1.SPU实现的PSI介绍
1.PSI的定义和种类
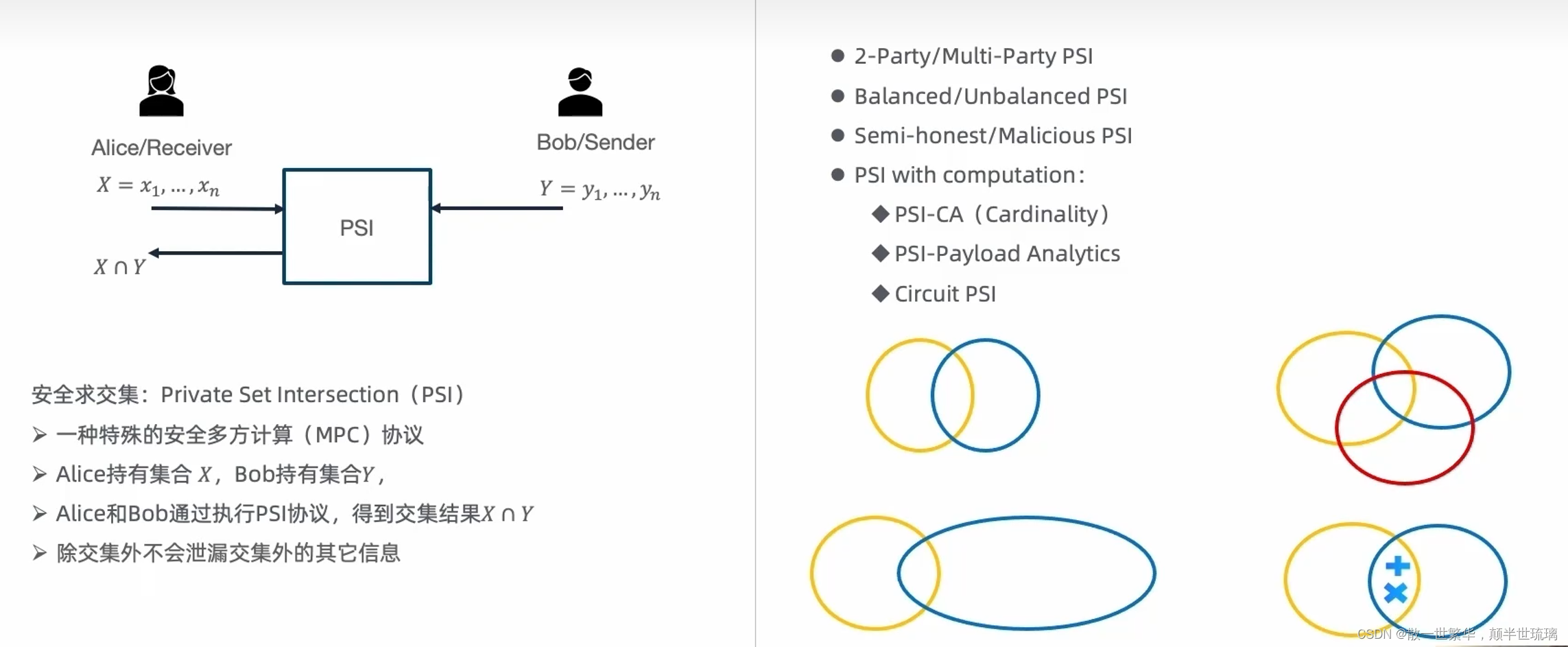
隐私集合求交(Private Set Intersection, PSI)是一种在密码学和安全多方计算(MPC)领域中的关键技术,允许两个或多个参与者在不泄露各自输入集合中非交集部分的前提下,找出他们所拥有的共同元素。隐语在 PSI 技术方面提供了相关的解决方案。
根据不同的实现机制和技术原理,PSI 可以分为以下几种类型:
-
基于公钥密码学的 PSI 方案:
- 基于判定型Diffie-Hellman (DDH):利用 DDH 难题设计的 PSI 协议,允许在不暴露额外信息的情况下计算集合交集。
- 基于RSA盲签名:通过 RSA 密码系统和盲签名技术实现集合求交,保证数据隐私性。
-
基于不经意传输 (Oblivious Transfer, OT):OT 是构建 PSI 的基础组件之一,通过 OT 实现让一方能够得知某些信息而无法获知其他无关信息,从而实现在不知情的情况下完成集合求交操作。
-
基于通用MPC的PSI方案:
- 基于混淆电路 (Garbled Circuit, GC):使用混淆电路技术,将逻辑运算转化为加密形式,使得计算过程能够在不解密数据的情况下得出交集结果。
-
基于同态加密 (Homomorphic Encryption, HE):通过支持某种数学运算的同态加密算法,可以在加密数据上直接执行计算,解密后得到交集结果,而无需在明文状态下交互数据。
此外,按照参与方的数量,PSI 还可以分类为:
- 两方PSI:仅涉及两个参与方之间的集合求交。
- 多方PSI:涉及三个或更多参与方之间的集合求交。
隐语还提到了对 PSI 协议的进一步细分,比如:
- 平衡PSI (Balanced PSI):适合双方数据量相差不大的场景,如 ecdh/kkrt16/bc22 协议。
- 非平衡隐私集合求交 (Unbalanced PSI):针对双方数据规模差异较大的情况设计的专门协议,能够有效处理数据量不对称时的效率问题。
2.PSI功能分层
隐私集合求交(Private Set Intersection, PSI)作为一种密码学技术,虽然本身不严格划分成多层架构,但在其实现过程中确实可以抽象出不同层次的功能模块来描述其工作流程和安全性保证。以下是按照逻辑层次对PSI功能的一种概括分层:
-
用户接口层:
这一层主要是对最终用户或者应用程序提供接口,让用户能够方便地提交待求交的私有数据集合,并获取求交结果。这一层通常会对原始数据进行预处理和格式转换,以便适应底层 PSI 协议的要求。 -
数据加密层:
在这一层,用户提交的原始数据被转化为加密形式,这是 PSI 安全性的关键步骤。可以采用多种加密技术,如同态加密、不经意传输(OT)、基于身份的加密(IBE)、或是基于零知识证明(ZKP)等方法,确保数据在传输和计算过程中始终保持加密状态。 -
协议层:
协议层具体实现 PSI 的核心算法和通信流程,例如基于哈希的 PSI、基于加法同态加密的 PSI 或基于 oblivious transfer 的 PSI。此层的设计要确保即使在多方参与的情况下,除了交集部分外,任何一方都无法得知对方集合的具体内容。 -
通信层:
负责执行协议层所需的网络通信任务,包括但不限于数据交换、消息同步和错误恢复等。这一层确保了 PSI 协议能在分布式环境下正确执行。 -
计算层:
包括对加密数据进行高效计算的方法,如基于半同态加密的计算、基于 garbled circuit 的计算等,用于在不解密情况下直接在加密数据上进行交集操作。 -
结果解密与验证层:
在完成交集计算后,这一层负责对加密的结果进行解密,并可能包含对结果的完整性或正确性验证机制,确保输出的交集确实是各个参与方私有集合的真实交集。
3.SPU实现的PSI种类
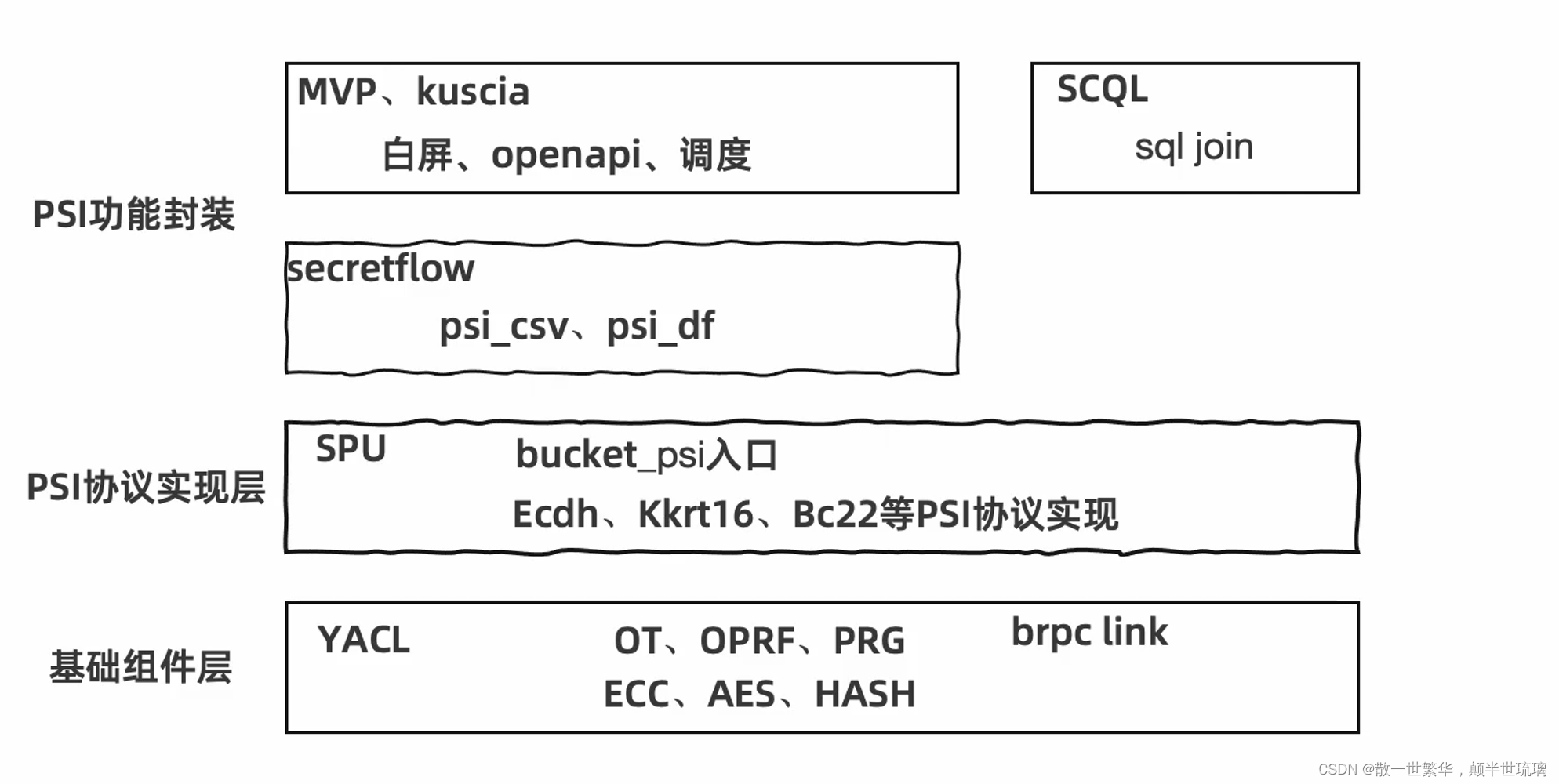
SPU(Secure Process Unit)作为一个专注于隐私计算和安全多方计算(MPC)的模块或框架,在实现 PSI(Private Set Intersection,隐私集合求交)功能时,支持多种协议和算法。以下是一些SPU实现的PSI种类:
-
基于DDH(Decisional Diffie-Hellman)的PSI协议:
SPU实现了基于DDH难题的PSI协议,这是一种经典的密码学协议,允许两方在不知道对方完整集合内容的情况下,仅计算出各自的交集部分。 -
KKRT协议:
KKRT是一种高效的多方PSI协议,SPU提供了KKRT协议的实现,它适用于多方之间进行隐私集合求交的操作。 -
基于BC22PCG的协议:
BC22PCG可能是另一种具体的PSI协议变体,但确切含义未在已有资料中详细说明,推测可能是针对特定应用场景优化过的PSI协议。
除此之外,SPU可能还支持其他的PSI变种,比如针对数据量不平衡情况的非平衡PSI协议(Unbalanced PSI),以及可能结合其他密码学工具如同态加密(HE)或不经意传输(Oblivious Transfer, OT)技术实现的更复杂版本的PSI协议。
总之,SPU旨在通过提供丰富的PSI协议选择和优化实现,以满足不同场景下对于数据隐私保护和性能需求的多样化要求。

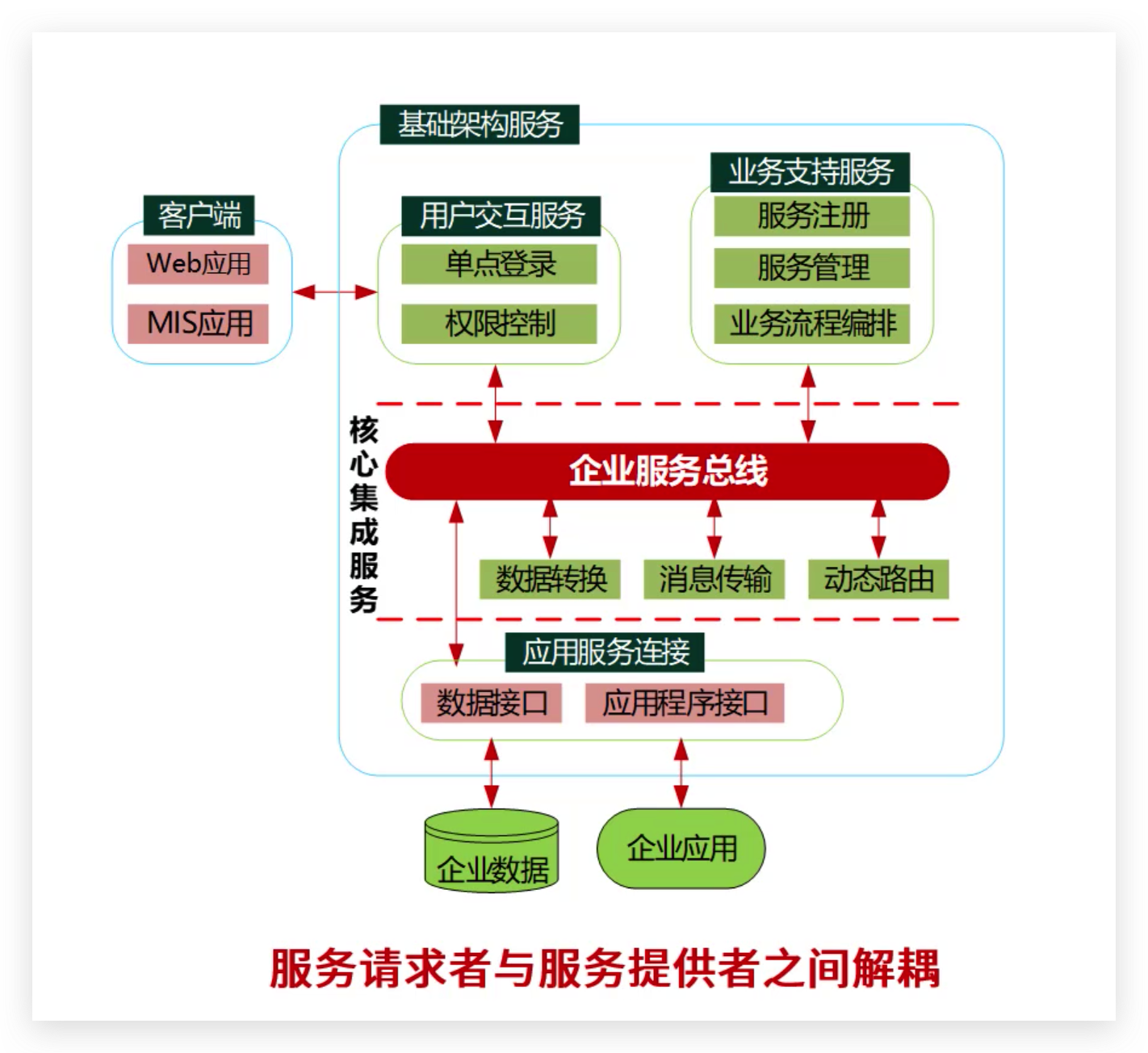
2.SPU PSI调度架构
SPU PSI 调用框架是一种用于处理大规模数据集的隐私计算技术。该框架主要由以下几个部分组成:
- 统一入口:用户可以通过
bucket_psi函数进入系统,这是高级API的一个入口点。 - 支持分桶求交:为了处理大量数据,SPU PSI 使用了分桶策略。这使得系统能够处理高达10亿规模的数据集。
- 输入输出处理:在数据处理过程中,系统会检查求交id列的数据完整性,并确保没有重复项。这些操作有助于保证数据质量。
- 输出处理:最后,系统会对求交结果进行排序,并生成完整的label列,以便于后续分析或应用。
在具体实现上,SPU PSI 调用框架包含两个关键的API:
- bucket_psi: 这个高级API通过Hash分桶方法支持海量数据,并涵盖了数据查重、分桶求交、结果广播及结果排序等全生产流程。
- mem_psi: 与 bucket_psi 不同,mem_psi 是一个低级API,它提供了算法内核的高性能,并且具有统一易用的接口。
此外,Operator 层起到了重要的作用:
- 它作为算法接入层,向上提供统一接口,方便用户使用。
- 工程化封装提高了系统的可维护性和扩展性。
- 注册工厂模式的应用提升了协议工程化的效率,使系统更加灵活和高效。

总的来说,SPU PSI 调用框架提供了一个全面、系统的方法来处理大规模数据集中的隐私计算问题,从而满足现代数据安全和隐私保护的需求。
3.PSI开发指南
1.启动Ray集群
启动ray集群的方法有两种,一种是Alice首先启动ray集群,另一种是Bob首先启动ray集群。以下是两种方法的具体步骤:
-
Alice首先启动ray集群:
- 注意这里的命令是启动Ray的主节点。
