文章汇总
文章是在总体上再一次地观察如何小样本领域存在的问题,并且发现了较为有趣的规律
1.测试误差随训练类别的数量而下降,而不是随每个类别的训练样本数量而下降。
2.训练算法(me:预训练模型)和自适应算法(me:预训练之后的微调)在少样本分类中完全不相关,这里的“完全不相关”是指任意一组自适应算法的性能排名不受训练算法选择的影响。
3.选择训练数据集的一部分来训练模型,或者如何在指定的适应场景中仅依靠少量数据从学习的模型中选择积极/有用的知识,是few-shot分类的一个重要研究方向。
4.自监督算法确实具有更好的泛化能力,少样本学习社区应该更加关注自监督学习的进展。
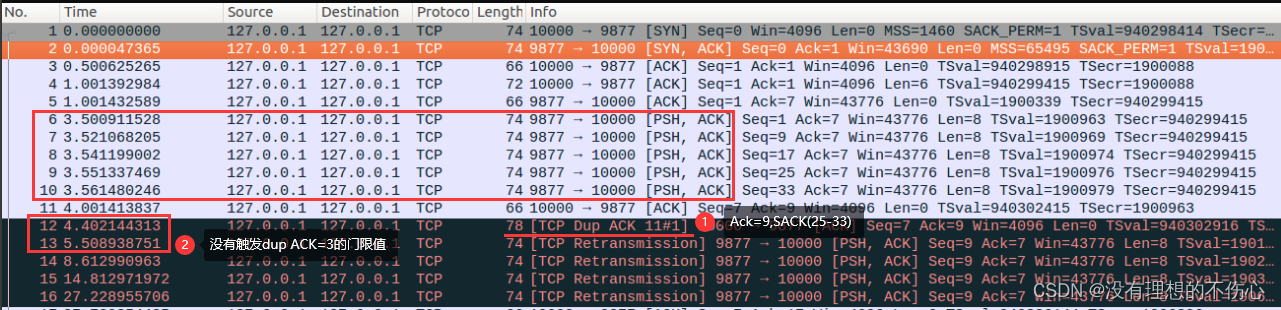
5.支持集的大小对于Finetune的有效性至关重要,当看到更多的数据时,主干可以更适当地调整。
6.miniImageNet(类似于CIFAR和tieredImageNet)的支持集大小很小,只有shot为5或25个,从训练数据集到测试数据集的分布偏移很小,而BSCD-FSL和元数据集的支持集大小大10倍,并且包含分布偏移非常大的数据集。作者向社会建议,一种方法除了报告标准的基准结果外,还应该报告不同的、具体的方式和镜头在不同分布偏移程度的数据集上的性能。
...
摘要
Few-shot分类包括训练阶段和适应阶段,前者在相对较大的数据集上学习模型,后者在有限的标记样本中适应以前未见过的任务。在本文中,我们通过经验证明了训练算法和自适应算法是可以完全分离的,这使得算法的分析和设计可以在每个阶段单独进行。
我们对每个阶段的荟萃分析揭示了一些有趣的见解,这些见解可能有助于更好地理解少镜头分类的关键方面以及与其他领域(如视觉表征学习和迁移学习)的联系。我们希望本文揭示的见解和研究挑战可以启发未来相关方向的工作。代码和预训练模型(在PyTorch中)可在GitHub - Frankluox/CloserLookAgainFewShot: [ICML 2023] A Closer Look at Few-shot Classification Again获得。
1. 介绍
在过去十年中,深度学习方法在大规模图像分类问题上取得了显著进展(Krizhevsky et al ., 2012;他等人,2016)。由于现实世界中有无限多的类别无法一次学习,因此图像分类成功后的愿望是使模型具备有效学习新视觉概念的能力。这种需求导致了少射分类(Fei-Fei et al ., 2006;Vinyals等人,2016)——学习一个能够适应仅给定少量标记样本的新分类任务的模型的问题。
这个问题可以自然地分为两个阶段:学习适应性模型的训练阶段和使模型适应新任务的适应阶段。为了使快速适应成为可能,人们自然会认为训练算法的设计要为算法的自适应使用做准备。为此,开创性作品(Vinyals et al ., 2016;Finn等人,2017;Ravi & Larochelle, 2017)用元学习框架形式化了这个问题,其中训练算法直接旨在以学习到学习的方式优化训练过程中的自适应算法。被元学习优雅的形式化和适合于少镜头学习的特性所吸引,许多后续作品设计了不同的元学习机制来解决少镜头分类问题。
然后,我们惊讶地发现,一个简单的迁移学习基线——使用训练集学习一个监督模型,并使用简单的自适应算法(例如,逻辑回归)对其进行调整——比所有元学习方法的表现都要好(Chen等人,2019;田等,2020;Rizve et al, 2021)。由于简单监督训练并不是专门为few-shot分类而设计的,因此这一观察结果表明,在设计训练算法时可以不考虑自适应算法的选择,同时也能获得令人满意的性能。在这项工作中,我们进一步提出以下问题:
训练算法(me:预训练模型)和自适应算法(me:预训练之后的微调)在少样本分类中完全不相关吗?这里的“完全不相关”是指任意一组自适应算法的性能排名不受训练算法选择的影响,反之亦然。
