THE MULTIMODAL INFORMATION BASED SPEECH PROCESSING (MISP) 2023
CHALLENGE: AUDIO-VISUAL TARGET SPEAKER EXTRACTION
第二章 目标说话人提取之《基于多模态信息的语音处理(misp) 2023挑战:视听目标说话人提取》
文章目录
- THE MULTIMODAL INFORMATION BASED SPEECH PROCESSING (MISP) 2023
- 前言
- 一、任务
- 二、动机
- 三、挑战
- 四、方法
- 1.
- 2.基线模型
- 3. 基线系统两阶段训练
- 4.
- 五、实验评价
- 1.数据集
- 2.消融实验
- 3.客观评价
- 4.主观评价
- 六、结论
- 七、知识小结
前言
语音新手入门,学习读懂论文。
本文作者机构是中国科学技术大学,卡内基梅隆大学,西北工业大学,科大讯飞

一、任务
提出了MISP 2023挑战赛,旨在通过使用MISP语料库的AVTSE系统提高后端ASR系统在实际场景中的准确性。具体而言,我们将使用预训练的ASR模型对AVTSE系统的语音输出进行解码,并以字符错误率(CER)作为评估指标。
二、动机
最近,神经科学的研究表明,包括面部和嘴唇运动在内的视觉模态可以显著影响人类的听觉注意,通过提供关于说话人的额外信息来增强语音感知,特别是在嘈杂的环境中。
三、挑战
现实场景中获取预注册音频的挑战,多个扬声器之间声学特征的潜在相似性,以及存在明显的噪声干扰。
当前的挑战有两个主要问题。首先,评价数据要么是在清洁语音中加入单一类型的噪声或干扰语音得到的模拟数据,要么是在真实场景中记录的,但说话者只是阅读特定的句子或单词排列。然而,在现实生活场景中,人们的对话通常没有特定的主题,并且他们遇到复杂的声学环境,其中包含多种类型的噪音,混响和其他扬声器的干扰,这可能导致模拟与现实之间的不匹配。