0. CPU缓存
根据摩尔定律:芯片中的晶体管数量每隔18个月就会翻一番。导致CPU的性能和处理速度变得越来越快,而提升CPU的运行速度比提升内存的运行速度要容易和便宜的多,所以就导致了CPU与内存之间的速度差距越来越大。
为了弥补CPU与内存之间巨大的速度差异,提高CPU的处理效率和吞吐,于是人们引入了L1,L2,L3高速缓存集成到CPU中。当然还有L0也就是寄存器,寄存器离CPU最近,访问速度也最快,基本没有时延。
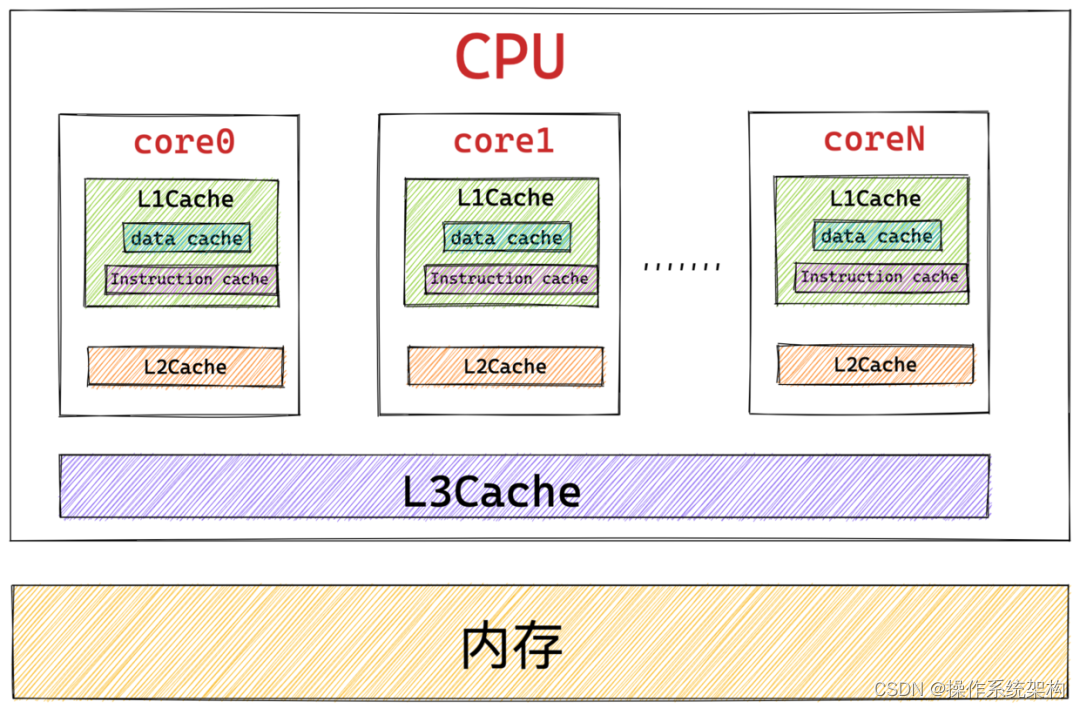
一个CPU里面包含多个核心,我们在购买电脑的时候经常会看到这样的处理器配置,比如4核8线程。意思是这个CPU包含4个物理核心8个逻辑核心。4个物理核心表示在同一时间可以允许4个线程并行执行,8个逻辑核心表示处理器利用超线程的技术将一个物理核心模拟出了两个逻辑核心,一个物理核心在同一时间只会执行一个线程,而超线程芯片可以做到线程之间快速切换,当一个线程在访问内存的空隙,超线程芯片可以马上切换去执行另外一个线程。因为切换速度非常快,所以在效果上看到是8个线程在同时执行。
图中的CPU核心指的是物理核心。
从图中我们可以看到L1Cache是离CPU核心最近的高速缓存,紧接着就是L2Cache,L3Cache,内存。
离CPU核心越近的缓存访问速度也越快,造价也就越高,当然容量也就越小。
其中L1Cache和L2Cache是CPU物理核心私有的(注意:这里是物理核心不是逻辑核心)
而L3Cache是整个CPU所有物理核心共享的。
CPU逻辑核心共享其所属物理核心的L1Cache和L2Cache
L1Cache离CPU是最近的,它的访问速度最快,容量也最小。
从图中我们看到L1Cache分为两个部分,分别是:Data Cache和Instruction Cache。它们一个是存储数据的,一个是存储代码指令的。
我们可以通过cd /sys/devices/system/cpu/来查看linux机器上的CPU信息。

在/sys/devices/system/cpu/目录里,我们可以看到CPU的核心数,当然这里指的是逻辑核心。
下面我们进入其中一颗CPU核心(cpu0)中去看下L1Cache的情况:

- level:表示该cache信息属于哪一级,1表示L1Cache。
