文章总结
动机
通过各种图像增强手段和冻结特征(已经训练好的特征)结合起来训练轻量级模型。
最终得到的最佳设置顺序
亮度,对比度FroFA (C)和后置cFroFA (Pc) 这三种连续的数据增强操作(具体这三种数据增强操作是干了什么,得去附录找)
这里三种FroFA介绍
(默认)FroFA
这里,
![]()
图像到特征的映射
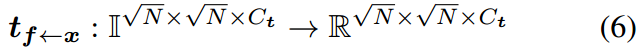
数据增强变化
![]()
特征到图像的映射
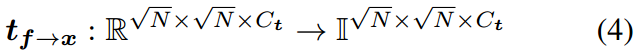
通道FroFA (cFroFA)
对其通道采用随机增强
通道平方FroFA
在通道FroFA上再进行
![]()
也对每个通道(
),即
进行操作
摘要
在在预训练的视觉模型输出(即所谓的“冻结特征”)之上训练线性分类器或轻量级模型,可以在许多下游小样本任务上获得令人印象深刻的性能。 目前,冻结特征在训练期间不会被修改。 另一方面,当直接在图像上训练网络时,数据增强是一种标准方法,可以在没有大量开销的情况下提高性能。 在本文中,我们对小样本图像分类进行了广泛的试点研究,探索在冻结特征空间中应用数据增强,称为“冻结特征增强(FroFA)”,总共涵盖了二十种增强。 我们的研究表明,采用看似简单的逐点 FroFA(例如亮度)可以在三个网络架构、三个大型预训练数据集和八个迁移数据集上一致地提高少样本学习的性能。
1. 介绍
视觉转换器(Vision transformer, vit)[19]在imagenet大小的[43,67]和更小的[21,38,41]数据集上取得了显著的性能。在这种设置中,数据增强,即一组预定义的随机输入转换,是一个关键因素。图像增强的例子是随机裁剪或像素修改,改变亮度或对比度。这些是更高级的策略的补充[13,46,73],如AutoAugment[12]。
一个更普遍的趋势是首先在大规模数据集上预训练视觉模型,然后在下游进行调整[6,8,49,71]。值得注意的是,即使在ViT输出(也称为冻结特征)之上训练一个简单的线性分类器或轻量级模型,也可以在许多不同的下游少镜头任务中产生显着的性能[16,25,52]。鉴于图像增强和冻结特征的成功,我们问:我们能否有效地将图像增强和冻结特征结合起来训练轻量级模型?
在本文中,我们重新审视了标准的图像增强技术,并将它们应用于数据受限的、少样本设置中的冻结特征。我们将这种类型的增强称为冻结特征增强(FroFA)。受到图像增强的启发,我们首先随机变换冻结的特征,然后在上面训练轻量级模型。在冻结特征上应用图像增强之前,我们唯一的修改是逐点缩放,使每个特征值位于[0,1]或[0,255]。
