忍不住
- 我才是最大的缺陷
- 首先应该学好表达
- 头脑风暴
- 分割
- paddledetection小目标检测也不行
- 缺陷检测
- 1.缺陷标注
- 修改代码为自己的数据集
- 训练
- 训练结果
- 结果图片
- 结论
- 再次出发
我才是最大的缺陷
真的,我真的被整无语了。测测测测,测个鬼。一天天的净整些没用的。

首先应该学好表达
客户有个需求(缺陷检测)+数据(4个图片)-BD需求(缺陷检测)+数据(4个图片)-技术??????????????
1.什么是缺陷?
2.4个图片你确定是给我做测试,而不是让我写ppt?
经过一周的反馈和交流后
客户有个需求(缺陷检测)+数据(2T数据)-BD需求(缺陷检测)+数据(2T数据)-技术??????????????
直到现在我还是一头雾水。
头脑风暴
1.目标检测
2.缺陷检测
前提都是要分割图片,因为客户提供的是2000万像素的图片。然后检测的缺陷大概是50个像素
如果类比到我们常用的512*512的图片,大概就是0.65536。 一个像素都不到。真棒。
分割
这里提一下,参考paddledetection的小目标检测。
使用了sahi,但是他们提供的代码,需要先使用labelme标注,然后转成coco格式。最后在分割。
但是: 没有分割后的图片???
修改代码 slicing.py 中的320行
image_pil.save(slice_file_path, quality=100)
如果我不想标注,我就想分割图片呢
import os
from sahi.slicing import slice_image
img_path=r'G:\sick\ic\NG\2_NG_G7P3900905EA'
output_images_dir=r'G:\sick\ic\NG\split'
image_names=os.listdir(img_path)
for image_name in image_names:
image_dir=os.path.join(img_path,image_name)
slice_image(image=image_dir,
output_file_name=image_name,
output_dir=output_images_dir,
slice_height=640,
slice_width=640,
min_area_ratio=0.1,
overlap_height_ratio=0.25,
overlap_width_ratio=0.25,
