💡💡💡本文改进内容: CVPR2023 动态稀疏注意力的双层路由方法BiLevelRoutingAttention,强烈推荐,涨点很不错,同时被各个领域的魔改次数甚多,侧面验证了性能。
💡💡💡BiLevelRoutingAttention对小目标检测效果比较好:BRA模块是基于稀疏采样而不是下采样,一来可以保留细粒度的细节信息,二来同样可以达到节省计算量的目的。
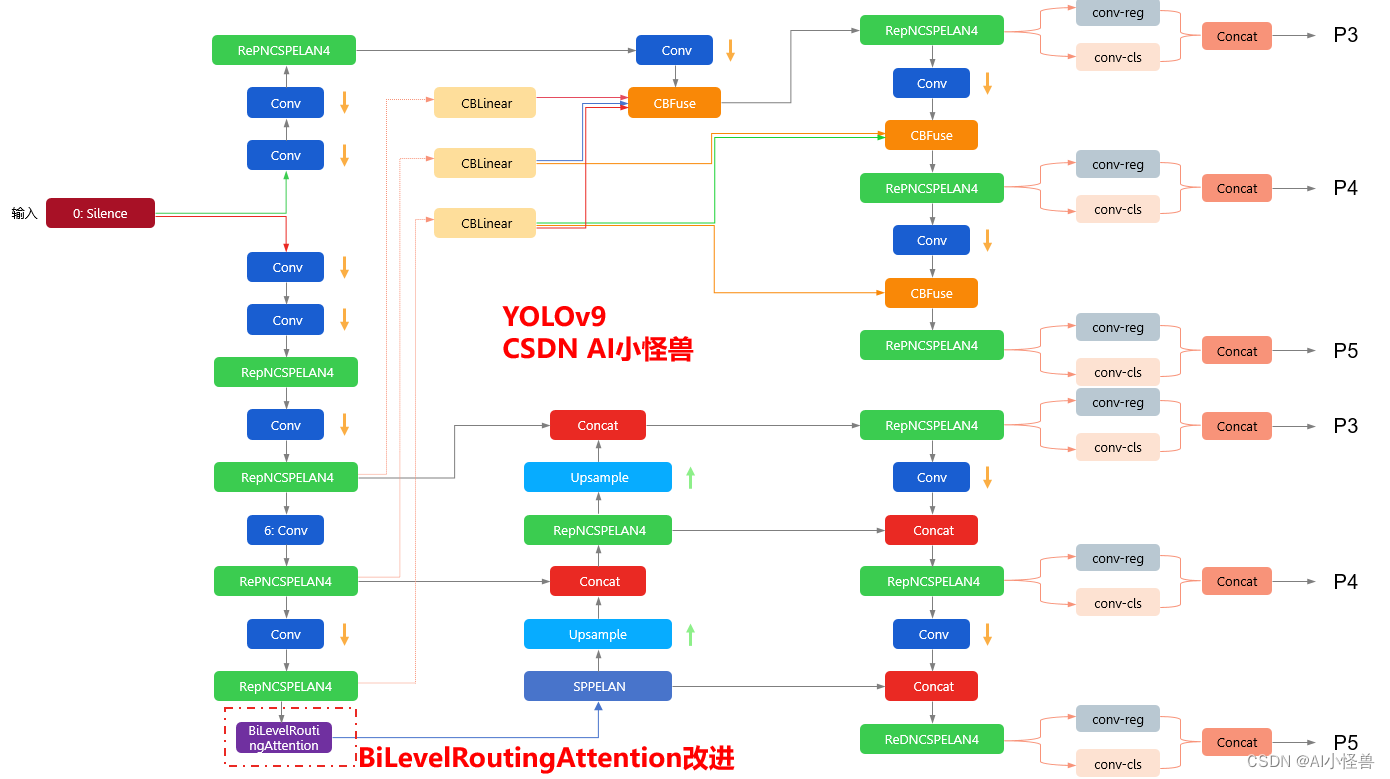
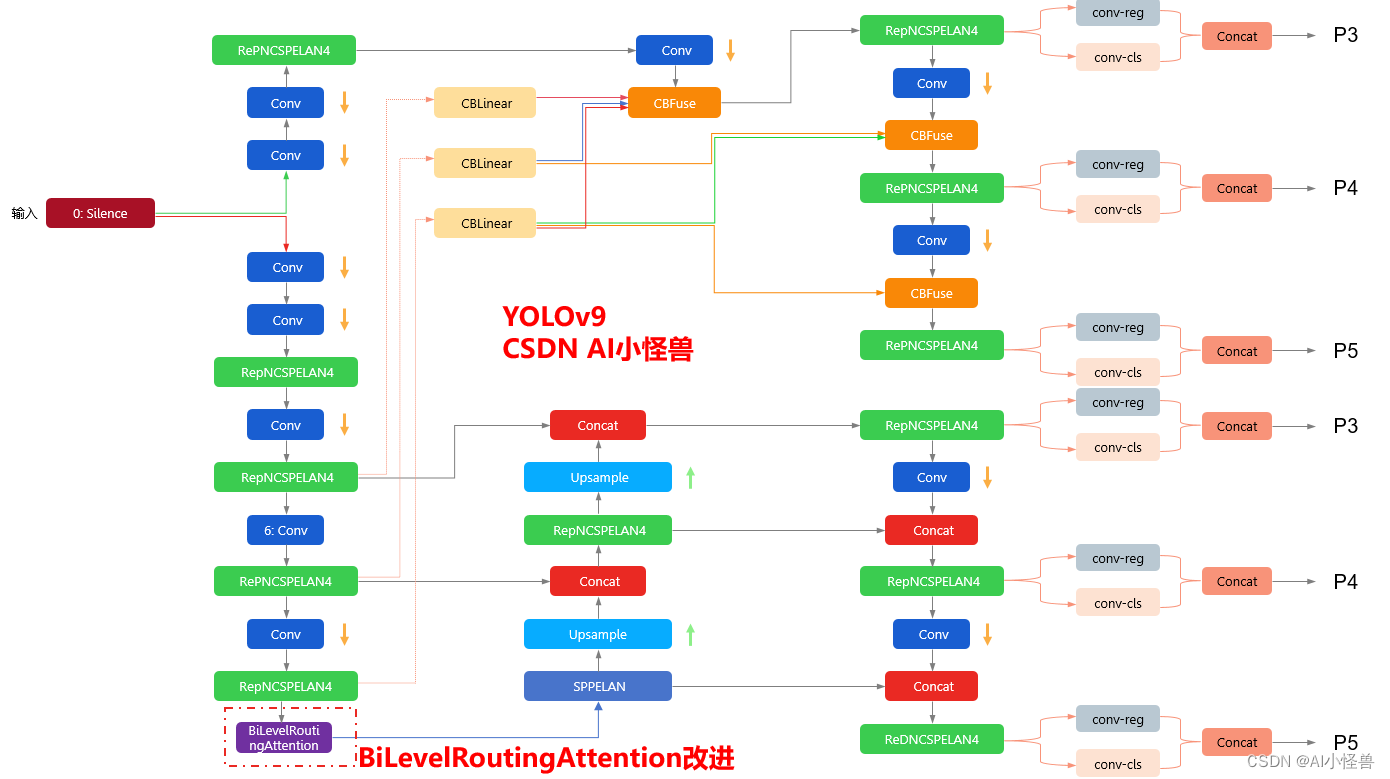
改进结构图如下:
YOLOv9魔术师专栏
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
✨✨✨ 新开专栏暂定免费限时开放,后续每月调价一次✨✨✨
🚀🚀🚀 本项目持续更新 | 更新完结保底≥80+ ,冲刺100+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐现更新的所有改进点抢先使用私信我,目前售价68,改进点20+个⭐⭐⭐
⭐⭐⭐专栏涨价趋势 99 ->199->259->299,越早订阅越划算⭐⭐⭐

YOLOv9魔改:注意力机制、检测头、blcok魔改、自研原创等
YOLOv9魔术师
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

YOLOv9框架图
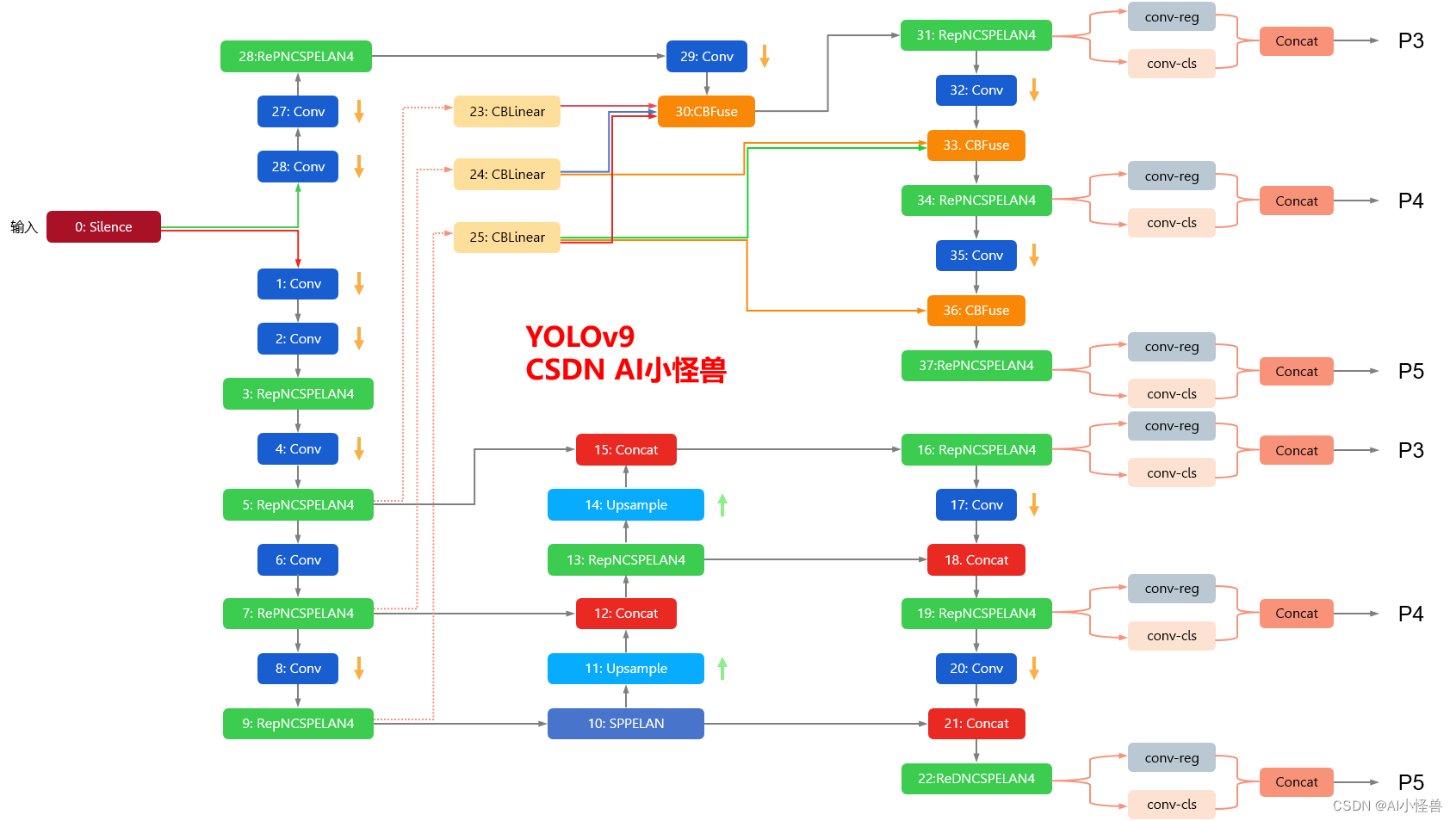
1.1 YOLOv9框架介绍
YOLOv9各个模型介绍

2.BiFormer介绍

论文:https://arxiv.org/pdf/2303.08810.pdf
代码:GitHub - rayleizhu/BiFormer: [CVPR 2023] Official code release of our paper "BiFormer: Vision Transformer with Bi-Level Routing Attention"
背景:注意力机制是Vision Transformer的核心构建模块之一,可以捕捉长程依赖关系。然而,由于需要计算所有空间位置之间的成对令牌交互,这种强大的功能会带来巨大的计算负担和内存开销。为了减轻这个问题,一系列工作尝试通过引入手工制作和内容无关的稀疏性到关注力中来解决这个问题,如限制关注操作在局部窗口、轴向条纹或扩张窗口内。
