可参考:
pandas:http://pandas.pydata.org/docs/user_guide/10min.html
一、基础知识
DataFrame 方法,可以将一组数据(ndarray、series, map, list, dict 等类型)转化为表格型数据
import pandas as pd
data = {'name': ['xx', 'zz', 'hh', 'aa'],
'year': [2000, 2001, 2002, 2003],
'age': [15, 16, 17, 18]}
df = pd.DataFrame(data)
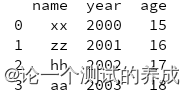
输出全部数据
print(df)

获取某一列数据
print(df['A'])

输出部分数据(切片)
print(df[2:3])
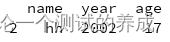
条件筛选数据
输出满足条件的所有数据
print(df[df['age']>15])

比较数据数据是否满足条件
print(df['age']>15)

行和列结合筛选
print(df[2:3][['name']])

删除指定行
df = df.drop(0)
print(df)

head 默认输出前5列,head方法里传入几个参数,输出几行
print(df.head())
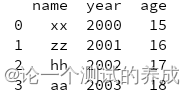
tail 默认输出最后5行
print(df,tail())
import pandas as pd
import numpy as np
#(1)生成日期 给定一个日期 生产一组递增日期数据
data = pd.date_range('20240318',periods=6)
#生成一组6行4列的表格数据,表头为ABCD
df = pd.DataFrame(np.random.randn(6,4),index=data,columns=list('ABCD'))
生成日期 给定一个日期 生产一组递增日期数据
print(data)

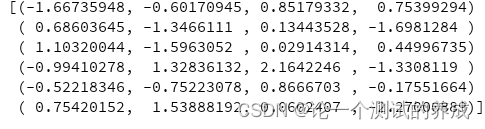
转置(行变成列,列变成行)
print(df.transpose())

数据转化为numpy数据
index=False 表示不要index
print(df.to_records(index=False))
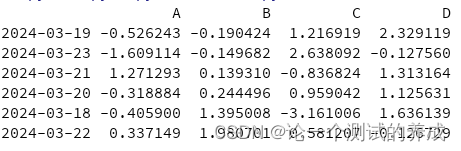
排序sort_values 默认升序
print(df.sort_values(by='B'))
按照索引获取数据
二、数据处理(分组)
(1) 对某一列元素进行分组求和处理
import pandas as pd
import numpy as np
data = {'X':['B','B','A','A'],'Y':[1,2,3,4]}
df = pd.DataFrame(data)
df = df.groupby(ele,sort=False).sum()
print(df)

(2)分组后得到某组的值
df = df.groupby(ele,sort=False).get_group('A')
print(df)






![Linux基础命令[20]-useradd](https://img-blog.csdnimg.cn/direct/390812f6efe04b4e8858587c8ddf53d4.png)