其次,这些挑战通常使用深度噪声抑制平均意见评分(DNSMOS)、短时客观可理解度(STOI)和语音质量感知评价(PESQ)等指标来评估语音质量,或邀请工作人员根据他们的实际听力体验进行评分。
四、方法
1.
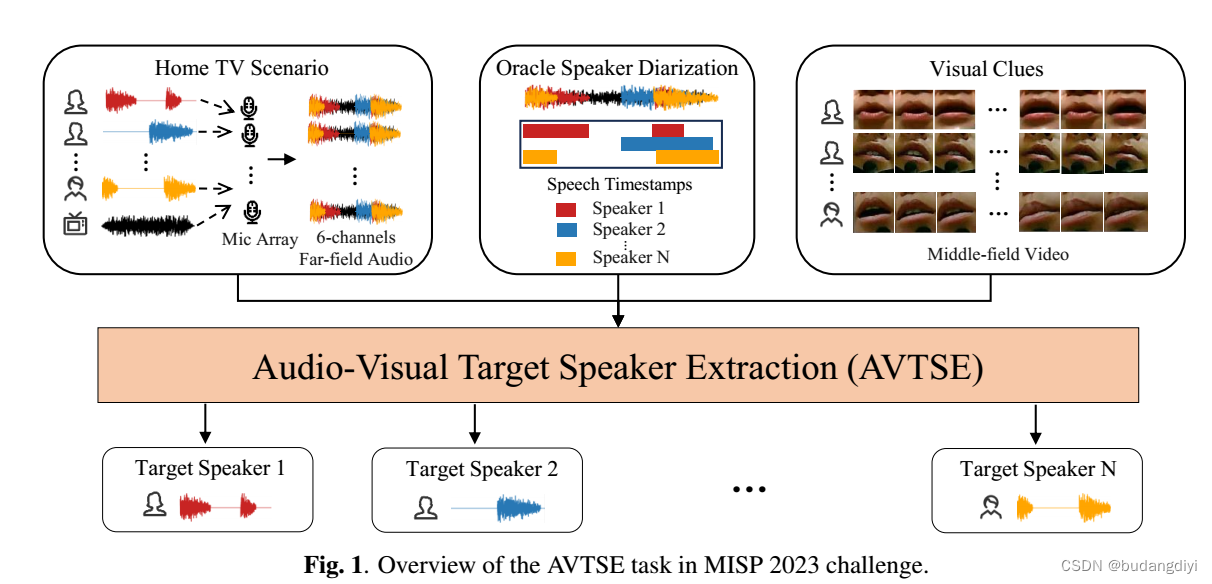
MISP语料库[19]侧重于真实的家庭电视场景:2-6人相互通信,背景是电视噪声和混响。在这种情况下,说话者在没有特定话题的情况下进行自发的对话,由于语言的重叠和多样性,这给谈话带来了挑战。此外,在某些会议中,来自电视的强烈背景噪声存在,其中可能播放电视节目,如戏剧,新闻,音乐和采访,进一步加剧了复杂性,特别是对于前端系统。
从包含多个说话人的重叠声音和背景噪声的录音中提取目标说话人的讲话。在一个会话中,每个演讲者依次被视为目标演讲者。我们还会提供oracle diarization的结果
2.基线模型
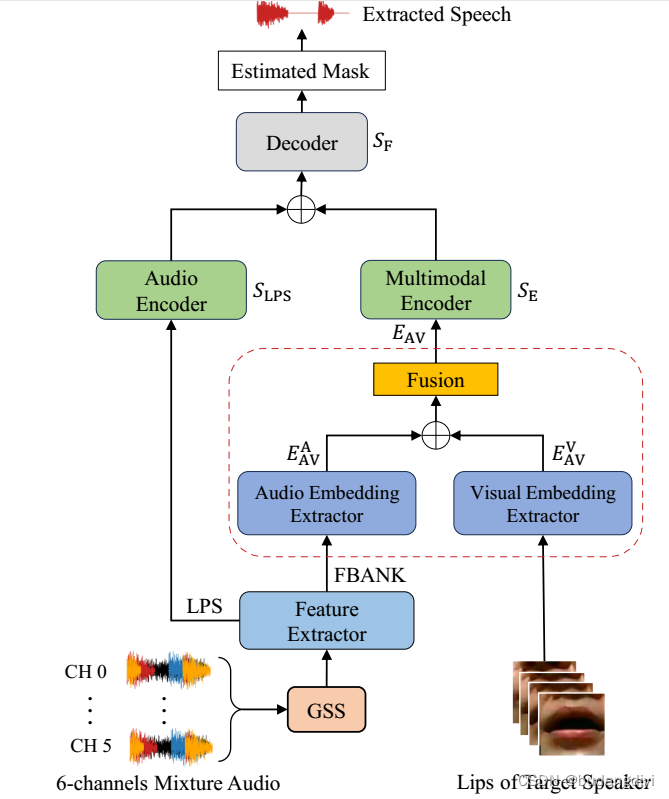
多模态嵌入感知语音增强(MEASE),该模型在视听语音增强(AVSE)领域实现了“SOTA”。利用oracle diarization结果对6声道混合音频进行引导源分离(guided source separation, GSS)。以初步减轻重叠语音的影响。然后使用MEASE模型进一步提取目标说话人的语音。
MEASE模型包括一个多模态嵌入提取器(红色虚线框)和一个嵌入感知增强网络。
首先从GSS的音频输出中提取FBANK特征和噪声对数功率谱(LPS)特征。随后,我们使用预训练的嵌入提取器从目标说话人的FBANK (AFBANK)和唇帧(V)中获得深度嵌入。
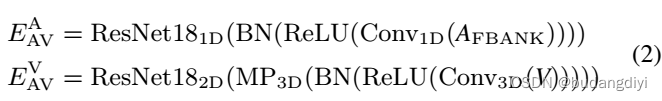
