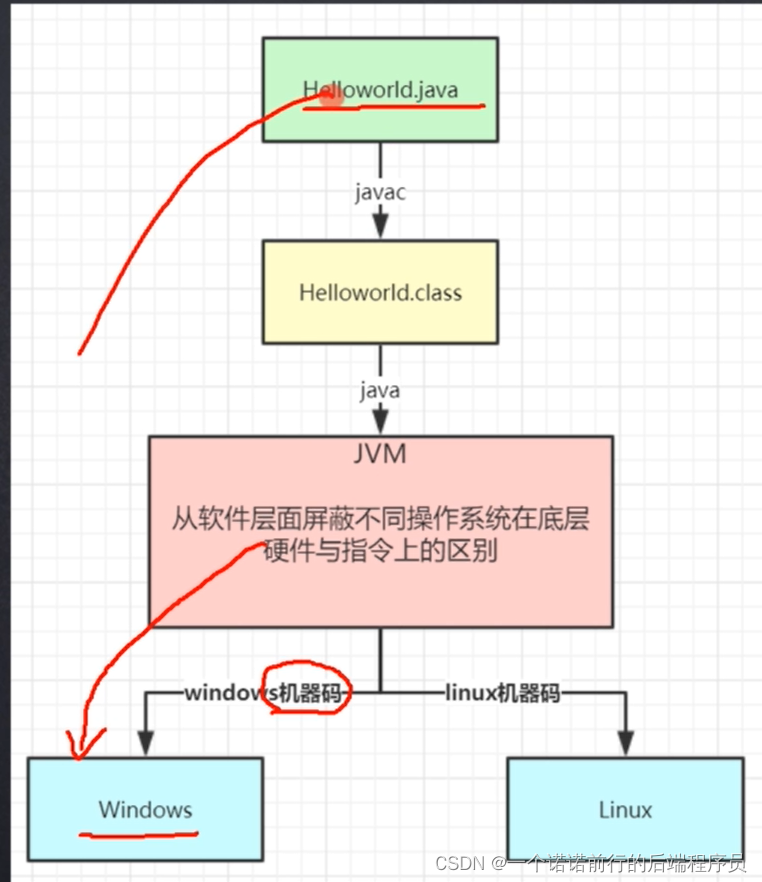
我们今天是讲java虚拟机,我们刚学java的时候写过hellowWorld
我们通过javaC指令把java 文件编译成字节码文件(class)
最终通过我们jvm 将class文件运行在 windows和linux平台上
我们也都知道java 语言有个跨平台,对我们java程序来说我们写的一份Java代码 可以到处运行 windows/linux
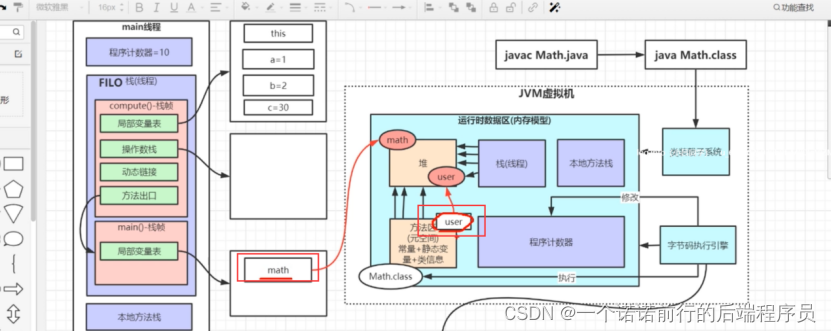
###java 虚拟机主要有 类加载子系统 运行时数据区 执行引擎
java--->class--->运行class文件 我们的jvm就开始工作了
java 虚拟机怎么跨平台, 就是jvm怎么帮我们实现跨平台
javac 编译成字节码(class)文件 再通过我们的java命令来运行他
运行Java指令 就代表java虚拟机开始工作了
首先会把字节码文件丢到java虚拟机第一个部分 ( 类装在子系统)
通过类加载子系统把我们的字节码文件丢到内存区域中(运行时数据区)
最终通过我们的字节码执行引擎来执行我们的代码
完整的java虚拟机由这 3快组成
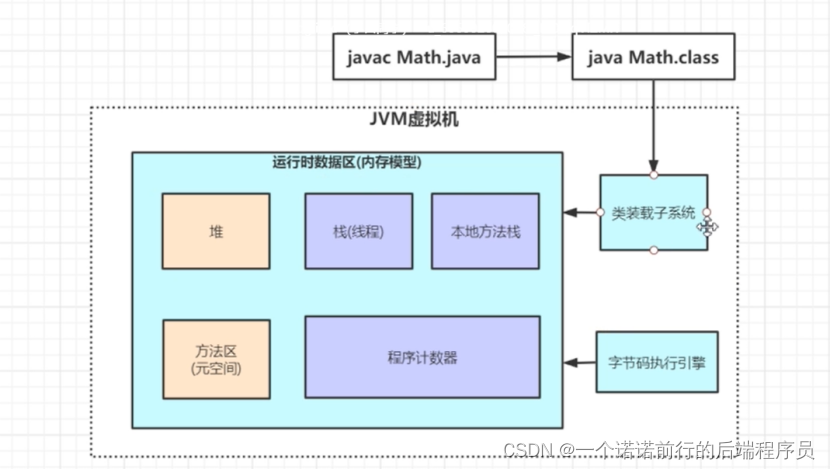
最最重要的部分就是运行时数据区 我们后续的调优会围绕这里来说
内存区域(运行时数据区)内存区域用来存放数据的
运行时数据区由那些部分组成
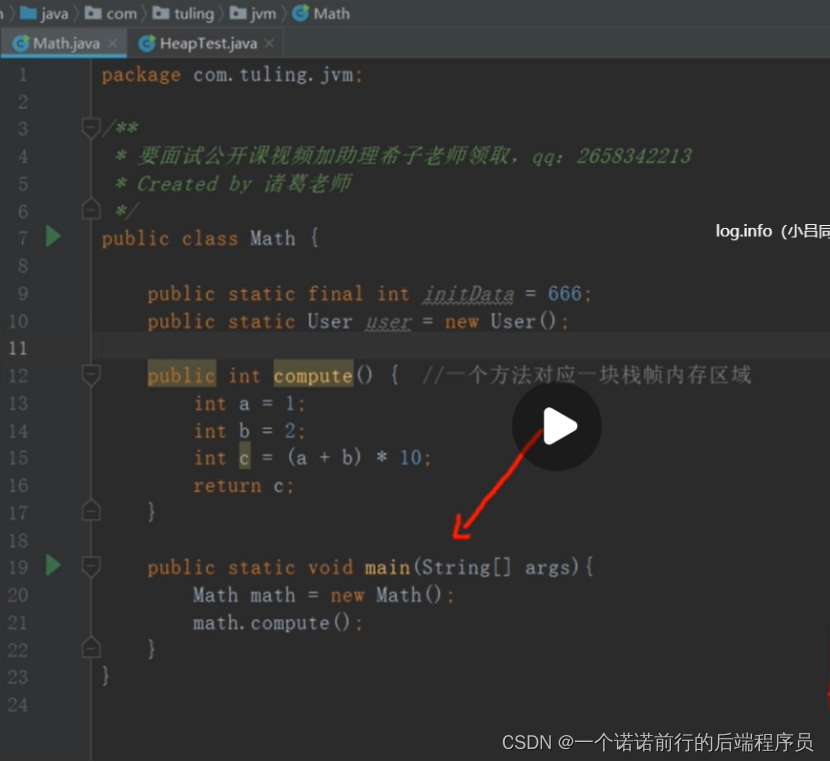
堆 我们一般new 对象就放在堆中
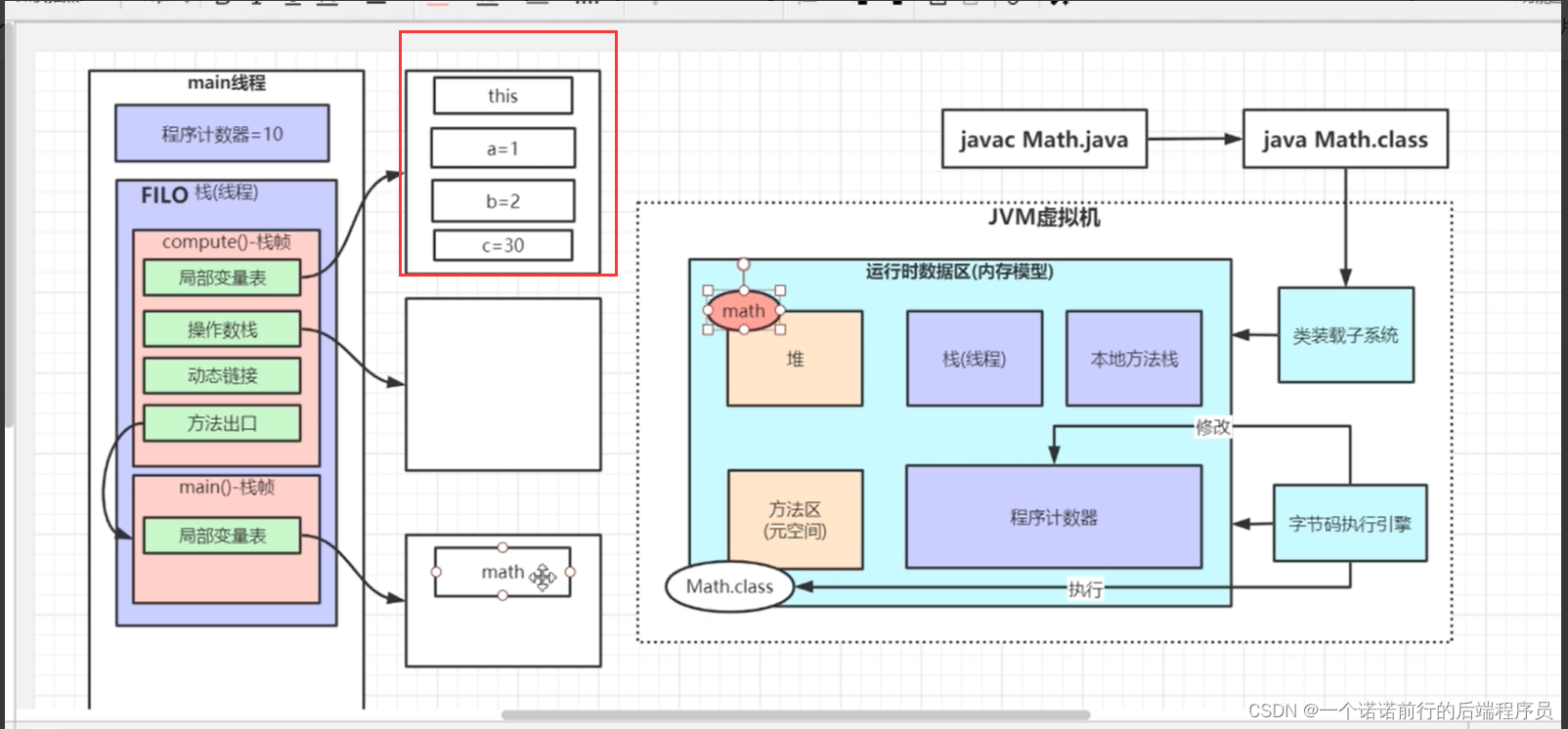
