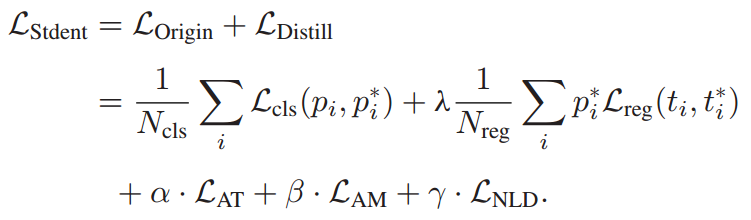2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛B题 解题全流程(持续更新)
-----基于多模态特征融合的图像文本检索
一、写在前面:
- 本题的全部资料打包为“全家桶”, “全家桶”包含:数据、代码、模型、结果csv、教程、详细实验过程PPT、教学视频、论文借鉴大纲构思
- 达到“以赛促学”的目的,从0到1,从环境配置开始,到模型构建、数据准备、模型训练、模型recall_TOP1、5、10召回验证、文到图预测、图到文预测、预测结果后处理为result.csv。全流程教学,良心制作。
- 本题基于Chinese Clip 多模态图文互检模型进行微调模型、知识蒸馏,根据赛题示例数据进行模型训练。
- 对比A题B题C题,B题C题偏难,相对选择人少,容易获奖,并且论文非常好写出创新和模型对比优化等核心部分。
二、先上结果:
2.1 任务一 构建图文互检多模态大模型以及评价指标展示:


本题模型的验证集就是附件一的全部数据(1k个对图文,分别构成了训练集和验证集),在验证集上的召回验证结果:

2.2 任务二文到图检索结果展示:
展示问题二 利用附件 2 中“word_test.csv”文件的文本信息, 对附件 2 的 ImageData 文件夹的图像进行图像检索,并罗列检索相似度较高的前五张图像,(预测结果的样例展示:)

result2.csv:


任务三 图到文检索结果展示:


result2.csv:

三、解题流程:
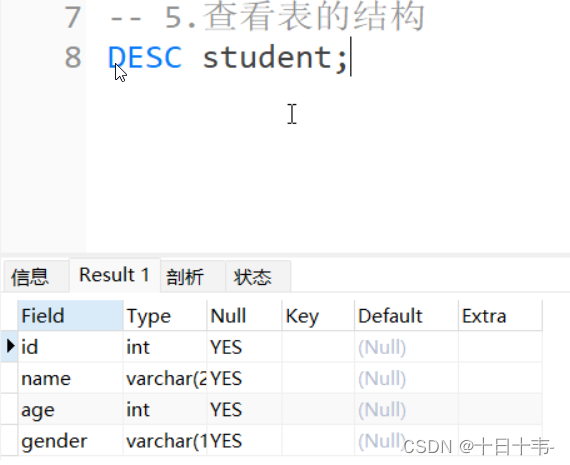
3.1 【样例数据】附件一 1k个图文对 数据分析与预处理
1、查看文本数据,句子长度,根据句子长度与句子的特征进行文本处理:

针对短文本,可以不用做处理,一般表示的就是这张图片的主体意思,针对长文本,需要使用句子特征(如【】,()、《》)进行提取,再根据命名实体识别、句子“主题式概括”进行罗列该图片的主体意思
再对图id与文本id进行重新id编码
处理结果如下所示:

2、进行模型构建训练的数据,本着样例数据少,1k个图文对,就不划分训练集和验证集数据了,直接训练集是1k个图文对,验证集也是1k个图文对,分别处理为对应的clip模型数据,jsonl,tsv格式:

其中tsv数据格式: 不是将图片以大量的小文件方式存放,而是将训练/验证/测试图片以base64形式分别存放在${split}_imgs.tsv文件中。文件每行表示一张图片,包含图片id(int型)与图片base64,以tab隔开,
最后经过序列化代码,对模型数据进行序列化,转换为模型训练的输如数据。进行模型训练
3.2 模型训练
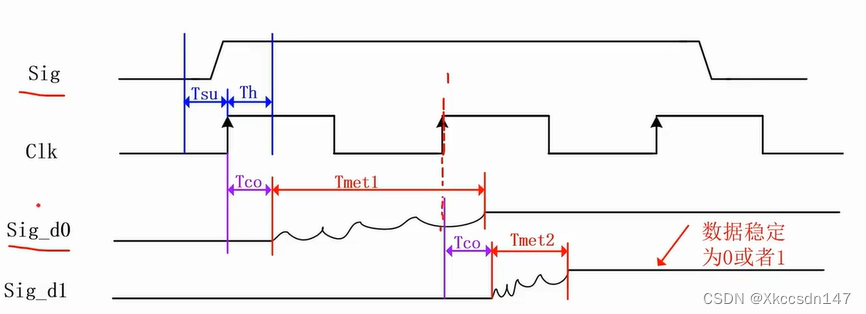
1、根据序列化的训练数据,选择模型合适的预训练权重,进行模型训练,(主要的坑在于该Chinese Clip模型的库文件配置不详、环境配置不详,并且训练的方式只能是分布式,就是一个机子没有分布式,都得填入伪分布式配置,就会导致训练失败),模型的训练环境要求、以及所需库文件版本,在教学视频和教程中有详细描述,并且整理为clipenv_requirements.txt。

3.3 任务二的结果预测:
1、针对任务二的“文到图检索”,首先需要对附件二的图数据、文本数据(依旧需要处理,如上3.1的文本数据处理。针对长短文本的处理),进行制作为tsv、jsonl格式
2、送入模型,进行特征提取,输出每个图片的特征矩阵、每个文本的特征矩阵数据
3、根据特征数据,进行预测,对每个文本id进行预测近似的5个图片id
4、根据预测结果,将文本id与图片id,根据前期处理的对照表,进行名称配对,使用pands进行表格处理,得到result1.csv
3.4 任务三的结果预测:
1、针对任务二的“图到文检索”,如任务二流程一样,数据准备
2、模型特征提取
3、根据特征数据,进行预测,对每个图片id进行预测近似的5个文本id
4、配对、result2.csv
四、全家桶内容展示
正式数据出来后也会更新全家桶的内容。



五、tips

获取全家桶:
“https://afdian.net/item/8cc7f3dae8d111eeb7b05254001e7c00“
历时5天晚上抽空制作,精心打磨,保证物有所值,
后续(时间不定,可能比赛结束后,用时一周时间,全家桶的支持补差价)会基于这个写一个可以做毕设或者课题申请、大创等展示作品,基于streamlit开发展示界面,效果类似于如下:(你完全可以收集一些专业领域的图文对、例如旅游、科研器材等,进行模型训练,然后填入该训练的模型权重,基于你的训练数据,进行图文互检的功能,这不又省了一个毕设了吗2333,创新点就可以是模型迁移、模型知识蒸馏等对比实验提高了一点评价指标。)