目录
一、遍历列表
1.使用for 循环和 enumerate()函数实现
2.案例代码
二、对列表进行统计和计算
1.统计数值列表的元素和
2.案例代码
三、对列表进行排序
1.使用列表对象的sort()方法
2.使用内置的 sorted()函数实现
四、列表推导式
1.从列表中选择符合条件的元素组成新的列表
2.案例代码
五、对列表进行统计和计算
1.统计数值列表的元素和
2.案例代码
六、Python常用的内置标准模块
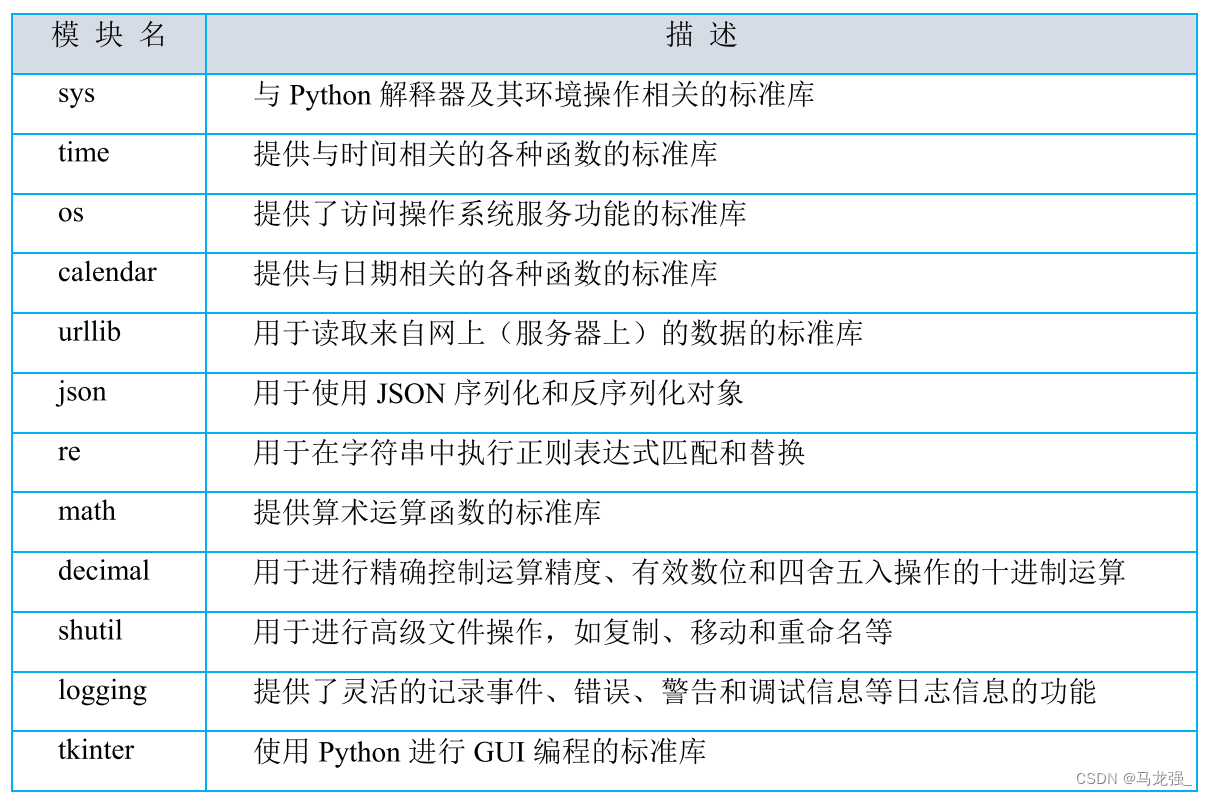
1.sys:sys.exit()用于退出程序
2.time:time.sleep(1) 用于暂停1秒
3.os:os.getcwd()用于获得当前工作目录
4.calendar:calendar.month(2022,5)用于打印2022年5月的日历
5.urllib:urllib.request.urlopen('https://www.example.com') 用于打开一个URL
6.json:json.loads('{"name":"John","age":30}')
7.re:re.search('\d+','abc123def')用于在字符串中查找数字
8.math:math.sqrt(9) 用于计算平方根
9.decimal:decimal.Decimal('0.1' + decimal.Decimal('0.2'))用于高精度的浮点数运算
10.shuil:shuil.copy('source.txt','destination.txt')用于复制文件
11.logging:logging.info('This is an info message')用于记录日志信息
12.tkinter:创建一个简单的窗口
七、python中的正则表达式
1.常用元字符
2.常用的限定符
3.python正则表达式常用标志
八、异常处理及程序调试
1.python中常见的异常
2.try...except语句
九、python中文件及目录操作
1.创建和打开文件
(1)创建新文件并写入内容
(2)打开并追加内容到文件
(3)读取文件内容
(4)以二进制模式打开文件
2.关闭文件
(1)使用.close()方法直接关闭
(2)使用with语句(推荐)
(3)使用try-finally块
3.删除文件
(1)删除文件
(2)删除的一个空目录
4.重命名文件和目录
5.stat()函数返回的对象常用属性
十、GUI界面编程
1.流行的GUI工具包
一、遍历列表
1.使用for 循环和 enumerate()函数实现
使用for 循环和enumerate0)函数可以实现同时输出索引值和元素内容,语法格式如下:
for index, item in enumerate(listname):# 输出 index 和 item
参数说明:
index:用于保存元素的索引。
item:用于保存获取到的元素值,要输出元素内容时,直接输出该变量V即可。
listname 为列表名称。
2.案例代码
# 定义一个列表
listname = ['apple', 'banana', 'cherry', 'date']
# 使用enumerate()函数和for循环遍历列表
for index, item in enumerate(listname):
# 参数说明:
# index: 当前元素在列表中的索引(从0开始)
# item: 当前索引对应的列表元素的值
print(f"索引: {index}, 元素内容: {item}")
# 示例输出:
# 索引: 0, 元素内容: apple
# 索引: 1, 元素内容: banana
# 索引: 2, 元素内容: cherry
# 索引: 3, 元素内容: date二、对列表进行统计和计算
1.统计数值列表的元素和
在Python中,提供了sum()函数用于统计数值列表中各元素的和。语法格式如下:
sum(iterablef,start])
参数说明:
iterable:表示要统计的列表。
start:表示统计结果是从哪个数开始(即将统计结果加上start所指定的y是可选参数,如果没有指定数,默认值为0。
2.案例代码
假设我们有一个数值列表 numbers = [1, 2, 3, 4, 5],如果我们想要计算这个列表中所有元素的和,可以直接调用 sum() 函数:
numbers = [1, 2, 3, 4, 5]
total_sum = sum(numbers)
print(total_sum)
#运行这段代码后,输出结果将会是 15,因为 1 + 2 + 3 + 4 + 5 的和是 15。如果想要从某个非零数值开始累加,比如从 10 开始,可以这样使用 start 参数:
numbers = [1, 2, 3, 4, 5]
total_with_start = sum(numbers, start=10)
print(total_with_start)
#这里的输出结果将会是 20,因为除了原本列表元素之和 15 外,还额外加上了 start 参数设定的初始值 10。三、对列表进行排序
1.使用列表对象的sort()方法
