概述
Nvidia的GPU发展了30多年,已经逐渐形成了消费级、专业级、AI加速等不同计算任务的GPU系列。
纵观Nvidia的GPU发展历程,其不断迭代的GPU架构以及性能强劲的GPU互联技术成了Nvidia始终站在市场顶峰的决胜法宝。
当前Nvidia企业级GPU的互联架构
Nvidia企业级GPU的互联经过20年的发展,产品不断在迭代,性能越来越高,但互联架构基本万变不离其综。采用PCIe+NVLink的协议组合,两类Switch的连接拓扑(SuperChip系列除外)。
与传统的互联相比:
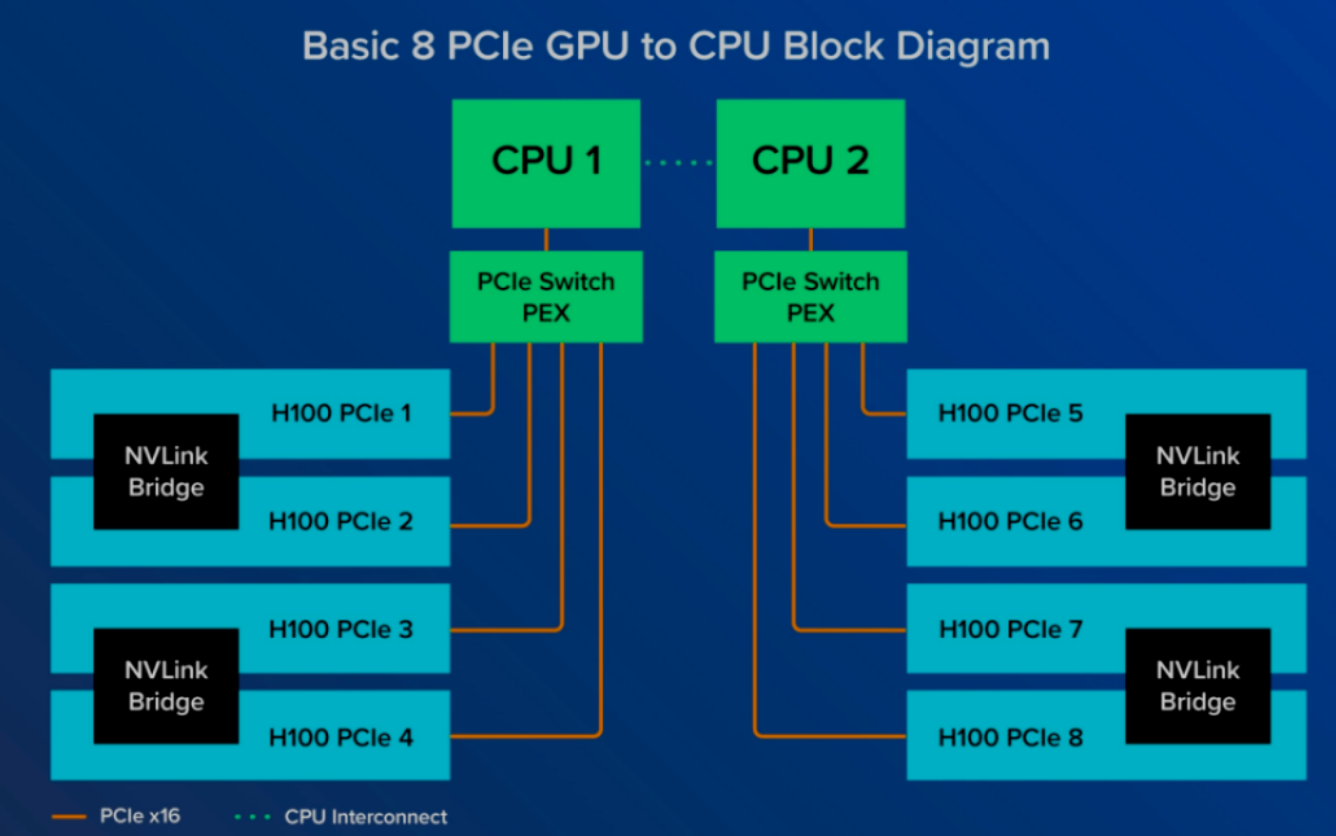
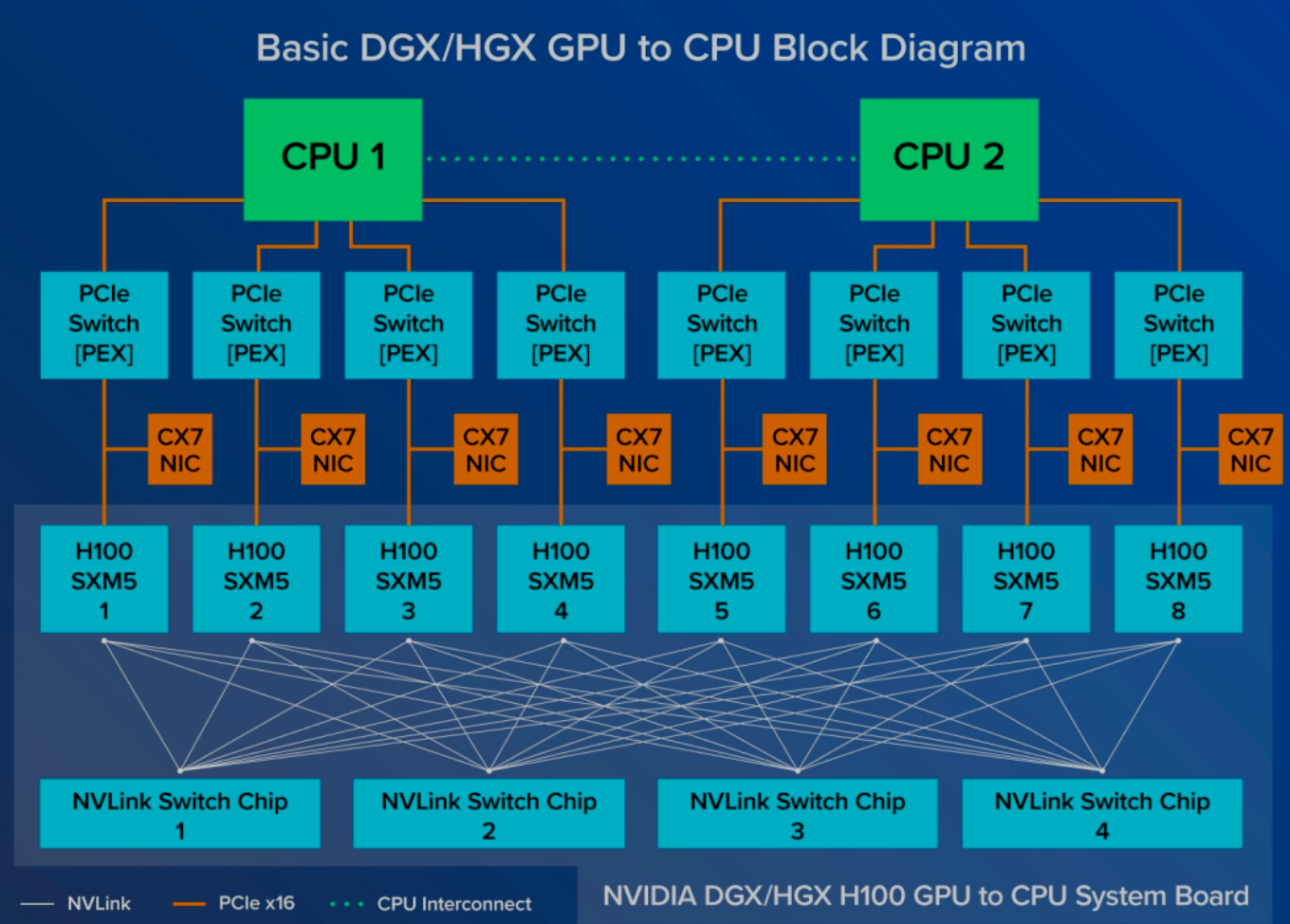
Nvidia GPU的两种接口:SXM和PCIe
