什么是RAG
RAG(Retrieval Augmented Generation),即检索增强生成技术。
RAG优势
- 部分解决了幻觉问题。由于我们可以控制检索内容的可靠性,也算是部分解决了幻觉问题。
- 可以更实时。同理,可以控制输入给大模型上下文内容的时效性,解决大模型更新不及时问题。
- 可以成为某个领域的专家。
- 可追溯。
RAG大概示意
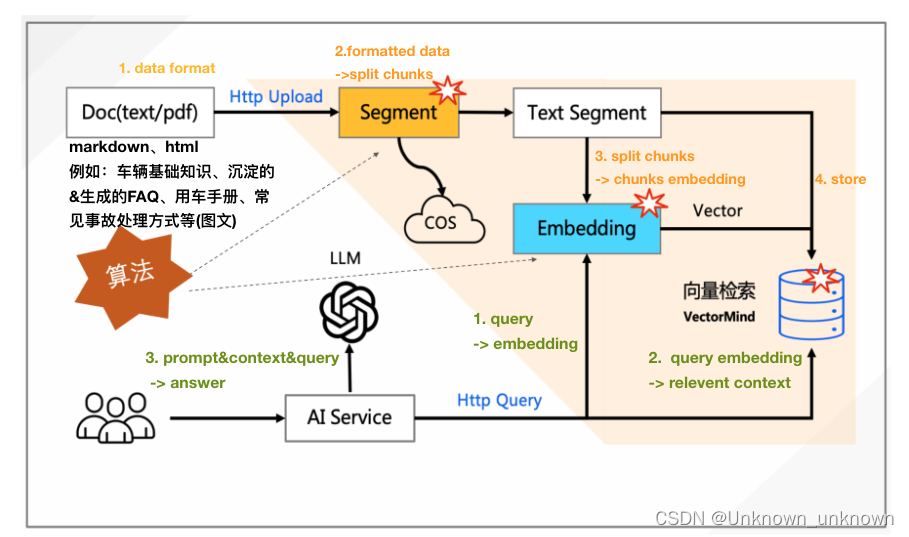
大致示意图如上。网上资料一搜一大堆,这里就不过多赘述。
想要自己搞一套也很简单,可以用一些开源的组装好的项目,也可以用langchain、llama-index自己搞一套。关于langchain、llama-index该选哪个,简单搞搞langchain,深入搞llama-index。
RAG 进一步优化
实现一个RAG很容易,但是想要做好有一定难度,这里提一些优化方案,也是本文的核心。
优化输入内容的组织形式
输入的内容不要只是简单平铺的文本,建议markdown、html形式,带上段落信息,分割也是以段落以句子为分割点,不要只是固定长度。
内置一些问答对
针对常见问题,预先内置一些问答对。
支持图文表格形式
对图片、表格,也通过一样上传向量库的方式进行支持。图片可以上传到cos,向量数据库存图片描述的embedding跟cos地址。
去掉低相关度回复
embedding检索时不要简单用top-k进行检索,需要关注实际相关度,相关度比较低时进行异常提示。
支持多轮
RAG多轮比较麻烦,除了对话多轮外,还需要支持的是检索多轮,即怎么根据上下文决定本次检索的信息。
其他
其他就是做好评测,做好正负反馈数据收集,持续迭代的事情了。另外,llama-index的数据结构也需要多看看,会有很多有意思的优化点。