- 输入以下命令来启动ray集群:
ray start --head --node-ip-address="ip" --port="port" --include-dashboard=False --disable-usage-stats - 其中,“ip”是要分配给主节点的IP地址,“port”是主节点要监听的端口。
-
Bob首先启动ray集群:
- 输入以下命令来启动ray集群:
ray start --head --node-ip-address="ip" --port="port" --include-dashboard=False --disable-usage-stats - 同样,这里“ip”是要分配给主节点的IP地址,“port”是主节点要监听的端口。
- 输入以下命令来启动ray集群:
注意,每个节点都需要知道其他节点的IP地址和端口号,以便它们可以相互通信。当所有节点都启动后,它们就组成了一个ray集群,可以在其中运行分布式任务和actor。
2.初始化SecretFlow
初始化 SecretFlow 的步骤如下所示:
- 创建一个名为
sf_cluster_config的字典对象,用于配置 SecretFlow 的集群设置。在这个字典中,你需要定义参与方的信息。例如,对于参与者 “alice” 和 “bob”,你可以这样设置:
sf_cluster_config = {
'parties': {
'alice': {
# 替换为 Alice 实际的地址信息
'address': 'ip:port of alice',
'listen_addr': '0.0.0.0:port'
},
'bob': {
# 替换为 Bob 实际的地址信息
'address': 'ip:port of bob',
'listen_addr': '0.0.0.0:port'
}
},
'self_party': 'bob' # 设置当前参与方的身份,这里是 'bob'
}
请注意,需要替换实际的 IP 地址和端口号。
2. 创建一个名为 tls_config 的字典对象,用于配置 TLS/SSL 加密通信。在这个字典中,你需要指定 CA 根证书、服务器证书和私钥文件路径。例如:
tls_config = {
'ca_cert': 'ca root cert of other parties', # 替换为实际的 CA 根证书路径