out_ext=".jpg",
verbose=False,
)
paddledetection小目标检测也不行
不管是yolov几都不行,目标太小了。而且缺陷不是固定形状的。本身标注就很难
缺陷检测
“Mixed supervision for surface-defect detection: from weakly to fully supervised learning”
因为之前有人给我推荐这个论文,缺陷检测效果很好。
所以就去训练了。
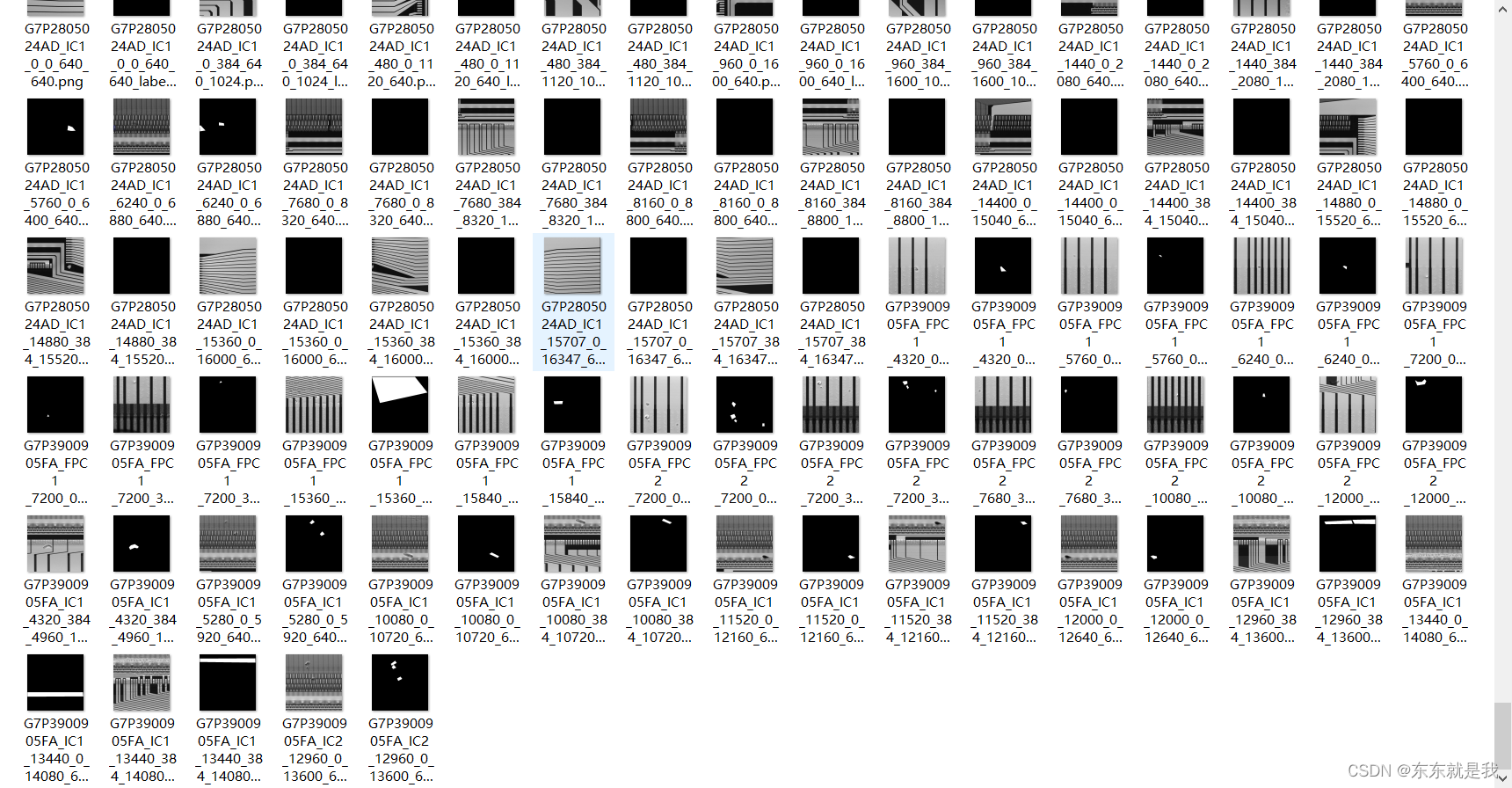
训练的图片大概就是这样


1.缺陷标注
还是使用labelme标注,标注好以后,需要转为一个mask图片
这个是吧有缺陷的图片转化一个mask作为标签
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import imgviz
import numpy as np
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("--input_dir", default=r"G:\sick\ic\mixed-segdec-net-comind2021-master\cocome\dota_sliced\json", help="input annotated directory")
parser.add_argument("--output_dir", default=r"G:\sick\ic\mixed-segdec-net-comind2021-master\cocome\dota_sliced", help="output dataset directory")
parser.add_argument("--labels", default=r"G:\sick\ic\mixed-segdec-net-comind2021-master\zw\class_names.txt", help="labels file")
args = parser.parse_args()
args.noviz = False
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_lbl_file = osp.join(
args.output_dir, "SegmentationClass", base + ".npy"
)
