🕺作者: 主页
我的专栏 C语言从0到1 探秘C++ 数据结构从0到1 探秘Linux 😘欢迎 ❤️关注 👍点赞 🙌收藏 ✍️留言
文章目录
- Hadoop伪分布式安装
- 一、实验目的
- 二、实验环境
- 三、实验内容
- 基本任务1:安装Linux虚拟机(至少5台)
- (1)BIOS设置(开启虚拟化)
- (2)配置网络(/etc/sysconfig/network-scripts/ifcfg-eth0)
- (3)关闭防火墙
- (4)关闭selinux(/etc/selinux/config)
- (5)删除/etc/udev/rules.d/70-persistent-net.rules //便于克隆,该文件也有网卡地址映射
- (6)拍摄快照,克隆新的虚拟机 ,启动新虚拟机,MAC地址就会改变
- (7)重复第2步,配置4台虚拟机IP
- (8)配置主机名(/etc/sysconfig/network)
- (9)配置映射(/etc/hosts)
- (10)验证 在20191909node01上 ping 20191909node02 或 ping 192.168.87.34
- (11)编辑 C:\WINDOWS\System32\drivers\etc\hosts //windows应用程序也可以访问主机名
- (12) 最后结果
- 基本任务2:hadoop伪分布式安装
- (1)安装java //可以通过xftp传输安装文件到/root/software/
- (2)设置ssh免密钥登录
- (3)安装Hadoop
- (4)修改配置文件
- (5) 格式化
- 四、出现问题及解决方案
- 五、实验结果
- (1)启动集群
- (2)通过浏览器查看信息
- (3)练习上传文件
- 六、实验思考题
Hadoop伪分布式安装
一、实验目的
- 安装Linux虚拟机(至少五台)
- hadoop伪分布式安装
二、实验环境
- centos 6.5
三、实验内容
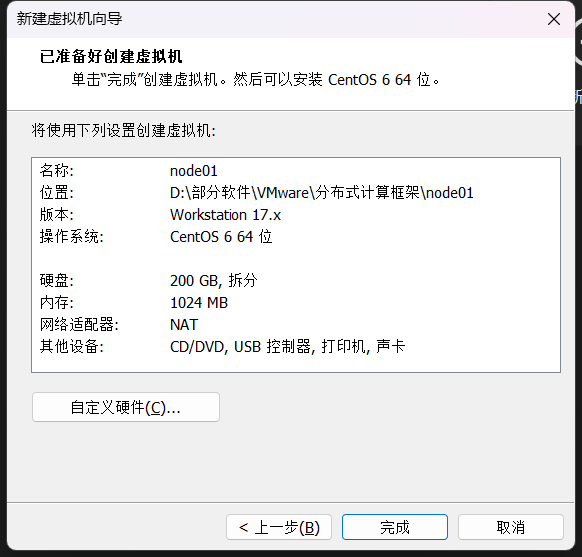
基本任务1:安装Linux虚拟机(至少5台)
(1)BIOS设置(开启虚拟化)
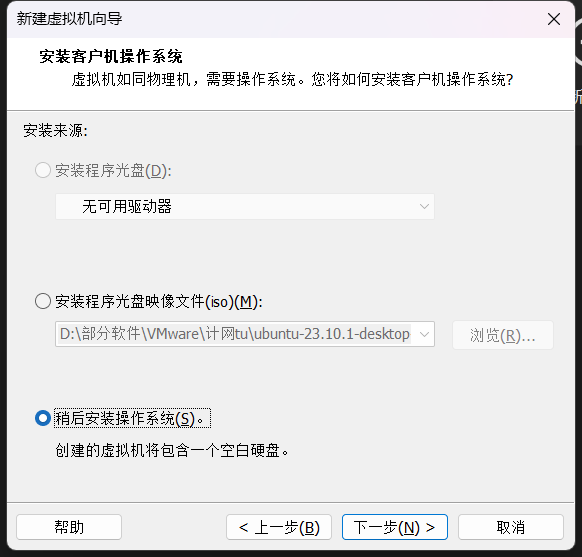
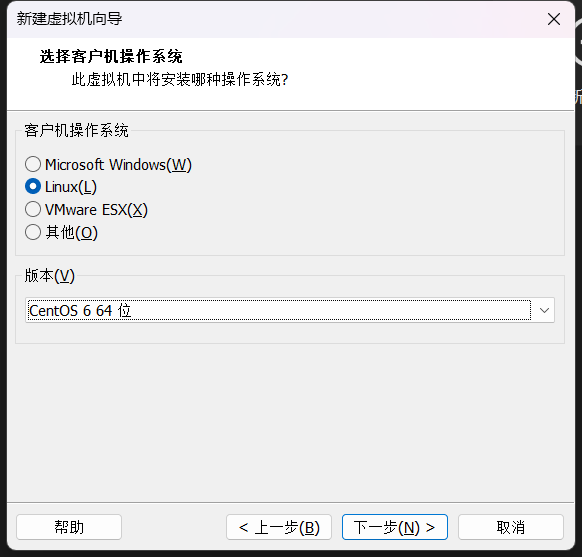
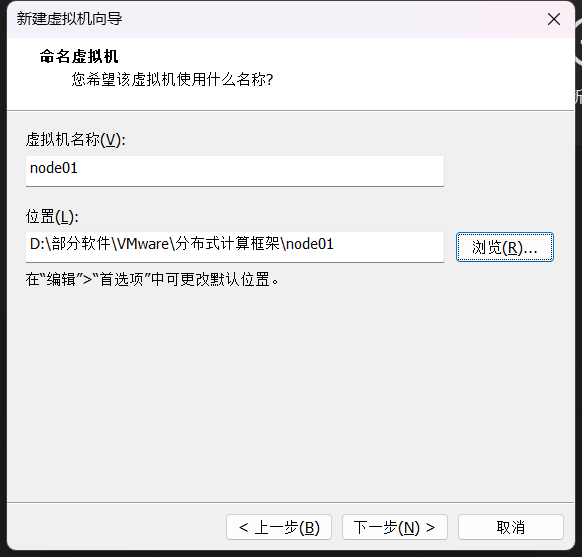
