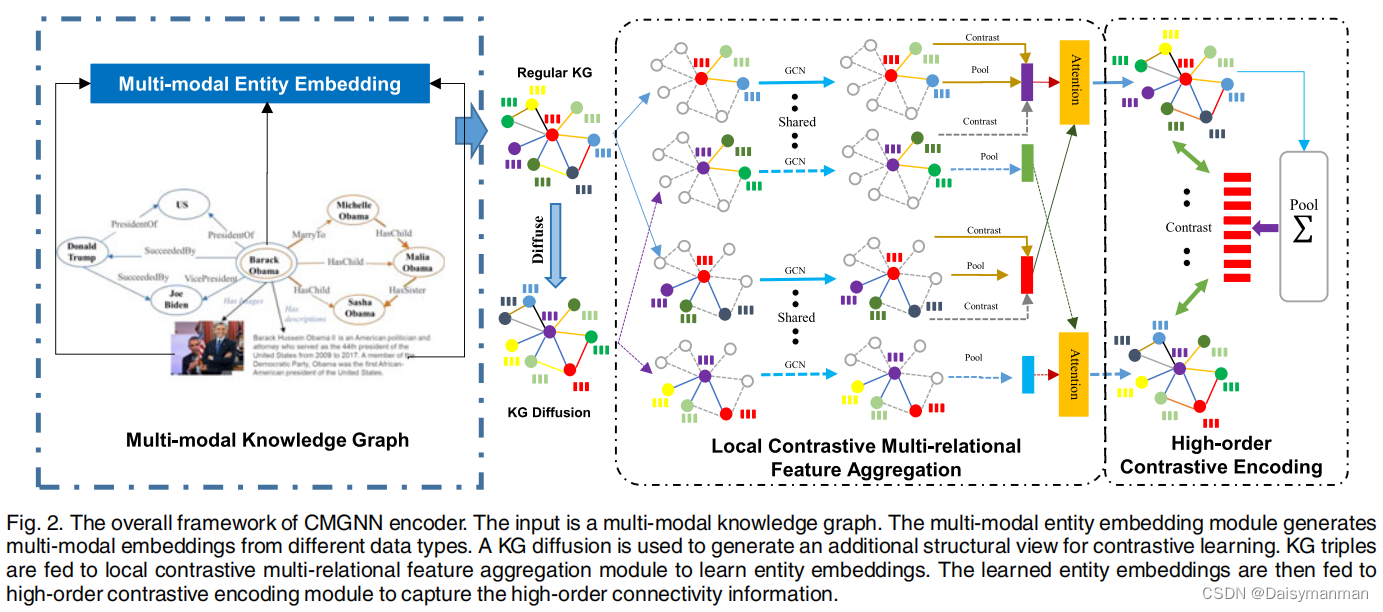
Human cortical encoding of pitch in tonal and non-tonal languages(在音调语音和非音调语言中人类大脑皮层的音高编码)
专业术语
tonal language 音调语言
pitch 音高
lexical tone 词汇音调
anatomical properties 解刨学特性
temporal lobe 颞叶
superior temporal gyri(STG)颞上回
spectrogram 声谱图
spectrum 频谱
pitch contour 音高轮廓
absolute pitch 绝对音高
relative pitch 相对音高
temporal receptive field 时间感受野
regression weights 回归权重
acoustic features 声学特征
pitch height 音高
pitch change 音高变化
speaker-normalized 说话者归一化的
lexical 词汇的
speech neuroscience 语音神经科学
high-resolution cortical recordings 高分辨率皮层记录
Electrocorticography(ECoG)皮层脑电图
Temporal Response Functions (TRFs) 时域反应函数
temporal dynamic 时间动态
概述
本文主要研究音调语言在不同母语的人群的大脑皮层中是如何被编码的,为了确定是否在语音感知上存在语言特异性,作者让母语为普通话和母语为英语的人都被动的听普通话和语言语音,并记录他们大脑皮层的活动。在普通话说话者中,观察到对普通话音调类别的敏感性增强。这表明他们的大脑对普通话语音的音调特征更为敏感。研究结果表明,语音感知依赖于一个共享的皮层听觉特征处理机制。然而,这个共享的特征处理机制可能会根据特定语言的统计特性而进行调整。
introduction
音高在非音调语言中用来传递语调信息,但在音调语言中,音调用来表示不同的词的意义。
在自然语音中,普通话词汇音调的实际音高特征在不同讲话者之间高度变化,这取决于讲话者声带(vocal tract)和喉部(larynx)的解剖特性(anatomical properties),以及在话语中的不同句子之间产生的变异,受单词的话语显著性、句子级短语结构和话语中基音频率(fundamental frequency)递降漂移等因素的影响。跨讲话者(cross-speaker)和跨话语(cross-utterance)的变异存在,需要对词汇音调的音高进行标准化以进行感知。
大量的脑神经影像研究表明 STG 是语音处理的关键皮层,并且表现出对多样的语音特征的选择性编码。但是,对于音调信息是如何被编码的还并不清楚,以及音调相关的音高的神经编码在母语为中文和母语为英语的人之间存在不同吗?
在本项工作中,作者记录了来自 15 个参与者(11 个母语为中文,4 个母语为英文)的神经活动,使用 ECoG 记录颞叶(temporal lobe)皮层,参与者被动的听自然的普通话和英文。通过在跨语言范式中为普通话和英语参与者使用相同的刺激,我们的目标是研究人脑如何处理语言内和跨语言的声音模式变异。
Results
说话者标准化音高定义了普通话中的词汇音调
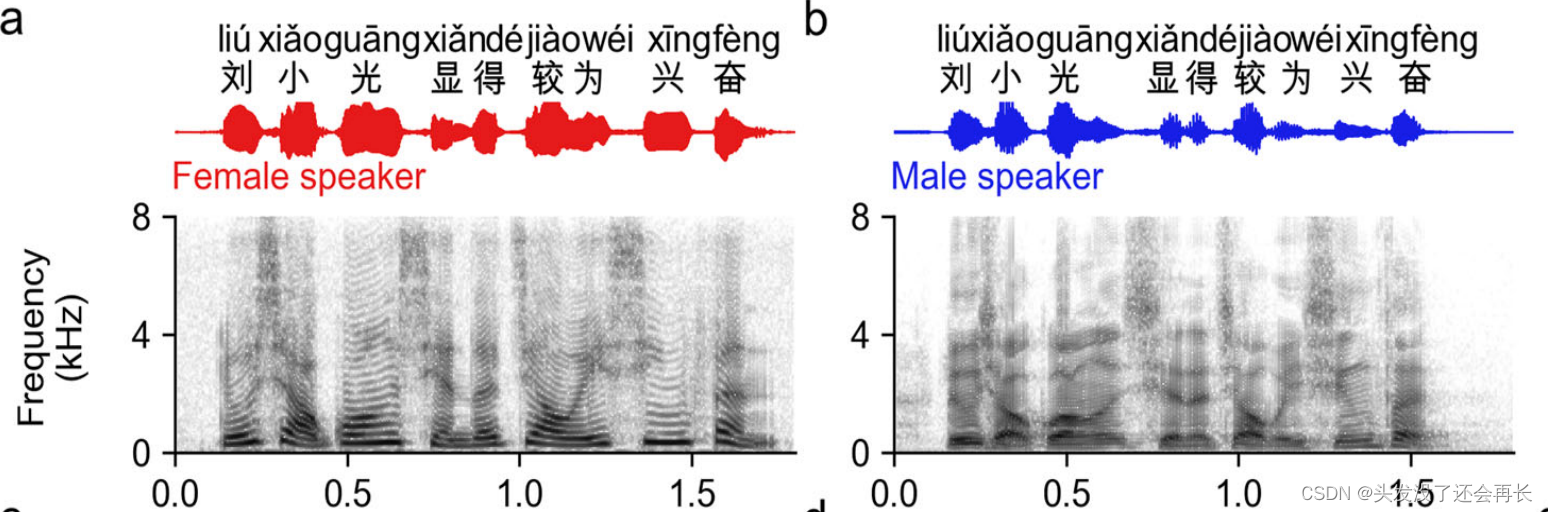
下图 a 和 b 展示了来自一个女性和男性说一句普通话的声音波形和声谱图(spectrogram)。可以看到不同说话者之间的音高和频率都是存在差异的。
Q:
为什么研究音调的时候,使用音高?
