aiohttp异步爬取实战
- 案例介绍
链接为https://spa5.scrape.center,页面如下图所示:
这是一个图书网站,整个网站包含数千本图书信息,网站数据是JavaScript渲染而得的,数据可以通过Ajax接口获取,并且接口没有设置反爬措施和加密参数。
完成目标:
- 使用aiohttp爬取全站的图书数据;
- 将数据通过异步的方式保存到MongoDB中。
-
准备工作
实现MonogDB异步存储,离不开异步实现的MongoDB存储卡motor,其安装命令为:
pip3 install motor -
页面分析
这个页面加载方式都是Ajax,分析如下信息:
- 列表页的Ajax请求接口格式https://spa5.scrape.center/api/book/?limit=18&offset={offset}。其中limit的值为每页包含多少本书;offset的值为每一页的偏移量,计算公式为offset。limit*(page - 1),如第一页的offset值为0,第2页offset的值为18,依此类推。
- 在列表页Ajax接口返回的数据里,results字段包含当前页里18本图书的信息,其中每本书的数据里包含一个id字段,这个id就是图书本身的ID,可以用来进一步请求详情页。
- 详情页的Ajax请求接口格式为https://spa5.scrape.center/api/book/{id}。其中的id即为详情页对应图书的ID,可以从列表页Ajax接口的返回结果中获取此内容。
-
实现思路
一个完善的异步爬虫应该能够充分利用资源进行全速爬取,其实现思路是维护一个动态变化的爬取队列,每产生一个新的task,就将其放入爬取队列中,有专门的爬虫消费者从此队列中获取task并执行,能做到在最大并发量的前提下充分利用等待时间进行额外的爬取处理。
我们将爬取逻辑拆分成两部分,第一部分爬取列表页,第二部分为爬取详情页。因为异步爬虫的关键点在于并发执行,所以可以将爬取拆分为如下两个阶段。
- 第一阶段是异步爬取所有列表页,我们可以将所有列表页的爬取任务集合在一起,并将其声明为由task组成的列表,进行异步爬取。
- 第二阶段则是拿到上一步列表页的所有内容并解析,将所有图书的id信息组合为所有详情页的爬取任务集合,并将其声明为task组成的列表,进行异步爬取,同时爬取结果也以异步方式存储到MongoDB里面。
- 基本配置
首先,先配置一些基本的变量并引入一些必需的库,代码如下:
import asyncio import aiohttp import logging logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s:%(message)s') INDEX_URL = 'https://spa5.scrape.center/api/book/?limit=18&offset={offset}' DETAIL_URL = 'https://spa5.scrape.center/api/book/{id}' PAGE_SIZE = 18 PAGE_NUMBER = 100 CONCURRENCY = 5这里导入asyncio、aiohttp、logging这3个库,然后定义了logging的基本配置。接着定义了URL、爬取页码数量PAGE_NUMBER、并发量CONCURRENCY等信息。
- 爬取列表页面
第一阶段来爬取列表页,还是和之前一样,先定义一个通用的爬取方法,代码如下:
semaphore = asyncio.Semaphore(CONCURRENCY) session = None async def scrape_api(url): async with semaphore: try: logging.info('scraping %s', url) async with session.get(url) as response: return await response.json() except aiohttp.ClientError: logging.error('error occurred while scraping %s', url, exc_info=True)这里声明一个信号量,用来控制最大并发量。接着定义scrape_api方法,接受一个参数url,该方法首先使用async with 语句引入信号量作为上下文,接着调用session的get方法请求这个url,然后返回响应的JSON格式的结果。另外,这里还进行了异常处理,捕获了ClientError,如果出现错误,就会输出异常信息。
