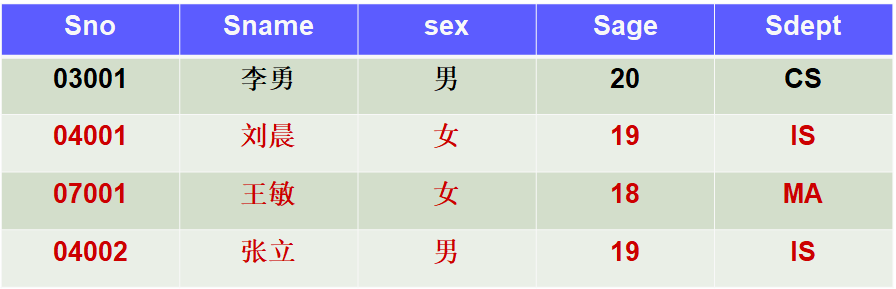
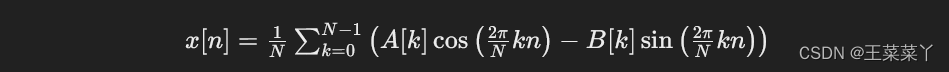深度学习中的优化问题
简要指南
我在 2019 年底左右开始撰写有关数学和机器学习的文章;从那时起,我写了数百篇教育文章,揭示了我们日常使用的算法背后的细节。
让写文章的人 感到尴尬的一个方法是:让他们阅读他们早期的作品。我也不例外。距离 2019 年已经过去了很长一段时间。(尽管我的写作速度仍然缓慢。)
尽管如此,还是有几篇早期的文章让我感到自豪。我捕捉到直觉和精确度之间最佳平衡点的帖子。最近,我一直致力于重新制作其中最好的部分。
这是第一个,我们从零开始优化百万变量的函数。让我们开始吧!
哪些参数对神经网络的性能贡献最大?
这是一个复杂的问题,因为性能取决于多个因素。通常最受关注的是网络架构。然而,这只是众多重要组成部分之一。高性能算法的一个经常被忽视的组件是用于拟合模型的优化器。
为了说明优化的复杂性,请考虑具有 11689512 个参数的 ResNet18 架构。寻找最优参数配置与在 11689512 维空间中定位点相同。我们可以通过以下方式暴力破解
-
用网格划分空间,
-
沿每个维度选择 10 个点,
-
并通过计算每个参数的损失函数来检查 10^11689512 个可能的参数配置,以找到损失最小的参数配置。
为了形象的理解数字 10^11689512,宇宙大约有 10^83 个原子,估计年龄为 4.32 × 10^17 秒(约 137 亿年)。如果我们每秒检查的参数配置与从大爆炸开始的原子数一样多,那么到目前为止我们已经能够检查 4.32 × 10^1411 个点。
这还差的很远。如果我们让宇宙中的每个原子检查自大爆炸以来的配置,网格大小仍然比我们可以检查的大约 10^8284 倍大。
所以,优化非常重要。如果没有优化器,深度学习就不可能实现。它们管理着这种难以理解的复杂性,使我们能够在几天而不是数十亿年的时间内训练神经网络。
在这篇文章中,我们将深入研究优化器的数学原理,看看它们如何处理这个看似不可能的任务。
优化的基础知识
让我们从简单的开始,最大化单个变量的函数。 (在机器学习环境中,我们的目标是最小化损失,但最小化 f 与最大化 f 相同。)例如,我们定义 f(x) = 25 · sin(x) - x²。
绘制的函数图像如下!

第一个想法是用线分成网格,检查每个点的值,然后选择函数最大化的点。正如我们在简介中所看到的,这是不可扩展的。因此,我们必须寻找另一种解决方案。