A: 在研究音调时使用音高是因为音高是最直接、最明显的指示音调变化的听觉特征。音调是语言中用于区分词义的重要特征,而音高是我们感知和测量音调的关键指标。可以从音高中得到音调特征,比如声谱图中 F0 表示的是音高特征,分析声谱图中的F0变化,可以获得一段音频信号中的音高轮廓,即不同时间点上的音高值,这些音高值的变化模式反映了音调在语音信号中的变化。
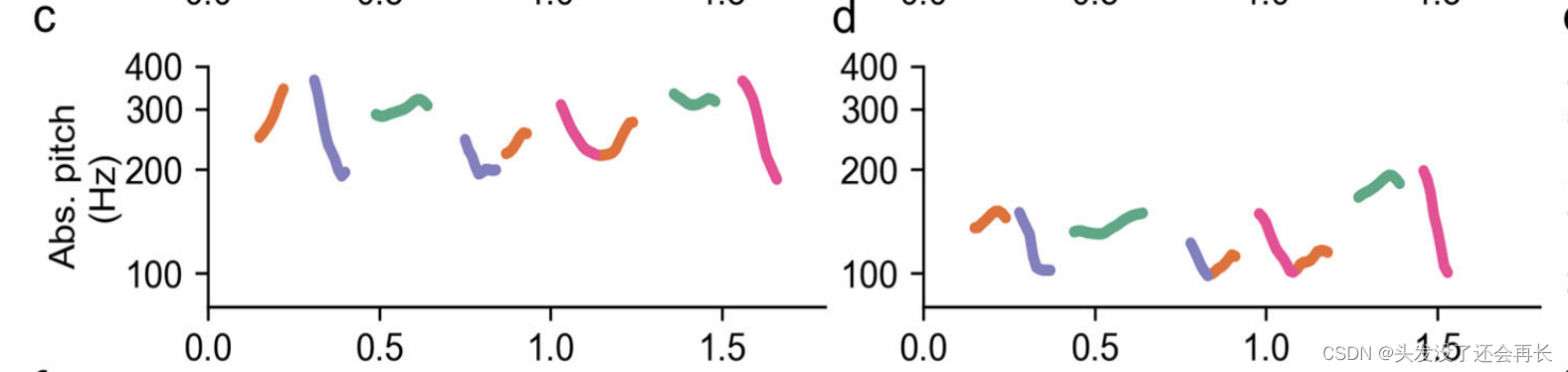
普通话中每一个音节都有一个词汇音调,主要由听觉特征的音高所提示,但是普通话的音调的绝对音高值由于说话者的基线音高的不同而不同。如下图 c 和 d 展示了上面两个句子的绝对音高,每一个音调都根据其词汇音调进行着色。

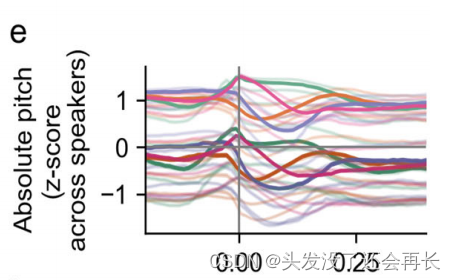
下图 e 是来自语料库中十位讲话者的每一个词汇音调的平均绝对音高轮廓。其中粗线是来自上面例子的两位说话者的绝对音高轮廓,上面颜色亮的来自女性,下面暗色的线来自男性。同一个音调可以有不同的音高轮廓,不同的音调也可以有相似的轮廓,所以音调不仅仅由绝对音高决定,还受其他因素影响。
在音调感知中,已经证明了两个重要的音高特征,即说话者标准化的相对音高和音高变化(relative pitch and pitch change)。
Q: 什么是说话者不标准化的相对音高和音高变化?
A: (1)首先,说话者标准化的相对音高是指将音高与说话者的个体差异进行标准化后的相对度量。不同的说话者具有不同的音高范围和音高偏差,因此通过标准化可以消除个体差异,使得不同说话者之间的音高比较更具可靠性。这种相对音高的度量使我们能够更准确地比较不同音调之间的高低关系,而不受说话者个体差异的影响。
(2)其次,音高变化是指音调在时间上的变化。音高变化是人们感知和理解音调的重要因素之一。通过音高变化,我们可以感知到音调的起伏、上升或下降趋势,从而理解和区分不同的音调。音高变化可以提供音调的动态信息,使我们能够更好地捕捉和解释音乐或语言中的情感、语气和意义。
下图 f,g展示了两个例子句子的相对音高轮廓(relative pitch contour),图 h 展示了每一个音调的平均相对音高(average relative pitch)。图 i,j 展示了例子句子的音高变化(pitch change),图 k 展示了每一个音调的平均相对音高变化(Average pitch change)。可以发现,每个音调的相对音高和音高变化的轮廓在不同讲话者之间保持一致,并且彼此之间有明显的区别。此外,说话者归一化后依旧存在音调之间的差异。

Relative pitch encoding underlies tone discrimination in STG
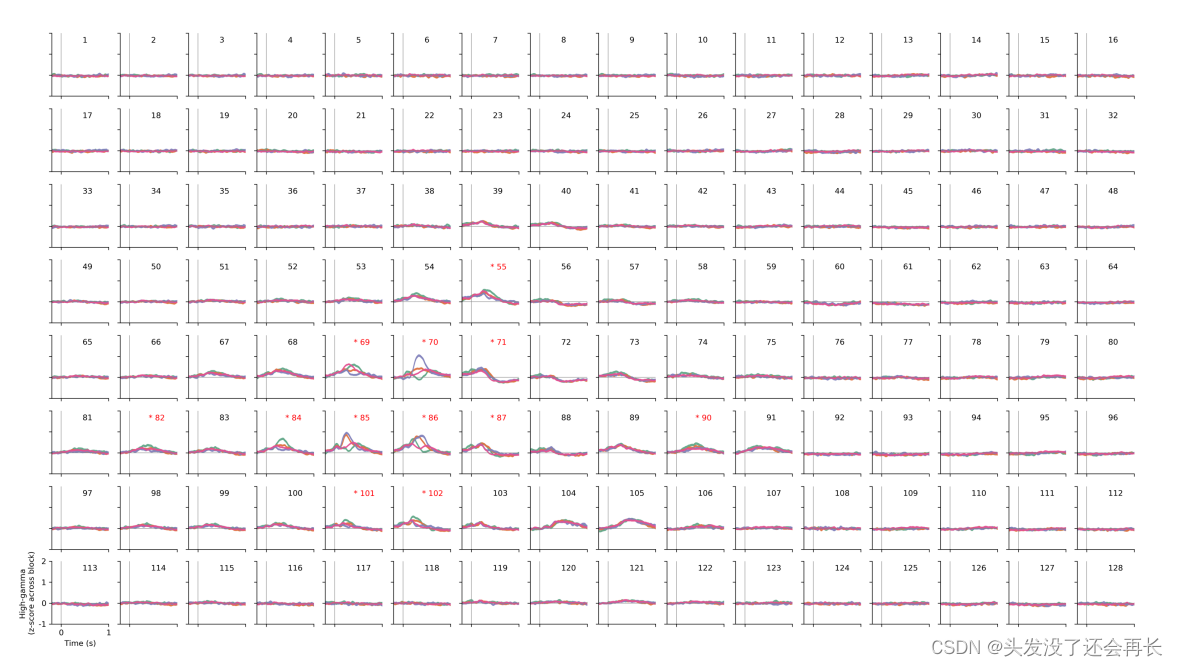
