Kafka
- Kafka
Kafka
Kafka的核心概念/ 结构
-
topoic
- Topic 被称为主题,在 kafka 中,使用一个类别属性来划分消息的所属类,划分消息的这个类称为 topic。topic 相当于消息的分配标签,是一个逻辑概念。主题好比是数据库的表,或者文件系统中的文件夹。
-
partition
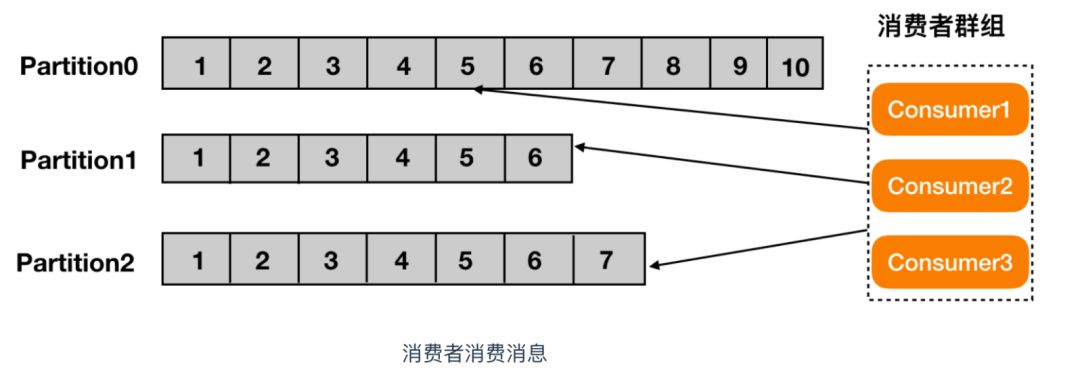
- partition 译为分区,topic 中的消息被分割为一个或多个的 partition,它是一个物理概念,对应到系统上的就是一个或若干个目录,一个分区就是一个
提交日志。消息以追加的形式写入分区,先后以顺序的方式读取。 - 注意:由于一个主题包含无数个分区,因此无法保证在整个 topic 中有序,但是单个 Partition 分区可以保证有序。消息被迫加写入每个分区的尾部。Kafka 通过分区来实现数据冗余和伸缩性
- 分区可以分布在不同的服务器上,也就是说,一个主题可以跨越多个服务器,以此来提供比单个服务器更强大的性能。
- partition 译为分区,topic 中的消息被分割为一个或多个的 partition,它是一个物理概念,对应到系统上的就是一个或若干个目录,一个分区就是一个
-
producer
- 生产者,即消息的发布者,其会将某 topic 的消息发布到相应的 partition 中。生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。不过,在某些情况下,生产者会把消息直接写到指定的分区。
-
consumer
- 消费者,即消息的使用者,一个消费者可以消费多个 topic 的消息,对于某一个 topic 的消息,其只会消费同一个 partition 中的消息
-
broker
-
Kafka 集群包含一个或多个服务器,每个 Kafka 中服务器被称为 broker。broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
broker 是集群的组成部分,每个集群中都会有一个 broker 同时充当了
集群控制器(Leader)的角色,它是由集群中的活跃成员选举出来的。每个集群中的成员都有可能充当 Leader,Leader 负责管理工作,包括将分区分配给 broker 和监控 broker。集群中,一个分区从属于一个 Leader,但是一个分区可以分配给多个 broker(非Leader),这时候会发生分区复制。这种复制的机制为分区提供了消息冗余,如果一个 broker 失效,那么其他活跃用户会重新选举一个 Leader 接管。
-
Kafka的应用场景
- 作为mq, 异步解耦削峰
- 活动跟踪, 实时检测, 将用户活动发布到中心topic上, 然后使用检测技术检测用户行为
- 日志聚合, 收集日志后, 提取出来进行流处理, 这样我们就可以自定义流来抽象我们的日志消息流
kafka为什么快
-
磁盘顺序读, 使得磁盘顺序寻址, 减少了时间
-
零拷贝 ->这个地方貌似还比较重要, 之后单独写一篇文章研究一下
-
消息可以分批发送,减少了网络传输和磁盘IO读写
- 在生产者生辰的时候, 消息不会立刻发送到kafka, 而是发送到生产者缓冲区, 封装成一个批次batch, 之后sender线程会从缓存中取出这些批次, 发送给kafka(batch有三个参数进行控制 : 累计消息数量+累计时间间隔+累计数据大小)
- 消费者消费的时候pull模式也可以自主决定是否批量从kafk拉取数据(但是如果kafka本身现在没有消息, 这个时候消费者会空转, kafka提供了参数可以让consumer阻塞直到新消息到达)
-
消息批量压缩
-
分区分段+索引
Kafaka中的Topic如何分区放置到不同的Broker
首先第一个分区放置的位置是从BrokerList中随机选择的
其他分区的位置, 会依次在这个位置向后偏移