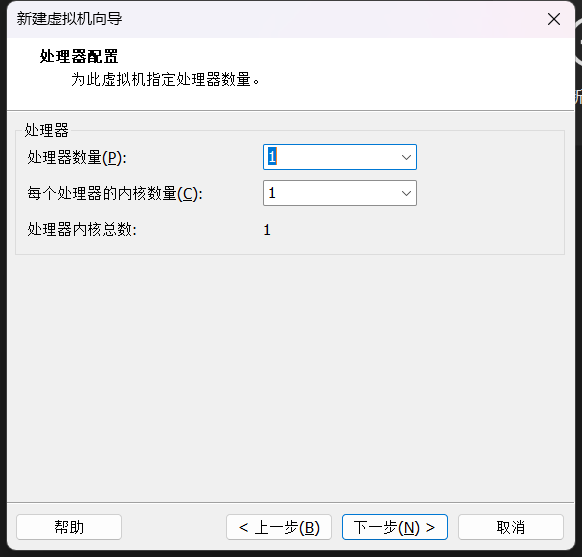
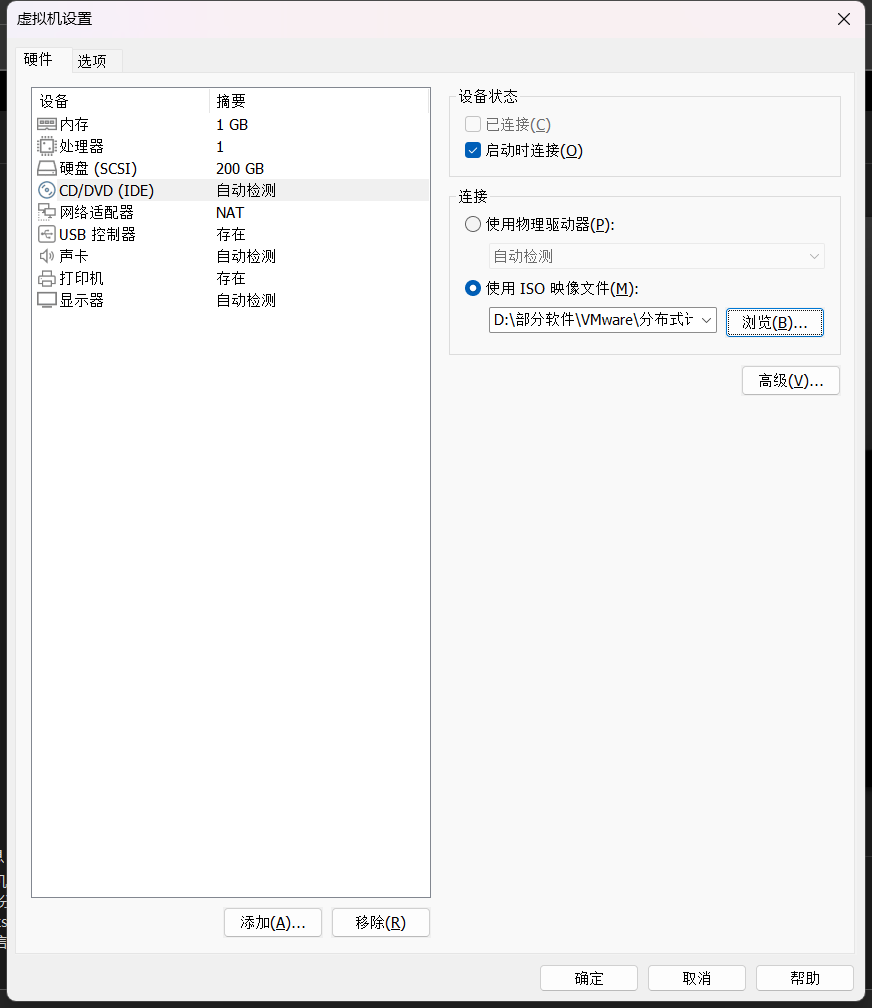

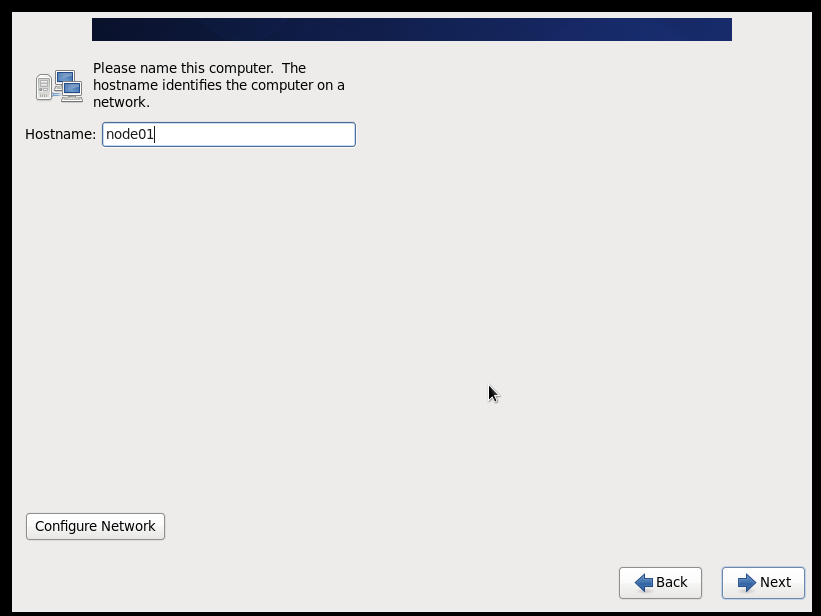
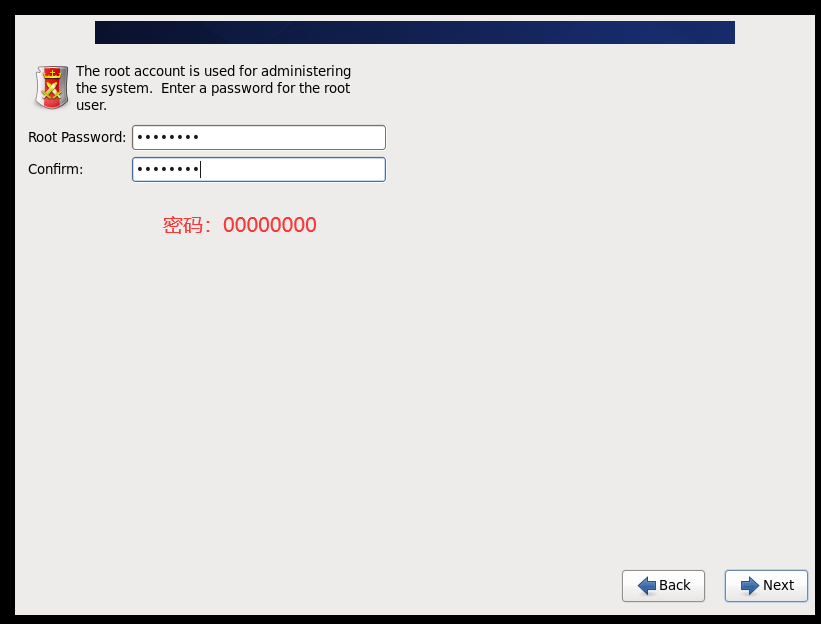
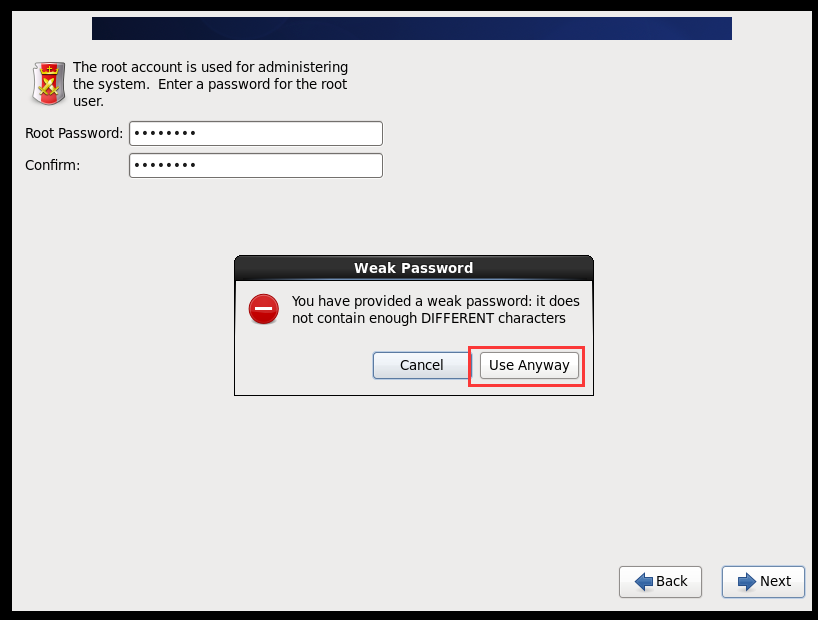
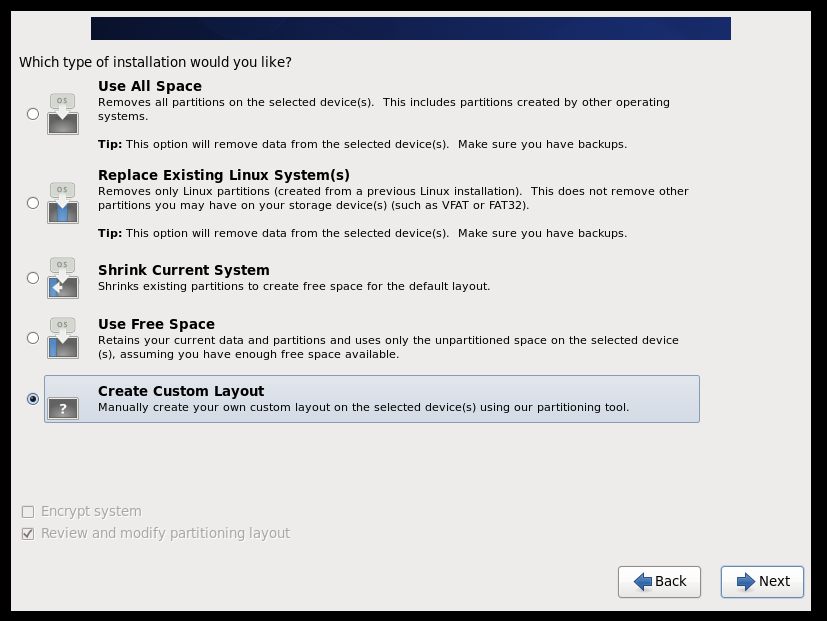
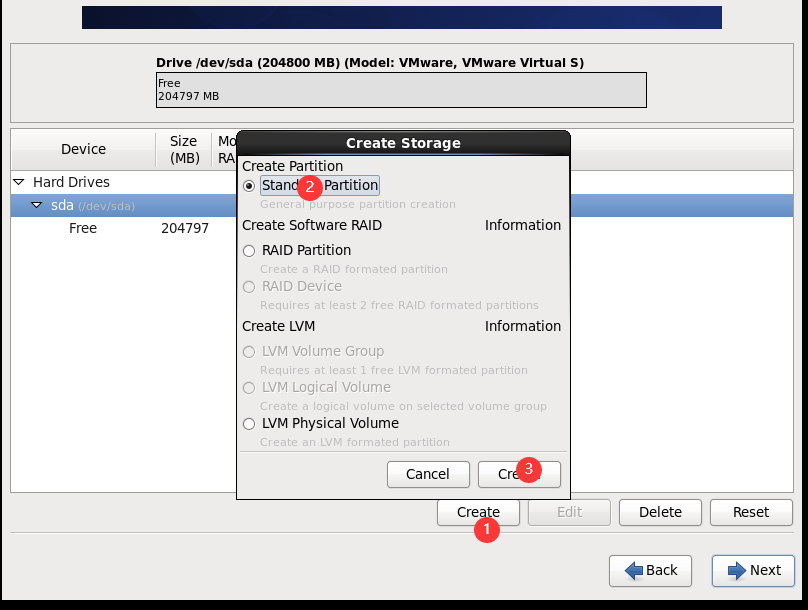

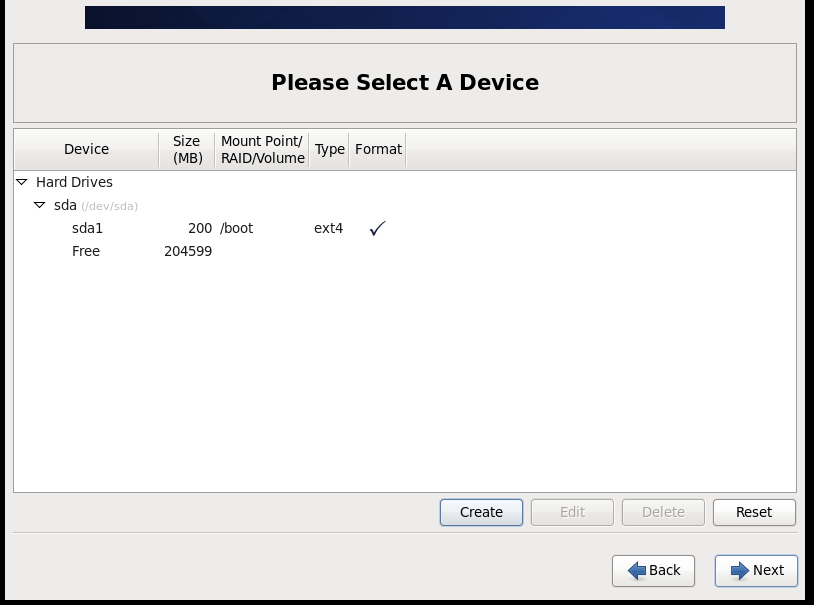
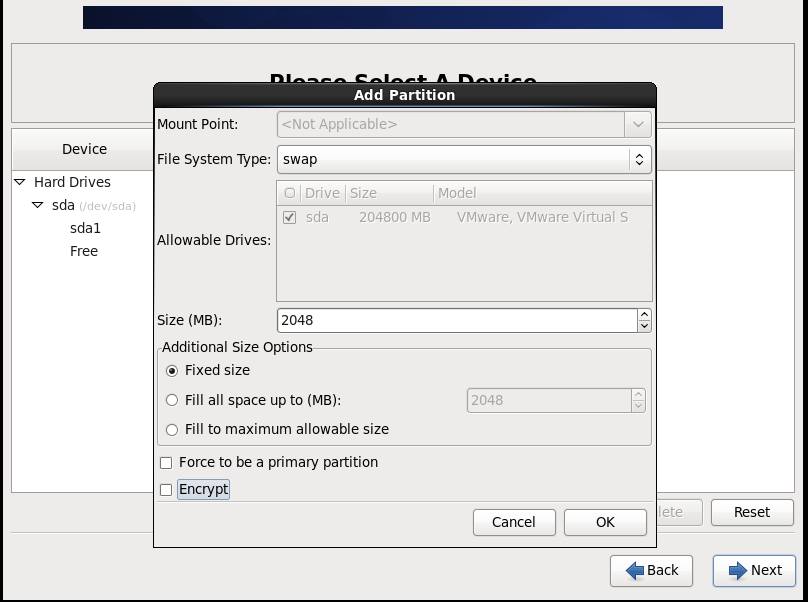
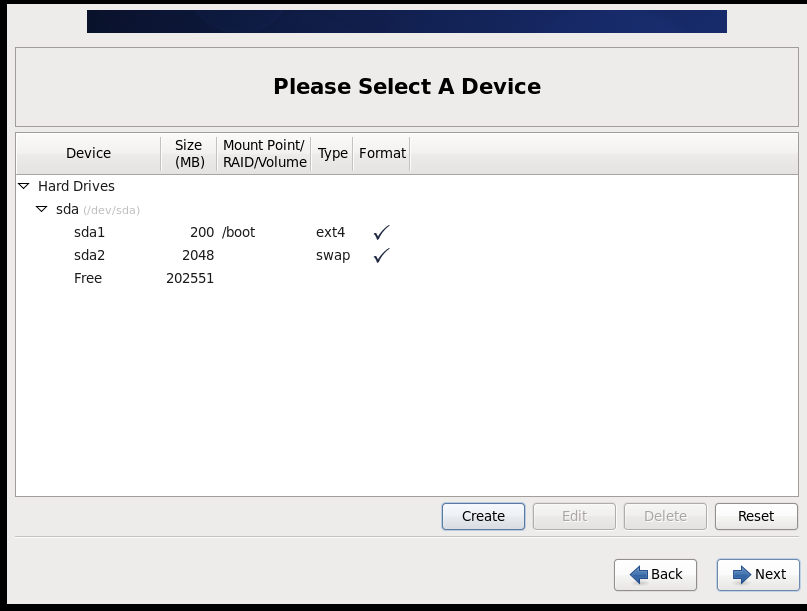
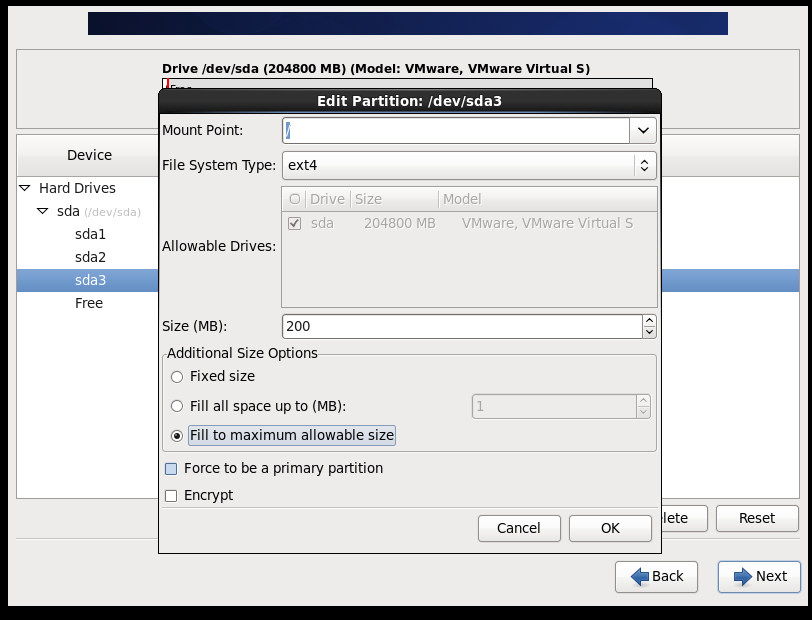
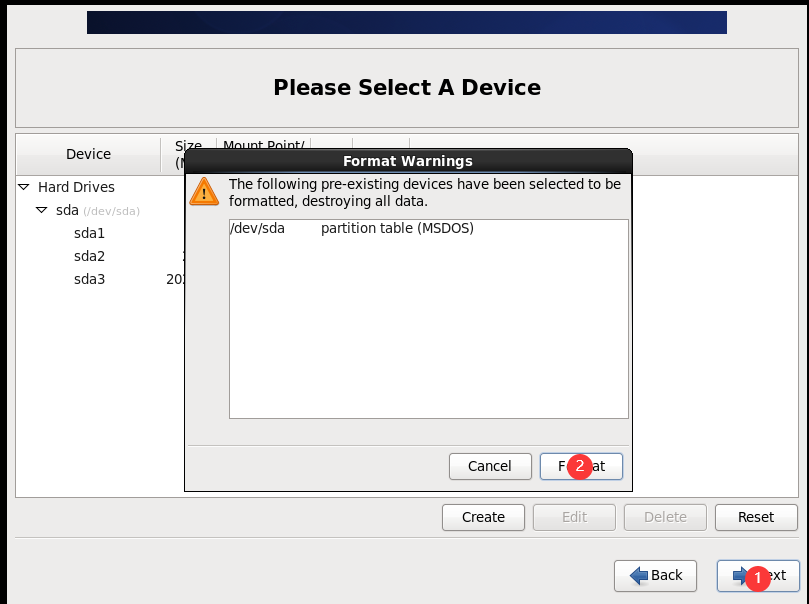
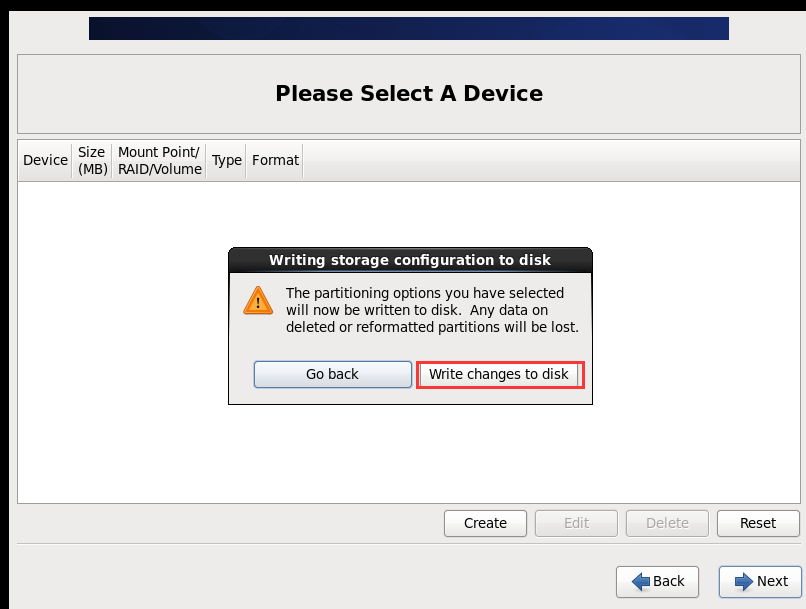
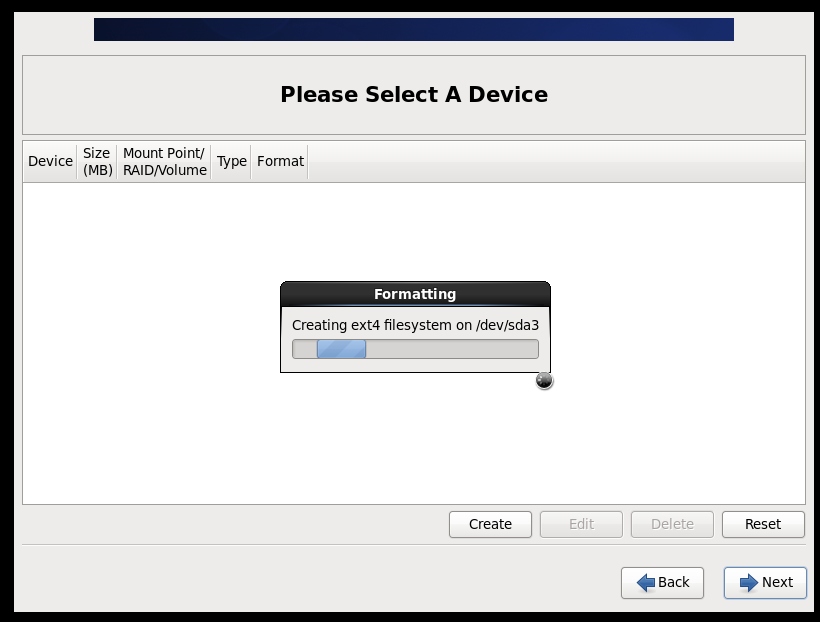
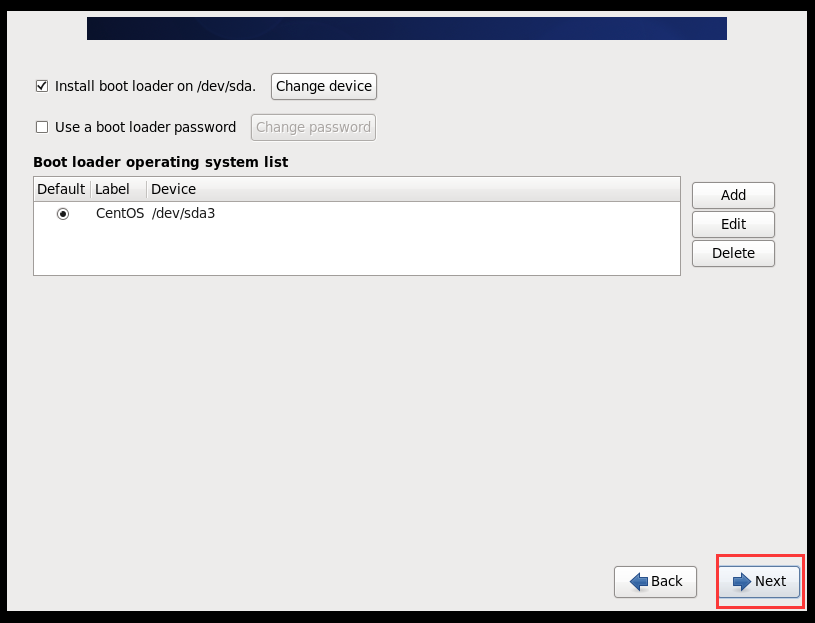
(2)配置网络(/etc/sysconfig/network-scripts/ifcfg-eth0)
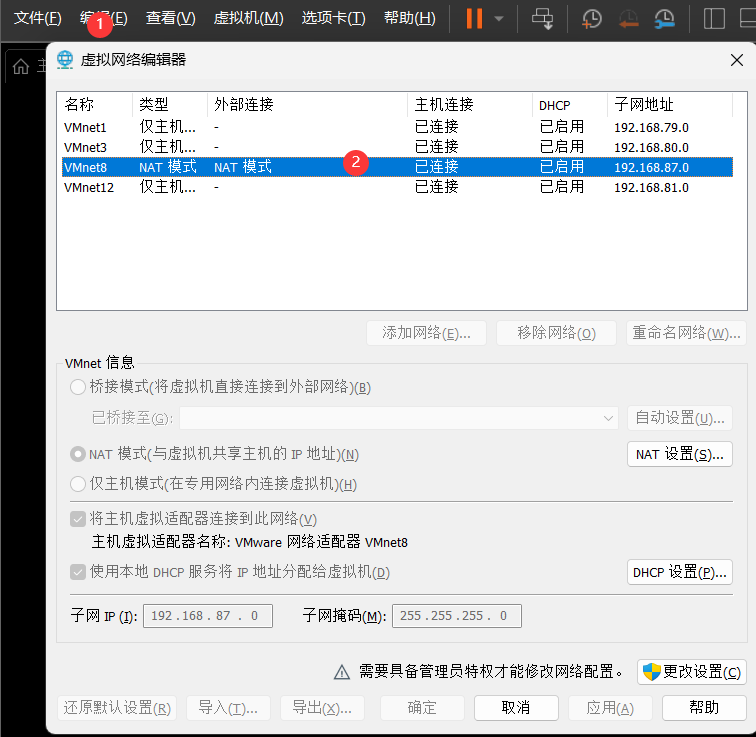
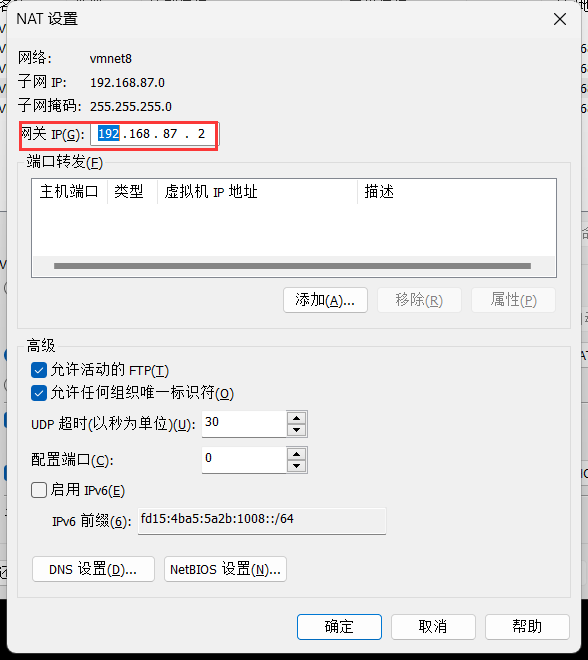
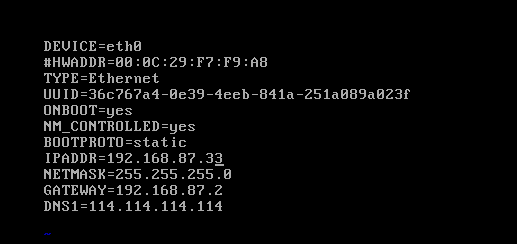
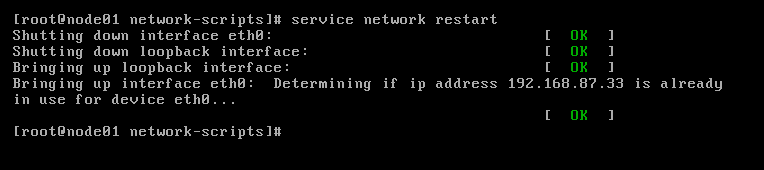
(3)关闭防火墙
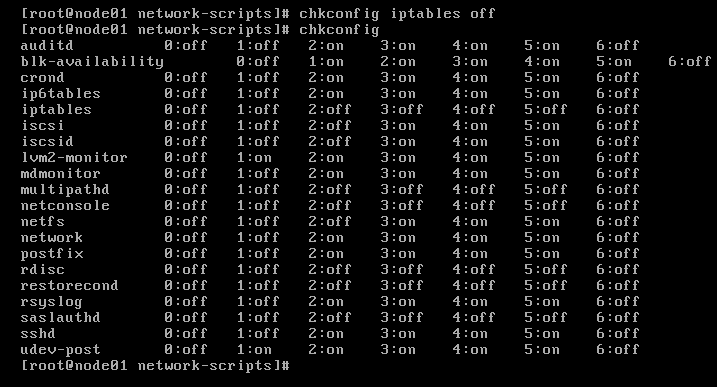
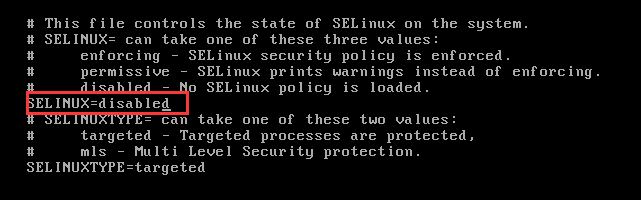
(4)关闭selinux(/etc/selinux/config)
SELINUX=disabled //将enforcing改为disabled
(5)删除/etc/udev/rules.d/70-persistent-net.rules //便于克隆,该文件也有网卡地址映射