为了理解词汇音调在人类非初级听觉皮层是如何表示的,当 11 位母语为普通话的参与者被动的听一段普通话语音时,我们评估了他们的神经活动,下图是,示例参与者(Subject M2)在单个电极上针对普通话词汇音调的平均事件相关高伽马活动图。每个图板对应一个单独的电极。绘制了对每个音调的平均神经活动(在整个记录块上进行了z得分处理;阴影区域表示均值±标准误)。红色的*表示在词汇音调之间存在显著不同模式的电极(P < 0.05,F检验,双侧,对所有时间点和电极进行了Bonferroni校正以进行多重比较)。下面这个图是使用 ERP 分析每一个电极的响应得到的,比如让被试者听一段话,这段话包含了不同的音调,记录的ECoG信号经过滤波一些预处理后得到的就是Hg频段的,然后先把句子onset和ECoG活动时间对齐再去找音调区分电极。
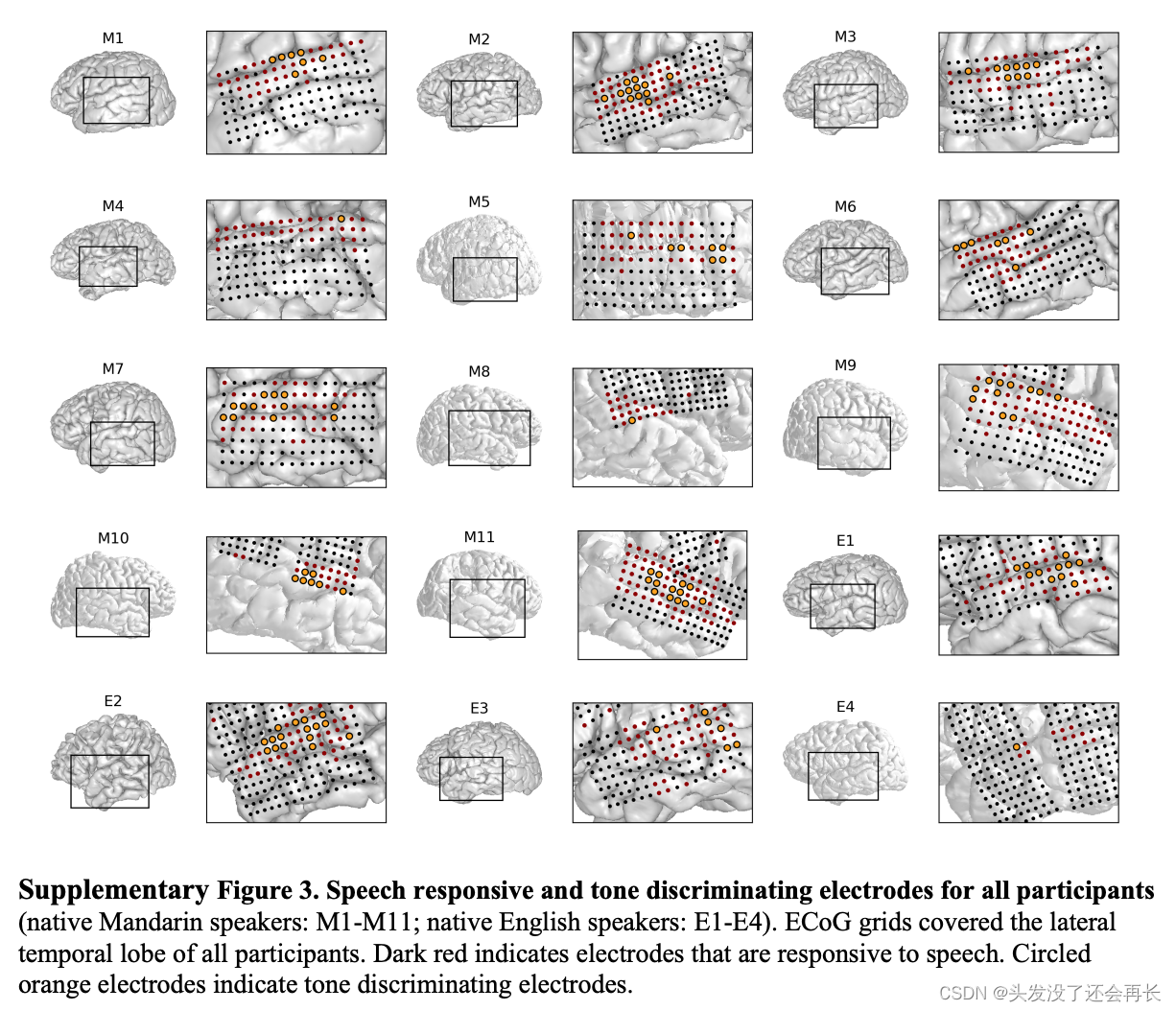
下图显示了所有为参与者的语音响应和音调区分的电极。
我们计算了高
γ
\gamma
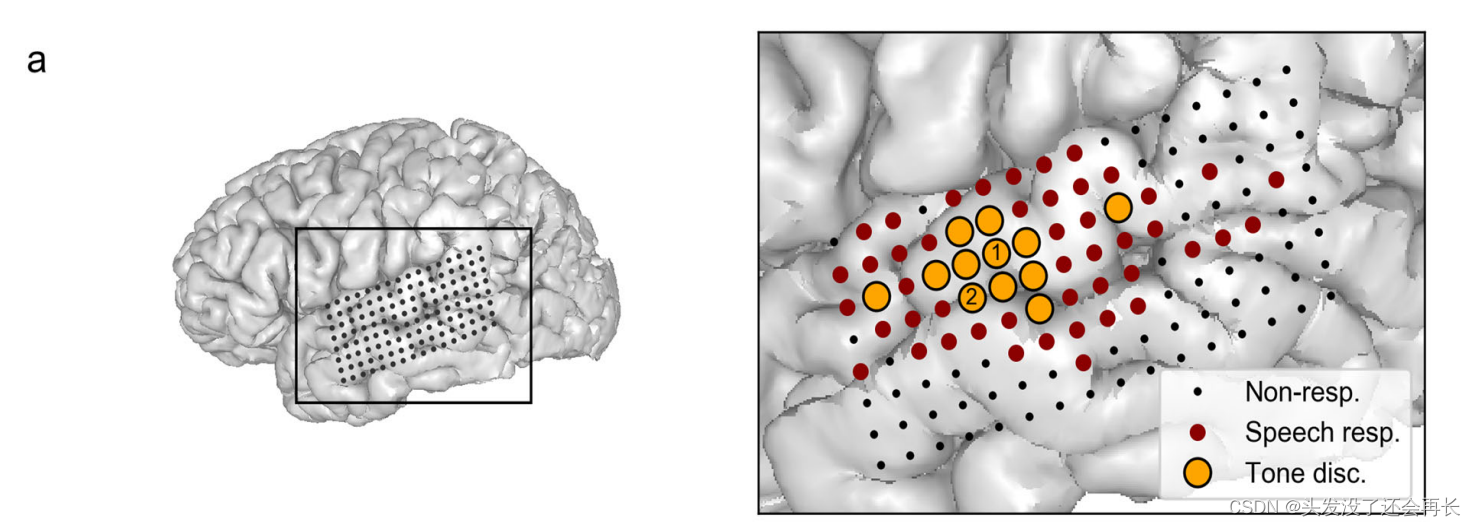
γ波段的信号振幅,发现在 STG 区域对普通话语音的广泛的皮层激活。如下图 a 所示,在 STG 的不同区域对不同的音调存在不同的激活模式。暗红色表示电极对语音有反应,橙色圆圈代表对不同的音调有不同的激活模式。
Q: 为什么计算高伽马(Hg)活动而不是别的频率信号?
A: 分析高伽马活动是因为高伽马频带(30-150 Hz)的神经活动与一系列认知功能和语言加工过程密切相关。
高伽马活动在神经科学研究中被广泛应用,尤其是在研究语言加工和音调处理方面。高伽马频带的神经活动被认为与多种认知过程相关,包括注意力、记忆、意识、语义理解和语音处理等。在语言领域中,高伽马活动被特别关注,因为它与语音的感知、音调的处理以及词汇和句法加工等语言功能密切相关。
上面两个图可以看出对于不同的音调,会有明显的可以区分的响应模式。但是没有发现电极针对一个音调类别进行响应。
下面针对图a 中的电极 1 和电极 2 对每一个音调的神经活动进行分析,分别分析高
γ
\gamma
γ波段,如下图 b 和图 g 所示。可以看出,电极 1 对音调 1、2、3 有较高的响应,电极 2 对音调 1、4 有较高的响应。
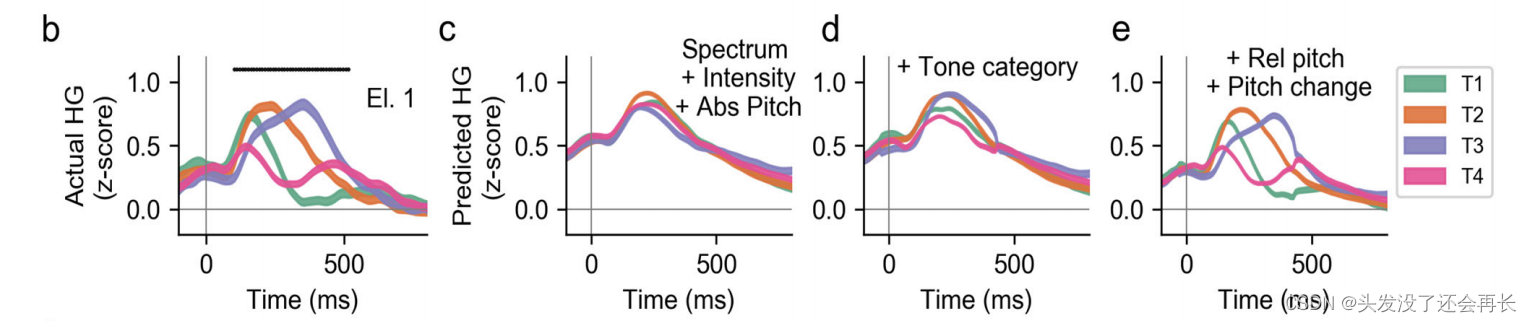
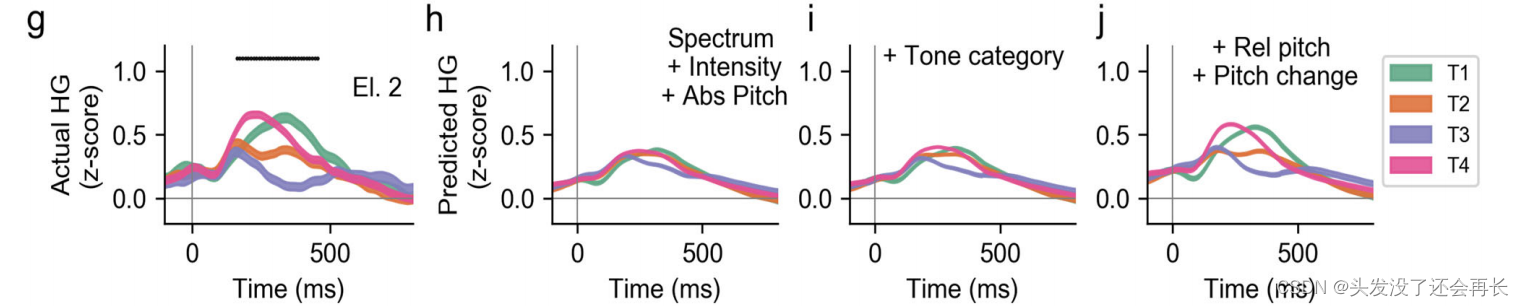
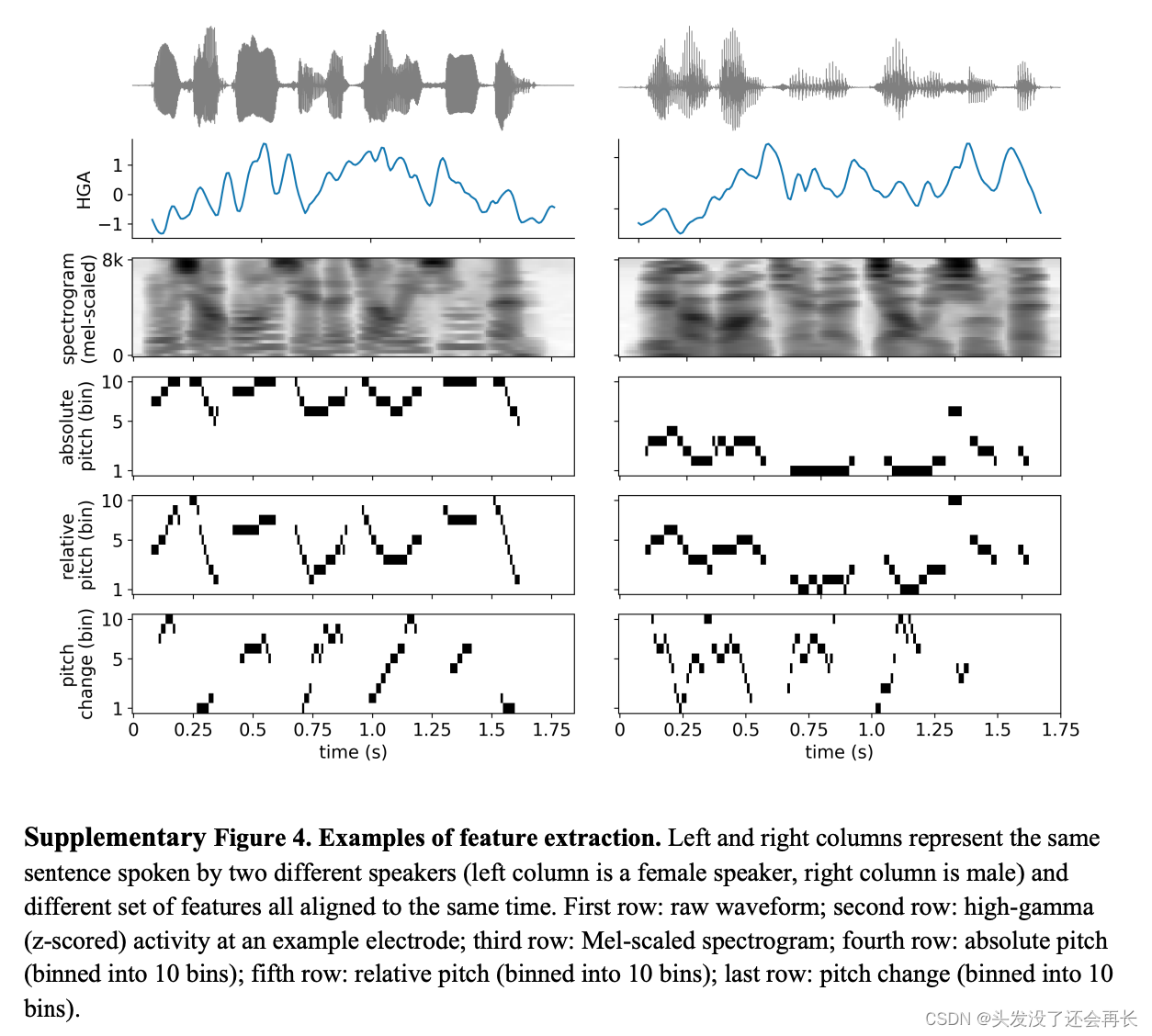
为了测试这些复杂的音高特征是否可以预测超出绝对音高和离散音调身份的神经活动,我们拟合了编码模型,下图展示了一个特征提取的例子,左边和右边是来自两个不同的测试者说同一个句子。分别分析了两个语音的HG 活动波形、声谱图、绝对音高、相对音高、音高变化。
