声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
神经网络优化算法NNA:
基于强化学习的神经网络优化算法RLNNA:
改进点1:基于强化学习的修正因子
改进点2:基于历史种群的迁移算子
改进点3:设计的反馈算子
改进算法框架图与伪代码:
效果展示
参考文献
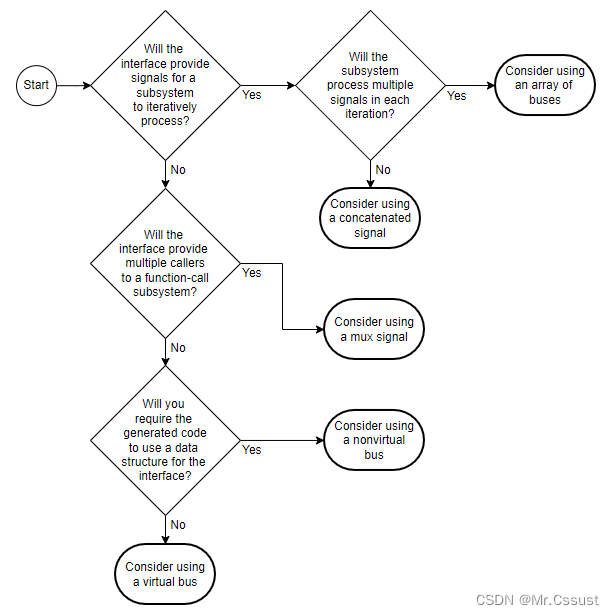
部分代码展示与程序目录
完整代码获取
应小伙伴要求,今天为大家带来一期在2023年SCI一区顶刊上的算法改进:基于强化学习的神经网络优化算法代码与原理讲解,非常新颖!相信大家也从来没见过,效果不错!
注意!这里的神经网络并不是传统意义上的神经网络,而是一种优化算法,大家可以类比为动物园优化算法,只是这位作者借用了神经网络的思想取名为神经网络优化算法(NNA),其本质上还是随机搜索的群智能优化算法,有点唬人!

神经网络优化算法NNA:
首先介绍一下原始的神经网络优化算法NNA!
神经网络算法灵感来自于生物神经系统的结构。一般来说,人工神经网络用于预测目的,它试图通过频繁改变权值来减小预测解与目标解之间的差距。然而,解决优化问题就是从给定的搜索空间中找到目标解。为了使人工神经网络适合作为一种优化技术,NNA的作者首先将当前最优解作为目标解。然后,通过调整每个神经细胞的权重值来获得更好的解。
NNA的结构由以下四个阶段组成:
(1)生成种群:

(2)更新权重矩阵:

(3)产生偏置:分别使用偏置算子和转移算子来进行勘探和开发。采用修正因子βt来分配勘探开发时间。



(4)转移算子:围绕当前搜索空间找到更好的解决方案。


![]()
此处就不再讲解原始神经网络算法的细节,具体内容大家可以查看原始文献!参考文献放在下面了!
Ali Sadollah, Hassan Sayyaadi, Anupam Yadav (2018).A dynamic metaheuristic optimization model inspired by biological nervous systems: Neural network algorithm, Applied Soft Computing, 71, pp. 747-782.
基于强化学习的神经网络优化算法RLNNA:
强化学习是机器学习的一个非常重要的分支,并与元启发式相结合在许多领域得到了应用。RL系统通常由五个部分组成:一个环境,一个学习代理,一组离散的环境状态,一组离散的代理行为和一个奖励分配机制。RL可以描述如下。首先,agent在时间t接收到状态和奖励,然后基于收到的奖励和状态,agent将采取行动。最后,随着行动的执行,环境将发生变化,这将在时间t + 1产生新的奖励和状态。根据RL的工作原理,RL的主要优点可归纳为以下几点:
1)强化学习只需要很少的环境信息,适合于复杂的任务。
2)强化学习的学习过程是在线的,可以直接与环境进行交互。
3) RL通过简单的奖励函数来评价得到的解的质量,而不是复杂的数学运算,可以提高计算效率。
废话不多说,直接来看一下是如何改进的!
改进点1:基于强化学习的修正因子
针对NNA中修正因子生成方法的不足,提出了一种基于RL的修正因子调整方法。该方法的基本思想可以表述为:如果一个个体能够在一个循环中找到更好的解,那么它就具有一些寻找全局最优解的有益信息,可以称为优秀个体。也就是说,为了不错过更好的解,优秀个体在自身周围执行搜索算子(即局部开发)是一个不错的选择。根据这一思想,RL的设计规则是基于得到的一个回路中每个个体的两个适应度值,定义为:

其中βti是第I个个体在时间t时的修正因子,τ是惩罚因子,h(x)和s(x)是两个差分函数,g(x)是控制函数。h(x)、s(x)、g(x)可以表示为(以最小问题为例):

其中,ft1为第I个个体在时刻t的适应度值,f(t+1)i,1为第i个个体在时刻t+1的适应度值。f(t+1)i,2是第i个个体在t+1时刻通过第二次函数评估得到的适应度值。根据公式(30),有两种候选动作,即保持动作和激活动作。对于一个个体,如果触发“keep action”,则该个体使用与上次迭代相同的修改因子来完成下一个搜索;如果触发了“activate action”,则该个体使用一个新的修改因子来执行下一个搜索。由(28)-(30)可知,当一个个体是RLNNA中的优秀个体时,会触发“激活动作”,其在下一次迭代中的修改因子会更小,这意味着它在下一次迭代中有更多的机会执行转移算子(即利用)。所设计的修正因子更新方法如下图所示。

改进点2:基于历史种群的迁移算子
如前所述,NNA的迁移算子仅以当前最优解为指导,这是增加NNA陷入局部极小的可能性的潜在风险。为了在一定程度上避免这种风险,我们引入历史种群信息来传递算子。在RLNNA中,传递算子包括一个当前传递项和一个历史传递项,可以表示为:

式中,κ1和κ2为两个标准正态分布的随机数,xt(old),i为历史种群xt old在时间t的第i个个体。Xt(old)由下式更新:

式中λ5为0 ~ 1之间均匀分布的随机数。那么,xt(old)的最终形式为:

其中φ(·)是一个排列函数,这意味着Xt old中的向量是随机排序的。
最后,基于贪婪策略完成更新:

与NNA的转移算子相比,RLNNA中的转移算子的优势可以概括为:
一方面,在迁移算子中引入历史种群,如(31)所示,迁移算子在搜索过程中起两个作用。首先,它可以增加种群多样性,从而在一定程度上降低过早收敛的风险。其次,在式(31)中,xt Best - xt,i和xt Best - xt old,i可以看作是两个微分向量。根据(32)和式(33)所示的Xt old的生成机制,更有可能的情况是|Xt Best - Xt old,i|大于|Xt Best - Xt,i|,这意味着所设计的传递算子比NNA具有更大的搜索空间。
另一方面,原始随机数是0 ~ 1之间的均匀分布,而改进的随机数κ1和κ2 in(31)服从标准正态分布。显然,标准正态分布产生的随机数比均匀分布产生的随机数具有更大的波动性。因此,(31)中的随机数κ1和κ2非常有助于RLNNA增加其搜索空间,增强其逃避局部最优的能力。
改进点3:设计的反馈算子
为了克服NNA收敛缓慢的缺点,我们设计了一个反馈算子,它是由偏置算子或传递算子对得到的试验种群Vt的进一步优化,可以表示为:

与迁移算子一样,在完成反馈算子步骤之后,执行贪婪选择策略,即:

公式(35)中,κ3、κ4为两个标准正态分布的随机数,m为1 ~ N之间的随机整数,f ~ m为第m个个体的适应度值。另外,m不等于i。由(35)可知,所设计的反馈算子具有以下两个优点:
一方面,它不仅考虑了当前反馈,还考虑了局部反馈。在当前反馈项中,vti从随机选择的vtm中学习,历史反馈项以历史种群为指导。需要注意的是,由于f (xt old,i)和f (vt i)之间存在不确定性关系,历史反馈项也可以称为随机扰动项。因此,所设计的反馈算子具有较强的随机性,有利于增加种群多样性。
另一方面,κ3和κ4也服从标准正态分布,其作用与κ1和κ2公式(31)相同。
改进算法框架图与伪代码:
为了使大家更好地理解,这边给出算法框架和伪代码,非常清晰!


如果实在看不懂,不用担心,可以看下代码,再结合上文公式理解就一目了然了!
效果展示
为了方便大家比较,这里采用经典的23个标准测试函数,也就是CEC2005与原始神经网络优化算法NNA进行对比!其他的大家可以回去慢慢试!效果都很好!











以上截的11个测试函数的图,可以看到,RLNNA在大部分函数上均远远超过原始的神经网络算法NNA,仅有一两个算法不如原算法,存在很明显的差距,大家应用到回归、分类、时序预测模型(如RLNNA-SVM)或应用到信号分解故障诊断领域都是一个不错的选择!
以上所有图片,均可一键运行main文件即可出图!!(其中测试函数图像仅需手动切换函数)
适用平台:Matlab(暂无版本限制)
参考文献
[1]Zhang Y. Neural network algorithm with reinforcement learning for parameters extraction of photovoltaic models[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 34(6): 2806-2816.
部分代码展示与程序目录
clear
clc
close
SearchAgents=30; % 种群数量
Function_name='F7'; % 函数名称
Max_iterations=1000; % 最大迭代次数
[lb,ub,dim,fobj]=Get_Functions_details(Function_name);
[Best_RLNNAs,Best_score,~,NNA_curve]=NNA(SearchAgents,Max_iterations,lb,ub,dim,fobj); % 调用NNA算法
[Alpha_RLNNAs,Alpha_score,RLNNA_curve]=RLNNA(SearchAgents,Max_iterations,lb,ub,dim,fobj); % 调用RLNNA算法
figure('Position',[290 206 648 287])
%Draw the search space
subplot(1,2,1);
func_plot(Function_name);
title('Test function')
xlabel('x_1');
ylabel('x_2');
zlabel([Function_name,'( x_1 , x_2 )'])
grid off
完整代码获取
如果需要免费获得图中的完整测试代码,只需点击下方小卡片,后台回复关键字:
RLNNA
也可点击小卡片,后台回复个人需求(比如RLNNA-SVM)定制此改进算法RLNNA优化模型(看到秒回):
1.回归/时序/分类预测类:SVM、RVM、LSSVM、ELM、KELM、HKELM、DELM、RELM、DHKELM、RF、LSTM、BiLSTM、GRU、BiGRU、PNN、CNN、BP、XGBoost、TCN、BiTCN、ESN等等均可~
2.组合预测类:CNN/TCN/BiTCN/DBN/Adaboost结合SVM/RVM/ELM/LSTM/BiLSTM/GRU/BiGRU/Attention机制类等均可(可任意搭配非常新颖)~
3.分解类:EMD、EEMD、VMD、REMD、FEEMD、CEEMDAN、ICEEMDAN、SVMD等分解模型均可~
4.其他:机器人路径规划、无人机三维路径规划、DBSCAN聚类、VRPTW路径优化、微电网优化、无线传感器覆盖优化、故障诊断等等均可~
5.原创改进优化算法(适合需要创新的同学):2024年的新算法CPO等或麻雀SSA、蜣螂DBO等任意优化算法均可,保证测试函数效果!
更多代码链接:更多代码链接



![[flask]异常抛出和捕获异常](https://img-blog.csdnimg.cn/direct/b52f1ea9c6344737bec4786a080362be.png)