前言:
Scrapy框架默认的事件驱动设计在某些场景下可能不够灵活或满足定制化需求。因此,深入研究Scrapy框架中的信号处理机制(Signals)是必要的。
本研究的目的是深入了解Scrapy框架中的信号处理机制,在网络爬虫中的应用和意义。通过研究Signals的设计原理和应用场景,我们可以更好地理解Scrapy框架的内部机制,提供更多的灵活性和可扩展性。同时,通过实例和案例分析,我们探讨了使用Signals实现各种高级功能和定制化的方法,进一步提升了Scrapy框架在实际应用中的价值和效果。
正文:
1.Signals的设计原理和概念
A. 信号的定义和作用
信号是一种在软件开发中常见的设计模式,用于在程序中传递和处理事件或消息。它是一种发布-订阅模式(Publish-Subscribe),其中有一个发布者(发送者)和一个或多个订阅者(接收者)。当发布者产生一个特定事件或条件时,它会发送一个信号,订阅者可以接收并对信号进行相应的处理。
在Scrapy框架中,信号被引入以处理各种事件,例如爬虫的启动和关闭、请求和响应的处理、数据提取和处理,甚至是异常的捕获和处理。通过使用信号处理机制,Scrapy允许开发者在适当的时候插入自定义的逻辑和处理代码,以便对这些事件进行响应和定制。
B. Scrapy中的信号机制简介
Scrapy中的信号机制(Signals)是一种事件驱动模型,它允许开发者对爬虫中的各个事件进行捕获和处理。Scrapy使用Twisted框架作为其底层网络引擎,而Twisted本身就提供了信号机制。Scrapy通过扩展Twisted中的信号机制,将其集成到框架中,从而实现了信号处理的功能。
Scrapy中定义了大量的信号,每个信号都与特定的事件相关联。例如,爬虫启动时会触发spider_opened信号,爬虫关闭时会触发spider_closed信号,而请求发送前和响应接收后则分别触发request_scheduled和response_received信号等。通过订阅这些信号,并为它们注册相应的处理函数,可以在对应的事件发生时执行自定义的逻辑和操作。