Nvidia发布的AI计算平台(机架式服务器)有两种,一种是SXM版本(Socketed Multi-Chip Module,即链路层为NVLink版本),另一种是PCIe版本。
SXM是英伟达专为实现GPU间超高速互连而研发的一种高带宽插座式解决方案。这一独特的设计使得GPU能够无缝对接于英伟达自家的DGX和HGX系统。这种设计为每一代Nvidia GPU配备了特定的SXM插座3,确保GPU与系统间实现最该效率的连接。
pcie版本则面向传统的CPU服务器架构,GPU通过pcie switch与CPU相连,每两个GPU则通过NVLink Bridge连接,与SXM相比GPU间的通信效率较低。
DGX、HGX和EGX
DGX、HGX和EGX是Nvidia退出的三种服务器参考架构,后面常跟具体的GPU型号,比如DGX B200等等。
DGX可视为出厂预装且高度可扩展的完整服务器解决方案,包含了Nvidia的GPU、CPU、DPU产品。
多台NVIDIA 显卡可通过NVSwitch系统轻松组合,形成包含32个乃至64个节点的超级集群SuperPod,足以应对超大规模模型训练的严苛需求。
DGX分为BasePOD9和SuperPOD10两个系列,BasePOD是Nvidia自定义的计算系统,通过多个NVswitch将GPU连接起来,通信效率更高,而SuperPOD则类似数据中心场景,通常常用机架式的服务器连接。
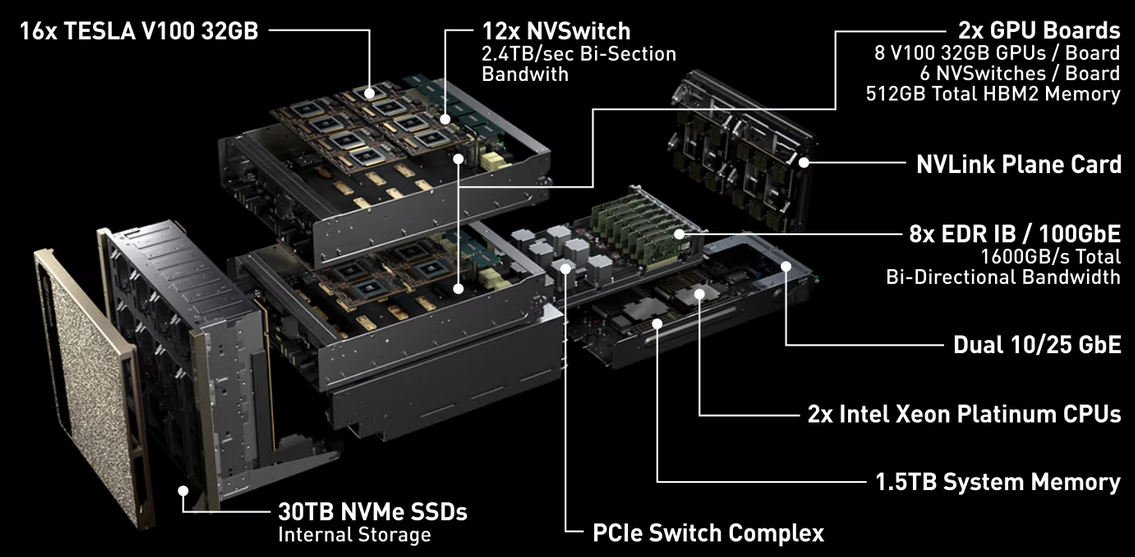
HGX则属于原始设备制造商(OEM)定制整机方案,包含了CPU和GPU。
EGX则用在边缘端,包含了CPU和GPU,但相比HGX规模更小。
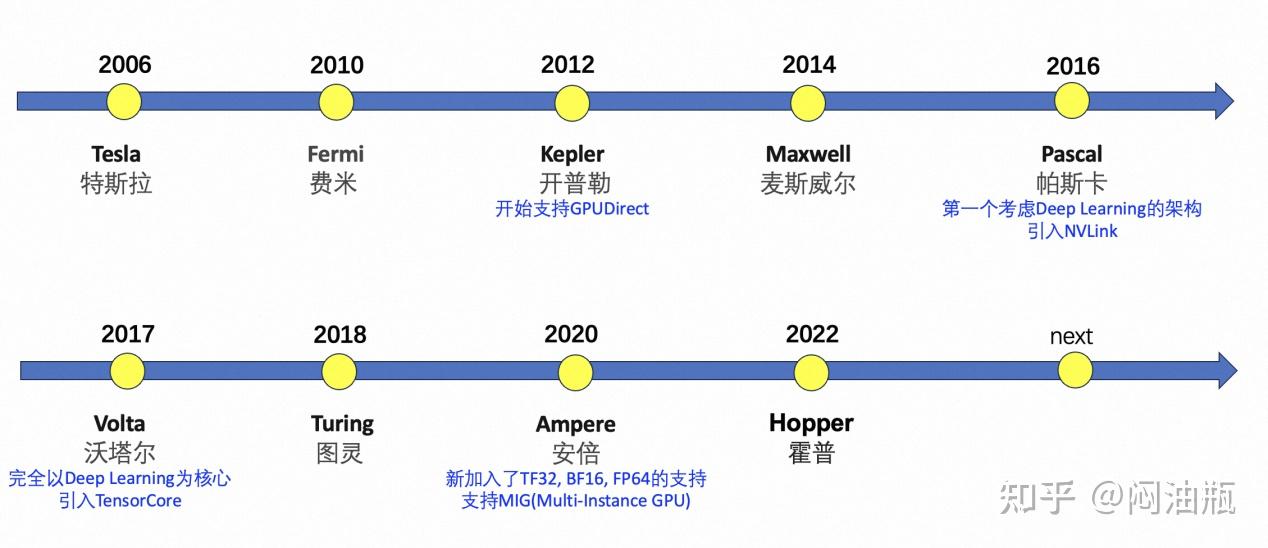
每代GPU产品的芯片架构