rm -f /etc/udev/rules.d/70-persistent-net.rules

(6)拍摄快照,克隆新的虚拟机 ,启动新虚拟机,MAC地址就会改变
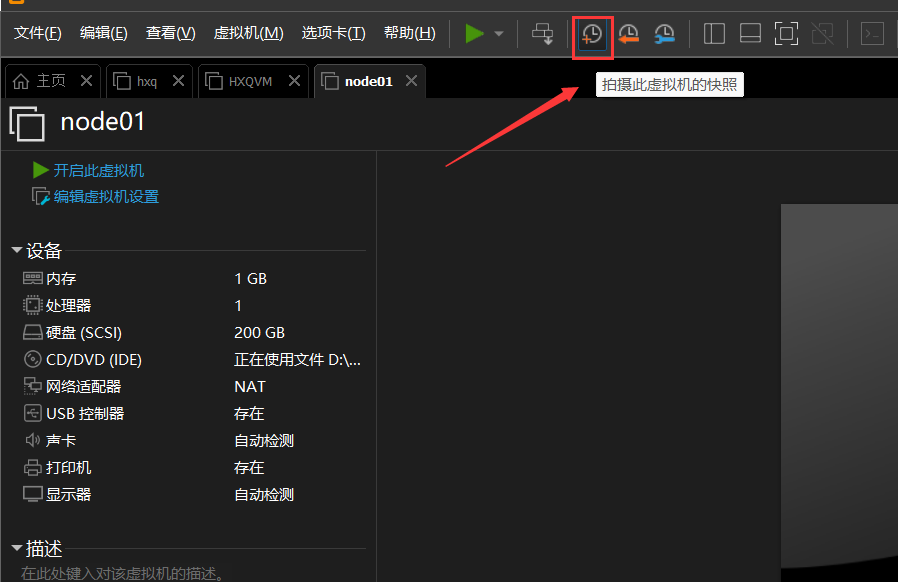
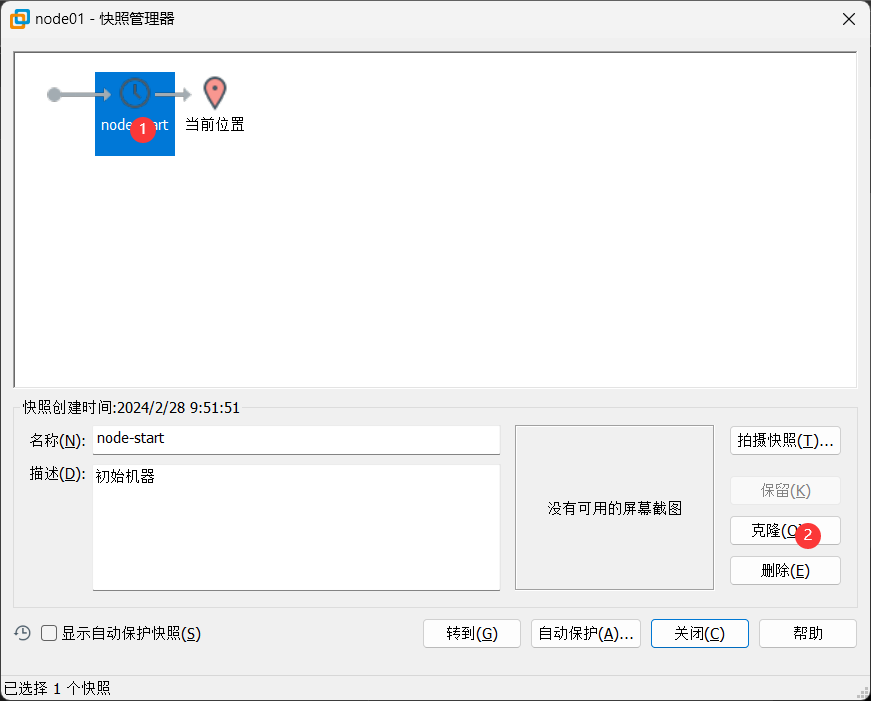
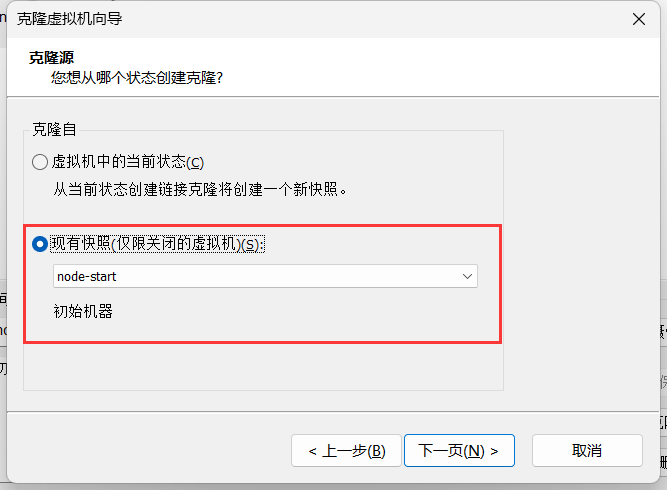
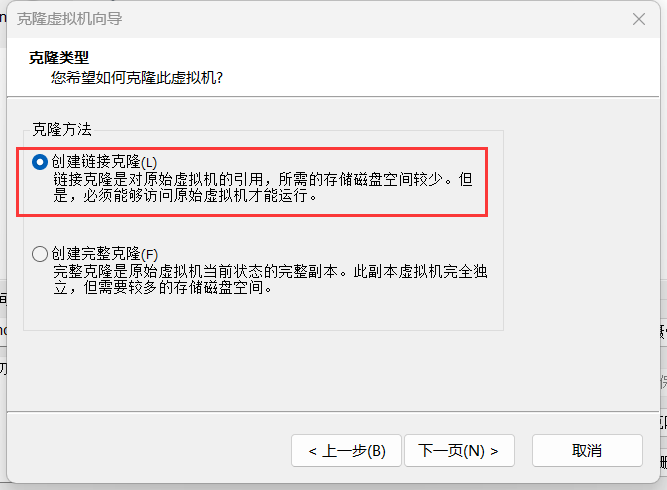
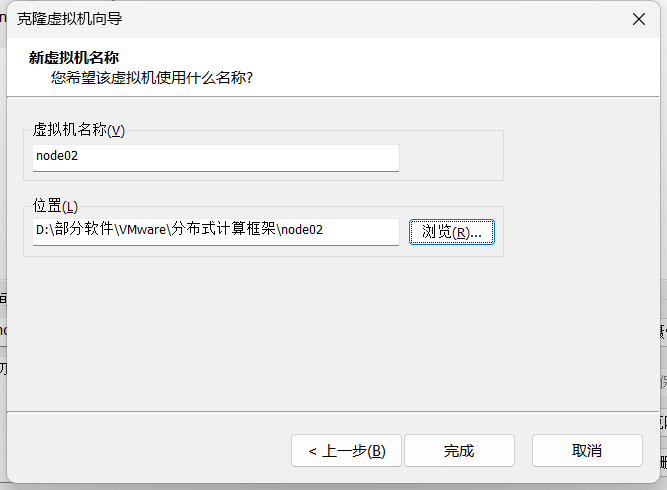
重复创建5台虚拟机
(7)重复第2步,配置4台虚拟机IP
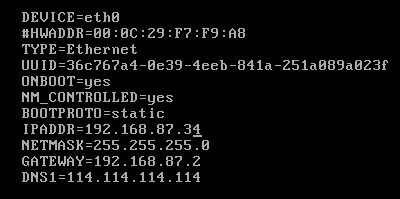
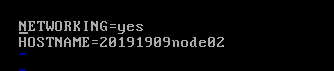
(8)配置主机名(/etc/sysconfig/network)
hostname=20191909node0x (要求:主机名=学号+序号)
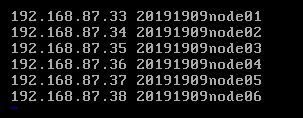
(9)配置映射(/etc/hosts)
192.168.87.33 20191909node01 //初始机作备用
192.168.87.34 hxq20191909node02
192.168.87.35 hxq20191909node03
192.168.87.36 hxq20191909node04
192.168.87.37 hxq20191909node05
192.168.87.38 hxq20191909node06
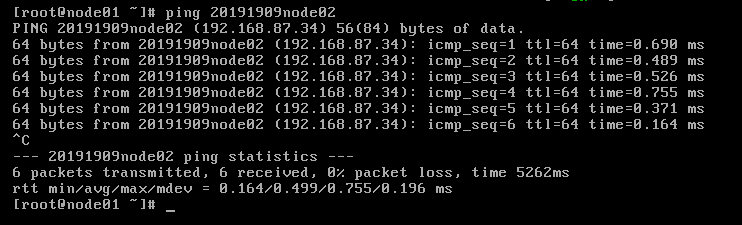
(10)验证 在20191909node01上 ping 20191909node02 或 ping 192.168.87.34
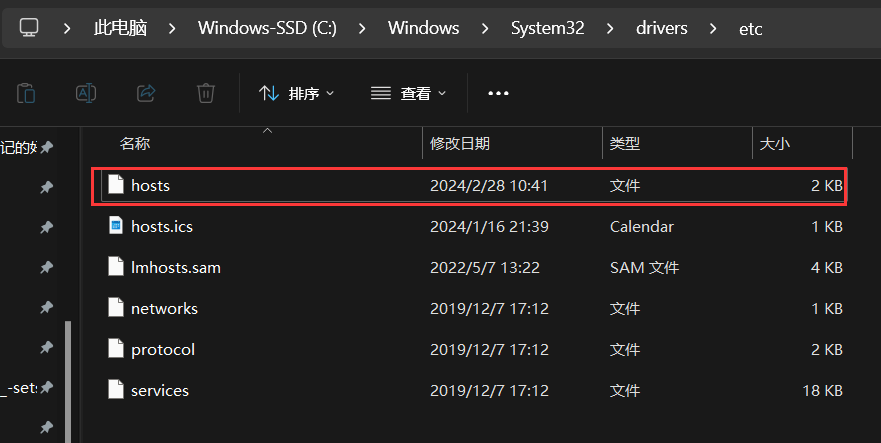
(11)编辑 C:\WINDOWS\System32\drivers\etc\hosts //windows应用程序也可以访问主机名
192.168.87.33 20191909node01
192.168.87.34 hxq20191909node02
192.168.87.35 hxq20191909node03