列表对象提供了sort()方法用于对原列表中的元素进行排序。排序后原列表中的元素顺序将发生改变。列表对象的sort0方法的语法格式如下:
listname.sort(key=None,reverse-False)
参数说明:
listname:表示要进行排序的列表。
key:表示指定从每个元素中提取一个用于比较的键(例如,设置“key=str.lower”表示在排序时不区分字母大小写)。
reverse:可选参数,如果将其值指定为True,则表示降序排列;如果为False,则表示升序排列,默认为升序排列
示例1:基本升序排序
fruits = ['apple', 'Banana', 'cherry', 'date']
fruits.sort()
print(fruits) # 输出: ['apple', 'Banana', 'cherry', 'date']
#在此例中,fruits 列表中的字符串按照字母顺序进行了升序排序。示例2:忽略大小写进行排序
fruits = ['apple', 'Banana', 'cherry', 'date']
fruits.sort(key=str.lower)
print(fruits) # 输出: ['apple', 'Banana', 'cherry', 'date']
#这里,通过 key=str.lower 指定了一个函数,使得在排序时先将每个元素转换为小写,然后再进行排序,因此不区分大小写。示例3:降序排序
numbers = [10, 5, 15, 2, 8]
numbers.sort(reverse=True)
print(numbers) # 输出: [15, 10, 8, 5, 2]
#在这个例子中,由于设置了 reverse=True,所以 numbers 列表中的数字将以降序排列。2.使用内置的 sorted()函数实现
在Python 中,提供了一个内置的sorted()函数,用于对列表进行排序。使用该函数进行排序后,原列表的元素顺序不变。storted0函数的语法格式如下:
sorted(iterable,key=None,reverse=False)
参数说明:
iterable:表示要进行排序的列表名称,
key:表示指定从每个元素中提取一个用于比较的键(例如,设置“key=str.lower”表示在排序时不区分字母大小写)
reverse:可选参数,如果将其值指定为True,则表示降序排列;如果为False,则表示升序排列,默认为升序排列。
示例1:使用 sorted() 函数对列表进行升序排序
fruits = ['apple', 'Banana', 'cherry', 'date']
sorted_fruits = sorted(fruits)
print(sorted_fruits) # 输出: ['apple', 'Banana', 'cherry', 'date']
print(fruits) # 输出: ['apple', 'Banana', 'cherry', 'date']
#在此例中,sorted() 函数对 fruits 列表进行了升序排序,但原列表 fruits 的内容并未改变,新排序的结果存储在新的变量 sorted_fruits 中。示例2:忽略大小写进行排序
fruits = ['apple', 'Banana', 'cherry', 'date']
sorted_fruits_ignore_case = sorted(fruits, key=str.lower)
print(sorted_fruits_ignore_case) # 输出: ['apple', 'Banana', 'cherry', 'date']
print(fruits) # 输出: ['apple', 'Banana', 'cherry', 'date']
#这里同样使用了 key=str.lower 参数,使排序时不区分大小写,但原列表 fruits 内容未变。示例3:使用 sorted() 函数进行降序排序
numbers = [10, 5, 15, 2, 8]
sorted_numbers_desc = sorted(numbers, reverse=True)
print(sorted_numbers_desc) # 输出: [15, 10, 8, 5, 2]
print(numbers) # 输出: [10, 5, 15, 2, 8]
#在这个例子中,由于设置了 reverse=True,numbers 列表中的数字以降序排列,但原列表的内容保持不变。新排序后的结果保存在 sorted_numbers_desc 中。四、列表推导式
1.从列表中选择符合条件的元素组成新的列表
在Python中,如果你想要在生成新列表时添加一个筛选条件,可以使用带有条件语句的列表推导式。其语法格式如下:
newlist = [Expression for var in list if condition]这里的参数说明补充完整如下:
newlist: 新生成的列表的名称,存储满足条件的元素经过特定表达式计算后得到的结果。Expression: 表达式,用于根据原列表list中的满足条件的元素计算新列表的元素值。var: 循环变量,对于原列表list中的每一个元素,在每次迭代中取到当前元素的值。list: 用于生成新列表的原列表。condition: 条件表达式,只有当该表达式为True时,当前var对应的元素才会被纳入新列表的计算之中。
2.案例代码
假设我们有一个列表,里面包含一些整数,我们想创建一个新的列表,只包含原列表中能被2整除的数的两倍:
original_list = [1, 2, 3, 4, 5, 6, 7, 8]
# 带条件的列表推导式,仅选取原列表中能被2整除的数,并将其乘以2放入新列表
newlist = [2 * var for var in original_list if var % 2 == 0]
# 输出: newlist 现在是 [4, 8, 12, 16]
print(newlist)在这个例子中,"Expression"是 2 * var,条件表达式是 var % 2 == 0,这会筛选出原列表中所有偶数并计算它们的两倍作为新列表的元素。
五、对列表进行统计和计算
1.统计数值列表的元素和
在Python中,提供了sum()函数用于统计数值列表中各元素的和。语法格式如下:
sum(iterable[,start])
参数说明:
iterable:表示要统计的列表。
start:表示统计结果是从哪个数开始(即将统计结果加上start所指定的Vstart:数),是可选参数,如果没有指定,默认值为0。
2.案例代码
#没有提供 start 参数的例子
numbers = [1, 2, 3, 4, 5]
total_sum = sum(numbers)
print(total_sum) # 输出: 15 因为 1+2+3+4+5=15
# 提供 start 参数的例子
more_numbers = [6, 7, 8, 9]
total_with_start = sum(more_numbers, 10) # 这里将 10 作为累加的初始值
print(total_with_start) # 输出: 30 因为 10+6+7+8+9=30六、Python常用的内置标准模块
1.sys:sys.exit()用于退出程序
import sys
sys.exit()2.time:time.sleep(1) 用于暂停1秒
import time
time.sleep(1)3.os:os.getcwd()用于获得当前工作目录
import os
print(os.getcwd())4.calendar:calendar.month(2022,5)用于打印2022年5月的日历
import calendar
print(calendar.month(2022, 5))5.urllib:urllib.request.urlopen('https://www.example.com') 用于打开一个URL
import urllib.request
response = urllib.request.urlopen('https://www.example.com')
print(response.read())6.json:json.loads('{"name":"John","age":30}')
import json
data = json.loads('{"name": "John", "age": 30}')
print(data)7.re:re.search('\d+','abc123def')用于在字符串中查找数字
import re
result = re.search('\d+', 'abc123def')
print(result.group())8.math:math.sqrt(9) 用于计算平方根
import math
print(math.sqrt(9))9.decimal:decimal.Decimal('0.1' + decimal.Decimal('0.2'))用于高精度的浮点数运算
from decimal import Decimal
result = Decimal('0.1') + Decimal('0.2')
print(result)10.shuil:shuil.copy('source.txt','destination.txt')用于复制文件
import shutil
shutil.copy('source.txt', 'destination.txt')11.logging:logging.info('This is an info message')用于记录日志信息
import logging
logging.basicConfig(level=logging.INFO)
logging.info('This is an info message')12.tkinter:创建一个简单的窗口
import tkinter as tk
window = tk.Tk()
window.title("My Window")
window.mainloop()七、python中的正则表达式
1.常用元字符
代码演示
import re
# 匹配任意字符
text = "abc123"
pattern = r"."