Nvidia的GPU从2006年到2024年开始依次Tesla → Fermi → Kepler → Maxwell → Pascal → Volta → Turing → Ampere → Hopper → Blackwell的架构演进。
截止Ampere架构的详细说明请参考此文8。
消费级GPU
主要包括GeForce系列(G系列),面向桌面端的游戏玩家或普通用户
专用型GPU
主要包括Quadro系列(P系列),面向计算机辅助设计、动画制作、虚拟显示领域
企业级GPU
包括Tesla系列等,主要面向高性能计算、机器学习等任务。
B100
2024年GTC上发布,具体参数如下,用在HGX B100计算系统中
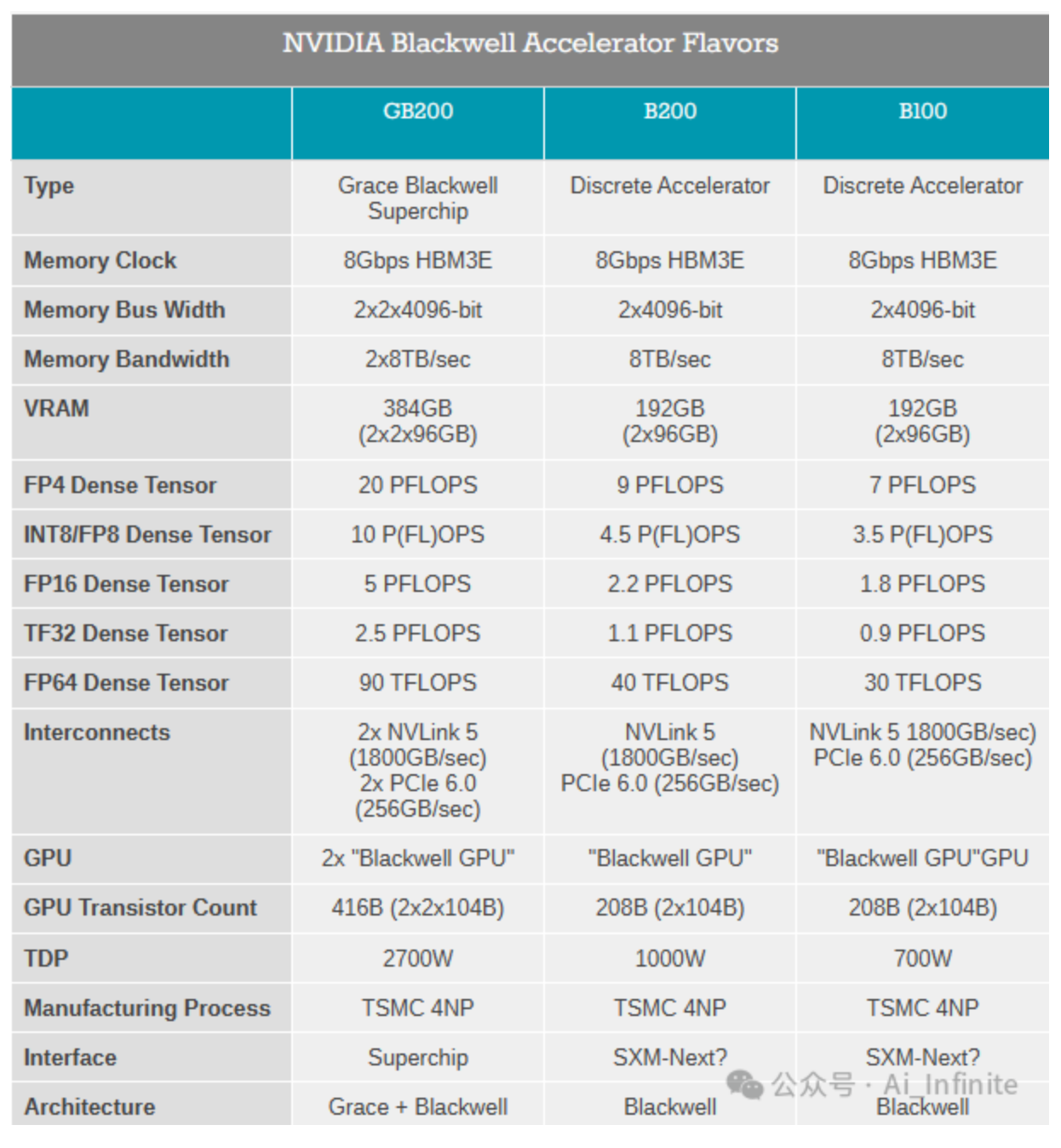
B200
2024年GTC上发布,该芯片采用Blackwell架构,具有 2080 亿个晶体管,采用专门定制的台积电 4NP 工艺制造。所有 Blackwell 产品均采用双倍光刻极限尺寸的裸片,通过 10 TB/s 的chiplet互联技术 NV-HBI连接成一块统一的 GPU。
B200可以支持多达 10 万亿个参数的 AI 模型,而 OpenAI 的 GPT-3 由 1750 亿个参数组成。它还通过单个 GPU 提供 20 petaflops 的 AI 性能——单个 H100 最多可提供 4 petaflops 的 AI 计算。
- 2x GPU die + 8x HBM3e
- 通过HBM 单芯片内存可达192GB
- D2D接口:NV-HBI(高带宽接口) 带宽:10 TB/s
- 功耗:1000W
- NVlink5 带宽:1800 GB/s
- PCIe 6.0 带宽:256 GB/s