本文方法:本文提出一种动态稀疏注意力的双层路由方法。对于一个查询,首先在粗略的区域级别上过滤掉不相关的键值对,然后在剩余候选区域(即路由区域)的并集中应用细粒度的令牌对令牌关注力。所提出的双层路由注意力具有简单而有效的实现方式,利用稀疏性来节省计算和内存,只涉及GPU友好的密集矩阵乘法。在此基础上构建了一种新的通用Vision Transformer,称为BiFormer。
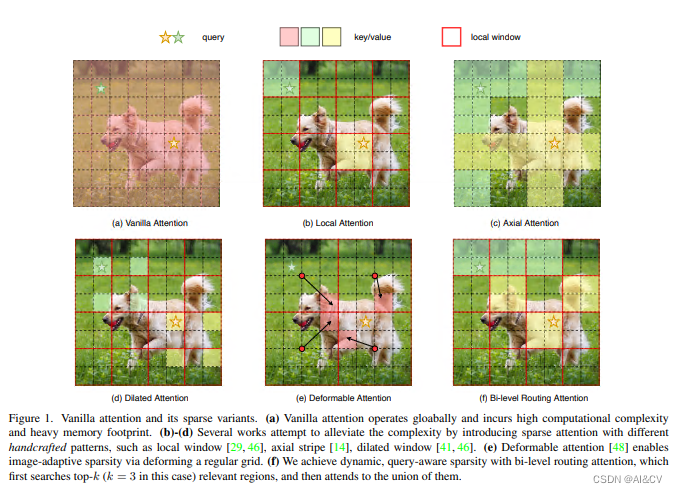
其中图(a)是原始的注意力实现,其直接在全局范围内操作,导致高计算复杂性和大量内存占用;而对于图(b)-(d),这些方法通过引入具有不同手工模式的稀疏注意力来减轻复杂性,例如局部窗口、轴向条纹和扩张窗口等;而图(e)则是基于可变形注意力通过不规则网格来实现图像自适应稀疏性;作者认为以上这些方法大都是通过将 手工制作 和 与内容无关 的稀疏性引入到注意力机制来试图缓解这个问题。因此,本文通过双层路由(bi-level routing)提出了一种新颖的动态稀疏注意力(dynamic sparse attention ),以实现更灵活的计算分配和内容感知,使其具备动态的查询感知稀疏性,如图(f)所示。

基于BRA模块,本文构建了一种新颖的通用视觉转换器BiFormer。如上图所示,其遵循大多数的vision transformer架构设计,也是采用四级金字塔结构,即下采样32倍。
具体来说,BiFormer在第一阶段使用重叠块嵌入,在第二到第四阶段使用块合并模块来降低输入空间分辨率,同时增加通道数,然后是采用连续的BiFormer块做特征变换。需要注意的是,在每个块的开始均是使用 的深度卷积来隐式编码相对位置信息。随后依次应用BRA模块和扩展率为 的 2 层 多层感知机(Multi-Layer Perceptron, MLP)模块,分别用于交叉位置关系建模和每个位置嵌

本文方法对小目标检测效果比较好。可能是因为BRA模块是基于稀疏采样而不是下采样,一来可以保留细粒度的细节信息,二来同样可以达到节省计算量的目的。
3.BiLevelRoutingAttention 加入到YOLOv9
3.1新建py文件,路径为models/attention/BiLevelRoutingAttention.py
本部分转为付费专栏开放
3.2修改yolo.py
1)首先进行引用
from models.attention.BiLevelRoutingAttention import BiLevelRoutingAttention2)修改def parse_model(d, ch): # model_dict, input_channels(3)
在源码基础上加入BiLevelRoutingAttention