- type:表示属于L1Cache的DataCache。
- size:表示DataCache的大小为32K。
- shared_cpu_list:之前我们提到L1Cache和L2Cache是CPU物理核所私有的,而由物理核模拟出来的逻辑核是共享L1Cache和L2Cache的,/sys/devices/system/cpu/目录下描述的信息是逻辑核。shared_cpu_list描述的正是哪些逻辑核共享这个物理核。
index1描述的是L1Cache中Instruction Cache的情况:

CPU缓存行
前边我们介绍了CPU的高速缓存结构,引入高速缓存的目的在于消除CPU与内存之间的速度差距,根据程序的局部性原理我们知道,CPU的高速缓存肯定是用来存放热点数据的。
程序局部性原理表现为:时间局部性和空间局部性。时间局部性是指如果程序中的某条指令一旦执行,则不久之后该指令可能再次被执行;如果某块数据被访问,则不久之后该数据可能再次被访问。空间局部性是指一旦程序访问了某个存储单元,则不久之后,其附近的存储单元也将被访问。
那么在高速缓存中存取数据的基本单位又是什么呢??
事实上热点数据在CPU高速缓存中的存取并不是我们想象中的以单独的变量或者单独的指针为单位存取的。
CPU高速缓存中存取数据的基本单位叫做缓存行cache line。缓存行存取字节的大小为2的倍数,在不同的机器上,缓存行的大小范围在32字节到128字节之间。目前所有主流的处理器中缓存行的大小均为64字节(注意:这里的单位是字节)。

从图中我们可以看到L1Cache,L2Cache,L3Cache中缓存行的大小都是64字节。
这也就意味着每次CPU从内存中获取数据或者写入数据的大小为64个字节,即使你只读一个bit,CPU也会从内存中加载64字节数据进来。同样的道理,CPU从高速缓存中同步数据到内存也是按照64字节的单位来进行。
比如你访问一个long型数组,当CPU去加载数组中第一个元素时也会同时将后边的7个元素一起加载进缓存中。这样一来就加快了遍历数组的效率。
事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构,如果你的数据结构中的项在内存中不是彼此相邻的(比如:链表),这样就无法利用CPU缓存的优势。由于数据在内存中不是连续存放的,所以在这些数据结构中的每一个项都可能会出现缓存行未命中(程序局部性原理)的情况。