然后,爬取列表页,实现代码如下:
async def scrape_index(page): url = INDEX_URL.format(offset=PAGE_SIZE * (page-1)) return await scrape_api(url)这里定义了scrape_index方法用于爬取列表页,它接受一个参数page。随后构造一个列表页的URL,将其传给scrape_api调用之后本身会返回一个协程对象。另外,由于scrape_api的返回结果就是JSON格式,因此这个结果已经是我们想要爬取的信息,不需要再额外解析了。
接下来定义main方法,将上面的方法串联起来调用,实现如下:
import json async def main(): global session session = aiohttp.ClientSession() scrape_index_tasks = [asyncio.ensure_future(scrape_index(page)) for page in range(1, PAGE_NUMBER + 1))] results = await asyncio.gather(*scrape_index_tasks) logging.info('results %s', json.dumps(results, ensure_ascii=False, indent=2)) if __name__ == '__main__': asyncio.get_event_loop().run_until_complete(main())这里首先声明了session对象,即最初声明的全局变量。这样的话,就不需要在各个方法里面都传递session了,实现起来比较简单。
接着定义了scrape_index_tasks,这就是用于爬取列表页的所有task组成的列表。然后调用asyncio的gather方法,并将task列表传入其参数,将结果赋值为results,它是由所有task返回结果组成的列表。
最后,调用main方法,使用事件循环启动该main方法对应的协程即可。
运行结果如下:
- 爬取详情页
第二阶段爬取详情页并保存数据。每个详情页对应一本书,每本书都需要一个ID作为唯一标识,而这个ID又正好在results里面,所以需将所有详情页的ID获取出来。
在main方法里增加results的解析代码,如下:
ids = [] for index_data in results: if not index_data:continue for item in index_data.get('results'): ids.append(item.get('id'))这样ids就是所有书的id了,然后用所有的id构造所有详情页对应的task,进行异步爬取即可。
这里再定义两个方法,用于爬取详情页和保存数据,实现如下:
from motor.motor_asyncio import AsyncIOMotorClient MONGO_CONNECTION_STRING = 'mongodb://localhost:27017' MONGO_DB_NAME = 'books' MONGO_CONNECTION_NAME = 'books' client = AsyncIOMotorClient(MONGO_CONNECTION_STRING) db = client[MONGO_DB_NAME] collection = db[MONGO_CONNECTION_NAME] async def save_data(data): logging.info('saving data %s', data) if data: return await collection.update_one({ 'id':data.get('id') },{ '$set':data },upsert=True) async def scrape_detail(id): url = DETAIL_URL.format(id=id) data = await scrape_api(url) await save_data(data)这里定义了scrape_detail方法用于爬取详情页数据,并调用save_data方法保存数据。save_data方法可以将数据保存到MongoDB里面。