192.168.87.36 hxq20191909node04
192.168.87.37 hxq20191909node05
192.168.87.38 hxq20191909node06
(12) 最后结果

基本任务2:hadoop伪分布式安装
(本例在20191909node01上搭建伪分布式)
(1)安装java //可以通过xftp传输安装文件到/root/software/
1.1 解压
rpm -i jdk-7u67-linux-x64.rpm //解压到/usr/java/jdk1.7.0_67
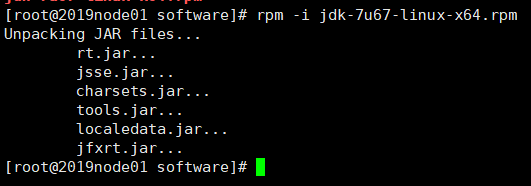
1.2 配置环境变量
vi + /etc/profile //通过. /etc/profile 或 source /etc/profile使其生效
export JAVA_HOME=/usr/java/jdk1.7.0_67
PATH=$PATH:$JAVA_HOME/bin
//下面未配置
export HADOOP_HOME=/opt/sxt/hadoop-2.6.5
PATH=$PATH:$JAVA_HOME:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HBASE_HOME=/opt/sxt/hbase-0.98.12.1-hadoop2
PATH=$PATH:$HBASE_HOME/bin
export ZOOKEEPER_HOME=/opt/sxt/zookeeper-3.4.6
PATH=$PATH:$ZOOKEEPER_HOME/bin
export HIVE_HOME=/opt/sxt/apache-hive-1.2.1-bin
PATH=$PATH:$HIVE_HOME/bin



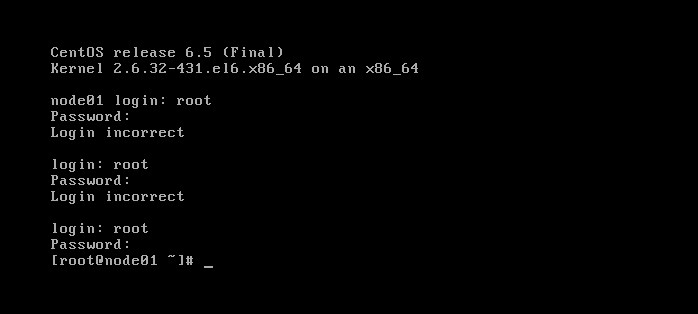
(2)设置ssh免密钥登录
rw-r–r-- 1 root root 1202 Nov 1 2019 authorized_keys
-rw------- 1 root root 668 Nov 1 2019 id_dsa
-rw-r–r-- 1 root root 601 Nov 1 2019 id_dsa.pub
cd /root/.ssh/ //如果没有.ssh目录,可以登录localhost自动产生