C. Signals的工作原理和流程
Signals的工作原理和流程可以总结为以下几个关键步骤:
-
信号的定义和注册: 在Scrapy框架中,每个信号都是作为一个独立的类属性进行定义的。这些信号的名称通常以“signal_”开头,然后是与事件相关的具体名称。例如,
spider_opened信号定义为signal_spider_opened。在注册信号之前,需要先通过装饰器@classmethod将信号属性转变为一个可以被订阅的描述符对象。 -
信号的订阅: 订阅信号意味着将一个处理函数与特定的信号关联起来。这个处理函数会在信号被触发时被调用。开发者可以通过在爬虫代码中使用装饰器
@receiver来订阅信号并注册处理函数。注册处理函数时,需要指定要订阅的信号和处理函数的关联。 -
信号的触发: 当一个与信号相关联的事件发生时,Scrapy会触发相应的信号。这意味着信号会被发送给所有订阅者,它们的处理函数将按照订阅的顺序被依次调用。发布信号时,Scrapy将提供与事件相关的一些参数或关键信息,以便处理函数进行处理。
-
信号处理函数的执行: 在信号处理函数被调用时,它们可以访问相关的事件数据和环境上下文,进而执行自定义的处理逻辑。处理函数可以根据信号被触发时所提供的参数,处理函数可以进行各种操作。例如,在爬虫启动时,可以使用爬虫名称和开始时间信息记录日志;在请求发送前,可以对请求进行修改或添加自定义的信息;在响应接收后,可以进行数据提取和处理,甚至可以对异常进行捕获和处理。
- 多个处理函数的执行顺序: 如果多个处理函数订阅了同一个信号,它们的执行顺序将按照注册的顺序进行。这意味着先注册的处理函数会先被调用,后注册的处理函数会后被调用。开发者可以通过控制处理函数的注册顺序来调整信号的处理流程。
-