1. false sharing
假设定义如下struct,其中有两个两个long型的volatile字段a,b:
struct false_sharing {
volatile long a;
volatile long b;
};
字段a,b之间逻辑上是独立的,它们之间一点关系也没有,分别用来存储不同的数据,数据之间也没有关联。假设false_sharing的对象内存模型中a,b 分别占用8个字节,并且其在内存中是相邻的;
如果恰好字段a,b被CPU读进了同一个缓存行,而此时有两个线程,线程a用来修改字段a,同时线程b用来读取字段b。
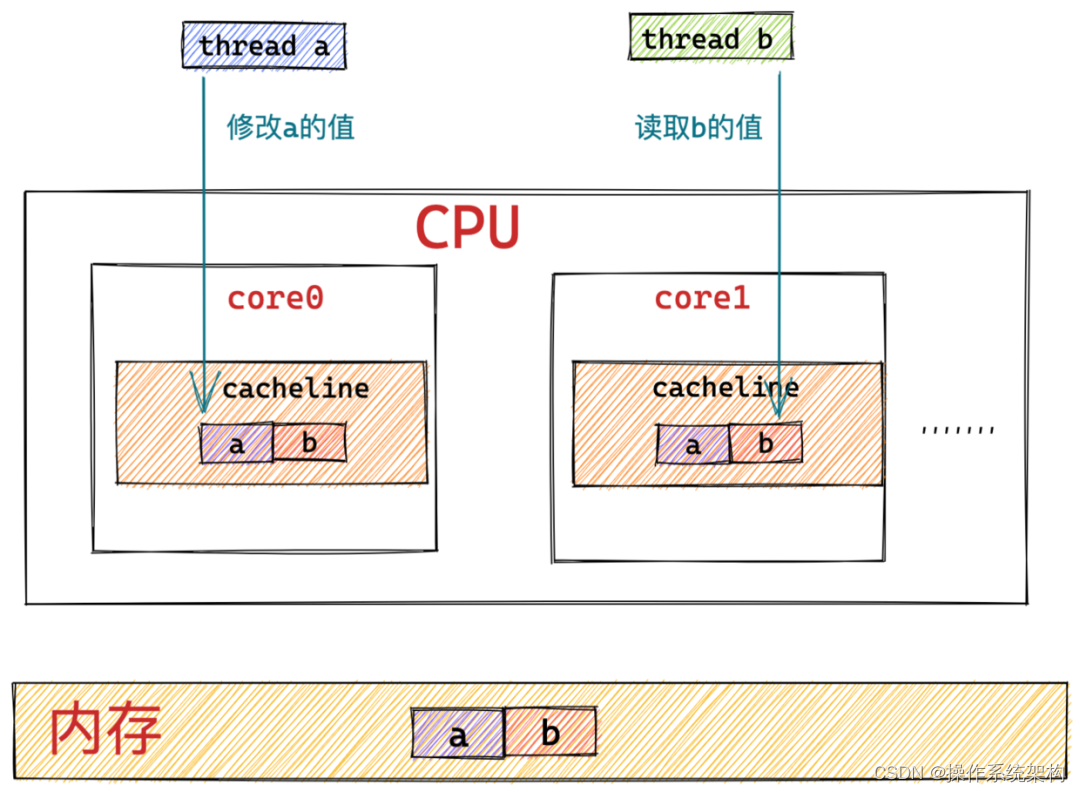
在这种场景下,会对线程b的读取操作造成什么影响呢?
我们知道声明了volatile关键字的变量可以在多线程处理环境下,确保内存的可见性。计算机硬件层会保证对被volatile关键字修饰的共享变量进行写操作后的内存可见性,而这种内存可见性是由Lock前缀指令以及缓存一致性协议(MESI控制协议)共同保证的。
-
Lock前缀指令可以使修改线程所在的处理器中的相应缓存行数据被修改后立马刷新回内存中,并同时锁定所有处理器核心中缓存了该修改变量的缓存行,防止多个处理器核心并发修改同一缓存行。
-
缓存一致性协议主要是用来维护多个处理器核心之间的CPU缓存一致性以及与内存数据的一致性。每个处理器会在总线上嗅探其他处理器准备写入的内存地址,如果这个内存地址在自己的处理器中被缓存的话,就会将自己处理器中对应的缓存行置为无效,下次需要读取的该缓存行中的数据的时候,就需要访问内存获取。
基于以上volatile关键字原则,我们首先来看第一种影响:

- 当线程a在处理器core0中对字段a进行修改时,Lock前缀指令会将所有处理器中缓存了字段a的对应缓存行进行锁定,这样就会导致线程b在处理器core1中无法读取和修改自己缓存行的字段b。
- 处理器core0将修改后的字段a所在的缓存行刷新回内存中。