如果这是真的,那么寻找训练算法和自适应算法最佳组合的问题可以简化为分别优化训练算法和自适应算法,这可能会在很大程度上简化未来的算法设计过程。我们通过系统地研究了用于少射分类的各种训练和自适应算法,给出了肯定的答案。
这种“不相关”的特性也为我们提供了一个机会,通过固定另一个阶段的算法来独立分析一个阶段的算法。我们在第4节对训练算法和第5节对自适应算法进行这样的分析。通过改变训练阶段的数据集规模、模型架构和适应阶段的镜头、方式、数据分布等重要因素,我们得到了一些有趣的观察结果,这些观察结果导致了更深层次的了解少样本分类,揭示视觉表征学习与迁移学习文献之间的关键关系。这种元层次的理解可以为未来的少量学习研究提供帮助。对每个阶段的分析得出以下主要观察结果:
1. 在少样本分类中,我们观察到一种不同的神经尺度规律,即测试误差随训练类别的数量而下降,而不是随每个类别的训练样本数量而下降。这一观察结果突出了训练课程数量在少样本分类中的重要性,并可能有助于未来的研究进一步理解少射分类与其他视觉任务之间的关键区别。
2. 我们发现两个评估的数据集上,增加训练数据集的规模并不总是导致更好的少射性能。这表明,仅仅通过提供大量数据来训练一个可以很好地解决所有可能任务的模型是不现实的。这也说明了适当过滤训练知识对于不同的小样本分类任务的重要性。
3. 我们发现标准的ImageNet性能并不能很好地预测监督模型的少样本镜头性能(与之前在其他视觉任务中的观察结果相反),但它确实能很好地预测自监督模型。这一观察可能成为理解few-shot分类与其他视觉任务的区别,以及监督学习与自监督学习的区别的关键。
4. 我们发现,与使用少量样本对整个网络进行微调会导致严重过拟合的普遍观点相反,微调在所有自适应算法中表现最好,即使在数据极其稀缺的情况下,例如,5-way 1-shot任务。特别是,部分微调方法的设计,以克服香草微调的过拟合问题,在少样本的设置表现较差。微调的优势随着方法、镜头数量的增加和任务分配转移程度的增加而扩大。然而,微调方法具有极高的时间复杂度。
我们表明,这些因素的差异是不同的少样本镜头分类基准中最先进的方法在自适应算法中存在差异的原因。
2. 少样本分类问题的定义
3. 训练算法和自适应算法不相关吗?
给定一组训练算法和一组自适应算法
,如果从
更改算法不影响从
更改算法的性能排名,则我们说
不相关,反之亦然。为了给出一个精确的描述,我们首先定义一个偏序。
定义3.1:
我们说两个训练算法都有偏阶
,如果对于所有
,
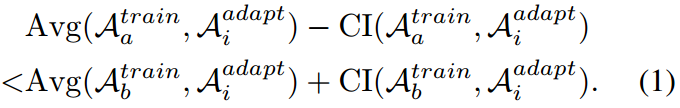
当使用中的每个自适应算法计算时,在
的置信区间内的值都大于或至少与
的置信区间有重叠时,这个不等式成立。这意味着,当与任意一种可能的自适应算法
结合使用时,有相当大的概率,训练算法
的性能并不比训练算法
差,因此两种训练算法的排名不受高概率自适应算法的影响。我们在这里用
代替来证明定义的偏序不是严格的,所以
同时成立,这意味着两种算法是可比较的。
中的偏序可以通过交换上面的训练和自适应算法来类似地定义。现在我们准备定义两组算法不相关的含义。
定义3.2:
如果和
在定义3.1中定义的偏序关系下都是有序集,则它们是不相关的。
现在,为了检验少镜头分类中的训练和自适应算法是否不相关,我们从以前的少镜头分类方法中选择了大量的训练和自适应算法,这些算法具有不同的训练数据集和网络架构,组成了。然后,我们分别对
的每对算法进行实验,检验这两个集合是否为有序集合。
算法评估
所选择的训练算法集Mtrain包含元学习和非元学习方法。
对于元学习方法,我们进行评估 MAML (Finn et al., 2017), ProtoNet (Snell et al.,2017), MatchingNet (Vinyals et al., 2016), MetaOpt (Lee et al., 2019), Feat (Ye et al., 2020), DeepEMD (Zhang et al.,2020) 和 MetaBaseline (Chen et al., 2021b);