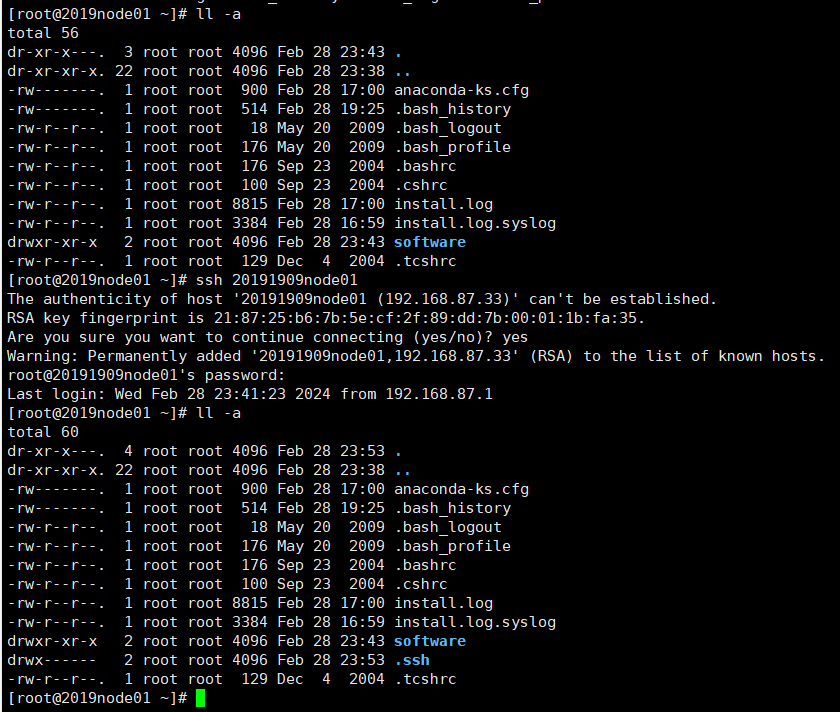
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat id_dsa.pub >> authorized_keys //将id_dsa.pub公钥文件追加到验证文件authorized_keys
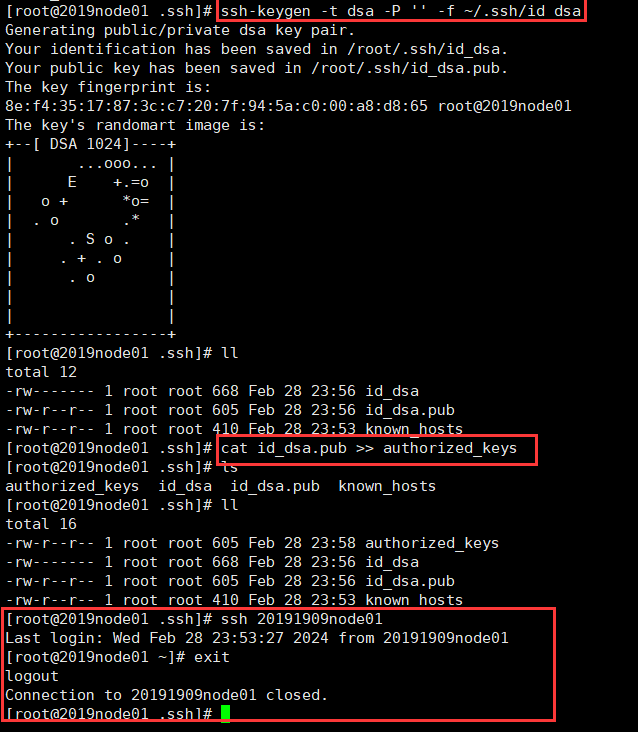
// 设置.ssh目录权限 chmod 700 -R .ssh
//第二种方法:
ssh-keygen
ssh-copy-id -i id_rsa.pub node01
(3)安装Hadoop
3.1 传输安装文件到/root/software

3.2 建立解压目的目录
mkdir -p /opt/20191909

3.3 解压
tar xf hadoop-2.6.5.tar.gz -C /opt/20191909/

3.4. 配置环境变量 //sbin目录存放系统级别脚本,bin目录存放一般命令
vi + /etc/profile
export HADOOP_HOME=/opt/2019109/hadoop-2.6.5
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

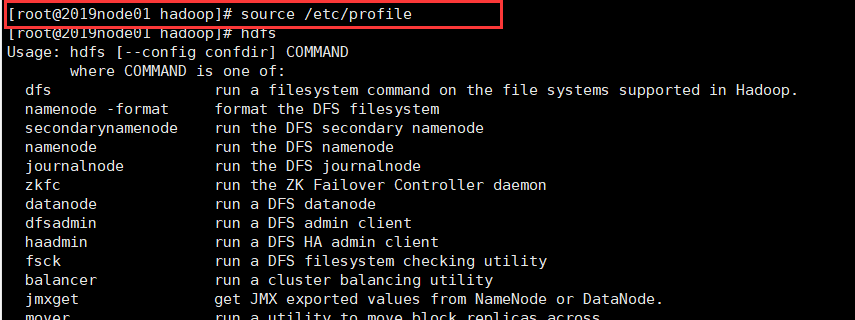
(4)修改配置文件
文件所在目录:/opt/20191909/hadoop-2.6.5/etc/hadoop
-
修改hadoop-env.sh,mapred-env.sh,yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_67

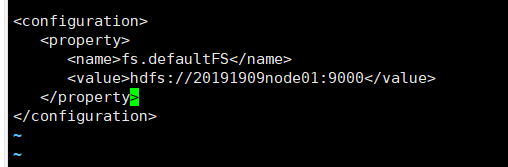
- 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://20191909node01:9000</value>
</property>
</configuration>
-
修改hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>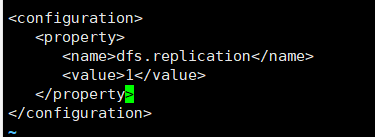
-
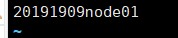
