1.读excel
1.to_dict() 函数基本语法
DataFrame.to_dict
(self,
orient='dict'
,
into=
) --- 官方文档
函数种只需要填写一个参数:orient 即可 ,但对于写入orient的不同,字典的构造方式也不同,官网一共给出了6种,并且其中一种是列表类型:
- orient ='dict',是函数默认的,转化后的字典形式:{column(列名) : {index(行名) : value(值) )}};
- orient ='list' ,转化后的字典形式:{column(列名) :{[ values ](值)}};
- orient ='series' ,转化后的字典形式:{column(列名) : Series (values) (值)};
- orient ='split' ,转化后的字典形式:{'index' : [index],‘columns' :[columns],’data‘ : [values]};
- orient ='records' ,转化后是 list形式:[{column(列名) : value(值)}......{column:value}];
- orient ='index' ,转化后的字典形式:{index(值) : {column(列名) : value(值)}};
备注:
1,上面中 value 代表数据表中的值,column表示列名,index 表示行名,如下图所示:
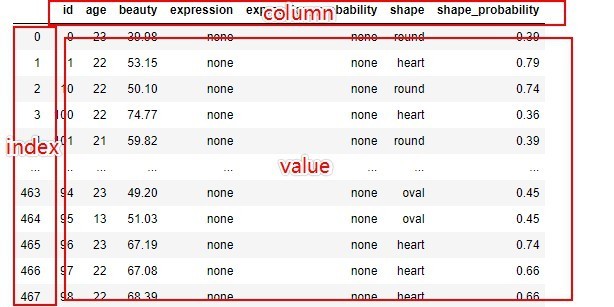
2,{ }表示字典数据类型,字典中的数据是以 {key : value} 的形式显示,是键名和键值一一对应形成的。
2,关于6种构造方式进行代码实例
六种构造方式所处理 DataFrame 数据是统一的,如下:
-
>>> import pandas as pd -
>>> df =pd.DataFrame({'col_1':[1,2],'col_2':[0.5,0.75]},index =['row1','row2']) -
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75
2.1,orient ='dict' — {column(列名) : {index(行名) : value(值) )}}
to_dict('list') 时,构造好的字典形式:{第一列的列名:{第一行的行名:value值,第二行行名,value值},....};
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('dict') -
{'col_1': {'row1': 1, 'row2': 2}, 'col_2': {'row1': 0.5, 'row2': 0.75}}
orient = 'dict 可以很方面得到 在某一列对应的行名与各值之间的字典数据类型,例如在源数据上面我想得到在col_1这一列行名与各值之间的字典,直接在生成字典查询列名为col_1:
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('dict')['col_1'] -
{'row1': 1, 'row2': 2}
2.2,orient ='list' — {column(列名) :{[ values ](值)}};
生成字典中 key为各列名,value为各列对应值的列表
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('list') -
{'col_1': [1, 2], 'col_2': [0.5, 0.75]}
orient = 'list' 时,可以很方面得到 在某一列 各值所生成的列表集合,例如我想得到col_2 对应值得列表:
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('list')['col_2'] -
[0.5, 0.75]
2.3,orient ='series' — {column(列名) : Series (values) (值)};
orient ='series' 与 orient = 'list' 唯一区别就是,这里的 value 是 Series数据类型,而前者为列表类型
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('series') -
{'col_1': row1 1 -
row2 2 -
Name: col_1, dtype: int64, 'col_2': row1 0.50 -
row2 0.75 -
Name: col_2, dtype: float64}
2.4,orient ='split' — {'index' : [index],‘columns' :[columns],’data‘ : [values]};
orient ='split' 得到三个键值对,列名、行名、值各一个,value统一都是列表形式;
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('split') -
{'index': ['row1', 'row2'], 'columns': ['col_1', 'col_2'], 'data': [[1, 0.5], [2, 0.75]]}
orient = 'split' 可以很方面得到 DataFrame数据表 中全部 列名或者行名 的列表形式,例如我想得到全部列名:
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('split')['columns'] -
['col_1', 'col_2']
2.5,orient ='records' — [{column:value(值)},{column:value}....{column:value}];
注意的是,orient ='records' 返回的数据类型不是 dict ; 而是list 列表形式,由全部列名与每一行的值形成一一对应的映射关系:
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('records') -
[{'col_1': 1, 'col_2': 0.5}, {'col_1': 2, 'col_2': 0.75}]
这个构造方式的好处就是,很容易得到 列名与某一行值形成得字典数据;例如我想要第2行{column:value}得数据:
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('records')[1] -
{'col_1': 2, 'col_2': 0.75}
2.6,orient ='index' — {index:{culumn:value}};