栈 当我们执行main线程的时候,java虚拟机就会给这个线程在栈上分配一个空间用来放置我们线程运行过程中存储的局部变量
每个线程都有它自己专属的 栈内存空间,因为不同的线程都会有他自己的局部变量
程序只要一开始运行java虚拟机 就会给他分配一个专属的线程栈 用来放局部变量
栈中是有栈祯的,当主线程开始运行,给他分配一块 线程栈 当你运行方法的时候,他也会给方法在线程栈中划一小块空间,用来放方法自己的局部变量
给每一个方法放置一块 自己方法的专属的内存空间 用来投放 abc 这些局部变量 叫做栈祯,
abc这些局部变量只会在comput方法内有效,当comput方法一结束,他的内存就会被销毁掉
一个方法就会对应一块栈祯内存区域,这些栈祯中用来放局部变量,方法自己的局部变量
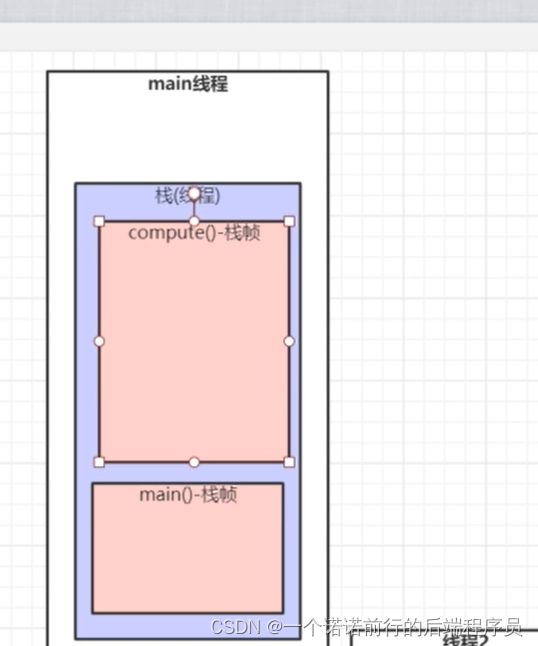
线程运行jvm,会给他分配一个线程栈,线程要运行方法,jvm 会在这个线程栈中放一个main方法的栈祯
调用 computer的时候也会 分配一个栈祯,后调用的方法先结束
方法一旦结束 它里面的方法空间都会被释放掉
方法一结束 实际上就是出栈
先调用main 方法分配内存空间,后调用computer 方法后分配内存空间
但是 computer方法先执行完 出栈 销毁, 再执行mian方法 出栈销毁
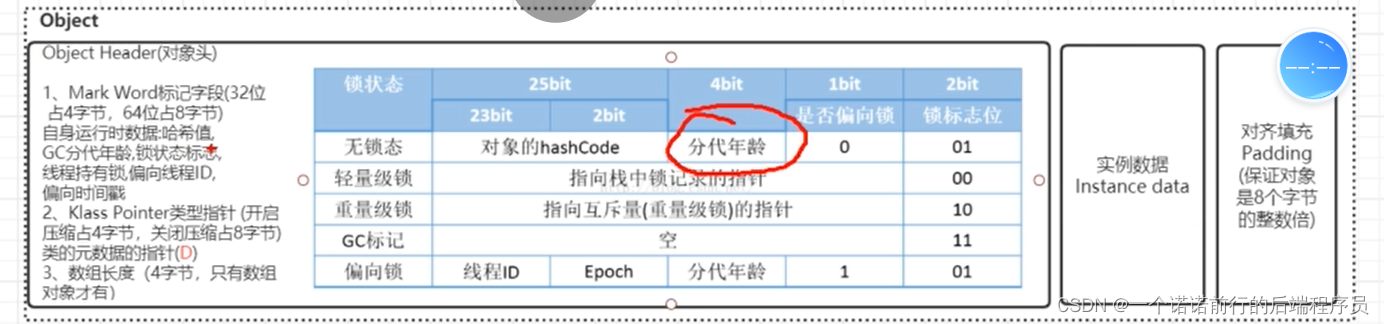
程序计数器 每个线程私有的 代表当前线程正在运行的位置
为什么要搞程序计数器呢,java程序是多线程的 假设我们的线程(没有抢到cpu)被挂起了,我们这个线程要想继续执行就得让抢占的线程结束了, 如果没有这个程序计数器 怎么知道恢复的时候在那行代码执行
