狗头
pytorch官网教程:Loading a TorchScript Model in C++ — PyTorch Tutorials 1.13.1+cu117 documentation
首先我已经有了个model.pt,就不需要做前面序列化为文件之类的操作,直接从在C++中加载开始
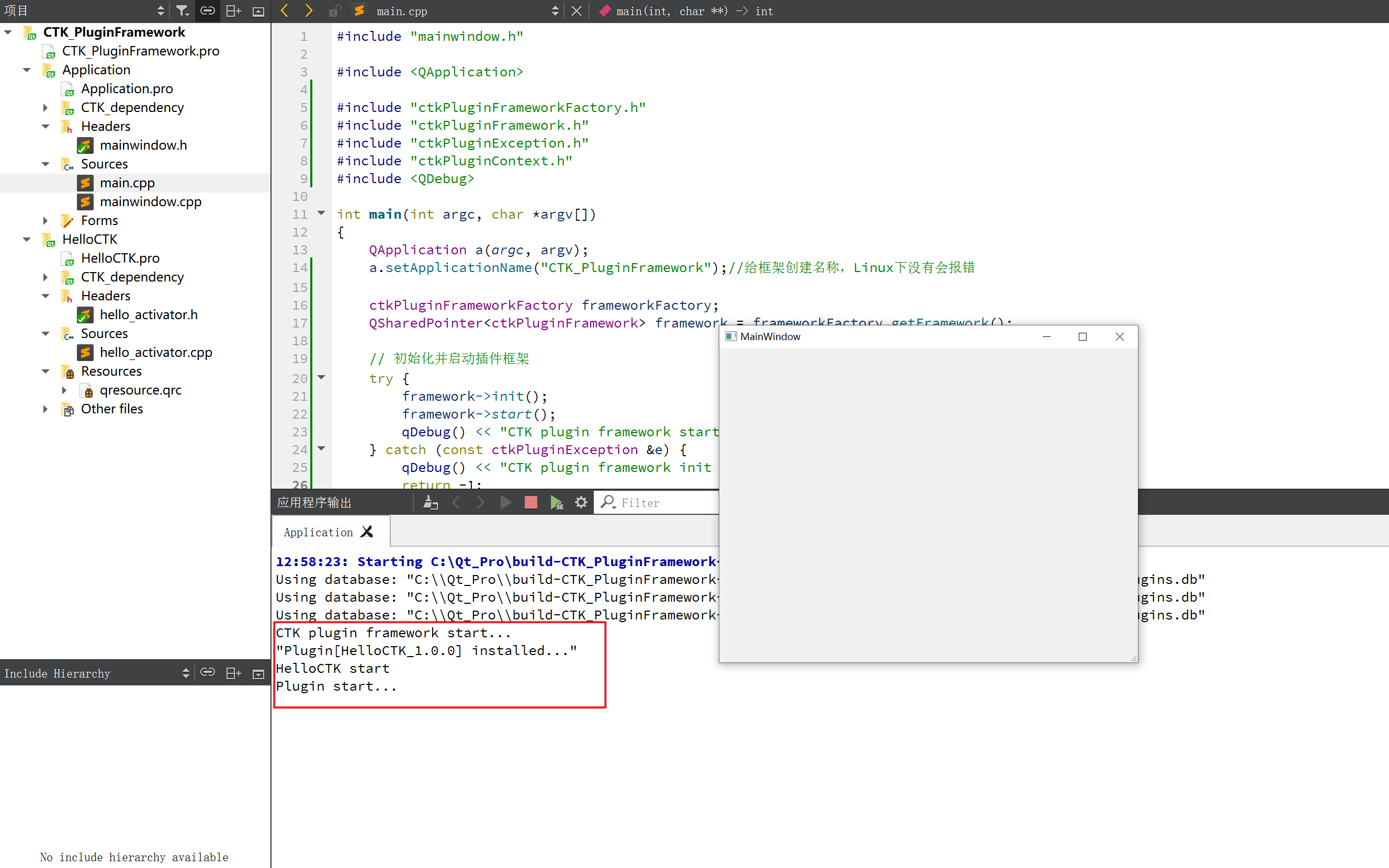
最后成功的版本:
example-app.cpp 内容:
#include <torch/script.h>
#include <torch/cuda.h>
int main(int argc, char* argv[]) {
torch::jit::script::Module module;
// auto device = torch::Device(c10::DeviceType::CUDA, 0);
//auto device = torch::kCUDA;
try {
std::cout << "before loading" << std::endl;
module = torch::jit::load("D:\\project\\example-app\\model_withoutgpu.pt");
// module.to(device);
std::cout << "after loading" << std::endl;
}
catch (const c10::Error& e) {
std::cerr << "error loading the model\n";
//return -1;
}
std::cout << "ok" << std::endl;
std::vector<torch::jit::IValue> inputs;
inputs.push_back(torch::rand({ 1, 6 }));
// Execute the model and turn its output into a tensor.
