文章目录
- 1. 写在前面
- 2. 接口分析
- 3. 代码实现
【🏠作者主页】:吴秋霖
【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python与爬虫领域研究与开发工作!
【🌟作者推荐】:对爬虫领域以及JS逆向分析感兴趣的朋友可以关注《爬虫JS逆向实战》《深耕爬虫领域》
未来作者会持续更新所用到、学到、看到的技术知识!包括但不限于:各类验证码突防、爬虫APP与JS逆向分析、RPA自动化、分布式爬虫、Python领域等相关文章
1. 写在前面
今天周末,抽时间更一下之前分析过的红薯扫码协议登录。思路反正是这么个思路,此类的应用场景很多。将登录后的CK给到爬虫采集使用,这样的一个闭环,在爬虫领域的圈子内基本很多工程师都用过。本期文章作者主要讲解分析过程与实现思路
2. 接口分析
首先打开Web端页面,会自动弹出一个二维码登录框,可以扫码并在手机点击确认登录。这里我们分析一下接口发包请求,如下所示:
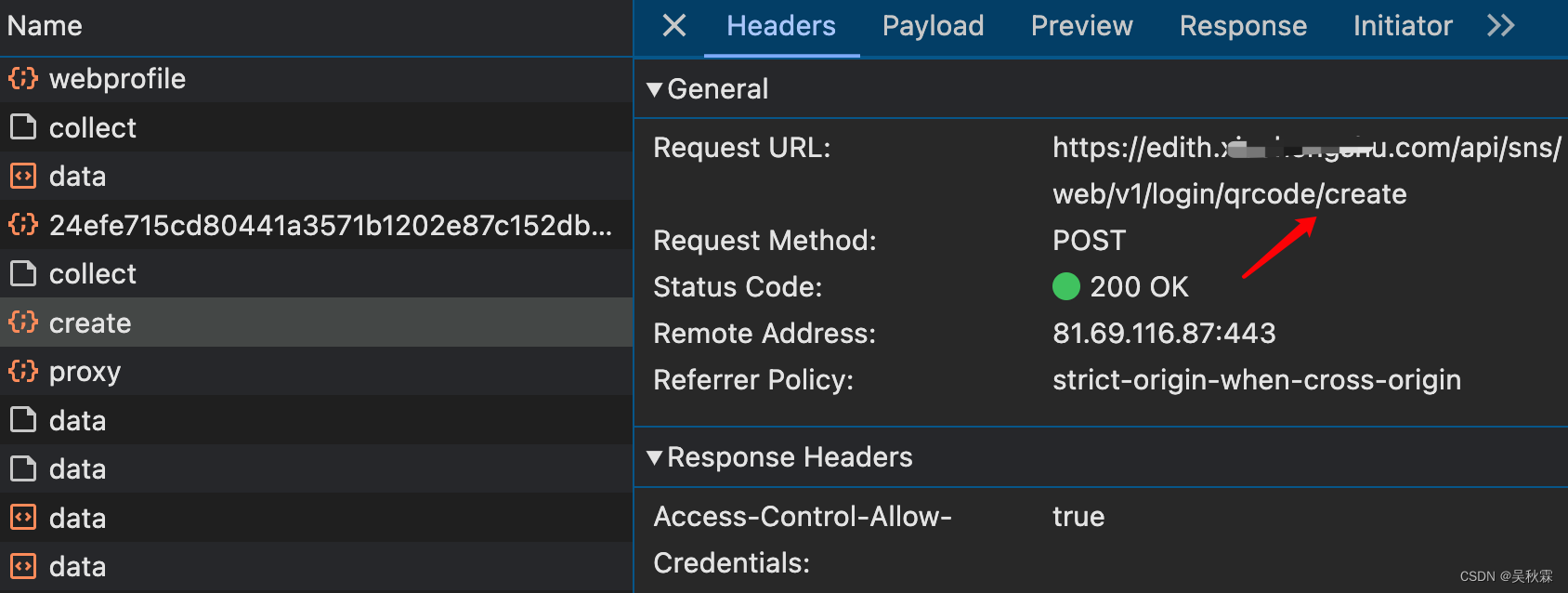
create这个即二维码生成接口,但是不同于其他网站,有固定的二维码URL,将码图片生成并存储在本地。接口也有一个登录的URL直链,码的话则是通过JS渲染生成的。当然有这个URL就够了,接口响应数据如下所示:
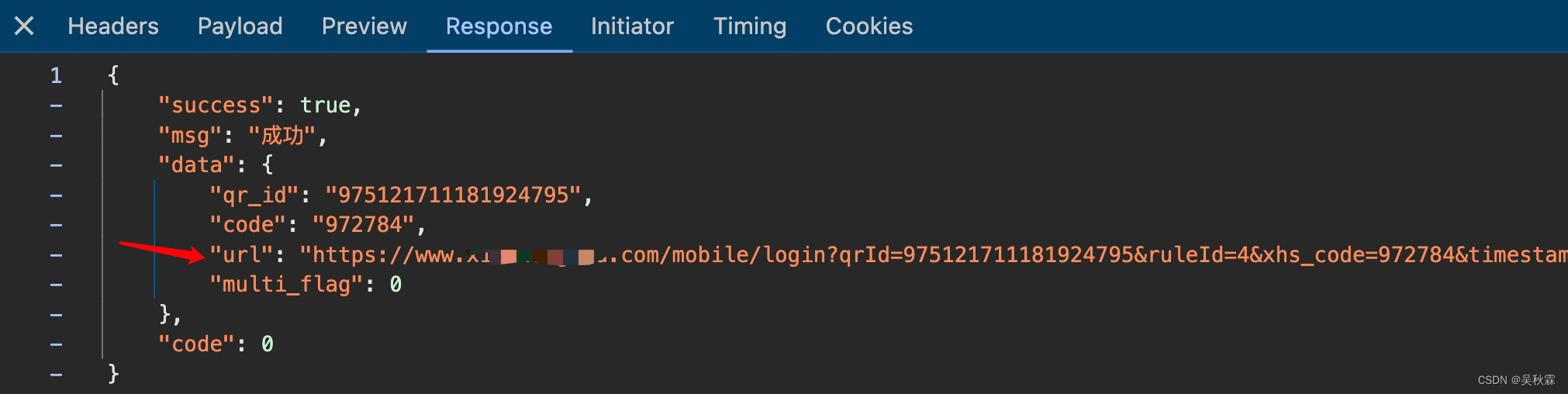
这里需要注意比较重要的三个字段,都将在后续使用上!qr_id、code你可以理解为二维码的标识,唯一且动态生成,即一码一ID!url登录链接,不是二维码链接!没有现成的二维码图或直链没有关系,我们可以使用Python生成二维码联动登录直链