out_png_file = osp.join(
args.output_dir, "SegmentationClassPNG", base + ".png"
)
if not args.noviz:
out_viz_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
with open(out_img_file, "wb") as f:
f.write(label_file.imageData)
img = labelme.utils.img_data_to_arr(label_file.imageData)
lbl, _ = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
labelme.utils.lblsave(out_png_file, lbl)
np.save(out_lbl_file, lbl)
if not args.noviz:
viz = imgviz.label2rgb(
lbl,
img,
font_size=15,
label_names=class_names,
loc="rb",
)
imgviz.io.imsave(out_viz_file, viz)
if __name__ == "__main__":
main()

如果是没有缺陷的图片呢
import cv2
import os
import numpy as np
import os.path as osp
file_path=r'G:\sick\ic\mixed-segdec-net-comind2021-master\datasets\tem'
file_name=os.listdir(file_path)
for name in file_name:
if name.endswith('.png'):
img_path=os.path.join(file_path,name)
img=cv2.imread(img_path,0)
mask=np.zeros_like(img)
tem=osp.splitext(img_path)[0]+'_label.png'
# print(1)
cv2.imwrite(tem,mask)

最后把所有的图片放在一个文件夹下
修改代码为自己的数据集
在data中增加一个文件,叫做input_myself.py
import numpy as np
import os
