Kafka消费者:监听模式VS主动拉取,哪种更适合你?
- 前言
- 监听模式的实现
- 监听器(Listener)的概念和作用
- 使用监听器实现 Kafka 消费者的步骤和方法
- 监听模式的优缺点分析
- 主动拉取模式
- 主动拉取(Polling)的概念和原理
- 使用轮询机制实现 Kafka 消费者的步骤和方法
- 主动拉取模式的优缺点分析
- 对比分析
- 监听模式与主动拉取模式的工作流程对比
- 监听模式与主动拉取模式的性能比较
- 总结:
- 进阶技巧与优化策略
- 监听模式和主动拉取模式的性能优化技巧
- 监听模式的性能优化技巧:
- 主动拉取模式的性能优化技巧:
- 如何避免监听模式和主动拉取模式可能遇到的问题
- 避免监听模式可能遇到的问题:
- 避免主动拉取模式可能遇到的问题:
- 混合使用监听模式和主动拉取模式的策略
- 混合使用监听模式和主动拉取模式的策略:
前言
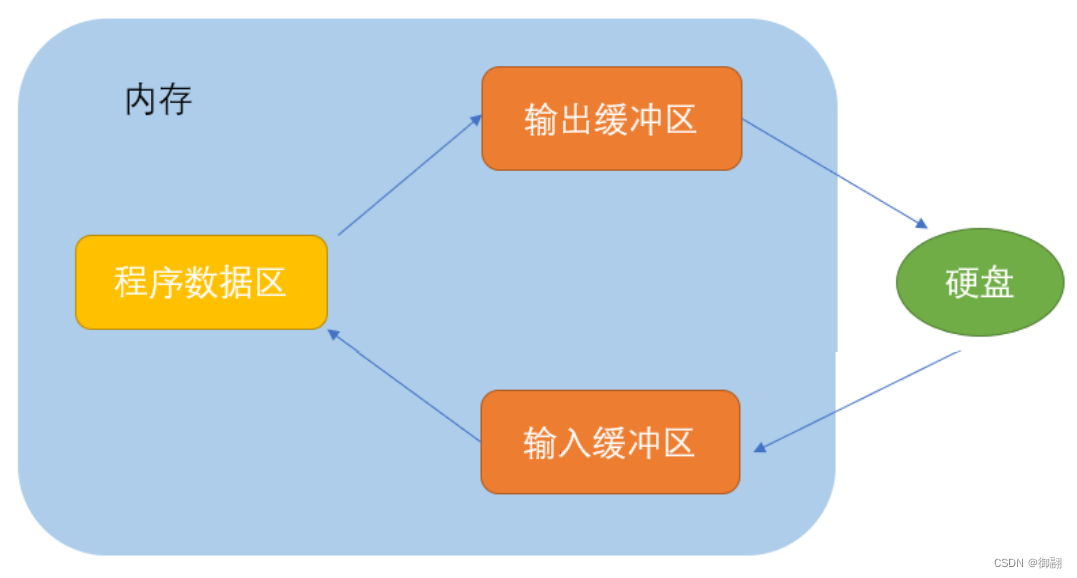
在Kafka的世界里,消费者扮演着至关重要的角色,它们是数据的最终接收者和处理者。但你是否曾想过,消费者可以有不同的工作模式吗?就像是在自助餐厅里,你可以选择等待服务员端菜上来(监听模式),也可以选择自己去取(主动拉取模式)。本文将带你进入这个有趣的话题,探讨Kafka消费者的两种实现方式,让你更加灵活地应对不同的场景。
监听模式的实现
监听器(Listener)的概念和作用
监听器是一种设计模式,用于在特定事件发生时执行相关操作。它通常包含一个事件监听器和一个事件源。事件源是生成事件的对象,而事件监听器则是在事件源触发事件时执行的代码块。
在软件开发中,监听器的作用是使对象能够对外部事件做出响应,而不需要主动轮询或等待事件发生。通过监听器,对象可以订阅感兴趣的事件,并在事件发生时被动地接收通知并执行相应的操作。
使用监听器实现 Kafka 消费者的步骤和方法
在 Kafka 中,消费者可以通过监听器模式实现对消息的消费。以下是使用监听器实现 Kafka 消费者的基本步骤和方法:
- 创建 Kafka 消费者:使用 Kafka 提供的客户端库创建一个消费者实例。
- 配置消费者:设置消费者所需的配置,包括 Kafka 集群的地址、消费者组ID、所订阅的主题等。
- 订阅主题:使用消费者实例订阅一个或多个主题,以开始消费消息。
- 注册监听器:为消费者注册一个消息监听器,以便在消息到达时触发相应的处理逻辑。
- 实现监听器逻辑:编写监听器逻辑,以定义消费者在接收到消息时所执行的操作,例如处理消息、记录日志等。
- 启动消费者:启动消费者实例,开始监听并消费消息。
监听模式的优缺点分析
优点:
- 松耦合性: 监听模式降低了对象之间的耦合度,使得对象之间的通信更加灵活,可以随时添加或移除监听器而不影响系统的其他部分。
- 增强可维护性: 监听模式将事件处理逻辑与触发事件的对象分离开来,使得代码更易于维护和理解。
- 提高扩展性: 可以通过添加新的监听器来扩展系统的功能,而无需修改现有的代码。
缺点:
- 过多监听器: 如果系统中存在大量的监听器,可能会导致性能问题和内存消耗增加。
- 难以调试: 由于监听器的执行顺序可能不确定,当系统出现问题时,调试起来可能会比较困难。
- 事件处理顺序: 在一些情况下,监听器的执行顺序可能会影响系统的行为,需要额外的管理和控制。
