文章目录
- 0.计算机如何完成y = a * b + c ?
- 1.线程间的互斥相关背景概念
- 2.pthread_mutex_t
- 3.pthread_mutex_lock()
- 4.time() or gettimeofday
- 5.锁的相关问题
- 6.锁的原理
- 7.可重入VS线程安全
- 8.完善后的代码
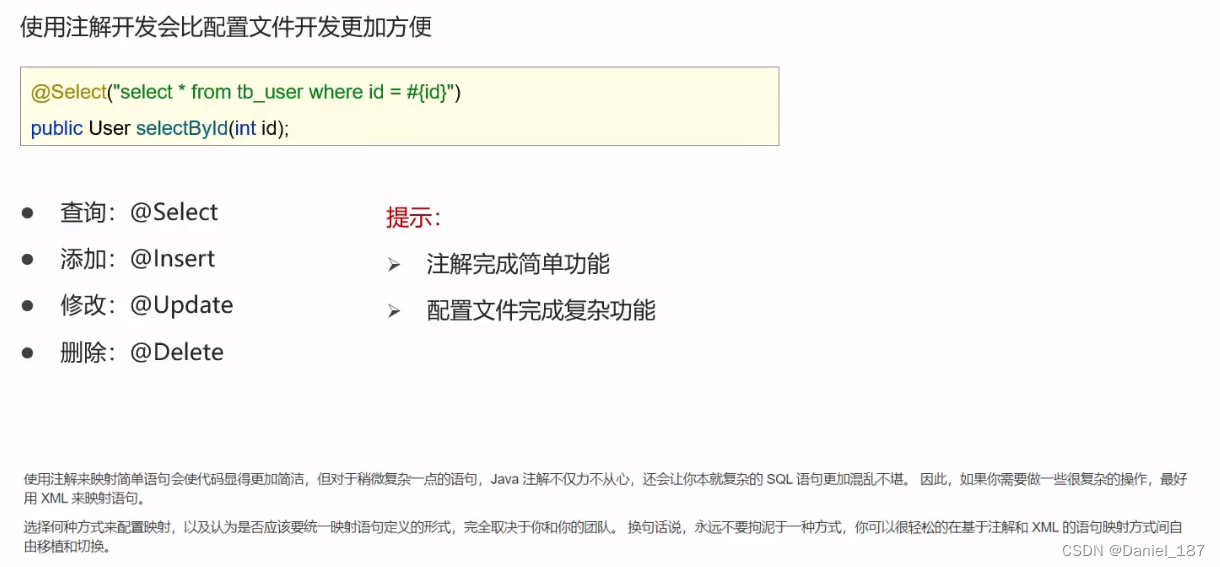
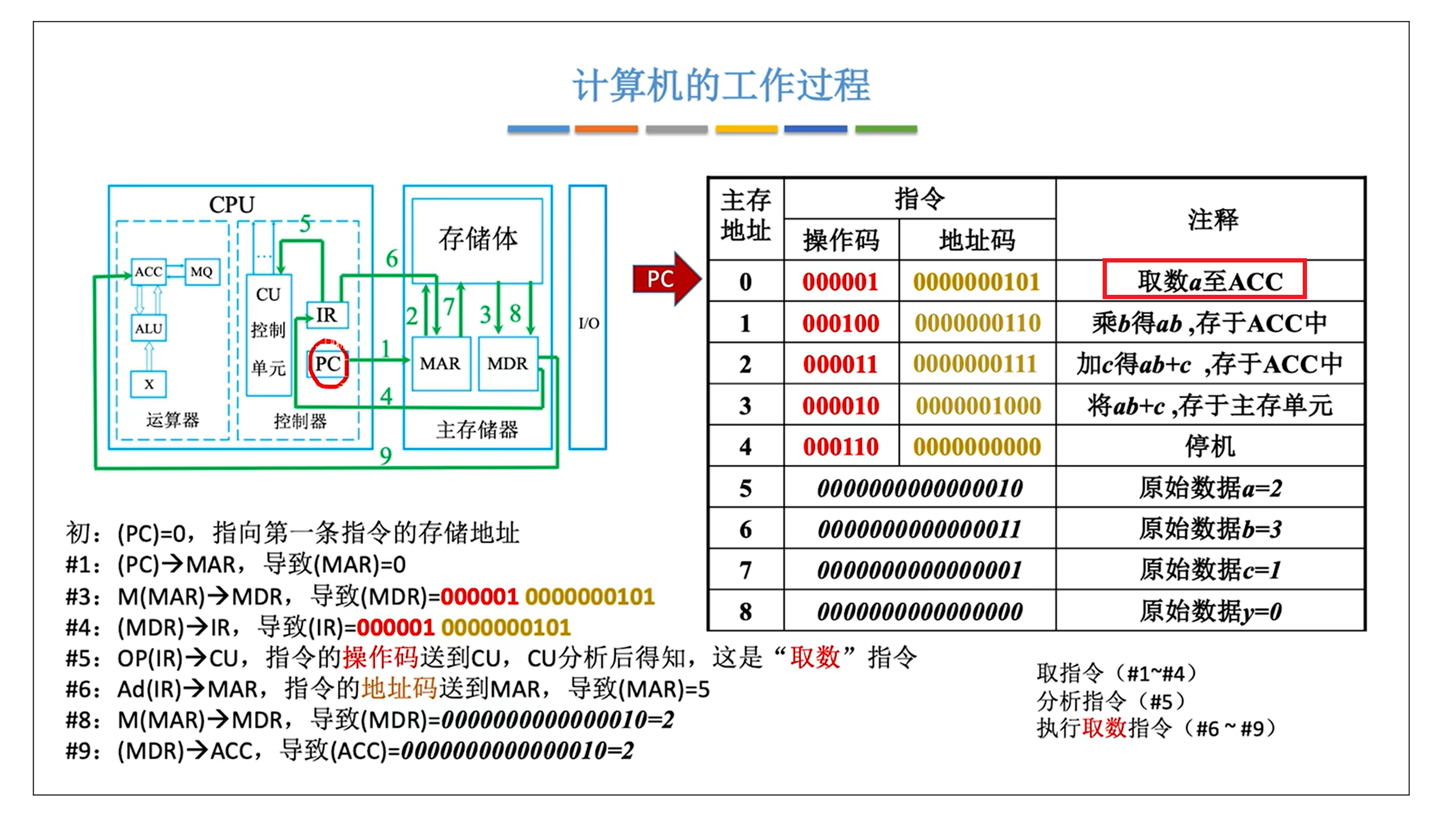
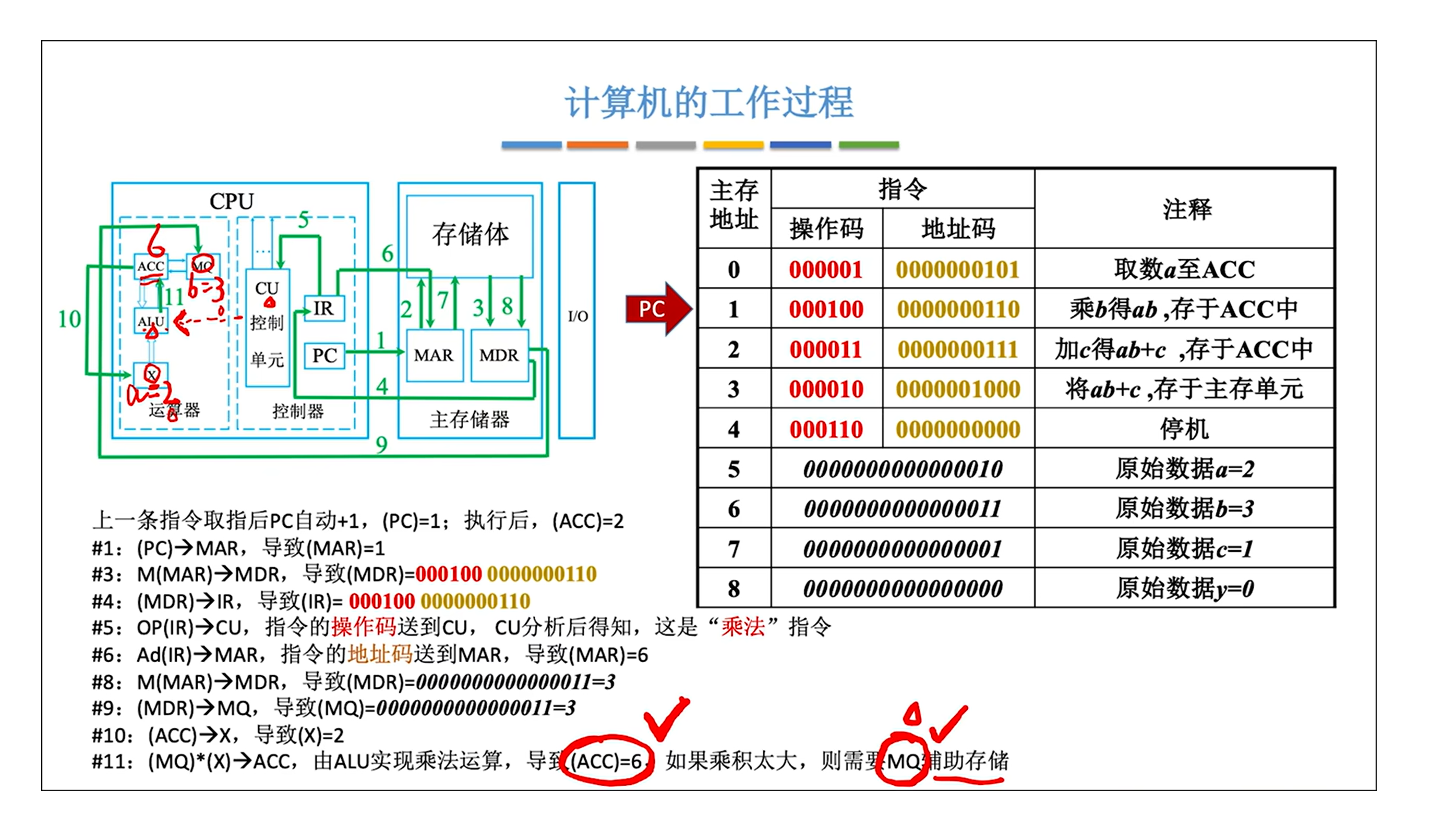
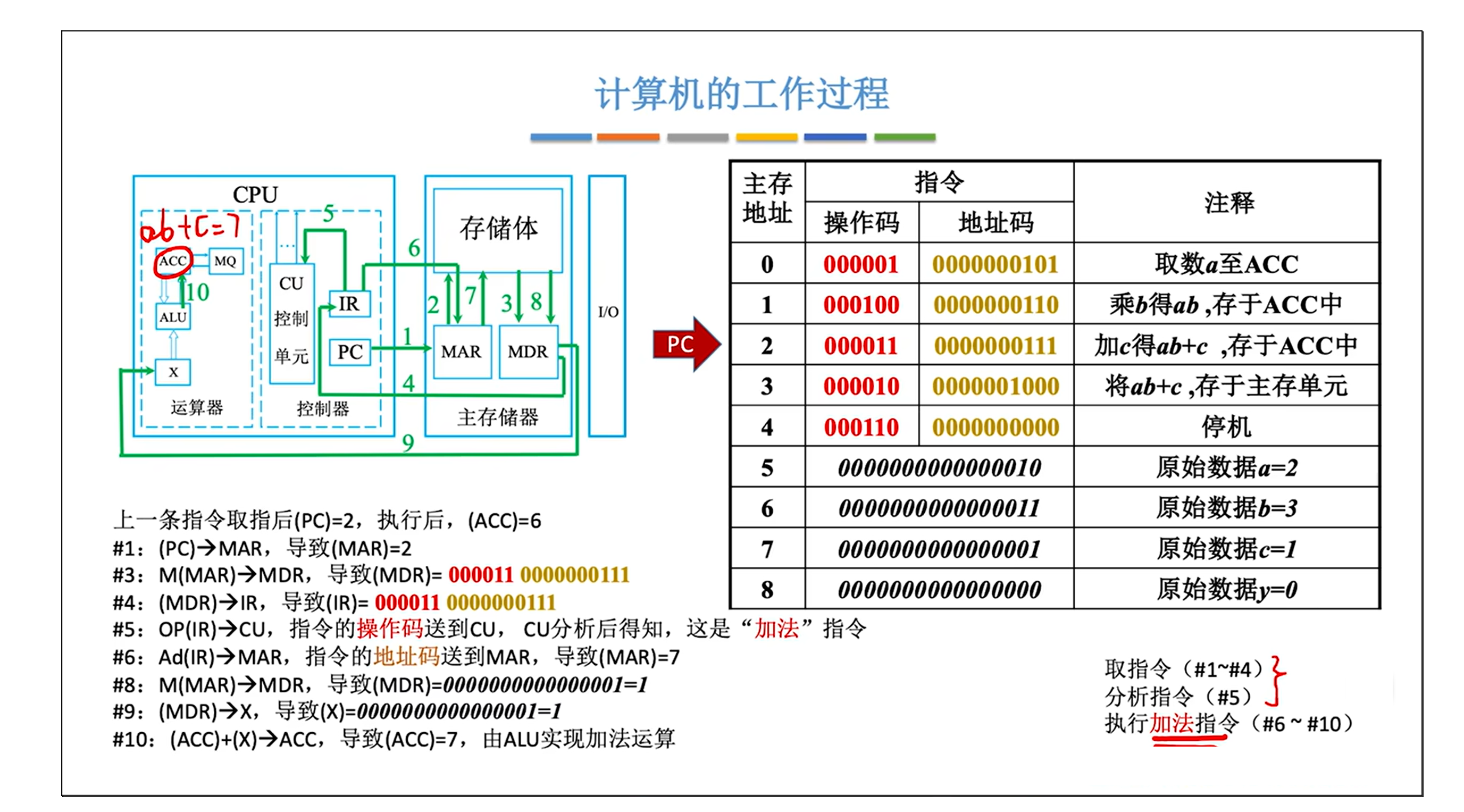
0.计算机如何完成y = a * b + c ?