from data.dataset import Dataset
from config import Config
class MyselfDataset(Dataset):
def __init__(self, kind: str, cfg: Config):
super(MyselfDataset, self).__init__(cfg.DATASET_PATH, cfg, kind)
self.read_contents()
def read_contents(self):
pos_samples, neg_samples = [], []
for sample in sorted(os.listdir(self.path)):
if not sample.__contains__('label'):
image_path = self.path + sample
seg_mask_path = f"{image_path[:-4]}_label.png"
image = self.read_img_resize(image_path, self.grayscale, self.image_size)
seg_mask, positive = self.read_label_resize(seg_mask_path, self.image_size, dilate=self.cfg.DILATE)
sample_name = f"{sample}"[:-4]
if positive:
image = self.to_tensor(image)
seg_loss_mask = self.distance_transform(seg_mask, self.cfg.WEIGHTED_SEG_LOSS_MAX, self.cfg.WEIGHTED_SEG_LOSS_P)
seg_loss_mask = self.to_tensor(self.downsize(seg_loss_mask))
seg_mask = self.to_tensor(self.downsize(seg_mask))
pos_samples.append((image, seg_mask, seg_loss_mask, True, image_path, seg_mask_path, sample_name))
else:
image = self.to_tensor(image)
seg_loss_mask = self.to_tensor(self.downsize(np.ones_like(seg_mask)))
seg_mask = self.to_tensor(self.downsize(seg_mask))
neg_samples.append((image, seg_mask, seg_loss_mask, True, image_path, seg_mask_path, sample_name))
self.pos_samples = pos_samples
self.neg_samples = neg_samples
self.num_pos = len(pos_samples)
self.num_neg = len(neg_samples)
self.len = 2 * len(pos_samples) if self.kind in ['TRAIN'] else len(pos_samples) + len(neg_samples)
self.init_extra()
修改dataset_catalog.py
from .input_ksdd import KSDDDataset
from .input_dagm import DagmDataset
from .input_steel import SteelDataset
from .input_ksdd2 import KSDD2Dataset
from .input_myself import MyselfDataset
from config import Config
from torch.utils.data import DataLoader
from typing import Optional
def get_dataset(kind: str, cfg: Config) -> Optional[DataLoader]:
if kind == "VAL" and not cfg.VALIDATE:
return None
if kind == "VAL" and cfg.VALIDATE_ON_TEST:
kind = "TEST"
if cfg.DATASET == "KSDD":
ds = KSDDDataset(kind, cfg)
elif cfg.DATASET == "DAGM":
ds = DagmDataset(kind, cfg)
elif cfg.DATASET == "STEEL":
ds = SteelDataset(kind, cfg)