##<<<<<<<我根据程序计数器的位置 我上次在这个位置 我这次在这个位置
这就是Java程序计数器的 初衷
线程切换的时候指导在那个位置来执行
jvm 的调优 以及arthas 调优工具
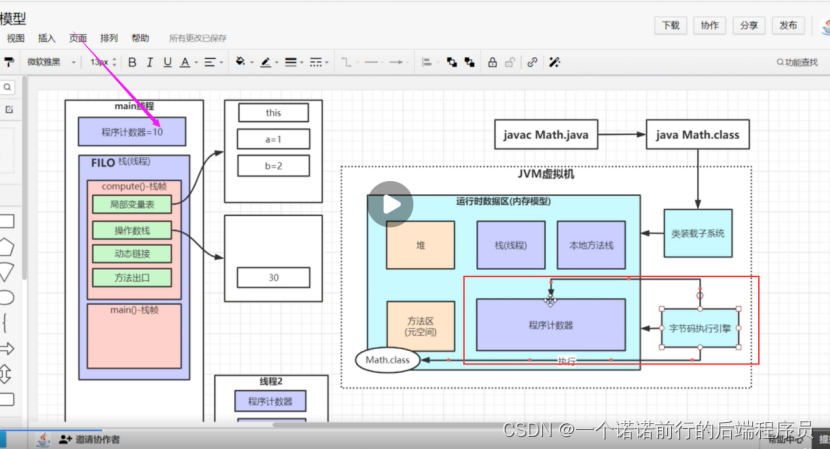
也就是我们程序计数器,当然是字节码执行引擎来操作并且修改的
程序计数器的值 每执行一行代码,这个值都会变化,谁去修改字节码执行引擎
字节码执行引擎来执行程序(.class文件)然后再修改程序计数器
动态连接 无非就是吧符号引用转成直接引用
https://www.jianshu.com/p/68721f23ee2b
new math 存储在堆中的
堆和栈的关系是,我栈里面的很多局部变量,假设其中的一部分局部变量他的值是一个对象类型对象分配到堆中
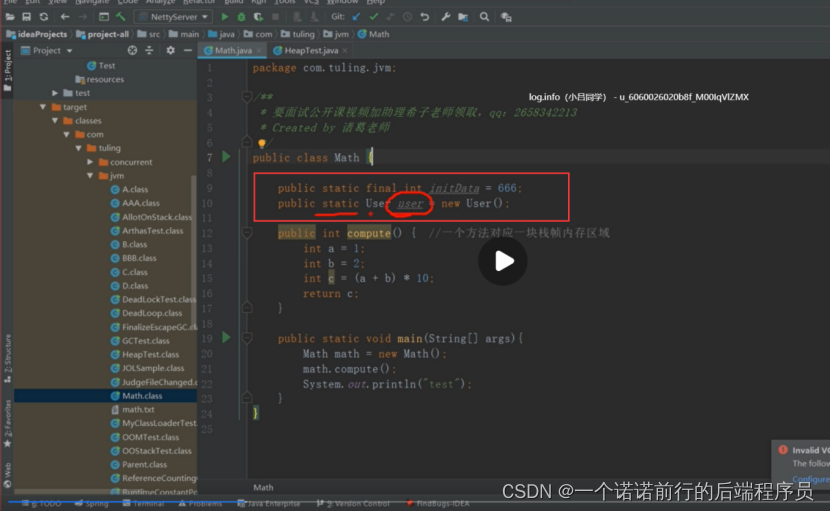
方法区在jdk1.8之前叫做永久代,放的是什么东西,放的是常量,静态,类信息
常量
static
指针引用,根据方法区中的内存地址就可以定位到对象在堆中的地址
类信息 就是我们的类加载过来
本地方法栈,本地方法,native方法本地方法接口 存储的数据
new Thread().start他的实现是根据本地C实现的

假设是7*24 d的程序 会一直new 对象
垃圾收集 gc
垃圾收集,字节码执行引擎操作的,当你的edit区满的时候
字节码执行引擎会在后台开启一个线程,来专门做垃圾收集
垃圾收集线程是 字节码执行引擎在 后台开启的 会专门负责垃圾收集
java 虚拟机垃圾收集的过程是怎么做的,到底是怎么收集垃圾的
gc的过程 gcRoot根节点