我们使用JFT-3B[71]、ImageNet21k[17]或WebLI[6]上预训练的ViTs研究了8个(少量样本)图像分类数据集。在从每个少镜头数据集中提取特征后,我们应用20种不同的冻结特征增强,并在此基础上训练轻量级的多头注意力池(MAP)[37]。我们的主要见解是:
1. 改变二维冻结特征形状和结构的几何增强总是导致ILSVRC-2012上的性能变差[57]。另一方面,简单的风格(逐点)增强,如亮度、对比度和隔色,可以在1、5和10 shot的设置上得到稳定的改善。
2. 通过采样每个冻结特征通道的独立值来增加每个通道的随机性效果出奇地好:在ILSVRC-2012 5-shot上,我们比MAP基线提高了1.6%的绝对值,比调优的线性baseline提高了0.8%的绝对值。
3. 虽然FroFA在ILSVRC-2012上提供了适度但显著的收益,但它在7个较小的少样本数据集上表现出色。特别是,FroFA比MAP基线的平均10次-shot精度高出2.6%,比线性探针基线高出5.2%。图1,左)。
4. 使用WebLI sigmoid型语言-图像预训练模型对相同的七个少样本数据集的结果[72]进一步强调了FroFA的传输能力。我们观察到,与MAP基线相比,1-shot的绝对增益为5.4%,25-shot的绝对增益为0.9%,而1-shot的绝对增益超过2%,5-shot至25-shot的绝对增益至少为3%。(cf。图1,右)。
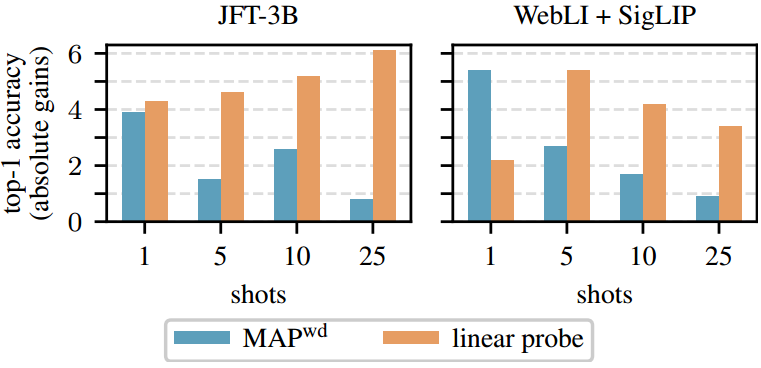
图1所示。在不同的少样本设置下,七个少样本测试集(CIFAR100 [1], SUN397[69],…)的平均前1精度增益。我们使用JFT-3B预训练[71]或WebLI s型语言图像预训练(SigLIP)[6,72]对L/16 ViT[19]中的冻结特征进行训练。我们提出的冻结特征增强(FroFA)方法在没有FroFA的情况下,与权重衰减正则化多头注意力池[37](MAPwd)和l2正则化线性探测基线相比,具有一致的增益。
2. 相关的工作
少样本迁移学习
最先进的视觉模型[6,16,19,32,55,71]通常在大规模数据集上进行预训练,例如ImageNet-21k[17]或JFT[27,71],然后再转移到其他较小规模的数据集,例如CIFAR10 [1], SUN397[68, 69]或ILSVRC-2012[57]。根据模型的大小,有效的迁移学习成为一个挑战。对于大型语言模型(llm),已经提出了许多方法,例如,适配器[28],低秩自适应[29],或提示调优[39],其中一些已经成功地适应于计算机视觉[5,22,30,74]。