通过信号机制,Scrapy提供了一个灵活且可扩展的方式来处理各种爬虫事件。它允许开发者根据实际需求,在适当的时候插入自定义的逻辑和操作。通过订阅和处理信号,开发者可以实现功能的定制化,优化爬虫工作流程,以及增加各种扩展功能。
小总结:
信号在Scrapy中是一种重要的设计原理和概念,通过使用信号机制,开发者可以响应和处理不同事件,实现灵活、可定制和可扩展的爬虫功能。
补:_signal的源码翻译

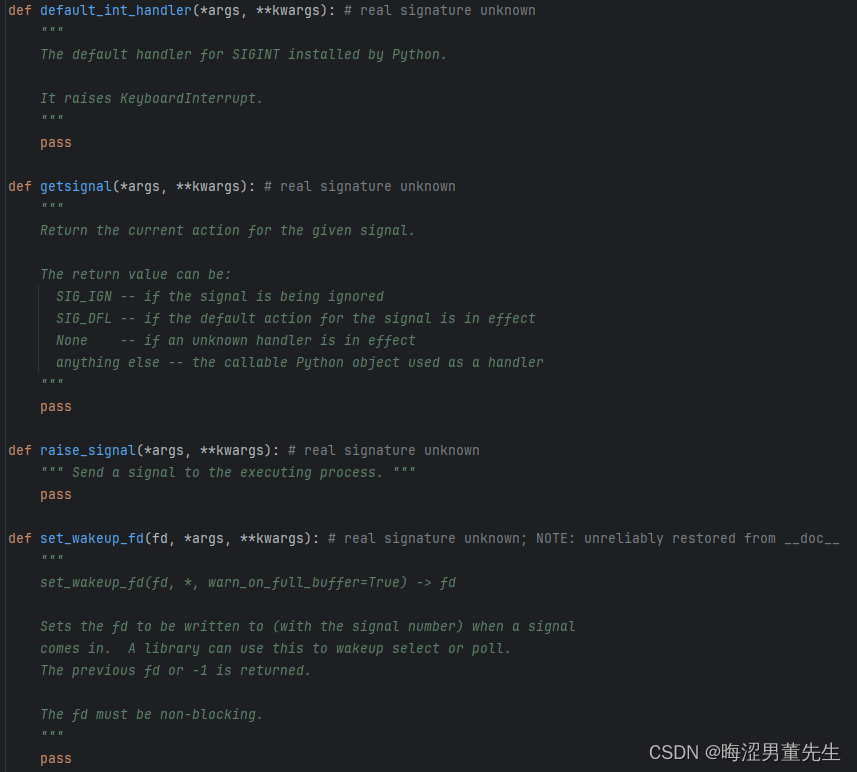
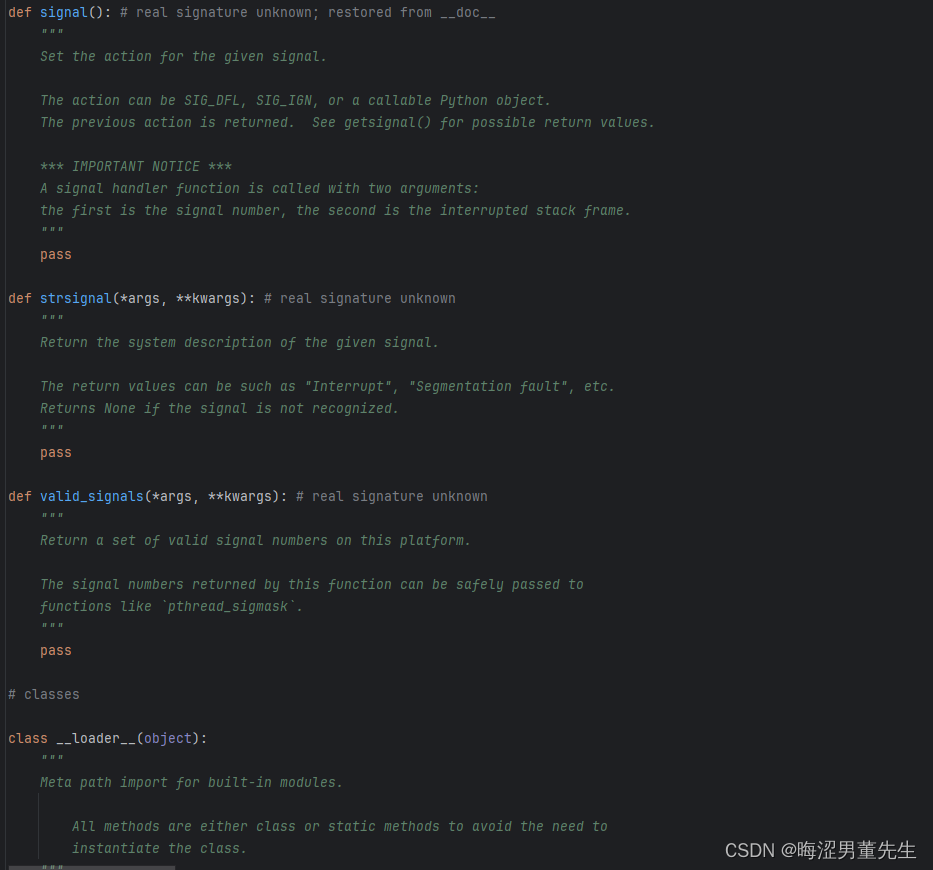
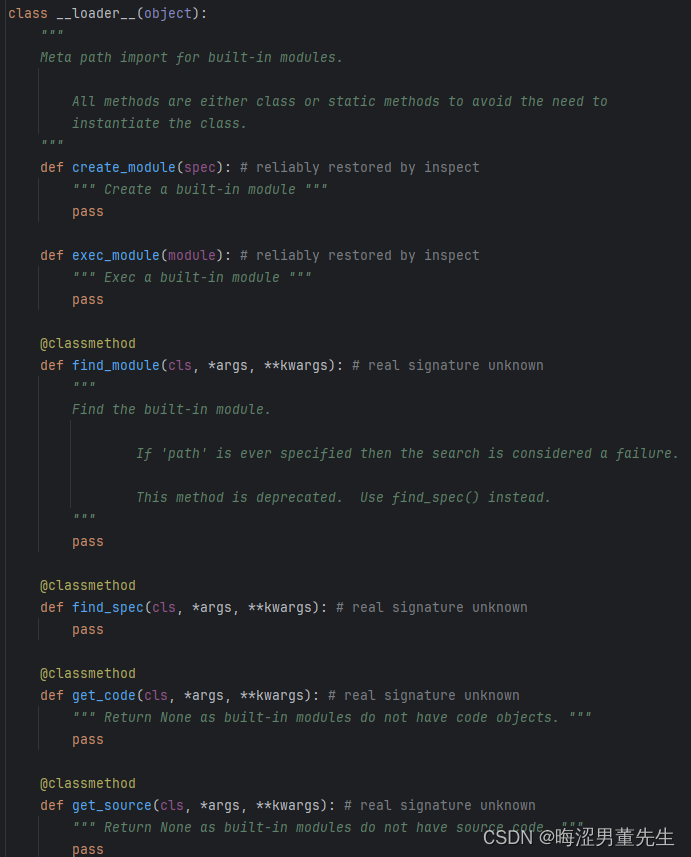
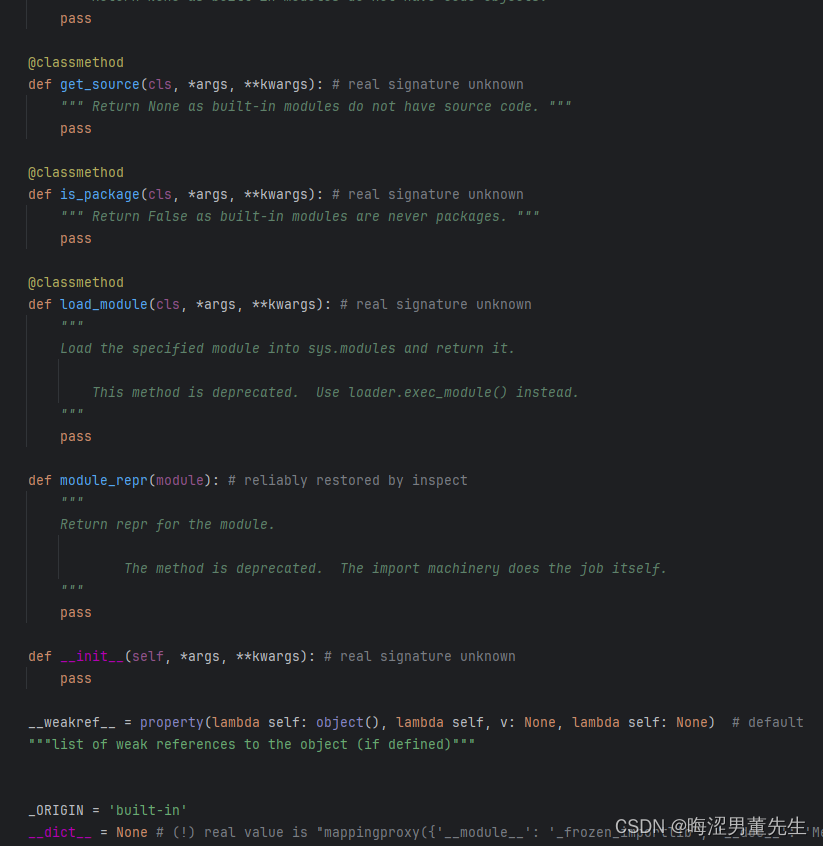
"""
这个模块提供了在Python中使用信号处理程序的机制。
函数:
alarm() -- 在指定的时间后引发SIGALRM [仅适用于Unix]
setitimer() -- 在指定的浮点时间后引发信号(稍后描述),定时器可以重新启动 [仅适用于Unix]
getitimer() -- 获取计时器的当前值 [仅适用于Unix]
signal() -- 设置给定信号的操作
getsignal() -- 获取给定信号的信号操作
pause() -- 等待信号到达 [仅适用于Unix]
default_int_handler() -- 默认的SIGINT处理程序
信号常量:
SIG_DFL -- 用于引用系统默认处理程序
SIG_IGN -- 用于忽略信号
NSIG -- 定义的信号数量
SIGINT,SIGTERM等 -- 信号编号
计时器常量:
ITIMER_REAL -- 实时递减,并在到期时发送SIGALRM
ITIMER_VIRTUAL -- 仅在进程执行时递减,
并在到期时发送SIGVTALRM
ITIMER_PROF -- 在进程执行和系统代表进程执行时均递减。
