利用人工智能(AI)技术预测未被充分监测的流域(ungauged watersheds)中的极端洪水事件
文章目录
- 利用人工智能(AI)技术预测未被充分监测的流域(ungauged watersheds)中的极端洪水事件
- 前言
- 一、论文主要内容
- 1.1 主要内容
- 1.2 主要数据
- 1.3 模型处理
- 二、论文相关的问答
- 2.1 数据分布如何
- 2.1 AI模型效果如何
- 2.1 为什么选择未被充分监测流域
- 2.1 LSTM模型的预测能力如何?
- 2.1 为什么会被选为nature
前言
介绍:
论文:Global prediction of extreme floods in ungauged watersheds
Github:https://github.com/tommylees112/neuralhydrology/tree/pixel
参考链接:https://mp.weixin.qq.com/s/GoOPqLtdYvPv3_no7GJUJQ
一、论文主要内容
1.1 主要内容
洪水影响:洪水是最常见的自然灾害之一,对发展中国家的影响尤为严重,因为这些国家往往缺乏密集的流量测量网络。准确及时的洪水预警对于减轻洪水风险至关重要。
AI预测模型:研究表明,基于人工智能的预测模型能够在没有长期数据记录的情况下,对未监测流域的极端河流事件进行可靠预测,预测时间可长达五天,与当前最先进的全球模型系统(Copernicus Emergency Management Service Global Flood Awareness System,简称GloFAS)的即时预报(零天预测时间)的可靠性相当或更好。
预测准确性:AI模型在预测一年至十年重现期事件的准确性与当前一年重现期事件的准确性相当或更好。这意味着AI可以为未监测流域提供更早的洪水预警,覆盖更大范围和更具影响力的事件。
实际应用:研究中开发的模型已被纳入一个实时预警系统,该系统在80多个国家提供公开可用的(免费和开放)实时预报。这些预报可以通过https://g.co/floodhub访问。
数据可用性:文章强调了增加水文数据可用性的重要性,以继续提高全球范围内可靠洪水预警的获取能力。
研究方法:AI模型使用长短期记忆(LSTM)网络,通过7天的预测时间范围预测日流量。模型的训练和测试使用了随机k折交叉验证,涵盖了5680个流量测量站的数据。
模型比较:与GloFAS相比,AI模型在不同重现期事件的预测中显示出更高的精确度和召回率。特别是在5年重现期事件的预测中,AI模型的表现优于GloFAS。
地理差异:两种模型在世界不同地区的可靠性存在差异。例如,在南美洲和西南太平洋地区,AI模型的表现与GloFAS存在显著差异。
预测可靠性:研究还探讨了在没有地面真实数据的地点评估预测可靠性的挑战,并尝试使用流域属性(地理、地球物理数据)来预测不同模型的可靠性。