我们首先研究单个电极的模型预测以试图理解说话者归一化编码的音高特征(pitch height and pitch change)是如何导致音调可辨别性的。
两个例子的 STG 电极的实际的响应和预测响应分别如图 b-e、g-j 所示。
图 b 是实际的响应,图 c 是利用频谱,强度,绝对音高特征的编码模型预测到的响应,图 d 是在 c 中的模型加入类别特征得到的预测响应,图 e 是完整的编码模型的预测响应,其中包含了说话者归一化的音高特征。g-j与 a-e 是相同的,只不过来自不同的说话者。可以看到,在加入频谱、强度和绝对音高(c)并不能匹配实际的响应,加入音调类别(d)也不能匹配实际的响应,但是加入说话者归一化的相对音高和音高变化(d)就可以匹配实际的响应。
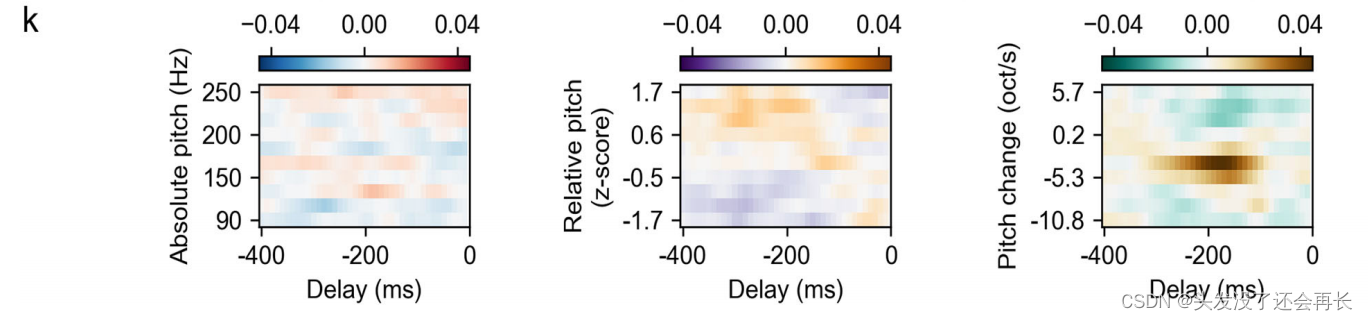
下图 f 、k关于绝对音高、相对音高和音高变化,模型的时间感受野(回归权重)显示了对正音高(positive pitch)和负音高(negative pitch)变化的选择性。
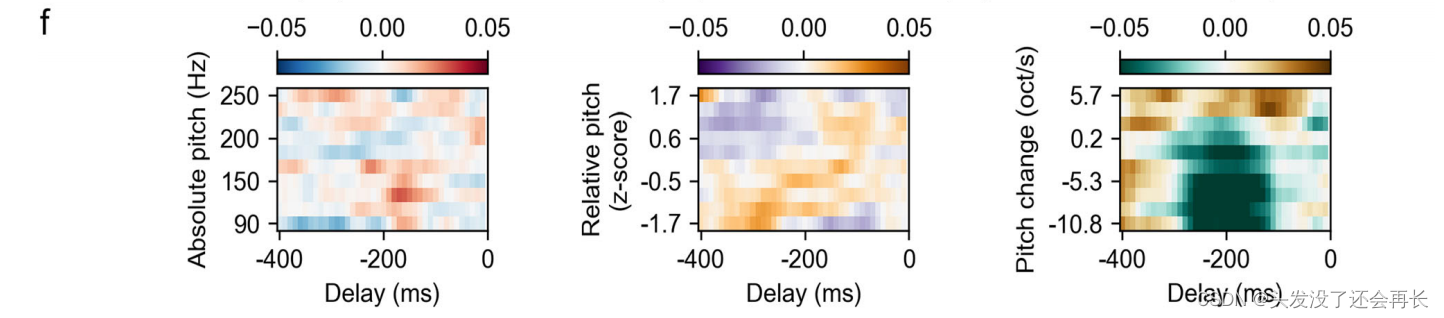
Q: 什么是
回归权重(agressive weight)?
A:回归权重是一种统计分析中的概念,用于衡量自变量对因变量的影响程度。在回归分析中,我们试图建立一个数学模型,通过自变量的值来预测因变量的值。回归权重就是这个数学模型中自变量的系数,它们表示了自变量对因变量的贡献程度或影响方向。
在具体的回归模型中,每个自变量都有一个对应的回归权重。这些权重可以告诉我们自变量的变化对因变量的变化有多大影响,以及这种影响是正向还是负向的。正的回归权重表示自变量的增加与因变量的增加相关,而负的回归权重表示自变量的增加与因变量的减少相关。
回归权重的大小可以用来衡量自变量对因变量的重要性。较大的权重表示自变量对因变量的影响更为显著,而较小的权重表示自变量的影响较小。通常,我们会通过统计方法来确定这些回归权重的显著性,并评估模型的拟合程度和预测能力。
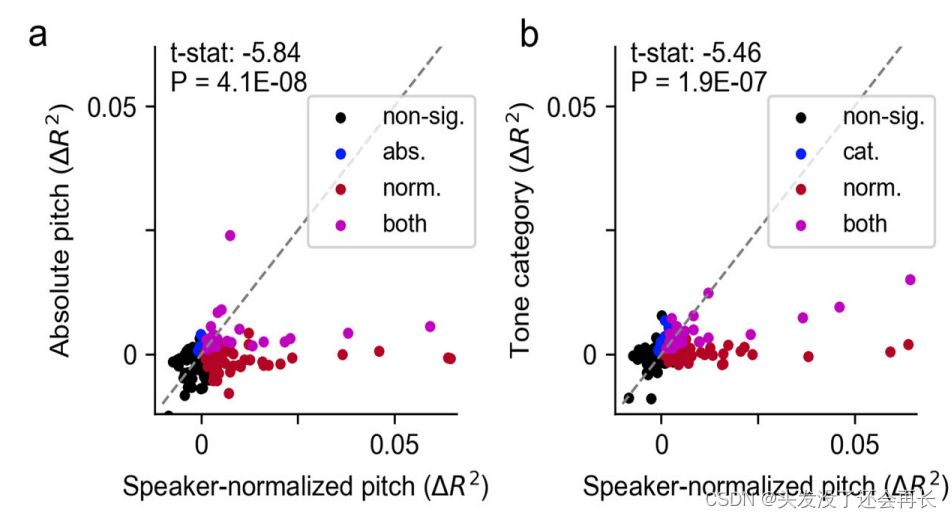
然后,我们量化了所有STG电极的编码,以测试哪些声学特征(acoustic features)是由区分音调的电极编码的。在所有11个普通话母语参与者的541个语音响应电极中,经过说话者归一化的音高特征在112个电极上(占20.7%)独特地解释了显著的方差量(独特
R
2
R^2
R2高达6%)。表示经过说话者归一化的音高特征对解释方差的贡献,与其他自变量相比具有独特的解释能力。但是在 STG 很少位置编码绝对音高和词汇音调类别信息。如下图 a 和 b 所示。
Q: 上面提到的
$R^2$是什么?