可达性分析算法
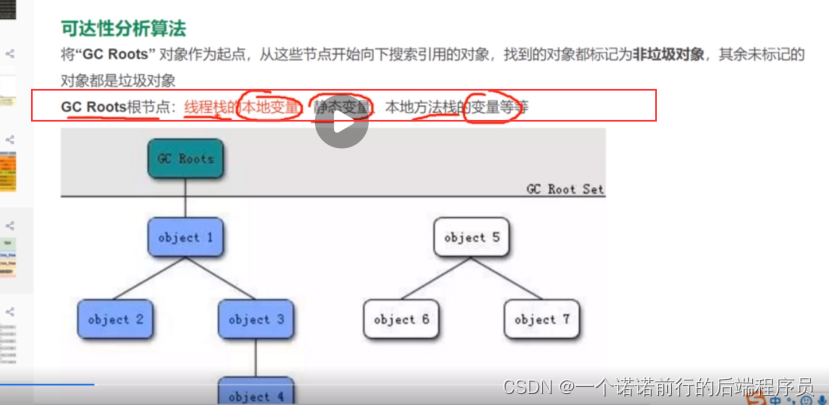
gc 垃圾收集过程 底层怎么找垃圾的 会运用一个算法 叫做 可达性分析算法
如果能找到的话 我们就认为这是一个非垃圾对象
没有任何指针可以引用的对象就是垃圾,直接干掉,这就是gc底层大概的过程
就是我们的可达性分析算法,通过gcroot出发找到可达对象,可达对象被认为非垃圾对象
没有标记到的,我们认为是垃圾对象就把他干掉
20240325
gc 垃圾收集过程 底层怎么找垃圾的 会运用一个算法 叫做 可达性分析算法,
他会从所有的gc root 出发比如说math,找出gcroot 引用的对象
如果能找到的话 我们就认为这是一个非垃圾对象
没有任何指针可以引用的对象就是垃圾 直接干掉 这就是gc底层大概的过程
这就是我们可达性分析算法,通过gcroot 出发找到可达对象, 可达对象被认为是非垃圾对象的 没有找到的我们认为是垃圾对象 就会把他干掉
当edit园区满了的话 字节码执行引擎会在后台开启一个垃圾收集线程来专门做垃圾收集,edit 圆区满了 触发minorgc ,minorgc 会回收整个年轻代,对象经过一次minorgc 没有让干掉 他的分代年龄会+1 ,minorgc会回收年轻代垃圾,
对象在年轻代生命周期
一般来说 15 就会到年老代
我们思考下 平时工作中那些对象可能会最终变为老年代对象
什么类型的对象 最终会存放在老年代
静态变量引用的对象 包括spring容器中的bean
包括连接池 缓存池对象
###########>>>>>>>>>>>
因为他在程序运行中 一直都会存在, 每经过一次MinorGC 他都不会被干掉