结合ITIMER_VIRTUAL,该计时器通常用于对
应用程序在用户空间和内核空间中花费的时间进行分析。
在到期时发送SIGPROF。
*** 重要通知 ***
信号处理程序函数被调用时有两个参数:
第一个参数是信号编号,第二个参数是中断的堆栈帧。
"""...后续自己可以看
2. Signals在Scrapy中的常见应用场景
Signals在Scrapy中提供了一种有效的方式来处理和响应各种爬虫事件,包括开始和结束信号处理、请求和响应信号处理、数据提取和处理信号处理以及异常处理信号处理。下面将详细介绍这些应用场景,并提供相应的代码和案例。
A. 开始和结束信号处理:
开始和结束信号处理是在爬虫的启动和结束时执行的处理函数。这些处理函数可以用于记录日志、发送通知、清理资源等操作。
Scrapy提供了两个主要的信号:spider_opened和spider_closed。
- 在
spider_opened信号被触发时,可以执行一些初始化操作,例如记录日志:
from scrapy import signals
def spider_opened(spider):
print(f"Spider {spider.name} started.")
# 在爬虫类中注册信号
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super().from_crawler(crawler, *args, **kwargs)
crawler.signals.connect(spider_opened, signal=signals.spider_opened)
return spider
- 在
spider_closed信号被触发时,可以进行资源清理等操作:
from scrapy import signals
def spider_closed(spider):
print(f"Spider {spider.name} closed.")