这里我们用到了支持异步的MongoDB存储库motor。motor的连接声明和pymongo是类似的,保存数据的调用方法也基本一致,不过整个都换成了异步方法。
接着在main方法里增加对scrape_detail方法的调用即可爬取详情页,实现如下:
scrape_detail_tasks = [asyncio.ensure_future(scrape_detail(id)) for id in ids] await asyncio.wait(scrape_detail_tasks) await session.close()运行结果如下:
/usr/bin/python3 /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/aiohttp示例.py 2024-03-24 22:19:09,706 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=0 2024-03-24 22:19:09,719 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=18 2024-03-24 22:19:09,720 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=36 ... 2024-03-24 22:19:13,645 - INFO:results [ { "count": 9040, "results": [ { "id": "7952978", "name": "Wonder", "authors": [ "R. J. Palacio" ], "cover": "https://cdn.scrape.center/book/s27252687.jpg", "score": "8.8" }, } ] }, { "count": 9040, "results": [ { "id": "6814760", "name": "一個人暖呼呼", "authors": [ "高木直子" ], "cover": "https://cdn.scrape.center/book/s32265782.jpg", "score": "8.3" }, { "id": "6813394", "name": "曼珠沙华·彼岸花", "authors": [ "\n 沧月", "鼎剑阁系列·沧月十周年珍藏版" ], "cover": "https://cdn.scrape.center/book/s6903111.jpg", "score": "7.6" }, { "id": "6802423", "name": "哦!爸爸们", "authors": [ "\n [日]\n 伊坂幸太郎", "乐读文库" ], "cover": "https://cdn.scrape.center/book/s8353972.jpg", "score": "7.6" }, { "id": "6802393", "name": "大漠荒颜·帝都赋", "authors": [ "\n 沧月", "鼎剑阁系列·沧月十周年珍藏版" ], "cover": "https://cdn.scrape.center/book/s6902785.jpg", "score": "7.9" }, { "id": "6802373", "name": "那些忧伤的年轻人", "authors": [ "\n 许知远", "理想国", "理想国·许知远作品" ], "cover": "https://cdn.scrape.center/book/s6884382.jpg", "score": "7.5" }, { "id": "6784039", "name": "你若安好便是晴天", "authors": [ "\n 白落梅" ], "cover": "https://cdn.scrape.center/book/s6877731.jpg", "score": "5.7" } ] }, { "id": "6758677", "name": "汉文学史纲要", "authors": [ "鲁迅" } ] } ] ..... 