result = re.findall(pattern, text)
print(result) # Output: ['a', 'b', 'c', '1', '2', '3']
# 匹配字母、数字或下划线字符
text = "hello_world 123"
pattern = r"\w"
result = re.findall(pattern, text)
print(result) # Output: ['h', 'e', 'l', 'l', 'o', '_', 'w', 'o', 'r', 'l', 'd', '1', '2', '3']
# 匹配空白字符
text = "hello world"
pattern = r"\s"
result = re.findall(pattern, text)
print(result) # Output: [' ']
# 匹配数字字符
text = "abc123def456"
pattern = r"\d"
result = re.findall(pattern, text)
print(result) # Output: ['1', '2', '3', '4', '5', '6']
# 匹配单词边界
text = "Hello, World! This is a test."
pattern = r"\b"
result = re.split(pattern, text)
print(result) # Output: ['Hello', ',', ' ', 'World', '!', ' ', 'This', ' ', 'is', ' ', 'a', ' ', 'test', '.']
# 匹配字符串开头
text = "hello world"
pattern = r"^hello"
result = re.search(pattern, text)
if result:
print("Match found!")
else:
print("Match not found.")
# 匹配字符串结尾
text = "hello world"
pattern = r"world$"
result = re.search(pattern, text)
if result:
print("Match found!")
else:
print("Match not found.")2.常用的限定符
代码演示
import re
# 使用 ? 限定符
pattern1 = r"ab?" # 匹配 "a" 或 "ab"
print(re.findall(pattern1, "ab ac abb")) # 输出 ['a', 'ab']
# 使用 + 限定符
pattern2 = r"ab+" # 匹配 "ab", "abb", "abbb", 等
print(re.findall(pattern2, "ab ac abb")) # 输出 ['ab', 'abb']
# 使用 * 限定符
pattern3 = r"ab*" # 匹配 "a", "ab", "abb", "abbb", 等
print(re.findall(pattern3, "ab ac abb")) # 输出 ['a', 'ab', 'abb']
# 使用 {n} 限定符
pattern4 = r"a{2}" # 匹配 "aa"
print(re.findall(pattern4, "aa a aa")) # 输出 ['aa']
# 使用 {n,} 限定符
pattern5 = r"a{2,}" # 匹配至少两个连续的 "a"
print(re.findall(pattern5, "aa a aaa")) # 输出 ['aa', 'aaa']
# 使用 {n,m} 限定符
pattern6 = r"a{2,4}" # 匹配 "aa", "aaa", "aaaa"
print(re.findall(pattern6, "aa a aaa aaaa aaaaa")) # 输出 ['aa', 'aaa', 'aaaa']3.python正则表达式常用标志

代码演示
import re
# 使用ASCII标志
print(re.findall(r'\w', 'Hello, 世界!', re.A)) # 输出:['H', 'e', 'l', 'l', 'o', ',']
# 使用IGNORECASE标志
print(re.findall(r'[a-z]', 'Hello, World!', re.I)) # 输出:['H', 'e', 'l', 'l', 'o', 'W', 'o', 'r', 'l', 'd']
# 使用MULTILINE标志
print(re.findall(r'^H', 'Hello
World', re.M)) # 输出:['H']
# 使用DOTALL标志
print(re.findall(r'.', 'Hello
World', re.S)) # 输出:['H', 'e', 'l', 'l', 'o', '
', 'W', 'o', 'r', 'l', 'd']
# 使用VERBOSE标志
pattern = re.compile(r"""
\d + # 一个或多个数字
\s * # 零个或多个空格
\d + # 一个或多个数字
""", re.X)
print(pattern.findall('123 456')) # 输出:['123 456']八、异常处理及程序调试
1.python中常见的异常

代码示例
try:
# 尝试访问一个没有声明的变量
a = undefined_variable
except NameError as e:
print("NameError:", e)
try:
# 索引超出序列范围引发的错误
my_list = [1, 2, 3]
print(my_list[3])
except IndexError as e:
print("IndexError:", e)
try:
# 缩进错误
def my_function():
print("Hello, world!")
return "Goodbye, world!"
