1
1
目标检测是计算机视觉领域中的一项重要任务,它的目标是在图像或视频中检测出物体的位置和类别。YOLO(You Only Look Once)是一系列经典的目标检测算法,最初由Joseph Redmon等人于2016年提出。YOLO算法具有快速、简单、端到端的特点,并且在速度和准确率上取得了很好的平衡,因此受到了广泛的关注和应用。
YOLO系列算法的核心思想是将目标检测问题转化为一个回归问题。它将整个图像分成一个固定大小的网格,每个网格负责检测该网格内的物体。YOLO算法在每个网格上预测多个边界框(bounding box),以及每个边界框所属的物体类别以及置信度分数。
YOLO算法系列有多个版本,包括YOLOv1、YOLOv2(也称为YOLO9000)、YOLOv3和YOLOv4等。每个版本都在YOLO的基础上进行了改进,提高了检测精度、速度和通用性。
「今天我们将实现YOLO V6的遥感影像目标检测。」
YOLO V6
YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。本框架同时专注于检测的精度和推理效率,在工业界常用的尺寸模型中:YOLOv6-nano 在 COCO 上精度可达 35.0% AP,在 T4 上推理速度可达 1242 FPS;YOLOv6-s 在 COCO 上精度可达 43.1% AP,在 T4 上推理速度可达 520 FPS。在部署方面,YOLOv6 支持 GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平台的部署,极大地简化工程部署时的适配工作。目前,项目已开源至 Github。
解决的问题:
RepVGG提出的结构重参数化方法表现良好,但在此之前没有检测模型使用。作者认为RepVGG的block缩放不合理,小模型和大模型没必要保持相似网络结构;小模型使用单路径架构,大模型就不适合在单路径上堆参数量。
使用重参数化的方法后,检测器的量化也需要重新考虑,否则因为训练和推理时的结构不同,性能可能会退化。
前期工作很少关注部署。前期工作中,推理是在V100等高配机器完成的,但实际使用时往往用T4等低功耗推理gpu,作者更关注后者的性能。
针对网络结构的变化,重新考虑标签分配和损失函数。
对于部署,可以调整训练策略,在不增加推理成本的情况下提升性能,如使用知识蒸馏。
具体实现:
网络设计
在one-satge的目标检测网络中,Backbone决定了表征能力,也很大程度上影响了参数量和推理效率;Neck主要作用是聚合高低层次的语义信息;Head由几个卷积层组成,负责预测最终结果。
考虑到硬件推理的因素,YOLOv6提出两个可缩放的可重参数化的Backbone和Neck来适应不同大小的模型,还提出一个使用混合通道策略的高效解耦头,总体网络结构如下:
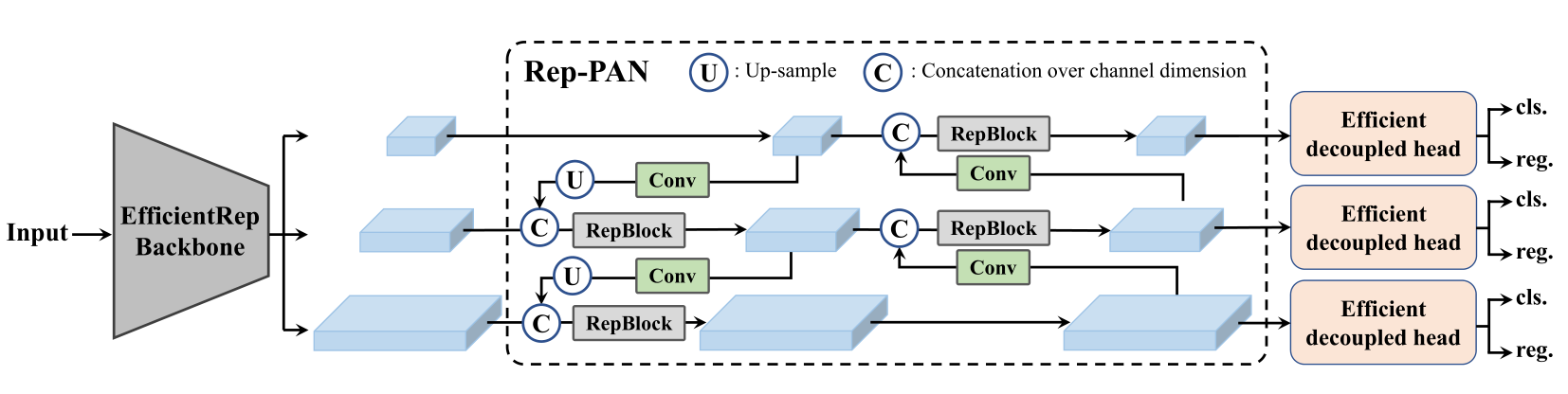
BackBone
在分类性能上,多分支网络相比单分支表现更好,但随并行性降低,其推理速度减慢。RepVGG的结构重参数化方式,采用多分支训练和单分支推理,达到了较好的精度-速度权衡。 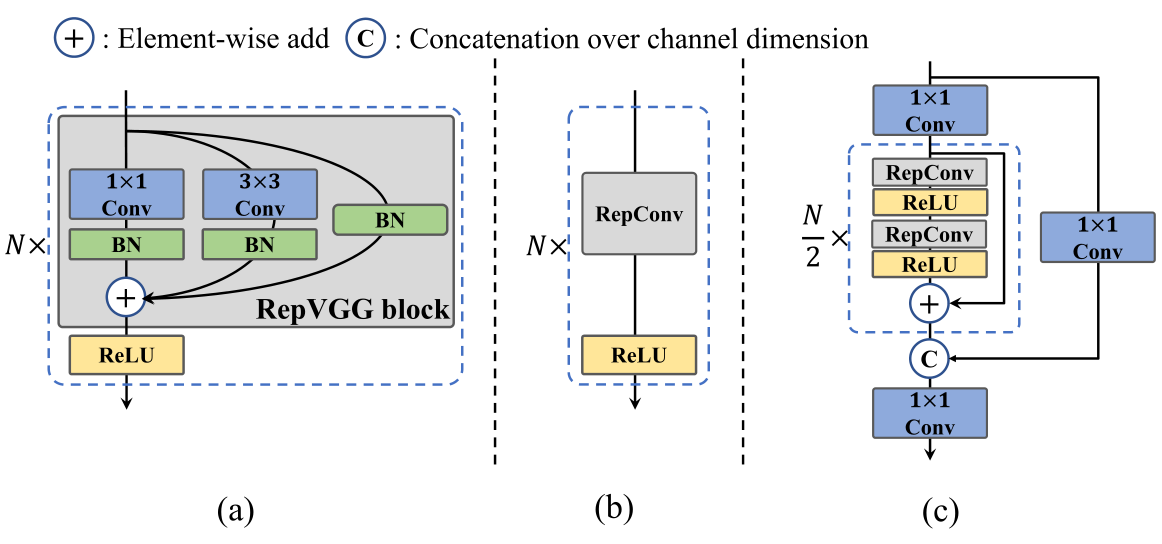 YOLOv6设计了可重参数化的Backbone并命名为EfficientRep。对于小模型,backbone的主要组成部分是训练阶段的 RepBlock,如图2(a)所示。