2024-03-24 22:19:13,648 - INFO:scraping https://spa5.scrape.center/api/book/7952978 2024-03-24 22:19:13,649 - INFO:scraping https://spa5.scrape.center/api/book/7916054 2024-03-24 22:19:13,650 - INFO:scraping https://spa5.scrape.center/api/book/7698729 2024-03-24 22:19:13,651 - INFO:scraping https://spa5.scrape.center/api/book/7658805 56772', 'comments': [{'id': '1151612381', 'content': '嗯。有全套的书。碟。还有英文书。什么时候北京的某个电影院一天放完一遍的话,还是会去看。'}, {'id': '1151222346', 'content': '小时候书和电影是分开看的,这次每读完一本就看一部电影,就跟找不同样。'}, {'id': '1238066995', 'content': '太棒了~总有一天要读英文原版试试~'}, {'id': '1002081826', 'content': '包括那些番外'}, {'id': '1697423417', 'content': '结束 还挺失落'}, {'id': '2247572685', 'content': '哈哈哈小柠檬让我想起了小学时候熬夜读书的热情还有因为熬夜被爸爸大半夜批评的记忆'}, {'id': '2186418302', 'content': '终于没有经受住诱惑,虽更适合青少年,但也是大众读物。'}, {'id': '2140636956', 'content': '还需要犹豫几星?不给五星的人是什么心态?'}, {'id': '2122408930', 'content': '老版读了几遍'}, {'id': '2031971050', 'content': '第一本是从张一洋那里借的,还有一本五三班的坏小子。'}], 'name': '哈利·波特精装全集(套装全7册)', 'authors': ['\n [英]\n J·K·罗琳'], 'translators': ['苏农', '马爱农', '马爱新'], 'publisher': '人民文学出版社', 'tags': ['哈利波特', 'J.K.罗琳', '魔幻', '小说', '奇幻', '英国', '外国文学', 'HarryPotter'], 'url': 'https://book.douban.com/subject/6856772/', 'isbn': '9787020086627', 'cover': 'https://cdn.scrape.center/book/s6951249.jpg', 'page_number': 1687, 'price': '430.00元', 'score': '9.4', 'introduction': '', 'catalog': None, 'published_at': '2011-01-20T16:00:00Z', 'updated_at': '2020-03-21T16:54:59.503224Z'} 2024-03-24 22:19:57,523 - INFO:scraping https://spa5.scrape.center/api/book/6847760 2024-03-24 22:19:58,009 - INFO:saving data {'id': '6854620', 'comments': [{'id': '905750233', 'content': '太拖沓,浪费时间'}, {'id': '932574876', 'content': '故事太拖沓,其实就是误会+错过,然后误会+错过,循环往复...囧'}, {'id': '676773490', 'content': '受不了女主。。。'}, {'id': '757656144', 'content': '就名字好一点。'}, {'id': '47香,直透人心扉。原来这就是爱。莫失莫忘的青春年华里,这样孤勇的爱,有生之年不会重来。当他的身边站着可堪比肩的校花,当他远在万里重洋之外,这份爱,她还有没有持续下去的希望?《你曾住在我心上(套装共2册)》倾情打造绵延数十年唯美纠结的虐心之作。