来源: 王道考研内容
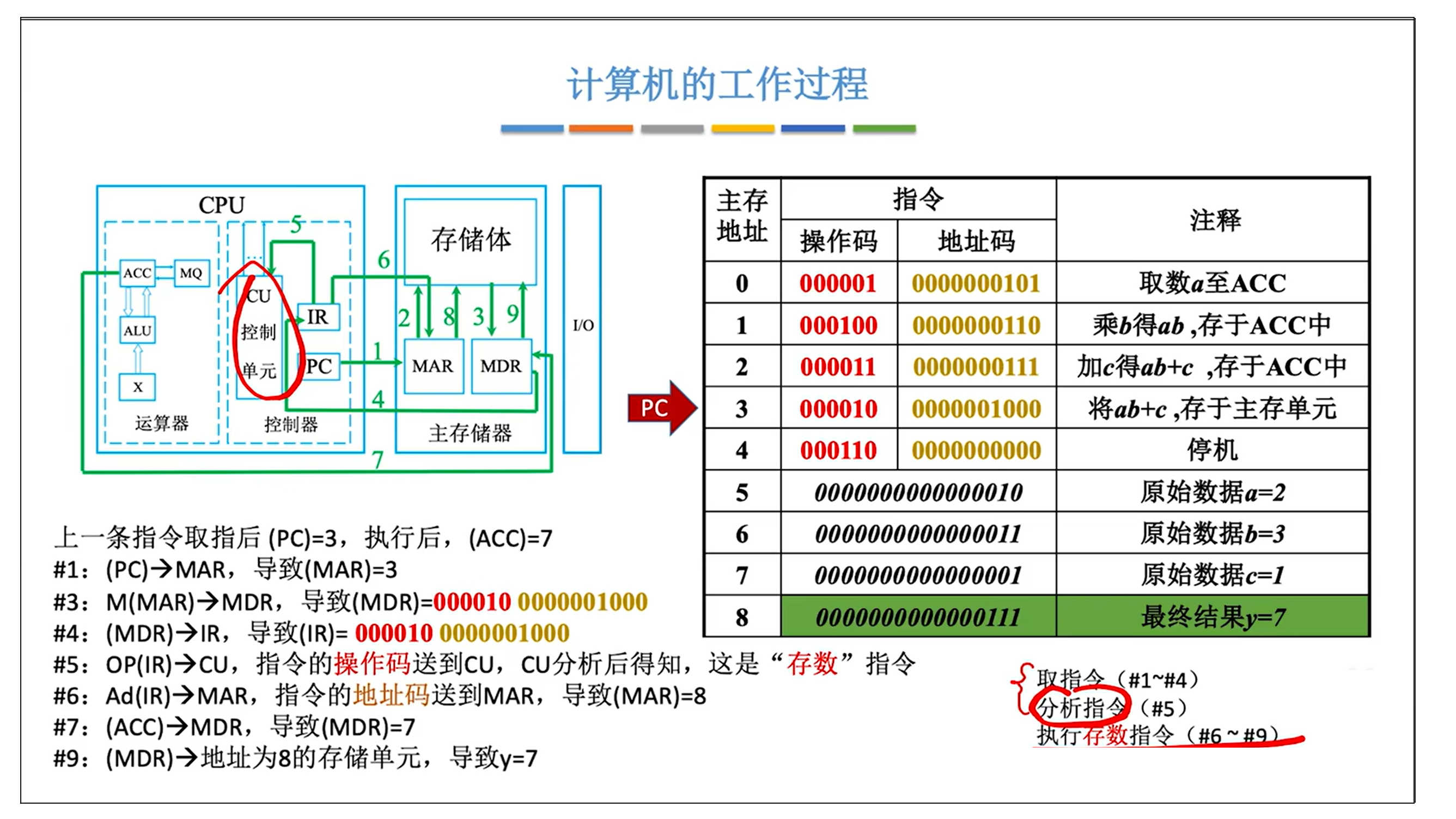
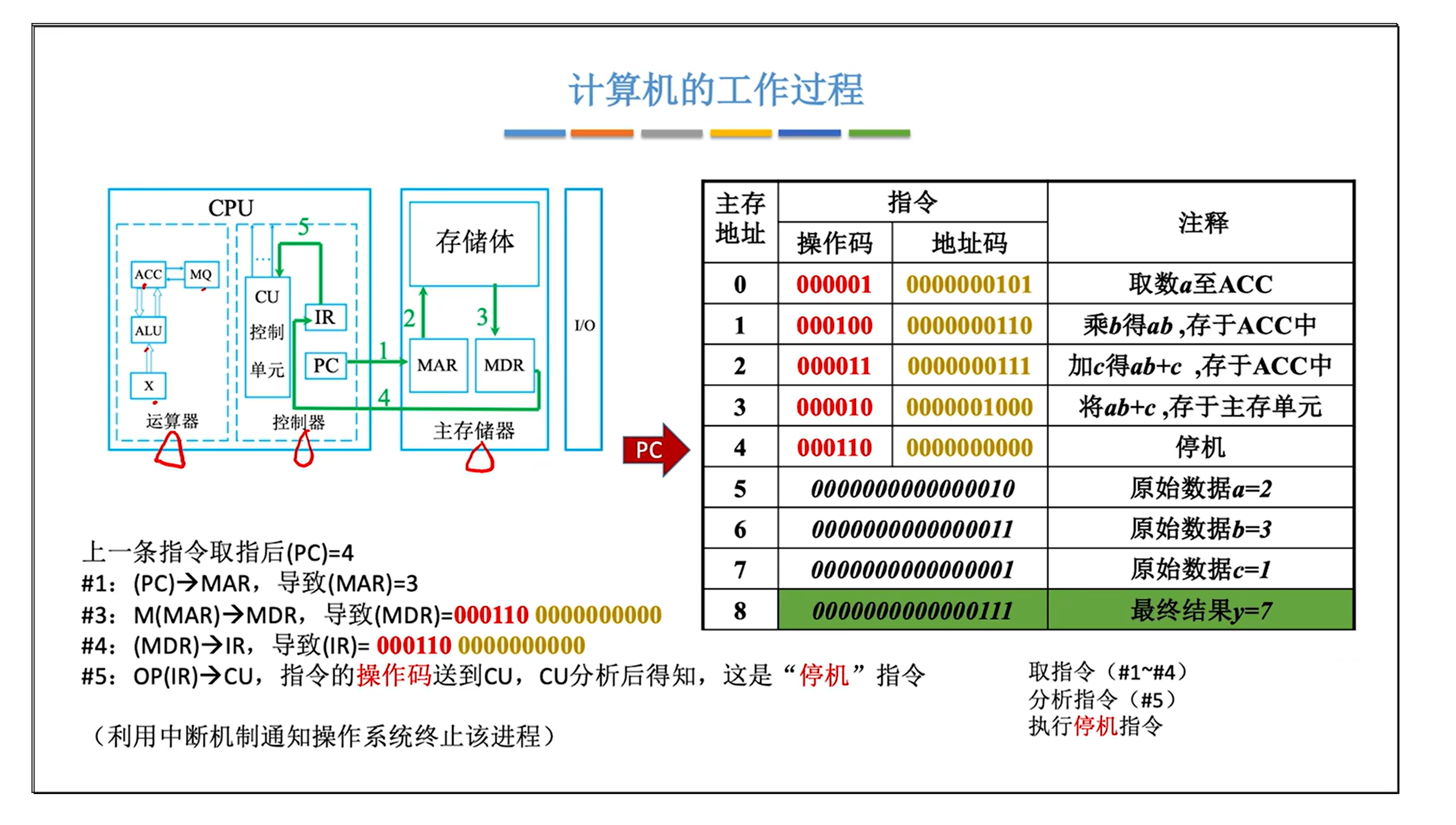
1.线程间的互斥相关背景概念
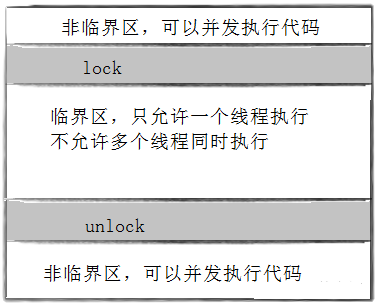
**临界资源:**多线程执行流的背景下,在同一时刻只能被一个执行流访问的资源叫做临界资源。
临界区:每个线程内部,访问临界资源的 代码,叫做临界区
互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用
原子性:不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成
多执行流并发执行引起的数据竞争问题
if (tickets > 0)
{
--tickets;
}
- 大部分情况,线程使用的数据都是局部变量,变量存储在线程栈空间内。这种情况,变量归属单个线程,其他线程无法访问这种变量。
- 很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之间的交互。比如,全局数据、堆空间数据。
- 多个线程并发的操作共享变量,会带来数据竞争,冲突以及数据不一致等问题。在不加保护的访问临界资源时即公共变量被多执行流同时访问和修改,会导致如同一编号的票被多个线程售出,某些线程售出了负数编号的票。除了多线程进程外,信号处理函数也是异步执行的(多执行流执行),同样存在数据竞争的问题。
并发运行问题
tickets > 0和–tickets操作并不是原子性操作,对应的操作:
- 将数据从内存加载到寄存器(当前线程的上下文中)
- 进行逻辑运算或算数运算
- 将数据写回内存
多核CPU允许多线程并行(同时)运行。在这三条步骤的其中任何一步,该线程都有可能被切换,切换前线程上下文会被保存。其他线程在执行时也对tickets进行了访问和修改。当原线程再次被CPU调度执行时,恢复上下文数据,此时的寄存器与内存就会发生数据不一致的错误。
2.pthread_mutex_t
为了解决数据竞争问题,可以使用互斥锁(Mutex)来保护对tickets变量的访问。互斥锁可以确保在同一时间只有一个线程能够访问临界区(对tickets变量的访问),从而避免数据竞争的发生。
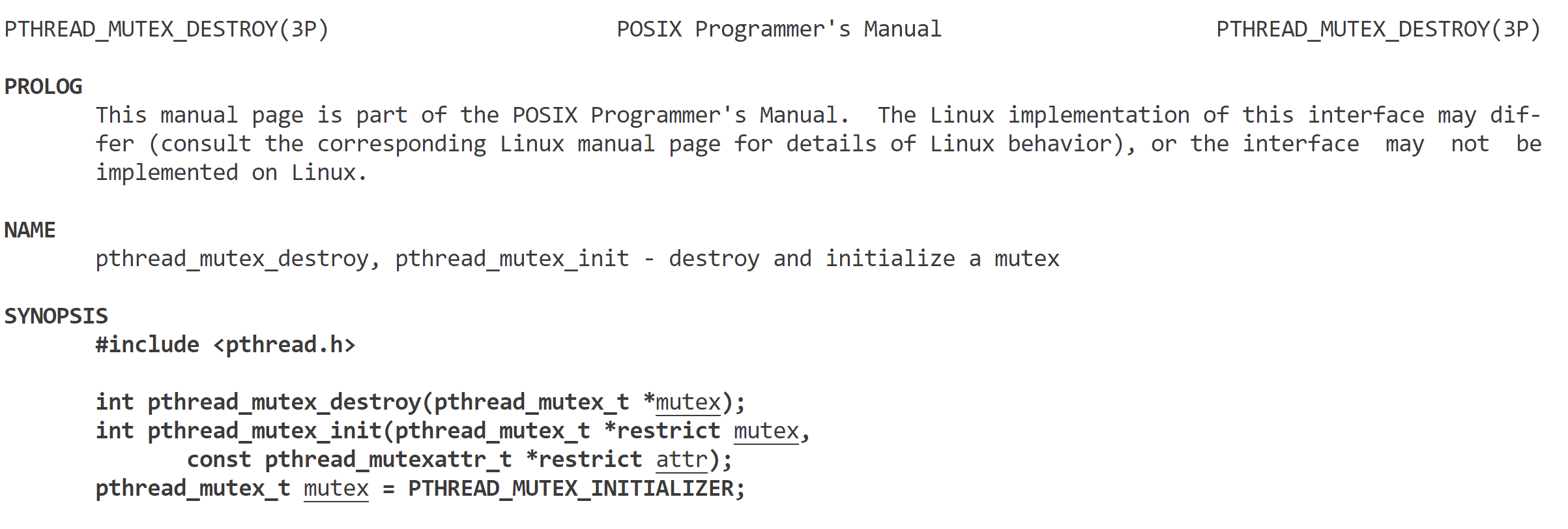
pthread_mutex_t的源码