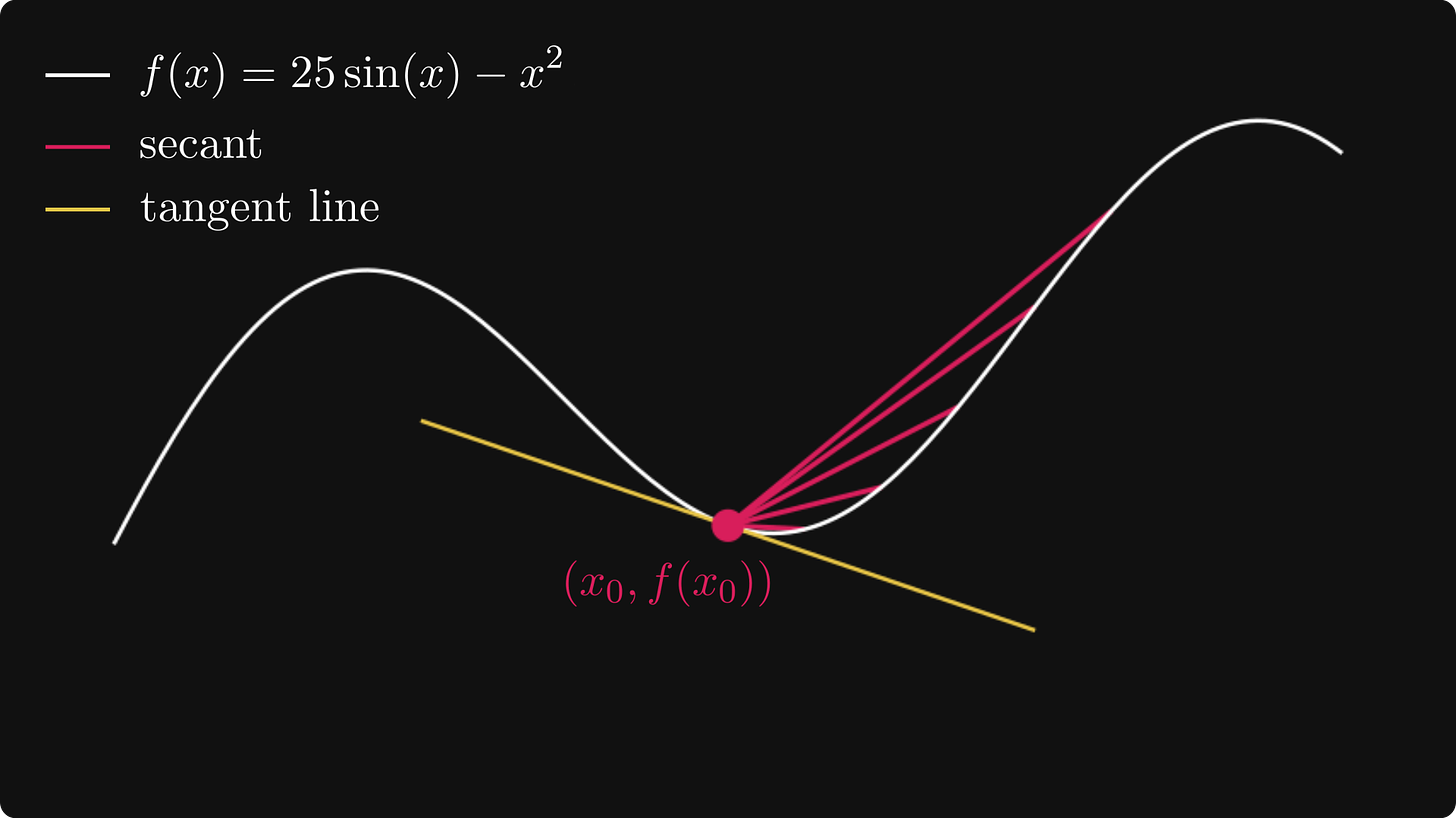
让我们想象一下,该功能是一个山区,而我们是试图到达顶峰的登山者!假设我们位于红点标记的位置。

如果我们想找到顶峰,我们该往哪个方向走呢?向上升的方向走。
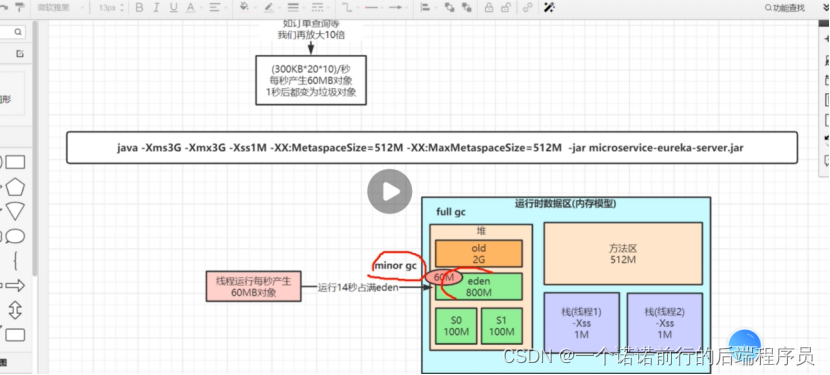
“上升”的概念由 导数的概念形式化。在数学上,导数定义为
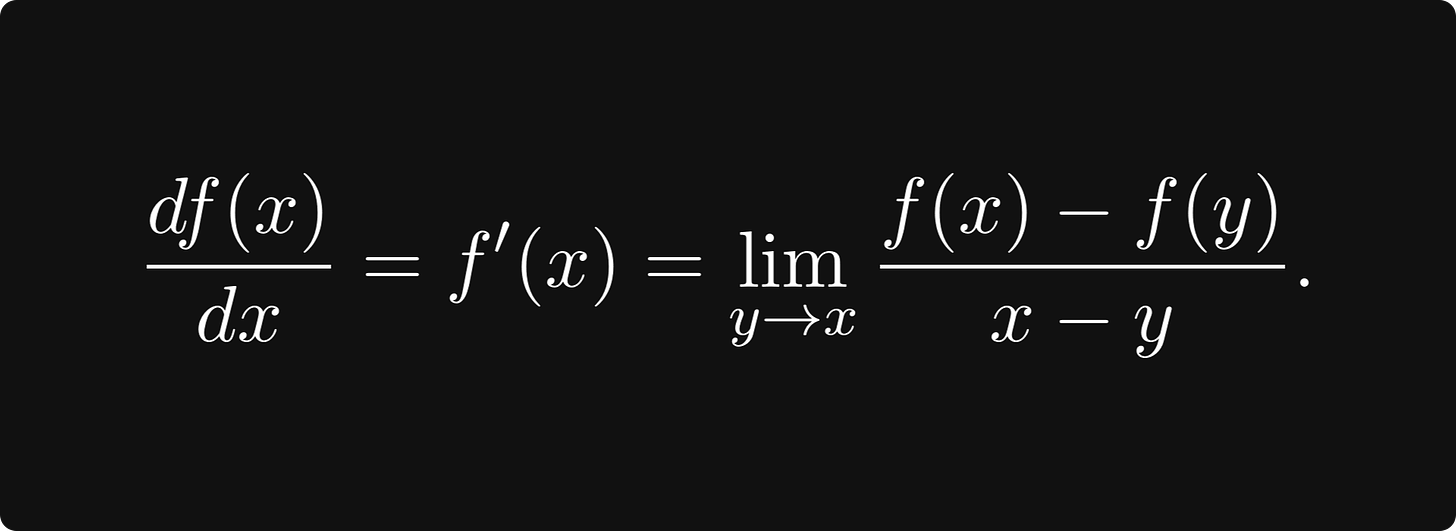
虽然这个量乍一看似乎很神秘,但它却具有简单的几何意义。让我们更仔细地观察点 x₀ 附近的函数,我们在此求导。
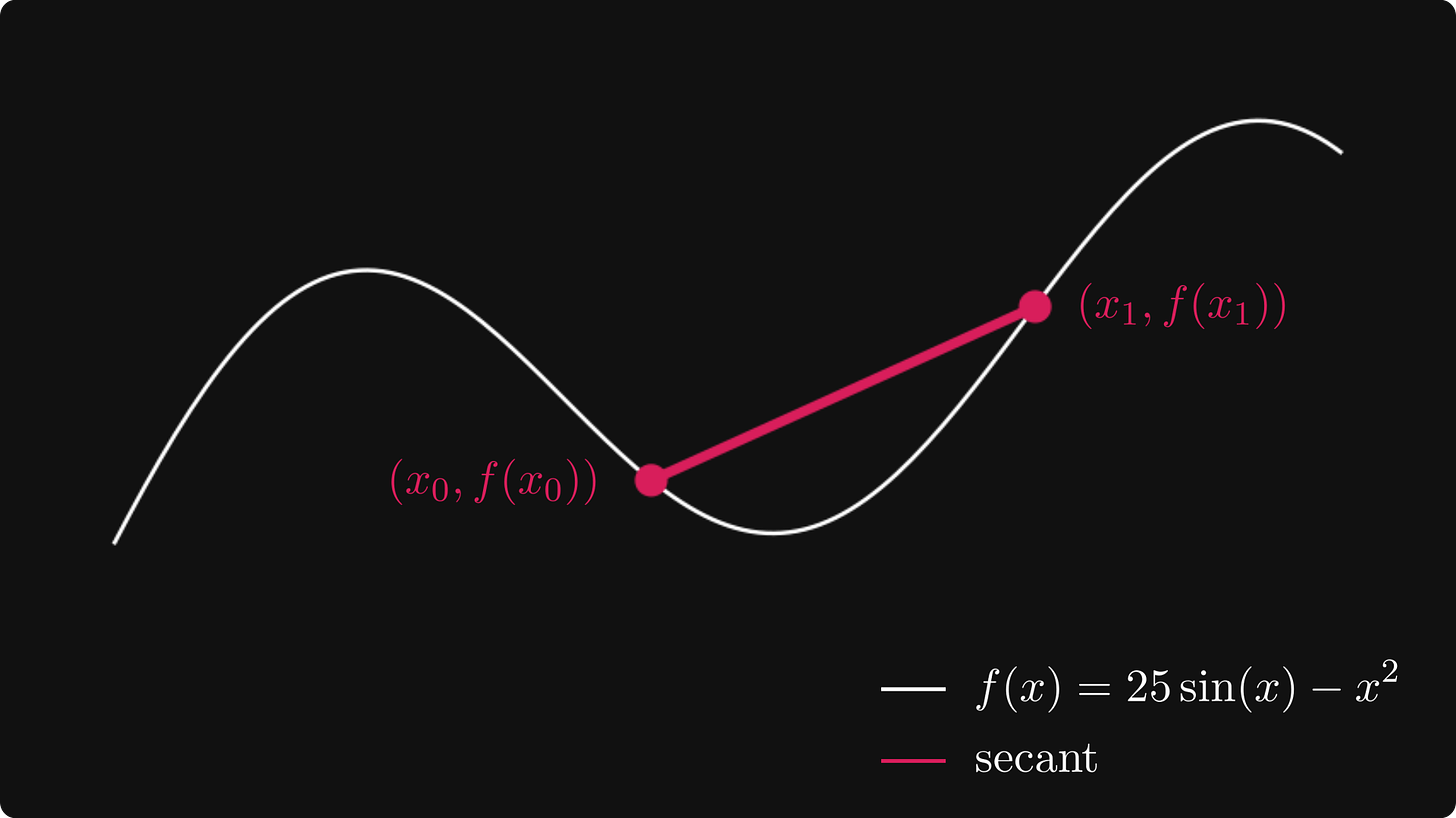
对于任何 x 和 y,通过 f(x) 和 f(y) 的直线由以下方程定义
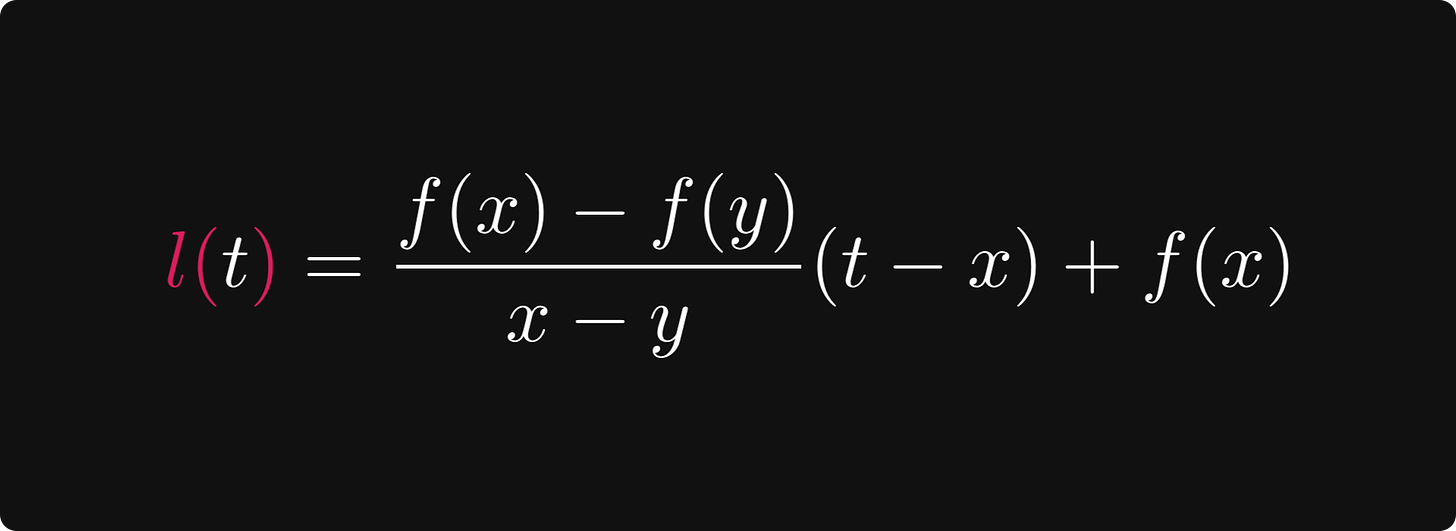
一般来说,对于由 at + b 定义的直线,量 a 称为直线的斜率。斜率也可以是负值,也可以是正值。
斜率为正的线向上,负斜率的线向下。绝对值 越高意味着线条越陡。如果我们让 y 越来越接近 x₀,就像导数定义中那样,我们会看到该线变成函数图在 x₀ 处的切线。
切线方程由以下函数给出

我们可以用向量 (1, f '(x)) 来描述它的方向。
如果我们再次想象自己处于登山者的位置,从 x₀ = -2.0,我们应该朝切线上升的方向前进。如果切线斜率很大,说明有很大的上升空间,则采取较大的步长,而如果斜率接近于零,这时接近峰值,应该采取较小的步长,以确保我们不会越过峰值。为了以数学方式形式化这一点,我们应该转到由下式定义的下一个点:
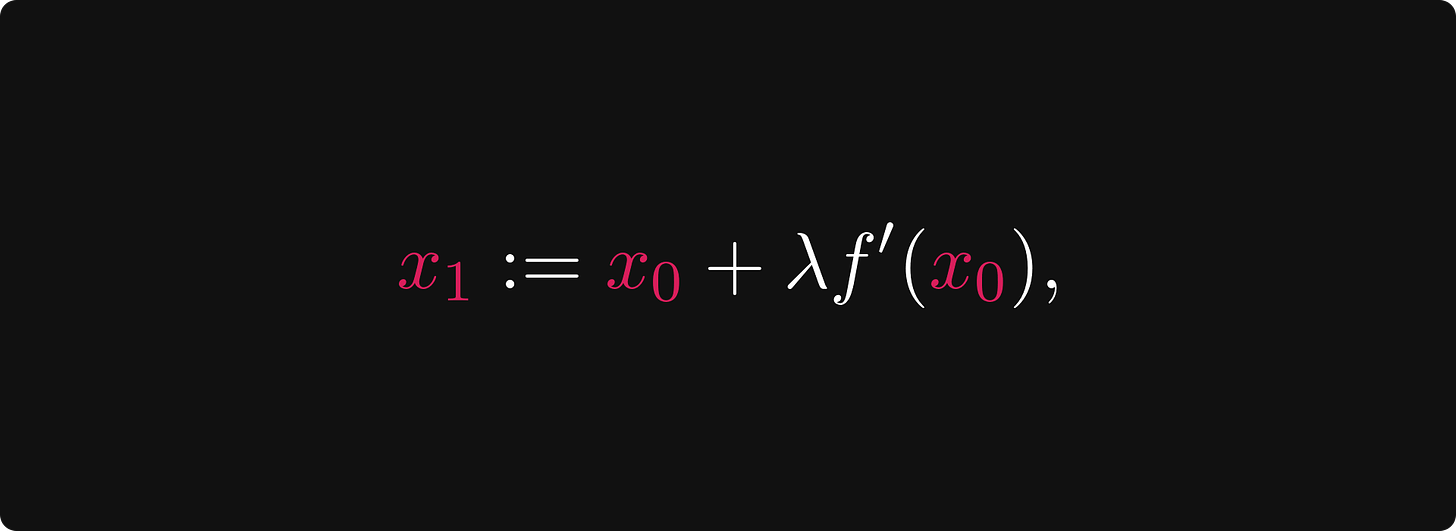
其中 λ > 0 是称为学习率的参数,设置在 上升 方向上的步长应有多大。
想一想:如果导数 f’(x₀) 为正,则 x₁ 使其向正方向移动。如果 f’(x₀) 为负,则 x₁ 向负方向移动。
后续步骤定义为

让我们想象一下这个过程!
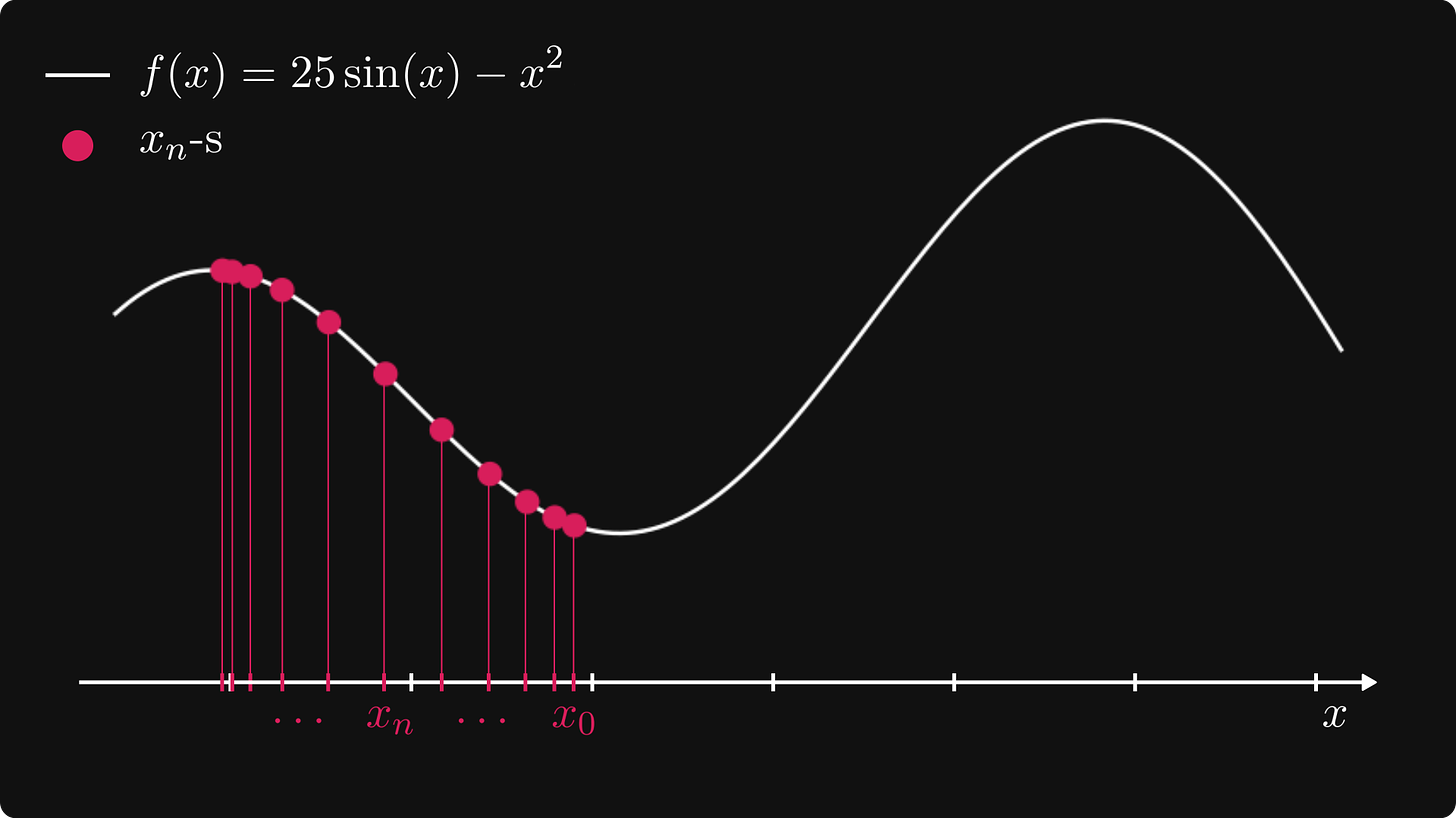
正如我们所看到的,这个简单的算法成功地找到了峰值!
(然而,这并不是函数的全局最大值。先说一下,这对于广泛的优化算法来说是一个潜在问题,但有解决方案。)
在这个简单的例子中,我们只最大化了单个变量的函数。这对于说明这个概念很有用。然而,在现实生活场景中,可能存在百万变量。对于神经网络来说,情况确实如此。下一部分将展示如何推广这个简单的算法来优化多维函数!
