有人可能会说,字符串这么简单还用介绍?但是很多人学习rust受到的第一个暴击就来自这浓眉大眼、看似毫无难度的字符串。
请看下面的例子。
fn main() {
let my_name = "World!";
greet(my_name);
}
fn greet(name: String) {
println!("Hello, {}!", name);
}
这段简单Hello world的代码看起来没什么问题,但是在rust里却编译不了。
error[E0308]: mismatched types
--> src/main.rs:3:11
|
3 | greet(my_name);
| ^^^^^^^
| |
| expected struct `std::string::String`, found `&str`
| help: try using a conversion method: `my_name.to_string()`
error: aborting due to previous error
报错的意思是,greet函数需要一个String类型的参数,但是提供了一个&str类型的实参。
这下不觉得字符串简单了吧?
学习Rust你必须理解&str和String的区别。别急,你还经常会在代码里看到 &'static str、&[u8]、&[u8; N]、Vec<u8> 、OsStr、OsString、CStr和CString。
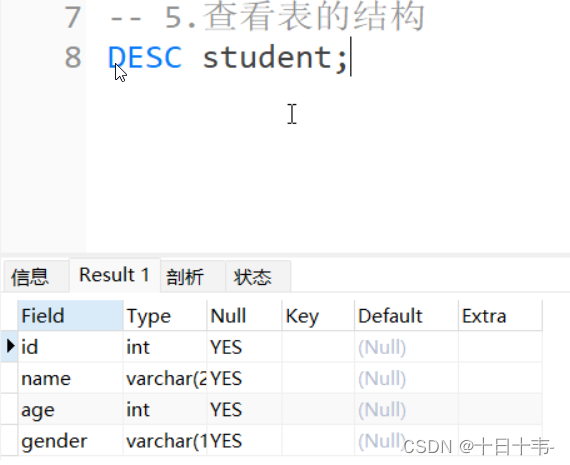
这张图很好地描绘了学习Rust后再谈到字符串的情形:

本文就介绍一下这些字符串相关的类型。
先来说说&str
&str
str类型也叫字符串切片,是最基本的字符器类型,通常是借用的试出现,也就是&str。
什么是切片?
在rust里,切片是连续序列[T]的动态大小视图 ,切片是内存块的视图,表示为指针和长度。 这样的定义会让人难以理解。其实slice就是一种引用,允许你对一个连续序列中元素进行引用。
fn main() {
let a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let slice = &a[3..7];
println!("{:#?}", slice);
}
let slice = &a[3..7];这一行我们创建了一个slice。它的内容是:
[
4,
5,
6,
7,
]
slice的中文翻译切片这个词,很容易让人认为是从一个连续序列中切下来一段,很难与引用联想在一起,我认为翻译成片段可能更合适。
理解了slice,&str就好理解了,&str就是字符串的slice。Rust负责保证str是有效的UTF-8。因为通常是以借用引用(&str)的方式出现,因此是不可变的。
在其它语言中常用的字符串操作,如split、find、trim,大小写转换等操作,都是str的方法,并不是由String类型提供。
在这里要注意,在对字符串使用切片语法时需要格外小心。因为字符串的内部是[u8]数组,每个数组的元素是一个u8,所以数组的长度就是字符串的长度,跟你看到的字符串的长度可能是不一样的。
let s = "我是中国人";
println!("{}",s.len());
你以为结果会是5,但是结果是15; 为什么是15,因为这个字符串的字节数是15。
let s = "我是中国人";
println!("{:?}",s.bytes())
结果是:
Bytes(Copied { it: Iter([230, 136, 145, 230, 152, 175, 228, 184, 173, 229, 155, 189, 228, 186, 186]) })
字符串的len()返回的是字节数,不是UTF-8字符数。
let s = "我是中国人";
println!("{}",s.chars().count());
这时输出的才是5。
所以当直接对字符串对切片时,一定要注意切片的索引必须落在字符之间的边界位置。
let s = "我是中国人";
let a = &s[0..2];
println!("{}",a);
这段代码可以编译,但是在运行时会报错
Compiling playground v0.0.1 (/playground)
Finished dev [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/playground`
thread 'main' panicked at src/main.rs:4:15:
byte index 2 is not a char boundary; it is inside '我' (bytes 0..3) of `我是中国人`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
每个汉字占用3个字节,&s[0..2]只取了前两个节点,所以报错信息告诉你,index 2是不是字符的边界。所以对字符串使用切片语法时需要格外谨慎。
注意: Rust里字符串字面量的类型是&'static str,这涉及到静态生命周期,有兴趣同学可以参考生命周期相关的文章。
String
在rust中String不是基本类型,是个复合类型,它包含了一个私有的u8的vec。
pub struct String {
vec: Vec<u8>,
}
因为它的唯一字段vec是私有的,所以只能通过String类型提供的构建函数创建String,因此let my_name = "Rust";这样语句创建出来的不是String类型。
因为它的底层是一个vec,所以String支持改变它自身的一些操作,比如push、pop、clear,可以看出来都是针对vec的操作。
let mut s = String::from("abc");
s.push('1');
s.push('2');
s.push('3');
assert_eq!("abc123", s);
let mut s = String::from("abč");
assert_eq!(s.pop(), Some('č'));
assert_eq!(s.pop(), Some('b'));
assert_eq!(s.pop(), Some('a'));
assert_eq!(s.pop(), None);
let mut s = String::from("foo");
s.clear();
assert!(s.is_empty());
assert_eq!(0, s.len());
assert_eq!(3, s.capacity());
&[u8]
&[u8]是一个切片,指向一段连续的内存区域,其中存储着 u8 类型的值(字节)。它不拥有数据,只是借用了数据的引用。
由于不拥有数据,&[u8] 通常用于不可变的字符串操作。可以从 String 或其他字节数组中创建&[u8] 切片。
let mut my_string = String::from("Hello, world!");
// 获取 &[u8] 切片
let my_bytes: &[u8] = my_string.as_bytes();
// 将 &[u8] 转换为 String (需要确保是有效的 UTF-8 编码)
let new_string = String::from_utf8(my_bytes.to_vec()).unwrap();
&[u8;N]
&[u8; N] 表示一个指向长度为 N 的 u8 类型数组的切片。
与 &[u8]的区别是,&[u8] 是一个指向任意长度u8 类型数组的切片,可以指向不同长度的数组。&[u8; N]是一个指向固定长度为 N 的字节数组的切片,只能指向长度为 N 的数组。
一个特别常用的场景就是网络协议栈的解析,数据包头通常都是固定长度的,非常适合用&[u8; N]来保存。
Vec<u8>
Vec<u8> 是String类型的底层存储,可以通过String::from_utf8这个方法创建一个String。
&u8
&u8只是 &[u8]切片中的一个元素,也不展开介绍。
OsStr和OsString
这两个类型包含在std::ffi这个模块里,ffi 的意思是 Foreign Function Interface ,外部函数接口,用来调用其它语言(如C语言)编写的函数。因为目前主流的操作系统都是用C语言写的,所以ffi可以用来调用系统接口和处理与操作系统相关的操作。
为什么需要OsStr和OsString呢?