slaves //从节点信息
20191909node01
-
修改hdfs-site.xml,增加:
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>20191909node01:50090</value> </property> </configuration>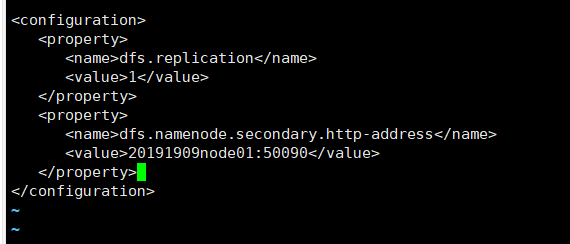
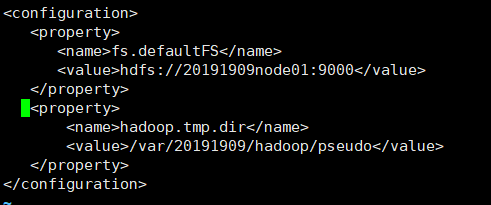
6.修改core-site.xml,增加:
<property>
<name>hadoop.tmp.dir</name>
<value>/var/20191909/hadoop/pseudo</value>
</property>
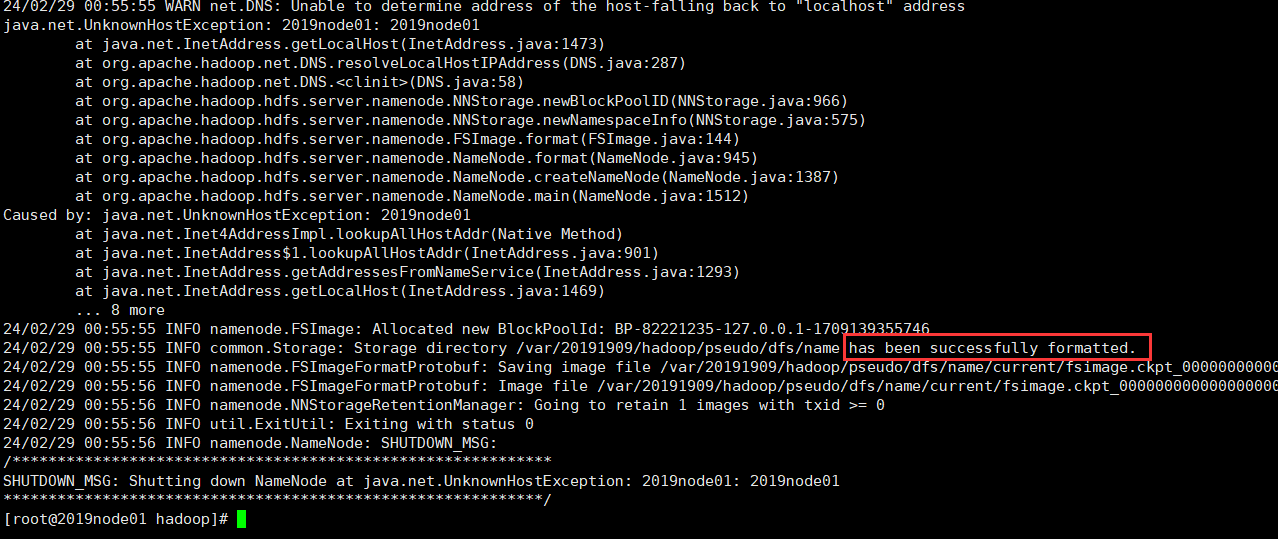
(5) 格式化
hdfs namenode -format

查看 /var/2019109/hadoop/pseudo/dfs/name/current/fsimage_…
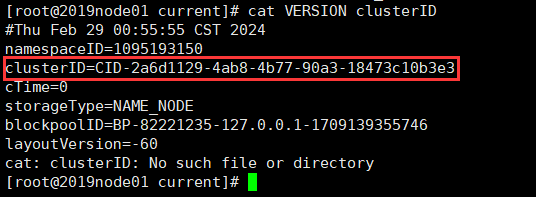
cat VERSION clusterID(集群ID)
四、出现问题及解决方案
问题:
- DataNode未启动
解决方案:
- 恢复快照,重新配置环境
五、实验结果
(1)启动集群
start-dfs.sh //可以jps查看启动哪些进程
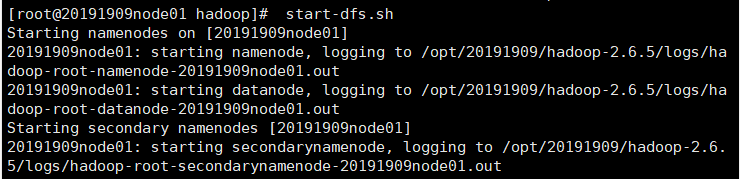
jps //命令
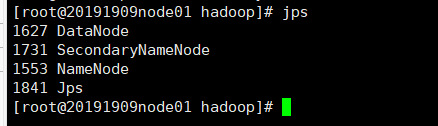
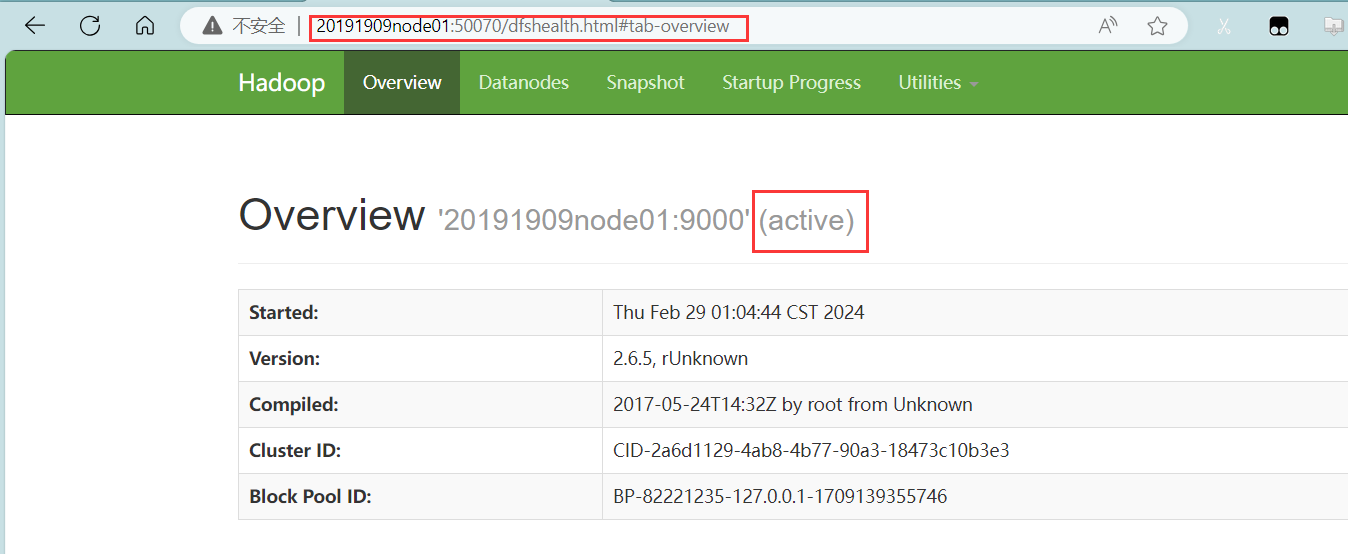
(2)通过浏览器查看信息
ss -nal 查看通讯端口

在火狐等浏览器输入20191909node01:50070,前提是要在windows下的c:/windows/system32/drivers/etc/hosts文件添加IP节点映射
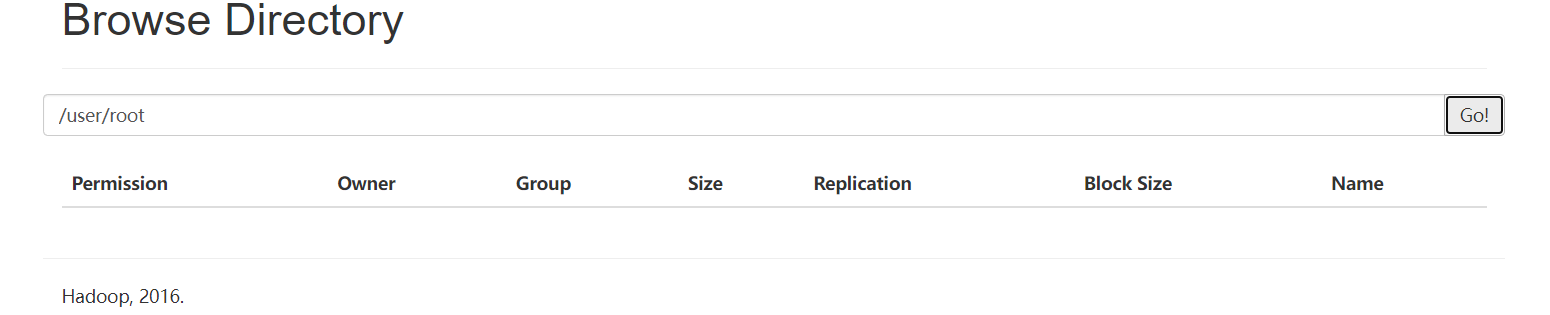
(3)练习上传文件
-
创建路径
hdfs dfs -mkdir -p /user/root

hdfs dfs -ls /
-
上传文件
cd ~/software
ls -lh ./ //查看文件大小