at::Tensor output = module.forward(inputs).toTensor();
// std::cout << "cuda是否可用:" << torch::cuda::is_available() << std::endl;
// std::cout << "cudnn是否可用:" << torch::cuda::cudnn_is_available() << std::endl;
std::cout << "ok" << std::endl;
while(1);
}CMakeLists.txt 内容:
find_package(PythonInterp REQUIRED)
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(custom_ops)
cmake_policy(SET CMP0054 NEW)
find_package(Torch REQUIRED)
add_executable(example-app example-app.cpp)
target_link_libraries(example-app "${TORCH_LIBRARIES}")
set_property(TARGET example-app PROPERTY CXX_STANDARD 14)cmd中,cmake指令:
进入example-app\build_debug路径下
cmake -DCMAKE_PREFIX_PATH=D:\libtorch -DCMAKE_BUILD_TYPE=Release -G "Visual Studio 17 2022" ..
这一步结束后
cmake --build . --config Debug其中 -DCMAKE_PREFIX_PATH=D:\libtorch根据自己路径修改,"Visual Studio 17 2022"根据自己visualstudio版本修改,--config Debug根据debug还是release修改,也可以进入项目中编译。
遇到的问题和几点:
dll放入exe所在文件夹
最重要的libtorch和pytorch版本对应,这个版本对应网上说法众说纷纭,就说我最后成功的。对应cuda11.7的libtorch1.13.1版本,是cpu版本还是cuda版本也要看清楚。训练环境在anaconda下,pytorch也是cuda版本1.13.1,cuda是11.7。但我训练时并没有使用gpu,最后加载成功。我尝试如果训练时使用gpu生成的.pt就会加载失败,在python在加载没有问题,但是使用时会报RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! 的问题,但探索源码确实训练时只使用了cuda。如果有人能解答我很感激。
torch.jit.load不能加载用torch.save保存的模型,必须对应。
在windows下libtorch的release版本和Debug版本是不同的,混用就会失败,在编译时要使用对用的libtorch。release就是发布版本,有问题不会报错直接退出了,调试不便,所以改用debug。但是release的执行速度远远快于debug版本,因此可以等没问题了换回。和名字对应了。
cmake时warning: Policy CMP0054 is not set: Only interpret if() arguments as variables or keywords when unquoted.