从图中我们可以看到此时字段a的值在处理器core0的缓存行中以及在内存中已经发生变化了。但是处理器core1中字段a的值还没有变化,并且core1中字段a所在的缓存行处于锁定状态,无法读取也无法写入字段b。
从上述过程中我们可以看出即使字段a,b之间逻辑上是独立的,它们之间一点关系也没有,但是线程a对字段a的修改,导致了线程b无法读取字段b。
第二种影响:
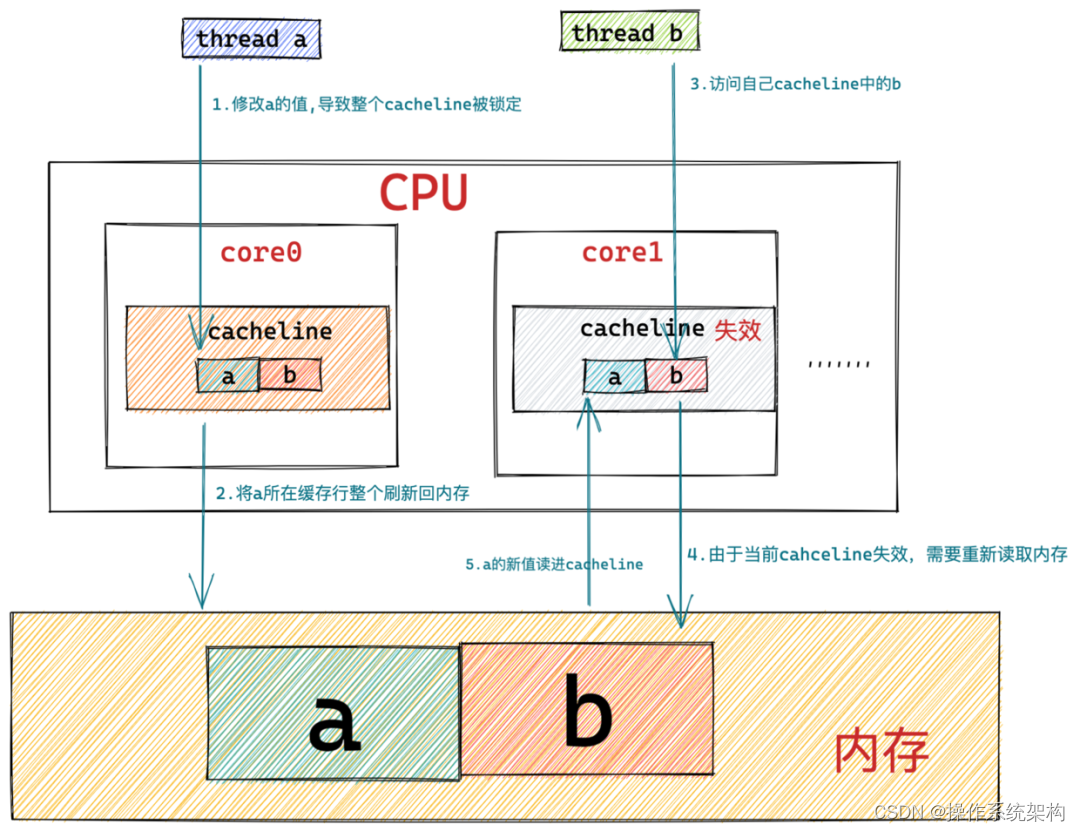
当处理器core0将字段a所在的缓存行刷新回内存的时候,处理器core1会在总线上嗅探到字段a的内存地址正在被其他处理器修改,所以将自己的缓存行置为失效。当线程b在处理器core1中读取字段b的值时,发现缓存行已被置为失效,core1需要重新从内存中读取字段b的值即使字段b没有发生任何变化。
从以上两种影响我们看到字段a与字段b实际上并不存在共享,它们之间也没有相互关联关系,理论上线程a对字段a的任何操作,都不应该影响线程b对字段b的读取或者写入。
但事实上线程a对字段a的修改导致了字段b在core1中的缓存行被锁定(Lock前缀指令),进而使得线程b无法读取字段b。
线程a所在处理器core0将字段a所在缓存行同步刷新回内存后,导致字段b在core1中的缓存行被置为失效(缓存一致性协议),进而导致线程b需要重新回到内存读取字段b的值无法利用CPU缓存的优势。
由于字段a和字段b在同一个缓存行中,导致了字段a和字段b事实上的共享(原本是不应该被共享的)。这种现象就叫做False Sharing(伪共享)。
在高并发的场景下,这种伪共享的问题,会对程序性能造成非常大的影响。
如果线程a对字段a进行修改,与此同时线程b对字段b也进行修改,这种情况对性能的影响更大,因为这会导致core0和core1中相应的缓存行相互失效。
2. False Sharing的解决方案
既然导致False Sharing出现的原因是字段a和字段b在同一个缓存行导致的,那么我们就要想办法让字段a和字段b不在一个缓存行中。
那么我们怎么做才能够使得字段a和字段b一定不会被分配到同一个缓存行中呢?
这时候,本小节的主题字节填充就派上用场了~~
我们通常会在字段a和字段b前后分别填充7个long型变量(缓存行大小64字节),目的是让字段a和字段b各自独占一个缓存行避免False Sharing。