对于非元学习方法,我们评估了监督算法,包括Cross-Entropy baseline (Chen et al., 2019), COS (Luo et al., 2021), S2M2 (Mangla et al., 2020), IER (Rizve et al.,2021), BiT (Kolesnikov et al., 2020), Exemplar v2 (Zhao et al., 2021) 和 DeiT (Touvron et al., 2021);
无监督算法包括MoCo-v2 (He et al, 2020)和DINO (Caron et al, 2021);
和多模态预训练算法CLIP (Radford et al, 2021)
涵盖了元学习方法,包括MatchingNet, MetaOpt,最近质心分类器(PN), Finetune (MAML);非元学习方法,包括逻辑回归(Tian等人,2020)、URL (Li等人,2021)、余弦分类器(Chen等人,2019);TSA (Li et al ., 2022b)和eTT (Xu et al ., 2022a)。
数据集
对于测试数据集,我们选择元数据集(Triantafillou等人,2020),这是一个数据集的数据集,涵盖了来自不同领域的10个不同的视觉数据集。我们从Meta-Dataset中删除ImageNet以避免训练中的标签泄漏。对于训练,我们选择了三个不同规模的数据集:miniImageNet的train split (Vinyals等人,2016)包含来自64个类的38400张图像,ImageNet的train split (Deng等人,2009)包含来自1000个类的100多万张图像,以及大型多模态数据集WebImageText (Radford等人,2021)包含4亿(图像,文本)对。为了完整起见,我们还在附录的表4-5中展示了传统的仅使用miniimagenet的实验。
结果
表1显示了和
算法成对组合的5-way 5-shot性能。
可以看出,训练算法和自适应算法根据定义3.2形成有序集:当我们固定任何自适应算法(表中的一列)时,从上到下,性能单调增加(或至少置信区间相交);类似地,自适应算法从左到右形成有序集合。one-shot的结果相似,见附录的表3。由于我们已经介绍了一堆有代表性的few-shot分类算法,我们可以大概率地说,在few-shot分类中,训练算法和自适应算法是不相关的。
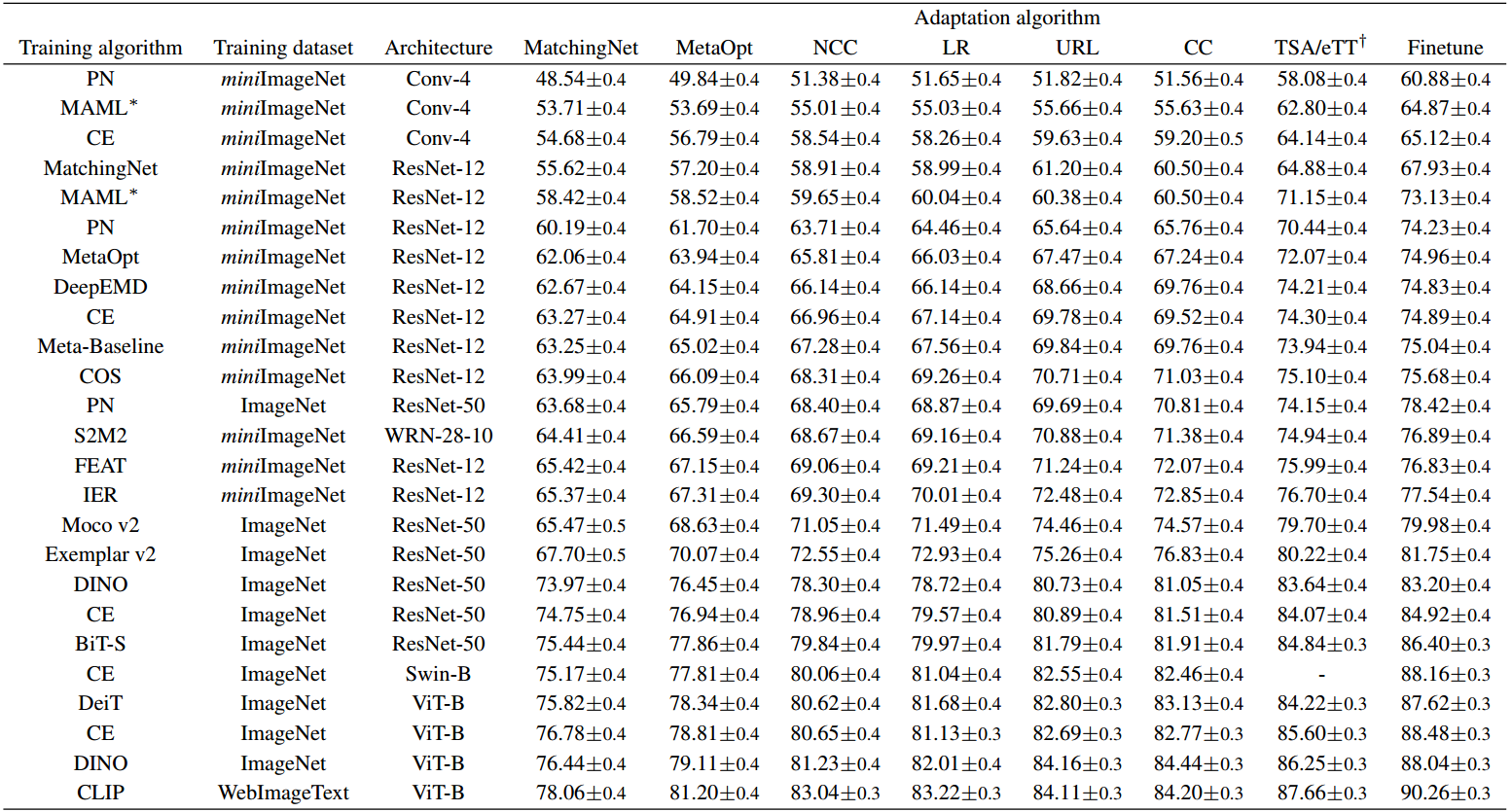
表1。多种训练和自适应算法的成对组合的少样本分类性能。所有评估任务都是从元数据集(不包括ImageNet)中采样的5-way 5-shot任务。我们在元数据集中对每个数据集抽样2000个任务,并报告所有数据集的平均准确率以及95%的置信区间。算法按照定义3.2从上到下、从左到右的偏序排列。*表示使用换能型BN的训练算法(Bronskill等人,2020),使用Fintune和TSA作为自适应算法产生更高、更不公平的性能。†:TSA和eTT都是特定于体系结构的部分微调算法,因此TSA只能用于CNN, eTT只能用于原始ViT。
评述
根据定义3.2,由于和
是不相关的,沿着有序集中的序列改变
或
中的算法总是会导致性能的提高。因此,在算法的任何一侧进行简单的贪婪搜索总是导致全局最优。一个直接的结果是,如果算法的两个阶段本身是最优的,那么它们的组合也是最优的。例如,从表1可以看出,对于Meta-Dataset上的5-way 5-shot任务,CLIP和Finetune分别是最优训练算法和最优自适应算法,它们的组合也成为最优组合。
这种算法的非纠缠性将大大简化少样本分类的算法设计过程。在在接下来的两节中,我们将首次分别分析算法的两个阶段,同时在另一个阶段中固定算法。
4. 训练分析
在本节中,我们将把自适应算法固定到最近质心分类器,并分析在少样本分类的训练过程中感兴趣的一些方面。根据第3节,如果我们改变自适应算法,观测值不会发生大概率变化。