'cert': 'server cert of alice in pem', # 替换为实际的服务器证书路径
'key': 'server key of alice in pem' # 替换为实际的服务器私钥路径
}
请注意,如果你是 Alice,则需要使用 Alice 的证书和私钥;如果你是 Bob,则需要使用 Bob 的证书和私钥。
3. 使用 SecretFlow 库的 init() 方法来初始化 SecretFlow。你需要提供 Ray 集群头节点的地址和上面创建的 cluster_config 和 tls_config 对象。例如,如果当前参与方是 Bob,则可以这样做:
import secretflow as sf
# 初始化 SecretFlow
sf.init(address='bob ray head node address', cluster_config=sf_cluster_config, tls_config=tls_config)
请将 “bob ray head node address” 替换为 Bob 的 Ray 头节点的实际地址。
同样地,如果当前参与方是 Alice,则应该将 “bob ray head node address” 替换为 Alice 的 Ray 头节点的实际地址。
3.启动SPU设备
- 定义一个名为
spu_cluster_def的字典对象,用于描述 SPU 节点的配置。这个字典应包含一个名为nodes的列表,其中包含了所有参与 SPU 计算的节点信息。例如:
spu_cluster_def = {
'nodes': [
{
'party': 'alice',
'address': '192.168.0.1:12945',
'listen_address': '0.0.0.0:12945'
},
{
'party': 'bob',
'address': '192.168.0.2:12946',
'listen_address': '0.0.0.0:12946'
}
],
'runtime_config': {
'protocol': spu.spu_pb2.SEMI2K,
'field': spu.spu_pb2.FM128,
}
}