最终他就会分代年龄达到一定的值时候, 他就会 放到老年代
我们的一些调优包括线上问题怎么排查
对象在堆中生命周期的流转 大概是怎么做的
我们对象在年轻代的生命周期 ,每次加1 加到15的话 放到老年代
分代年龄在对象头中 比如说对象加锁
我们一些调优包括一些线上诊断问题怎么去做的
对象在堆的生命周期流转 的流程
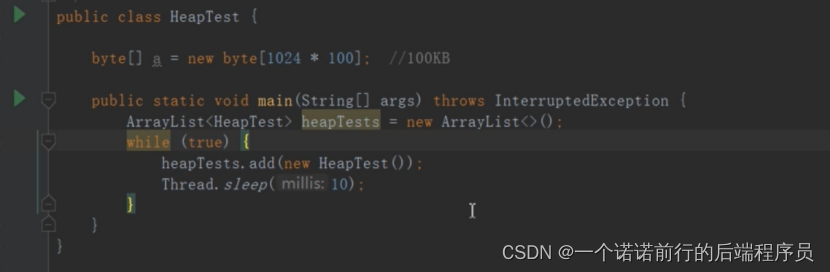
这个程序一旦运行最终会内存溢出
最主要的对象 new HeapTest
因为按照可达性分析算法来说 new HeapTest都是被Tests 直接或者间接引用着
最终肯定会有内存溢出 因为在我们程序运行中很多对象回收不了
########<<<<<<<<<
jvisualvm jdk 的调优工具
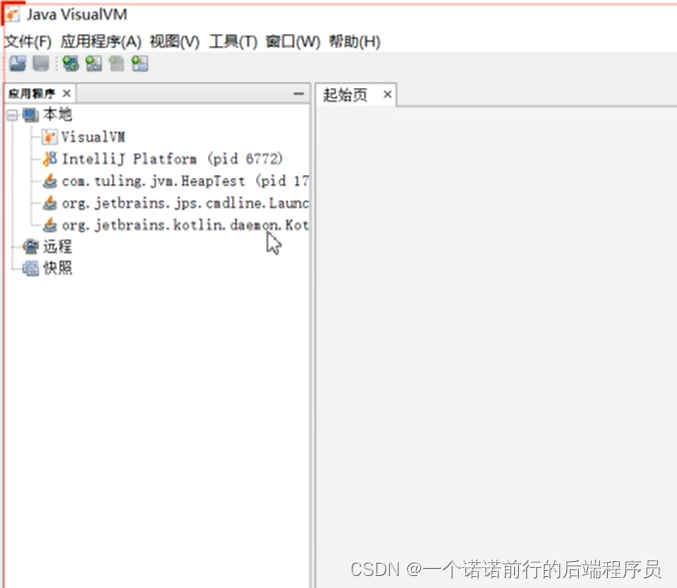
他会找出我们本机所有的Jvm进程
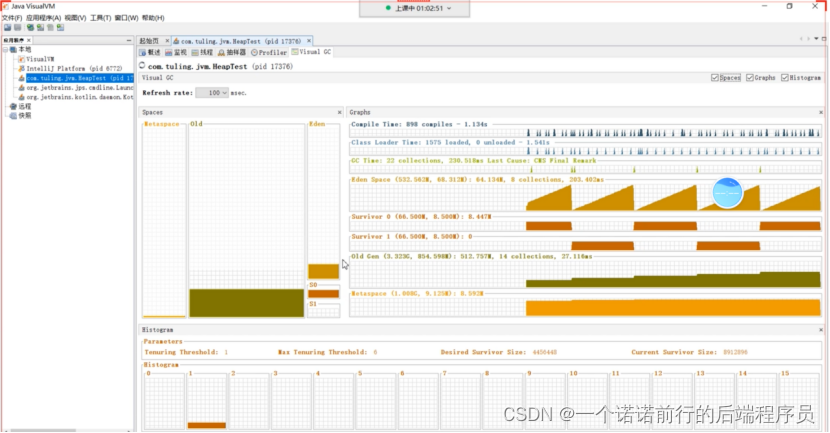
edit源区在不断增长 增长到一定程度突然就没有了
没有 之后 老年代会增长
这个实际上就是我们的 程序在运行过程中 内存区域的变动情况
我程序运行他底层的执行过程,老年代不断增长 老年代放满之后 先做 FullGC
他会回收我们整个堆的对象 老年代 的对象 都是 被引用的,FullGC也没有用
释放不出空间, 只能内存溢出,也就是最终就会内存溢出
我们刚说了arthas工具 我们可以用阿里的arthas
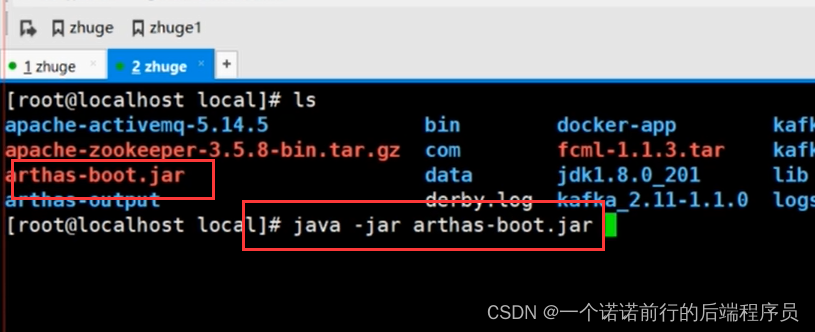
java- jar 执行就好了
是用来监控你的java虚拟机的 jvm 的进程也就是说 你这台机器上的有一个jvm虚拟机在跑