在推理阶段,RepBlock转换为3×3卷积层+ReLU激活函数的堆叠(记为 RepConv),如图2(b)所示。因为3*3卷积在CPU和GPU上优化和计算密度都更好,所以在增强表征能力的同时,可以有效利用计算资源同时增加推理速度。 然而随模型容量增加,单路径模型的计算代价和参数量呈指数级提升,所以改用CSPStackRep Block作为中大型网络的Backbone,如图2(c)所示。CSPStackRep Block由三个1×1卷积和两个带残差连接的RepVGG block(训练使用)或RepConv(推理使用)组成的模块堆叠。可以在不增加计算成本的前提下提升性能,做到准确率和速度的权衡。
YOLOv6设计了可重参数化的Backbone并命名为EfficientRep。对于小模型,backbone的主要组成部分是训练阶段的 RepBlock,如图2(a)所示。在推理阶段,RepBlock转换为3×3卷积层+ReLU激活函数的堆叠(记为 RepConv),如图2(b)所示。因为3*3卷积在CPU和GPU上优化和计算密度都更好,所以在增强表征能力的同时,可以有效利用计算资源同时增加推理速度。 然而随模型容量增加,单路径模型的计算代价和参数量呈指数级提升,所以改用CSPStackRep Block作为中大型网络的Backbone,如图2(c)所示。CSPStackRep Block由三个1×1卷积和两个带残差连接的RepVGG block(训练使用)或RepConv(推理使用)组成的模块堆叠。可以在不增加计算成本的前提下提升性能,做到准确率和速度的权衡。
Neck
集成多尺度的特征是检测模型常用且有效的手段,YOLOv6也不例外,在PAN的基础上,把CSPBlock替换为RepBlock(小模型使用)或CSPStackRep Block(大模型使用),并调整宽度和深度,将YOLOv6的颈部命名为Rep-PAN。
Head
YOLOv5的检测头在分类和回归上共享参数,而FCOS和YOLOX将两个分支解耦,在每个分支中引入两个额外3×3卷积层提高性能。YOLOv6则采用混合通道策略构建高效解耦头,即中间3*3卷积只使用一个,Head的宽度由Backbone和Neck的宽度因子共同缩放,从而进一步降低了计算成本和延迟。此外,YOLOv6使用基于锚点的Anchor free方式,预测锚点到边界框四周的距离。
源码
源码地址;https://github.com/meituan/YOLOv6
安装
git clone https://github.com/meituan/YOLOv6
cd YOLOv6
pip install -r requirements.txt
DIOR数据集
「DIOR」由23463张最优遥感图像和190288个目标实例组成,这些目标实例用轴向对齐的边界框手动标记,由192472个轴对齐的目标边界框注释组成。数据集中图像大小为800×800像素,空间分辨率为0.5m ~ 30m。该数据集分为训练验证集(11725张图像)和测试集(11738张图像)。 「DIOR」是一个用于光学遥感图像目标检测的大规模基准数据集。涵盖20个对象类。这20个对象类是飞机、机场、棒球场、篮球场、桥梁、烟囱、水坝、高速公路服务区、高速公路收费站、港口、高尔夫球场、地面田径场、天桥、船舶、体育场、储罐、网球场、火车站、车辆和风磨。 论文地址:Object Detection in Optical Remote Sensing Images: A Survey and A New Benchmark