因为在不同的操作系统中,字符串的编码是有差异的。
在 Unix 系统上,字符串通常是非零字节的任意序列,通常情况下,这些字符串会被解释为 UTF-8 编码的文本,但并非总是如此。
在 Windows 上,字符串通常是非零 16 位值的任意序列,通常情况下,这些字符串会被解释为 UTF-16 编码的文本,也并非总是如此。
在 Rust 中,字符串始终是有效的 UTF-8 编码,可以包含零。 这意味着 Rust 字符串只能包含有效的 UTF-8 编码的字节序列,但可以包含 0 字节。
因为操作系统原生字符串与Rust字符串的这种差异,因此需要有一种类型能同时表示这两种字符串,并可以在需要时进行相互转换,这种类型就是OsString 和 OsStr。
注意, OsString 和 OsStr 内部不一定以平台原生的形式保存字符串;
use std::env;
use std::ffi::OsString;
fn main() {
// 获取命令行参数
let args: Vec<OsString> = env::args_os().collect();
// 获取第一个参数(文件名)
let filename = &args[1];
// 打印文件名
println!("Filename: {:?}", filename);
}
Path 和PathBuf
Path 结构表示底层文件系统中的文件路径。有两种样式: Path posix::Path ,用于类 UNIX 系统,以及 windows::Path ,用于 Windows。只所以有两种形式,是因为windows和Unix的路径差别很大,比如路径分隔符就不一样,windows用\,Unix用/。
prelude.rs会根据当前平台导出相应的特定于平台 Path 的变体。
Path这个类型是一个切片,是不可变的(immutable),它的owned版本的类型是PathBuf。Path和PathBuf的关系跟str和String的关系相似。
因为Path是与操作系统相关的,因此它内部使用的是OsStr。
pub struct Path {
inner: OsStr,
}
下面是Path的代码示例。
use std::path::Path;
use std::ffi::OsStr;
// 注意: 下面代码不能运行在windows下
let path = Path::new("./foo/bar.txt");
let parent = path.parent();
assert_eq!(parent, Some(Path::new("./foo")));
let file_stem = path.file_stem();
assert_eq!(file_stem, Some(OsStr::new("bar")));
let extension = path.extension();
assert_eq!(extension, Some(OsStr::new("txt")));
PathBuf是 Path的 owned版本,是可变的。
use std::path::PathBuf;
let mut path = PathBuf::new();
path.push(r"C:\");
path.push("windows");
path.push("system32");
path.set_extension("dll");
CStr和CString
在C语言中字符串是NUL(\0)为结尾的一维字符数组。
Rust中的CStr表示对以 nul 结尾的字节数组的借用引用,也就是C语言的字符串在Rust中的对应类型。
它可以安全地从 &[u8] 切片构建,也可以不安全地(unsafely)从原始 *const c_char 构建。
因为Rust的字符串必须是UTF-8的,所以CStr要转换为String,需要通过 UTF-8 验证,以保证每个字符都是UTF-8的。
use std::ffi::CStr;
use std::os::raw::c_char;
extern "C" { fn my_string() -> *const c_char; }
unsafe {
let slice = CStr::from_ptr(my_string());
println!("string buffer size without nul terminator: {}", slice.to_bytes().len());
}
总结
在Rust语言中有几种字符串相关的类型,&str和String是Rust字符串最常用的类型,前者是一个slice,是借用引用,后者则是它的owned版本,可变。OsStr和OsString是Rust的字符串和操作系统原生字符串的桥,通过这个桥,Rust的字符串和操作系统原生字符串可以相互转换。Path和PathBuf则是Rust为不同的操作系统提供的统一的路径(Path)类型,在内部使用的是OsStr。而CStr则是C语言中以NUL(\0)为结尾的一维字符数组在Rust语言的一种表示。
本文为原创,未经同意不得转载。本文亦发表于https://www.renhl.com/posts/2024/03/17/rust-string-osstring-cstring/