生命周期
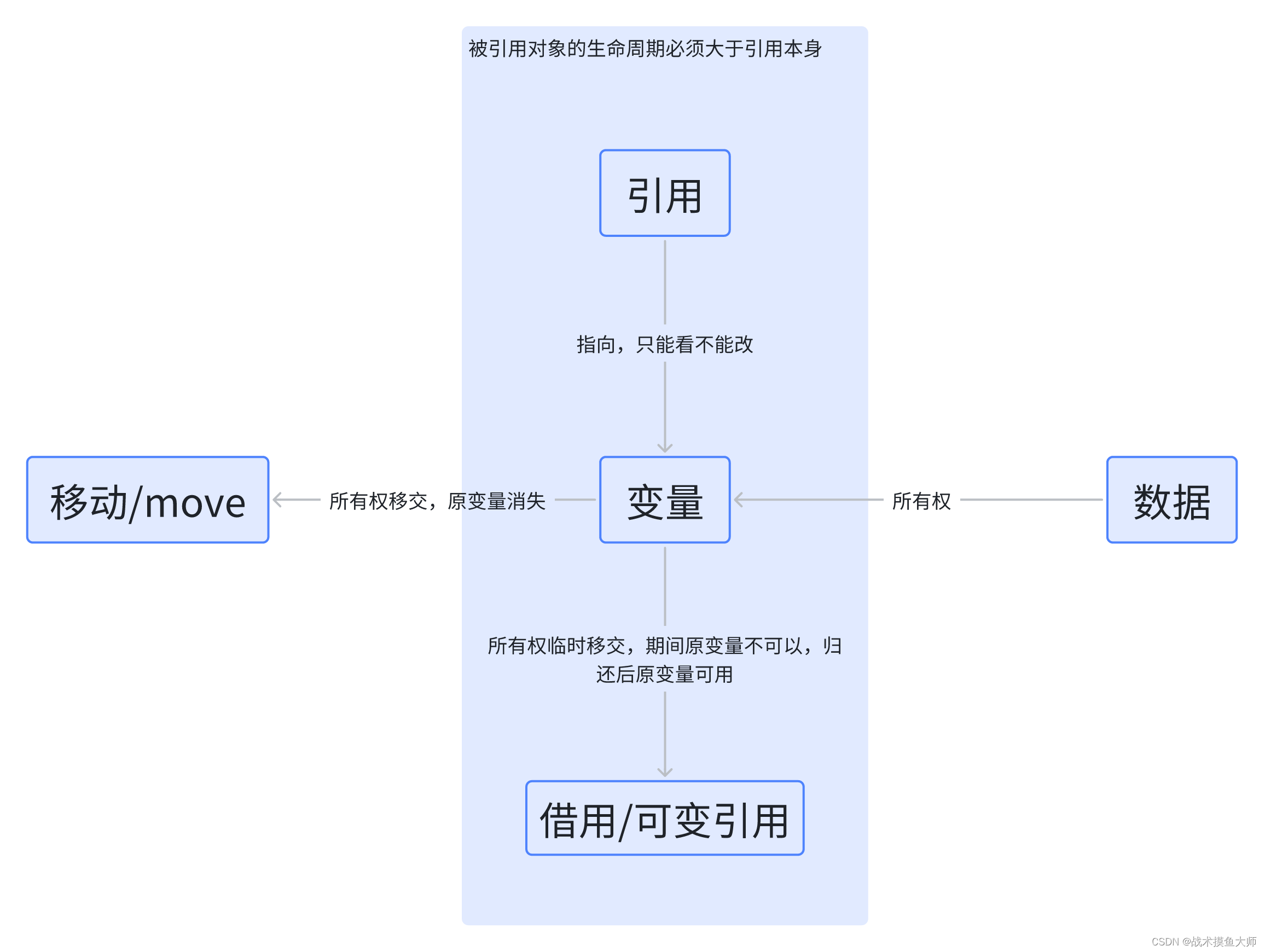
生命周期,简而言之就是引用的有效作用域。在大多数时候,我们无需手动的声明生命周期,因为编译器可以自动进行推导。生命周期的主要作用是避免悬垂引用,它会导致程序引用了本不该引用的数据:
{
let r;
{
let x = 5;
r = &x;
}
println!("R:{}",r);
}
这种情况r就是悬垂指针,r是引用的x,但是x的生命周期是到大括号结束就结束了,所以下面再使用r时,r就是一个悬垂指针。避免悬垂指针的方法就是:确保被引用的变量的生命周期长于引用本身。
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
//会报错,因为编译器不知道返回是x还是y,自然就没法对result进行生命周期分析
println!("The longest string is {}", result);
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
对于一些复杂情况,编译器无法自己推导出生命周期,就需要我们自己进行生命周期标注:
&i32 // 一个引用
&'a i32 // 具有显式生命周期的引用
&'a mut i32 // 具有显式生命周期的可变引用
生命周期标注不对代码的逻辑起到任何作用,它自身并不具有什么意义,因为生命周期的作用就是告诉编译器多个引用之间的关系。
标注后的longest函数:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
//这里告诉编译器,x和y的生命周期要长于`a
//然后将二者的生命周期统一设定为较短的那个的生命周期
//这样就不管是返回x还是y,result的生命周期都是一样的
if x.len() > y.len() {
x
} else {
y
}
}
当只与一个参数有关时,可以只标注一个的生命周期:
fn function<'a>(arg1:&'a mut String,arg2:& mut String) -> &'a mut String{
return arg1;
}
fn main(){
let mut s1 : String = String::new();
let mut s2 : String = String::new();
let s3 = function(&mut s1,&mut s2);
println!("s3:{}",s3);
}
生命周期问题只针对于引用,主要是为了解决引用/借用还在,被引用/借用的没了的情况,对于move就没有这么麻烦,一旦move,直接生命周期就重新计算了,与之前的变量就没关系了。
结构体也有生命周期的要求,结构体内部有引用,被引用的对象的生命周期要长于结构体对象的生命周期:
struct ImportantExcerpt<'a> {
part: &'a str,
}
fn main() {
let novel1 = String::from("Call me Ishmael. Some years ago...");
let first_sentence1 = novel1.split('.').next().expect("Could not find a '.'");
let i = ImportantExcerpt {
part: first_sentence1,
}; //这种没有问题
let i;
{
let novel2 = String::from("Call me Ishmael. Some years ago...");
let first_sentence2 = novel2.split('.').next().expect("Could not find a '.'");
i = ImportantExcerpt {
part: first_sentence2,
};
}