超级芯片(Superchip)
超级芯片是由Nvidia的CPU和GPU通过NVLink协议在板级上封装起来的集成系统。Grace是Nvidia基于Arm架构研发的CPU。
Grace Hopper(GH100)
2022年春季,Nvidia发布了Grace Hopper GPU平台。Grace Hopper平台实际上是由Grace CPU和Hopper GPU通过NVLink C2C技术连接的超级芯片(Superchip)4。

Grace blackwell(GB200)
2024年3月GTC 2024会议上,Nvidia发布了Grace blackwell GPU平台,该平台是由Grace CPU和Blackwell架构的GPU通过NVlink-C2C构成的superchip。相比于前一代的一对一连接,GB改成了一对二连接。
- chip-to-chip接口:NVlink C2C技术 900GB/s
- 功率:2700W

AI计算平台
同样是CPU+GPU的加速平台,与GH和GB等系列不同的,BasePOD的CPU通常是Intel的志强系列。
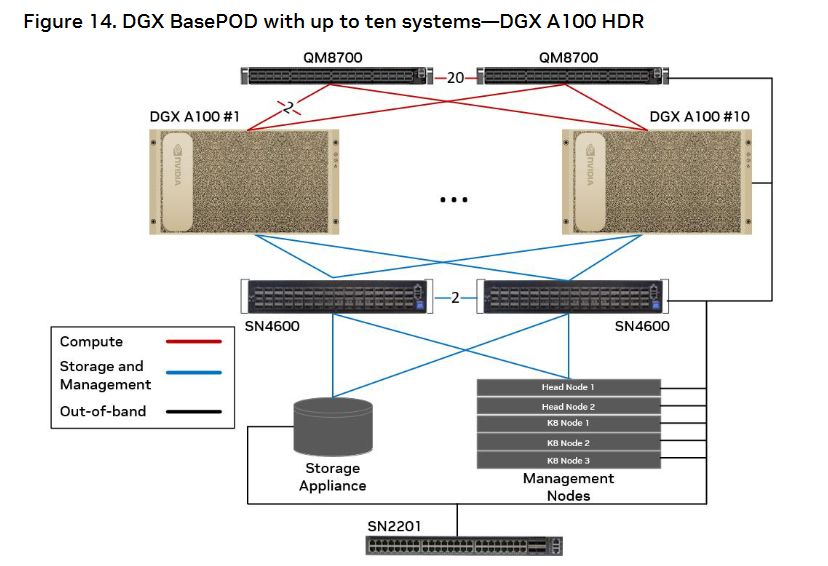
DGX A100 BasePOD
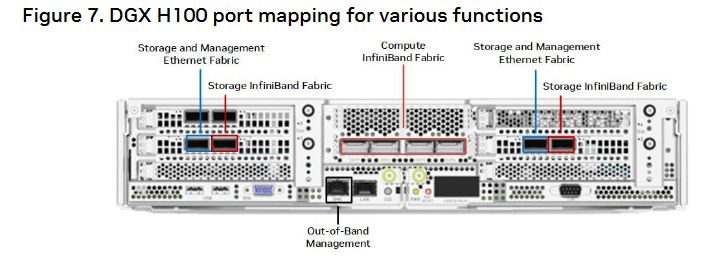
DGX H100 BasePOD
DGX H100是用于训练、推理和分析的高性能AI计算系统。组件包括BlueField-3 DPU、DNR InfiniBand、第二代MIG技术以及H100 GPU。
- 8个H100 GPU
- 2个56 core的intel Xeon处理器
- 16 petaFLOPS@FP16