/* Data structures for mutex handling. The structure of the attribute
type is not exposed on purpose. */
typedef union
{
struct __pthread_mutex_s
{
int __lock;
unsigned int __count;
int __owner;
#ifdef __x86_64__
unsigned int __nusers;
#endif
/* KIND must stay at this position in the structure to maintain
binary compatibility. */
int __kind;
#ifdef __x86_64__
short __spins;
short __elision;
__pthread_list_t __list;
#define __PTHREAD_MUTEX_HAVE_PREV 1
/* Mutex __spins initializer used by PTHREAD_MUTEX_INITIALIZER. */
#define __PTHREAD_SPINS 0, 0
#else
unsigned int __nusers;
__extension__ union
{
struct
{
short __espins;
short __elision;
#define __spins __elision_data.__espins
#define __elision __elision_data.__elision
#define __PTHREAD_SPINS \
{ \
0, 0 \
}
} __elision_data;
__pthread_slist_t __list;
};
#endif
} __data;
char __size[__SIZEOF_PTHREAD_MUTEX_T];
long int __align;
} pthread_mutex_t;
mutex的含义

初始化互斥量有两种方法:
方法1,静态分配:pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER。使用PTHREAD_ MUTEX_ INITIALIZER初始化的互斥量不需要销毁
方法2,动态分配:int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);.