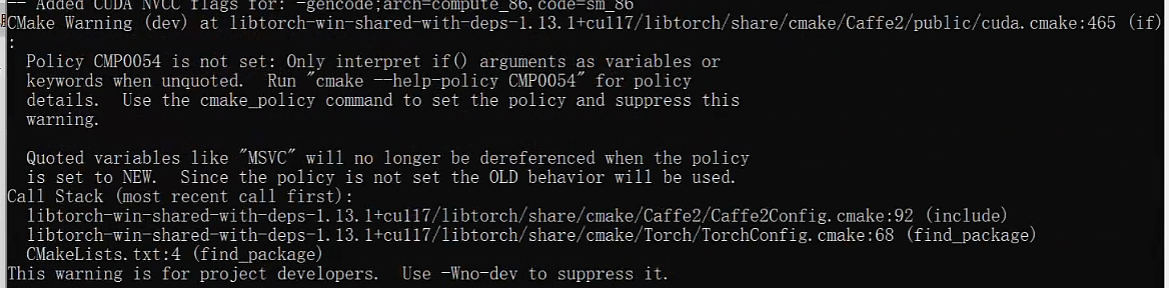
在CMakeLists.txt中加入cmake_policy(SET CMP0054 NEW)解决
cmake配置libtorch报错Failed to compute shorthash for libnvrtc.so,在CMakeLists.txt中加入find_package(PythonInterp REQUIRED)解决,必须放在开头
还有一个思路就是c++这边的问题比较难判断是哪一块,可以在python中尝试相同接口加载.pt看会不会出现错误。因为c++这出错不是报c10::error就是abort() has been calles. 根本无从下手啊。还有当考虑输入维度出现问题的话,都可以在python中用相同接口来验证。
import torch
policy = torch.jit.load('model_withoutgpu.pt')
output = policy.forward(torch.rand(1,6))
print(output)
actions = policy(torch.rand(1, 6))
print(actions)
print(actions.shape)同时每次都需要出去点exe感觉也很麻烦,我更想用本地Windows调试器。这时会报:
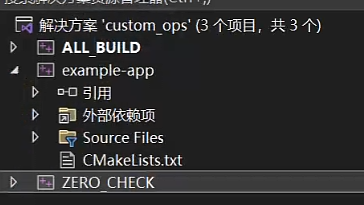
无法启动项目,\ALL_BULID拒绝访问。
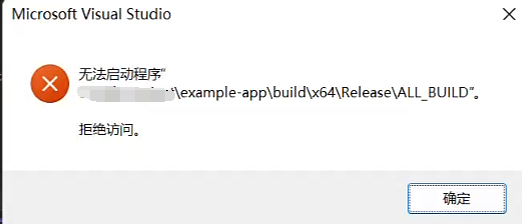
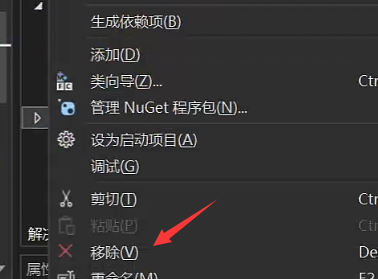
解决方法:把cmake自动生成的另外两个项目ALL_BUILD和ZERO_CHECK右键移除即可
我在成功后尝试将这段代码嵌入自己的项目中,在visualstudio中配置即可,不用写cmake也可以,很愉快。还是注意看清release还是debug。
添加工程的头文件目录:项目-xxx属性-配置属性-c/c++-常规-附加包含目录:

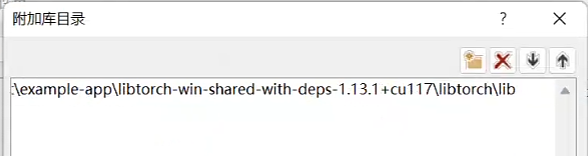
添加文件引用的lib静态库路径:项目-xxx属性-配置属性-链接器-常规-附加库目录:
然后添加工程引用的lib文件名:项目-xxx属性-配置属性-链接器-输入-附加依赖项:
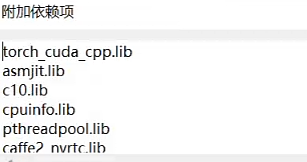
libtorch-win-shared-with-deps-debug-1.13.1+cu117\libtorch\lib下所有.lib
把libtorch\lib下所有dll放到exe所在的文件夹下。
运行成功