4.1. 关于训练数据集的规模
我们首先感兴趣的是理解训练数据集的规模如何影响少样本分类性能。在few-shot分类中,由于训练和适应中的类不需要重叠,所以除了增加每个类的样本数量外,我们还可以通过增加训练类的数量来增加训练数据集的大小。这与标准的视觉分类任务不同,标准的视觉分类任务更感兴趣的是研究增加每个类别的样本数量的效果。
我们在ImageNet的训练集上进行了两种类型的缩放实验,ImageNet是一个标准的视觉数据集,总是被用作下游任务的预训练数据集。我们选择了三种具有代表性的训练算法,涵盖了主要的算法类型:
(1)交叉熵(Cross Entropy, CE)训练,即图像分类任务中的标准监督训练;
(2) ProtoNet (PN),一种广泛使用的元学习算法;
(3) MoCo-v2,一种强无监督视觉表示学习算法。对于每个数据集规模,我们随机选择样本或类5次,使用指定的训练算法训练模型,并报告5次训练试验的平均性能和标准方差。
我们选择的适配数据集包括来自Meta-Dataset和ImageNet标准验证集的9个数据集。我们在图1中绘制了对每个类的样本数量进行测距的结果,在图2中绘制了对类数量进行测距的结果。两个轴都以对数尺度绘制。我们还在附录的图8-9中报告了BSCD-FSL基准和DomainNet中另外9个数据集的评估结果。我们提出以下意见
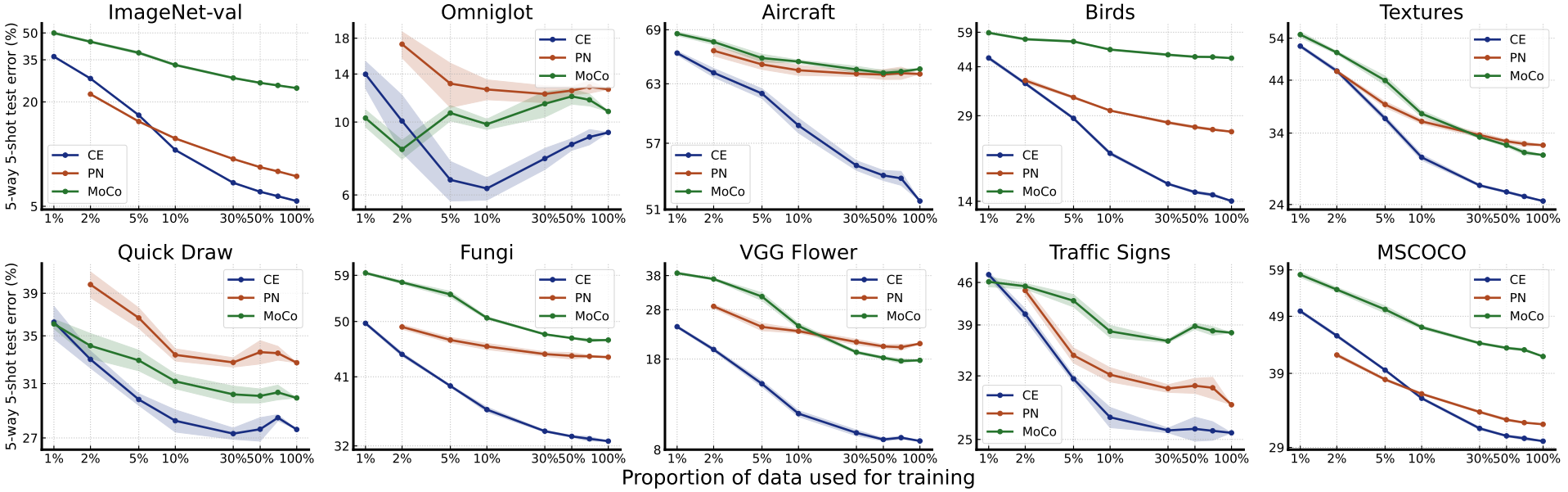
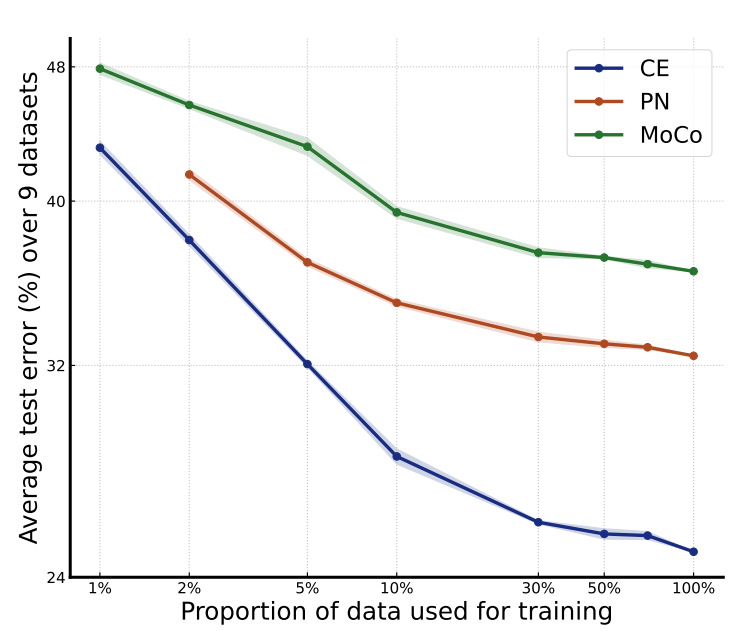
图1所示。每个训练类的样本量对少样本分类性能的影响。我们使用ImageNet训练集的所有1000个类进行训练。两个轴都是对数比例的。ImageNet-val是指对ImageNet的原始验证集进行少样本分类。平均性能是通过对9个数据集(不包括ImageNet-val)的性能进行平均得到的。彩色观看效果最佳。
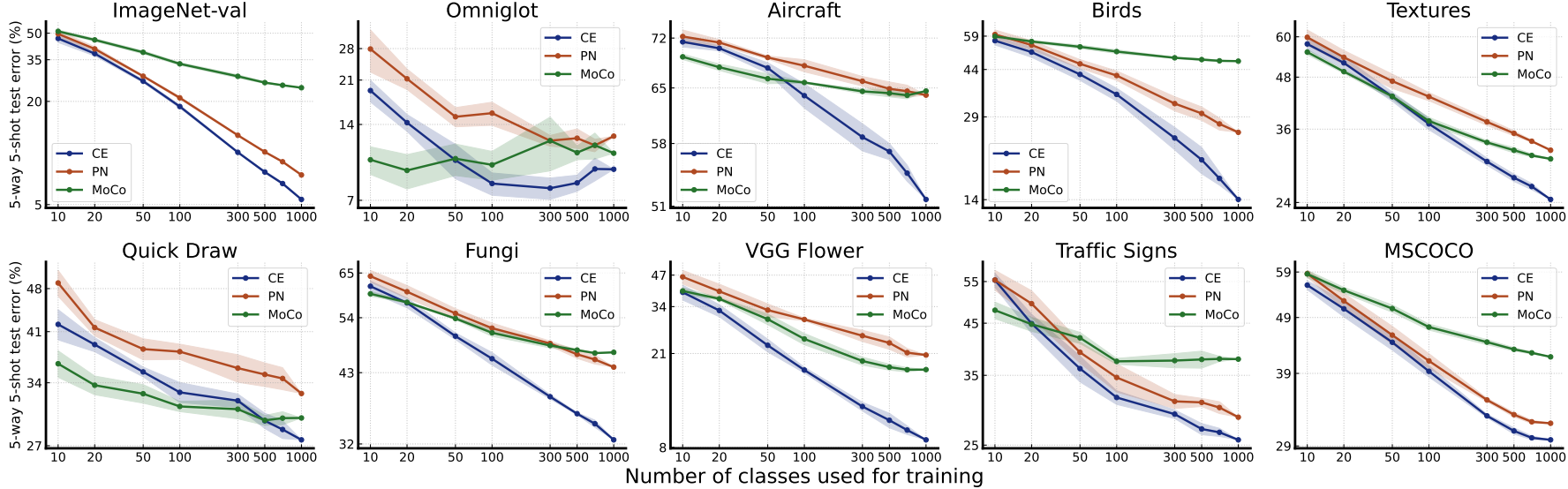

图2。训练班数对少射分类性能的影响。对于ImageNet中随机选择的每个类,我们使用来自训练集中的所有样本进行训练。两个轴都是对数比例的。最好以彩色观看。
Neural scaling laws for training.
对比图1和图2,我们可以看到,对于监督模型(CE和PN),增加类的数量比增加每个类的样本数量更有效(我们在附录的图10-12中给出了更清晰的比较)。增加每个类的样本数量的效果会很快趋于平稳,而增加类的数量会在所有尺度上带来非常稳定的性能改进。我们注意到图2中大多数PN和CE的性能曲线看起来都是一条直线。如图13-15所示,我们绘制线性拟合来验证我们的观察结果。实际上,训练班级数的对数标度与平均检验误差的对数标度之间的Pearson系数对于CE为- 0.999,对于PN为- 0.995,显示出很强的线性证据。这种线性表明了在几次分类中存在一种形式的神经标度定律:测试误差随着训练类别的数量而下降,这与在其他机器学习任务中观察到的神经标度定律不同(hetness等人,2017;翟等,2022;Kaplan等人,2020),测试误差随着每类训练样本的数量呈幂律下降。这种差异揭示了few-shot分类与其他任务之间的内在差异:虽然在训练类中看到更多的样本确实有助于识别同一类中的新样本,但在新任务中识别以前未见过的类可能没有太大帮助。另一方面,看到更多的类可能有助于模型学习更多潜在有用的知识,这些知识可能有助于区分新的类。
更大不一定更好
在大多数评估的数据集上,测试误差随着更多的训练样本/类而减少。然而,在Omniglot和ISIC(如图8-9所示)上,误差先下降,然后上升,特别是对于监督模型。相反,之前的研究(Snell et al, 2017)表明,一个简单的PN模型,无论是在Omniglot(类分离)上训练还是评估,都可以很容易地获得接近于零的误差。这表明,随着训练样本/类数量的增加,从ImageNet学习到的知识与在这两个数据集中区分新类所需的知识之间存在越来越大的不匹配。因此,在一个可以很好地解决所有可能任务的大数据集上训练一个大模型是不现实的,除非训练数据集已经包含了所有可能的任务。如何选择训练数据集的一部分来训练模型,或者如何在指定的适应场景中仅依靠少量数据从学习的模型中选择积极/有用的知识,是few-shot分类的一个重要研究方向。
