本文是观看视频What is Prompt Tuning?后的笔记。
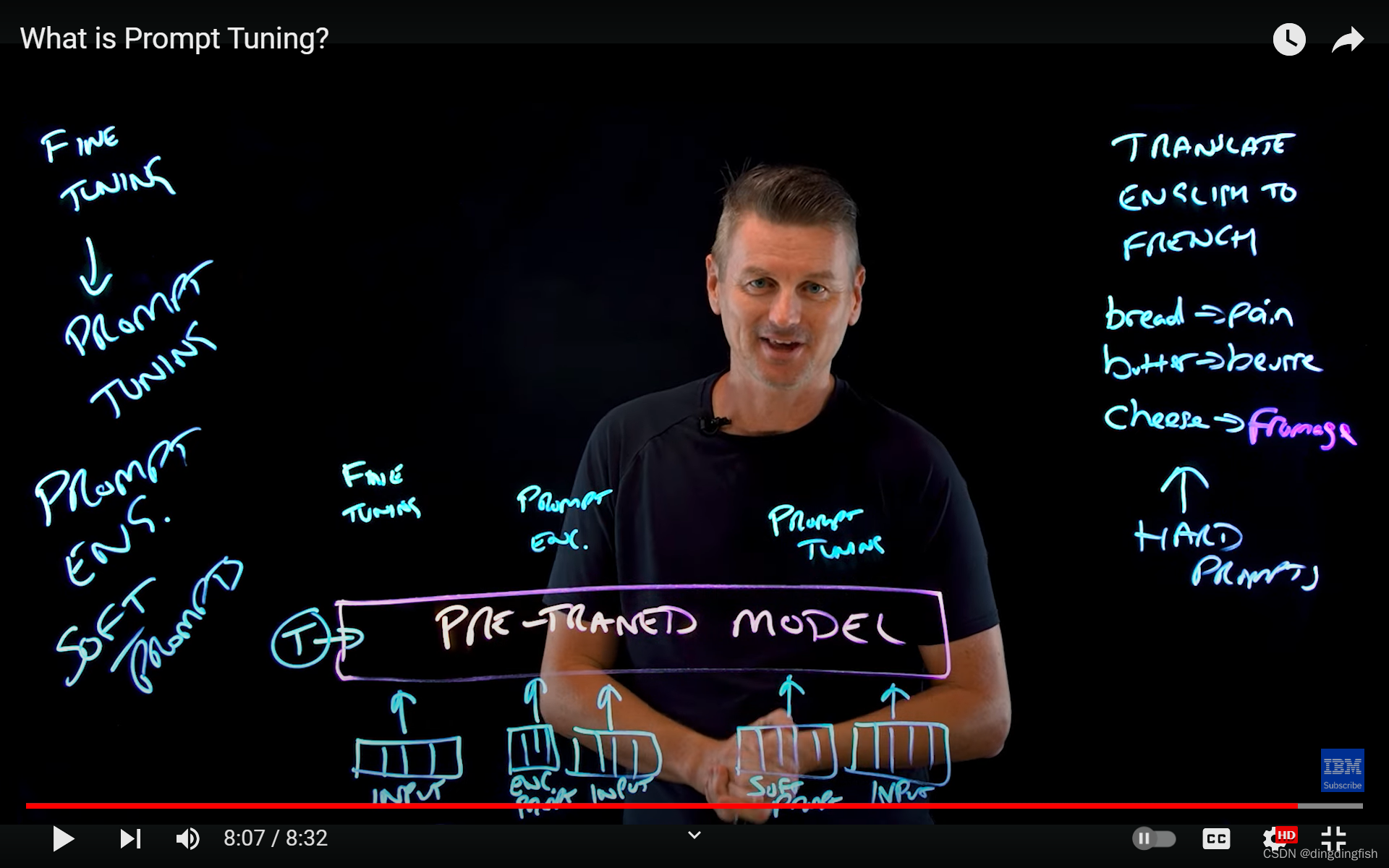
大语言模型(如ChatGPT )是基础模型,是经过互联网上大量知识训练的大型可重用模型。 他们非常灵活,同样的模型可以分析法律文书或撰写文章。 但是,如果我们需要用其解决专门的任务,目前最好的方法是使用微调(fine tuning)。
通过微调,你可以收集并标记目标任务的大量示例,然后你可以微调您的模型,而不是从头开始训练一个全新的模型。 但现在出现了一种更简单、更节能(指不需要消耗太多GPU)的技术来代替微调,这就是提示调整(prompt tuning)。
提示调整可以使用有限的数据,针对非常特定的任务定制大模型。 并且不需要像微调那样收集数千个带标签的示例。 在提示调整中,优质准确的提示将被输入到AI 模型中,为其提供特定于任务的上下文。 提示可以是人类引入的额外单词,更常见的则是引入模型嵌入层的人工智能生成的数字,以指导模型做出所需的决策或预测。
使用提示来指导大语言模型的输出,这就是提示工程(prompt engineering),即开发提示来指导大语言模型执行特定任务的任务。例如,希望大语言模型翻译英语为中文,我可以通过设计(engineer)提示来实现。
首先,我的第一个提示会是“将英语翻译成中文”。 这个提示是任务的描述。 然后,添加一些简短的示例。 例如,英语单词“bread”变成“面包”,将“butter”变成“黄油”。 然后,在提示的下一部分,我将添加接下来要翻译的单词:“cheese”。
由人类编写的提示发送给模型,然后模型从其巨大内存中检索适当的响应,模型的输出是就是它的预测。在本例中专门针对中文中的其他单词,输出为 “奶酪”。我们使用提示工程来训练模型来执行专门的任务,只需在推理时引入一个提示,而无需重新训练模型。
如果任务更复杂,需要成百上千的提示。那么我们可以用AI设计的提示(称为软提示)替代手工提示(由人类硬编码的,也称为硬提示)。软提示通常优于硬提示,人眼无法识别,每个提示都包含一个嵌入或一串数字(嵌入层的这一串数字要比人工编制成百上千的提示方便的多),他们可以从大模型中提取知识。