一般扫码登录不知道大家有没有了解过,一张二维码创建出来后,一般是有一个服务会不断扫,扫什么?扫用户是否扫码、是否登录、码状态是否失效等等
所以这里也是一样,页面刷新生成二维码那一刻起,可以看到监测二维码状态一直在请求,直到二维码失效。这部分也是我们接下来需要构造实现的,如下所示:
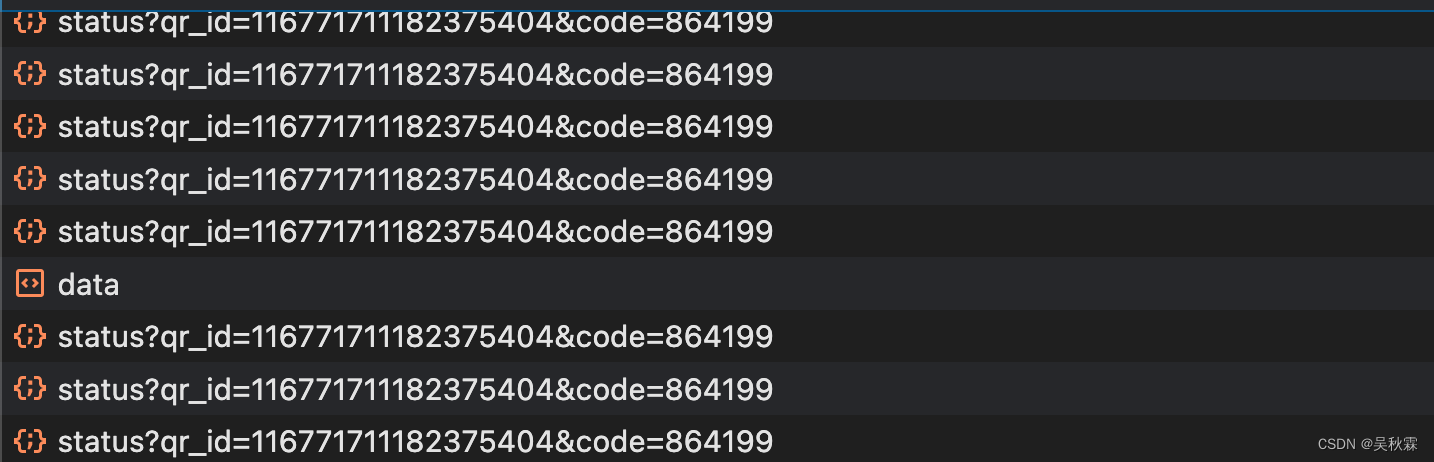
这里的码状态监测请求频率在一秒钟扫一次,注意最好也保持在这个频率去构造监测二维码状态的请求

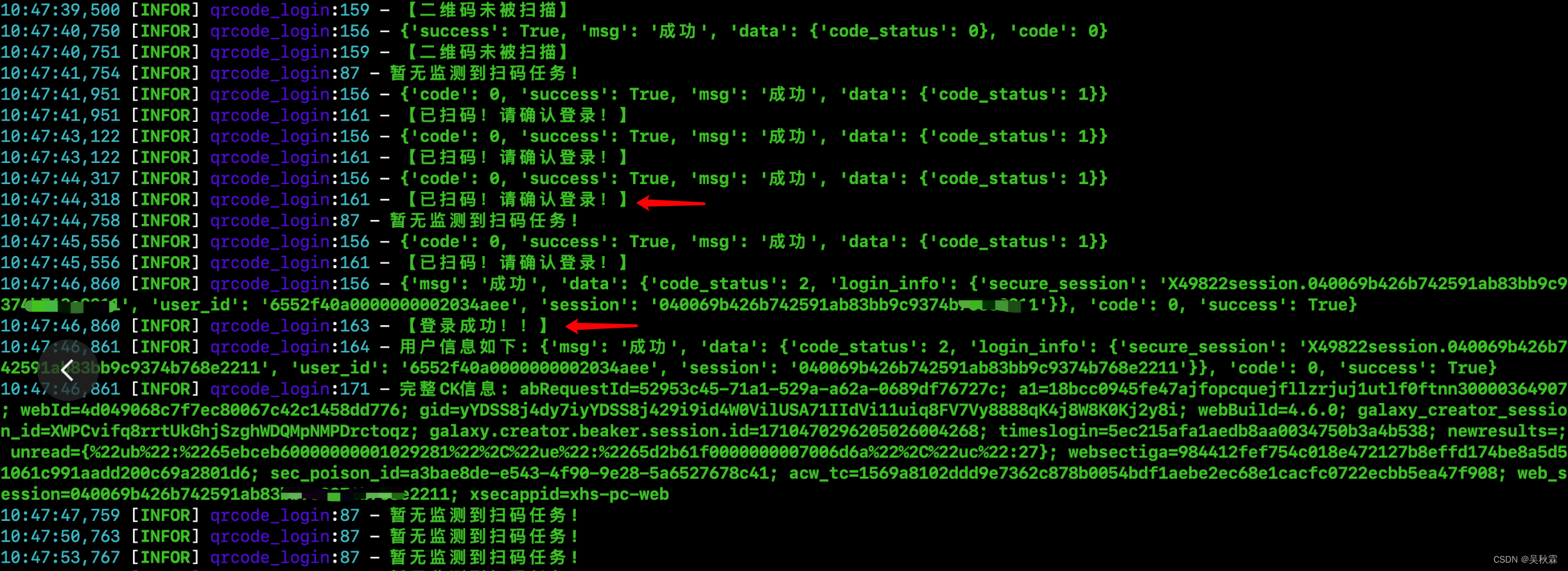
监测二维码状态的接口响应主要就是码是否被扫描了、是否确认登录了、登录是否成功了的一系列反馈。主要体现在code_status这个字段
0是二维码未被扫描、1是二维码已被扫描,但是待确认登录、2是登录成功、3则是码已经失效
3. 代码实现
流程实现主要涉及到两个接口,倒不是特别复杂。唯一需要分析与技术攻关的就是请求头内的x-s参数,这个是在生成二维码信息以及监测二维码状态请求中必须的一个参数,动态加密生成的
这个参数的话作者在很早之前就分别完成了补环境跟纯算分析还原,这里就不再复述。感兴趣的可以阅读之前的文章:x-s与x-s-common参数分析

扫码登录的话它只监测x-s,不用去管x-s-c这个参数,这个参数在请求的时候可以不携带!接下来我们先实现二维码创建,通过create接口生成二维码信息,代码实现如下:
# -*- coding: utf-8 -*-
import execjs
import qrcode
import requests