CE训练效果更好
从两幅图可以看出,在小规模的训练数据上,PN和MoCo的表现与CE相当,但随着训练数据的增加,差距逐渐扩大。考虑到所有算法在训练过程中都被输入了相同的数据量,我们可以推断CE训练确实比PN和MoCo训练的可扩展性更好。这种趋势在细粒度数据集(包括Aircraft, Birds, Fungi和VGG Flower)中更为明显。
虽然这种现象需要进一步调查,但我们推测这是由于CE在训练过程中同时区分了所有的类,并且这需要区分所有可能的细粒度类。相反,像PN这样的元学习算法通常只需要区分每次迭代期间有限的类数量,MoCo等自监督模型不使用标签,因此更关注图像中的全局信息(Zhao et al ., 2021),在细粒度数据集上表现不佳。我们把它留给未来的工作来验证这个猜想是否普遍成立。
4.2. ImageNet性能vs Few-shot性能
然后,我们确定了训练数据集的规模,并研究了训练算法和网络架构的变化对少y样本性能的影响。我们特别关注CE训练和自监督模型,因为它们具有表1所示的优越性能。
先前的研究表明,在ImageNet上训练的CE模型的标准ImageNet性能是其在一系列视觉任务上的性能的强大预测因子(具有线性关系),包括迁移学习(Kornblith等人,2019),开放集识别(Vaze等人,2022)和域泛化(Taori等人,2020)。我们这里要问的是,这个观察结果是否也适用于少弹分类。如果这是真的,我们可以通过等待最先进的ImageNet模型,在使用ImageNet作为训练数据集(如Meta-Dataset)的基准测试上改进少量分类。为此,我们测试了36个具有不同网络架构的预训练监督CE模型,包括VGG (Simonyan & Zisserman, 2015)、ResNet (He等人,2016)、MobileNet (Howard等人,2017)、RegNet (Radosavovic等人,2020)、DenseNet (Huang等人,2017)、ViT (Dosovitskiy等人,2021)、Swin Transformer (Liu等人,2021b)和ConvNext (Liu等人,2022)。我们还使用不同的网络算法和架构测试了32个自监督ImageNet预训练模型。算法包括MoCo-v2 (He等人,2020)、MoCo-v3 (Chen等人,2021a)、InstDisc (Wu等人,2018)、BYOL (Grill等人,2020)、SwAV (Caron等人,2020)、OBoW (Gidaris等人,2021)、SimSiam (Chen等人,2021)、Barlow Twins (Zbontar等人,2021)、DINO (Caron等人,2021)、MAE (He等人,2022)、iBOT (Zhou等人,2022)和EsViT (Li等人,2022a)。我们使用KNN (Caron et al, 2021)来计算这些自监督模型的top-1精度。我们将监督模型的结果绘制在图3中,将自监督模型的结果绘制在图4中。
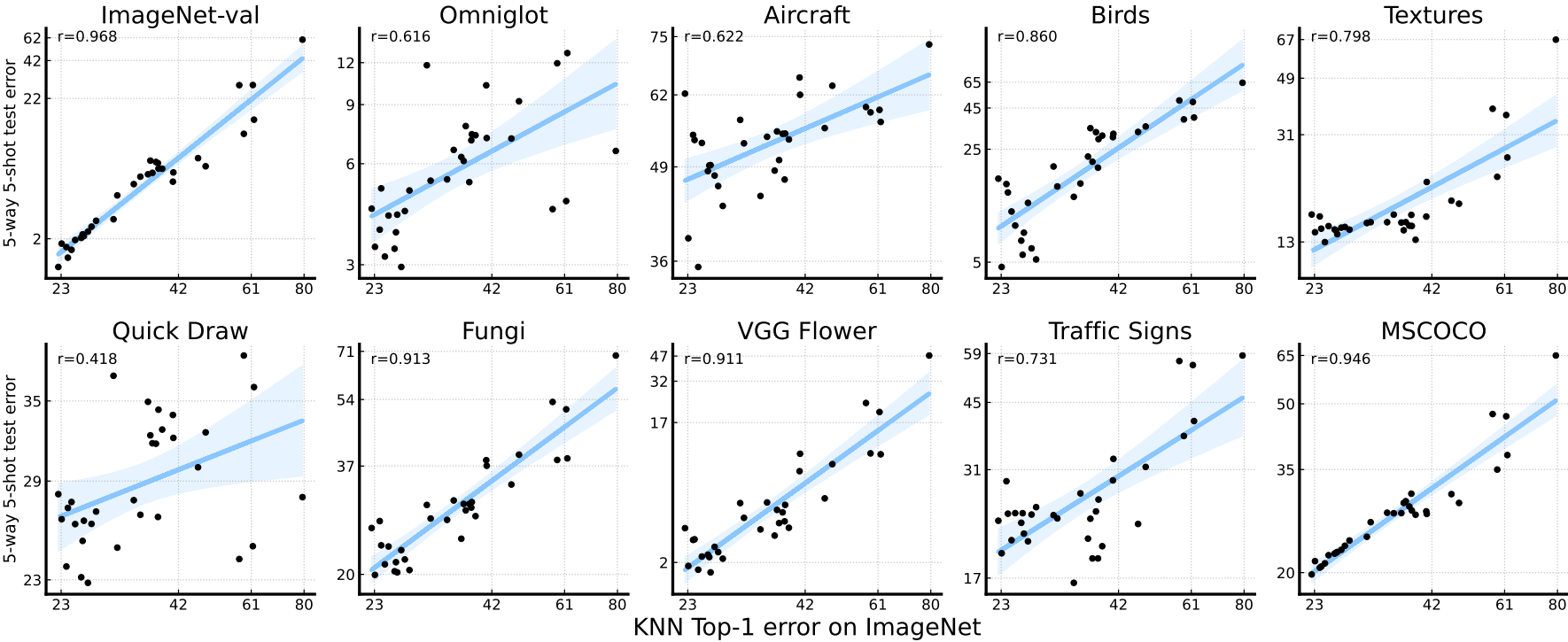
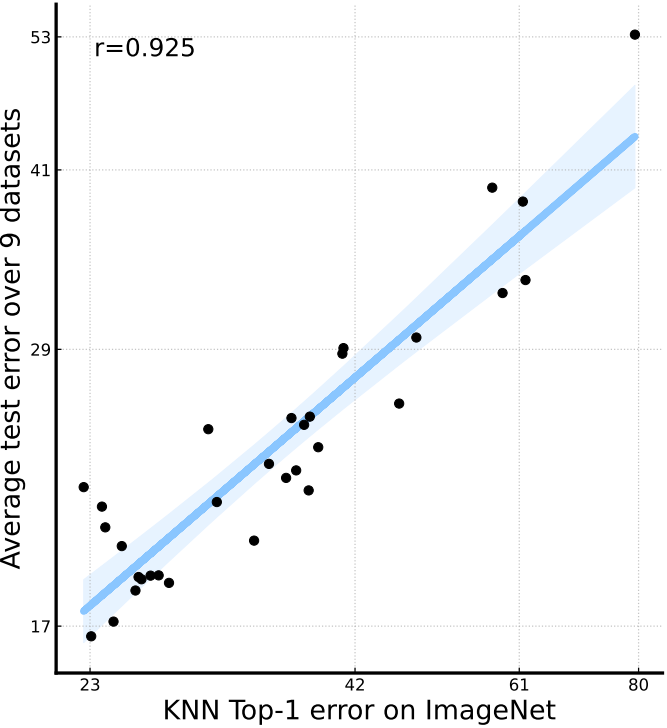
图4。对于自监督模型,ImageNet性能是一个很好的预测器。图中的每个点都是一个具有特定训练算法/架构的自监督模型。两个轴都是对数比例的。回归线和95%置信区间用蓝色表示。“r”表示两个数据轴之间的相关系数。
监督ImageNet模型过拟合到ImageNet性能