except IndentationError as e:
print("IndentationError:", e)
try:
# 传入的值错误
int("abc")
except ValueError as e:
print("ValueError:", e)
try:
# 请求一个不存在的字典关键字引发的错误
my_dict = {"a": 1, "b": 2}
print(my_dict["c"])
except KeyError as e:
print("KeyError:", e)
try:
# 输入输出错误(如要读取的文件不存在)
with open("nonexistent_file.txt", "r") as f:
content = f.read()
except IOError as e:
print("IOError:", e)
try:
# 当import语句无法找到模块或fom无法在模块中找到相应的名称时引发的错误
import nonexistent_module
except ImportError as e:
print("ImportError:", e)
try:
# 尝试访问未知的对象属性引发的错误
my_object = object()
print(my_object.undefined_attribute)
except AttributeError as e:
print("AttributeError:", e)
try:
# 类型不合适引发的错误
1 + "2"
except TypeError as e:
print("TypeError:", e)
try:
# 内存不足
big_list = [0] * (10**9)
except MemoryError as e:
print("MemoryError:", e)
try:
# 除数为0引发的错误
print(1 / 0)
except ZeroDivisionError as e:
print("ZeroDivisionError:", e)2.try...except语句
在Python中,try...except语句用于异常处理,它可以捕获和处理可能出现的错误,防止程序因为运行时错误而意外终止。
基本的异常捕获
try:
# 尝试执行可能会引发异常的代码
num1 = int(input("请输入一个整数:"))
num2 = int(input("请输入另一个整数:"))
result = num1 / num2
print("两数相除的结果是:", result)
except ValueError: # 如果输入的不是整数,int()会抛出ValueError
print("输入错误,无法转换为整数,请重新输入有效的整数")
except ZeroDivisionError: # 如果除数为0,会抛出ZeroDivisionError
print("除数不能为0")
except Exception as e: # 其他未知错误
print(f"发生了未知错误:{e}")
# 如果try块中的代码没有引发异常,将会执行else块(如果有)
else:
print("计算完成")
# finally块总会在try-except结构完成后被执行,无论是否发生异常
finally:
print("程序已完成本次操作")多个异常处理
try:
filename = input("请输入文件名:")
with open(filename, 'r') as file:
content = file.read()
except FileNotFoundError:
print("文件不存在")
except PermissionError:
print("没有权限打开此文件")
except Exception as e:
print(f"其他错误:{e}")
else:
print("成功读取文件内容")
finally:
print("尝试关闭文件操作已结束")使用as关键字捕获异常对象
try:
# 访问可能不存在的字典键
my_dict = {'name': 'Alice'}
value = my_dict['age']
except KeyError as key_error:
print(f"键 '{key_error.args[0]}' 不存在于字典中")捕获并重新抛出异常
def divide(a, b):
try:
return a / b
except ZeroDivisionError:
print("内部捕获到了除数为零的错误")
raise # 重新抛出异常,让调用者决定如何处理
try:
result = divide(10, 0)
except ZeroDivisionError:
print("外部捕获到了除数为零的错误,程序正常处理了这个异常")3.assert 语句调试程序
检查函数的返回值是否符合预期
def add_two_numbers(a, b):
return a + b
num1 = 5
num2 = 7
expected_sum = 12
# 使用assert语句验证add_two_numbers函数的返回结果
assert add_two_numbers(num1, num2) == expected_sum, f"Expected sum of {num1} and {num2} to be {expected_sum}, but got different result."
# 上述代码中,如果add_two_numbers(num1, num2)的结果不等于expected_sum,就会抛出AssertionError,并附带错误信息确保列表的长度满足特定条件
my_list = [1, 2, 3, 4, 5]
# 确保列表的长度至少为5
assert len(my_list) >= 5, f"The list should contain at least 5 elements, but it has {len(my_list)}."
# 如果my_list的长度小于5,就会触发AssertionError,并显示错误信息在循环中进行断言,确保每次迭代的结果都满足某个条件
for i in range(10):
# 确保循环变量i始终小于10
assert i < 10, f"During iteration, variable i ({i}) should always be less than 10."