CLIP-Adapter[22]建立在对比语言图像预训练[52]的基础上,并将其与适配器[28]相结合。后续研究[74]提出了使用查询键缓存模型[24,51]代替梯度下降方法的TiP-Adapter。受llm提示调优成功的启发[39],Jia等人提出了在模型输入处进行视觉提示调优[30]。另一方面,AdaptFormer[5]使用额外的中间可训练层来微调冻结视觉变压器[19]。
相反,我们没有引入额外的提示[30]或需要通过网络反向传播的中间参数[5,22]。相反,我们在ViT的固定特征上训练一个小网络。这与线性探测[52]相一致,线性探测通常用于将视觉模型转移到其他任务[16,25,71],这是我们的目标。
此外,我们关注的是少样本迁移学习[36,66],而不是基于元学习或度量的少样本学习[2,9,48,50,54,56,59]。Kolesnikov等人[32]和Dehghani等人[16]表明,在大规模预训练骨干的冻结特征上训练的轻量级模型可以在大量下游(少量)任务中获得高性能。迁移学习也显示出与元学习方法竞争或略优于元学习方法[20]。在这些工作的基础上,我们提出了冻结特征增强来改进少镜头迁移学习。
数据增强
在低数据状态下训练时提高性能的一种常用方法是数据增强[60]。在计算机视觉领域,一些突出的候选者是AutoAugment[12]、AugMix[26]、RandAugment[12]和TrivialAugment[46]。这些方法通常将低级图像增强组合在一起以增强输入。已有关于特征空间增强的研究[18,35,40,44,65],但缺乏对单模态视觉模型冻结特征的大规模实证研究。
为此,我们通过重新制定20个图像增强来研究冻结特征增强,包括AutoAugment[12]、inception crop[62]、mixup[65,73]和patch dropout[42]中使用的子集。
3. 框架概述
我们在3.1节介绍了我们的符号,然后在3.2节介绍了我们的缓存和训练管道,在3.3节介绍了冻结特征增强(FroFAs)。
3.1. 符号
设为RGB图像,高H,宽W,
。分类模型处理x,并输出预定义的类集合S中每个类的分类分数
,其中
。设L为多层分类模型的中间层数,D为多层分类模型的特征数。我们将x的中间特征表示描述为
,层索引
,特征索引
。在视觉变压器[19]中,
通常是二维的,其中
分别是patch的个数和每patch通道的个数。最后,我们引入patch索引
,每patch通道索引
。
3.2. 缓存冻结特征的训练
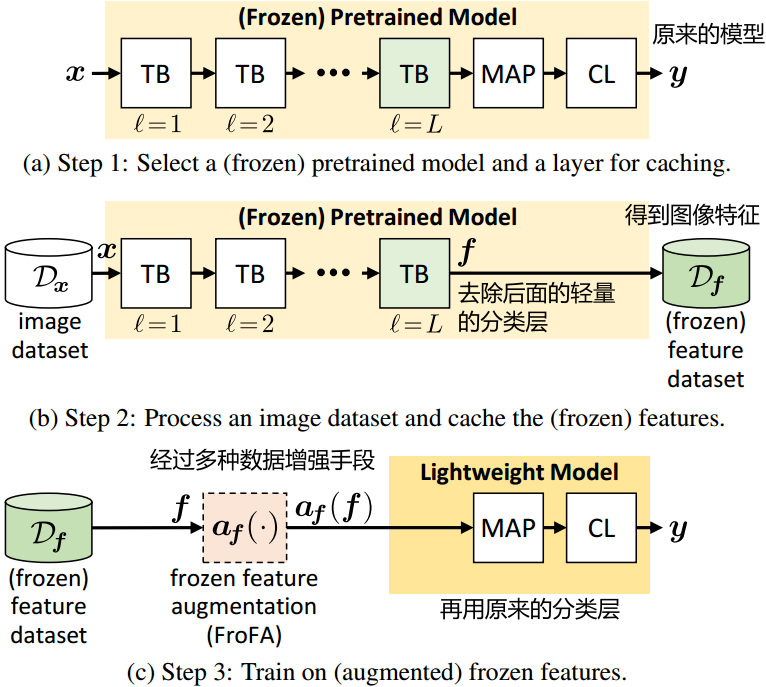