Kafka中的topic中的partition数据是如何存储到磁盘
Topic中的partition是以文件夹的形式保存到Broker, 每个分区号从0递增, 且消息有序, Partition文件下有多个Segment(xxx.index, xxx.log), 分段, segment文件的大小和配置文件大小一致, 如果大小大于了1G, 就会滚动一个新的segment并且以上一个segment最后一条消息的偏移量命名
kafka为什么分区
- 方便在集群中扩展, 每个partiotion可以通过调整适应所在的机器, 而一个topic可以由多个partition组成, 所以整个集群可以适应任意大小的数据
- 提高并发, 因为可以通过partition为单位进行读写
- 为了提高Kafka处理消息吞吐量。假如同一个topic下有n个分区、n个消费者,每个分区会发送消息给对应的一个消费者,这样n个消费者就可以负载均衡地处理消息。同时生产者会发送消息给不同分区,每个分区分给不同的brocker处理,让集群平坦压力,这样大大提高了Kafka的吞吐量。
Consumer如何消费指定分区消息
Consumer消费消息的时候,可以发出fetch请求消费特定分区, 而且可以通过指定消息在日志中的偏移量offset, 可以从这个地方开始消费消息, 也可以消费以前消费过的消息, 甚至跳过一部分消息
kafka的ack的三种机制
request.required.acks有三个值0 1 -1(all)
1(默认):这意味着producer在ISR的leader已成功收到数据并得到确认,如果Leader宕机,则会丢失数据
0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但数据可靠性是最低的。
-1:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是这样也不能保证数据不丢失。比如当ISR中只有leader时,(ISR的成员由于某些情况会增加也会减少,最后就剩下一个leader),这样就变成ack=1的情况。
Kafka的手动提交和异步提交
partition中的offset用来记录我们消费的消息, 假设某一个消费者挂了, 这时候它所订阅的分区分摊给其他消费者, 如果分区中的offset因为没来得及消费就提交了offset或者消费了还没来得及提交offset, 就会导致消息重复消费/消息丢失
所以决定提交的时刻是十分重要的
-
自动提交偏移量
- 当enable.auto.commit被设置为true,提交方式就是让消费者自动提交偏移量,每隔5秒消费者会自动把从poll()方法接收的最大偏移量提交上去:
- 如果刚好到了5秒时提交了最大偏移量,此时正在消费中的消费者客户端崩溃了,就会导致消息丢失
- 如果成功消费了,下一秒应该自动提交,但此时消费者客户端奔溃了提交不了,就会导致其他分区的消费者重复消费
- Spring中使用commitSync()提交偏移量,commitSync()将会提交poll返回的最新的偏移量,所以在处理完所有记录后要确保调用了commitSync()方法。
-
手动提交
- 当enable.auto.commit被设置为false可以有以下三种提交方式
-
提交当前偏移量(同步提交) : 在broker对请求做出回应之前,客户端会一直阻塞,这样的话限制应用程序的吞吐量
-
异步提交 : 不会有吞吐量的问题。不过发送给broker偏移量之后,不会管broker有没有收到消息, 如果服务器返回提交失败,异步提交不会进行重试。如果同时存在多个异步提交,进行重试可能会导致位移覆盖。所以异步提交不会进行重试
-
同步和异步组合提交
先异步提交, 如果失败, 就trycatch兜底使用同步提交, 保证offset准确
kafka生产者生产过程, 消费模式
-
生产过程
- 消息首先会被封装成一个ProduceRecord对象
- 然后对消息进行序列化处理