println!("{:?}",i); //这种就会报错,因为first_sentence2在大括号结束的时候生命周期已经结束了
}
函数情况下分为输入生命周期和输出生命周期,一些编译器可以推断出输入输出生命周期的情况,就不需要进行生命周期标注,编译器推断生命周期有三个规则:
-
每一个引用参数都会获得独自的生命周期
例如一个引用参数的函数就有一个生命周期标注: fn foo<'a>(x: &'a i32),两个引用参数的有两个生命周期标注:fn foo<'a, 'b>(x: &'a i32, y: &'b i32), 依此类推。 -
若只有一个输入生命周期(函数参数中只有一个引用类型),那么该生命周期会被赋给所有的输出生命周期,也就是所有返回值的生命周期都等于该输入生命周期
-
例如函数 fn foo(x: &i32) -> &i32,x 参数的生命周期会被自动赋给返回值 &i32,因此该函数等同于 fn foo<'a>(x: &'a i32) -> &'a i32
-
若存在多个输入生命周期,且其中一个是 &self 或 &mut self,则 &self 的生命周期被赋给所有的输出生命周期。拥有 &self 形式的参数,说明该函数是一个 方法,该规则让方法的使用便利度大幅提升。
更多关于生命周期的内容,请参考
函数返回/异常处理
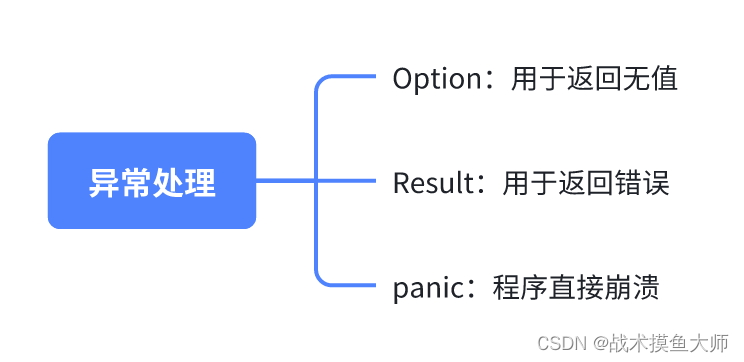
Rust的函数返回为了解决是否有值的问题,引入了一个枚举类型Option,有值时返回Some(T),没值时返回None,再也不用绞尽脑汁如何思考返回-1或者None了。
enum Option<T> {
Some(T),
None,
}
Rust的异常分为可恢复异常Result,出了异常不直接崩溃,还可以根据异常的类别继续运行,类似于其他语言中函数返回了-1或者None。另一种是不可恢复异常panic,出了问题直接崩溃,类似于其他语言中的assert。
Result<T,E>
对应可以挽救的error,Result是一个枚举类型
enum Result<T, E> {
Ok(T),
Err(E),
}
使用案例:
fn plus_one(x: Option<i32>) -> Option<i32> {
match x { //match就类似于C里面的switch语句
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
当函数正常运行时,返回Ok包裹着的返回结果,当函数运行失败时,返回Err包裹的错误类型,
一般使用Result的工作流程就是:函数返回一个Result,然后使用match匹配结果:
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let f = File::open("hello.txt");
let f = match f {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {:?}", e),
},
other_error => panic!("Problem opening the file: {:?}", other_error),
},
};
}
Result也可以通过unwrap或者except转换为panic:
use std::fs::File;
fn main() {
let f = File::open("hello.txt").unwrap();
//不出问题就提取出来返回结果,出问题就直接panic
let f = File::open("hello.txt").expect("Failed to open hello.txt");
//跟上面一样的效果,不过会报错自定义的错误提示
}
panic
对应不可恢复error,出现panic代码直接崩溃
fn main() {
panic!("crash and burn");
}
更多关于panic的请看Rust圣经