我们研究了带有L个变压器块(TBs)的预训练视觉变压器,然后是多头注意池(MAP)[37]和分类层(CL)。图2a给出了一个简化的说明。为了简单起见,我们忽略了第一个转换块之前的所有操作(例如,修补,位置嵌入等)。
为了缓存中间特征,我们通过网络处理图像数据集中的每张图像
,直到变压器块
。接下来,我们存储结果特征
。在处理整个图像数据集
后,我们获得(冻结的)特征数据集
,其中
(图2b)。
最后,我们使用缓存(冻结)的特征训练一个轻量级模型。图2c显示了一个使用特征数据集训练单个MAP层和分类层的示例。由于我们的重点是快速训练,我们将对更大模型的详细分析推迟到未来的工作中。
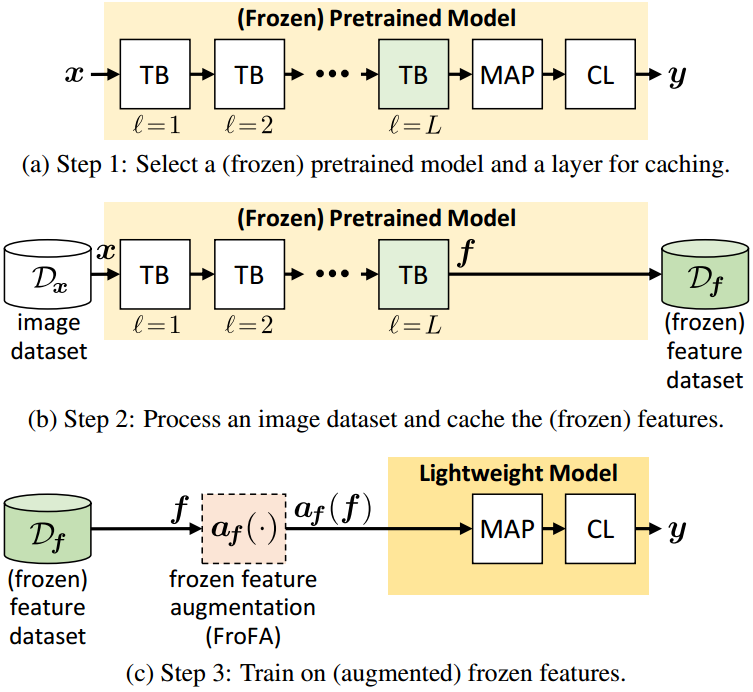
图2。用于缓存和训练(冻结)特性的管道。
(2a):给定一个(冻结的)预训练视觉transformer,有L个transformer块(TBs)、一个多头注意力池(MAP)层和一个分类层(CL),我们选择它的第L个transformer块进行缓存。
(2b):接下来,我们输入图像来缓存(冻结)特征
。
(2c):最后,我们使用在上面训练一个轻量级模型。在这种情况下,我们研究冻结特征增强(FroFA)
。
3.3. 冻结特征增强(FroFA)
数据增强是改进泛化的常用工具。然而,它通常应用于输入,或者在我们的例子中:图像。我们如何将这样的图像增强映射到中间转换特征表示?
回想一下,特征表示(层索引
省略了)是二维的。我们首先将其重塑为三维表示,即,
![]()
我们进一步定义
![]()
作为c-th通道的重塑二维表示。由于图像和特征在两个基本方面有所不同,即通道维度和值范围,我们接下来将讨论这个问题。
通道维度
RGB图像只有三个通道,而特征可以拥有任意数量的通道。为了解决这个问题,我们简单地忽略了依赖于三个颜色通道的图像增强,比如颜色抖动,而只包括可以有任意数量通道的增强,记为。这已经涵盖了大多数常用的图像增强。
值范围
RGB值在一个特定的范围内,例如
或
,而理论上特征没有这样的限制。假设
,我们定义图像增强为
![]()
其中是图像增广的集合。为了解决值范围不匹配的问题,我们引入了确定性特征到图像的映射
![]()
它将f *(1)的每个元素从映射到
,以
作为f *的通道数。我们使用

其中分别是f *的最小值和最大值,此时
的元素在
中。
我们进一步定义了图像到特征的映射
![]()
这将映射回原始特征值范围。在这种情况下,我们取(4)的倒数并使用
![]()
结合(3)、(4)和(6),我们得到了一个通用的(冻结的)特征增强作为函数组合
![]()
我们现在定义了的三种变体:
1. (默认)FroFA:我们在整个特性上应用一次。我们设
,并计算
的所有元素在(5),(7)中的
。此外,与通常在像素空间中所做的一样,
对随机增广值进行采样,并使用相同的值更改
的所有元素。例如,以FroFA方式使用随机对比将
的每个元素按完全相同的随机抽样因子进行缩放。
2. 通道FroFA (cFroFA):对于映射特征中的每个通道,
对每个通道采样一个随机增强值,并将该值应用于该通道中的所有元素(
)。通过使用cFroFA进行随机对比示例,我们获得C个独立采样的缩放因子,每个通道一个。
3.通道平方FroFA:除了在cFroFA中对每个通道(
)应用增强之外,
也对每个通道(
),即
进行操作。在这种情况下,
分别为每个通道的最大值和最小值。相比之下,FroFA和cFroFA在整个特性中使用最大值和最小值。我们将此变体表示为,因为映射(4)、(6)和增广(3)都是基于每个通道应用的。虽然没有增加额外的随机性,但我们发现,对于随机亮度,这种变体在一系列增强超参数范围内给出了更稳定的结果。
4. 实验设置
在本节中,我们将描述我们的实验设置。
4.1. 网络体系结构
我们使用预训练的Ti/16[63]、B/16[19]和L/16[19]视觉变压器。此外,我们效仿Zhai等人[71],在最终分类层之前,在冻结特征上进行训练,采用了轻量级的多头部注意力池(MAP)[37]。3.3秒。)。
4.2. 数据集
预训练
我们考虑三个预训练数据集,即JFT-3B[71]、ImageNet-21k[17]和WebLI[6]。JFT首先由Hinton等人[27]引入,现在是一种广泛使用的专有大规模数据集[6,10,14,19,32,33,61]。我们使用JFT-3B[71],它由29,593个标签的类层次结构下的近30亿个多标签图像组成。使用半自动流水线对图像进行带噪声标签的标注。我们遵循通常的做法[16,71],忽略了标签的分层方面。
ImageNet-21k包含14,197,122(多)标签图像,其中包含21,841个不同的标签。我们将前51,200张图像平分为验证和测试集,并使用剩余的14,145,922张图像进行训练。
最后,webi是一个用于视觉语言训练的网络规模的多语言图像-文本数据集。它包含109种语言的文本、100亿张图片和大约310亿张图片-文本对。
少样本迁移学习
我们研究了8个用于少射迁移学习的数据集,即ILSVRC-2012[57]、CIFAR10[1]、CIFAR100[1]、DMLab[3,70]、DTD[11]、Resisc45[7]、SUN397[68, 69]和SVHN[47]。
4.5. 基本模型
我们建立了两个基线:MAP和Linear probe。