from PIL import Image
from io import BytesIO
def get_xs(url, data):
a1 = '' # 自行获取
with open("xsAndxscommon.js", encoding='utf-8') as f:
ctx = execjs.compile(f.read())
res = ctx.call(
"getXs",
url,
data,
a1)
return res
def generate_qrcode():
headers = {
# 自动获取
}
url = '' # 自动获取
api = "/api/sns/web/v1/login/qrcode/create"
data = {
"qr_type": 1
}
sign = get_signature(api, data)
headers['x-s'] = sign['x-s']
data = json.dumps(data, separators=(',', ':'))
json_data = self.session.post(url, headers=headers, data=data).json()
code = json_data.get('code', -1)
if code == 0:
data = json_data.get('data', {})
if data:
logger.log('INFOR', f'二维码生成完成!信息如下: {json_data}')
code = data.get('code', '')
qr_id = data.get('qr_id', '')
loginurl = data.get('url', '')
qr = qrcode.QRCode()
qr.add_data(loginurl)
img = qr.make_image()
a = BytesIO()
img.save(a, 'png')
png = a.getvalue()
a.close()
t = showpng(png)
t.start()
login_status_monitor(code, qr_id)
else:
logger.log('ERROR', f'二维码生成出现异常: {json_data}')
在创建生成二维码时,请求的cookie信息,是没有登录的,可以使用网站固定的即可!上面程序运行后会弹出一张二维码,等待扫描
另外可以看到代码中有一个方法login_status_monitor则是在生成码之后就需要调用的,模拟对码扫描状态的监测,这一部分的代码实现如下所示:
def login_status_monitor(code, qr_id):
while True:
cookies = {
# 自行获取
}
url = "" # 自行获取监测接口URL
params = {
"qr_id": qr_id,
"code": code
}
api = api = f'/api/sns/web/v1/login/qrcode/status?qr_id={qr_id}&code={code}'
sign = get_xs(url=api, data='')
headers.update(sign)
response = requests.get(url, headers=headers, cookies=cookies, params=params).json()