###attention #####
elif m in {BiLevelRoutingAttention}:
c2 = ch[f]
args = [c2, *args]
###attention #####3.3 yolov9-c-BiLevelRoutingAttention.yaml
# YOLOv9
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# anchors
anchors: 3
# YOLOv9 backbone
backbone:
[
[-1, 1, Silence, []],
# conv down
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3
# avg-conv down
[-1, 1, ADown, [256]], # 4-P3/8
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
# avg-conv down
[-1, 1, ADown, [512]], # 6-P4/16
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
# avg-conv down
[-1, 1, ADown, [512]], # 8-P5/32
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
[-1, 1, BiLevelRoutingAttention, [512]], # 10
]
# YOLOv9 head
head:
[
# elan-spp block
[-1, 1, SPPELAN, [512, 256]], # 11
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 14
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# elan-2 block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 17 (P3/8-small)
# avg-conv-down merge
[-1, 1, ADown, [256]],
[[-1, 14], 1, Concat, [1]], # cat head P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)
# avg-conv-down merge
[-1, 1, ADown, [512]],
[[-1, 11], 1, Concat, [1]], # cat head P5
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 23 (P5/32-large)
# multi-level reversible auxiliary branch
# routing
[5, 1, CBLinear, [[256]]], # 24
[7, 1, CBLinear, [[256, 512]]], # 25
[9, 1, CBLinear, [[256, 512, 512]]], # 26
# conv down
[0, 1, Conv, [64, 3, 2]], # 27-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 28-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 29
# avg-conv down fuse
[-1, 1, ADown, [256]], # 30-P3/8
[[24, 25, 26, -1], 1, CBFuse, [[0, 0, 0]]], # 31
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 32
# avg-conv down fuse
[-1, 1, ADown, [512]], # 33-P4/16
[[25, 26, -1], 1, CBFuse, [[1, 1]]], # 34
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 35
# avg-conv down fuse
[-1, 1, ADown, [512]], # 36-P5/32
[[26, -1], 1, CBFuse, [[2]]], # 37
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38
# detection head
# detect
[[32, 35, 38, 17, 20, 23], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]⭐⭐⭐现更新的所有改进点抢先使用私信我,目前售价68,改进点20+个⭐⭐⭐
⭐⭐⭐专栏涨价趋势 99 ->199->259->299,越早订阅越划算⭐⭐⭐