A: R 2 R^2 R2(R-squared)是一种统计度量,用于评估回归模型对因变量变异性的解释程度。它表示因变量的变异性能够由回归模型中的自变量解释的比例。
R 2 R^2 R2的取值范围在0到1之间,其中0表示回归模型无法解释因变量的变异性,而1表示回归模型完全能够解释因变量的变异性。
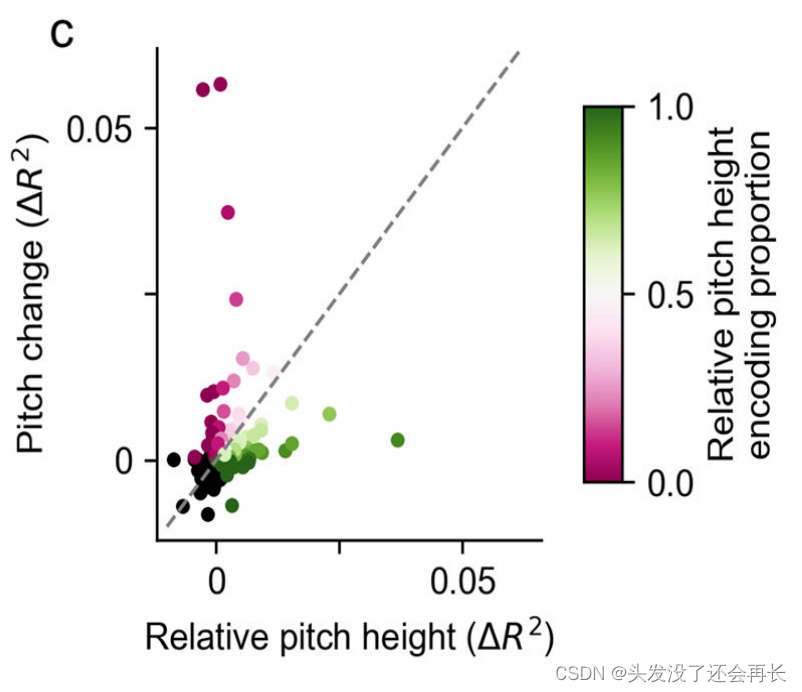
下图 c 绘制了相对音高和音高变化所解释的独立方差的散点图,每个点代表一个单独的电极。彩色点表示对于这两组特征的显著编码,颜色表示对应特征集所解释的方差比例。在针对经过说话者归一化的音高特征进行调整的电极中,个别电极可能调整到相对音高或音高变化中的其中一种特征,而很少有电极对这两种特征都显示出较强的调整。意味着不同的电极可能在音高编码方面具有不同的特异性,并且对于相对音高高度和音高变化的敏感性可能存在差异。
Q: 什么是
独立方差?
A:独立方差(unique variance)是指在多元回归分析中,每个自变量(或特征)对因变量的解释能力中所独立贡献的方差部分。
在多元回归模型中,当多个自变量同时被纳入模型时,它们可能会共同对因变量的变异性进行解释。然而,每个自变量也可能独立地对因变量的变异性做出贡献。独立方差指的就是在所有自变量中,每个自变量单独解释的方差部分,即不被其他自变量解释的部分。
通常,独立方差的比例可以用R2值来表示,即R2值表示因变量的变异性能够由所有自变量共同解释的比例。而独立方差则是在这个共同解释的变异性中,每个自变量所独立贡献的部分。
此外,经过说话者归一化的音高特征所解释的方差与单个电极的音调间区分能力显著相关(通过在音调开始后的1秒时间窗口内计算的最大F统计量来量化;Pearson’s r = 0.85,n = 112个电极,p = 9 × 10^(-32);图d)。然而,绝对音高所解释的方差与之不相关(Pearson’s r = 0.17,n = 42个电极,p = 0.3;图e)。因此,在单个电极的水平上,关于词汇音调的不同神经反应主要是由说话者标准化音高特征的编码驱动的。
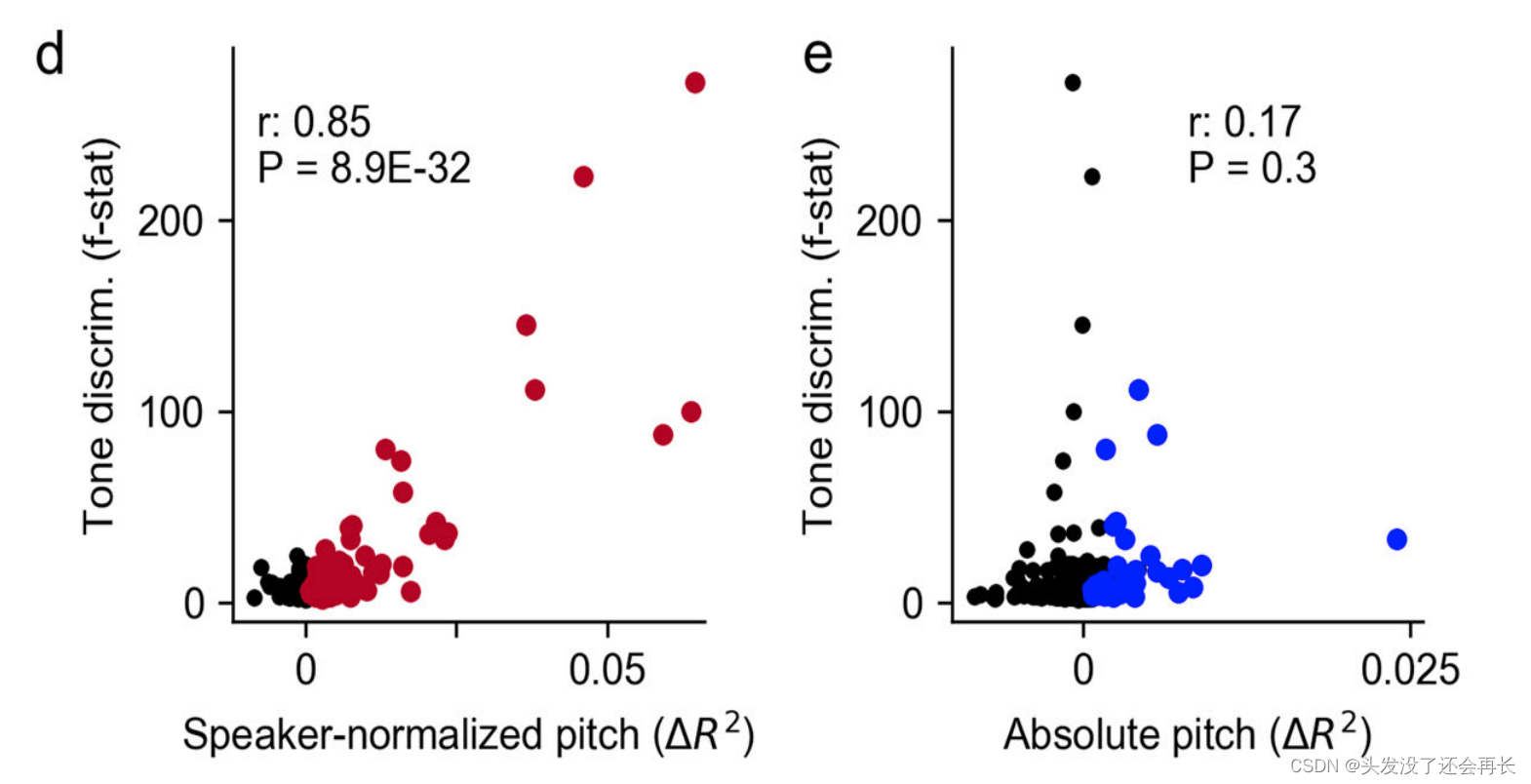
因此,结果表明,说话者归一化音高特征,包括相对音高和音高改变,对音调感知是很重要的。
Speaker-normalized pitch encoding is shared across languages
然后我们想要确定对于用一个听者,是否说话者归一化是针对特定语言的,还是它可以用一般的、语言不变的音高处理听觉机制来解释。
让同样的母语为普通话的人听一段英语(如下图 a),英语对重音和语调有音高变化,但对音调没有变化。同样记录神经活动,我们测试了当音高变化不再表示词汇内容和音调的时候,是否也提取了说话者标准化的音高。

依旧是拟合编码模型,使用英语语音产生的神经响应去训练模型,然后使用普通话语音测试神经响应。
图 b 显示了一个例子 STG 上的电极对不同音调的高伽马响应,c 和 d 是预测模型的结果,两个预测模型分别是使用普通话和语言进行拟合的。两个模型都能很好的捕捉实际的响应模式,
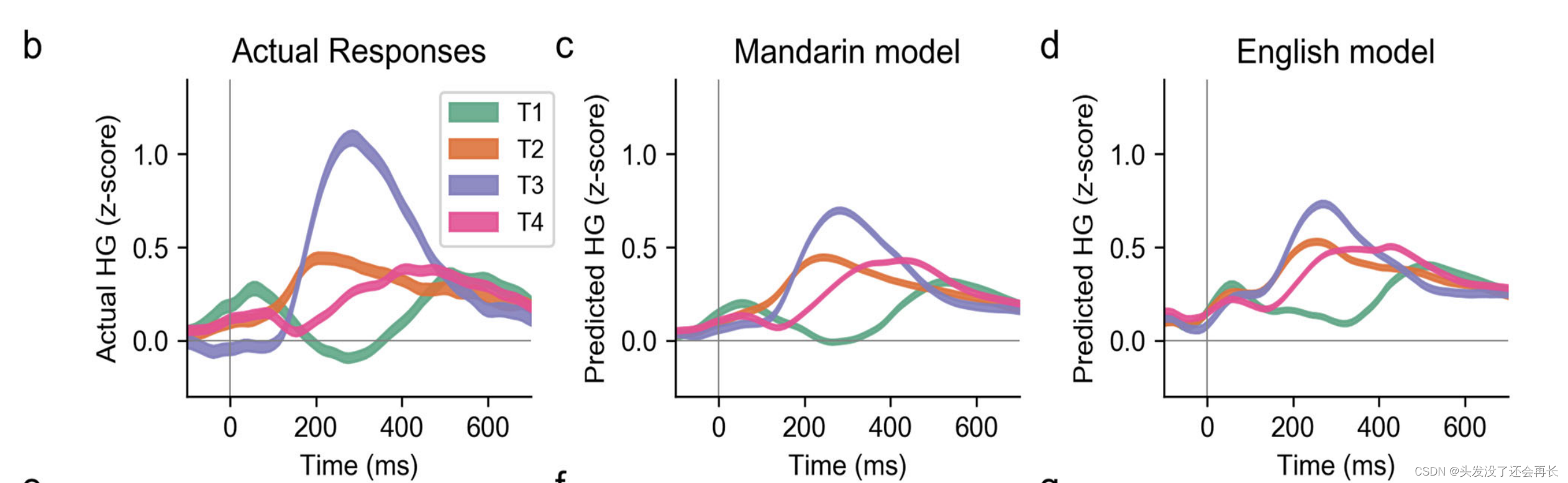
这些结果表明,对于给定的听众来说,单个电极对音高的编码在很大程度上是与语言无关的,因此进一步证明了局部神经对听觉音高线索的编码,而不是对词汇音调类别的处理。
Neural tuning properties are shaped by language experience
这一小节,用来研究编码是否受语言经验的影响,虽然普通话和英语都有音高,但是相比英语,普通话的音调轮廓有更大的音高的动态范围,并且时间上以音节为片段组织。利用这个信息,我们让母语为英语的人听一段相同的普通话,我们比较了英语和普通话说话者之间的STG调谐特性(图5a),以确定说话者归一化音高的局部编码的差异,并评估这些局部差异对音调类别的群体级编码的影响。
针对每个单独的电极,根据说话者归一化音高特征(相对音高高度和音高变化),调谐特性进行了量化(如下图 b 所示,普通话(红色)、英语(蓝色))。调谐曲线的调制深度(最大和最小高伽马响应之间的差异)和调谐曲线的线性性(音高特征和高伽马活动之间的Fisher转换相关系数)用于描述。普通话说话者显示出了更宽的动态范围,覆盖了相对音高高度的平衡分布,而英语说话者显示出了偏向于高相对音高调谐的非对称分布。
