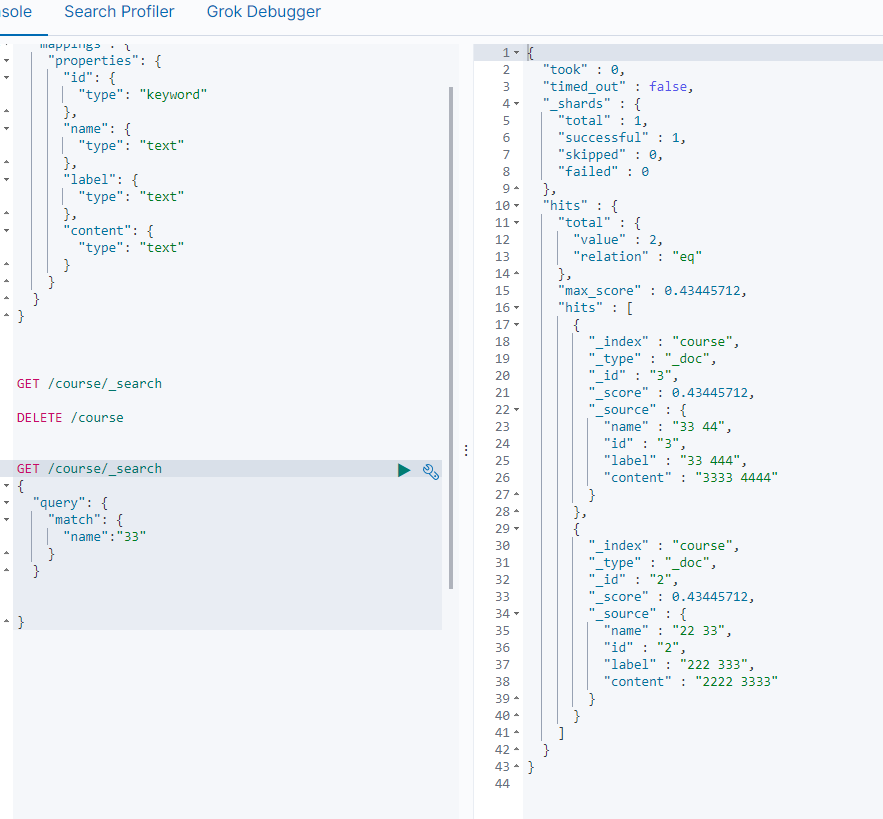
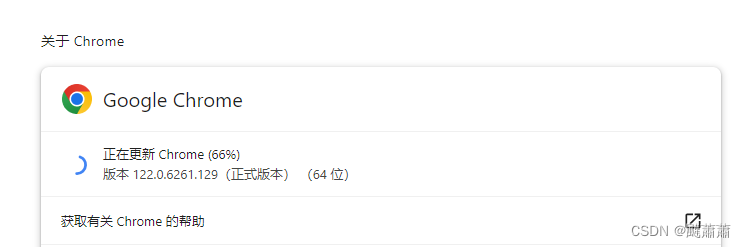
下载chrome驱动
通过chrome浏览器的 设置-帮助-关于Google Chrome 查看你所使用的Chrome版本
驱动可以从这两个地方找:
- 【推荐】https://storage.googleapis.com/chrome-for-testing-public
- http://npm.taobao.org/mirrors/chromedriver
import zipfile
import os
import requests
def un_zip(file_name, to_dir='./'):
"""unzip zip file"""
zip_file = zipfile.ZipFile(file_name)
if os.path.isdir(to_dir):
pass
else:
os.mkdir(to_dir)
for names in zip_file.namelist():
zip_file.extract(names, to_dir)
zip_file.close()
def download_driver(url=None, to_dir='./', version=''):
print('install chrome-driver first')
if not url:
url = 'http://npm.taobao.org/mirrors/chromedriver/LATEST_RELEASE'
if len(version)>0:
url = 'http://npm.taobao.org/mirrors/chromedriver/LATEST_RELEASE_'+version
version = requests.get(url).content.decode('utf8')
driver_file = 'http://npm.taobao.org/mirrors/chromedriver/' + version + '/chromedriver_win32.zip'
else:
driver_file = url
r = requests.get(driver_file)
download_zip = "chromedriver_win32.zip"
with open(download_zip, "wb") as code:
code.write(r.content)
un_zip(download_zip, to_dir)
# os.remove(download_zip)
print('done')
download_driver(url='https://storage.googleapis.com/chrome-for-testing-public/123.0.6312.58/win64/chromedriver-win64.zip', to_dir='./', version='')
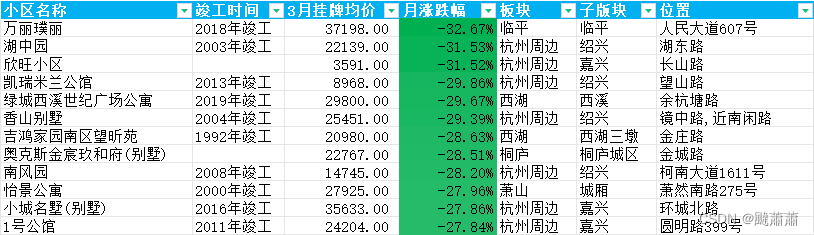
数据库交互
把抓取的数据保存到数据库,sqlite数据库是一个db文件,可以用DBeaver工具打开,很方便
import sqlite3
class DBC:
def __init__(self, dbname):
self.db = dbname
self.conn = None
def __enter__(self):
self.conn = sqlite3.connect(self.db)
return self.conn
def __exit__(self, exc_type, exc_val, exc_tb):
if exc_type is not None:
self.conn.rollback()
print("rollback")
print(exc_type, exc_val, exc_tb)
else:
self.conn.commit()
self.conn.close()
def insert2db(data):
with DBC('anjuke.db') as conn:
cur = conn.cursor()
cur.executemany("""
insert into anjuke(community_name,year,address, tags, price, if_down, percent) values
(?,?,?,?,?,?,?)
""", data)
with DBC('anjuke.db') as conn:
cur = conn.cursor()
cur.execute("""
drop table if exists anjuke
""")
cur.execute("""
create table if not exists anjuke(
id INTEGER primary key AUTOINCREMENT not null,
community_name TEXT,
year TEXT,
address TEXT,
tags TEXT,
price TEXT,
if_down BOOL,
percent TEXT
)
""")
selenium 爪巴虫
import time
import traceback
from selenium import webdriver
browser = webdriver.Chrome()
def process(url):
browser.get(url)
html = browser.page_source
html = BeautifulSoup(html,)
As = html.find_all("a", {"class": "li-row"})
if len(As) == 0:
raise Exception("EMPTY")
data = []
for A in As:
price = A.find("div", {"class": "li-side"})
price_value = price.find("div", {"class": "community-price"})
if price_value:
price_value = price_value.text.strip()
minus = price.find("span")
if minus:
minus = 'propor-green' in minus.attrs['class']
percent = price.find("span")
if percent:
percent = percent.text.strip()
info = A.find("div", {"class": "li-info"})
community_name = info.find("div", {"class": "nowrap-min li-community-title"}).text
year = info.find("span", {"class": "year"})
if year:
year = year.text
advantage =info.find("div", {"class":"prop-tags"})
if advantage:
advantage = advantage.text.strip()
address = info.find("div", {"class": "props nowrap"}).find_all("span")[-1].text
data.append((community_name,year,address, advantage, price_value, minus, percent))
insert2db(data)
i = 0
while i < 50: # 超过50显示重复数据
i += 1
url = f'https://hangzhou.anjuke.com/community/o8-p{i}' # o2,o4,o6,o8不同排序条件
print(url)
try:
process(url)
except Exception as e:
traceback.print_exc()
s = input("check:") # 抓取过程中,可能需要输入验证码
i = i-1
time.sleep(0.5)