多维度优化
对于单变量函数,我们可以将导数视为切线的斜率。然而,对于多个变量,情况就不同了。
让我们通过研究一个例子来建立我们的直觉!定义函数
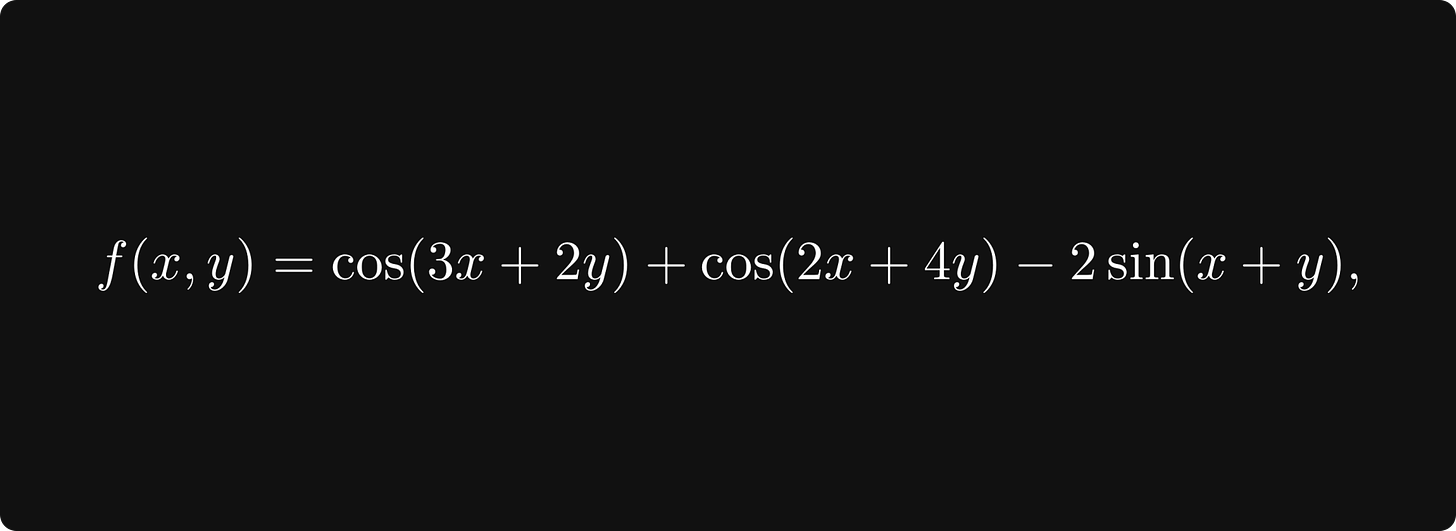
这将是本节中我们的demo示例。

作者注。对于插图的不一致表示歉意,但我未能适应 Manim 中的多变量曲面图。尽管我竭尽全力调整
z_index,但我无法按照正确的顺序正确渲染曲面和切平面。
对于两个变量的函数,图像是一个曲面。我们立即发现 切线的概念没有明确定义,因为我们有许多到曲面上给定点的切线。事实上,过该点的所有切线形成了一个平面。这称为切平面。
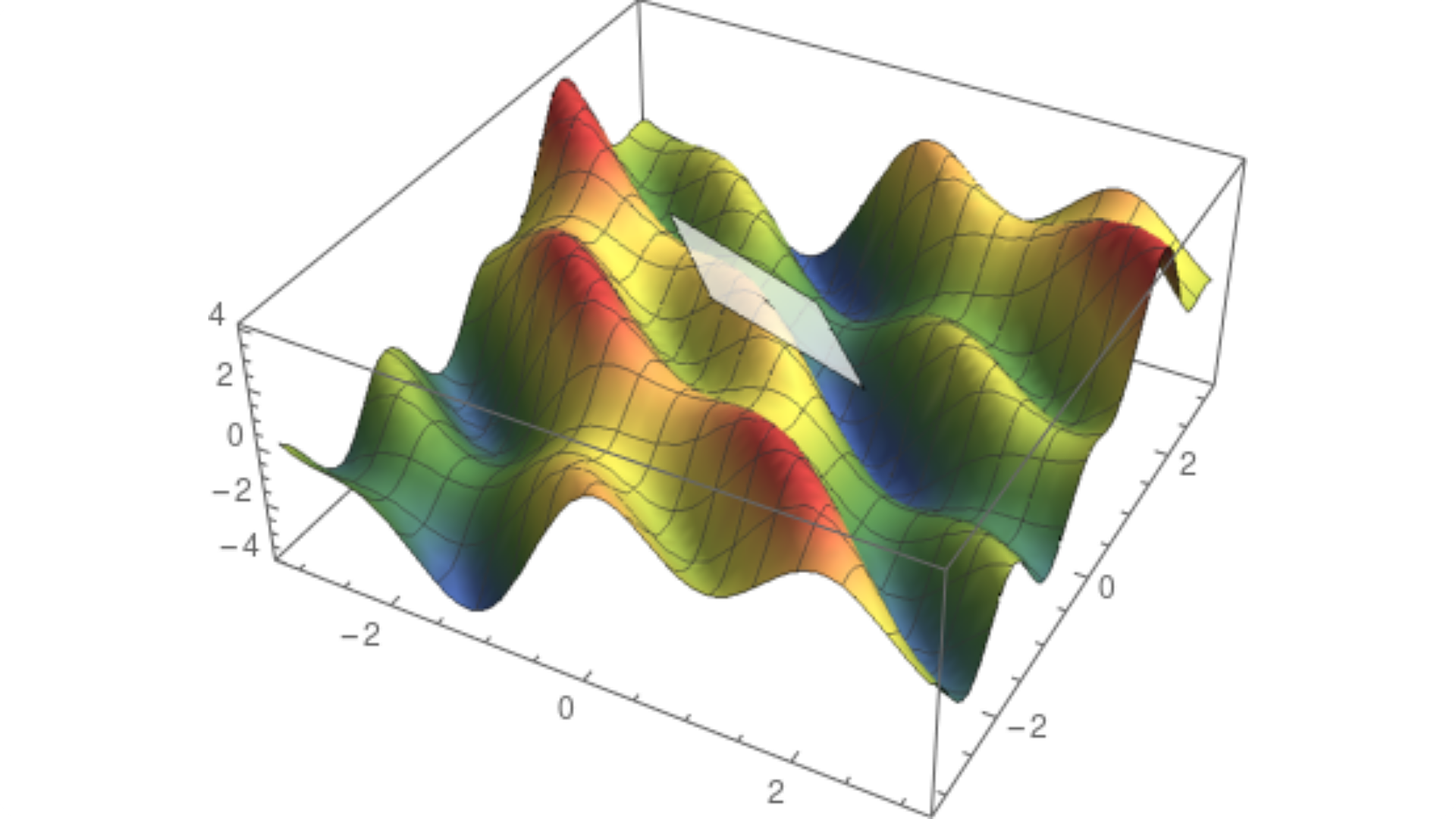
然而,切平面包含两个特殊方向。
假设我们正在查看 (0, 0) 处的切平面。对于每个多变量函数,固定除一个变量之外的所有变量都是单变量的函数。在我们的例子中,我们将有两个函数
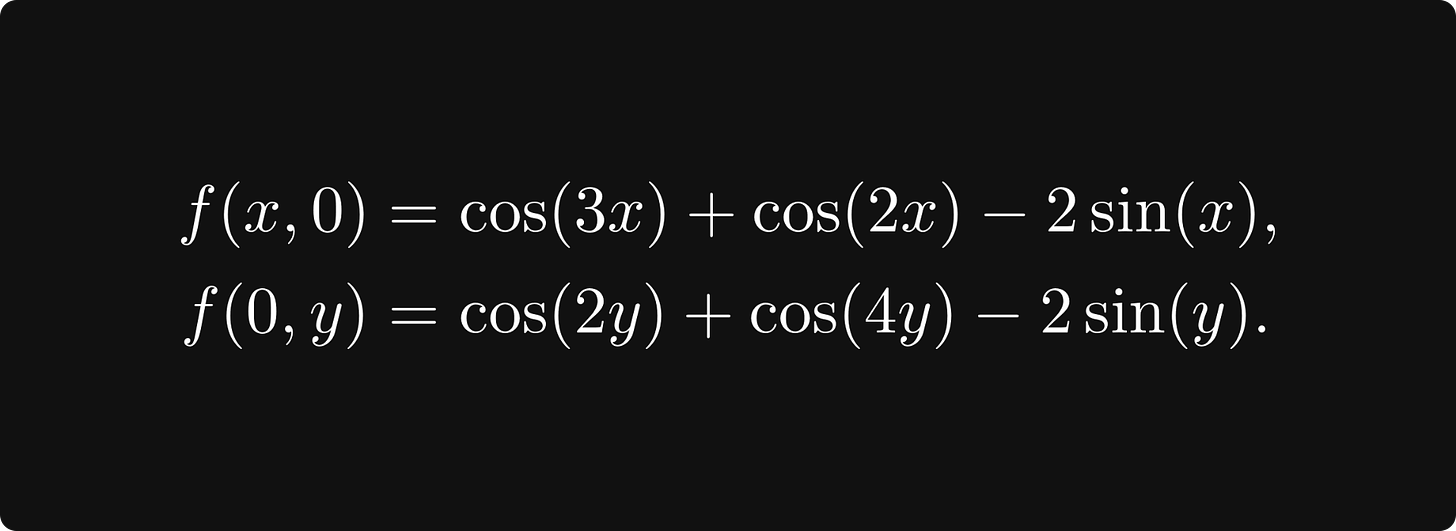
我们可以通过用垂直于其中一个轴的垂直平面对曲面进行切片来可视化这些函数。平面和曲面相交的地方是 f(x, 0) 或 f(0, y) 的图形,具体取决于您使用的平面。这就是它的样子。