数据集处理
由于dior数据集是voc格式,所以需要将其转换为yolo格式。可以参照yolo v6中给出的voc2yolo.py。
也可以参照以下的方法。
新建一个文件夹JPEGImages,将JPEGImages-test和PEGImages-trainval里的图片都放进JPEGImages里面。 代码参考链接:https://blog.csdn.net/weixin_43365477/article/details/135622835
# coding:utf-8
import os
import random
import argparse
import xml.etree.ElementTree as ET
from os import getcwd
from shutil import copyfile
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='DIOR/Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
opt = parser.parse_args()
sets = ['train', 'val', 'test']
classes = ['airplane', 'airport', 'baseballfield', 'basketballcourt', 'bridge', 'chimney', 'dam',
'Expressway-Service-area', 'Expressway-toll-station', 'golffield', 'groundtrackfield', 'harbor',
'overpass', 'ship', 'stadium', 'storagetank', 'tenniscourt', 'trainstation', 'vehicle', 'windmill']
abs_path = os.getcwd()
print(abs_path)
# if not os.path.exists('/DIOR'):
# os.makedirs('DIOR')
if not os.path.exists('DIOR_dataset/labels/'):
os.makedirs('DIOR_dataset/labels/')
if not os.path.exists('DIOR_dataset/labels/train'):
os.makedirs('DIOR_dataset/labels/train')
if not os.path.exists('DIOR_dataset_yolo/labels/test'):
os.makedirs('DIOR_dataset/labels/test')
if not os.path.exists('DIOR_dataset_yolo/labels/val'):
os.makedirs('DIOR_dataset/labels/val')
if not os.path.exists('DIOR_dataset/images/'):
os.makedirs('DIOR_dataset/images/')
if not os.path.exists('DIOR_dataset/images/train'):
os.makedirs('DIOR_dataset/images/train')