# 如果在某次迭代中i的值大于等于10,就会触发AssertionError,并显示错误信息assert 语句在生产环境中应谨慎使用,因为它在Python优化级别 -O 或 -OO 下会被忽略。在开发阶段,它是一个很好的工具,可以帮助开发者快速发现和定位潜在的问题。在软件发布之前,通常会移除或替换掉不必要的断言语句,以避免影响性能。
九、python中文件及目录操作
在Python中,想要操作文件需要先创建或者打开指定的文件并创建文件对象可以通过内置的 open0函数实现。Open0)函数的基本语法格式如下:
file = open(filename[,mode[,buffering]])
参数说明:
file:被创建的文件对象。
Filename:要创建或打开文件的文件名称,需要使用单引号或双引号括起来。如果要打开的文件和当前文件在同一个目录下,那么直接写文件名即可,否则需要指定完整路径。例如,要打开当前路径下的名称为status.txt的文件,可以使用“status.txt'
mode:可选参数,用于指定文件的打开模式。默认的打开模式为只读(即
buffering:可选参数,用于指定读写文件的缓冲模式,值为0表达式不缓存;值为1表示缓存;如果大于1,则表示缓冲区的大小。默认为缓存模式。
1.创建和打开文件
(1)创建新文件并写入内容
# 创建并写入新文件(如果文件不存在则创建,存在则覆盖原有内容)
filename = "example.txt"
with open(filename, "w") as file: # "w" 是写入模式
file.write("Hello, World!\nThis is some text.\n")
# 解释:
# "w" 模式意味着写入模式,如果文件存在则清空原有内容,不存在则创建新文件
# 使用with语句可以确保文件在操作完毕后自动关闭,无需手动调用close()方法(2)打开并追加内容到文件
filename = "existing_file.txt"
with open(filename, "a") as file: # "a" 是追加模式
file.write("Appended line.\n")
# 解释:
# "a" 模式表示追加模式,即在文件末尾追加内容,如果文件不存在则创建新文件(3)读取文件内容
filename = "readme.txt"
with open(filename, "r") as file: # "r" 是读取模式,这是默认模式,通常可以省略
content = file.read()
print(content)
# 解释:
# "r" 模式用于读取文件内容,如果文件不存在则抛出FileNotFoundError异常(4)以二进制模式打开文件
filename = "binary_data.bin"
with open(filename, "wb") as binary_file: # "wb" 是二进制写入模式
binary_data = b"This is binary data"
binary_file.write(binary_data)
with open(filename, "rb") as binary_file: # "rb" 是二进制读取模式
read_data = binary_file.read()
print(read_data)
# 解释:
# "wb" 和 "rb" 分别是二进制写入和读取模式,用于处理非文本格式的数据,如图片、音频等注意,除了上述提到的"w", "a", "r", "wb", "rb",还有其他模式如 "x"(创建新文件,如果文件已存在则报错),"t"(文本模式,"r" 和 "w" 默认的),"b"(二进制模式),"+"(读写模式,同时支持读和写操作)。此外,还可以组合使用,如 "r+" 用于读写现有文件,"a+" 用于追加和读取等。
2.关闭文件
(1)使用.close()方法直接关闭
# 打开文件
file_obj = open('example.txt', 'r')
# 读取或写入文件...
data = file_obj.read()
# 关闭文件
file_obj.close()(2)使用with语句(推荐)
#使用with语句自动关闭文件,即使在处理文件过程中出现异常也会关闭
with open('example.txt', 'r') as file_obj:
data = file_obj.read()
# 这里不需要调用file_obj.close(),因为退出with块时会自动关闭文件(3)使用try-finally块
file_obj = open('example.txt', 'r')
try:
data = file_obj.read()
# 对文件的操作...
finally:
file_obj.close()3.删除文件
(1)删除文件
使用os模块提供的os.remove()或os.unlink()方法。这两个方法是等价的,都可以用来删除单个文件。
示例代码
import os
# 定义要删除的文件路径
file_path = '/path/to/your/file.txt'
# 删除文件
try:
os.remove(file_path)
# 或者
# os.unlink(file_path)
print(f"文件'{file_path}'已成功删除")
except FileNotFoundError:
print(f"文件'{file_path}'不存在")
except PermissionError:
print(f"没有权限删除文件'{file_path}'")
except Exception as e:
print(f"删除文件时发生错误: {e}")(2)删除的一个空目录
使用os.rmdir()方法;但如果要删除包含子文件和子目录的目录及其内容,应该使用shutil模块的shutil.rmtree()方法
示例代码
import shutil
# 定义要删除的目录路径
dir_path = '/path/to/your/directory/'
# 删除目录及其所有内容
try:
shutil.rmtree(dir_path)
print(f"目录'{dir_path}'及其所有内容已成功删除")
except FileNotFoundError:
print(f"目录'{dir_path}'不存在")
except PermissionError:
print(f"没有权限删除目录'{dir_path}'及其内容")
except Exception as e:
print(f"删除目录及其内容时发生错误: {e}")4.重命名文件和目录
使用os模块的rename()函数来重命名文件或目录。这个函数接受两个参数:源文件或目录的完整路径,以及目标文件或目录的新名称(也是完整路径)。如果目标文件或目录已经存在,rename()函数会将其替换。
