目录
引言
二、RNN的基本原理
代码事例
三、RNN的优化方法
1 长短期记忆网络(LSTM)
2 门控循环单元(GRU)
四、更多优化方法
1 选择合适的RNN结构
2 使用并行化技术
3 优化超参数
4 使用梯度裁剪
5 使用混合精度训练
6 利用分布式训练
7 使用预训练模型
五、RNN的应用场景
1 自然语言处理
2 语音识别
3 时间序列预测
六、RNN的未来发展
七、结论
引言
众所周知,CNN与循环神经网络(RNN)或生成对抗网络(GAN)等算法结合,可以更好地处理序列数据和生成更逼真的图像。
今天讲rnn,在人工智能和机器学习的浪潮中,循环神经网络(Recurrent Neural Network,简称RNN)以其独特的序列建模能力,成为了处理时间序列数据的重要工具。
无论是语音识别、自然语言处理,还是时间序列预测等领域,RNN都展现出了强大的应用潜力。
本文将详细解析RNN算法的基本原理、优化方法,探讨其应用场景,并展望其未来发展。
二、RNN的基本原理
RNN是一种特殊的神经网络,其结构允许信息在内部循环传递。与传统的神经网络不同,RNN在处理序列数据时,能够利用前一个时间步的输出作为下一个时间步的输入,从而捕捉序列中的时间依赖关系。这种循环结构使得RNN能够处理任意长度的序列数据,并有效地提取序列中的特征信息。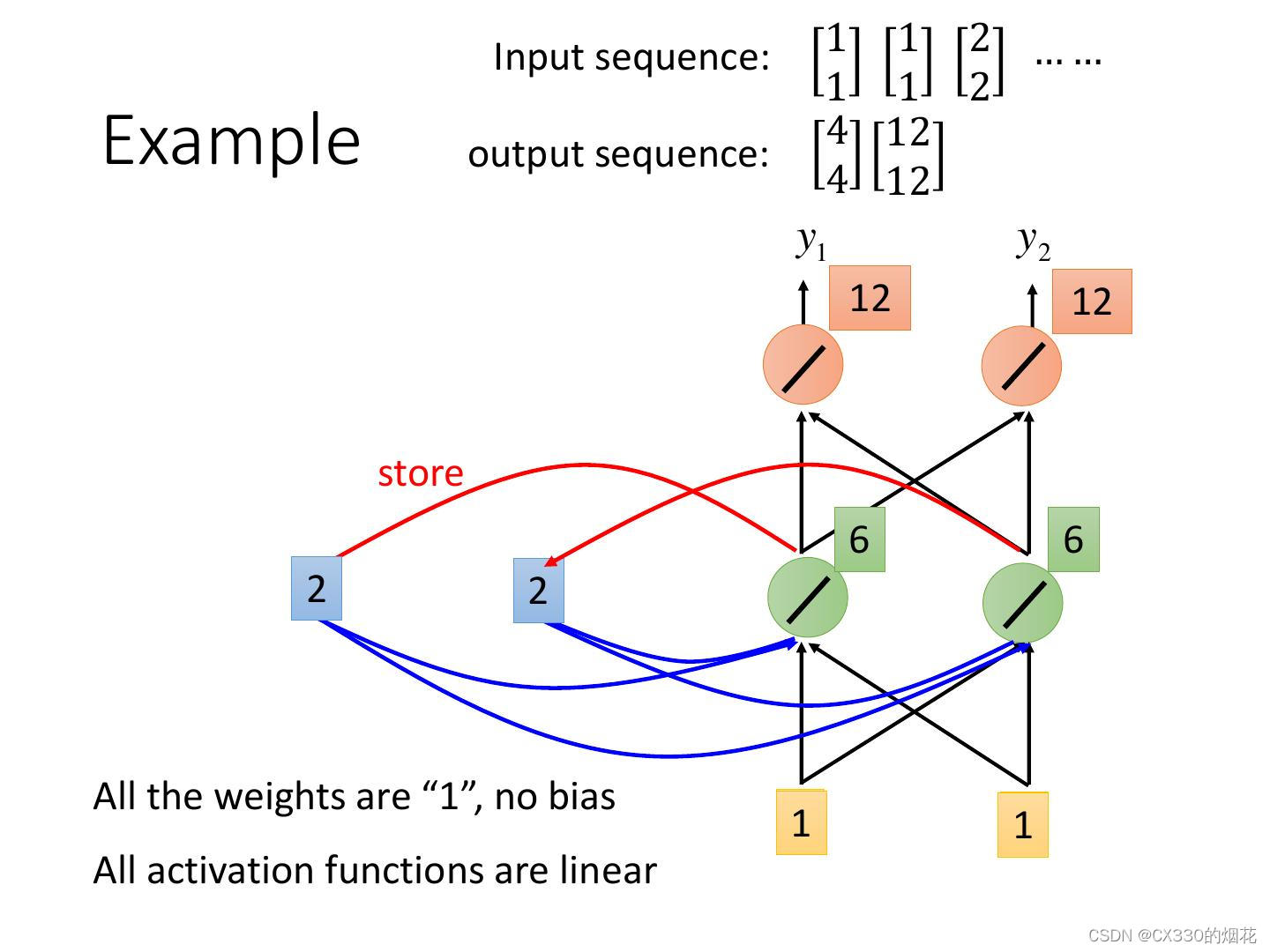
RNN的基本结构包括输入层、隐藏层和输出层。在每个时间步,输入层接收当前的输入数据,并将其与隐藏层的状态进行组合,然后传递给输出层。同时,隐藏层的状态也会被更新,并作为下一个时间步的输入。这种循环机制使得RNN能够捕捉序列中的长期依赖关系。
代码事例
这段代码定义了一个简单的RNN模型,其中包含一个RNN层和一个全连接层。在前向传播中,我们首先初始化隐藏状态h0,然后通过RNN层进行前向传播。我们取出最后一个时间步的隐藏状态,通过全连接层得到输出。最后,我们假设了一个批量的输入数据,并通过模型进行前向传播。
请注意,为了运行这段代码,你需要有一个支持PyTorch的环境,并且可能还需要一个支持CUDA的GPU(如果你的代码中有.to(device)的部分并且你想在GPU上运行)。如果你没有GPU,可以简单地移除.to(device)相关的代码,代码将在CPU上运行。
import torch
import torch.nn as nn
# 定义一个简单的RNN模型
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐藏状态
h0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device) # (num_layers * num_directions, batch, hidden_size)
