1. Introduction
开源llm举例:LLaMA 、Qwen 、Mistral 和Deepseek
大型语言模型的发展包括预训练、监督微调(SFT)和基于人类反馈的强化学习(RLHF)等主要阶段
InternLM2的显著特点
- 采用分组查询注意力(GQA)来在推断长序列时减少内存占用
- 预训练:4k个上下文文本——高质量的32k文本——位置编码外推
- 监督微调(SFT)和基于人类反馈的强化学习(RLHF)
- 条件在线RLHF(COOL RLHF)
- 多轮Proximal Policy Optimization(PPO)缓解奖励作弊问题
2. Infrastructure
2.1 InternEvo
在预训练、有监督微调和RLFH期间使用的训练框架InternEvo
特点:数据、张量、序列和管道并行技术
多种Zero Redundancy Optimizer (ZeRO, 2020)策略、FlashAttention技术、混合精度训练(Mixed Precision Training)
MFU:模型计算量利用率
减少通信开销:自适应分片技术(如Full-Replica、Full Sharding和Partial-Sharding)
通信与计算的重叠
长 序 列 训 练:InternEvo将GPU内存管理分解为四个并行维度 (数据、 张量、 序列和管道) 和三个分片维度(参数、梯度和优化器状态)
容错性:异步保存机制、冷存储
2.2 Model Structure
LLaMA的结构设计原则:在Transformer的基础架构上,将LayerNorm替换为RMSNorm,采用SwiGLU作为激活函数,分组查询注意力(GQA)
3. Pre-train
详细描述如何为预训练准备文本、代码和长文本数据
3.1 Pre-training Data
文本数据
以JSON Lines (jsonl)格式存储
处理步骤包括:数据格式化、应用启发式统计规则清洗数据、使用局部敏感哈希(LSH)方法进行数据去重、采用复合安全策略过滤数据

代码数据
通过训练代码数据,有可能提升推理能力
数据源分布
格式清理:转换为markdown格式
代码去重
质量筛选
依赖排序
长文本数据
数据过滤管道:长度选择、统计过滤器、语言模型perplexity过滤器
3.2 Pre-training Settings
分词Tokenization
预训练中超参数设置
AdamW优化器、余弦退火学习率衰减策略
3.3 Pre-training Phases
三个阶段:
不超过4k长度的预训练语料库——不超过32k长度的预训练数据——特定能力增强数据
4. Alignment
4.1 有监督微调
将数据样本转换为 ChatML 格式
4.2 COOL RLFH
用Proximal Policy Optimization (PPO)方法设置reward函数
RLHF存在的问题
- 偏好冲突:有益和无害
- 奖励作弊(reward hacking)的问题
条件在线RLHF
整合多个偏好且减少奖励作弊
作用机理:将不同的系统提示(system prompt)应用于不同类型的偏好
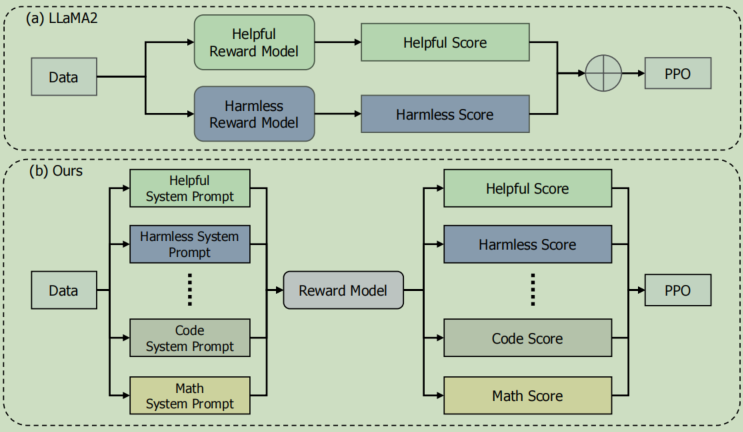
如何减少奖励作弊:
RLHF分为两个路径:
快速路径(Fast Path)用于立即、有针对性的改进
慢速路径(Slow Path)则用于长期、全面地优化奖励模型
4.3 长上下文微调
一类来自书籍的长序列文本,另一类是来自GitHub仓库的数据
4.4 工具增加的llm
代码解释器(<|interpreter|>)和外部插件(<|plugin|>)
5. 评估和分析
5.1 总体性能
使用OpenCompass进行评估
5.2 在下游任务上的表现
(1) 全面测试,(2) 语言和知识,(3) 推理和数学,(4) 多种编程语言编程,(5) 长文本建模,(6) 工具利用
5.3 对齐表现
6. 结论
参考资料
InternLM技术报告