# 在爬虫类中注册信号
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super().from_crawler(crawler, *args, **kwargs)
crawler.signals.connect(spider_closed, signal=signals.spider_closed)
return spider
B. 请求和响应信号处理:
请求和响应信号处理允许开发者在请求发送前和响应接收后执行一些操作,例如修改请求、提取响应数据、记录日志等。
Scrapy提供了两个常见的信号:request_scheduled和response_received。
- 在
request_scheduled信号被触发时,可以修改请求或添加自定义信息:
from scrapy import signals
def modify_request(request):
request.headers.update({'User-Agent': 'Mozilla/5.0'})
return request
# 在爬虫类中注册信号
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super().from_crawler(crawler, *args, **kwargs)
crawler.signals.connect(modify_request, signal=signals.request_scheduled)
return spider
- 在
response_received信号被触发时,可以进行页面数据提取和处理:
from scrapy import signals
def process_response(response, spider):
# 处理响应
data = response.xpath('//div/text()').get()
print(data)
# 在爬虫类中注册信号
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super().from_crawler(crawler, *args, **kwargs)
crawler.signals.connect(process_response, signal=signals.response_received)
return spider
C. 数据提取和处理信号处理:
数据提取和处理信号处理允许在爬虫提取数据后进行额外的处理操作,例如保存数据、进行数据清洗、存储到数据库等。
Scrapy提供了item_scraped信号,它在每次处理提取的数据时触发。
在爬虫类中定义处理函数,进行数据处理操作:
from scrapy import signals
def save_data(sender, item, response, spider):
# 保存数据到持久化存储
# ...
# 在爬虫类中注册信号
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super().from_crawler(crawler, *args, **kwargs)
crawler.signals.connect(save_data, signal=signals.item_scraped)
return spider
D. 异常处理信号处理:
异常处理信号处理能够捕获并处理Scrapy中的各种异常情况,例如超时、连接错误等,在出现异常时执行相应的操作,如重新发送请求、记录异常日志等。
Scrapy提供了spider_error信号,在异常发生时触发。
定义异常处理函数,例如重新发送请求:
from scrapy import signals
def retry_request(failure, spider):
# 发生异常,重新发送请求
request = failure.request.copy()
request.meta['retry_times'] = request.meta.get('retry_times', 0) + 1
return request
# 在爬虫类中注册信号
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super().from_crawler(crawler, *args, **kwargs)
crawler.signals.connect(retry_request, signal=signals.spider_error)
return spider
通过上述代码和示例,我们可以看到在Scrapy中信号的灵活性和强大功能。通过订阅和处理信号,我们可以对爬虫的不同阶段进行处理和操作,从而实现定制化的功能、自定义的流程以及增加各种扩展功能。
总结:
本篇主要讲Scrapy框架中信号处理机制的设计原理、概念和应用场景。信号机制是一种发布-订阅模式,用于在程序中传递和处理事件或消息。在Scrapy中,通过信号处理机制可以对爬虫中的各种事件进行捕获和处理,如开始和结束信号处理、请求和响应信号处理、数据提取和处理信号处理以及异常处理信号处理。
每个信号与特定的事件相关联,Scrapy定义了大量信号供开发者使用。多个处理函数的执行顺序按注册顺序进行。
在开始和结束信号处理中,可以进行初始化操作和资源清理等。请求和响应信号处理允许对请求和响应进行修改和处理。数据提取和处理信号处理可用于保存数据和进行数据清洗等。异常处理信号处理能够捕获并处理各种异常情况,如重新发送请求。
总结来说,通过使用信号处理机制,Scrapy提供了灵活、可定制和可扩展的爬虫功能。大家可以根据不同的事件进行处理和操作,实现定制化的功能和自定义的流程,增加各种扩展功能。使用信号机制可以更好地理解Scrapy框架的内部机制,提供更多的灵活性和可扩展性。