elif cfg.DATASET == "KSDD2":
ds = KSDD2Dataset(kind, cfg)
elif cfg.DATASET == "myself":
ds = MyselfDataset(kind, cfg)
else:
raise Exception(f"Unknown dataset {cfg.DATASET}")
shuffle = kind == "TRAIN"
batch_size = cfg.BATCH_SIZE if kind == "TRAIN" else 1
num_workers = 0
drop_last = kind == "TRAIN"
pin_memory = False
return DataLoader(dataset=ds, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers, drop_last=drop_last, pin_memory=pin_memory)
训练
执行python train_net.py 增加参数如下
--GPU=0
--DATASET=myself
--RUN_NAME=RUN_NAME
--DATASET_PATH=datasets/yc/
--RESULTS_PATH=save/results
--SAVE_IMAGES=True
--DILATE=7
--EPOCHS=50
--LEARNING_RATE=1.0
--DELTA_CLS_LOSS=0.01
--BATCH_SIZE=1
--WEIGHTED_SEG_LOSS=True
--WEIGHTED_SEG_LOSS_P=2
--WEIGHTED_SEG_LOSS_MAX=1
--DYN_BALANCED_LOSS=True
--GRADIENT_ADJUSTMENT=True
--FREQUENCY_SAMPLING=True
--TRAIN_NUM=538
--NUM_SEGMENTED=538
--FOLD=0
训练结果
执行python join_folds_results.py 参数如下
--RUN_NAME=RUN_NAME
--RESULTS_PATH=save/results
--DATASET=myself
E:\miniconda\envs\hikvision\python.exe G:\sick\ic\mixed-segdec-net-comind2021-master\join_folds_results.py --RUN_NAME=RUN_NAME --RESULTS_PATH=save/results --DATASET=myself