hdfs dfs -put hadoop-2.6.5.tar.gz /user/root
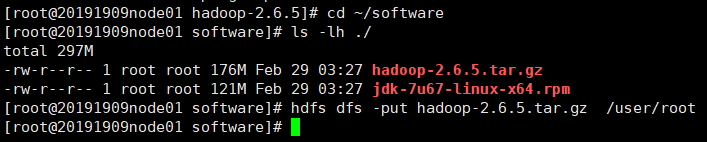
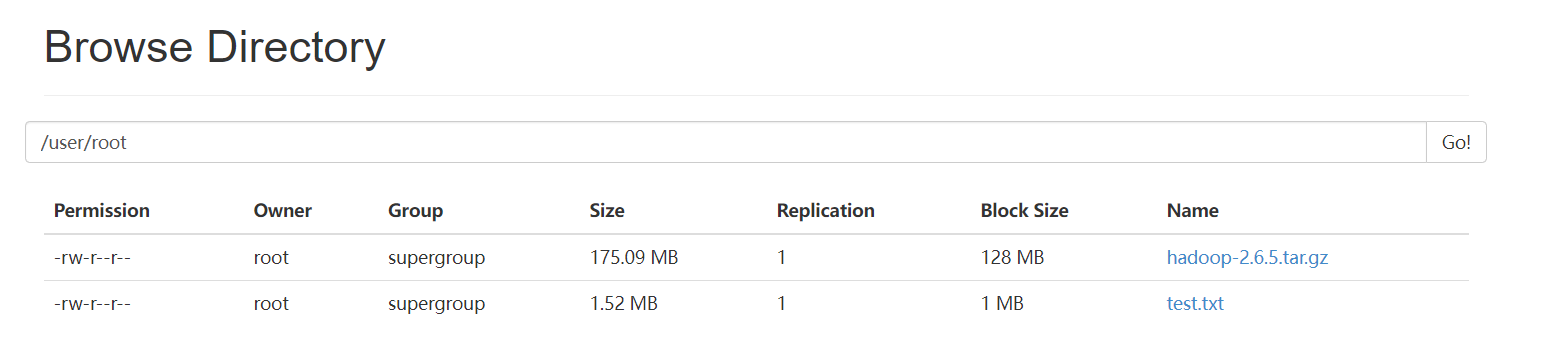
在浏览器查看
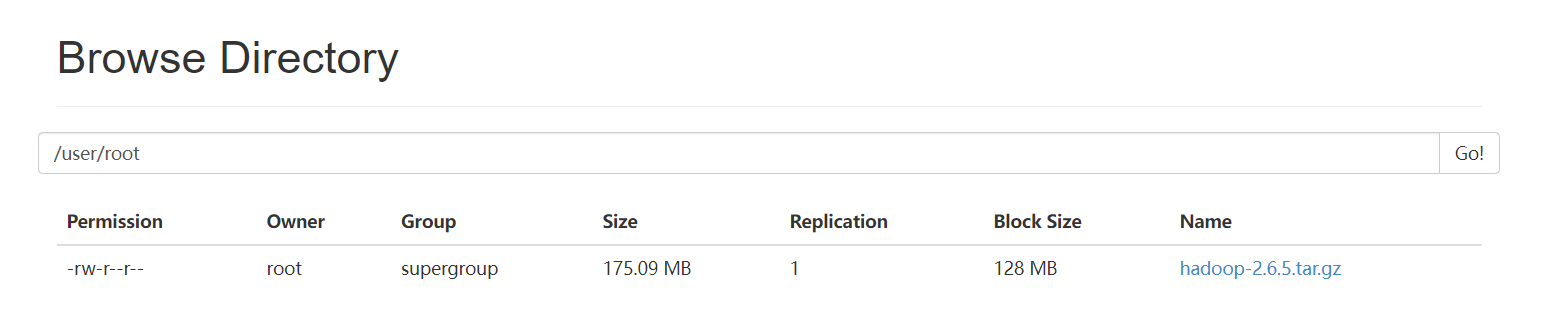
该文件应该生成两个块,块大小默认128MB
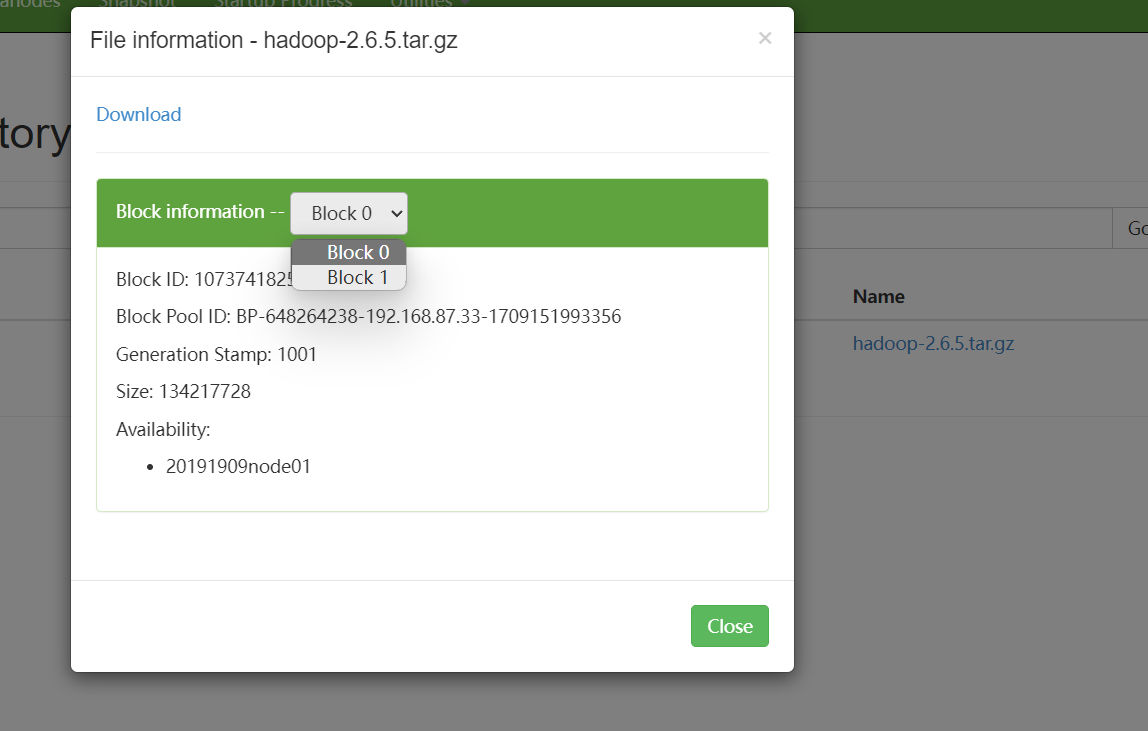
查看/var/20191909/pseudo/data/…实际存储位置

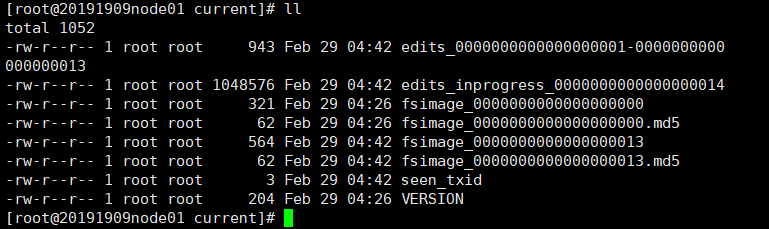
-
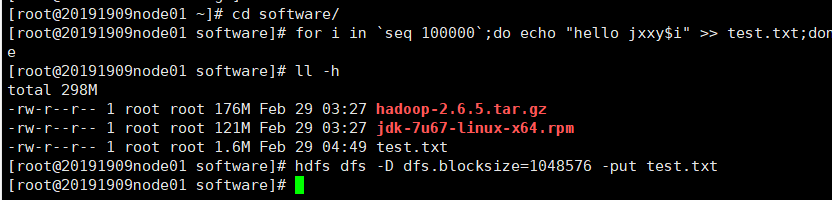
在~/software目录里创建一个新文件
for i in seq 100000;do echo “hello jxxy$i” >> test.txt;done
查看新文件大小
ll -h //test.txt文件大小约为1.6M
设置块大小上传文件
hdfs dfs -D dfs.blocksize=1048576 -put test.txt
-
每次需要关闭集群
stop-dfs.sh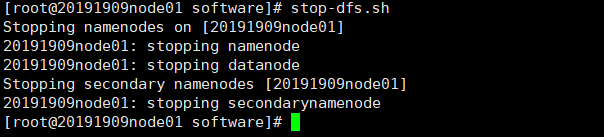
六、实验思考题
-
安装linux时,如何配置网络?
在安装Linux时配置网络,通常需要编辑网络配置文件,比如
/etc/network/interfaces或者/etc/sysconfig/network-scripts/ifcfg-eth0,设置IP地址、子网掩码、网关等信息,然后重启网络服务使配置生效。 -
为什么要删除/etc/udev/rules.d/70-persistent-net.rules?
删除
/etc/udev/rules.d/70-persistent-net.rules文件是因为这个文件会存储设备的 MAC 地址与接口名的映射关系,如果更换了网卡或者调整了网络配置,可能会导致网络接口名混乱,删除该文件可以让系统在下次启动时重新生成正确的映射关系。 -
为什么要设置ssh免密钥登录?如何设置?
设置SSH免密钥登录可以提高安全性并方便远程登录管理。具体设置方法包括:生成密钥对、将公钥添加到目标服务器的
~/.ssh/authorized_keys文件中,确保权限正确;然后就可以直接SSH登录而无需输入密码。 -