对于监督模型,我们可以从图3中观察到,在大多数与ImageNet差异足够大的数据集上,如Aircraft, Birds, Textures, Fungi, VGG Flower,随着ImageNet性能的提高,few-shot分类的测试误差先减小后增大。临界点在ImageNet上的Top-1误差约为23%,这是2017年最佳的ImageNet性能(例如,DenseNet (Huang et al, 2017))。这表明近年来ImageNet上图像分类的改进与ImageNet下游任务指定为少样本分类时的性能过拟合。我们还观察到,在像Quick Draw、Traffic Signs和Ominglot这样的数据集上,ImageNet性能和few-shot性能之间没有明确的关系。由于有监督的ImageNet性能通常是其他具有挑战性的视觉任务的一个强有力的预测器,所以少样本分类是一个特殊的任务,需要不同的和更好的泛化能力。识别差异背后的原因可能会导致对少镜头分类和视觉表征学习的更深入理解。
对于自监督模型来说,ImageNet性能是一个很好的少样本性能预测器
与监督模型不同的是,对于自监督模型,我们观察到ImageNet性能与few-shot分类性能之间存在明显的正相关关系。最好的自监督模型在ImageNet上仅获得77%的top-1准确率,但获得83%以上的平均少样本性能,优于所有评估的监督模型。因此,自监督算法确实具有更好的泛化能力,少样本学习社区应该更加关注自监督学习的进展。
5. 适应性分析
在本节中,我们将训练算法固定为在miniImageNet上训练的CE模型,并分析自适应算法。
5.1. Way and Shot Analysis
way和shot是小样本分类适应阶段的重要变量。这是我们第一次分析在训练算法不变的情况下,不同的自适应算法在不同的方式和镜头选择下的性能变化情况。在本实验中,我们选择ImageNet和Quick Draw作为评估的数据集,因为这两个数据集有足够的类和每个类的图像进行采样,并且分别代表域内和域外数据集。对于ImageNet,我们从miniImageNet中移除所有类。
Neural scaling laws for adaptation
我们注意到,对于Logistic回归、Finetune和MetaOPT,当改变shot次数时,性能曲线近似于直线。这表明,对于自适应数据集的尺度,分类误差遵循传统的神经尺度规律(与我们在4.1节中发现的训练数据集的尺度不同)。虽然这对Finetune来说似乎是一个合理的现象,但我们发现逻辑回归和MetaOpt是一个惊喜,这是基于冻结特征构建的线性算法(用于适应),因此预计会很快达到性能饱和。
这表明,即使是在miniImageNet上训练的小规模模型,对于新任务,学习到的特征仍然是相当线性可分的。然而,它们的增长率不同,表明它们的规模能力不同。
主干自适应适用于高速、高目标或跨域任务
从图5可以看出,虽然Finetune和部分Finetune算法TSA在ImageNet上的1-shot和5 -shot任务上并没有明显优于其他算法,但当镜头或方式增加或任务在Quick Draw上进行时,它们的优势会变得更大。因此,我们可以推断,当数据规模足够大以避免过拟合时,或者当域移动太大以至于学习到的特征空间在新域上变形时,首选backbone自适应。

图5。基于ImageNet和Quick Draw的自适应算法的方法和实例实验。对于shot实验,我们将shot固定为5次并显示测试误差,对于射击实验,我们将射击次数固定为5次并显示测试精度。两个轴都是对数比例的。
查询支持匹配算法伸缩性差
查询支持匹配算法(如TSA、MatchingNet、NCC和URL)通过比较查询特征与支持特征的相似性来获得查询预测,不同于从其他直接从支持集学习分类器的算法。如图5所示,当shot为1或5时,所有这些算法都表现良好,但随着shot次数的增加,除Quick Draw上的TSA外,这些算法的尺度都弱于幂律,在这种情况下主干自适应更受欢迎。考虑到URL作为一种灵活的、可优化的线性头部,TSA作为一种局部微调算法具有足够的适应能力,但它们不能很好地扩展,特别是在ImageNet上,说明查询支持匹配算法的目标在数据规模增加时,在适应过程中存在根本性的优化困难。