if not os.path.exists('DIOR_dataset/images/test'):
os.makedirs('DIOR_dataset/images/test')
if not os.path.exists('DIOR_dataset/images/val'):
os.makedirs('DIOR_dataset/images/val')
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id, path):
#输入输出文件夹,根据实际情况进行修改
in_file = open('DIOR/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('DIOR_dataset/labels/' + path + '/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
#difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
train_percent = 0.6
test_percent = 0.2
val_percent = 0.2
xmlfilepath = opt.xml_path
# txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
# if not os.path.exists(txtsavepath):
# os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
list_index = list(list_index)
random.shuffle(list_index)
train_nums = list_index[:int(num * train_percent)]
test_nums = list_index[int(num * train_percent): int(num * test_percent)+int(num * train_percent)]
val_nums = list_index[int(num * test_percent)+int(num * train_percent):]
for i in list_index:
name = total_xml[i][:-4]
if i in train_nums:
convert_annotation(name, 'train') # lables
image_origin_path = 'DIOR/JPEGImages/' + name + '.jpg'
image_target_path = 'DIOR_dataset/images/train/' + name + '.jpg'
copyfile(image_origin_path, image_target_path)
if i in test_nums:
convert_annotation(name, 'test') # lables
image_origin_path = 'DIOR/JPEGImages/' + name + '.jpg'
image_target_path = 'DIOR_dataset/images/test/' + name + '.jpg'
copyfile(image_origin_path, image_target_path)