(每个点的位置反映了该电极或观测位置在调谐曲线的线性性和调制深度方面的特性。例如,位于图的右上方的点表示具有较高的线性性和调制深度,表明该电极或观测位置对音高特征具有较强的线性响应并能够明显区分不同的音高。相反,位于图的左下方的点表示具有较低的线性性和调制深度,表明该电极或观测位置对音高特征的响应较弱,或者无法明显区分不同的音高。)
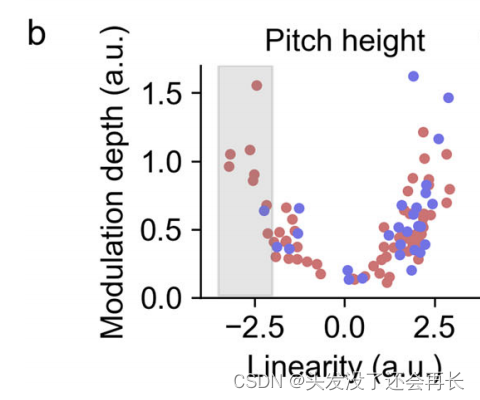
母语为普通话和母语为英语的说话者的自然反应显示了对音高变化相似的调谐。如下图 d 所示。
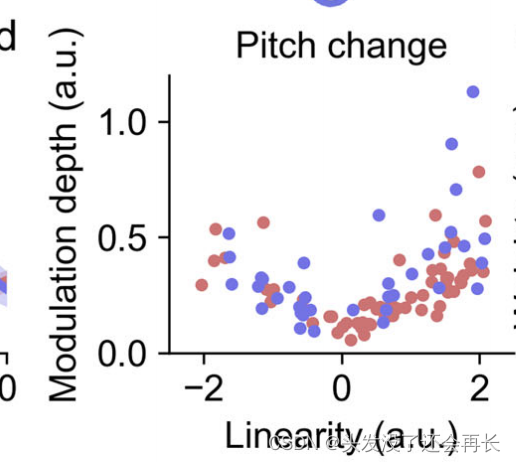
此外,考虑到词汇音调(lexical tone)的时间动态(temporal dynamics),在处理普通话说话者的音高轮廓动态时可能需要不同的整合时间(integration time)。
Q: 什么是
整合时间?
A: 整合时间是指在感知和处理时间动态信息时,系统或个体为了准确地捕捉和理解信息而需要整合或聚合数据的时间窗口长度。在语言处理中,特别是在处理音调或声音的时候,整合时间指的是系统或个体在感知和解析音高变化或音调轮廓时所需的时间间隔。
不同的语言或音调系统可能对时间动态信息的处理有不同的整合时间要求。对于某些语言,如普通话,音调在时间上的变化非常重要,因此可能需要较长的整合时间来捕捉和解析音调的动态特征。而对于其他语言,如英语,音调变化的动态特征可能相对较少,因此可能需要较短的整合时间。
为了评估整合时间,我们比较了个体STG电极的经过说话者归一化的音高特征的平均时域反应函数(TRF)。我们计算了每个时间点相对音高特征的平均绝对回归权重,这代表了编码特性在时间上的动态变化。英语说话者的神经响应显示出音高高度的较短时域反应函数(TRF),峰值出现在约100毫秒左右,而普通话说话者的TRF则持续较长,延伸到约300毫秒左右。
换句话说,他们预测所有听者都会处理说话者归一化的音高,因此即使非声调语言的说话者也能够感知词汇音调之间的心理物理边界。然而,研究还表明,母语为声调语言的说话者可能对语言边界具有超越声学线索的增强敏感性。这意味着他们可能更加敏感于语言中的音调变化,并能够更准确地识别和区分不同的语言边界。这表明母语为声调语言的说话者在处理音调信息时可能具有一定的优势和专门化的处理能力。
Q: 什么是
TRF?
A: 平均时域反应函数(TRF)是一种分析方法,用于研究刺激输入(例如声音、视觉刺激)和神经系统活动之间的关系。TRF可以用来推断在特定时间延迟上刺激输入如何在神经系统中被表示和处理。TRF通过测量神经信号(例如脑电图、脑磁图)和外部刺激之间的时间相关性来估计神经系统对刺激的响应。它可以显示在给定时间延迟内刺激输入的对应神经活动水平,从而提供了对刺激如何在神经系统中被编码和解码的信息。TRF的计算通常基于统计模型,可以使用线性回归或机器学习方法来估计刺激输入与神经信号之间的关系。
Neural population sensitivity to tone categories
普通话说话者在感知音调特征时更加关注音调的形状和轮廓,即音调的上升和下降的曲线模式。他们对于音调变化的形状和走势更敏感,并且能够区分不同的音调轮廓。相比之下,英语说话者主要关注心理物理的音高水平,即音调的高低程度。他们更注重不同音高之间的差异,而不太关注音调的形状和走势。因此,普通话者在区分和归类不同音调的能力上具有一定的优势。
为了解决这个问题,我们随后研究了普通话说话者的STG(颞叶上沟)响应在音调类别(tone categories)上是否存在增强的敏感性(sensitivity),并在整体的人群中得到反映。
我们汇总了非初级听觉皮层(non-primary auditory cortex)中对语音有响应的电极的数据,包括普通话参与者中的316个电极和英语参与者中的171个电极。
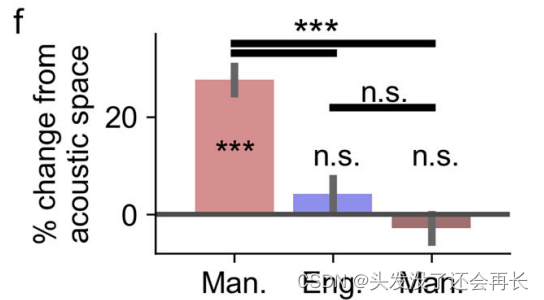
使用多元模式分类器(multivariate pattern classifier)计算了将普通话参与者的集合神经响应数据对四个声调进行分类的最高整体配对分类准确率,并将其与基于声学特征本身的声调分类准确率进行比较。与声学分类准确率相比,普通话参与者的神经分类准确率高出28%(超过了随机水平)(t(198) = 7.88, p = 2.2 × 10−13, 通过自助法进行的双样本t检验,n = 200次重复,双侧检验;图5f),而在英语参与者中没有观察到差异(与声学空间相比,变化率为4.2%)(t(198) = 1.09, p = 0.28, 通过自助法进行的双样本t检验,n = 200次重复,双侧检验;图5f)。如下图所示,红色表示普通话参与者的神经分类准确性高出声学特征本身的百分比,蓝色是英语参与者的,深红色是普通话参与者但是移除了负调谐电极。可以看到表现出强烈负音高编码的电极(图5b中的灰色矩形)从分析中移除后,音调解码准确性显著降低。这表明在音调类别表示中,正负方向均具有强烈调谐的平衡分布是至关重要的。