书签:', 'catalog': '\n 楔子\t1\n 卷一 童年\t2\n 记得当时年纪小\t3\n 不是冤家不聚头\t11\n 韶华不为少年留\t20\n 西出阳关无故人\t30\n 卷二 花季\t40\n 新朋缘来也可庆\t40\n 又到绿杨曾折处\t50\n 黄花时节碧云天\t59\n 年少抛人容易去\t68\n 银汉红墙入望遥\t77\n 卷三 雨季\t88\n 未若柳絮因风起\t88\n 花明柳暗绕天愁\t98\n 不知迷路为花开\t107\n 风波不信菱枝弱\t116\n 桂花吹断月中香\t125\n 自今岐路各西东\t135\n 清声不远行人去\t143\n 一片幽情冷处浓\t153\n 又误心期到下弦\t162\n 卷四 大学\t1\n 春城何处不飞花\t1\n 良辰未必有佳期\t9\n 红楼隔雨相望冷\t19\n 不辞冰雪为卿热\t27\n 纵逢晴景如看雾\t35\n 不语还应彼此知……………………………………………………………………… ……43\n 遥听弦管暗看花\t1\n 行云归北又归南\t9\n 谁言千里自今夕\t17\n 一任南飞又北飞\t25\n 不将颜色托春风\t33\n 劳劳谁是怜君者\t40\n 萤在荒芜月在天\t49\n 卷五 工作\t59\n 归时休放烛花红\t59\n 长教碧玉藏深处\t67\n 无情有恨何人见\t76\n 又见桐花发旧枝\t84\n 别来几度春风换\t93\n 十一年前梦一场\t101\n 人生若只如初见\t109\n 十年一觉扬州梦\t119\n 当时只道是寻常\t127\n 盈盈自此隔银湾\t136\n 持向今朝照别离\t144\n 急雪乍翻香阁絮\t153\n 春云吹散湘帘雨\t161\n 莫向横塘问旧游\t170\n 旧时明月照扬州\t179\n 后记\t 191\n 精彩书评\t 191\n · · · · · · ', 'published_at': '2011-10-20T16:00:00Z', 'updated_at': '2020-03-21T17:29:20.321848Z'} 2024-03-24 22:19:58,011 - INFO:scraping https://spa5.scrape.center/api/book/6835758 2024-03-24 22:19:58,546 - INFO:saving data {'id': '6854525', 'comments': [{'id': '958876319', 'content': '塔勒布的书,超5星。需要再多研究其它资料来好好理解,因为它太「实用」了:避免负面黑天鹅、抓住正面黑天鹅的机会是一辈子都需要考虑的事情。'},\n 第三部分\n 极端斯坦的灰天鹅\n 第十四章 从平均斯坦到极端斯坦,再回到平均斯坦\n 在极端斯坦,没有人是安全的。反过来也一样:也没人受到完全失败的威胁。我们现在的环境允许小人物在成功的希望前等待时机—活着就有希望。\n 第十五章 钟形曲线—智力大骗局\n 由于钟形曲线的不确定性计量方法忽视了跳跃性或者不连续变化发生的可能性及影响,因此无法适用于极端斯应对办法是在思维中避免从众。但在避免上当之外,这种态度受制于一种行为方式,不是思维方式,而是如何将知识转化为行动,并从中找出那些有价值的知识。\n 第十九章 一半对一半—如何与黑天鹅打成平手\n 当我受到正面黑天鹅事件的影响时,我会非常冒险,这时失败只有很小的影响;当我有可能受到负面黑天鹅事件的袭击时,我会非常保守。\n 后记1 从白天鹅到黑天鹅\n 后记2 强大与脆弱—更深层次的哲学与经验的反思\n · · · · · · ', 'published_at': '2011-09-30T16:00:00Z', 'updated_at': '2020-03-21T17:40:30.176461Z'} 2024-03-24 22:19:58,548 - INFO:scraping https://spa5.scrape.center/api/book/6834237 .... Process finished with exit code 0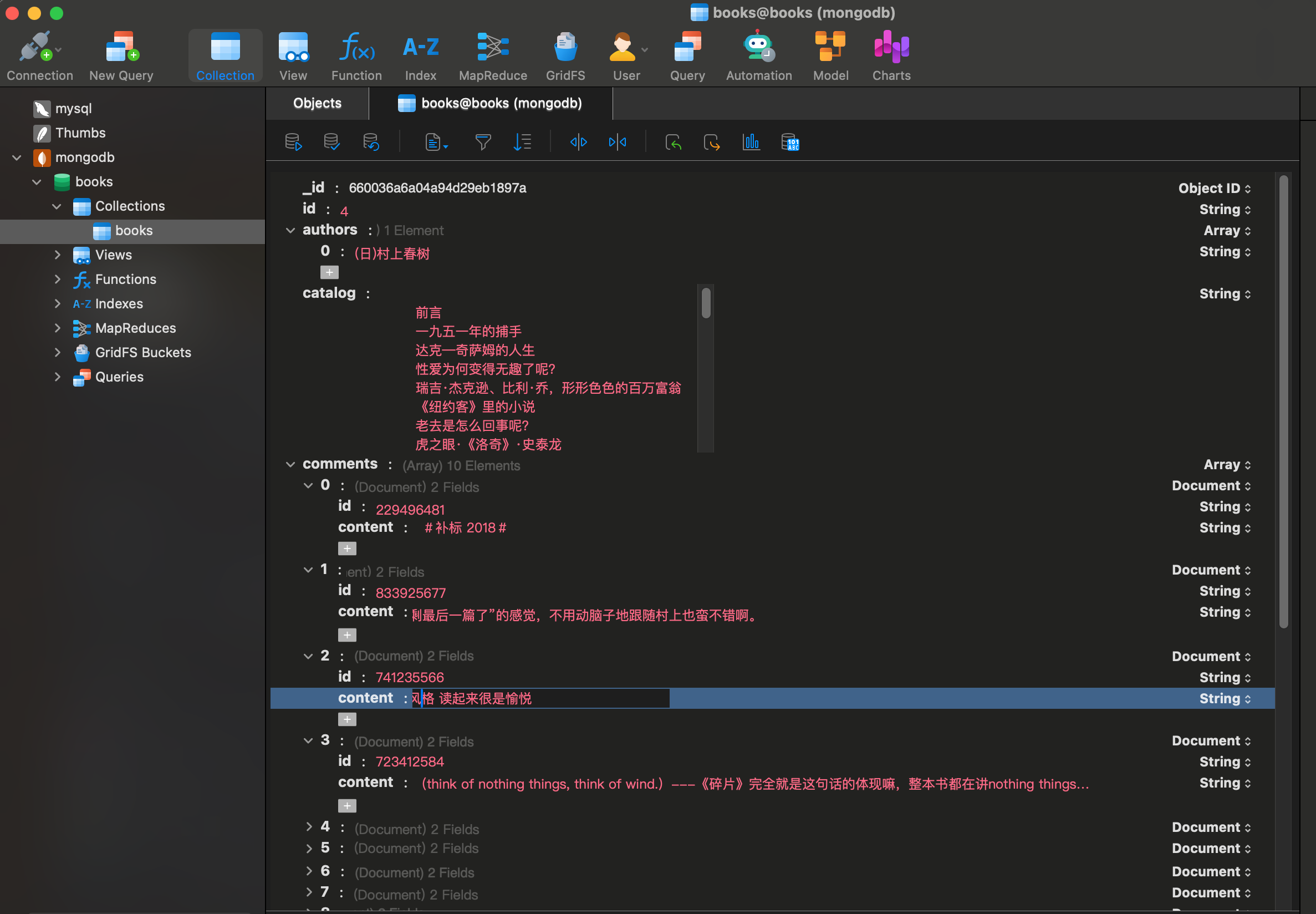
至此,我们就使用aiohttp完成了对图书网站的异步爬取。
以上涉及的相关库的操作可以在[小蜜蜂AI网站][https://zglg.work]获取更多体验。




![[flask]cookie的基本使用/](https://img-blog.csdnimg.cn/direct/53d9e47e4b91420187a59faa2ba89a8d.png)