执行java -jar 就可以看到你这个服务器上的jvm 进程
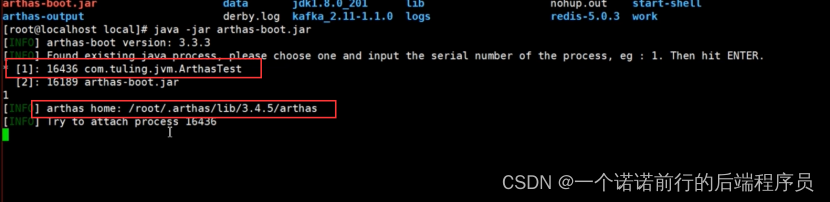
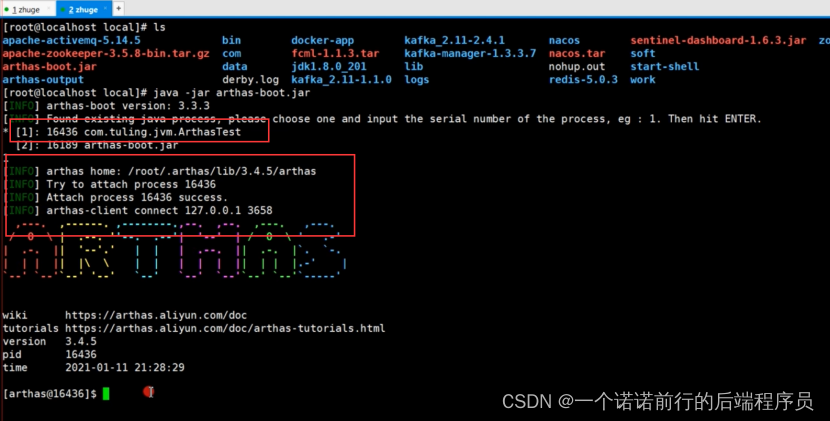
然后我们可以吧arthas工具 挂载在我们这个Java进程下,各个区域的内存情况,线程数 并且可以实时刷新的
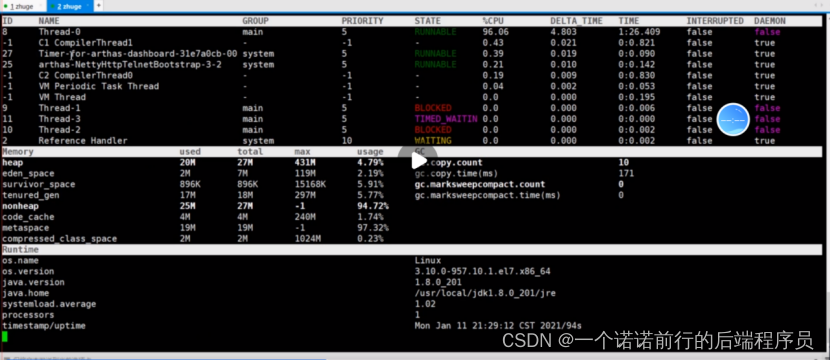
比方说线程占用cpu 情况 这边有个线程占用cpu 达到98%了
此时肯定有问题
#############>线上cpu .内存突然暴增 怎么定位
用archars 只需要 thread 8

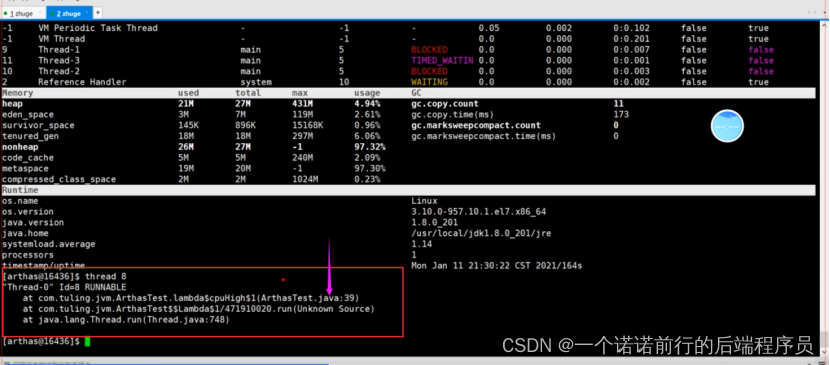
就代表出现在我们代码的多少行, 他是一个死循环 一直在这里空转 当然cpu 消耗搞了
通过一系列的命令可以实现整个java虚拟机调优诊断的 功能
很多命令 可以帮我们调优诊断jvm 虚拟机线上运行的过程
代码发布在线上 可能依然存在 很多时候怀疑运维没有发布成功,jad 反编译 可以看到线上实际代码的情况
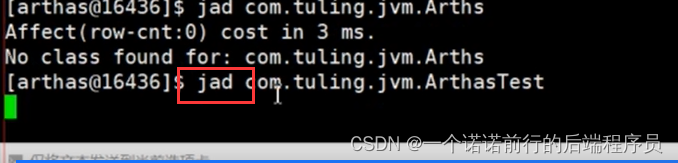
我基于jad 反编译线上正在运行的代码,线上正在运行的代码直接,反编译出来,就可以检查我代码是否有改动过
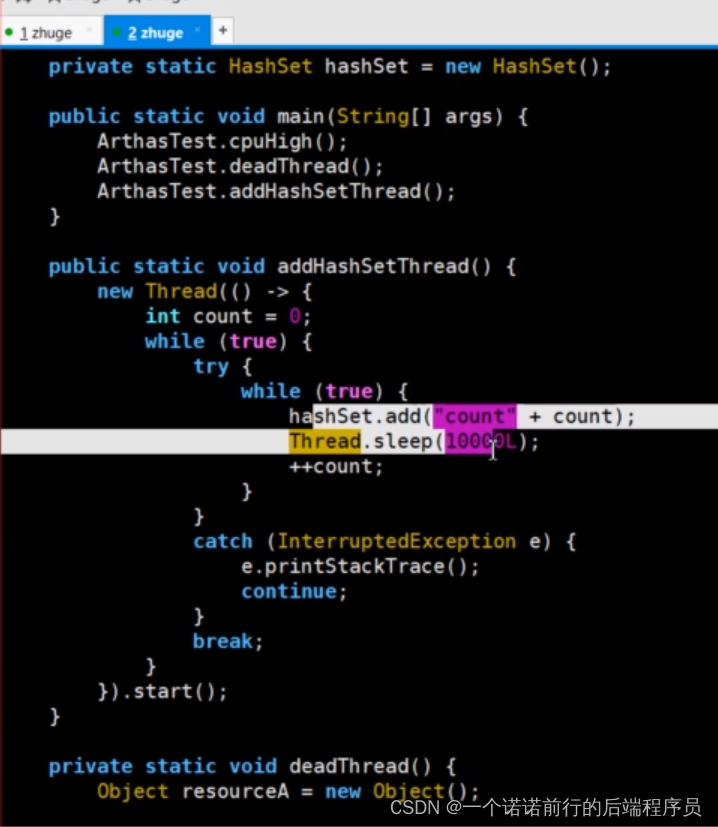
我就可以知道是运维没有发布成功还是我没有更改成功 ,arches 功能很强大
通过案例继续讲解调优,java虚拟机线上问题的诊断 定位问题
java 虚拟机的调优 目的是为了干嘛 用各种命令找到线上的问题?