MAP:我们首先缓存最后一个变压器块中的N个×C-shaped冻结特征。然后,我们训练一个轻量级MAP头(参见。图2)根据4.4节的训练方案从头开始。每当我们包含权重衰减扫描时,我们都会添加一个“wd”上标,即MAPwd。为简单起见,MAP头采用与底层预训练模型相同的体系结构设计。
Linear probe:我们使用预训练MAP头部缓存的1 × c形冻结特征来解决具有封闭形式解的l2正则化回归问题[71]。我们使用2的指数从- 20到10来扫描L2衰减因子。这个设置是我们的辅助基线。
5. 寻找最优的FroFA设置
我们首先将研究重点放在JFT-3B上预训练的L/16 ViT上,即我们最大的模型和最大的纯图像分类预训练数据集,然后在ILSVRC-2012训练集的子集上进行少量迁移学习,即我们最大的少量迁移数据集。我们将此设置称为JFT-3B L/16基本设置。、
5.1. 基本模型性能
我们首先在表1中报告基准性能。我们观察到MAP和线性探针在1次-shot时(- 8.6%绝对值)之间的差距很大,而在5-shot,10-shot和25-shot设置时,MAP和线性探针之间的差距分别显著减小至- 0.8%,- 0.6%和+0.8%绝对值。
在下面,我们的主要比较点是MAP基线。这可能是违反直觉的,因为在大多数情况下,性能比线性探测更差。然而,在基于map的设置中,更高的输入维度(参见。第4.5节)为我们提供了输入重塑的选项(参见第3.3节),这为冻结特征增强(frofa)开辟了更多的空间和多样性。稍后在第6.3节中,我们将我们最好的FroFA与线性探头的性能进行比较。
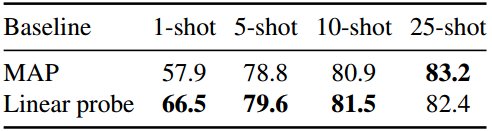
表1。ILSVRC-2012测试集的基线平均前1精度。我们使用JFT-3B L/16基础设置(参见。第5节),并遵循各自的基线设置(参见。4.5秒。)。每个镜头采样五次。每张照片的最佳效果是加粗的。
5.2. Default FroFA
现在我们研究将单个FroFA添加到MAP基线的效果,并从默认FroFA公式开始。回想一下,我们每个输入只使用一个随机采样值(参见附录3.3。)。在表2中,我们报告了18个不同frofa的MAP基线之外的收益,这些frofa分为几何、裁剪和下降、风格和其他。在附录第S3.7节中,我们报告了另外两个frofa。
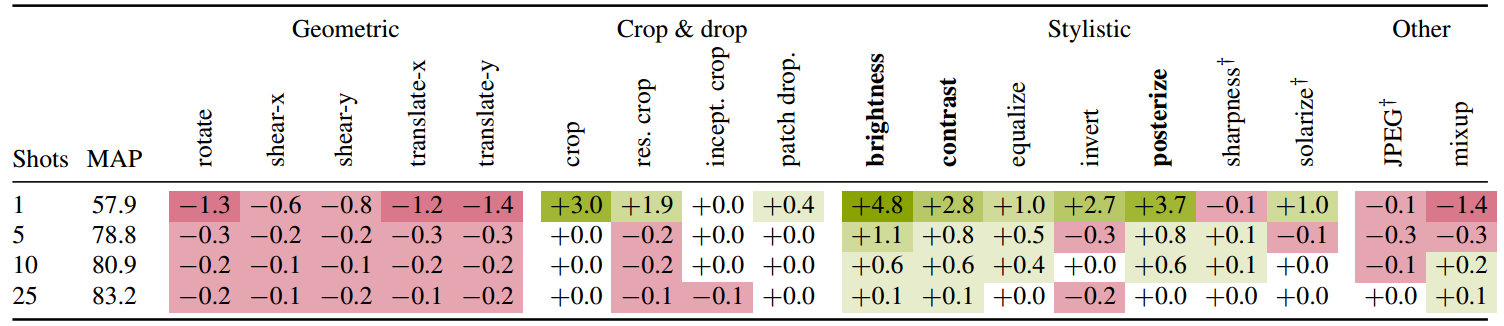
表2。在我们的ILSVRC-2012测试集上,默认FroFA的(平均)前1精度。报告了MAP基线的绝对增益。