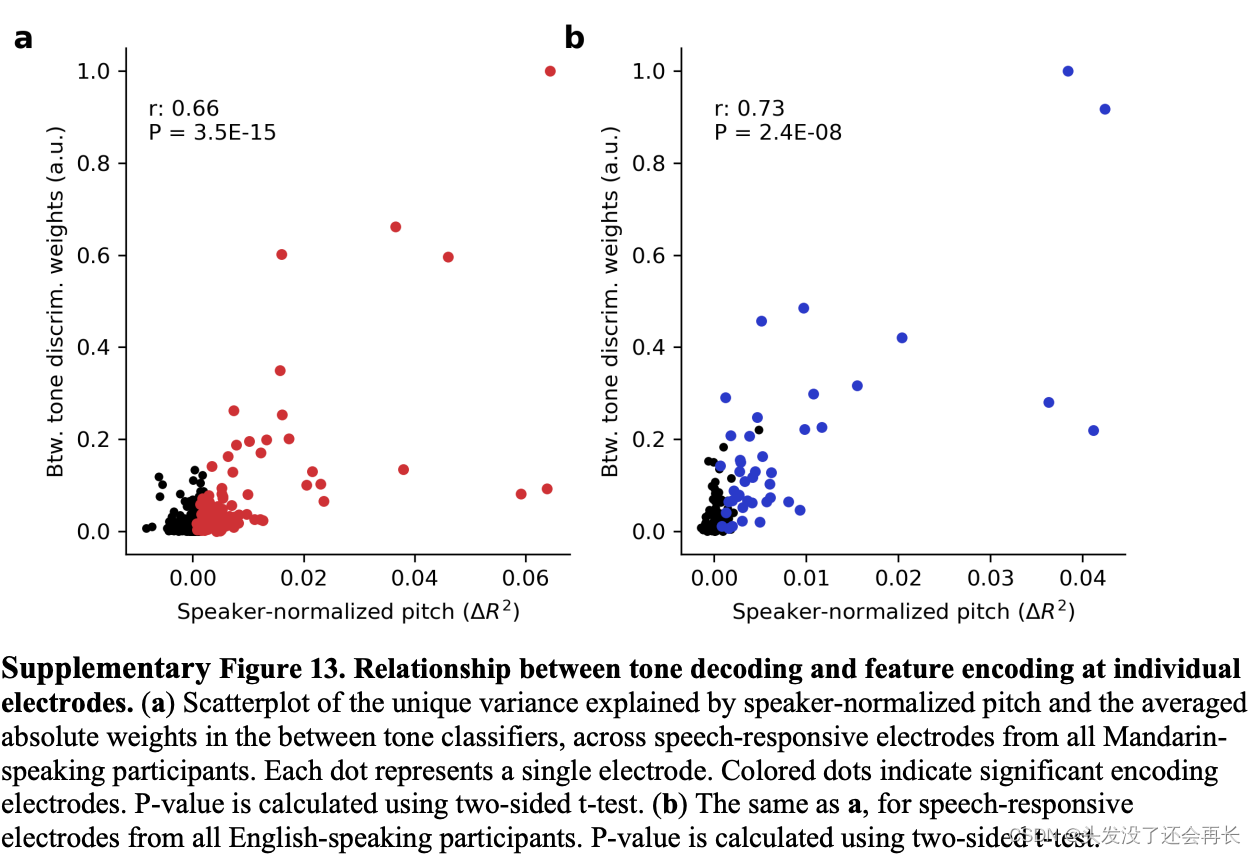
另外,实验发现,音高编码电极对母语为普通话的说话者和英语说话者在音调分类中都起到了贡献。如下图所示,散点图中的每一个点表示一个电极,红色点表示普通话说话者的响应电极,蓝色为英语说话者的响应电极。该散点图的横轴表示标准化说话者音高解释的唯一方差,纵轴是音调分类器中的平均绝对权重。可以看到大多数 电极的说话者归一化音高的方差都在音调分类器中占有一定的权重,说明音高编码电极对音调分类有一定的作用。
Q: 什么是标准化说话者音高解释的
唯一方差?
A:"唯一方差"表示在音调解码任务中,由标准化说话者音高解释所能独立解释的方差。换句话说,它表示标准化说话者音高对于解释音调分类的能力,而不是其他因素的贡献。这个方差的大小可以反映标准化说话者音高在音调解码中的重要性。
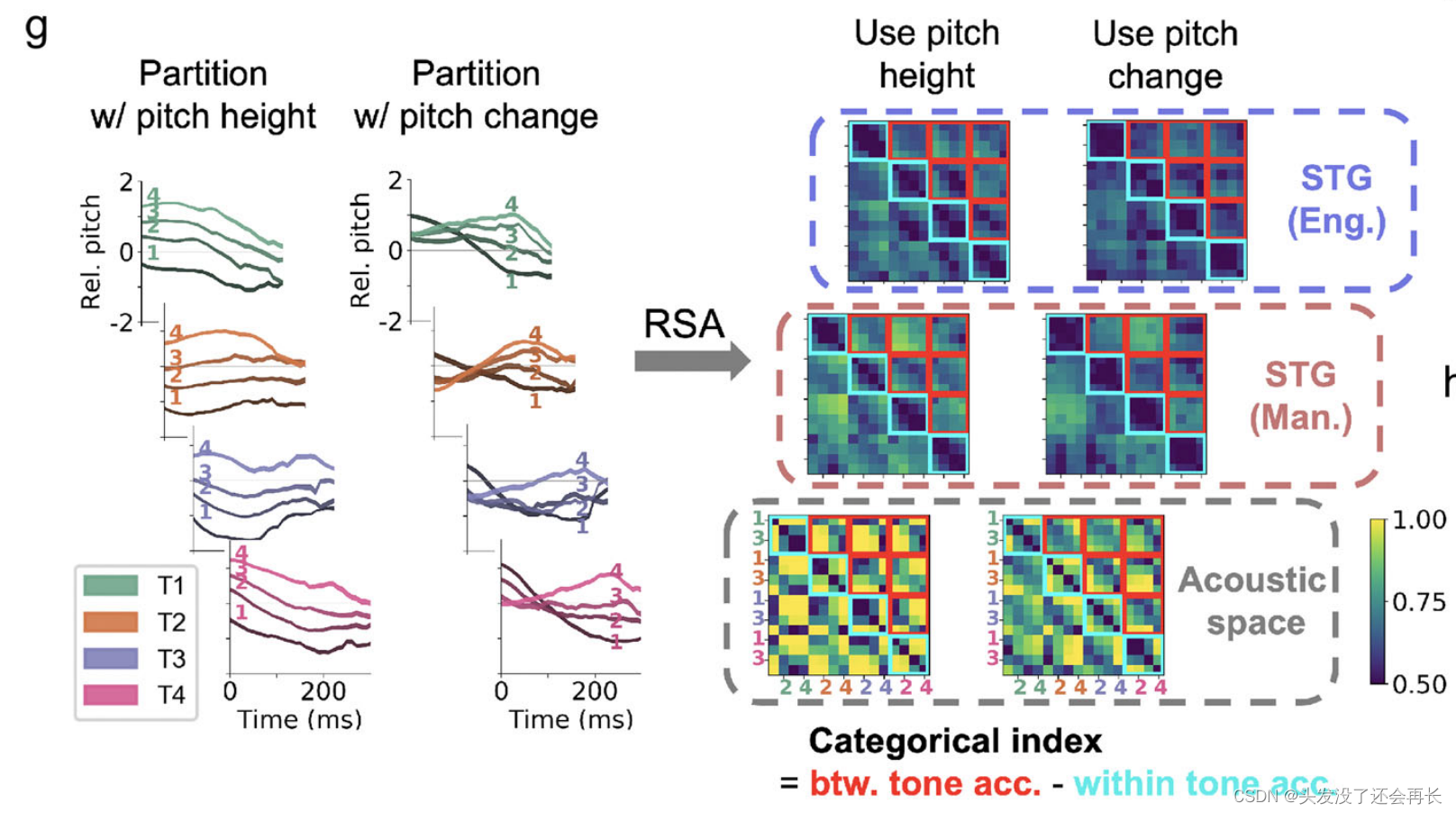
我们进一步希望研究一个基本问题,即群体级别的神经反应是否编码了音高变异(pitch variance)以及声学的连续参数(说话者归一化音高的真实表示),还是偏向于音调的知觉类别。特别地,我们想要测试STG区域的神经反应是否对音调的声学特征维度,如音高和音高变化,敏感于音调的类别边界。为了回答这个问题,我们使用了表示相似性分析(representational similarity analysis)。
首先,我们通过将每个音调类别的音节根据说话者归一化的音高或音高变化分为四组,创建了一个音高曲线的连续谱。如下图 g 所示,(左边的图分别表示音高和音高变化,一个折线图对应一个音调,每一个折线图中四个折线表示四个不同的音节)分别基于平均相对音高和平均音高变化进行分组,对声学空间和母语为普通话的说话者以及母语为英语的说话者的STG区域的群体活动进行了表示相似性分析(RSA)。分类指数=音调间分类准确率的平均值(红色块)- 音调内分类准确率的平均值(青色块)。
在单试次神经响应和音高曲线上应用了多元模式分类器,以评估连接的神经群体空间和声学空间中不同音节组之间的表示相似性。我们评估的关键指标是对音调间类别和音调内类别的响应之间相似性的程度。在音调内类别中具有高相似性但在类别之间具有低相似性表明存在分类表示。
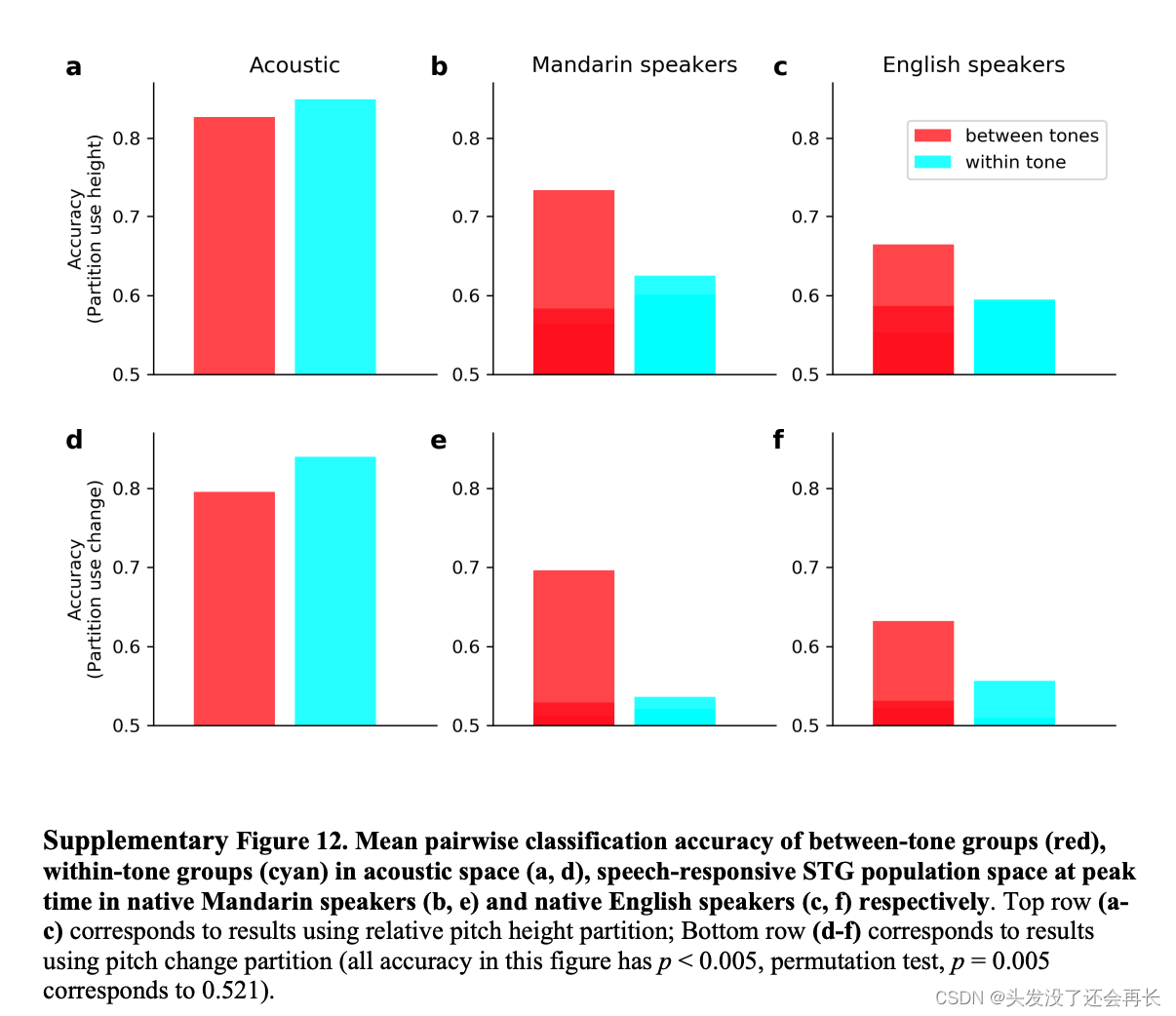
可以得到以下结论:在声学空间中,音调间的可辨识度和音调内的可辨识度都较高,而在神经空间中,与音调内的可辨识度相比,音调间的可辨识度更高,无论是对于普通话说话者还是英语说话者。
Q: 如何使用
多元模式分类器计算相似性的?
A:举例:当使用音高(pitch height)计算不同音节组之间的表示相似性时,可以将相同音调的不同音节的音高数据输入多元模式分类器,并根据分类结果计算相似性。
具体步骤如下:
(1)数据准备:准备包含不同音节的音高数据集。确保该数据集中包含了具有相同音调但不同音节的样本。
(2)特征提取:从每个音节样本中提取音高特征。这可以包括提取音高曲线、音高的平均值、最大值或其他统计特征等。确保提取的特征与训练分类器时使用的特征一致。
(3)模型训练:使用多元模式分类器(如支持向量机、随机森林或深度学习模型)对准备好的音高数据集进行训练。在训练过程中,模型将学习从输入音高特征到相应的音节类别的映射关系。
(4)预测和相似性计算:给定具有相同音调的不同音节的音高特征,将它们输入训练好的模型进行预测。模型将输出相应的音节类别预测结果。根据预测结果,可以计算不同音节之间的相似性,例如使用预测结果的概率分布或距离度量。
此外,对分类准确性进行分析得到下图,可以看到声学特征对音调间和音调内的分类准确率都很高,但是对于两个说话者的音高和音高变化数据,都在音调间有更高的分类准确率。
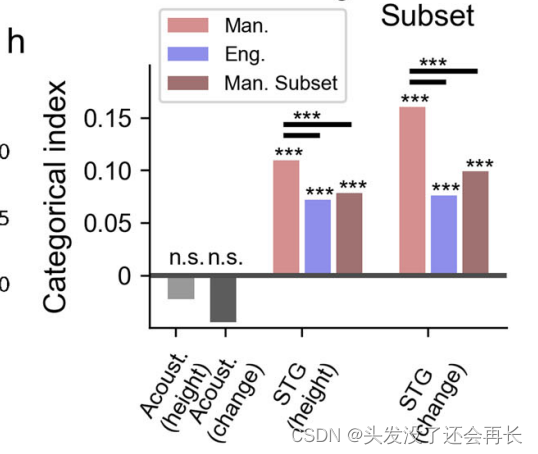