我们java虚拟机调优的目的是为了 干什么
我们java虚拟机调优的目的是为了减少FullGC
调优最大可能减少fullgc ,因为线上系统频繁fullGC 会对我们性能有影响
减少fullGC
只要我们java虚拟机在做Fullgc minotgc他都会停掉我们的用户线程 这个就叫做stw,
由用户发起的线程叫做用户线程 java ,虚拟机做底层 在做垃圾收集的时候
gc 线程的时候 会停止这个用户线程
停掉用户线程会有很大影响 意思是我用户在下单 突然做GC 如果GC 时间长的话
对用户的感知 很慢 突然会感觉网站会卡
GC 很频繁 对用户的感知,网址时不时就很卡,体验感就不好
减少FullGC, 甚至有时候要减少minor gc 最终我们调优的目的是减少stw的时间
让我们的网站更加流畅 用户几乎 不会说感知到太多的卡顿
在gc运行过程中,为什么要设置一个stw, 如果没有stw的话,程序在做gc的过程中,根据可达性分析算法就会去找垃圾, 我们程序就会一直会运行,假设gc没有结束,也就是说gc线程和用户线程在同步进行
gc线程没有结束 用户线程提前结束 -我gc 就会结束不了 因为以前不是垃圾 现在变成垃圾了
我GC 就结束不了了 ,就是因为这个过程我在GC 过程中,有可能用户的线程 在运行过程中可能会导致这个对象的状态发生了变化 所以Java虚拟机 在设计gc的过程中让用户线程停止 ,专心搞垃圾收集 可能效率还高一些 这就是stw机制
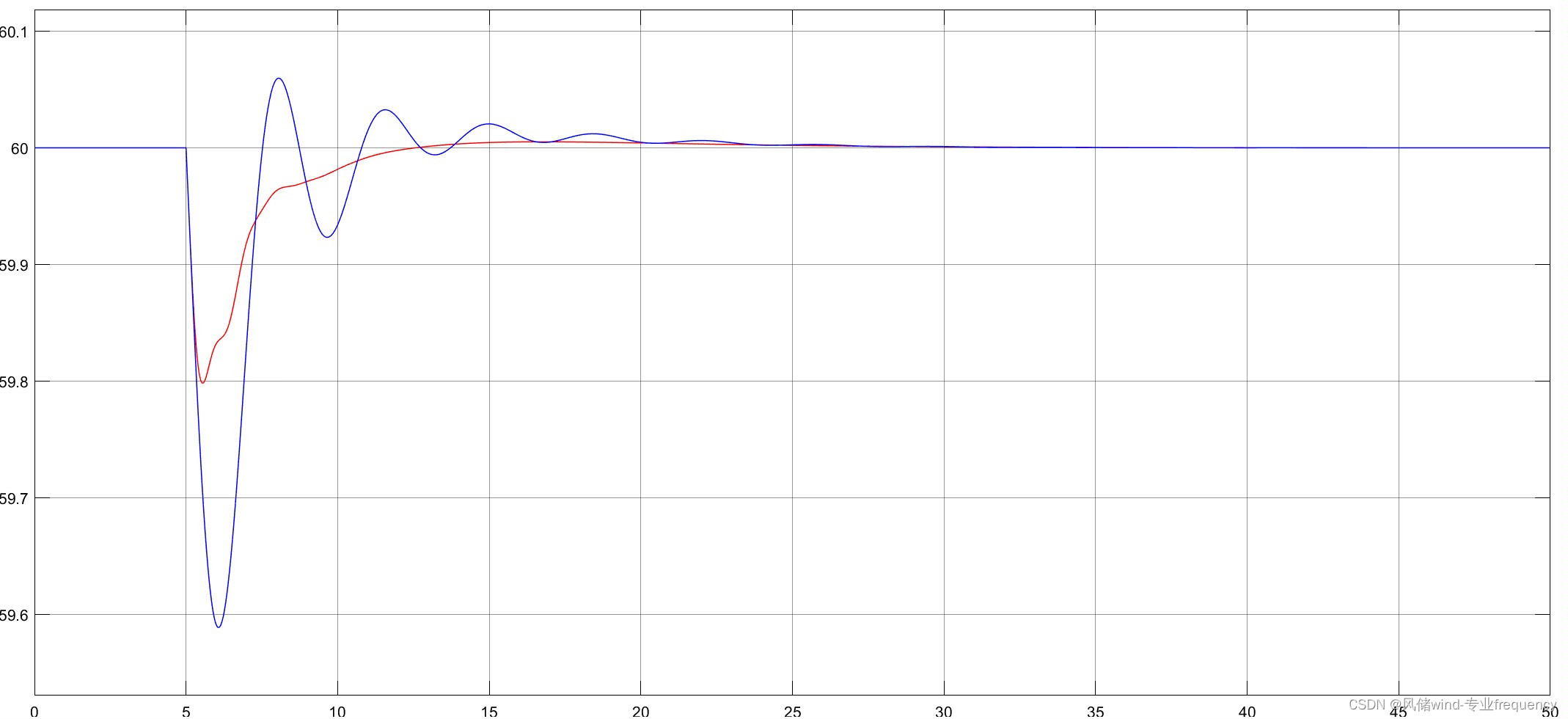
我们碰到问题后 我们怎么对他进行分析调优,比如说我们平时系统运行还算正常,一旦到了流量稍微高一些 比如说大促活动, 我们就会发现我们的线上频繁FullGC 问题在哪里
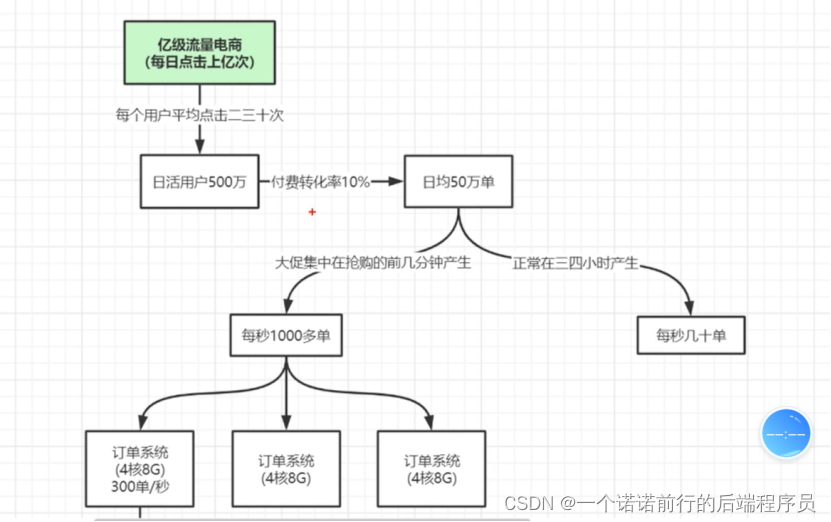
亿级流量电商网站
日活用户 ##怎么算 每天来访问我的用户,正常情况下,我可能早上1小时 中午1小时 下午2小时
也就是每秒几十单,但是在大促的时候不一样
大促的时候我就经常频繁发生FullGC基于这样的压力 我们就已经频繁fullGC le 对于这样的系统来说
怎么设置java虚拟机参数的 比如说堆内存
当然我们还得要最终压测 来进行评估
我们系统频繁触发Fullgc 怎么分析和评估
怎么分析 可以根据这个系统的并发压力大致算算 我们的内存区域的使用情况
比如说我们搞了3个集群 也就是每一个节点300在大促下的并发,一个create下单方法 ,下单 createOrder(order) // 每秒300个订单生存丢到堆中去