示例代码
import os
# 重命名文件
source_file_path = "/path/to/original_filename.txt"
new_file_path = "/path/to/new_filename.txt"
os.rename(source_file_path, new_file_path)
# 如果源文件和目标文件在同一目录下,只需提供文件名
source_file_name = "old_name.txt"
new_file_name = "new_name.txt"
current_dir = os.getcwd() # 获取当前工作目录
os.rename(os.path.join(current_dir, source_file_name), os.path.join(current_dir, new_file_name))
# 重命名目录
source_dir_path = "/path/to/original_directory"
new_dir_path = "/path/to/new_directory"
os.rename(source_dir_path, new_dir_path)5.stat()函数返回的对象常用属性
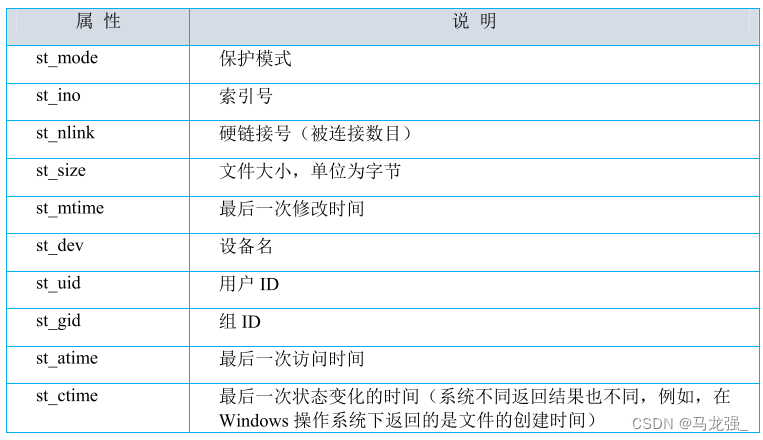
os.stat()函数用于获取文件或文件系统的状态信息,并返回一个包含多个属性的os.stat_result对象。这个对象的属性对应着文件的各种元数据,以下是其中一些常用的属性:
代码示例
import os
import time
import stat
file_info = os.stat('/path/to/some/file')
# 访问属性
mode = file_info.st_mode
inode_number = file_info.st_ino
size_bytes = file_info.st_size
last_access_time = time.ctime(file_info.st_atime)
modification_time = time.ctime(file_info.st_mtime)
# 检查文件类型
if stat.S_ISREG(file_info.st_mode):
print("这是一个普通文件")
elif stat.S_ISDIR(file_info.st_mode):
print("这是一个目录")
elif stat.S_ISLNK(file_info.st_mode):
print("这是一个符号链接")
else:
print("这是其他类型的文件或特殊文件")十、GUI界面编程
1.流行的GUI工具包
-
Tkinter:内置于Python的标准库中,是最容易上手且跨平台的GUI工具包,适合初学者和快速原型开发。
-
PyQt5:基于Qt库的Python绑定,提供丰富的组件和专业的外观,适用于开发复杂的桌面应用程序。Qt库的强大功能和跨平台特性使得PyQt5在专业应用中非常流行。
-
wxPython:另一个跨平台的GUI库,它利用wxWidgets C++库实现,同样支持丰富的UI组件和现代化的界面设计。
-
Kivy:面向触摸屏应用开发,特别适合创建移动应用和多点触控应用,支持iOS、Android、Windows、Linux和macOS等多个平台。
-
PySide2:类似于PyQt5,是Qt库的另一种Python绑定,遵循LGPL v3许可,也是一个功能齐全的跨平台GUI库。
-
PySimpleGUI:设计简洁,易于学习和使用,构建现代美观的GUI更加便捷,适合快速开发简单的桌面应用。
-
Gtk+ / PyGObject:GTK+是另一个流行的GUI工具包,PyGObject是其Python绑定,可用于创建原生外观的应用程序。
-
Electron + Flask + Python(非纯Python GUI库):Electron可以包装Python应用,并结合Flask等Web框架,实现跨平台的桌面应用程序开发,虽然这种方式并非传统意义上的GUI库,但在某些应用场景中也是一种可行方案。
-
DearPyGui:一个相对较新的库,以其快速且强大的可视化界面创建能力受到关注,尤其适合游戏开发人员快速搭建GUI界面。
十一、Python语言基础
1.保留字
Python中的保留字(也称为关键字)是那些在Python语言中有特殊含义和用途的词汇,它们不能用作变量名、函数名或者其他标识符。保留字列表会随着Python版本的更新可能会有所增减,不过在Python 3.x版本中,目前的保留字共有33个,以下是完整的Python 3保留字列表:
False # 布尔类型,表示假 None # 特殊类型,表示无值或null True # 布尔类型,表示真 and # 逻辑与运算符 as # 用于别名或导入时的指定别名 assert # 断言语句,检查条件是否满足,不满足时触发AssertionError async # 异步编程相关,用于定义异步函数或协程 await # 在异步上下文中等待协程的结果 break # 循环中断语句 class # 定义类的关键字 continue # 循环中跳过剩余语句,继续下一轮循环 def # 定义函数的关键字 del # 删除对象引用或从集合中删除元素 elif # 条件语句,else if的简写 else # 条件语句中,当if条件不满足时执行的代码块 except # 异常处理结构的一部分,捕获并处理异常 finally # 不论try-except是否捕获到异常都会执行的代码块 for # 迭代循环结构的关键字 from # 导入模块时指定来源的关键字 global # 声明全局变量的关键字 if # 条件判断的关键字 import # 导入模块的关键字 in # 成员关系测试及循环中迭代对象的关键字 is # 判断两个对象是否为同一对象或相等 lambda # 创建匿名函数的关键字 nonlocal # 在嵌套函数中引用外层函数变量的关键字 not # 逻辑非运算符 or # 逻辑或运算符 pass # 空语句,占位符,不做任何事 raise # 抛出异常的关键字 return # 从函数返回值的关键字 try # 尝试执行代码,并可捕获异常的关键字 while # 条件循环结构的关键字 with # 上下文管理协议,简化资源获取和释放的操作 yield # 在生成器函数中产生下一个值的关键字
2.转义字符

代码案例
print("Hello\nWorld")
"""
Hello
World
"""
print("Hello\0World") #Hello World
print("Hello\tWorld") #Hello World
print("He said, \"Hello!\"") #He said, "Hello!"