在实际应用中,监听模式适用于需要对外部事件进行响应的场景,但需要根据具体情况权衡其优缺点并进行合适的设计和实现。
主动拉取模式
主动拉取(Polling)的概念和原理
主动拉取(Polling)是一种常见的获取数据的方式,其原理是消费者周期性地向消息队列(比如 Kafka)发送请求,以获取新的消息。在主动拉取模式中,消费者控制消息获取的频率和时机,而不是被动地等待消息的到达。
主动拉取的基本原理如下:
- 消费者周期性地向消息队列发送拉取请求。
- 消息队列收到请求后,返回当前可用的消息给消费者。
- 消费者处理获取到的消息,并根据需要进行下一步操作。
使用轮询机制实现 Kafka 消费者的步骤和方法
使用轮询机制实现 Kafka 消费者的步骤如下:
- 配置 Kafka 消费者客户端:设置 Kafka 服务器地址、消费者组 ID、序列化器等参数。
- 订阅主题:使用消费者客户端订阅一个或多个主题,以开始消费消息。
- 循环轮询:在一个无限循环中,反复执行以下步骤:
- 发送拉取请求:消费者定期向 Kafka 服务器发送拉取消息的请求。
- 获取消息:从拉取请求的响应中获取新的消息。
- 处理消息:对获取到的消息进行处理,例如保存到数据库、进行业务逻辑处理等。
以下是使用轮询机制实现 Kafka 消费者的示例代码:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class KafkaPullConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("topic"));
while (true) {
// 发送拉取请求
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// 处理获取到的消息
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}
主动拉取模式的优缺点分析
优点:
- 控制消费速率: 消费者可以根据自身处理能力调整拉取的频率,避免因消息过多而导致系统压力过大。
- 实时性更好: 消费者可以在需要时立即拉取消息,实现更快的消息处理响应时间。
- 灵活性: 可以根据业务需求灵活地调整轮询的间隔时间和拉取消息的方式。
缺点:
- 资源浪费: 如果设置的轮询间隔过短,可能会导致消费者频繁发送拉取请求,造成资源浪费。
- 实时性和性能平衡: 较短的轮询间隔可以提高消息处理的实时性,但可能会增加系统的负载和延迟。
- 延迟和不一致性: 由于消息的拉取是由消费者控制的,可能会导致消息之间的处理延迟和不一致性。
在实际应用中,需要根据具体的业务需求和系统性能权衡主动拉取模式的优缺点,并进行合适的选择和调优。
对比分析
监听模式与主动拉取模式的工作流程对比
监听模式工作流程:
- 消费者注册到消息队列的主题上,设置消息监听器。
- 消费者通过监听器被动地接收来自消息队列的消息。
- 当消息到达时,消息队列通知监听器,监听器执行相应的处理逻辑。
主动拉取模式工作流程:
- 消费者周期性地发送拉取请求到消息队列。
- 消息队列返回可用的消息给消费者。
- 消费者处理获取到的消息。
监听模式与主动拉取模式的性能比较
性能比较:
- 监听模式: 监听模式的性能受到消息到达的通知速度和消息处理的效率的影响。当消息到达速度很快时,可能会出现消息积压和处理延迟的情况。