if i in val_nums:
convert_annotation(name, 'val') # lables
image_origin_path = 'DIOR/JPEGImages/' + name + '.jpg'
image_target_path = 'DIOR_dataset/images/val/' + name + '.jpg'
copyfile(image_origin_path, image_target_path)
最终会生成yolo格式的数据集,且按训练集、验证集、测试集划分开。最终数据集形式如下 
YOLO V6训练DIOR
YOLO V6的操作文档可以看这里:https://yolov6-docs.readthedocs.io/zh-cn/latest/ 我们针对我们制作的DIOR数据集,来修改参数。
修改dataset.yaml
找到源代码中data/dataset.yaml。
# Please insure that your custom_dataset are put in same parent dir with YOLOv6_DIR
# 放入刚处理的DIOR数据集路径
train: .\DIOR_dataset\images\train # train images
val: .\DIOR_dataset\images\val # val images
test: .\DIOR_dataset\images\test # test images (optional)
# whether it is coco dataset, only coco dataset should be set to True.
is_coco: False
# Classes,类别名
nc: 20 # number of classes
names: ['airplane', 'airport', 'baseballfield', 'basketballcourt', 'bridge', 'chimney', 'dam',
'Expressway-Service-area', 'Expressway-toll-station', 'golffield', 'groundtrackfield', 'harbor',
'overpass', 'ship', 'stadium', 'storagetank', 'tenniscourt', 'trainstation', 'vehicle', 'windmill'] # class names
修改train.py
找到源代码中tools/train.py。 修改img-size为800,其他选项根据注释自行修改。
训练
运行train.py
测试
训练结束后,运行tools/eval.py。即可验证精度(注意weights改成训练结果路径),img-size为800。
输出结果
运行tools/infer.py source为test图片路径,其它参数根据注释选择性修改。 部分测试结果如下。 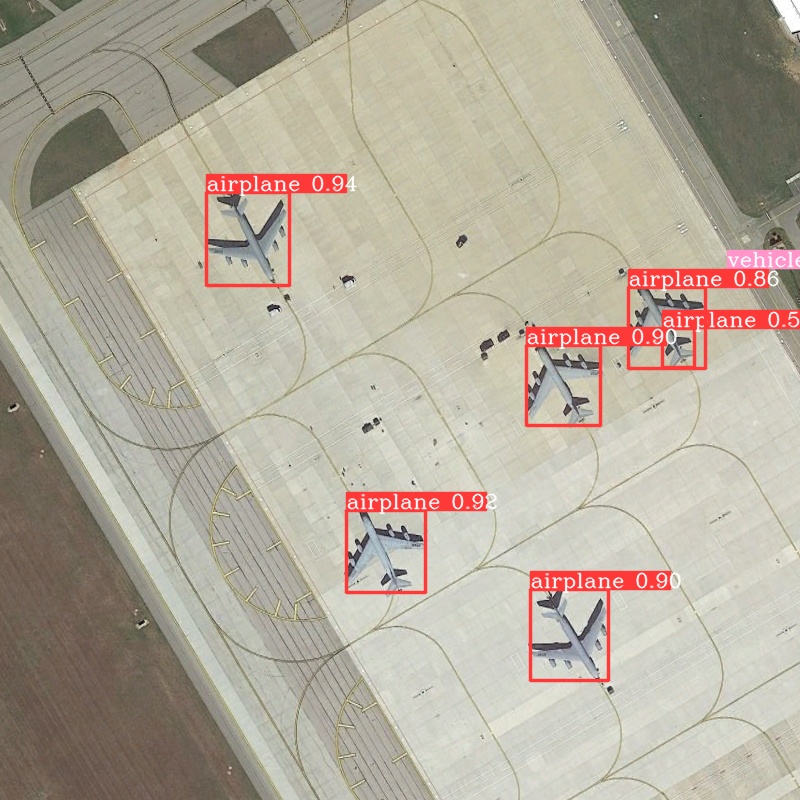
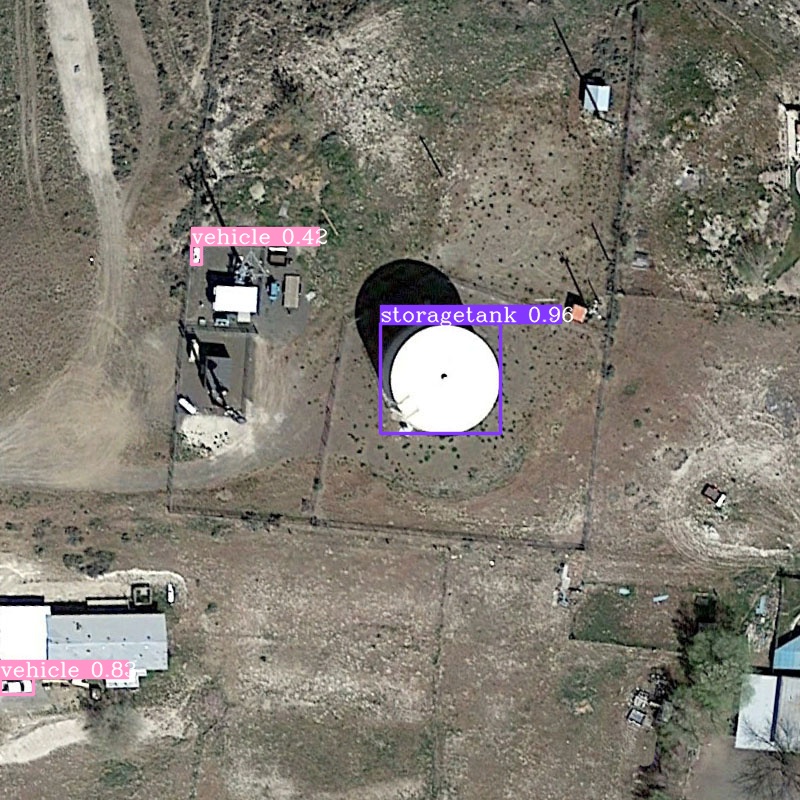

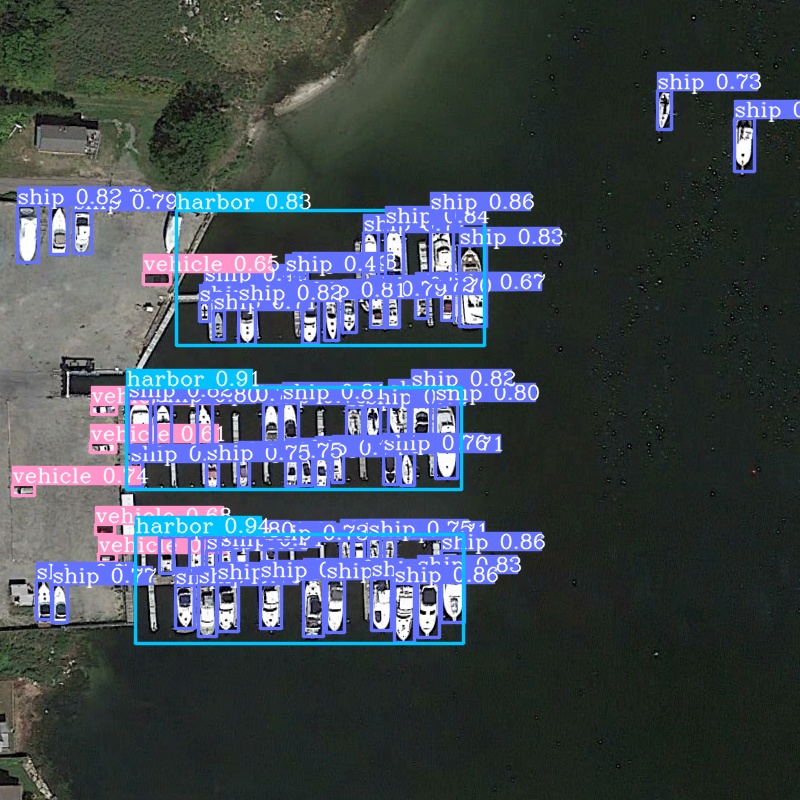
总结
今天的分享就到这里,感兴趣的可以自行下载数据集与源代码试试。
往期精彩
本文由 mdnice 多平台发布