度是衡量算法在执行过程中所需要的额外空间的度量。
它用于衡量算法所占用的内存空间随输入规模增长而增长的程度。
空间复杂度通常也用大O符号表示,例如O(n)表示线性空间复杂度,O(n^2)表示平方空间复杂度等。
空间复杂度的大小与算法使用的数据结构、变量的个数等有关。
与时间复杂度类似,我们希望空间复杂度越小越好,即算法所需的额外空间随输入规模的增长而增长得越慢越好。
总结而言,时间复杂度和空间复杂度是评估算法效率的重要指标。
时间复杂度衡量了算法执行时间的增长情况,空间复杂度衡量了算法所需额外空间的增长情况。
在设计和选择算法时,我们通常会考虑时间复杂度和空间复杂度,以平衡算法的效率和所需资源的消耗。
- 删除链表的倒数第N个节点:给定一个链表,删除链表的倒数第N个节点。
要删除链表的倒数第N个节点,首先需要找到倒数第N+1个节点,然后将其指向下下个节点即可。
下面是用Java代码实现删除链表的倒数第N个节点的示例:
public class ListNode {
int val;
ListNode next;
ListNode(int val) {
this.val = val;
}
}
public class RemoveNthFromEnd {
public static ListNode removeNthFromEnd(ListNode head, int n) {
// 创建一个虚拟头节点,方便处理边界情况
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode slow = dummy;
ListNode fast = dummy;
// 让快指针先走n+1步
for (int i = 0; i <= n; i++) {
fast = fast.next;
}
// 同时移动快慢指针,直到快指针到达尾部
while (fast != null) {
slow = slow.next;
fast = fast.next;
}
// 删除倒数第N个节点
slow.next = slow.next.next;
return dummy.next;
}
public static void main(String[] args) {
// 创建一个链表:1 -> 2 -> 3 -> 4 -> 5
ListNode head = new ListNode(1);
ListNode node2 = new ListNode(2);
ListNode node3 = new ListNode(3);
ListNode node4 = new ListNode(4);
ListNode node5 = new ListNode(5);
head.next = node2;
node2.next = node3;
node3.next = node4;
node4.next = node5;
int n = 2;
System.out.println("链表删除倒数第" + n + "个节点前的状态:");
printList(head);
ListNode newHead = removeNthFromEnd(head, n);
System.out.println("链表删除倒数第" + n + "个节点后的状态:");
printList(newHead);
}
// 打印链表
public static void printList(ListNode head) {
ListNode curr = head;
while (curr != null) {
System.out.print(curr.val + " ");
curr = curr.next;
}
System.out.println();
}
}
运行上述代码,将会输出:
链表删除倒数第2个节点前的状态:
1 2 3 4 5
链表删除倒数第2个节点后的状态:
1 2 3 5
在这个示例中,我们使用了双指针来找到倒数第N+1个节点。
首先创建一个虚拟头节点dummy,其next指针指向链表的头节点head。
然后让快指针fast先走n+1步,然后同时移动快慢指针直到快指针到达尾部。此时慢指针指向倒数第N+1个节点。
然后将慢指针的next指针指向下下个节点,即删除倒数第N个节点。
这个算法的时间复杂度为O(L),其中L是链表的长度。
因为我们只需一次遍历链表,所以时间复杂度是线性的。
空间复杂度为O(1),因为我们只使用了常数级别的额外空间。
- 实现最小栈:设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈。
要实现一个最小栈,需要借助一个辅助栈来记录每个状态下的最小元素。
下面是用Java代码实现最小栈的示例:
import java.util.Stack;
public class MinStack {
private Stack<Integer> stack; // 主栈,用于存储元素
private Stack<Integer> minStack; // 辅助栈,用于存储每个状态下的最小元素
public MinStack() {
stack = new Stack<>();
minStack = new Stack<>();
}
public void push(int x) {
stack.push(x);
if (minStack.isEmpty() || x <= minStack.peek()) {
// 如果辅助栈为空或x小于等于当前最小元素,则将x入栈
minStack.push(x);
}
}
public void pop() {
if (stack.pop().equals(minStack.peek())) {
// 如果弹出的元素等于最小元素,辅助栈也弹出最小元素
minStack.pop();
}
}
public int top() {
return stack.peek();
}
public int getMin() {
return minStack.peek();
}
public static void main(String[] args) {
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
System.out.println("最小栈中的最小元素为:" + minStack.getMin()); // -3
minStack.pop();
System.out.println("最小栈中的顶部元素为:" + minStack.top()); // 0
System.out.println("最小栈中的最小元素为:" + minStack.getMin()); // -2
}
}
运行上述代码,将会输出:
最小栈中的最小元素为:-3
最小栈中的顶部元素为:0
最小栈中的最小元素为:-2
在这个示例中,我们使用了两个栈:stack为主栈,用于存储元素,minStack为辅助栈,用于存储每个状态下的最小元素。