我们使用JFT-3B L/16基础设置(参见。总共,我们调查了18个frofa,分类为几何,作物和下降,风格和其他。我们用红色表示恶化,用绿色表示改善。每个镜头采样五次,除了用“†”标记的增强。最好的三个froa是黑体字。
几何增强
有趣的是,所有几何增强都会导致所有设置下的性能变差
裁剪和裁剪
使用简单的裁剪或调整大小和裁剪的组合,在1-shot设置下,性能提升显著,分别为3.0%和1.9%。
另一方面,patch drop在1-shot中提供了适度的收益。掉落补丁与训练效率直接相关,因此我们对此进行了进一步的研究。图3a显示了1-和25-shot的前1精度与patch数量的关系。其他-shot的结果相似(参见。补充,第S3.1节)。
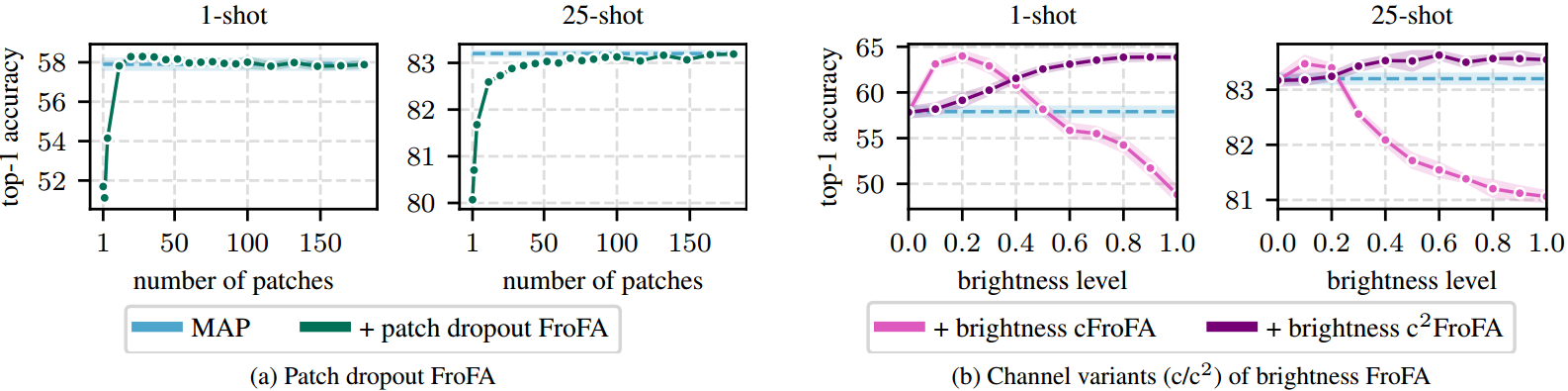
图3。在我们的ILSVRC-2012测试集上,FroFA变体的平均前1精度。我们使用JFT-3B L/16基础设置(参见。第5节)。我们扫描一个基本扫描(参见。第4.4节)首先在我们的ILSVRC-2012验证集上为每个FroFA操作点找到最佳设置(参见。补充,第S2.2节)。阴影区域表示通过采样每个镜头五次收集的标准误差。
各种风格
当使用各种风格时,可以观察到最大的收益,特别是亮度,对比度和隔色。我们将亮度确定为表现最好的FroFA, 1次拍摄时绝对增益4.8%,5次拍摄时绝对增益1.1%,10-shot时绝对增益高达0.6%。
其他
JPEG和mixup都不能提高性能,但或多或少会使性能变差。
5.3. Channel FroFA
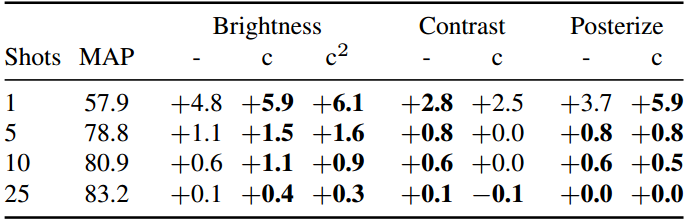
表3。在我们的ILSVRC-2012测试集中,选择默认(-)和通道(c/c2) FroFA的平均前1精度。报告了MAP基线的绝对增益。我们使用JFT-3B L/16基础设置(参见。每个镜头被采样五次。每次拍摄和FroFA的最佳结果以黑体字表示(如果接近,则为多个,即±0.2)。
我们继续使用通道FroFA (cFroFA)使用三种风格增强:亮度,对比度和隔色。在表3中,我们报告了相对于MAP基线的绝对增益,并结合了信道(c)和非信道(-)变体。首先,对比cFroFA并没有改善其在所有镜头的非通道变体。其次,posterize cFroFA将1-shot的表现从3.7%提高到5.9%,同时保持所有其他shot的表现。最后,亮度cFroFA显着提高了所有的性能,shots: 4.8% → 5.9% on 1-shot, 1.1% → 1.5% on 5-shot,0.6% → 1.1% on 10-shot, and 0.1% → 0.4% on 25-shot.