DGX B200 BasePOD
2024年3月,Nvidia发布了其最新的用于AI运算的统一平台 DGXTM B200,相比上一代提升了3倍的训练性能和15倍的推理性能,可以处理不同的工作负载,包括大语言模型、推荐系统(recommender system)和对话机器人(chatbots)等。
- 8个 B200 张量核GPU,每个GPU采用Blackwell GPU架构
- 1440 GB GPU内存
- 两个 Intel® Xeon® Platinum 8570 CPU
- 系统内存 4TB
- 72 petaFLOPS training and 144 petaFLOPS inference
- 第5代NVlink
- 功耗~14.3kW max
- 10个rack单元

Hopper DGX SuperPOD
Hopper架构的DGX SuperPOD推测是由basePOD组成的集群系统(官网并没有明说,根据数据手册的图片推测)。
- 第4代NVLink技术 + 第3代NVSwitch
- 最多连接256个H100

Blackwell DGX SuperPOD
GTC2024公布的基于Blackwell架构的数据中心。与上一代Hopper架构的SuperPOD不同,Blackwell架构的SuperPOD的基本节点不再是BasePOD,而是1U大小的Blackwell计算节点,该节点由Grace Blackwell、NVswitch、DPU等设备组成,集成度相比BasePOD更高。
下图是GTC2024黄仁勋主题演讲的截图,由于产品尚未完全发布,不排除也会由DGX B200 BasePOD系统组成的SuperPOD。
- 第5代NVLink技术 + 第5代NVSwitch
- 最多连接576个GB
SuperPOD集群如图所示:

多台NVL72构成超算集群
2块GB200构成一个blackwell计算节点。

18个Blackwell计算节点构成一个Rack,即一个GB200计算节点。如图所示,图中显示27个Blackwell节点,猜测有可能分水冷和风冷,水冷节点数可能多一点。

一个rack再包含光量子infiniband路由器可构成GB200 NVL72平台。


通过Quantum-X800 infiniband或者spectrum-X800网络交换机连接racks, 8台NVL72构成rack集群

单计算节点组成
infiniband 网卡
每个计算节点配备了connectx-800G infiniband supernic,工业级的先进的GPU RDMA,且可编程配置

Bluefield-3 DPU
强大的基础设施处理器,能够实现网络内计算

NVLink switch
用于连接一个GB计算节点上的4个GPU,构成网络。

互联技术
NVLink和NVSwitch
NVLink是NVIDIA推出的一种高速的GPU到GPU的互联接口协议;
NVSwitch是将多条NVLink整合,在单个节点内以NVLink的速度实现多对多的GPU通信的芯片。
二者类似PCIe技术和PCIe switch的关系,但与传统的 PCIe 系统解决方案相比,NVLink能为多 GPU 系统提供更快速的替代方案。
如图所示是NVIDIA发布的几代NVLink信息7:


NVLink C2C
将NVLink技术延申到芯片到芯片,将Nvidia的GPU、DPU和CPU一致性的互连起来。
基于世界领先的Serdes链路技术,通过先进封装,NVLink-C2C相比GPU上的PCIe5.0 PHY有25倍的能效提升和90倍的面积效率提升。与传统的SerDes互联相比,NVLink C2C采用了高密度单端架构和NRZ调制。
- 支持AMBA CHI协议
- 互联带宽为900GB/s
- 40Gbps NRZ调制,BER<1e-12
- 免除FEC,接口时延可以做到小于5ns
软件
参考文献
- Nvidia官网:DGX B200
- Nvidia官网:NVLink-C2C
- 智能计算芯世界:英伟达AI服务器NVLink版与PCIe版的差异与选择
- Nvidia官网:H100白皮书
- Nvidia官网:Blackwell 架构
- 极客湾:英伟达官宣全球最强AI芯片:性能提升 30 倍,并将重新设计整个底层软件堆栈
- NVIDIA官网:NVlink和NVswitch
- Will Zhang知乎:英伟达GPU架构演进近十年,从费米到安培
- NVIDIA官网:DGX BasePOD
- NVIDIA官网:DGX SuperPOD
- 不糊弄的说微信:NVIDIA Blackwell架构和实现详解