orient ='index'与2.1用法刚好相反,求某一行中列名与值之间一一对应关系(查询效果与2.5相似):
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('index') -
{'row1': {'col_1': 1, 'col_2': 0.5}, 'row2': {'col_1': 2, 'col_2': 0.75}} -
-
#查询行名为 row2 列名与值一一对应字典数据类型 -
>>> df.to_dict('index')['row2'] -
{'col_1': 2, 'col_2': 0.75}
2.写excel
1.pd.DataFrame.from_records例子:
数据可以作为结构化的 ndarray 提供:
>>> data = np.array([(3, 'a'), (2, 'b'), (1, 'c'), (0, 'd')],
... dtype=[('col_1', 'i4'), ('col_2', 'U1')])
>>> pd.DataFrame.from_records(data)
col_1 col_2
0 3 a
1 2 b
2 1 c
3 0 d数据可以作为字典列表提供:
>>> data = [{'col_1': 3, 'col_2': 'a'},
... {'col_1': 2, 'col_2': 'b'},
... {'col_1': 1, 'col_2': 'c'},
... {'col_1': 0, 'col_2': 'd'}]
>>> pd.DataFrame.from_records(data)
col_1 col_2
0 3 a
1 2 b
2 1 c
3 0 d数据可以作为具有相应列的元组列表提供:
>>> data = [(3, 'a'), (2, 'b'), (1, 'c'), (0, 'd')]
>>> pd.DataFrame.from_records(data, columns=['col_1', 'col_2'])
col_1 col_2
0 3 a
1 2 b
2 1 c
3 0 d2.pd.DataFrame.from_dict例子
代码
# -*- coding: utf-8 -*-
import xlrd
import os
import pandas as pd
class ExcelReader:
def __init__(self, config):
"""
filepath: str
sheetnames: list
header_index : int
"""
self.path = config['filepath']
self.sheetnames = config.get('sheetnames',0)
header_index = config.get('header_index',0)
self.data = {}
if not self.sheetnames:
data_xls = pd.read_excel(self.path, sheet_name=0, header=header_index, )
data_xls.fillna("", inplace=True)
self.data[0] = data_xls.to_dict('records')
else:
for name in self.sheetnames:
#每次读取一个sheetname内容
data_xls = pd.read_excel(self.path,sheet_name=name,header=header_index,)
data_xls.fillna("",inplace=True)
self.data[name] = data_xls.to_dict('records')
class ExcelWriter:
"""
支持多写一个表格多个sheet
"""
def __init__(self,config):
self.path = config['filepath'] # str 路径
self.sheetnames = config.get('sheetnames') # list sheet name
if not self.sheetnames:
self.sheetnames = []
self.writer = pd.ExcelWriter(self.path)
self.data = {} #key --sheet_name value -- sheet data: dict:
for name in self.sheetnames:
self.data[name] = {}
def to_excel(self, sheet_name=None, startrow=0, index=False):
if not sheet_name:
for name in self.sheetnames:
df = pd.DataFrame.from_records(self.data[name])
df.to_excel(self.writer, sheet_name=name, startrow=startrow, index=index)
else:
df = pd.DataFrame.from_records(self.data[name])
df.to_excel(self.writer, sheet_name=sheet_name, startrow=startrow, index=index)
def write_row(self, sheet_name, row_data: dict):
"""
sheet_name: sheet_name 可以为不存在self.sheet_name中的值
"""
if sheet_name not in self.data:
self.sheet_name.append(sheet_name)
self.data[sheet_name] = {}
for col in row_data:
self.data[sheet_name][col] = [row_data[col]]
return
if not self.data[sheet_name]:
for col in row_data:
self.data[sheet_name][col] = [row_data[col]]
else:
for col in self.data[sheet_name]:
self.data[sheet_name][col].append(row_data.get(col,''))
def save(self):
"""
保存并关闭
"""
self.to_excel() #数据写入excel对象内
self.writer.save() #保存并关闭
参考:
pandas 读取excel、一次性写入多个sheet、原有文件追加sheet_pandas 写入多个sheet-CSDN博客