Running evaluation for RUN save/results\myself\RUN_NAME
RUN RUN_NAME: AP:1.00000, AUC:1.00000, FP=0, FN=0, FN@.5=1, FP@.5=0, FP@FN0=0
结果图片
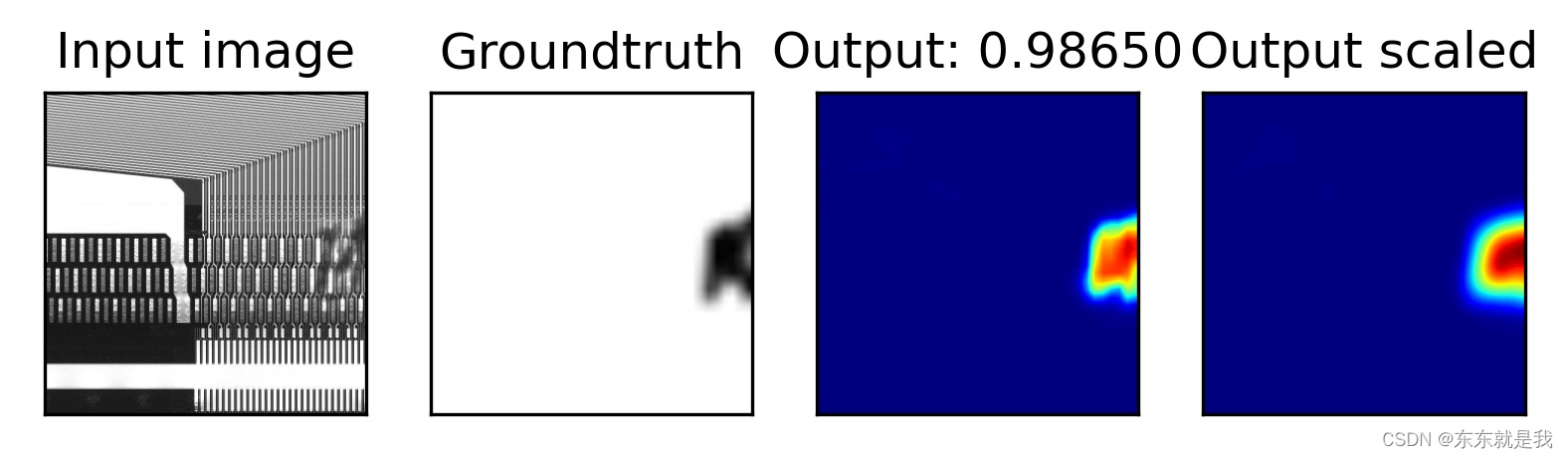
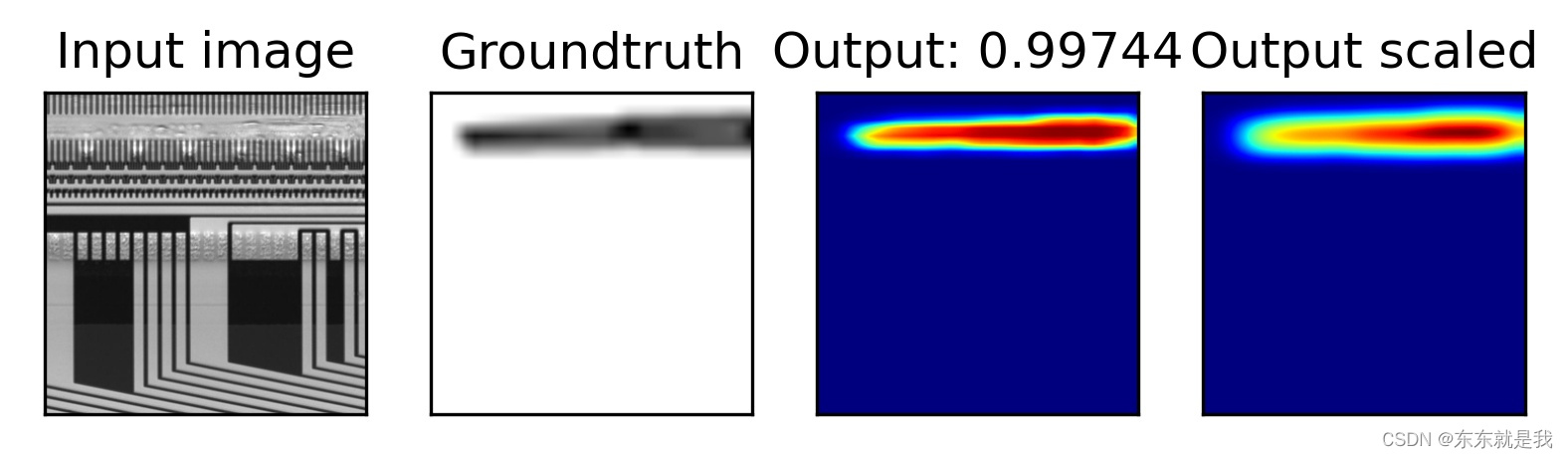
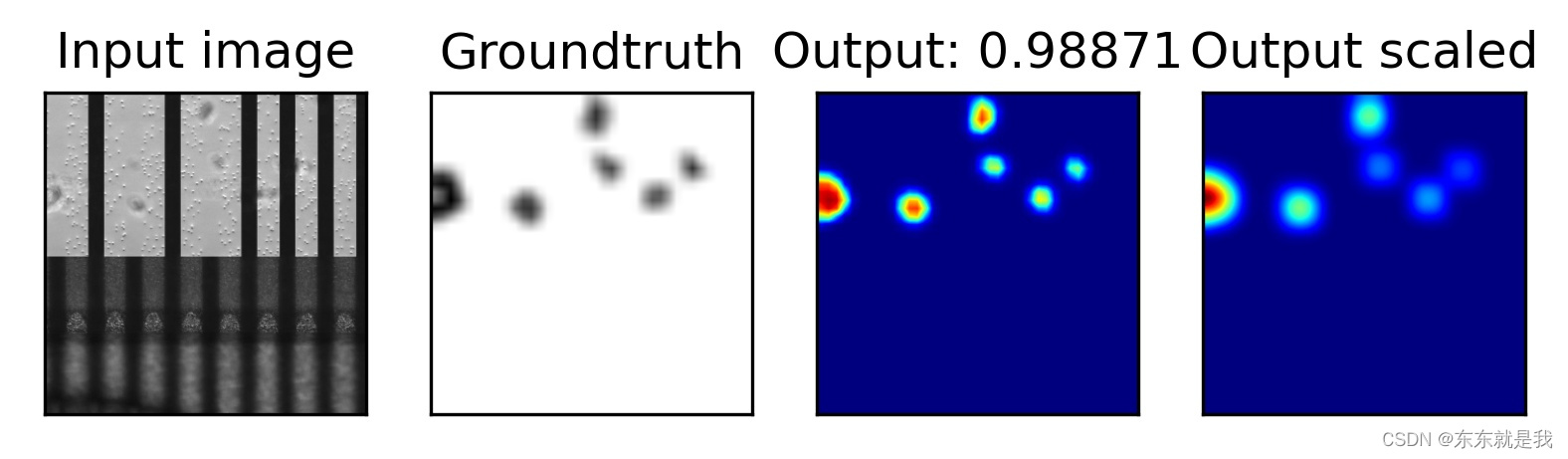
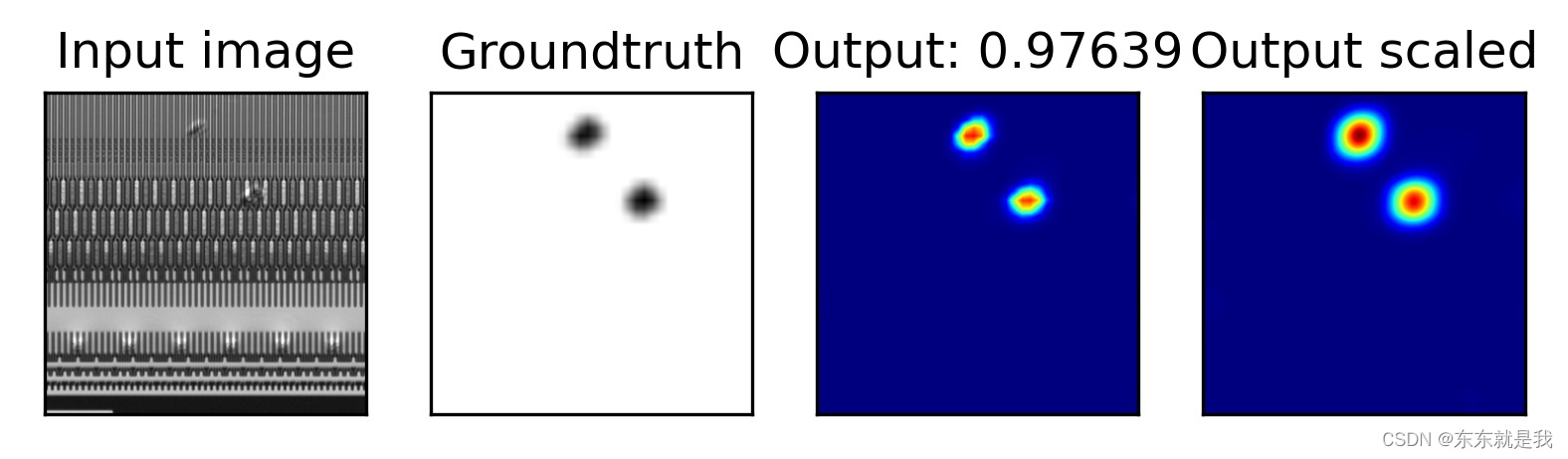
效果是不是炸裂
结论
最后我又弄个新的图片去测试模型的泛化性
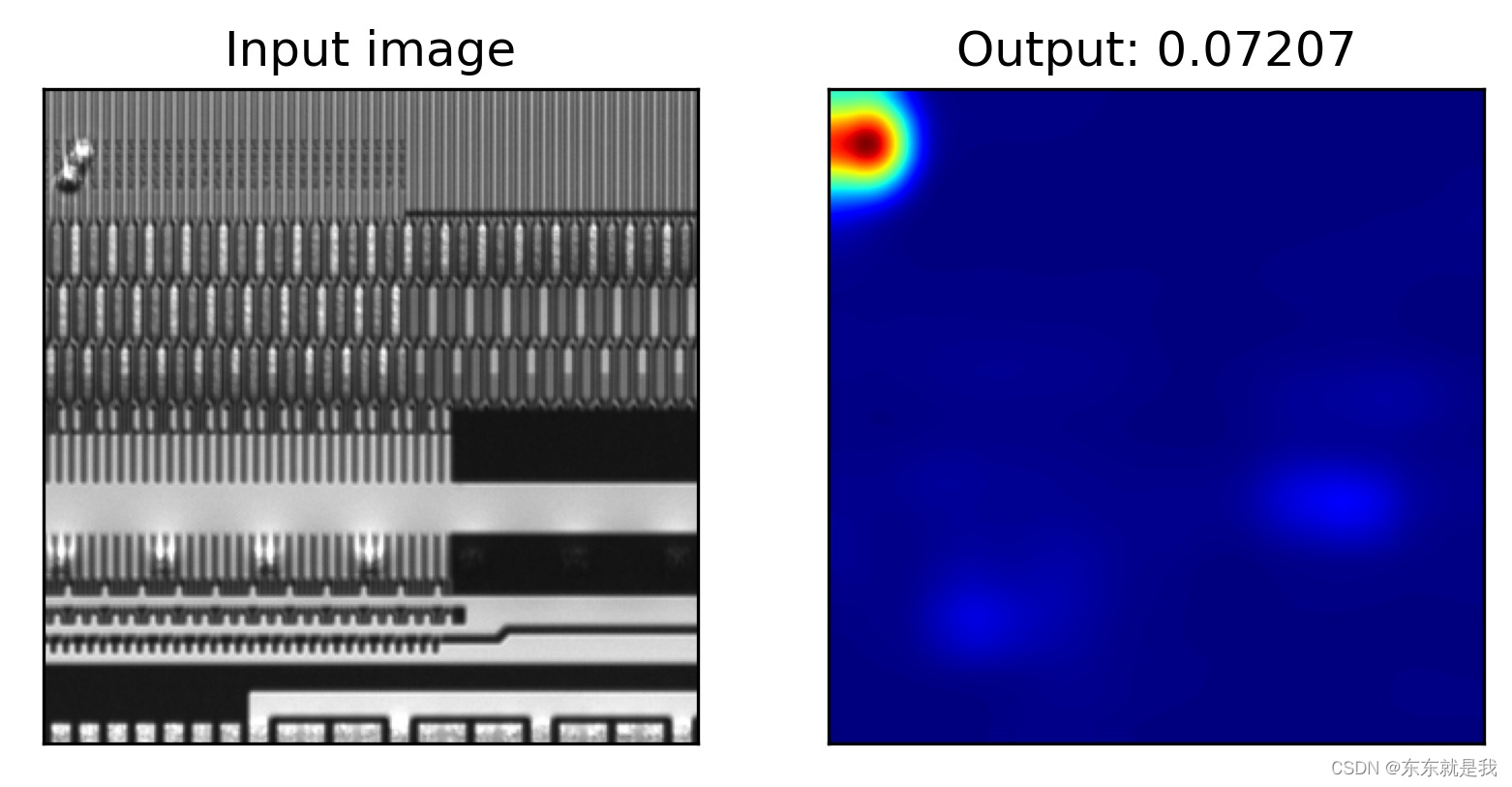

简直离谱他妈给离谱开门。这玩意怎么用啊
再次出发
https://github.com/openvinotoolkit/anomalib.git
在网上找了很久,发现有个现成的缺陷检测的库。不管咋样先拿来试一下
安装,数据准备,训练
# Import the required modules
from anomalib.data import Myself
from anomalib.models import Patchcore
from anomalib.engine import Engine
# Initialize the datamodule, model and engine
datamodule = Myself(num_workers=0)
model = Patchcore()
engine = Engine(image_metrics=["AUROC"],
accelerator="auto",
check_val_every_n_epoch=1,
devices=1,
max_epochs=1,
num_sanity_val_steps=0,
val_check_interval=1.0,
)
# Train the model
engine.fit(datamodule=datamodule, model=model)

好像不能直接训练啊。还是需要去研究一下。。。。。
难受!!!!!!!!!!!!!