print('She said, \'Hi!\'') #She said, 'Hi!'
print("C:\\Users\\binjie09") #C:\Users\binjie09
print("Hello\fWorld") #HelloWorld
print("\011") #制表符
print("\x48\x65\x6c\x6c\x6f\x21") #Hello!
3.数据类型转换
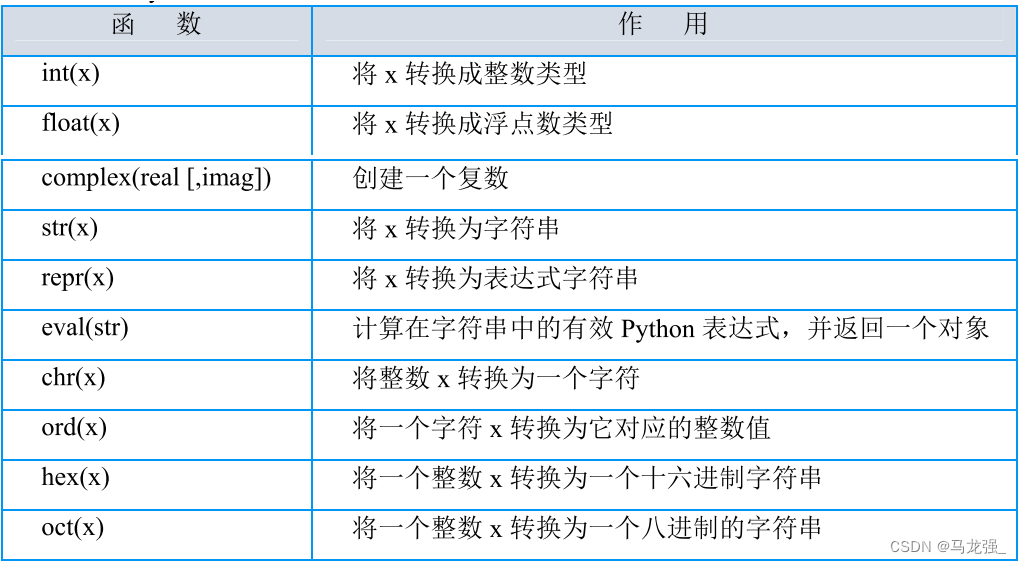
代码示例
x = 42
# 将x转换成整数类型
int_x = int(x)
print(int_x) # 输出:42
# 将x转换成浮点数类型
float_x = float(x)
print(float_x) # 输出:42.0
# 创建一个复数
complex_x = complex(3, 4)
print(complex_x) # 输出:(3+4j)
# 将x转换为字符串
str_x = str(x)
print(str_x) # 输出:"42"
# 将x转换为表达式字符串
repr_x = repr(x)
print(repr_x) # 输出:"42"
# 计算在字符串中的有效Python表达式,并返回一个对象
eval_x = eval("3 + 4")
print(eval_x) # 输出:7
# 将整数x转换为一个字符
chr_x = chr(x)
print(chr_x) # 输出:"*"
# 将一个字符x转换为它对应的整数值
ord_x = ord("A")
print(ord_x) # 输出:65
# 将一个整数x转换为一个十六进制字符串
hex_x = hex(x)
print(hex_x) # 输出:"0x2a"
# 将一个整数x转换为一个八进制的字符串
oct_x = oct(x)
print(oct_x) # 输出:"0o52"