1.2 主要数据
ECMWF Integrated Forecast System (IFS) High Resolution (HRES) atmospheric model: 提供了包括总降水量(TP)、2米温度(T2M)、地表净太阳辐射(SSR)、地表净热辐射(STR)、雪fall(SF)和地表压力(SP)等变量的日聚合单层预测数据。
ECMWF ERA5-Land reanalysis: 与上述HRES模型相同的六个变量。
NOAA Climate Prediction Center (CPC) Global Unified Gauge-Based Analysis of Daily Precipitation: 提供了降水估计数据。
NASA Integrated Multi-satellite Retrievals for GPM (IMERG) early run: 同样提供了降水估计数据。
HydroATLAS database: 提供了地质、地球物理和人为的流域属性数据。
所有输入数据都是根据每个测量站或预测点的上游总面积,对流域多边形进行面积加权平均处理。研究中使用的5680个评估测量站的上游总面积范围从2.1平方千米到4,690,998平方千米不等
1.3 模型处理
-
数据收集:首先,从各个数据源收集所需的气象数据、降水数据、流域属性数据以及流量测量数据。
-
数据整合:将收集到的数据整合到一起,确保它们具有相同的时间序列和空间分辨率。这可能涉及到数据的合并、对齐和匹配。
-
缺失值处理:对于缺失的数据,采用合适的插值方法进行填充。例如,可以使用其他数据源的相似变量数据进行替换,或者使用历史数据的平均值进行插值,并添加标记以示区分。
-
面积加权平均:对于流域属性数据,需要根据每个测量站上游的总面积进行面积加权平均,以得到代表整个流域的综合特征。
-
标准化:对所有数值型数据进行标准化处理,通常包括去除均值和除以标准差,以便在模型训练中减少不同特征量纲的影响。
-
特征选择:根据模型的需要,选择与洪水预测相关的特征。这可能包括气象数据中的降水量、温度等,以及流域属性数据中的流域面积、土壤类型等。
-
序列构建:将选定的特征按照时间序列顺序排列,构建成输入序列。对于LSTM模型,这通常包括一个固定长度的历史数据窗口,例如过去365天的数据。
-
目标变量定义:定义模型的输出目标,即未来一段时间内的流量预测。这可能涉及到将流量数据转换为适合模型学习的格式,例如,使用流量的对数变换来处理数据的偏态分布。
-
数据集划分:将整合和预处理后的数据划分为训练集和测试集。这通常涉及到时间序列的分割,确保训练集和测试集在时间上是不重叠的。
-
模型训练:使用处理好的训练数据集来训练LSTM模型。在训练过程中,模型会学习如何根据输入的历史数据来预测未来的流量。
-