logger.info(response)
code_status = response["data"]["code_status"]
if code_status == 0:
logger.info("【二维码等待扫描】")
elif code_status == 1:
logger.info("【已扫码,请确认登录】")
elif code_status == 2:
logger.info("【登录成功】")
break
elif code_status == 3:
logger.info("【二维码已失效】")
time.sleep(1)
扫码状态的监测需要注意的点就是保持与Web站点时间频率一致,然后每一次构造请求都需要使用最新生成的x-s参数,不然是不行的
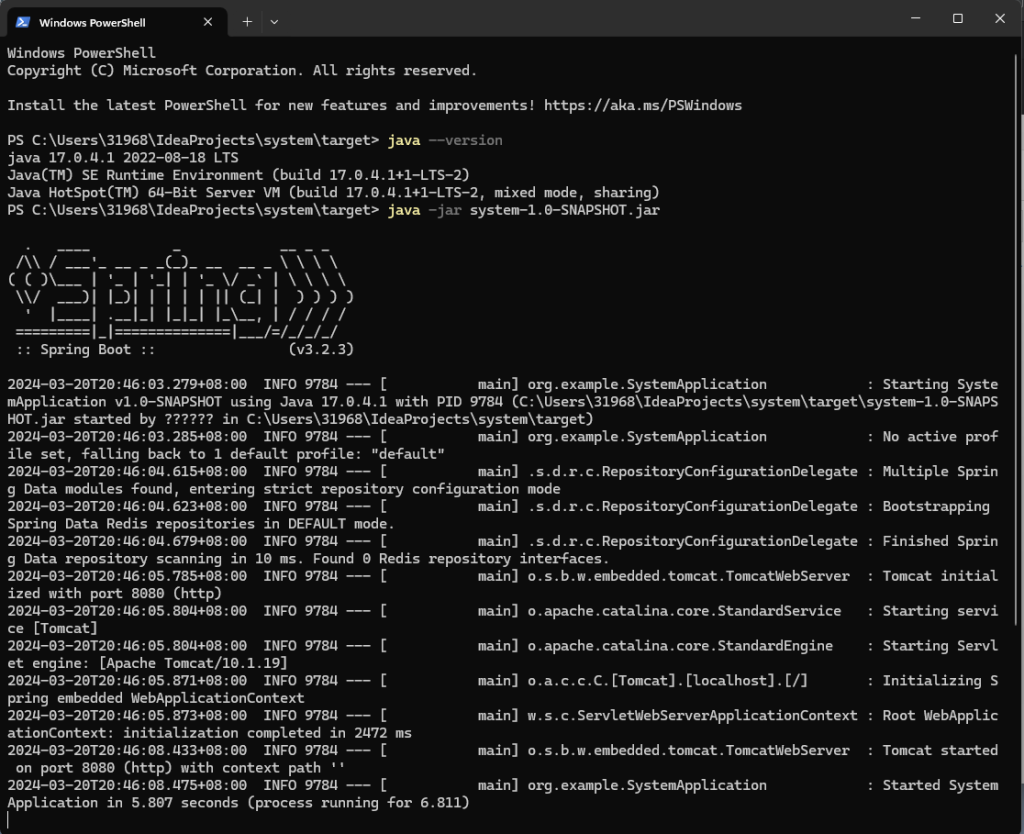
接下来,运行程序则会弹出二维码,掏出你的手机扫码并点击确认登录,即可完成!监测二维码状态的服务日志如下所示:
作者个人的的话,将它做成了一个Web服务,部署到了一台云服务上面,不管在何时何地只要作者打开手机访问就能看到二维码,如下所示:

手机浏览器刷新就会生成创建出一张新的码。作者平日里,周末的时候啥的,可能会需要获取一两篇爆款的笔记,学习研究一下别的博主是如何创作笔记的,然后就是看看最新的爆款方向啥的。所以这个扫码登录功能还对接了数据获取的爬虫服务

总之所有的一切一切,都是为了学习!使用技术手段学习自然是Buff加层。最后,今天的技术分享就到这里了,祝大家周末愉快!如果对你有帮助给个赞吧~