在此示例中,有两个节点分别属于 Alice 和 Bob。你需要将 address 和 listen_address 替换成每个节点的实际 IP 地址和端口号。
- 使用 SecretFlow 框架中的
sf.SPU()函数来启动 SPU 设备。你需要将前面定义的spu_cluster_def字典传递给这个函数,如下所示:
spu = sf.SPU(spu_cluster_def)
这将在每个节点上启动 SPU 设备,并准备执行相应的计算任务。
需要注意的是,在实际使用时,你可能需要根据你的硬件环境和网络条件调整 address 和 listen_address 的值,以确保它们指向正确的 IP 地址和可用的端口号。同时,protocol 和 field 参数也需要根据你的特定需求进行选择和配置。
4.执行PSI并获取结果
1.使用 spu.psi_csv() 方法执行 PSI 协议
# 参数包括:
select_keys: # 需要选择的键列表。
input_path: # 输入数据的路径。
output_path: # 输出数据的路径。
receiver: # 接收输出文件的一方。
protocol: # PSI 协议类型,如 'ECDF_PSI_2PC' 或 'BC22_PSI_2PC'.
curve_type: # 曲线类型,如 'CURVE_25519'.
2.接收 PSI 结果
spu.psi_csv() 方法返回一个 reports 对象,它包含有关输入数据量总数和交集数量的信息。
可以通过 reports[‘original_count’] 和 reports[‘intersection_count’] 来获取这些信息。
输出文件的路径也可以通过 reports[‘output_path’] 获取。
3.获取交集结果
根据指定的接收者 (receiver),可以在对应的输出文件路径中找到交集结果。
例如,如果 receiver=‘alice’,则交集结果保存在 ‘data/psi_output.csv’ 中;如果 receiver=‘bob’,则保存在 ‘data/psi_output_bob.csv’’ 中。
通过执行 PSI,我们可以得到两个数据集之间的交集,同时保持数据的私有性。这使得两个组织能够在不泄露各自原始数据的情况下,发现共同感兴趣的项目或客户。这种技术对于合作分析、市场营销、风险评估等领域具有重要的应用价值。