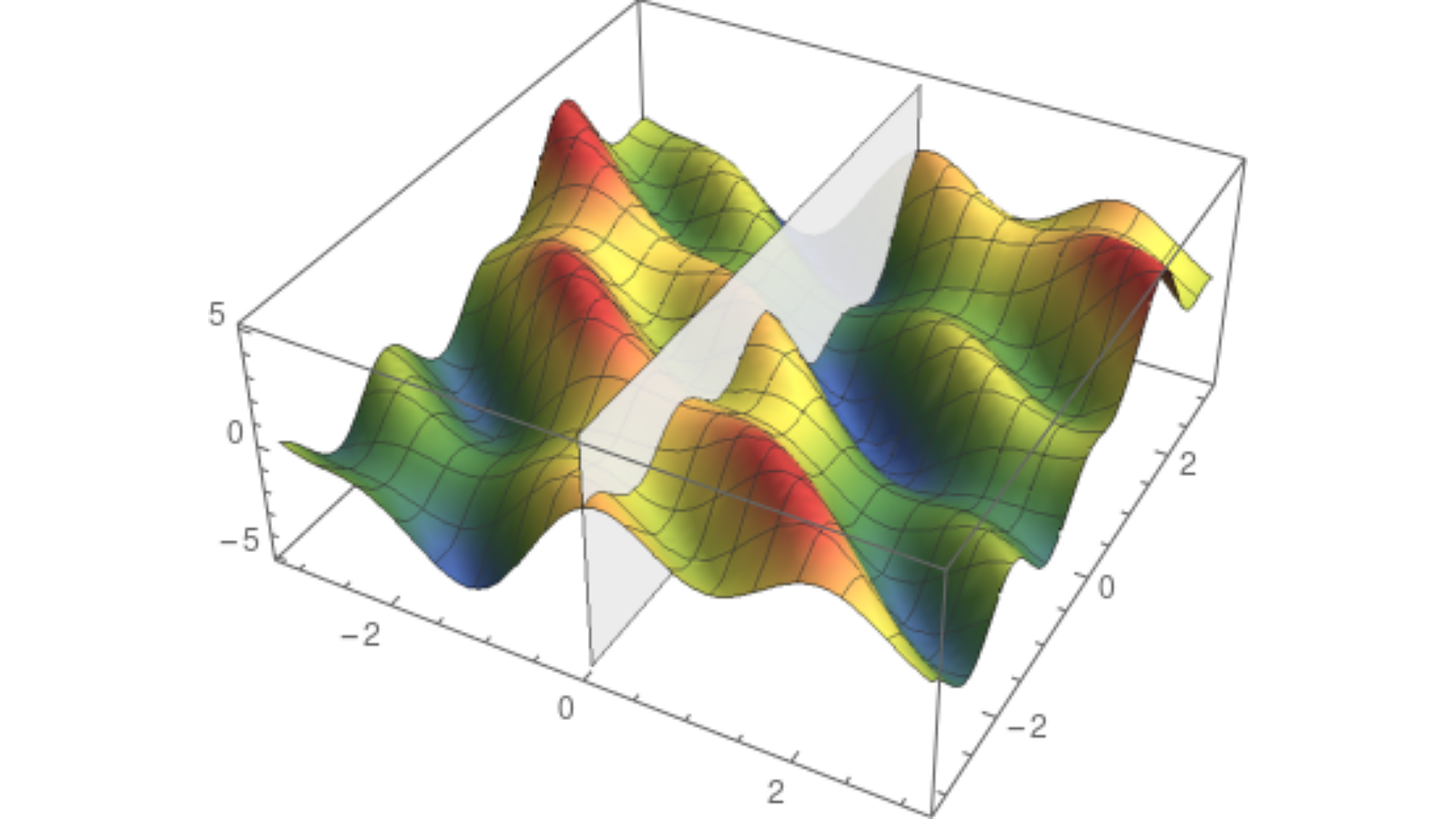
对于单变量函数 f(x, 0) 和 f(0, y),我们像上一节中所做的那样定义导数。这些称为 f(x, y) 的偏导数,它们在我们的寻峰算法中发挥着重要作用。
在数学上,偏导数定义为
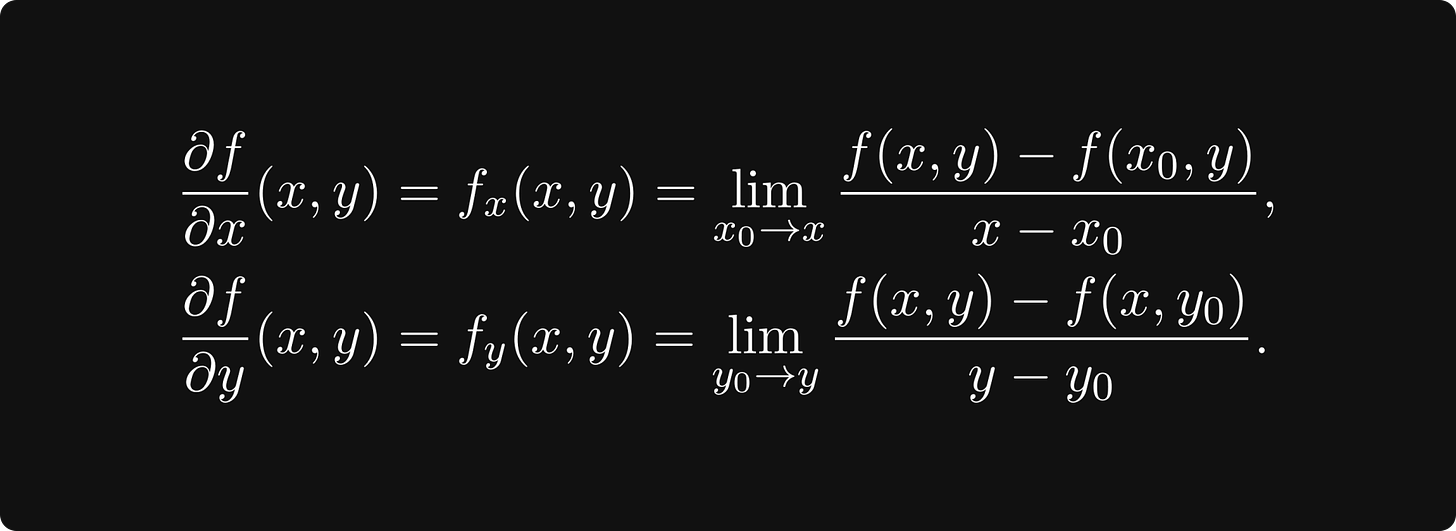
每个偏导数代表切平面中的一个方向。
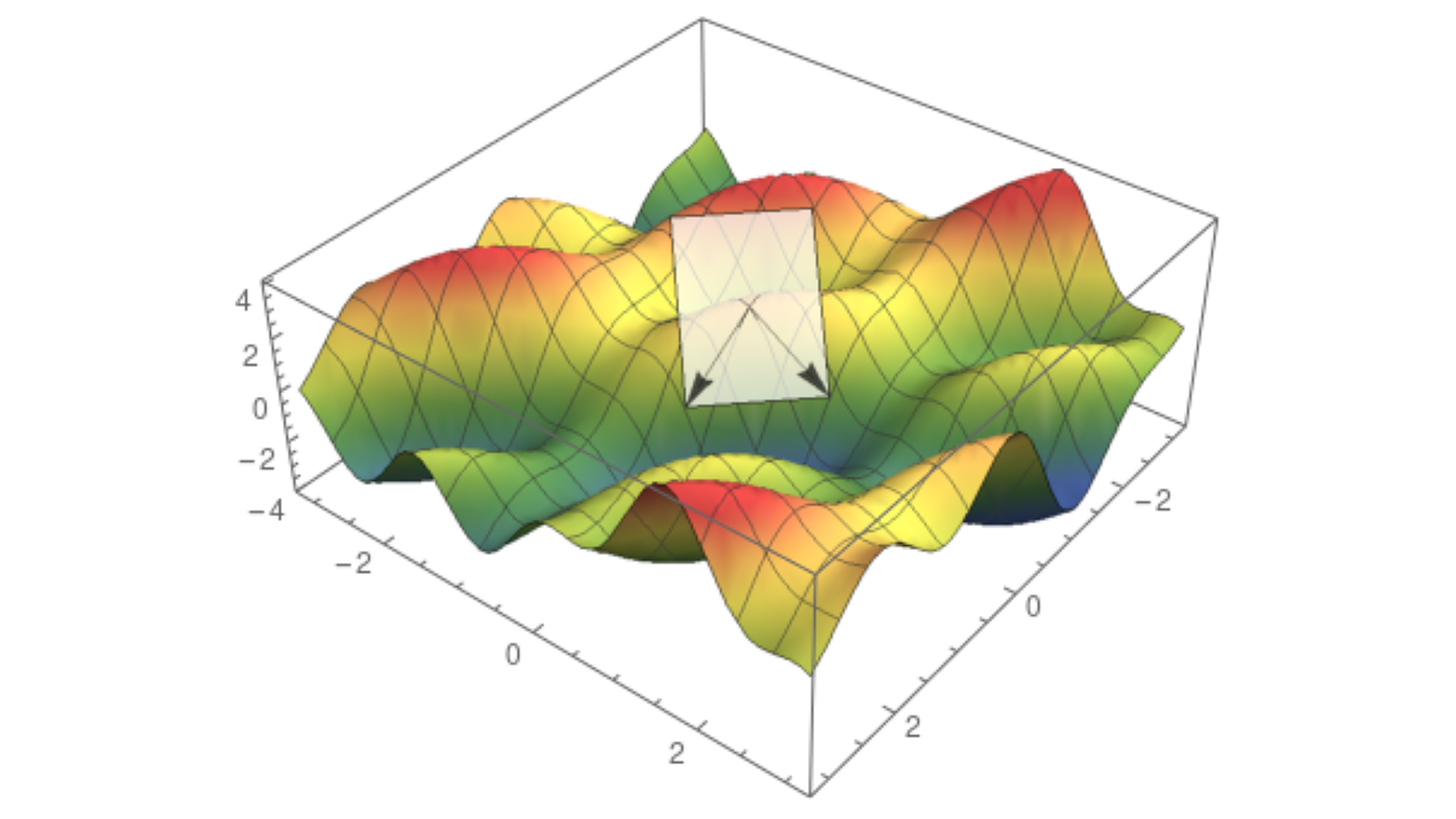
偏导数描述了 f(x,·) 和 f(·, y) 切线的斜率。
最陡上升的方向由梯度给出,定义为
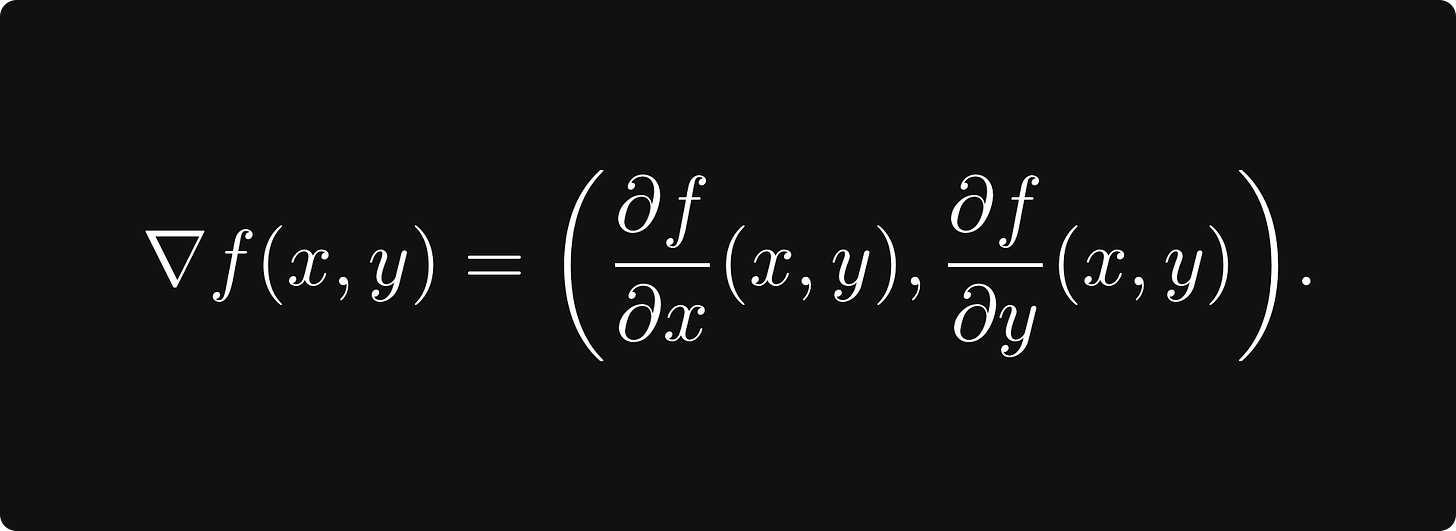
(请注意,梯度是参数空间中的方向。)
总而言之,峰值查找算法现在是
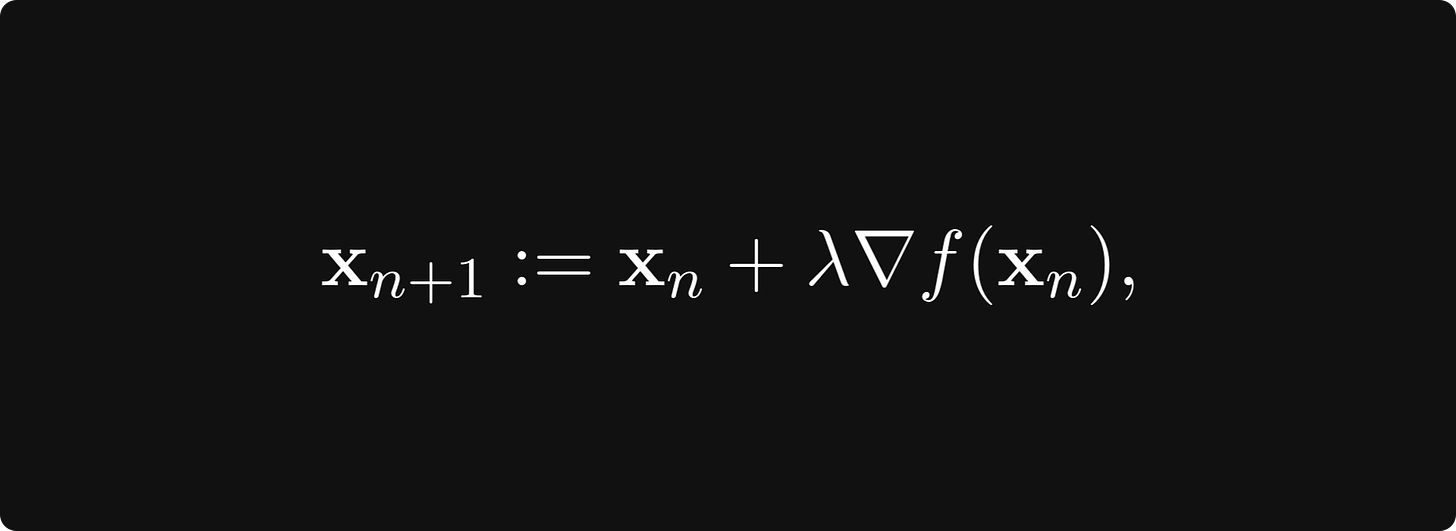
这称为梯度上升。为了找到函数的最小值,我们向 负梯度方向迈出一步,即最速下降的方向:
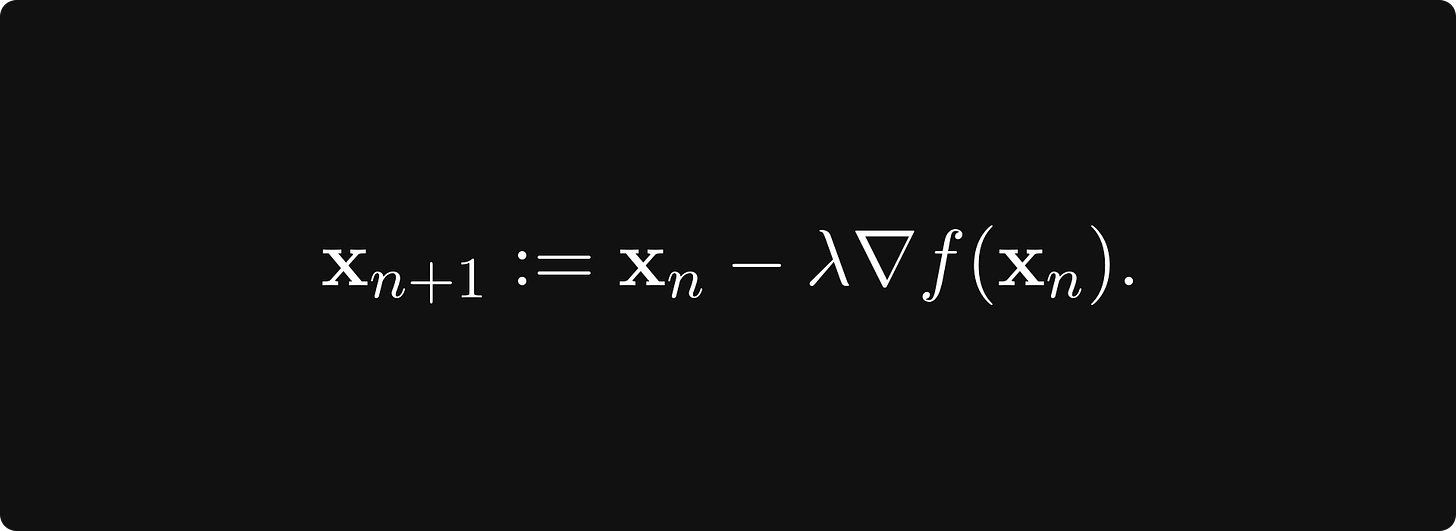
这个版本称为梯度下降。您可能更频繁地看到这一点,因为我们希望最大限度地减少机器学习的损失。
为什么梯度指向最陡的上升方向?