互斥锁的基本使用方法
- 定义互斥锁变量:
在使用互斥锁之前,先定义一个互斥锁变量。使用pthread_mutex_t类型来声明互斥锁变量,如:pthread_mutex_t mutex; - 初始化互斥锁:在使用互斥锁之前,需要对互斥锁进行初始化。
静态初始化:在定义互斥锁变量时,使用PTHREAD_MUTEX_INITIALIZER宏进行初始化。
动态初始化:可以使用pthread_mutex_init函数来初始化互斥锁,例如pthread_mutex_init(&mutex, NULL);第一个参数是要初始化的互斥锁变量,第二个参数是互斥锁的属性,通常使用NULL表示使用默认属性; - 对临界区加锁:在访问共享资源之前,需要加锁。使用pthread_mutex_lock函数来加锁,如:pthread_mutex_lock(&mutex);如果互斥锁已经被其他线程锁定,那么当前线程会被阻塞,直到互斥锁被解锁。
- 访问共享资源:在互斥锁被锁定的情况下,可以安全地串行访问共享资源。
- 解锁:在访问共享资源完成后,需要解锁互斥锁,以便其他线程可以继续访问共享资源。使用pthread_mutex_unlock函数来解锁,例如:pthread_mutex_unlock(&mutex);
- 销毁互斥锁:
不再需要使用互斥锁时,需要将其销毁。使用pthread_mutex_destroy函数来销毁互斥锁,如:pthread_mutex_destroy(&mutex);
静态初始化的互斥锁在程序结束时会自动被系统回收,无需手动销毁。
不要销毁一个已经加锁的互斥量
对于已经销毁的互斥量,要确保后面不会有线程再尝试加锁
3.pthread_mutex_lock()

在访问共享资源完成后,需要解锁互斥锁。否则,其他线程会被一直阻塞。需要特别注意break, goto等跳转语句跳过解锁函数。
被互斥锁锁定的临界区只能串行执行(互斥访问),虽然保证了多执行流访问临界资源的安全性,但是会在一定程度上降低程序的效率。
尽量保证被互斥锁锁定的代码都是访问临界资源的代码,不要将其他无关的操作也放入临界区中。因为相比并发或并行执行,临界区串行执行的效率较低。
调用pthread_ lock 时,可能会遇到以下情况
- 互斥量处于未锁状态,该函数会将互斥量锁定,同时返回成功
- 其他线程已经锁定互斥量,或者存在其他线程同时申请互斥量,但没有竞争到互斥量,那么pthread_ lock调用会陷入阻塞(执行流被挂起),等待互斥量解锁
4.time() or gettimeofday
详细解释
在 Linux 下,time() 和 gettimeofday() 函数都被用于获取当前的时间或时间戳,但它们之间有一些重要的区别。
time() 函数:
time() 函数返回从 Epoch(1970年1月1日 00:00:00 UTC)到当前时间的秒数。它的精度是秒级的。
函数原型:
c
#include <time.h>
time_t time(time_t *tloc);
如果 tloc 不是 NULL,则该函数也会将结果存储在 tloc 指向的内存位置。
如果成功,它返回自 Epoch 以来经过的秒数。
如果出错,它返回 -1。
示例:
c
#include <stdio.h>
#include <time.h>
int main() {
time_t current_time;
current_time = time(NULL);
if (current_time == -1) {
perror("time");
return 1;
}
printf("Current time since the Epoch: %ld\n", (long) current_time);
return 0;
}
gettimeofday() 函数:
gettimeofday() 函数返回当前的时间,包括秒和微秒部分。因此,它的精度更高,可以达到微秒级。
函数原型:
c
#include <sys/time.h>
int gettimeofday(struct timeval *tv, struct timezone *tz);
tv 是一个指向 timeval 结构的指针,该结构用于存储秒和微秒。
tz 是一个指向 timezone 结构的指针,但在现代系统中,它通常被设置为 NULL,因为时区信息可以通过其他方式获得。
如果成功,它返回 0。
如果出错,它返回 -1。
timeval 结构定义如下:
c
struct timeval {
time_t tv_sec; /* seconds */
suseconds_t tv_usec; /* microseconds */
};
示例:
c
#include <stdio.h>
#include <sys/time.h>
int main() {
struct timeval tv;
if (gettimeofday(&tv, NULL) == -1) {
perror("gettimeofday");
return 1;
}
printf("Current time: %ld.%06ld\n", (long)tv.tv_sec, (long)tv.tv_usec);
return 0;
}
注意:
由于 gettimeofday() 使用了微秒级的精度,因此在某些系统上可能比其他时间函数(如 time())更慢。
在许多现代应用中,建议使用更高级的时间处理函数,如 clock_gettime(),它提供了更多的时钟选项和更高的精度。
在多线程环境中,time() 和 gettimeofday() 都不是线程安全的。如果需要线程安全的时间函数,应考虑使用 clock_gettime() 或其他同步机制。
5.锁的相关问题
linux下,mutex的工作原理是什么?它是如何保护临界区的?
在Linux下,互斥锁(mutex)是一种同步机制,用于确保在任何给定时刻只有一个线程或进程可以进入临界区,从而避免数据竞态条件和不一致性。以下是关于mutex工作原理、如何保护临界区以及如何让线程变安全的详细解释:
互斥锁的工作原理:
互斥锁基于原子操作和硬件支持来实现其同步机制。原子操作是一种不可分割的操作,即使在多核处理器上也是如此。Linux内核利用现代处理器提供的硬件指令(如“比较并交换”CMPXCHG指令)来支持原子操作,确保在执行操作期间不会被中断或其他线程干扰。
互斥锁内部有一个计数器(通常称为互斥量),其值只能为0或1。当线程需要进入临界区时,它会检查互斥锁的状态。如果计数器的值为0,表示当前没有线程占用临界区,该线程可以获取互斥锁并进入临界区。如果计数器的值为1,则表示临界区已被其他线程占用,该线程将被阻塞,直到互斥锁被释放。
保护临界区:
临界区是访问临界资源的代码段,这些资源一次只允许一个线程或进程访问。通过使用互斥锁,可以确保在任何时候只有一个线程能够进入临界区并执行相关操作。当线程进入临界区之前,它会尝试获取互斥锁。如果成功获取到锁,线程将执行临界区内的代码;如果锁已被其他线程占用,则当前线程将被阻塞,直到锁被释放。这种方式有效地保护了临界区,避免了多个线程同时访问临界资源导致的竞态条件。
线程安全:
线程安全是指多个线程访问某个方法或资源时,不管这些线程如何交替执行,每次运行的结果都与单线程运行的结果一致。线程安全问题通常由全局变量和静态变量引起。当多个线程同时对全局变量或静态变量进行写操作时,就可能导致数据不一致或其他问题。
通过使用互斥锁,可以确保对临界资源的互斥访问,从而实现线程安全。当线程需要访问临界资源时,它必须先获取互斥锁。这确保了在同一时间只有一个线程能够访问临界资源,从而避免了数据竞态条件。一旦线程完成对临界资源的访问,它会释放互斥锁,允许其他线程进入临界区。通过这种方式,互斥锁有效地保证了线程安全。
总之,Linux下的互斥锁通过原子操作、硬件支持和内核态调用实现其工作原理,保护临界区并确保线程安全。它是多线程编程中重要的同步机制之一,用于解决多线程环境中的竞态条件和数据不一致性问题。
加锁就是串行执行了吗?
是的!执行临界区代码一定是串行的!