# RNN的前向传播
out, _ = self.rnn(x, h0) # out: tensor of shape (batch, seq_len, hidden_size)
# 取最后一个时间步的隐藏状态作为输出
out = self.fc(out[:, -1, :])
return out
# 设定RNN模型的参数
input_size = 10 # 输入特征维度
hidden_size = 20 # 隐藏层大小
output_size = 1 # 输出维度
# 实例化RNN模型
rnn_model = SimpleRNN(input_size, hidden_size, output_size)
# 假设有一个批量的输入序列,其形状为 (batch_size, seq_len, input_size)
batch_size = 32
seq_len = 5
x = torch.randn(batch_size, seq_len, input_size)
# 将模型和数据移动到GPU(如果有的话)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
rnn_model = rnn_model.to(device)
x = x.to(device)
# 前向传播
output = rnn_model(x)
print(output.shape) # 输出形状应为 (batch_size, output_size)
三、RNN的优化方法
尽管RNN具有强大的序列建模能力,但在实际应用中,其训练过程往往面临着一些挑战。其中,梯度消失和梯度爆炸是RNN训练过程中常见的问题。为了解决这些问题,研究者们提出了多种优化方法。
1 长短期记忆网络(LSTM)
LSTM是一种特殊的RNN结构,通过引入门控机制和记忆单元,有效地缓解了梯度消失和梯度爆炸的问题。LSTM通过控制信息的流动,使得模型能够更好地捕捉序列中的长期依赖关系。
2 门控循环单元(GRU)
GRU是另一种改进的RNN结构,其结构与LSTM类似,但更加简化。GRU通过引入重置门和更新门,实现了对信息的有效筛选和传递,提高了模型的性能。
此外,为了提高RNN的训练效率和泛化能力,研究者们还采用了正则化技术(如dropout、L1/L2正则化等)和优化算法(如Adam、RMSprop等)。这些技术可以帮助RNN更好地适应不同的任务和数据集。
四、更多优化方法
1 选择合适的RNN结构
不同的RNN结构具有不同的计算复杂度和性能。例如,长短期记忆网络(LSTM)和门控循环单元(GRU)是两种广泛使用的RNN变体,它们通过引入门控机制来改善梯度消失问题,并在一定程度上提高了训练效率。因此,根据具体任务和数据特点选择合适的RNN结构是非常重要的。
2 使用并行化技术