- 主动拉取模式: 主动拉取模式的性能取决于消费者发送拉取请求的频率和消息处理的效率。可以通过调整拉取频率来平衡系统的实时性和性能,但频繁的拉取请求可能会导致资源浪费。
适用性和选择建议:
-
监听模式适用于:
- 对消息实时性要求不高,可以接受一定的延迟。
- 系统中存在较少的消息并发量,不会造成消息积压的情况。
- 希望简化消息处理逻辑,减少代码复杂度的场景。
-
主动拉取模式适用于:
- 需要实时获取消息并快速响应的场景。
- 对消息处理效率和资源利用率有较高要求的场景。
- 可以容忍轮询带来的一定的延迟和资源消耗的场景。
-
综合选择建议:
- 在需要实时性较高、资源利用率较高的场景下,可以选择主动拉取模式。
- 在对实时性要求不高,希望简化消息处理逻辑的场景下,可以选择监听模式。
总结:
- 监听模式适用于消息到达通知频率不高且系统负载可控的场景,能够简化消息处理逻辑,但对消息处理的实时性要求不高。
- 主动拉取模式适用于对消息实时性要求高、系统负载可控且需要更精细的资源利用的场景,但可能会增加系统的复杂度和维护成本。
- 在实际应用中,可以根据业务需求、系统性能和资源限制等因素综合考虑,并根据场景灵活选择合适的模式。
进阶技巧与优化策略
监听模式和主动拉取模式的性能优化技巧
监听模式的性能优化技巧:
- 批量处理消息: 在消息到达后,可以进行批量处理,减少处理次数,提高效率。
- 异步处理: 将消息处理逻辑放入异步线程中进行处理,避免阻塞主线程,提高并发性能。
- 消息过滤: 在注册监听器时,可以设置过滤条件,只处理满足条件的消息,减少不必要的消息处理,提升效率。
主动拉取模式的性能优化技巧:
- 调整拉取频率: 根据业务需求和系统负载情况,合理调整拉取频率,避免过频繁或过稀少地发送拉取请求。
- 增加拉取批次: 通过增加单次拉取的消息数量来减少拉取请求的次数,降低系统开销。
- 自适应拉取: 根据消息队列中消息积压情况自适应调整拉取频率和批次,保持系统的稳定性和高效性。
如何避免监听模式和主动拉取模式可能遇到的问题
避免监听模式可能遇到的问题:
- 避免处理阻塞: 在监听器中避免长时间的阻塞操作,以免影响其他消息的处理。
- 异常处理: 在监听器中对异常情况进行处理,避免异常抛出导致监听器无法继续接收消息。
- 优雅关闭: 在程序关闭时,确保监听器能够优雅地关闭,释放资源。
避免主动拉取模式可能遇到的问题:
- 拉取超时处理: 在发送拉取请求后,及时处理超时情况,防止因网络延迟或其他原因导致的拉取失败。
- 避免频繁拉取: 避免过于频繁地发送拉取请求,以免造成系统资源的浪费和消息队列的压力过大。
- 负载均衡: 在使用多个消费者时,进行负载均衡,避免某些消费者负载过重,导致消息处理不均衡。
混合使用监听模式和主动拉取模式的策略
混合使用监听模式和主动拉取模式的策略:
- 结合场景需求: 根据具体的业务场景和需求,灵活选择使用监听模式或主动拉取模式,或两者结合使用。
- 预警机制: 监听模式可用于重要数据的实时监控,而主动拉取模式可用于定期拉取大量数据,结合两者可实现全面的数据监控和获取。
- 动态切换: 根据系统负载情况和消息队列的压力,动态切换监听模式和主动拉取模式,以保证系统的稳定性和性能。
混合使用监听模式和主动拉取模式可以充分发挥它们各自的优势,提高系统的灵活性和性能,并根据具体场景的需求进行灵活调整和优化。