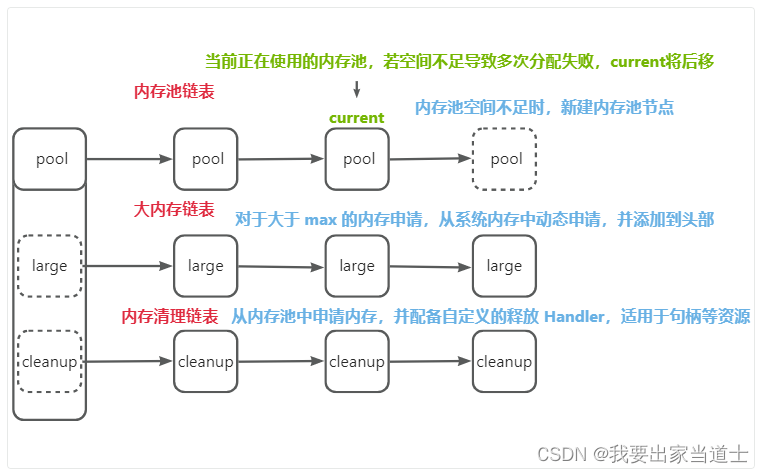
一、mysql中的锁有哪些?
1.1 锁的类型
(1)共享锁(Shared Lock): 共享锁允许事务读取数据,但不允许其他事务修改数据。多个事务可以同时持有共享锁。
-- 事务A获取共享锁
START TRANSACTION;
SELECT * FROM table_name WHERE column_name = 'value' LOCK IN SHARE MODE;
-- 事务B也可以获取共享锁
START TRANSACTION;
SELECT * FROM table_name WHERE column_name = 'value' LOCK IN SHARE MODE;
(2)排他锁(Exclusive Lock): 排他锁用于写操作,只有一个事务能持有排他锁,其他事务无法同时持有共享锁或排他锁。
-- 事务A获取排他锁
START TRANSACTION;
UPDATE table_name SET column_name = 'new_value' WHERE id = 1 FOR UPDATE;
-- 事务B无法获取排他锁,需等待事务A释放锁
START TRANSACTION;
UPDATE table_name SET column_name = 'another_value' WHERE id = 1 FOR UPDATE;
1.2 锁的级别
(1)行级锁(Row Lock): 行级锁针对数据表中的行进行加锁,可以减少并发操作产生的锁冲突。
-- 事务A获取行级锁
START TRANSACTION;
SELECT * FROM table_name WHERE id = 1 FOR UPDATE;
-- 事务B也可以获取行级锁,但针对不同行
START TRANSACTION;
SELECT * FROM table_name WHERE id = 2 FOR UPDATE;
(2)表级锁(Table Lock): 表级锁对整个表进行加锁,会限制其他事务对表的操作。
-- 事务A获取表级锁
LOCK TABLES table_name WRITE;
-- 事务B无法同时获取表级锁,需等待事务A释放锁
LOCK TABLES table_name READ;
二、哪些实际业务场景下,我们会在代码中用到mysql的锁?
-
简单事务控制: 对于一些简单的事务控制场景,例如在单个数据库事务中需要确保某些数据的完整性和一致性时,可以直接在 SQL 中增加排他锁来实现。这样做既简单又直接,避免引入额外的复杂性。
-
低并发情况: 如果业务场景下并发访问量不高,或者不需要跨服务或跨实例进行加锁操作,直接在 SQL 中增加排他锁可能会更加轻量和直观,不需要引入额外的分布式系统组件。
-
数据库专用功能: 有些数据库系统提供了特定的排他锁机制,并且对于特定的业务场景,这些数据库专用的排他锁功能可能更加适用和高效。
-
特定的数据操作: 在某些需要对整个表或某些数据范围进行原子操作的情况下,直接在 SQL 中增加排他锁可能更加方便和可行,特别是针对较小规模的数据操作。
三、实际的业务场景是在电商系统中处理订单库存扣减操作。当多个用户同时下单购买同一商品时,需要确保库存扣减的原子性和数据的一致性。适合用Mysql的锁还是Redis加分布式锁,为什么?
在实际订单库存扣减的业务场景中,使用分布式锁(如 Redis 分布式锁)比直接在 SQL 中增加排他锁更好的主要原因有以下几点:
-
跨服务支持: 如果订单库存扣减的业务涉及到多个服务或多个实例,使用分布式锁可以跨服务地实现对共享资源(库存数据)的加锁操作,确保不同服务之间的并发访问问题。
-
细粒度控制: 分布式锁可以实现更细粒度的控制,例如针对每个商品ID进行加锁,而不是一次性锁住整个表或某个范围的数据,从而提高并发性能。
-
避免数据库负担: 直接在 SQL 中增加排他锁可能会给数据库带来额外的负担,特别是在高并发的情况下,容易造成数据库性能瓶颈。通过采用分布式锁,可以将部分锁操作转移到 Redis 等缓存中,减轻数据库压力。
-
灵活性和可扩展性: 使用分布式锁可以更灵活地控制锁的获取和释放逻辑,同时也更容易实现锁的超时、自动续期等功能,满足不同业务场景的需求。此外,分布式锁的架构也更具扩展性,便于水平扩展和集群部署。