在这种情况下,梯度为我们提供最陡上升方向的原因并不简单。为了提供解释,我们需要做一些数学计算。除了用垂直于 x 或 y 轴的垂直平面对表面进行切片之外,我们还可以用任意方向 (e₁, e₂) 给定的垂直平面对它进行切片。通过偏导数,我们有

我们可以将它们视为 f(x, y) 沿 (1, 0) 和 (0, 1) 方向的导数。尽管这些方向具有特殊的意义,但我们可以从任何方向来做。
比如说,我们有方向 e = (e₁, e₂)。然后,关于 e 的方向导数定义为
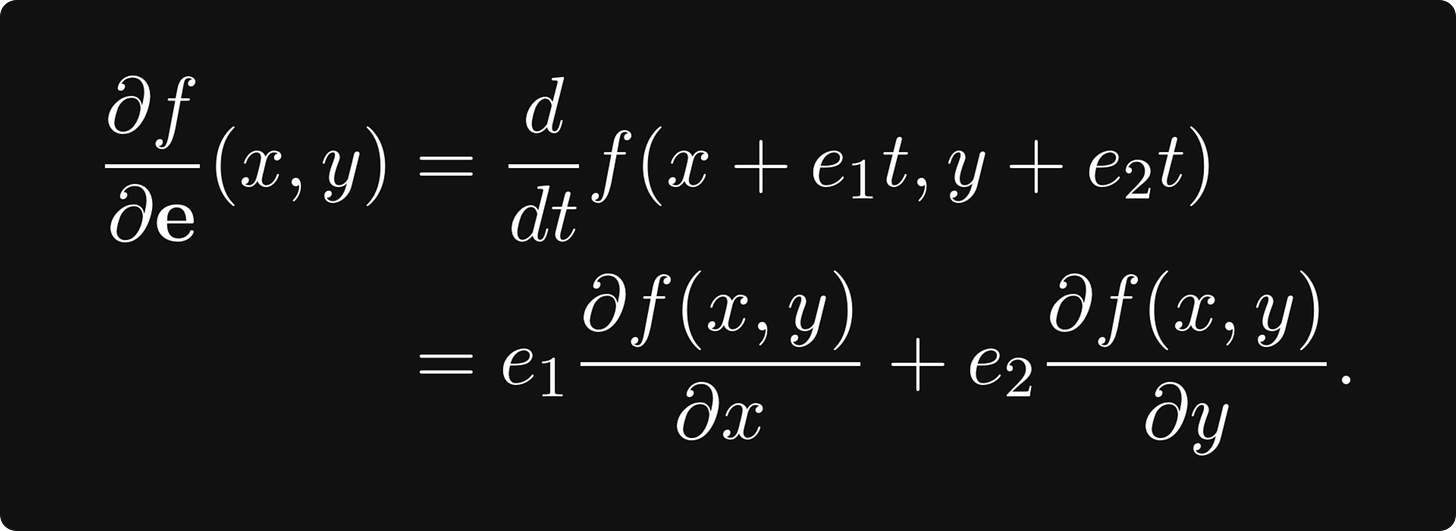
注意最后一个恒等式是 方向 e 和梯度 ∇f 的点积:
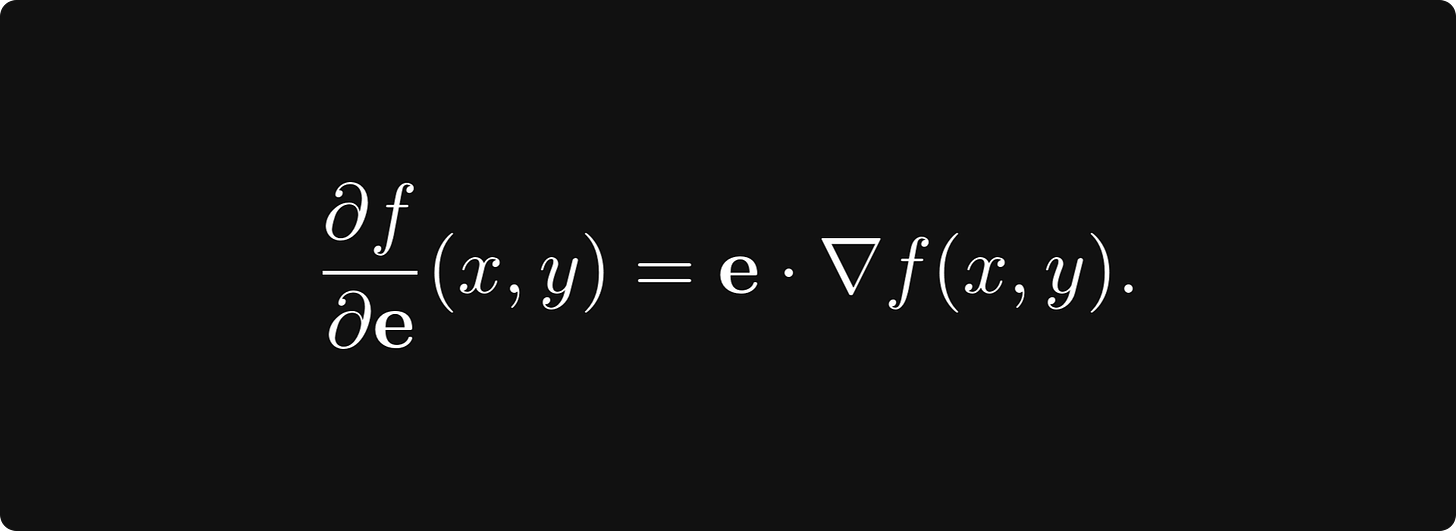
哪个方向使方向导数最大化?这将是最陡上升的方向,因此如果我们想要优化,我们想知道这个特定方向。
正如我们所提到的,这只不过是梯度本身,回想一下我们可以将点积写为

| · |表示向量的长度(也叫模),α 是两个向量之间的角度。 (这在任意数量的维度中都是如此,而不仅仅是在二维中。)
当 cos(α) = 1 时,该表达式最大化;即 α 为零,这意味着向量 e 和 ∇f 具有相同的方向。
训练神经网络
现在,我们准备从理论转向实践,看看如何训练神经网络。假设我们的任务是将 n 维特征向量分类为 c 类。为了在数学上形式化这一点,让函数 f: ℝⁿ → ℝᶜ 代表我们的神经网络,将 n 维特征空间映射到 c 维空间。
神经网络本身是一个参数化函数;我们用单个 m 维向量 w ∈ ℝᵐ 表示其参数。 (习惯上写成 f(x, w) 来明确表达对参数的依赖。)
J:ℝᵐ→ℝ,将神经网络参数的空间映射到实数。损失函数采用以下形式
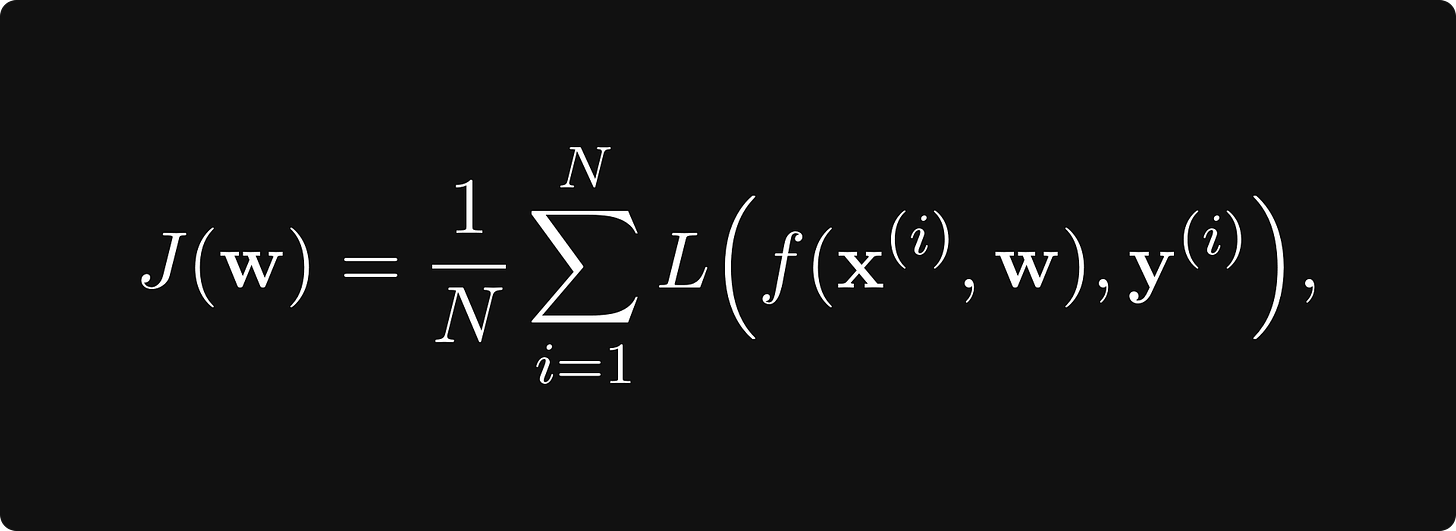
其中 x-es 是以 y-s 作为观测值的数据点,L 是衡量预测 f(x) 和真实值 y 之间误差的逐项损失。
例如,如果 J 是交叉熵损失,那么
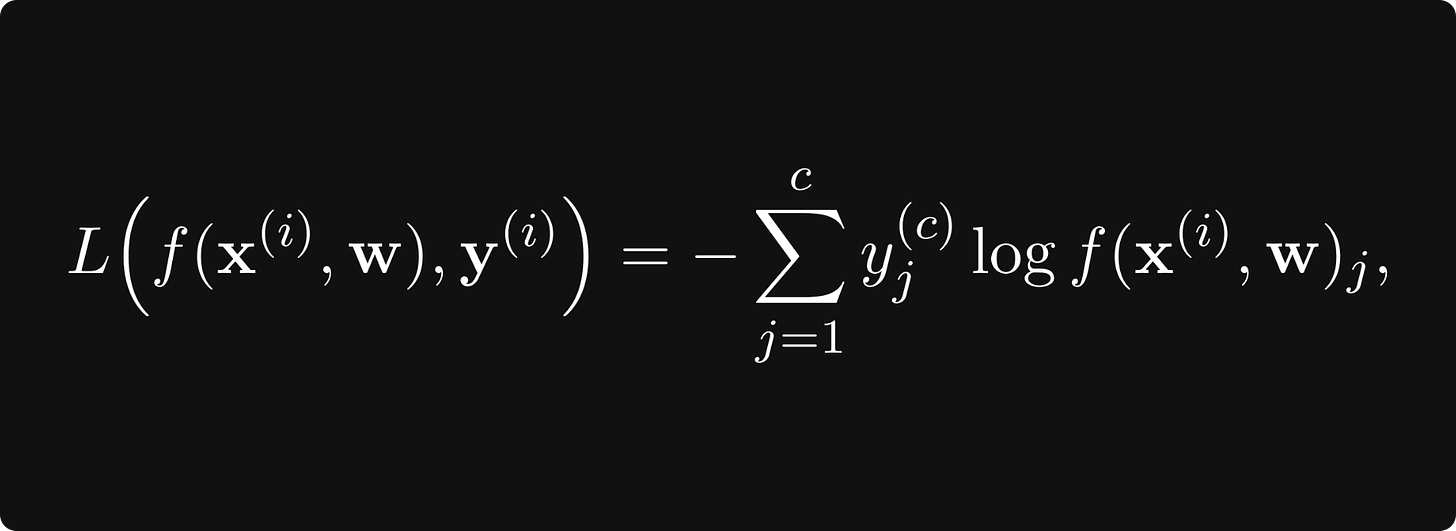
其中
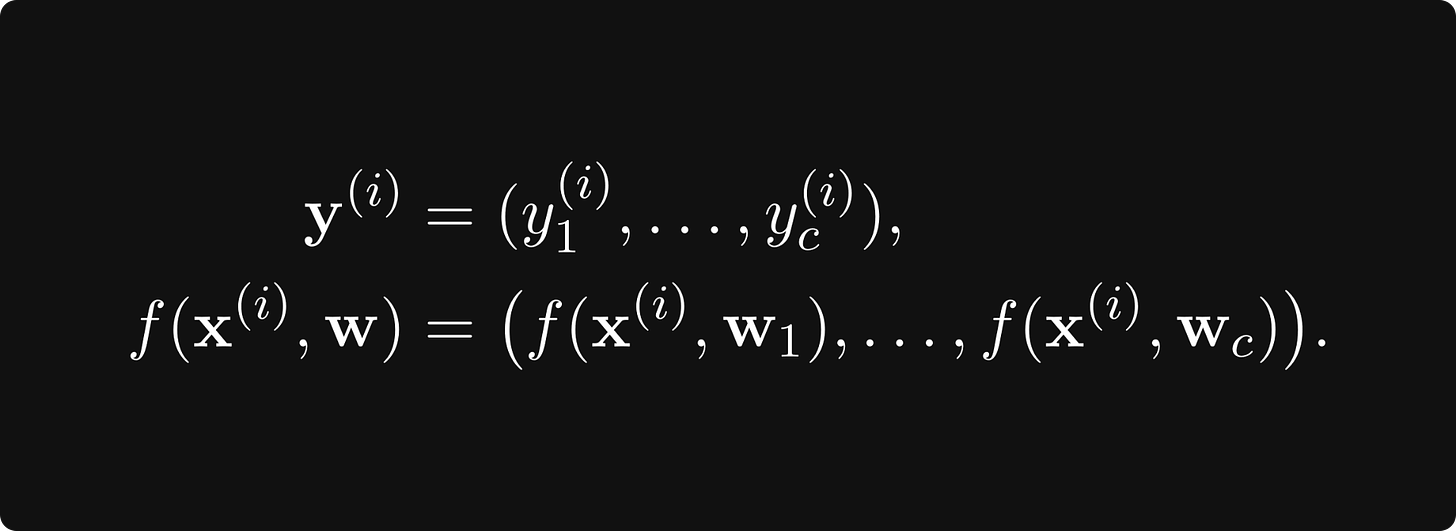
这可能看起来很简单,但计算起来可能很困难。在现实生活中,数据点的数量可能达到数百万,参数的数量也可能达到数百万。因此,我们有一个包含数百万项的和,为此我们需要计算数百万个导数以最小化。实践中我们该如何解决这个问题呢?
随机梯度下降 Stochastic gradient descent
要使用梯度下降,我们必须计算
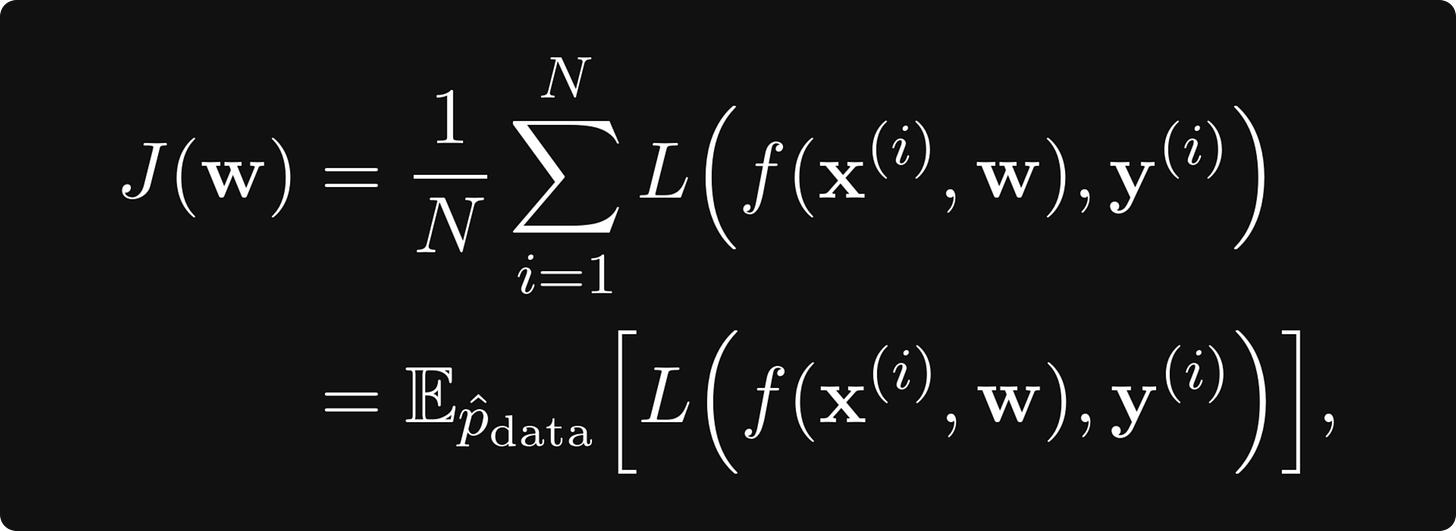
其中预期值是根据给定训练数据的经验概率分布而取的。我们可以将序列 L(f(xᵢ, w), yᵢ) 视为独立、同分布的随机变量。
根据大数定律,
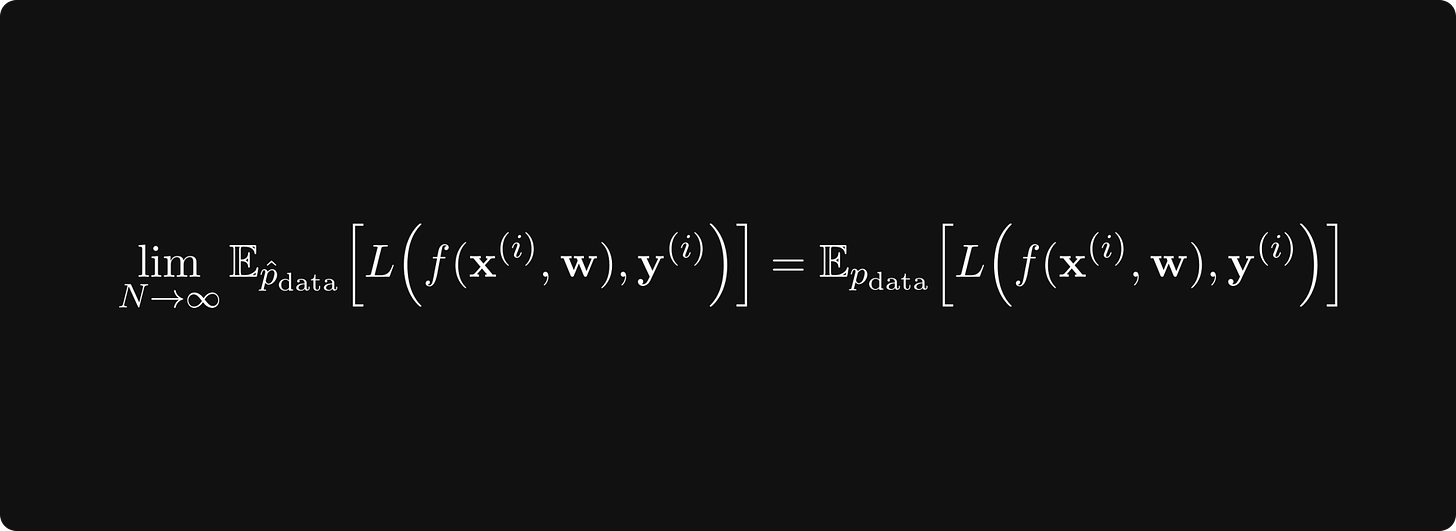
成立,其中 极限期望值 是相对于 数据的真实潜在概率分布而取的。 (这是总体的,未知的。)
这意味着随着我们增加训练数据,我们的损失函数会收敛到真实损失。因此,如果我们对数据 进行 采样并计算梯度
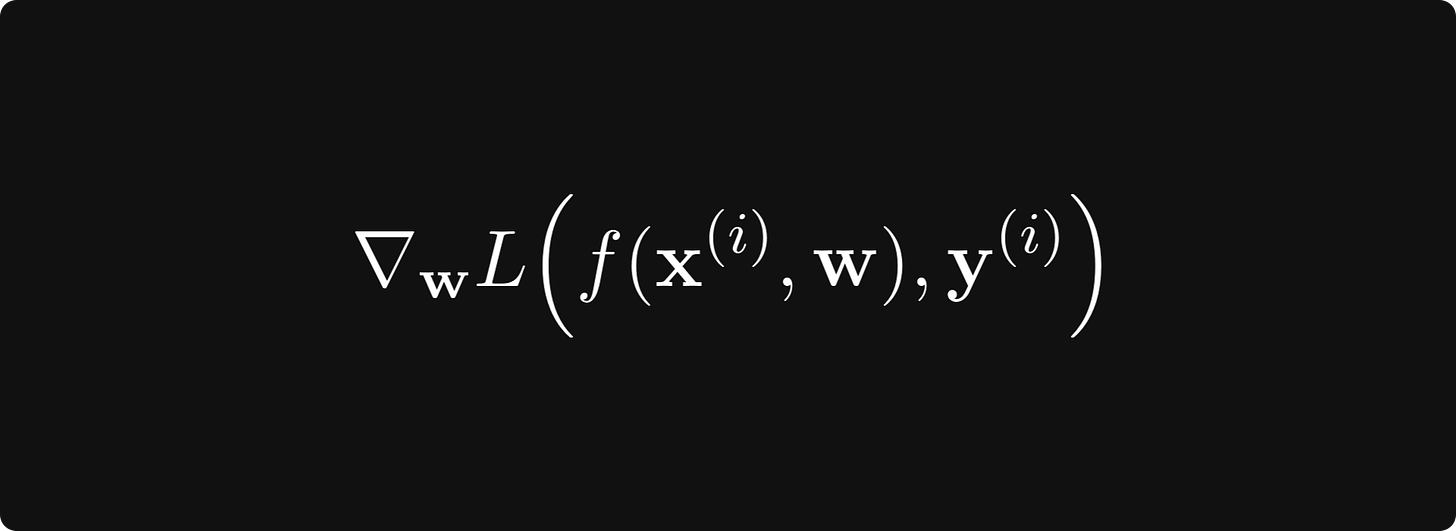
对于某些 i 而不是全部,如果我们计算得足够多,我们仍然可以获得合理的估计。