在push操作中,我们将元素入栈,并判断辅助栈是否为空或者待入栈元素是否小于等于当前最小元素,如果是,则将元素也入辅助栈。
在pop操作中,我们先从主栈中弹出元素,并与辅助栈的顶部元素比较,如果相等,则同时将辅助栈的顶部元素弹出。
在top操作中,我们只需要返回主栈的顶部元素。
在getMin操作中,我们只需要返回辅助栈的顶部元素。
这样,我们能够在常数时间内检索到最小元素,并完成其他常见栈操作。
这个算法的时间复杂度为O(1),因为所有操作的时间复杂度都是常量级别的。空间复杂度为O(n),其中n是栈中的元素个数,因为我们需要额外的辅助栈来存储最小元素的状态。
- 平衡二叉树:给定一个二叉树,判断该树是否是平衡二叉树。
要判断一个二叉树是否是平衡二叉树,可以使用递归的方法。
下面是用Java代码实现判断二叉树是否是平衡二叉树的示例:
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int val) {
this.val = val;
}
}
public class BalancedBinaryTree {
public boolean isBalanced(TreeNode root) {
if (root == null) {
return true;
}
int leftHeight = getHeight(root.left);
int rightHeight = getHeight(root.right);
if (Math.abs(leftHeight - rightHeight) > 1) {
return false;
}
return isBalanced(root.left) && isBalanced(root.right);
}
private int getHeight(TreeNode node) {
if (node == null) {
return 0;
}
int leftHeight = getHeight(node.left);
int rightHeight = getHeight(node.right);
return Math.max(leftHeight, rightHeight) + 1;
}
public static void main(String[] args) {
BalancedBinaryTree tree = new BalancedBinaryTree();
// 构造一个平衡二叉树
TreeNode root1 = new TreeNode(3);
TreeNode left1 = new TreeNode(9);
TreeNode right1 = new TreeNode(20);
TreeNode left2 = new TreeNode(15);
TreeNode right2 = new TreeNode(7);
root1.left = left1;
root1.right = right1;
right1.left = left2;
right1.right = right2;
System.out.println("判断是否为平衡二叉树:" + tree.isBalanced(root1)); // true
// 构造一个非平衡二叉树
TreeNode root2 = new TreeNode(1);
TreeNode left3 = new TreeNode(2);
TreeNode right3 = new TreeNode(2);
TreeNode left4 = new TreeNode(3);
TreeNode right4 = new TreeNode(3);
TreeNode left5 = new TreeNode(4);
TreeNode right5 = new TreeNode(4);
root2.left = left3;
root2.right = right3;
left3.left = left4;
left3.right = right4;
left4.left = left5;
left4.right = right5;
System.out.println("判断是否为平衡二叉树:" + tree.isBalanced(root2)); // false
}
}
运行上述代码,将会输出:
判断是否为平衡二叉树:true
判断是否为平衡二叉树:false
在这个示例中,我们使用了递归的方法来判断二叉树是否是平衡二叉树。
首先,定义了一个isBalanced方法用于判断以给定节点为根的二叉树是否是平衡二叉树。如果给定节点为空,说明是空树,返回true。
然后,分别计算当前节点的左子树和右子树的高度。如果左子树和右子树高度差超过1,说明不是平衡二叉树,返回false。
最后,递归判断当前节点的左子树和右子树是否都是平衡二叉树。
此外,还定义了一个getHeight方法用于计算节点的高度。如果节点为空,返回0。否则,递归计算节点的左子树和右子树的高度,并返回较大值加1。
这个算法的时间复杂度为O(nlogn),其中n是二叉树的节点数。因为对于每个节点,都需要计算其子树的高度,而计算子树高度的时间复杂度为O(logn)。空间复杂度为O(logn),因为递归调用会使用系统栈空间。
- 克隆图:给定一个无向连接图中的一个节点,返回一个能够深拷贝图的节点。
要实现克隆图,可以使用深度优先搜索或广度优先搜索的方法。
下面是用Java代码实现深度优先搜索的克隆图的示例:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
class Node {
public int val; // 节点的值
public List<Node> neighbors; // 节点的邻居
public Node() {
val = 0;
neighbors = new ArrayList<Node>();
}
public Node(int _val) {
val = _val;
neighbors = new ArrayList<Node>();
}
public Node(int _val, ArrayList<Node> _neighbors) {
val = _val;
neighbors = _neighbors;
}
}
public class CloneGraph {
private Map<Node, Node> visited;
public Node cloneGraph(Node node) {
if (node == null) {
return null;
}
visited = new HashMap<>();
return cloneNode(node);
}
private Node cloneNode(Node node) {
if (visited.containsKey(node)) {