ReLu(·)、BN(·)和MP3D(·)分别代表ReLu激活层、批归一化层和时空最大池化层。
3. 基线系统两阶段训练
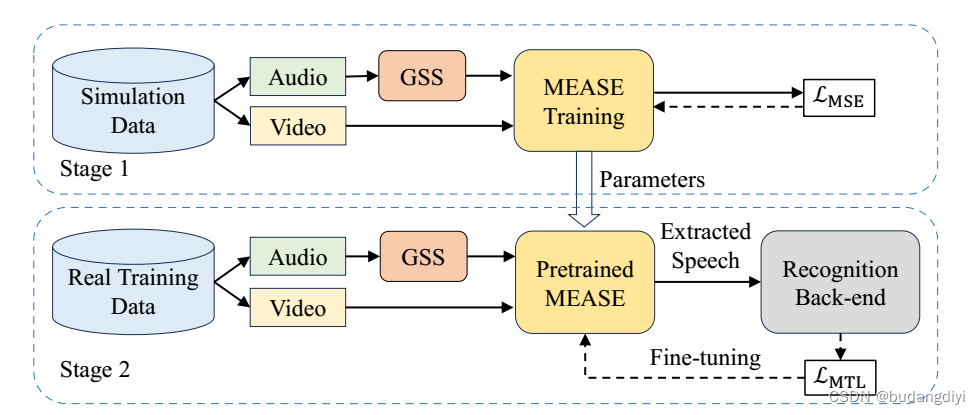
首先,以LMSE为损失函数,利用模拟数据训练MEASE模型;然而,这种训练方法由于没有考虑后端识别任务,不可避免地会导致提取的语音产生一定程度的失真,从而影响识别系统的准确性。因此,在第二阶段,作者使用识别后端对预训练的MEASE模型进行微调。作者在第二阶段使用了来自训练集的真实远场数据。
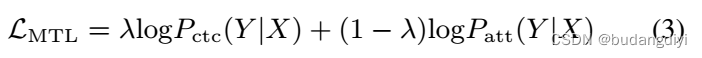
X和Y分别表示编码器输出和目标序列。λ是CTC损失与注意交叉熵(attention cross entropy, CE)损失之间的权重因子。
4.
五、实验评价
1.数据集
使用MISP 2021挑战的AVSR语料库训练集,持续时间为106.09小时,包括21个房间和200个扬声器。
2.消融实验
3.客观评价
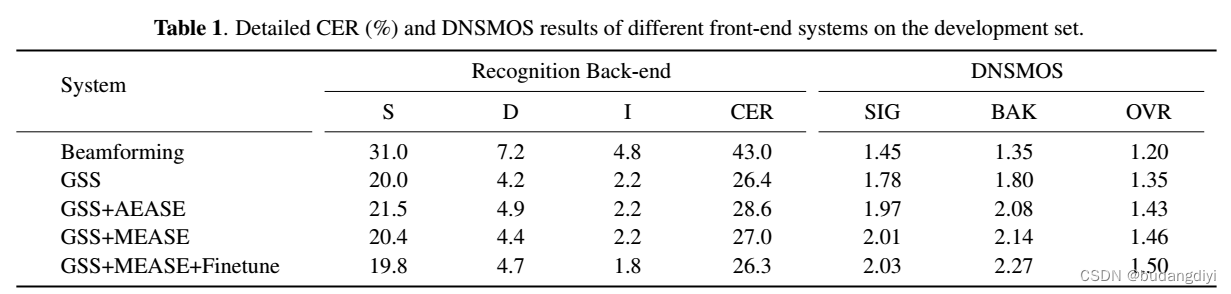
S, D, I表示替换,删除和插入的数量。N是基本真理中的字符数。
DNSMOS:深度噪声抑制平均意见评分
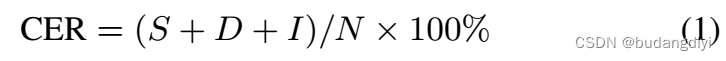
AEASE是MEASE的简化版本,因为它不利用视觉形式。
GSS+MEASE+Finetune”的结果作为我们最终的基线结果。
4.主观评价
六、结论
我们提供了MISP 2023挑战的数据集,任务设置和基线系统的详细描述,这是AVTSE任务的第一个基准。我们还对基线实验结果进行了深入分析,强调AVTSE任务在现实场景中仍然具有重要的研究潜力。未来,我们计划探索AVTSE系统在长录音情况下的解决方案,并结合主观听力测试,进一步研究真实语音听觉质量与后端任务性能之间的关系。