这称为随机梯度下降,简称 SGD,是迄今为止深度学习中最流行的优化器。几乎所有可行的方法都源于SGD。
三个基础 使我们能够有效地训练深度神经网络:利用 GPU 作为通用计算工具、反向传播和随机梯度下降。如果没有 SGD,深度学习的广泛采用就不可能实现。
与几乎所有新方法一样,SGD 也引入了全新的蠕虫病毒。明显的问题是,我们的 子样本大小应该有多大?太小可能会导致梯度估计有噪声,而太大则性能递减。选择子样本也需要谨慎。例如,如果所有子样本都属于一个类别,则估计值可能会相差一英里。然而,实验和适当的数据随机化可以在实践中解决这些问题。
改进梯度下降
梯度下降(也包括 SGD 变体)存在几个问题,这些问题可能导致它们在某些情况下无效。例如,正如我们所看到的,学习率控制着我们在梯度方向上采取的步长。一般来说,我们在这个参数上可能会犯两个错误。首先,我们可以将步长设置得太大,这样损失就无法收敛,甚至可能发散。其次,我们可能永远不会达到局部最小值,因为如果步长太小,我们就会太慢。为了演示这个问题,让我们看一个简单的例子并研究一下该函数
f(x) = x + 2 · sin(x)。
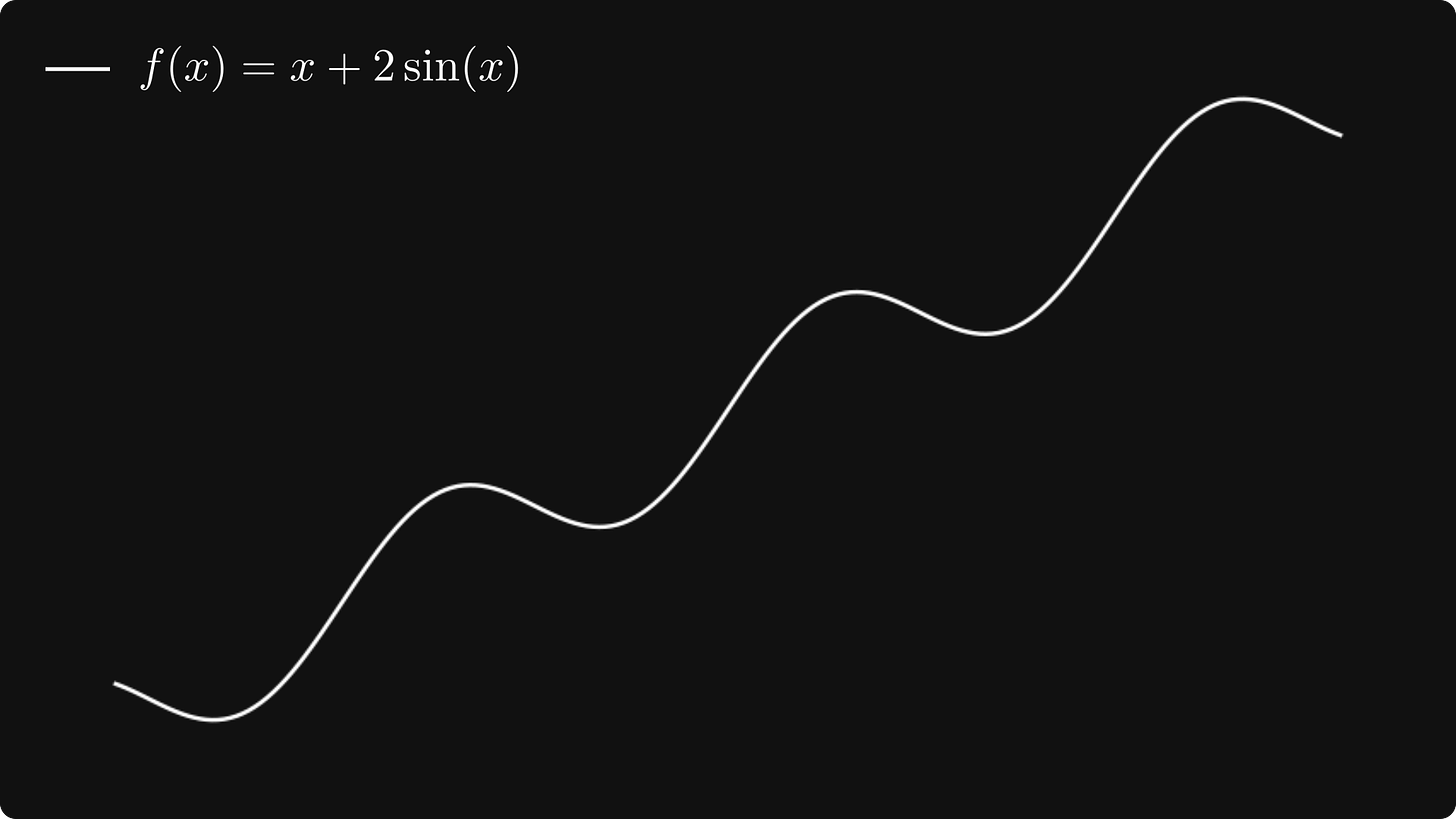
假设我们从 x₀ = 2.5 开始梯度下降,学习率
α = 1、α = 0.1、α = 0.01。
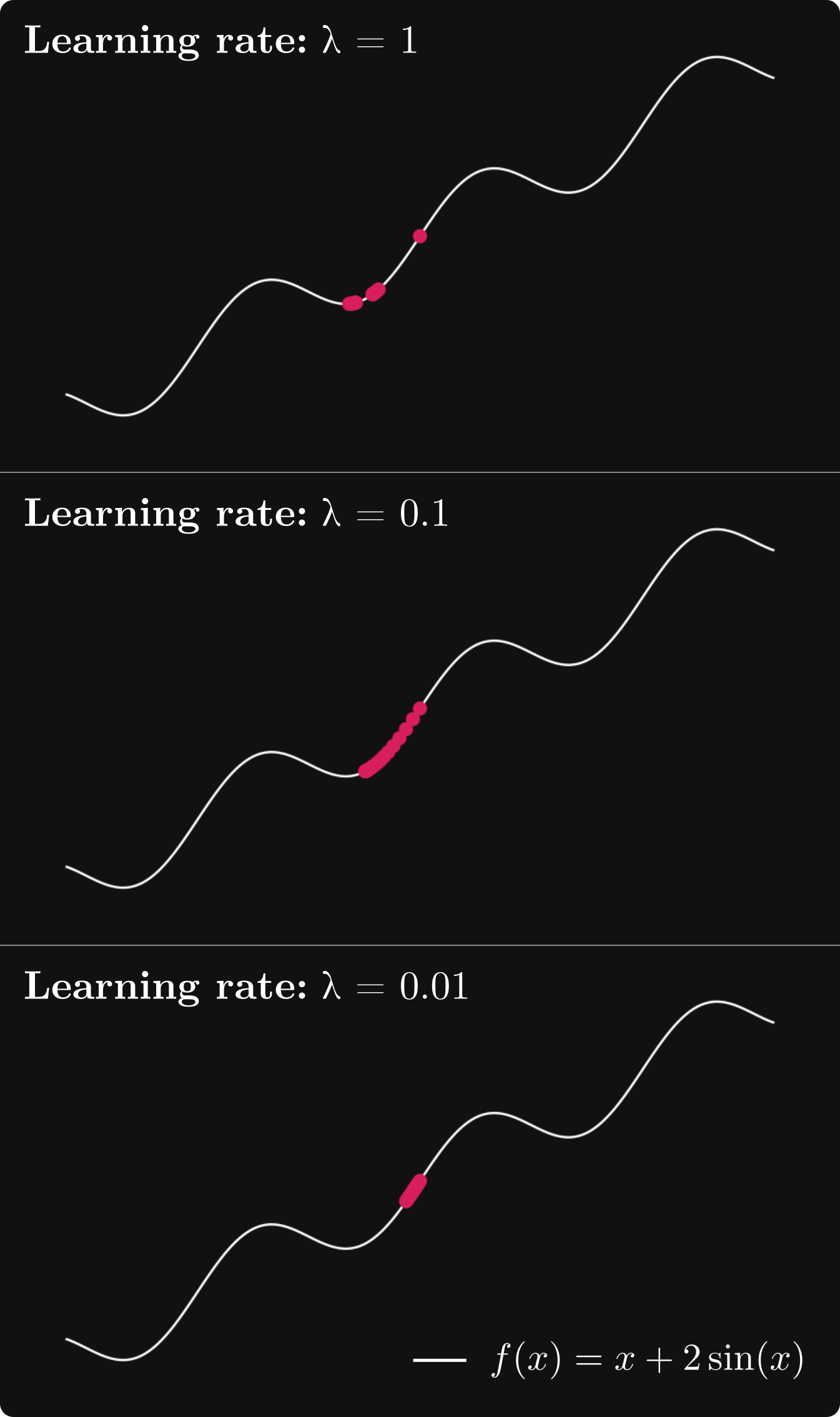
这里发生的情况可能并不明显,所以让我们绘制每个学习率的 x-s。

当 α = 1 时,序列在两点之间振荡,无法收敛到局部最小值。当 α = 0.01 时,收敛速度似乎非常慢。然而,α = 0.1 似乎正好。在一般情况下你如何确定这一点?他们的主要思想是学习率不一定必须是恒定的。启发式地,如果梯度模 很大,我们应该降低学习率以避免跳得太远。另一方面,如果模很小,则可能意味着我们正在接近局部最优,因此为了避免超调,学习率绝对不应该增加。动态改变学习率的算法称为自适应算法。
这种自适应算法最著名的例子之一是 AdaGrad。它累积地存储梯度大小并据此调整学习率。 AdaGrad 定义了一个累积变量 r 0 = 0 r_0 = 0 r0=0 并用规则更新它
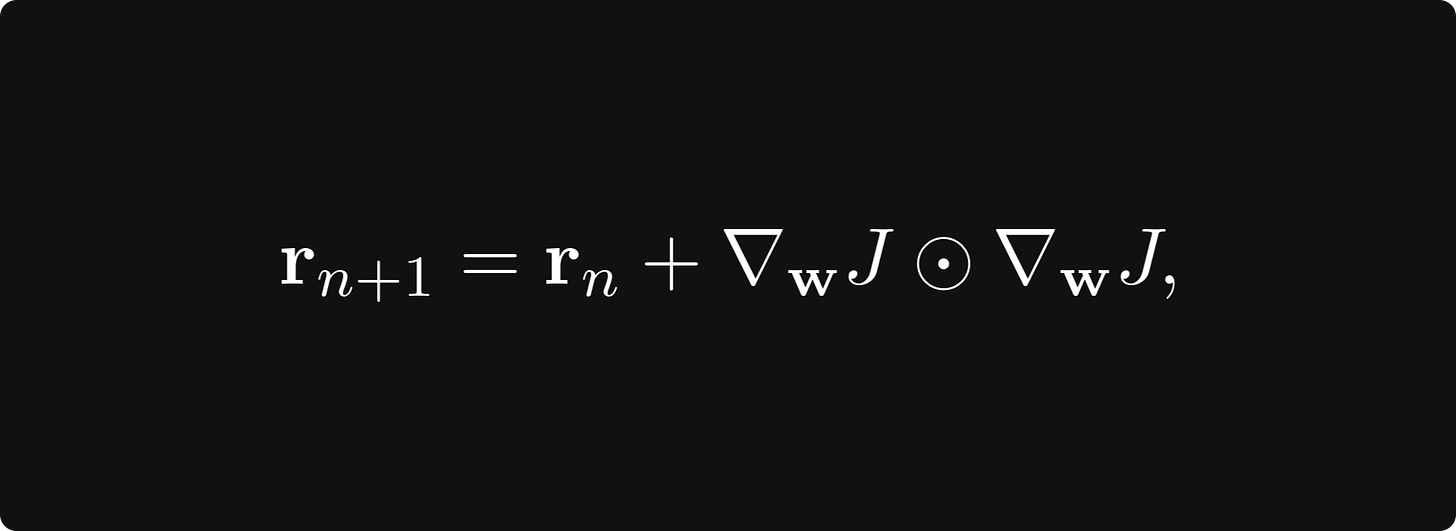
其中
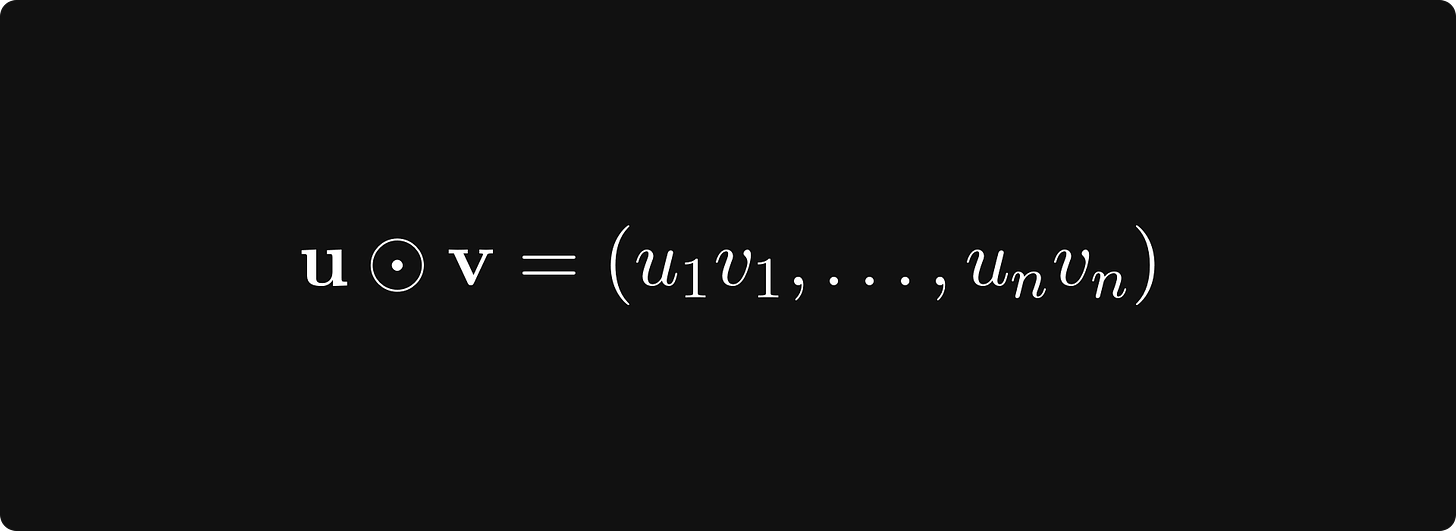
表示两个向量的对应分量乘积。然后用它来缩放学习率:
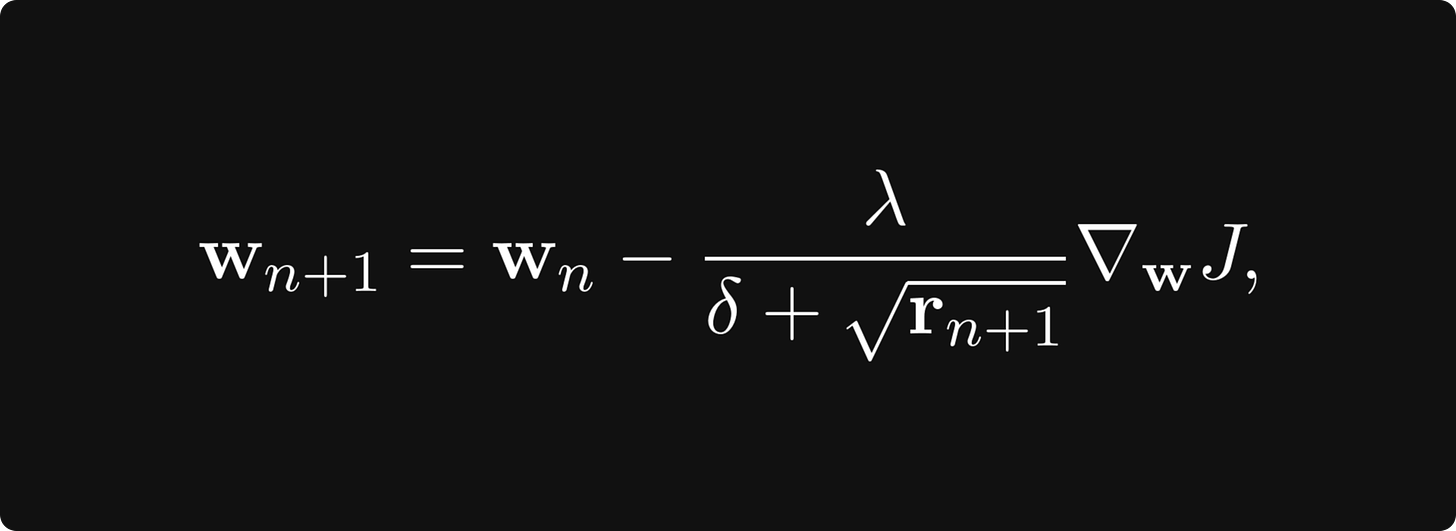
其中 δ 是为了数值稳定性而考虑的一个小数,并且按分量求平方根。首先,当梯度很大时,累积变量增长很快,从而降低了学习率。当参数接近局部最小值时,梯度变小,因此学习率实际上停止。
当然,AdaGrad 是解决这个问题的一种可能的方案。每年都有越来越多的先进优化算法出现,解决了与梯度下降相关的各种问题。然而,即使使用最先进的优化方法,调整学习率也是有益的。
关于梯度下降的问题,另一个问题是,例如,确保我们找到全局最优值或接近其值的局部最优值。正如您在前面的示例中所看到的,梯度下降经常陷入不良的局部最优状态。为了详细了解这个问题和其他问题的解决方案,我建议阅读 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 编写的《深度学习》教科书的第 8 章。