搭建hadoop时,为什么要配置hadoop.tmp.dir?
配置
hadoop.tmp.dir参数是为了指定Hadoop在运行过程中存储临时数据的目录,一般情况下应该设置在一个独立的磁盘或者目录上,以避免对主要存储产生影响。 -
安装完全分布式,为什么要同步服务器时间?
同步服务器时间在完全分布式环境下非常重要,因为各个节点之间需要保持时间同步以确保协调运行。可以使用NTP服务来实现时间同步,配置主服务器为时间服务器,其他服务器与其同步即可。
-
启动过程中如果发现某个datanode出现问题,如何处理?
如果在启动过程中某个DataNode出现问题,可以先查看日志文件以确定具体问题,尝试重启DataNode服务或者进行故障排查处理。如果问题无法解决,可能需要考虑替换硬件或修复软件错误。
-
zookeeper的作用是什么?
Zookeeper的作用是提供分布式应用程序的协调服务,包括配置管理、命名服务、集群管理等功能。在Hadoop集群中,Zookeeper通常用于协调和管理Hadoop集群的各个组件,确保它们能够正确协同工作。
hadoop.tmp.dir` 参数是为了指定Hadoop在运行过程中存储临时数据的目录,一般情况下应该设置在一个独立的磁盘或者目录上,以避免对主要存储产生影响。
-
安装完全分布式,为什么要同步服务器时间?
同步服务器时间在完全分布式环境下非常重要,因为各个节点之间需要保持时间同步以确保协调运行。可以使用NTP服务来实现时间同步,配置主服务器为时间服务器,其他服务器与其同步即可。
-
启动过程中如果发现某个datanode出现问题,如何处理?
如果在启动过程中某个DataNode出现问题,可以先查看日志文件以确定具体问题,尝试重启DataNode服务或者进行故障排查处理。如果问题无法解决,可能需要考虑替换硬件或修复软件错误。
-
zookeeper的作用是什么?
Zookeeper的作用是提供分布式应用程序的协调服务,包括配置管理、命名服务、集群管理等功能。在Hadoop集群中,Zookeeper通常用于协调和管理Hadoop集群的各个组件,确保它们能够正确协同工作。
![[Vue3] 配置 Pinia 并存储、读取、修改数据 | 集中式状态(数据)管理](https://img-blog.csdnimg.cn/direct/8a049d8f49e04f0184ca537b55c7edac.png)