5.2. 微调分析
从表1和图5可以看出,vanilla Finetune算法的性能总是最好的,即使是在数据极其稀缺的域内任务上进行评估时也是如此。特别是,我们已经表明,最近的部分微调算法,如TSA和eTT,旨在克服这个问题,都不如finetune算法。这是相当令人惊讶的,因为最初的元数据集基准(Triantafillou等人,2020)表明,当数据极其稀缺时,Finetune会遇到严重的过拟合。
原因有两个方面。首先,在Meta-Dataset的原始论文中,训练算法和自适应算法是绑定在一起的,所以不同的自适应算法使用不同的主干,使得比较不公平。这个问题随后在TSA和eTT的论文中被放大,他们在基准测试中复制Finetune的原始结果的同时,为自己的自适应算法使用了强主干。其次,以前的作品通常为Finetune寻找一个单一的学习率。我们发现分别搜索脊骨和线性头部的学习率是很重要的。这个简单的更改带来了相当大的性能改进,如图6所示。我们发现脊柱的最佳学习率通常比线性头部的最佳学习率要小得多。
我们也想知道是什么关键因素,使Finetune有效。在图7中,我们展示了当我们增加支持集中的样本总数(方式×镜头)时,Finetune相对于PN的改进是如何变化的。只要支持集大小不改变,所有选择的方法的相对改进都相当接近。因此,支持集的大小对于Finetune的有效性至关重要,这与我们的直觉一致,当看到更多的数据时,主干可以更适当地调整。
Bias of evaluation protocols in different benchmarks
在分析了Finetune的有效性之后,我们现在可以回答一个问题:为什么在传统的基准测试中,如CIFAR, miniImageNet, tieredImageNet,最先进的算法在适应过程中不适应学习主干,而在BSCD-FSL和元数据集模型适应等基准测试中却变得流行?从表2中可以看出,miniImageNet(类似于CIFAR和tieredImageNet)的支持集大小很小,只有5或25个,从训练数据集到测试数据集的分布偏移很小,而BSCD-FSL和元数据集的支持集大小大10倍,并且包含分布偏移非常大的数据集。因此,根据我们的分析,Finetune等骨干自适应算法在miniImageNet等基准上没有优势,特别是在学习率没有分离的情况下;而在BSCD-FSL和元数据集上,主干需要适应新的领域,丰富的支持样本使这成为可能。为了避免评估的偏差,我们向社会建议,一种方法除了报告标准的基准结果外,还应该报告不同的、具体的方式和镜头在不同分布偏移程度的数据集上的性能。
6. 相关工作
作为一个活跃的研究领域,few-shot学习被认为是构建高效类脑机器的关键一步(Lake et al, 2017)。元学习(Thrun & Pratt, 1998;Schmidhuber, 1987;Naik & Mammone, 1992)被认为是实现这一目标的理想框架。在这个框架下,方法可以大致分为三个分支:基于优化的方法、黑盒方法和基于度量的方法。基于优化的方法,主要起源于MAML (Finn et al, 2017),学习如何在给定几个训练样本的情况下优化神经网络的经验。这个方向的变体考虑元学习优化的不同部分,包括模型初始化点(Finn et al ., 2017;Rusu等人,2019;Rajeswaran等人,2019;Zintgraf et al, 2019;Jamal & Qi, 2019;Lee等人,2019),优化过程(Ravi & Larochelle, 2017;Xu et al ., 2020;Munkhdalai & Yu, 2017;Li et al, 2017)或两者兼而有之(Baik et al, 2020;Park & Oliva, 2019)。黑盒方法(Santoro et al ., 2016;Garnelo et al, 2018;Mishra等人,2018;Requeima等人,2019)直接将学习过程建模为没有显式归纳偏差的神经网络。基于度量的方法(Vinyals等,2016;Snell等,2017;Sung等,2018;Yoon等人,2019;Zhang等人,2020)元学习是一种特征提取器,它可以产生具有预定义度量的形状良好的特征空间。在少量图像分类的背景下,目前最先进的元学习方法主要分为基于度量的和基于优化的。
