《LeetCode热题 100》
经过了两个多月,终于刷完了代码随想录的题目,现在准备开始挑战热题一百了,接下来我会将自己的题解以博客的形式同步发到力扣和 c 站,希望在接下来的征程中与大家共勉!
题组一:哈希
题集链接:LeetCode 热题 100
01.两数之和(No.1)
题目链接
<1> 题目
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 104-109 <= nums[i] <= 109-109 <= target <= 109- 只会存在一个有效答案
<2> 题解
本题中给出一个数组和一个 target,问数组中哪两个数字可以组合成 target;并且题目中明确的指出,一定会有且仅有一组解。
本题将选择限制在 两个数字,并且只有一种情况,那如果遍历到一个数字 i,其实只需要查询它的前面中存不存在 target - i 就可以了,比如说如下的情况:
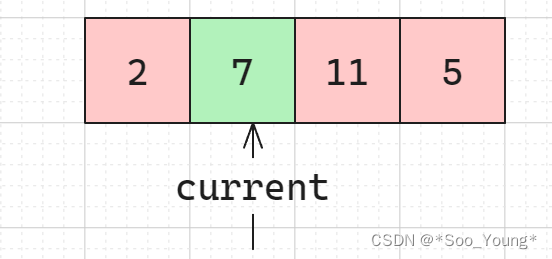
如果说当前遍历到 7,从开头到 7 是否遍历过 2 即可;但是这样每次都要从头开始遍历,时间开销比较大。
那能不能通过一个映射关系将每个数据是否出现和出现的位置存储下来,然后通过查询这个映射关系,来快速得知数组中是不是存在这个元素了呢?
比如上面的情况,当遍历到 2,先查询前面是否遍历到过 target - 2,如果没有就将 2 存储下来,并且与其出现的位置做一个映射;此时当遍历到 7 的时候,就可以通过查询这个映射来得知 2 是否出现过和其最后一次出现的下标是什么了。
for (int i = 0; i < nums.length; i++) {
int temp = target - nums[i];
if (map.containsKey(temp)) {
// 查看前面是否遍历过 target - nums[i]
res[0] = i;
res[1] = map.get(temp);
break;
}
map.put(nums[i], i); // 如果没有就将其存储下来,之后使用
}
其实到这里这道题就结束了,写出完整的代码:
<3> 代码
class Solution {
public int[] twoSum(int[] nums, int target) {
// key 为数字,value 为下标
int[] res = new int[2];
for (int i = 0; i < nums.length; i++) {
int temp = target - nums[i];
if (map.containsKey(temp)) {
res[0] = i;
res[1] = map.get(temp);
break;
}
map.put(nums[i], i);
}
return res;
}
}
02. 字母异位词分组(No. 49)
题目链接
<1> 题目
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
示例 1:
输入: strs = [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
输出: [[“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]]
示例 2:
输入: strs = [“”]
输出: [[“”]]
示例 3:
输入: strs = [“a”]
输出: [[“a”]]
提示:
1 <= strs.length <= 1040 <= strs[i].length <= 100strs[i]仅包含小写字母
<2> 题解
本题给出一组字符串,让我们将所有的 字母异位词 进行归类,放到一组中。
所谓字母异位词就是能够通过调换位置来变成相同的单词的一组词语,比如 “cat” “act” 和 “tac” 就是一组字母异位词。它们的特点就是 拥有的字母相同,同时 拥有的每个字母出现的次数也是相同的;判断两个单词是否是字母异位词其实也就是判断这个特点。
但显然 拥有字母相同、拥有的每个字母出现的次数相同 这两个特点直接写成代码是相当冗余的,所以这时候就考虑到有没有一种方式能将拥有这两个特点的单词映射为同一个数据结构,那对于本题,其实就可以映射为一个数组,下标表示它是 “a” 到 “z” 中的哪一个(题目中规定了只会出现小写字母),数组中存储的是这个单词出现的次数,比如 abbbcc 经过映射之后就是这样的:

用 ASCII 码可以将字母映射为数字,利用这个式子:
字母 - 'a'
写出代码就是这样的:
public int[] getHash(String s) {
int[] hash = new int[26];
for (int i = 0; i < s.length(); i++) {
hash[s.charAt(i) - 'a']++;
}
return hash
}
这样每种单词就被映射为一个唯一的数组,如果它们是字母异位词,那它们的这个 hash 数组就一定是相同的。
那本题就可以先去遍历,每次遍历到一个字符串,就将其转化为这种哈希数组,然后判断这个哈希数组在之前是否出现过,如果出现过 就将其归为一类。
思路到这里其实就比较清晰了,但是代码实现上还是有些困难,首先遇到的第一个问题,我如何将哈希数组和字符串存在一起呢?
相当简单,用 Map 嘛!但是 Map 不能将非包装类作为键值对,首先要解决的就是将哈希数组变为可以放到 Map 类中的类型。
最容易想出来的就是将字符串拼接起来,所以自然的写出了如下的代码:
StringBuilder res = new StringBuilder();
for (int i : hash) {
res.append(i);
}
return res.toString();
但是此时,虽然我们的哈希数组是唯一的,但是通过这种方式转化成的字符串可不一定是唯一的啊,比如说这两个字符串:“bdddddddddd”,“bbbbbbbbbbc”,将它们拼接然后写出来就会出现如下的情况:
01010000000…
01010000000…
啊,相同的,那怎么办呢?