为了量化词汇音调的分类结构,我们定义了"分类指数"(CI),它是区分不同音调之间的平均可辨别性与同一音调内的平均可辨别性之间的差异。如下图 h,基于声学相对音高轮廓的分类指数,对以母语为普通话的说话者(红色)和排除负向调谐电极的STG(深红色)子集,以及以母语为英语的说话者(蓝色)进行了比较(***p < 0.005,n.s. p > 0.1,置换检验)。较高的CI值表示较好的音高分类能力,而较低的CI值表示较差的音高分类能力。通常,CI值越接近1,表示群体或条件之间的音高处理差异越大;而CI值越接近0,表示群体或条件之间的音高处理差异越小。标有三个***的表示差异显著,标有 n.s.表示差异不显著,可以看到,声学空间的差异不显著,即不同音调之间的音高差异和同一音调内的音高变化都对声学空间中的音高产生了影响。STG 上的差异较为显著(普通话说话者:CI = 0.11 和 0.16,均 p < 0.005,置换检验;英语说话者:CI = 0.072 和 0.076,均 p < 0.005,置换检验),因此对于具有相同声学音高差异的标记属于不同的词汇音调,他们会更容易区分,这支持了STG群体中词汇音调的分类表示。
Discuss
音高传递丰富的词汇和语调信息,并且在不同语言中可以用于不同的目的。据估计,全球超过一半的口语语言使用语音音高对比来区分词义。这些声调语言可能具有截然不同的声调系统。因此,在语音神经科学中,声调在声调语言使用者中的表示方式以及这种表示是否与语言有关,是至关重要的问题。
我们的高分辨率皮层记录显示,STG中的局部皮层区域对经过说话者归一化(speaker-normalized)的音高特征(高度和变化)进行编码。对说话者归一化音高的敏感性不是普通话说话者特有的,对于英语说话者同样存在,我们的研究结果表明,用于词汇音调感知(lexical tone perception)的经过说话者归一化的音高的神经表示与语调(intonation)的神经表示重叠(即大脑中负责处理词汇音调和语调的神经机制在一定程度上是相似的),并且在不同语言之间是共享的,反映了一般的听觉处理。
音高(pitch height)和音高变化(pitch change)可以独立编码,这对语言学中的音高感知模型具有重要意义。我们发现,就局部STG(Superior Temporal Gyrus,颞上沟)尺度上的经过说话者归一化的音高特征的调谐曲线(tuning curve)和平均时域反应函数(TRFs)而言,普通话和英语说话者存在重要差异,这可能反映了这两种语言的音高统计特征的差异。普通话可能需要更宽的范围,特别是在中性音高以下的相对低音高方面,而英语可能需要更多的高音高探测器而不是低音高探测器。这些适应性特征可能解释了普通话和英语说话者之间群体音调类别编码的差异。
高密度皮层记录所提供的详细时空信息支持了一个新兴的语音处理模型,该模型在多个空间尺度上支持语音处理:一方面支持对相关声学特性(例如经过说话者归一化的音高)的一般听觉编码,另一方面支持语言特定的“调谐”,使这些特性能够支持有意义的语言知觉(例如词汇音调)。我们的研究结果揭示了复杂声学特性的线性真实编码,以及不同尺度上词汇音调的非线性、分类表示。具体而言,局部STG(Superior Temporal Gyrus,颞上沟)区域对经过说话者归一化的音高有很强的编码能力,但对词汇音调类别的编码能力较弱。分布式的STG网络中的群体编码显示出更强的分类偏向。(即当人们听到不同的词汇音调时,STG中的多个区域会以相似的方式对其进行编码,表现出更强的分类特征)这与先前的人类电生理证据一致,即STG可以支持人群级别的分类知觉,同一个感觉区域可以参与词汇前加工和词汇处理过程。因此,我们的研究结果表明非主要听觉皮层可以参与一般听觉和语言处理。
然而,值得指出的是,由于ECoG电极阵列的覆盖范围限制,我们无法评估前额-颞-顶叶之间的长程连接或其他区域在语言知觉过程中的潜在参与。因此,目前尚不清楚与语言相关的分类表示是由非主要听觉皮层内的反复交互产生,还是由语言网络中其他相互作用区域的顶-下影响所致。
总体而言,我们的研究结果表明,作为声调语和非声调语的代表,普通话和英语在人类非主要听觉皮层中共享了一个与语音相关的音高的基础高阶听觉编码。这种高阶听觉处理可能受到特定语言经验的影响,以适应特定语言的语言统计特征。
以上是对这篇文献的理解和学习记录,希望大家可以多多交流,可以大胆提问,可能有理解错误或者为解释清楚的地方,欢迎批评指正!:)









![[Java、Android面试]_11_线程的启动方式和区别](https://img-blog.csdnimg.cn/direct/5bb2af74cbd64984872b07983a4d8e84.png)