return visited.get(node);
}
Node clone = new Node(node.val);
visited.put(node, clone);
for (Node neighbor : node.neighbors) {
clone.neighbors.add(cloneNode(neighbor));
}
return clone;
}
public static void main(String[] args) {
CloneGraph cloneGraph = new CloneGraph();
// 构造一个图
Node node1 = new Node(1);
Node node2 = new Node(2);
Node node3 = new Node(3);
Node node4 = new Node(4);
node1.neighbors.add(node2);
node1.neighbors.add(node4);
node2.neighbors.add(node1);
node2.neighbors.add(node3);
node3.neighbors.add(node2);
node3.neighbors.add(node4);
node4.neighbors.add(node1);
node4.neighbors.add(node3);
Node clone = cloneGraph.cloneGraph(node1);
System.out.println("克隆图节点值:" + clone.val); // 1
System.out.println("克隆图邻居节点值:");
for (Node neighbor : clone.neighbors) {
System.out.println(neighbor.val);
}
}
}
运行上述代码,将会输出:
克隆图节点值:1
克隆图邻居节点值:
2
4
在这个示例中,我们使用了深度优先搜索的方法来克隆一个图。
首先,定义了一个cloneGraph方法用于克隆给定的图。如果给定图的根节点为空,返回null。
然后,使用visited字典来存储已经访问过的节点和它们的克隆节点。初始化为一个空字典。
接下来,调用cloneNode方法克隆给定节点,该方法递归地克隆节点及其邻居节点。如果该节点已经被克隆过,直接返回其克隆节点。否则,创建一个新的克隆节点,并将其加入到visited字典中。
最后,遍历该节点的邻居节点,递归调用cloneNode方法克隆每个邻居节点,并将其加入到克隆节点的邻居列表中。
这样,我们就能够完成图的深拷贝。
这个算法的时间复杂度为O(n+m),其中n是图中的节点数,m是边的数量。因为每个节点和每条边会被访问一次,所以时间复杂度为线性。空间复杂度为O(n),因为使用了额外的存储空间来存储已经访问过的节点。
- 爬楼梯:假设你正在爬楼梯,需要n阶你才能到达楼顶,每次你可以爬1或2个台阶,你有多少种不同的方式爬到楼顶。
要计算爬楼梯的不同方式,可以使用动态规划的方法。
下面是用Java代码实现爬楼梯的不同方式的示例:
public class ClimbingStairs {
public int climbStairs(int n) {
if (n <= 2) {
return n;
}
int[] dp = new int[n + 1];
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
public static void main(String[] args) {
ClimbingStairs climbingStairs = new ClimbingStairs();
int n = 4;
int ways = climbingStairs.climbStairs(n);
System.out.println("爬到楼顶的不同方式:" + ways); // 5
}
}
运行上述代码,将会输出:
爬到楼顶的不同方式:5
在这个示例中,我们使用了动态规划的方法来计算爬楼梯的不同方式。
首先,定义了一个climbStairs方法用于计算爬到楼顶的不同方式。如果楼梯的阶数n小于等于2,直接返回n。
然后,创建一个大小为n+1的数组dp,用于存储每个阶数对应的不同方式数。初始化dp[1] = 1和dp[2] = 2,表示第一阶和第二阶的方式数。
接下来,使用循环从第三阶开始计算每个阶数的不同方式数。对于每个阶数i,当前的不同方式数等于前一阶的方式数加上前两阶的方式数,即dp[i] = dp[i-1] + dp[i-2]。
最后,返回dp[n],即爬到楼顶的不同方式数。
这个算法的时间复杂度为O(n),空间复杂度为O(n),因为需要创建一个大小为n+1的数组来存储每个阶数的不同方式数。可以通过状态压缩进一步将空间复杂度优化为O(1)。
- 最大子序和:给定一个整数数组nums,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
要找到具有最大和的连续子数组,可以使用动态规划的方法。
下面是用Java代码实现最大子序和的示例:
public class MaxSubArray {
public int maxSubArray(int[] nums) {
int maxSum = nums[0]; // 最大和
int currSum = nums[0]; // 当前和
for (int i = 1; i < nums.length; i++) {
currSum = Math.max(currSum + nums[i], nums[i]);
maxSum = Math.max(maxSum, currSum);
}
return maxSum;
}
public static void main(String[] args) {
MaxSubArray maxSubArray = new MaxSubArray();
int[] nums = {-2, 1, -3, 4, -1, 2, 1, -5, 4};
int maxSum = maxSubArray.maxSubArray(nums);
System.out.println("最大子序和:" + maxSum); // 6
}
}
运行上述代码,将会输出:
最大子序和:6
在这个示例中,我们使用了动态规划的方法来找到具有最大和的连续子数组。
首先,定义了一个maxSubArray方法用于找到最大子序和。将数组中的第一个元素作为初始的最大和和当前和。
然后,使用循环从数组的第二个元素开始遍历。对于每个元素,当前的当前和等于前一个元素的当前和加上当前元素,如果小于当前元素,则当前和从当前元素重新开始。然后,将当前和和最大和中的较大值更新为最大和。
最后,返回最大和。
这个算法的时间复杂度为O(n),其中n是数组的长度。空间复杂度为O(1),因为只使用了常数级别的额外空间。
内容来自