其实解决方式也很简单,将它们隔开就可以了,变成这样
0|1|0|10|000000…
0|10|1|0|000000…
在每次 append 之前再 append 上一个 | 就可以实现了。
此时就终于解决了将每一个字符串映射为同一种数据类型,可以使用 Map 将哈希数组和字符串映射起来了;此时去遍历字符串,获取映射好的哈希数组字符串,然后检查 Map 中是否含有这个哈希字符串,如果含有就将其存放到 **值(Value)**中的 List 中,如果不存在,就构造一个新的链表存入这个元素然后将其放到 Map 中。
if(map.containsKey(hash)) {
// 存在的情况
List<String> strings = map.get(hash);
strings.add(s);
} else {
// 不存在的情况
List<String> list = new ArrayList<>();
list.add(s);
map.put(hash, list);
}
完成!写出最终代码
<3> 代码
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<>();
for (String s : strs) {
String hash = getHash(s);
if(map.containsKey(hash)) {
List<String> strings = map.get(hash);
strings.add(s);
} else {
List<String> list = new ArrayList<>();
list.add(s);
map.put(hash, list);
}
}
return new ArrayList<>(map.values());
}
public String getHash(String s) {
int[] hash = new int[26];
for (int i = 0; i < s.length(); i++) {
hash[s.charAt(i) - 'a']++;
}
StringBuilder res = new StringBuilder();
for (int i : hash) {
res.append("|");
res.append(i);
}
return res.toString();
}
}
03. 最长连续子序列(No. 128)
题目链接
<1> 题目
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9
提示:
0 <= nums.length <= 105-109 <= nums[i] <= 109
<2> 题解
(1)哈希解法
本题其实类似 两数之和 的思想,比如说我手中有一个 3,那此时要寻找的就是 2 是否出现过,并且以 2 作为结尾的子序列的长度为多少,如果没有出现过,那 3 就只能作为子序列的第一个元素。
所以此时就需要一个数据结构,能够同时存储某个元素是否出现,且能存储以它为结尾的子序列的长度,那就是双列集合 Map 了,将 KEY 设定为数字,将 VALUE 设定为以它为结尾的子序列的长度;此时为了让在遍历 3 之前,得知 2 是否遍历过,且要知道长度,那此时就必须对数组进行 排序处理。
对每个数字分为两种处理逻辑:
- 如果 num - 1 出现过,那此时以它为结尾的长度就是 map.get(num - 1) + 1
- 如果没有出现过,那此时以它为结尾的长度就是 1
以上两种情况都要将其存放到 map 中。
if (map.containsKey(num - 1)) {
int l = map.get(num - 1);
map.put(num, l + 1);
res = Math.max(res, l + 1);
} else {
map.put(num, 1);
}
每次加一的时候获取一次值,因为不确定最终的结果是以谁为结尾,后面附上完整的代码。
(2)动态规划解法
其实本题我首先想出来的就是动态规划的解法,接下来分析一下解题的思路
1. 状态
将本题的状态考虑出来解答就比较简单了,就是以 num 为结尾的子序列的最大长度。
思考一下这个状态能否转移呢?
以 nums 为结尾的子序列的长度其实就是通过以 nums - 1 为结尾的子序列的长度推出的,所以为了让 dp 数组中的元素紧凑,此时也需要先对数组进行 排序。
2. dp 数组
dp[i] 就定义为以 i 结尾,最长的子序列的长度。
3. 状态转移方程
回顾一下 dp 数组,如果对递推公式存在疑问先回去看dp数组的定义
分为三种情况,因为 nums 已经排好序了,所以 nums[i] 的上一个可能
- 等于 nums[i]
- 小于 nums[i] - 1
- 等于 nums[i] - 1
对于第一种情况,那 dp[i] = dp[i - 1]
对于第二种情况,就为 dp[i] = 1
最后一种情况就是恰好等于的情况,也就是 dp[i] = dp[i - 1] + 1;
4. 初始化
本题依赖于 dp[i - 1] 所以一开始要将 dp[0] 初始化成 1
写出完整的代码
<3>代码
哈希解法
class Solution {
public int longestConsecutive(int[] nums) {
if (nums.length == 0) return 0;
Map<Integer, Integer> map = new HashMap<>(); // 存储出现过的数字和长度
int res = 1;
Arrays.sort(nums); // 排序
for (int num : nums) {
int temp = 0;
if (map.containsKey(num - 1)) {
// 如果出现过
int l = map.get(num - 1);
map.put(num, l + 1);
res = Math.max(res, l + 1);
} else {
// 未出现过的话
map.put(num, 1);
}
}
return res;
}
}
动态规划解法
class Solution {
public int longestConsecutive(int[] nums) {
if (nums.length == 0) return 0;
Arrays.sort(nums); //先对数组进行排序
int[] dp = new int[nums.length];
dp[0] = 1;
int res = 1;
for (int i = 1; i < nums.length; i++) {
if (nums[i] == nums[i - 1]) {
// 相等的情况
dp[i] = dp[i - 1];
continue;
}
if (nums[i] == nums[i - 1] + 1) {
dp[i] = dp[i - 1] + 1;
} else {
dp[i] = 1;
}
res = Math.max(res, dp[i]);
}
return res;
}
}