深度神经网络的损失函数是什么样的?
在前面部分的示例中,我们仅可视化了像 f(x) = 25 · sin(x) - x² 这样的简单示例。这是有原因的:对于两个以上的变量绘制函数并不简单。由于我们先天的局限性,我们最多只能从三个维度去观察和思考。然而,我们很聪明,因此,我们可以采用一些技巧来掌握神经网络的损失函数。关于这一点的一篇优秀论文是由Hao Li等人撰写的Visualizing the Loss Landscape of Neural Nets,他们能够通过本质上选择两个随机方向并绘制二变量函数来可视化损失函数
f(a, b) = L(w + au + bv)
(为了避免尺度不变性造成的扭曲,他们还为随机方向引入了一些归一化因子。)他们的研究揭示了 ResNet 架构中的跳跃连接如何塑造损失景观,从而更容易优化。
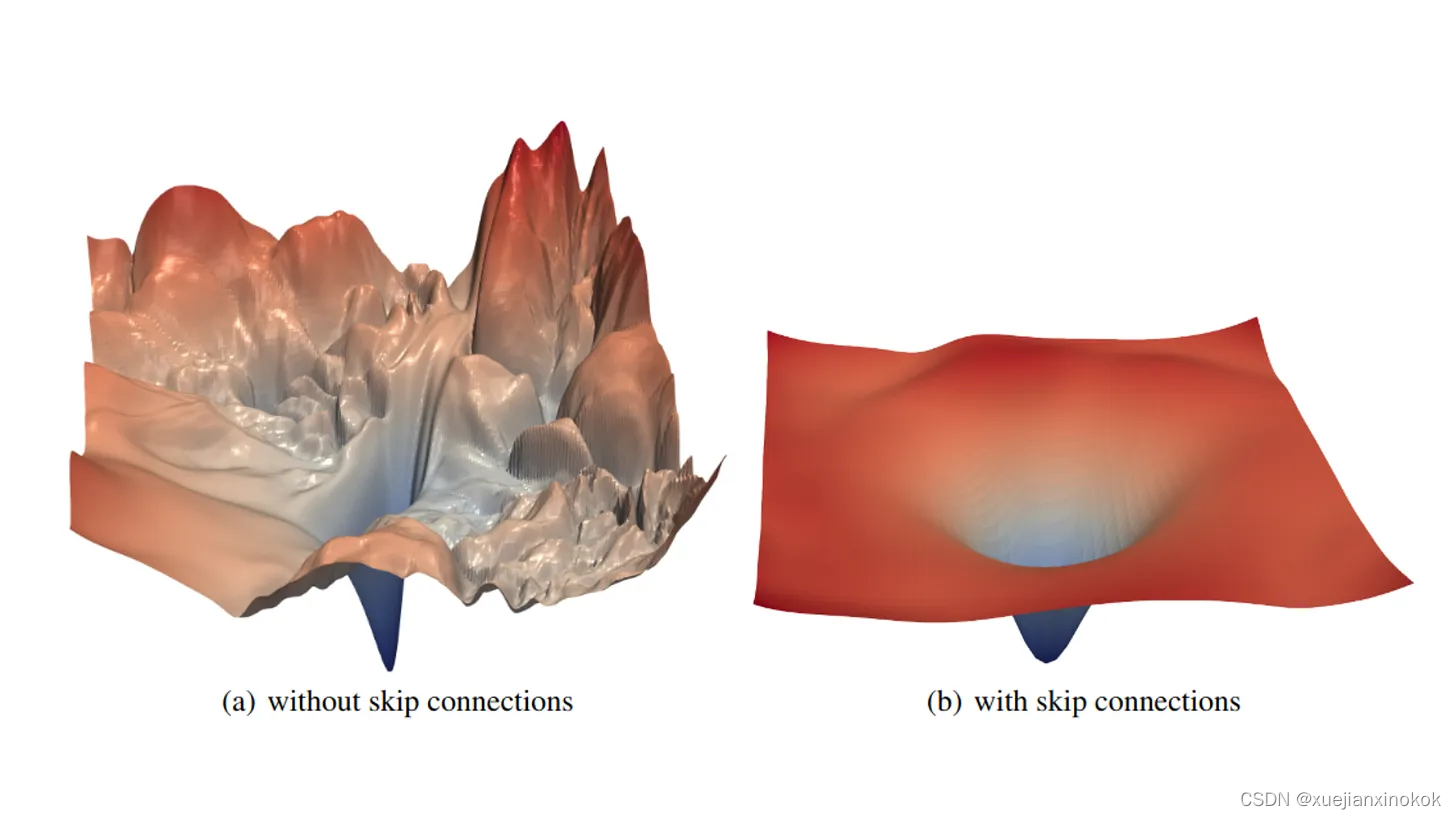
ResNet 损失函数地貌。资料来源:可视化神经网络的损失地貌,作者:Hao Li 等人。
尽管跳过连接取得了显着的改进,但我的观点是证明高度多维优化是困难的。通过查看该图的第一部分,我们可以看到许多局部极小值、尖峰、平台等。良好的架构设计可以使优化器的工作变得更容易,但通过深思熟虑的优化实践,我们可以解决更复杂的损失情况。这些是齐头并进的。
结论
在前面的部分中,我们了解了梯度背后的直觉,并以数学上精确的方式定义了它们。我们已经看到,对于任何可微函数,无论变量数量有多少,梯度总是指向最陡的上升点,这是梯度下降算法的基础。尽管概念上非常简单,但当应用于具有数百万个变量的函数时,它具有显着的计算困难。这个问题可以通过随机梯度下降来缓解。然而,还有很多问题:陷入局部最优、选择学习率等。由于这些问题,优化很困难,需要研究人员和实践者的关注。有一个非常活跃的社区,使其不断变得更好,取得了惊人的成果!了解深度学习优化的数学基础后,您就走上了提高最先进水平的正确道路!一些帮助您入门的优秀论文:
-
Visualizing the Loss Landscape of Neural Nets by Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein
-
Adam: A Method for Stochastic Optimization by Diederik P. Kingma and Jimmy Ba
-
Calibrating the Adaptive Learning Rate to Improve Convergence of ADAM by Qianqian Tong, Guannan Liang and Jinbo Bi
-
On the Variance of the Adaptive Learning Rate and Beyond by Liyuan Liu, Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Jiawei Han
深度学习中最常见的优化器