RNN的训练过程通常是串行的,因为每个时间步的输出都依赖于前一个时间步的状态。然而,可以通过一些技术实现RNN的并行化,如使用分块处理(chunked processing)或分割序列成多个子序列。这样,可以在多个计算单元上同时处理不同的时间步,从而加速训练过程。
3 优化超参数
超参数的选择对RNN的训练效率有很大影响。例如,学习率、批次大小、正则化参数等都需要仔细调整。使用网格搜索、随机搜索或贝叶斯优化等方法可以帮助找到最佳的超参数组合。
4 使用梯度裁剪
在RNN的训练过程中,梯度可能会变得非常大或非常小,这可能导致训练不稳定或收敛速度变慢。使用梯度裁剪技术可以防止梯度爆炸,确保训练过程的稳定性。
5 使用混合精度训练
混合精度训练是一种使用不同精度的数值来表示和计算模型参数和梯度的方法。通过使用半精度浮点数(FP16)代替全精度浮点数(FP32),可以在不损失太多精度的前提下减少内存占用和计算量,从而加速训练过程。
6 利用分布式训练
分布式训练是一种利用多个计算节点来加速模型训练的方法。通过将数据集分割到多个节点上,并在这些节点上并行地进行前向传播和反向传播,可以显著减少训练时间。
7 使用预训练模型
在某些情况下,可以使用预训练的RNN模型作为起点,而不是从头开始训练。预训练模型已经在大量数据上进行了训练,并具有一定的泛化能力。通过微调这些模型以适应特定任务,可以加快训练速度并提高性能
五、RNN的应用场景
RNN在多个领域都有着广泛的应用,下面我们将详细探讨其中几个典型的应用场景。
1 自然语言处理
在自然语言处理领域,RNN被广泛应用于文本分类、情感分析、机器翻译等任务。通过捕捉句子或段落中的上下文信息,RNN能够更准确地理解文本的含义和意图,从而提高模型的性能。
2 语音识别
在语音识别领域,RNN也发挥着重要作用。通过将语音信号转换为特征序列,RNN可以捕捉语音中的时序依赖关系,实现高精度的语音识别。此外,RNN还可以与其他技术(如声学模型、语言模型等)结合,进一步提高语音识别的性能。
3 时间序列预测
时间序列预测是RNN的另一个重要应用场景。在金融、交通、气象等领域,时间序列数据普遍存在。通过利用RNN捕捉时间序列中的长期依赖关系,我们可以预测未来一段时间内的变化趋势,为决策提供有力支持。
六、RNN的未来发展
随着深度学习技术的不断进步和应用场景的拓展,RNN在未来将有更广阔的发展前景。一方面,研究者们将继续探索更加高效、稳定的RNN结构,以提高模型的性能和鲁棒性;另一方面,RNN将与其他深度学习技术(如卷积神经网络、注意力机制等)进行深度融合,形成更加强大的序列建模能力。此外,随着计算资源的不断提升和算法的不断优化,RNN在处理大规模序列数据时将更加高效和准确。
七、结论
通过对RNN算法的深入解析和探讨,我们可以看到其在序列建模中的强大能力和广泛应用前景。未来,随着技术的不断进步和应用场景的拓展,RNN将在更多领域展现出其独特的价值。我们期待RNN在人工智能和机器学习领域发挥更大的作用,为人类社会的发展做出更多贡献。