考虑到亮度cFroFA的强大改进,我们进一步测试了亮度(表3中的
)。乍一看,
变体的性能与cFroFA变体相当。在图3b中,我们报告了1和25-shot的前1精度作为亮度水平的函数。其他镜头的结果相似,可以在补充部分S3.1中找到。现在我们清楚地观察到,亮度cFroFA对亮度水平比亮度
。一般来说,亮度cFroFA仅适用于小亮度水平(0.1至0.5),而其
对应值的性能优于MAP基线。我们将亮度
更好的灵敏度属性归因于
上的通道映射(5),(7),因为这是与cFroFA相比的唯一变化。当从cFroFA切换到
时,我们没有观察到类似的效果。
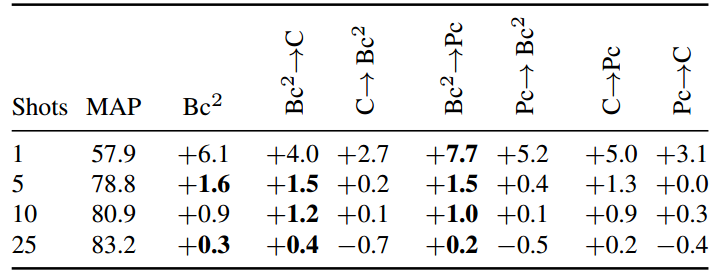
5.4. Sequential FroFA
最后,在我们最好的三种增强中,即亮度,对比度FroFA (c)和后置cFroFA (Pc),我们依次组合其中的两个(→),产生六种组合。在表4中,我们将所有六种组合与我们的先验最佳
进行比较。在单杆上,
的表现明显优于“
”,将绝对收益从6.1%提高到7.7%,同时在其他射击上保持表现。我们得出结论,先进的FroFA协议可以进一步提高性能。作为初步调查,我们使用我们最好的三个frofa应用了RandAugment和TrivialAugment的变体。表3),然而,成功有限。我们将结果纳入附录第S3.2节,并将更深入的调查留给未来的工作。
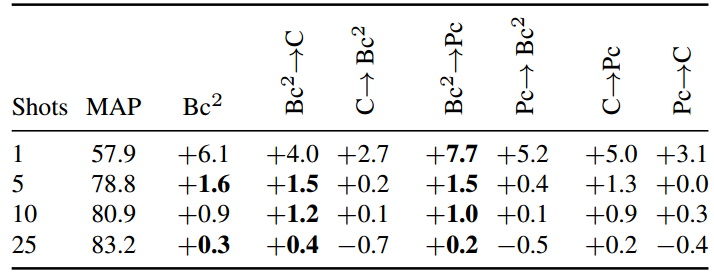
表4。在我们的ILSVRC-2012测试集上,顺序FroFA协议的平均前1精度。报告了MAP基线的绝对增益。我们使用JFT-3B L/16基础设置(参见附录5)。我们将亮度,对比度FroFA (C)和后置cFroFA (Pc)的最佳设置顺序组合在一起(一次两个,顺序由“↑”表示)。每个镜头采样五次。每次拍摄的最佳结果是黑体字(如果接近,则为多个,即±0.2)。
8. 结论
我们沿着模型大小、预训练和转移少样本数据集三个方向研究了20种冻结特征增强(FroFAs)用于少样本迁移学习。我们表明,与FroFA的训练,特别是风格的,在所有镜头的代表性基线上有很大的改进。此外,每个通道的变体进一步提高了性能,例如,在ILSVRC-2012 5-shot设置中,绝对上提高了1.6%。最后,我们证明了FroFA在较小的少样本数据集上表现出色。例如,七个少样本任务的平均结果表明,在JFT-3B L/16视觉转换器的缓存冻结特征上进行训练,每个通道的亮度FroFA变体在1到25个镜头设置的线性探头上获得至少4.0%的绝对增益。
参考资料
文章下载(2024 CVPR)
https://arxiv.org/abs/2403.10519

主页
Frozen Feature Augmentation