- 对消息进行分区处理, 决定消息发向哪个主题的哪个分区
- 分好区后在Batch缓存中等待
- Sender线程启动将缓存中的数据批量发送到kafka---->发送的时候也是分为同步发送和异步发送的, 同步发送会等待结果, 异步发送会调用回调(异步回调可以在消息发送失败的时候记录日志)
-
消费模式
- 当Producer将消息推送到Broker之后, Consumer就会从Broker中获取消息
- 设置ConsumerConfig.DEFAULT_FETCH_MAX_WAIT_MS_CONFIG 阻塞等待消息
kafka怎么保证消息顺序性
Kafka分布式的单位是partition,同一个partition用一个write ahead log组织,所以可以保证FIFO的顺序。
不同partition之间不能保证顺序。因为同一个key的Message可以保证只发送到同一个partition。
Kafka中发送1条消息的时候,可以指定(topic, partition, key) 3个参数。partiton和key是可选的。如果你指定了partition,那就是所有消息发往同1个partition,就是有序的。
并且在消费端,Kafka保证,1个partition只能被1个consumer消费。或者你指定key(比如order id),具有同1个key的所有消息,会发往同1个partition。
Kafka如何实现延迟队列
-
使用kafka本身做延迟队列
- kafka本身没有延迟功能, 只是使用offset当作记录消息消费的位置
- 可以通过不断消费, 检测延时的时间有没有到达, 到达就消费数据, 没到达就把消息重新投递到partition中
- 但是这个消费不准确, 如果partiotion中的数据很多, 重新投递到分区的消息再次消费的时候可能远比设置的时间更久了
-
另外的方法并不是基于kafka本身实现的延迟队列
- 比如使用时间轮+kafka实现
- kafka+java delayqueue实现
- kafka+rockdb
Kafka的消息不漏发是如何实现的
- 个人认为消息完全不漏发是很难保证的, 毕竟从生产者到消费者消费的整个过程中, 存在着很多不确定因素
- 但是上面所说的, offset机制, 为了保证offset准确性而提到的手动提交,手动异步提交+同步提交
-
如果生产者发送到服务端kafka的时候, 失败了, 如何解决?
- 生产者使用异步回调, 记录失败的消息
- 使用消息确认机制, 确认所有partition的leader副本同步到消息之后, 才认为本次生产者发送消息成功
- 并且需要设置消息失败后生产者重试次数
- 本地也可以通过异常来定义消息日志表, 定期扫描这个表作为补偿
-
服务端broker如何保证消息不丢失?
- 服务端会将消息数据持久化保存到磁盘, 一般是先写入缓存然后刷盘, 如果刷盘失败, 消息丢失
- 这个时候可以使用同步刷盘(当生产者发送消息到broker端的时候,需要等待broker端把消息进行落盘之后,才会返回响应结果给生产者), 但是影响性能
- partition副本机制, 确保不止一个partition保存了消息
-
消费者端使用自动提交offset, 导致offset错误
- 设置手动提交
- 同时消费者端也需要进行幂等处理,防止重复消费 ->比如设置业务在数据库中的唯一约束, 或者在业务层面给消息加一个id, 作为去重
- 这里我们再想一个问题, 假如我整个kafka作为消息队列都挂了怎么办?那消息不是全部丢了吗?
- 这个时候一般会临时增加降级存储, 比如先起一个缓存, 把这些消息存储起来, 这个时候不断重试将消息推送到kafka中, 这样能够保证kafka能够第一时间消费到消息


![[C++]函数重载(什么是函数重载,函数重载的原理(底层怎么实现))](https://img-blog.csdnimg.cn/direct/f41a4f3553204bd39eea1541c6eb4aca.png)