按照一个对象1kb来说 每秒300个对象 300kb, 可能还涉及到主表 明细表 扩展表之类的
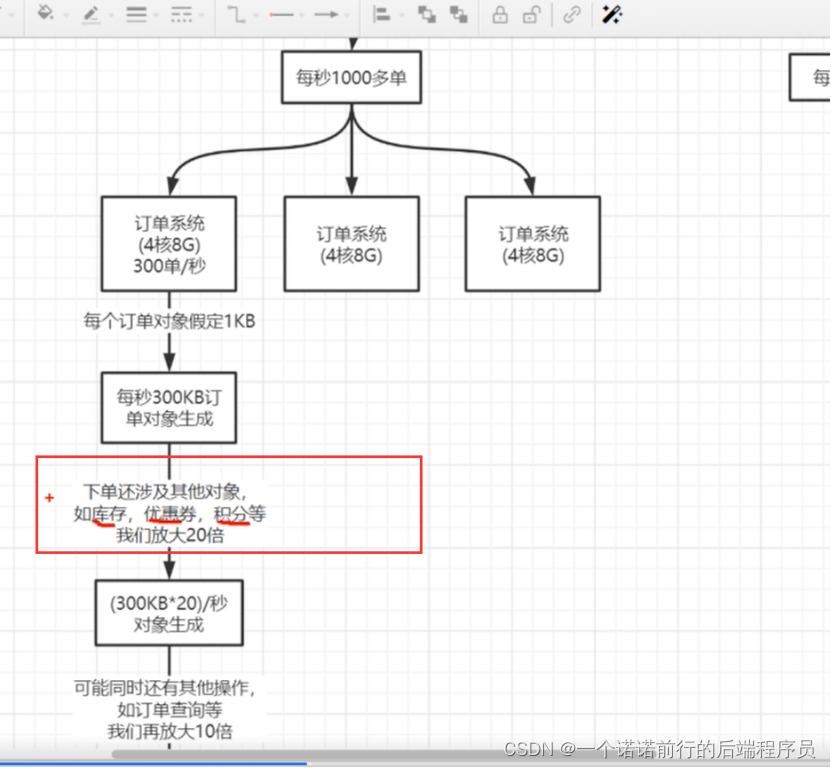
因为在下单过程中可能还有查询过程 比如说查询订单这些 所以我们的内存再扩大10倍
我每秒有6兆对象生成,你需要根据你的业务场景来分析你核心业务中的对象生成情况
我可能还有其他操作 ##>>>>.比如说订单查询系统 这些操作占用的内存
按照我们核心业务以及 按照我们系统的核心业务以及压力情况
每秒大概60兆数据生成
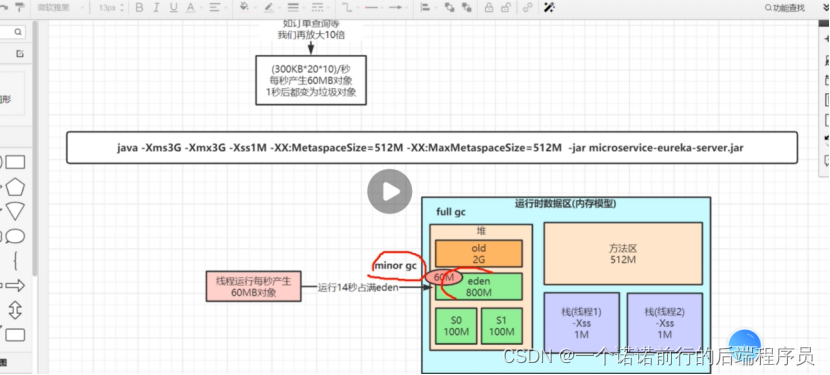
我下完订单后 我的方法也就结束了,这些对象就会变成垃圾 就没有GCroot的引用了 就会变成垃圾
######<< 比如说我服务器4核8G 都是怎么设置我们Jvm虚拟机内存的 比方说堆内存
根据系统的并发压力 可以分析他的内存使用情况 最终我们也要给我们的压测
年轻代有8:1:1
放满触发edit 每秒产生的对象 1s后变成垃圾对象
你的根据你系统的业务场景 每秒产生多少对象来评估你的堆内存参数,尽可能的减少FullGC
老年代满了,就会做FullGC, 老年代几分钟就放满了 执行一次FullGC 就会触发STW机制
根据程序的核心业务流程一些对象的使用 生成情况 合理的配比,java 虚拟机内存的各个部分 来规避FullGC 的产生
给我们这个系统java虚拟机调优让他几乎不发生FullGC,比方说mq kafka 都是运行在java虚拟机上
kafka 单机承受10w+ 的系统
高性能mq 但性能怎么用 底层是有很多优化的
每秒有几百兆对象发到edit源区
对于单机想做高并发 你的jvm 参数一定要做设置 比如说你最起码的做大内存
就是说你想单机支撑 大并发的时候,你的单机器的jvm 内存就得放大一些,因为这样可以避免频发触发FullGC
比方说30G 的内存, 你minorGC 一次回收怎么都的几分钟 minorgc 回收过程中也会stw
呢么停顿个几秒种
在执行MinorGC 的时候 会STW 停止用户线程
在做STW的时候会有大量的超时 这样 客户端会有大量的报错
思考怎么调优 此时一定要借助于垃圾收集器
基于大内存的GC 该怎么来优化


![[密码学] 密码学基础](https://img-blog.csdnimg.cn/direct/5e3bbec0c02a41f4adb7735597225b4f.png)