这些软提示可以是高级提示或特定于任务的提示,他们替代了额外的训练数据,对于引导模型得到所需输出非常有效。 不过,提示调整的缺点之一是缺乏可解释性。 这意味着人工智能会发现针对给定任务进行优化的提示,但它通常无法解释为什么选择这些嵌入。 就像深度学习模型本身一样,软提示也是不透明的。
假设我们有一个预先训练的大语言模型,现在,让我们考虑三种方法来使其可以完成特定任务。
- 微调(fine tuning)。 针对目标任务,我们将成千上万个样例数据补充到模型中,然后对模型进行调整即可。
- 提示工程(prompt engineering)。无需调整模型,只需给模型输入2个提示:即问题本身和人工编写的提示(硬提示,如前翻译的例子)。
- 提示调整(prompt tuning)。无需调整模型,只需给模型输入2个提示:即问题本身和AI编写的软提示。
提示调整可以在多个领域改变游戏规则。 例如在多任务学习中,建模者需要在任务之间快速切换,多任务提示调整等技术使模型能够快速适应,并且成本比重新训练小得多。 又如在持续学习领域,AI模型需要学习新任务和概念而不忘记旧的。 所以,提示调整可以让您比微调和提示工程更快地使模型适应专门任务,从而更容易发现和修复问题。
所以这篇文章要点是什么呢。
- 通用模型变专用模型,可以用微调和提示2种技术,提示更轻量级些。
- 提示又分为提示工程和提示调整2类。前者是人工的,称为硬提示;后者是软件的,称为软提示,更自动化。
- 提示涉及嵌入,这又和向量数据库产生了关系。
提示工程和提示调整的区别,可参见文章Prompt Engineering vs Prompt Tuning: A Detailed Explanation
![鱼眼相机的测距流程及误差分析[像素坐标系到空间一点以及测距和误差分析]](https://img-blog.csdnimg.cn/direct/07bb974a9eff4c16a7c897d0535b04d5.png)