结合Linux下的线程互斥与同步,简要介绍什么叫做原子性
在Linux下,线程互斥与同步是并发编程中的关键概念,它们共同确保多个线程在访问共享资源时的正确性和一致性。而原子性(atomicity)则是这些概念中的一个重要属性。
原子性指的是一个操作或者一组操作要么全部执行并且执行过程不会被任何因素打断,要么就全部不执行。换句话说,一个原子操作是不可中断的,即在执行完毕之前,不会被其他线程或进程干扰。在Linux下,原子操作通常是由硬件指令和内核支持来保证的,确保在执行期间不会被其他线程打断。
在线程互斥的上下文中,原子性尤为重要。例如,当多个线程试图同时修改一个共享变量时,如果没有原子性的保证,就可能导致数据的不一致和竞态条件。通过使用互斥锁(mutex)等同步机制,可以确保对共享资源的访问是原子的,即一次只有一个线程可以访问和修改共享资源。
同样,线程同步也需要原子性的保证。条件变量、信号量等同步机制都是基于原子操作来实现的,以确保线程在同步过程中的正确性和一致性。
因此,原子性是Linux下线程互斥与同步的重要基础,它确保了多线程环境中对共享资源的正确访问和操作,从而避免了数据竞态条件和不一致性的问题。
Linux下的线程互斥与同步的原子性体现在哪里?
Linux下的线程互斥与同步的原子性主要体现在对共享资源的访问和操作的不可分割性上。原子性确保了在多线程环境中,对共享资源的访问和操作不会被其他线程打断,从而避免了数据竞态条件和不一致性的问题。
在Linux下,线程互斥与同步的原子性主要通过以下方式实现
硬件指令支持: 现代处理器提供了原子操作的硬件指令,如“比较并交换”(Compare-and-Swap,CAS)或“加载链接/存储条件”(Load-Linked/Store-Conditional)等。这些指令允许一个操作在不被中断的情况下完成,即使在多核处理器上也是如此。Linux内核利用这些硬件指令来实现原子操作,从而确保线程互斥与同步的原子性。
互斥锁(Mutex:互斥锁是一种常用的同步机制,用于保护临界区。当一个线程尝试获取互斥锁以访问临界区时,该操作是原子的。如果锁已被其他线程持有,那么获取锁的操作会失败,并且当前线程会被阻塞,直到锁被释放。这种原子性的获取和释放锁的操作确保了只有一个线程能够进入临界区,从而避免了数据竞态条件。
原子变量操作:Linux提供了原子变量操作的API,如__sync_fetch_and_add、__sync_bool_compare_and_swap等。这些函数提供了对变量进行原子性读写和修改的能力,确保了对共享变量的访问和修改不会被其他线程打断。
条件变量和信号量:条件变量和信号量也是用于线程同步的机制。条件变量允许线程在特定条件不满足时阻塞,并在条件满足时被唤醒。信号量则用于控制对共享资源的访问数量。这些机制的实现也依赖于原子操作来确保同步的正确性。
综上所述,Linux下的线程互斥与同步的原子性是通过硬件指令支持、互斥锁、原子变量操作以及条件变量和信号量等机制共同实现的。这些机制确保了多线程环境中对共享资源的访问和操作的不可分割性,从而避免了数据竞态条件和不一致性的问题。
加锁了之后,线程在临界区中,是否会切换,会有问题吗?
加锁了之后,线程在临界区中会切换,不会有问题
虽然被切换了,但是在持有锁的状态下被切换的
所以其他抢票线程要执行临界区代码,也必须先申请锁
但是其他线程是无法申请成功的,所以其他线程无法进入临界区,保证了临界区中数据一致性
一个访问临界资源的线程不申请锁 当其他持有锁的线程被切换后 他依然可以访问临界资源 – 错误的编码方式,程序员就不要写出这样的代码,即程序员要给所有访问临界资源的线程的加锁。
对于访问临界资源的线程而言,临界区代码要么全部执行成功,要么全部不执行,访问临界资源的操作不可被中断(不能同时执行其他线程的临界区代码),这就是原子性的体现
对没有持有锁的线程2最有意义的情况有两种:
- 线程1没有持有锁 不访问临界资源
- 线程1释放锁 线程2可以申请锁
线程要访问临界资源 必须先申请锁 前提:每一个线程都必须先看到同一把锁
==> 锁本身是不是就是一种共享资源?谁来保证锁的安全呢?
为了保证锁的安全,申请和释放锁必须是 原子的!如何保证?锁是如何实现的?
6.锁的原理
- 在汇编层面,一条汇编语句要么已经执行完,要么就还没有执行,是原子性的。
- 为了实现互斥锁操作,大多数体系结构都提供了swap或exchange汇编指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性。即使是多处理器平台(并行),访问内存的总线周期也有先后,一个处理器上的交换指令执行时另一个处理器的交换指令只能等待总线周期。
- CPU的寄存器数据,本质就是当前执行流的上下文。寄存器的存储空间被所有执行流共享,但是寄存器的内容是被每一个执行流私有的【意思就是,所有的执行流都能将自己的上下文放到cpu寄存器内,让寄存器来调度,但是同一时间,cpu的寄存器只能被一个执行流私有,即只能有一个执行流被调度】所以在切换线程时,要将当前线程的寄存器数据保存到其PCB中,并加载要调度的新线程的寄存器数据。
- swap/exchange指令:以一条汇编的方式,将内存和CPU内寄存器数据进行交换
- 在汇编的角度,如果一个操作只用一条汇编语句就可以完成,称该操作的执行是原子的!【本章的第一部分(计算机如何完成y = a * b + c ?)】实际上讲解了更底层指令的过程。
- 为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的 总线周期也有先后,一个处理器上的交换指令执行时,另一个处理器的交换指令只能等待总线周期。
执行流视角是如何看待CPU寄存器的?
CPU内部的寄存器本质,叫做当前执行流的上下文!寄存器空间是被所有的执行流共享的,但是寄存器的内容,是被每一个执行流私有的!