交叉验证:为了评估模型的泛化能力,使用交叉验证技术来重复训练和测试过程,确保模型在不同的数据子集上都有稳定的表现。
-
性能评估:使用测试集数据评估模型的性能,计算精确度、召回率、F1分数等指标,以确定模型在预测洪水事件方面的准确性和可靠性。
二、论文相关的问答
2.1 数据分布如何
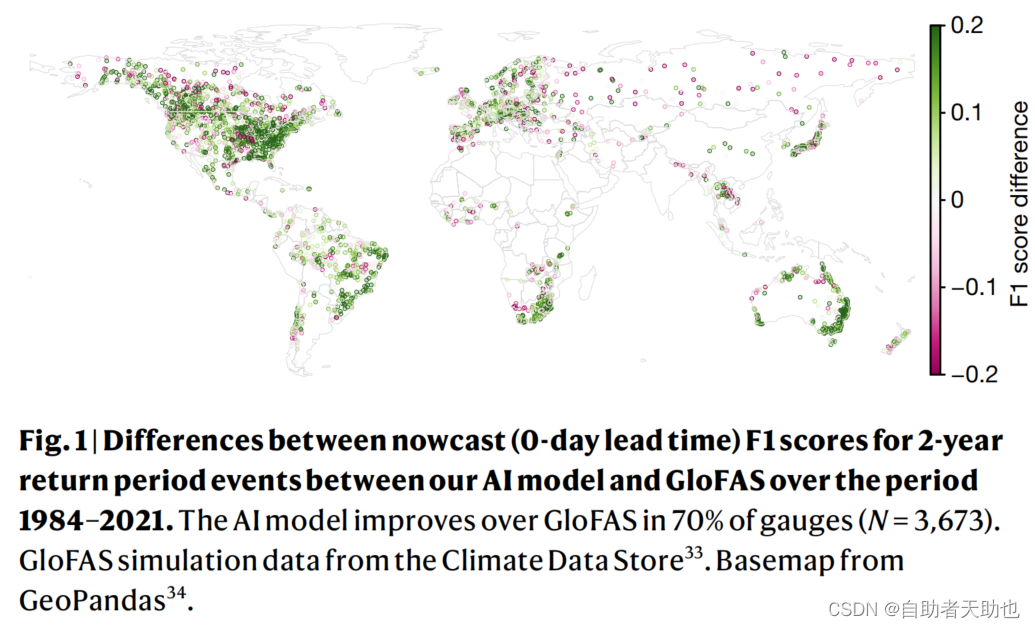
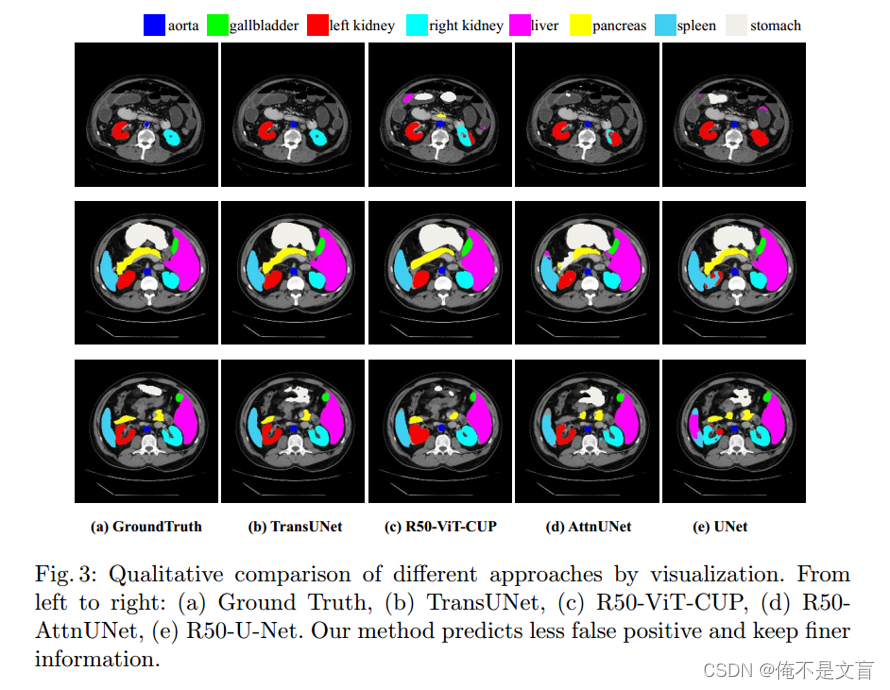
如图分析,从分布上分析,大部分数据分布在美洲和欧洲,尤其是北美地区,中国比较少,因此该实验不适合国情。
2.1 AI模型效果如何
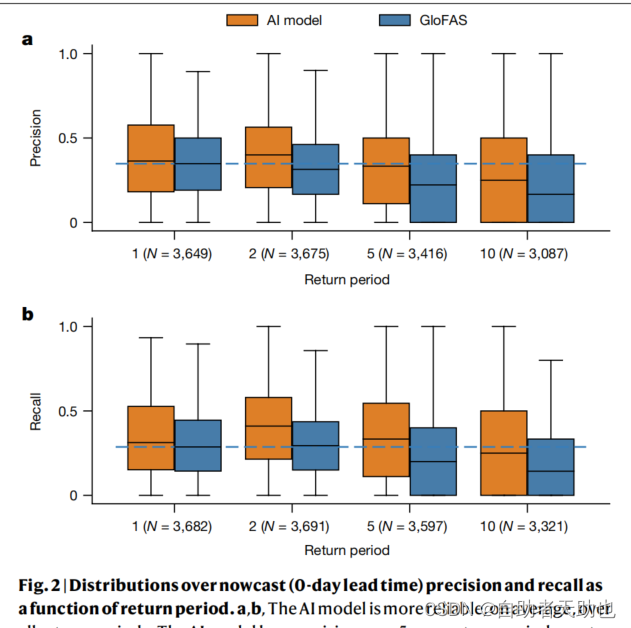
不管是目前在应用的全球洪水系统GloFAS还是AI模型预测的结果来说,分数都是低于0.5;AI模型的precision和recall的值域比GloFAS要大。时间越长,预测分数越低。
2.1 为什么选择未被充分监测流域
数据稀缺性:许多流域,尤其是在发展中国家,缺乏足够的流量测量站来提供长期的数据记录。
风险缓解需求:未被充分监测的流域往往位于易受洪水影响的地区,这些地区的居民和基础设施面临较高的洪水风险。
技术挑战:在未被充分监测的流域进行洪水预测是一个技术挑战,因为它要求模型能够在没有或只有很少现场数据的情况下进行准确预测。
模型泛化能力:通过在未被充分监测的流域上测试模型,可以评估模型的泛化能力,即模型在不同地理、气候和水文条件下的适用性和预测性能。
提高预测效率:开发能够在未被充分监测流域有效工作的洪水预测模型,可以减少对传统监测基础设施的依赖,提高预测效率,并降低在这些地区实施洪水预警系统的成本。
论文说是为了发展中国家进行分析,地图上的点上看都是发达国家的点,发达国家【69.4%】 发展中国家【31.6%】
2.1 LSTM模型的预测能力如何?
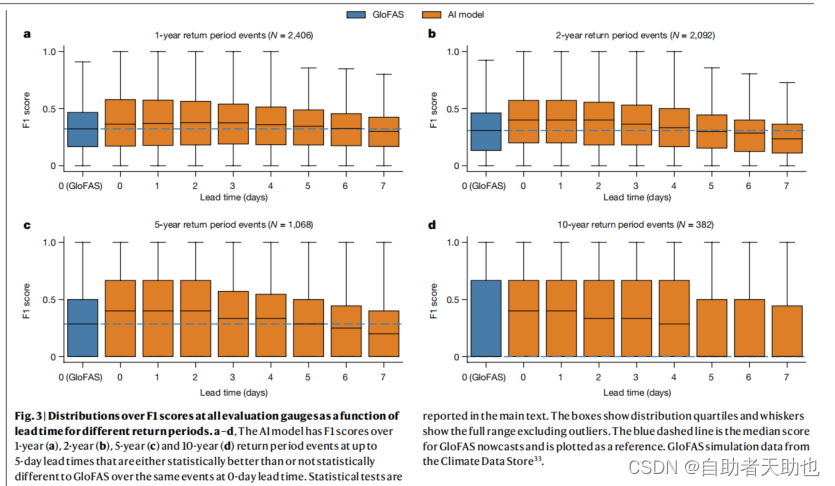
这些子图显示了在不同预测时间(从0天到5天)和不同重现期的洪水事件下,模型预测性能的变化。确实前5天的分数都是高于GloFAS。
2.1 为什么会被选为nature
创新性方法:用LSTM编码水文学、气象学的相关数据,并提供了一套标准化、合理化的清洗手段,来预测极端天气的内容
全球影响:洪水是全球性的问题,对人类社会和自然环境都有重大影响,虽然发达国家数据居多,但是发展中国家的数据也不少
数据稀缺性:该研究展示了在数据稀缺环境下,如何利用现有数据和AI技术提高预测能力,5680点位的数据是混合数据,有监测数据的内容也有合成的内容,其中一项挑战是去预测未监测流域的情况。
提高了风险预测的准确性:确实是高于GloFAS.
跨学科合作:该研究可能涉及气象学、水文学、数据科学、机器学习等多个学科的合作,这种跨学科的方法是解决复杂问题的重要途径。
项目还开源了:鼓励全球进行合作和提高行业的整体水平