最近,一些利用监督学习的非元学习方法(Chen et al ., 2019;田等,2020;Dhillon等,2020;Triantafillou等,2021;Li et al, 2021)或无监督表示学习方法(Rizve et al, 2021;Doersch等,2020;Das等,2022;Hu et al ., 2022;Xu等人,2022a)训练特征提取器的方法已经出现,用于处理少镜头图像分类。此外,一堆元学习方法(Chen et al ., 2021b;Zhang等,2020;Hu et al ., 2022;Ye等人,2020)学习从预训练主干初始化的模型(我们的实验还考虑了预训练+元学习训练算法,如Meta-Baseline、DeepEMD和FEAT。因此,我们的结论普遍成立)。由于这些方法并不严格遵循元学习框架,因此训练算法与自适应算法不一定有关系,而且它们比元学习方法更简单、更高效,同时取得更好的性能。沿着这条线,本文进一步揭示了在少拍图像分类中,训练阶段和自适应阶段是完全分离的。
一项相关工作(Sbai et al ., 2020)也对few-shot学习进行了详细而全面的分析,特别是对训练过程进行了分析。我们的研究在几个方面补充了这项工作:(1)我们发现的神经尺度定律之前没有被发现,这证明了类数在少拍学习中的重要性。虽然在Sbai et al(2020)中也从不同的角度讨论了班级数量的重要性,但在Sbai et al(2020)中没有明确的结论,因此我们对他们的研究进行了补充;(2)我们观察到,更大的数据集可能会导致特定下游数据集的性能下降,无论是在增加类别数量还是每个类别的样本数量方面。这些发现在Sbai等人(2020)中没有出现,因此我们的研究通过检查特定的数据集为未来的研究开辟了新的途径;(3) Sbai et al(2020)没有明确的证据表明简单监督训练的可扩展性优于其他类型的训练算法;(4)此外,本文还对18个数据集进行了评估,包括ImageNet和CUB之外的数据集,这是Sbai et al .(2020)中唯一研究的数据集。因此,我们的研究提供了一个更广阔的视角,并补充了Sbai等人(2020)的分析。
7. 讨论
从我们的分析中得到的一个教训是,仅通过缩放模型和数据集进行训练并不是一个万能的解决方案。训练目标的设计要么考虑自适应数据集是什么(而不是自适应算法),要么自适应算法选择准确的感兴趣的训练知识。前一种方法将训练的模型限制在特定的目标领域,而后一种方法在目标任务中提供的标记数据很少的情况下,由于分布估计的偏差,使得知识选择困难甚至不可能实现(Luo et al, 2022;Xu et al ., 2022b)。
我们应更加努力地将训练数据与适应所需的数据结合起来。尽管我们已经证明了vanilla Finetune的表现如此之好,但我们认为这种蛮力、非选择性模型自适应算法并不是最终的解决方案,而且它还有其他缺点,如具有极高的自适应成本,如附录d所示。从另一个角度来看,我们的工作指出了使用few-shot分类作为更好地理解一般视觉表示学习的一些关键方面的工具的可行性。
参考资料
论文下载(ICML(CCF A) 2023)
https://arxiv.org/abs/2301.12246

代码地址
GitHub - Frankluox/CloserLookAgainFewShot: [ICML 2023] A Closer Look at Few-shot Classification Again