图解互斥锁
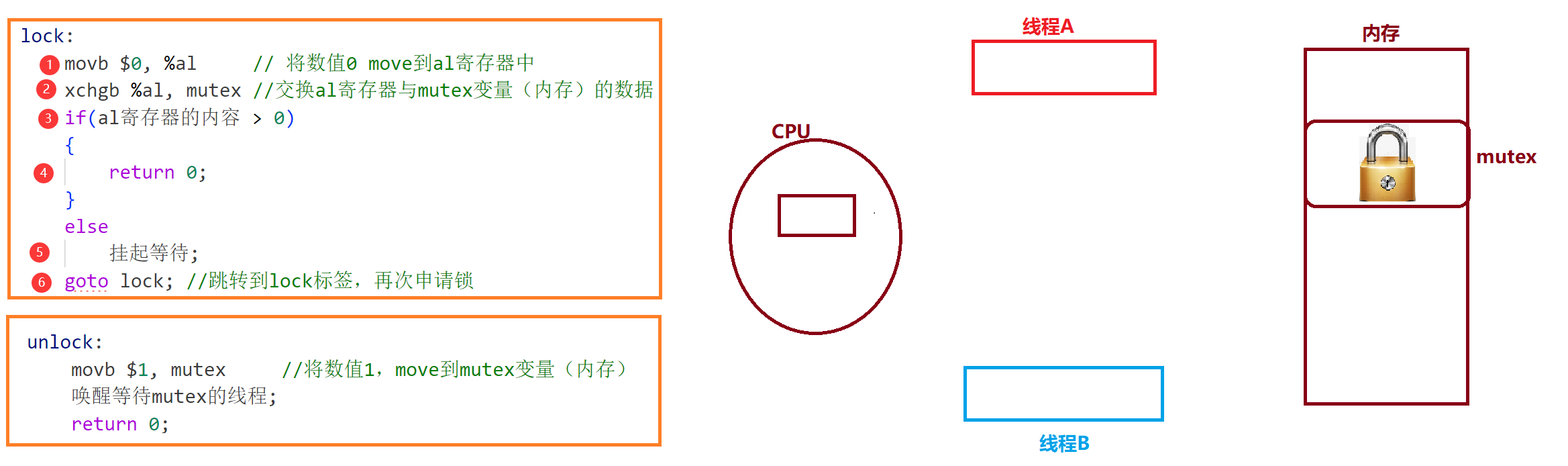
假设共识:
- 将互斥锁变量mutex理解成一个整形变量,某进程cpu上下文寄存器的值为1表示互斥锁被线程持有。在内存创建互斥锁变量初始化为1。
- 由于exchange汇编指令是原子的,所以不管线程如何切换,只有一个线程能够将mutex(内存)中的1值交换到自己的寄存器当中,即该线程的上下文中。而线程上下文是线程的私有数据,实现了公有到私有的转换。同时寄存器当中的0值被交换到了mutex中,其他线程再进行交换也只能交换到0。
- 在进行if判断时,交换到1值的线程执行return 0,可以安全地进入临界区访问临界资源;而交换到0值的线程阻塞等待,直到互斥锁被解锁,这些线程才会被唤醒,然后再次尝试申请锁
- 当持有锁的线程访问完临界资源后,会将mutex变量重新置为1,即解锁互斥锁。之后OS唤醒等待互斥锁解锁的线程,让他们再次竞争申请锁。
- 为了保证锁的安全,申请和释放锁,必须是原子的!在设计加锁时,通过一条原子性的exchange指令,保证了加锁和解锁的原子性。
- 加锁了之后,线程在临界区中,是否会切换,会有问题吗?线程在临界区中也可能会被切换,但他是持有锁被切换的,所谓持有锁切换是指互斥锁的1值保存在当前线程的上下文,被当前线程私有。而其他线程即使被CPU调度执行,也无法抢占互斥锁,也就无法访问临界区代码。所以不会有任何问题。
假设存在的情况:
A执行1:cpu寄存器值=0;执行2前被切换;A带着CPU寄存器的值0回老家【保存上下文】
B执行1:cpu寄存器值=0;执行2,交换使得mutex=0,寄存器=1;执行3,if条件满足,进入if,执行4前被切换;B带着CPU寄存器的值1回老家【保存上下文】
A继续执行2,交换使得mutex=0,寄存器=1;执行3,if条件不满足,挂起等待。
B继续执行4,return 0;表示加锁成功。
A等待结束,执行6,进行A的加锁。
如此,mutex自己保证了自己的原子性。那个“1”就好像一个令牌,不管有多少个线程,令牌只有一个,线程即使被切换,他也是带着令牌走的。
有同学会问,我们为了使得一个全局变量ticket被安全的访问,又添加了一个mutex,现如今为了保护ticket搞了一个也要被保护的mutex,为什么不直接将保护mutex的思想用到ticket上?这是多此一举吗?
当然不是。在多线程编程中,多个地方都会用到锁,如果我们在项目中编写代码时,加一个锁就把对应的代码添加一些if/else/exchange,这样的代码质量简直难评。设计者给我们设计了一个线程库,设计者考虑到线程安全的问题,设计了锁这样的概念,为的就是让程序员使用时,能够简单通过加锁/解锁这样的语句实现复杂的原子操作,类似于封装有益于提高代码可维护性可重用性的思想。
7.可重入VS线程安全
线程安全:
多个线程并发执行时,在没有锁保护的情况下访问了共享资源(如全局或静态变量,堆区数据等),会出现数据竞争从而导致数据冲突,数据不一致等线程安全问题。多个线程并发执行同一段代码时,不会出现不同的结果称之为线程安全。常见的如果对全局变量或者静态变量进行操作,并且没有锁保护的情况下,会出现线程不安全的问题。
重入:
同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他的执行流再次进入,我们
称之为重入。一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题,则该函数被称为可重入函数,否则,是不可重入函数。
常见的线程不安全的情况
- 不保护共享变量的函数
- 函数状态随着被调用而发生改变的函数【使用count++】
- 返回指向静态变量指针的函数
- 调用线程不安全函数的函数
- AB线程分别执行a函数和b函数,ab函数都改变了ticket的值,也有可能导致线程不安去。
常见的线程安全的情况
- 每个线程对全局变量或者静态变量只有读取的权限,而没有写入的权限,一般来说这些线程是安全的
- 类或者接口对于线程来说都是原子操作
- 多个线程之间的切换不会导致该接口的执行结果存在二义性
- 仅使用本地(局部)数据,或者通过制作全局数据的本地拷贝来保护全局数据。
- 使用互斥锁(Mutex)来保护对共享资源的访问。互斥锁可以确保在同一时间只有一个线程能够访问临界区,从而避免数据竞争的发生。
- 不调用线程不安全的函数
常见不可重入的情况
- 调用了malloc/free函数,因为malloc函数是用全局链表来管理堆的
- 调用了标准I/O库函数,标准I/O库的很多实现都以不可重入的方式使用全局数据结构
- 可重入函数体内使用了静态的数据结构
常见可重入的情况
- 不使用全局变量或静态变量
- 不使用用malloc或者new开辟出的空间
- 不调用不可重入函数
- 不返回静态或全局数据,所有数据都有函数的调用者提供
- 使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据【在临界区前,搞一个局部变量存储可能会被影响的全局变量,临界区后,再把该值拷贝回去,保证此全局变量不会被改变】
可重入与线程安全联系
函数可重入的 ⇒ 线程安全
函数不可重入 ⇒ 不能由多个线程使用 ⇒ 有可能引发线程安全问题
一个函数中有全局变量 ⇒ 这个函数既不是线程安全也不是可重入的。
可重入与线程安全区别
- 可重入函数是线程安全函数的一种
- 可重入函数 ⇒ 线程安全,线程安全不一定是可重入的
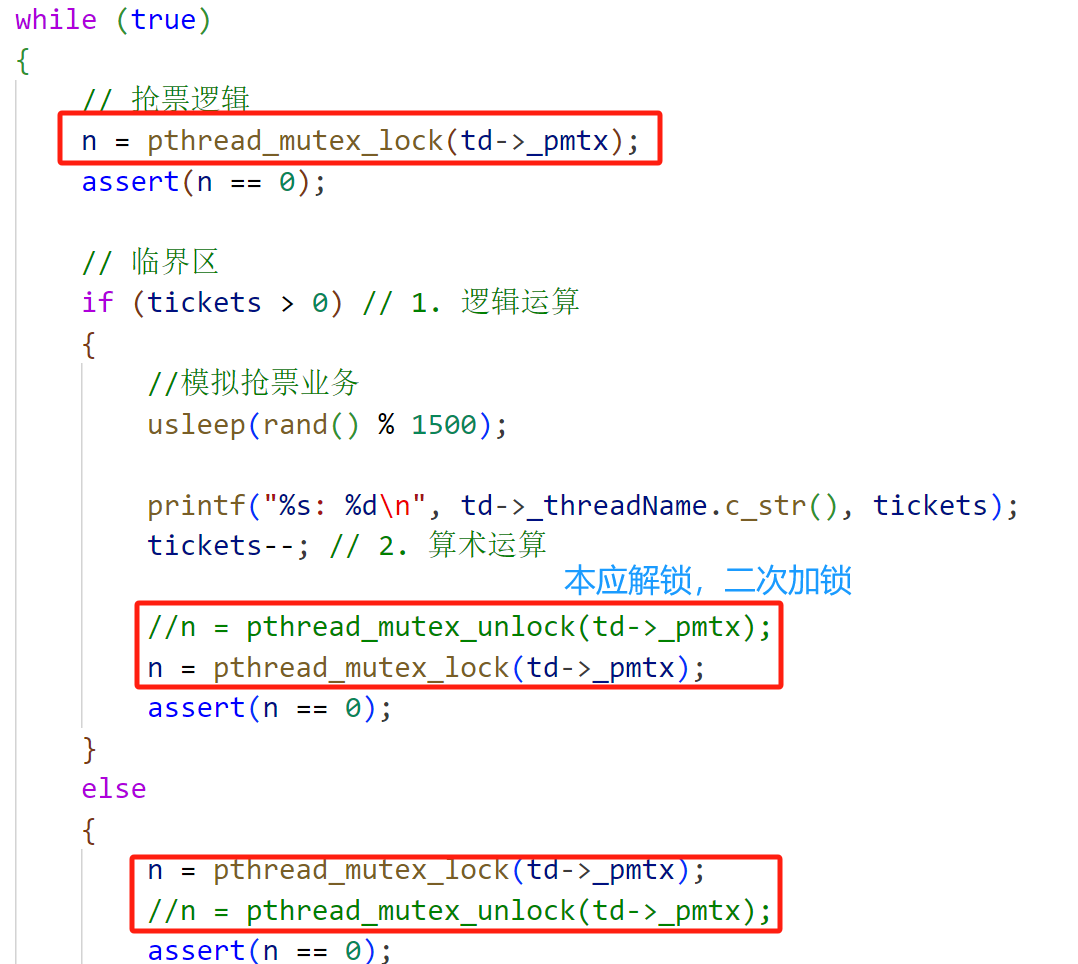
- 如果对临界资源的访问加上锁,则这个函数是线程安全的,但如果这个重入函数锁还未释放则会产生死锁,因此是不可重入的【示例如下,即线程只使用一个锁的死锁现象】
8.完善后的代码
#include <iostream>
#include <thread>
#include <cerrno>
#include <cstring>
#include <unistd.h>
#include <pthread.h>
#include <ctime>
#include <cassert>
#include <cstdio>