In practical scenarios, there are a optimization methods that perform extremely well. If you would like to do some research on your own, here is a list of references.
在实际场景中,有一些优化方法表现得非常好。如果您想自己做一些研究,这里有一个参考列表。
-
Adadelta: ADADELTA: An Adaptive Learning Rate Method by Matthew D. Zeiler
-
AdaGrad: [Adaptive Subgradient Methods for Online Learning and Stochastic Optimization](http://(https//jmlr.org/papers/v12/duchi11a.html) by John Duchi, Elad Hazan, and Yoram Singer
-
Adam: Adam: A Method for Stochastic Optimization by Diederik P. Kingma and Jimmy Ba
-
AdamW: Decoupled Weight Decay Regularization by Ilya Loshchilov and Frank Hutter
-
Averaged Stochastic Gradient Descent: Acceleration of stochastic approximation by averaging by B. T. Polyak and A. B. Juditsky
-
FTRL, or Follow The Regularized Leader: Ad Click Prediction: a View from the Trenches by H. Brendan McMahan et al.
-
Lookahead: Lookahead Optimizer: ksteps forward, 1 step back by Michael R. Zhang, James Lucas, Geoffrey Hinton, and Jimmy Ba
-
NAdam: Incorporating Nesterov Momentum into Adam by Timothy Dozat
-
RAdam, or Rectified Adam: On the Variance of the Adaptive Learning Rate and Beyond by Liyuan Liu, Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Jiawei Han
-
Ranger: Ranger21: a synergistic deep learning optimizer by Less Wright and Nestor Demeure
-
Stochastic Gradient Descent with momentum: On the importance of initialization and momentum in deep learning by Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton
原文地址