using namespace std;
// pthread_mutex_t 是原生线程库提供的一个数据类型
// pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER; 全局锁的初始化方式
/*
#define PTHREAD_MUTEX_INITIALIZER
{
{
0, 0, 0, 0, 0, __PTHREAD_SPINS, { 0, 0 }
}
}
*/
class ThreadData
{
public:
ThreadData(const std::string &threadName, pthread_mutex_t *pmtx)
: _threadName(threadName), _pmtx(pmtx)
{
}
public:
std::string _threadName;
pthread_mutex_t *_pmtx;
};
int tickets = 10000; // 并发访问如果不加保护的访问临界资源就会出现数据不一致
void *getTickets(void *args)
{
// 加锁的粒度越小越好
ThreadData *td = (ThreadData *)args;
int n = 0;
while (true)
{
// 抢票逻辑
n = pthread_mutex_lock(td->_pmtx);
assert(n == 0);
// 临界区
if (tickets > 0) // 1. 逻辑运算
{
// 模拟抢票业务
usleep(rand() % 1500);
tickets--; // 2. 算术运算
cout << td->_threadName << "have got one, remain: " << tickets << endl;
n = pthread_mutex_unlock(td->_pmtx);
assert(n == 0);
}
else
{
n = pthread_mutex_unlock(td->_pmtx);
assert(n == 0);
break;
}
// 抢完票后续动作
usleep(rand() % 2000);
}
delete td;
return nullptr;
}
#define THREAD_NUM 100
int main()
{
time_t start = time(nullptr);
srand((unsigned long)time(nullptr) ^ getpid() ^ 0x147);
pthread_mutex_t mtx;
pthread_mutex_init(&mtx, nullptr);
pthread_t t[THREAD_NUM];
// 多线程抢票的逻辑
for (int i = 0; i < THREAD_NUM; i++)
{
std::string name = "thread " + std::to_string(i + 1);
ThreadData *td = new ThreadData(name, &mtx);
pthread_create(t + i, nullptr, getTickets, (void *)td);
}
for (int i = 0; i < THREAD_NUM; i++)
{
pthread_join(t[i], nullptr);
}
pthread_mutex_destroy(&mtx);
time_t end = time(nullptr); // typedef long time_t
std::cout << "run time: " << (long long)(end - start) << "s" << std::endl;
}

设两个进程共用一个临界资源的互斥信号量mutex,当mutex=1时表示
没有一个进程进入临界区而非两个进程都在等待
mutex简单理解就是一个0/1的计数器,用于标记资源访问状态:
0表示已经有执行流加锁成功,资源处于不可访问
1表示没有执行流完成加锁,资源可访问
请简述什么是线程互斥,为什么需要互斥
线程互斥:线程互斥是一种机制,这种机制确保当多个线程会访问临界资源时只有一个线程能够访问临界资源,其他线程必须等待。
原因:如果没有互斥机制,会导致数据不一致或数据损坏。具体来说,多个线程可能在进程的地址空间内部同时运行,进程的大部分资源对于线程来说是共享的。当多个线程同时尝试对临界资源进行操作时,如果没有互斥机制,会导致数据不一致或数据损坏。
进程/线程信息
ps命令用于查看进程信息,其中-L选项用于查看轻量级进程信息
pthread_self() 用于获取用户态线程的tid,而并非轻量级进程ID
getpid() 用于获取当前进程的id,而并非某个特定的轻量级进程
在有多个线程的情况下,主线程调用pthread_cancel(pthread_self()), 则主线程状态为Z, 其他线程正常运行
主线程调用pthread_cancel(pthread_self())函数来退出自己, 则主线程对应的轻量级进程状态变更成为Z, 其他线程不受影响,这是正确的(正常情况下我们不会这么做)
在有多个线程的情况下,主线程从main函数的return返回或者调用pthread_exit函数,则整个进程退出
主线程调用pthread_exit只是退出主线程,并不会导致进程的退出
简述什么是LWP
LWP是轻量级进程。在Linux下进程是资源分配的基本单位,线程是cpu调度的基本单位,而Linux下的线程使用进程pcb描述实现,同一个进程中的所有pcb共用同一个虚拟地址空间,因此相较于传统进程,Linux下的线程更加的轻量化,我们称之为轻量级进程。
简述LWP与pthread_create创建的线程之间的关系
pthread_create是一个库函数,功能是在用户态创建一个用户级线程,而这个线程的运行调度是基于一个轻量级进程实现的。
轻量级进程ID与进程ID之间的区别
Linux下的轻量级进程是一个pcb,每个轻量级进程都有一个自己的轻量级进程ID(pcb中的pid),而同一个程序中所有的轻量级进程组成线程组,拥有一个共同的线程组ID。