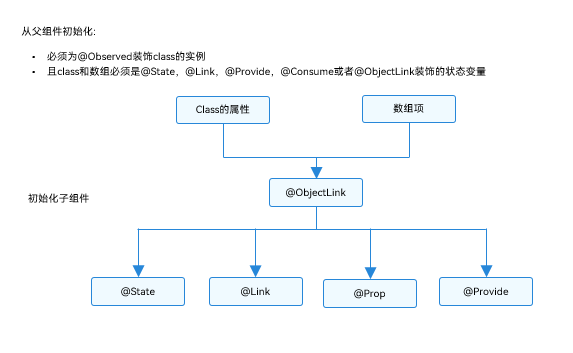
真题1
1、考生文件夹下存在一个文件PY101. py,请写代码替换横线,不修改其他代码,实现以下功能:
键盘输入正整数n,按要求把n输出到屏幕,格式要求:宽度为20个字符,减号字符-填充,右对齐,带千位分隔符。如果输入正整数超过20位,则按照真实长度输出。
例如:键盘输入正整数n为1234,屏幕输出---------------1,234
提示:建议使用本机提供的Python集成开发环境IDLE编写、 调试及验证程序。
代码
n = eval(input("请输入正整数:"))
print("{:->20,}".format(n))
2、考生文件夹下存在一个文件PY102. py,请写代码替换横线,不修改其他代码,实现以下功能:
a和b是两个列表变量,列表a为[3, 6, 9]已给定,键盘输入列表b,计算a中元素与b中对应元素乘积的累加和。
例如:键盘输入列表b为[1,2, 3],累加和为13+26+3*9=42, 因此,屏幕输出计算结果为42
提示:建议使用本机提供的Python集成开发环境IDLE编写、调试及验证程序。
代码
a = [3,6,9]
b = eval(input()) #例如:[1,2,3]
s = 0
for i in range(3):
s += a[i]*b[i]
print(s)
3、考生文件夹下存在一个文件PY103. py,请写代码替换横线,不修改其他代码,实现以下功能:
以123为随机数种子,随机生成10个在1 (含)到999 (含)之间的随机整数,每个随机数后跟随一个逗号进行分隔,屏幕输出这10个随机数。
提示:建议使用本机提供的Python集成开发环境IDLE编写、 调试及验证程序。
代码
import random
random.seed(123)
for i in range(10):
print(random.randint(1,999), end=",")
4、考生文件夹下存在一个文件PY201.py,请写代码替换横线,不修改其他代码,实现以下功能:
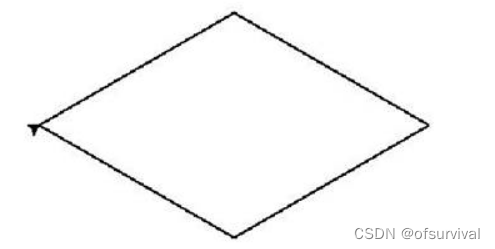
使用turtle库的turtle. right()函数和turtle.fd()函数绘制一个菱形,边长为200像素,4个内角度数为2个60度和2个120度,效果如图所示。
提示:建议使用本机提供的Python集成开发环境IDLE编写、调试及验证程序。
代码
import turtle
turtle.right(-30)
turtle.fd(200) # (1)
turtle.right(60)
turtle.fd(200)
turtle.right(120) # (2)
turtle.fd(200)
turtle.right(60)
turtle.fd(200)
turtle.right(120)
5、考生文件夹下存在一个文件PY202.py,该文件是本题目的代码提示框架,其中代码可以任意修改,请在该文件中编写代码,以实现如下功能:
键盘输入一组人员的姓名、性别、年龄等信息,信息间采用空格分隔,每人一行,空行回车结束录入,示例格式如下:
张三 男 23
李四 女 21
王五 男 18
计算并输出这组人员的平均年龄(保留2位小数)和其中男性人数,格式如下:
平均年龄是20.67 男性人数是2
提示:建议使用本机提供的Python集成开发环境IDLE编写、 调试及验证程序。
代码
data = input() # 姓名 年龄 性别
s=n=i=0
while data:
i+=1
ls = data.split()
s+=int(ls[2])
if ls[1]=='男':
n+=1
data = input()
s/=i
print("平均年龄是{:.2f} 男性人数是{}".format(s,n))
6、考生文件夹下存在3个Python源文件,分别对应3个问题,1个文本文件,作为本题目输入数据,请按照源文件内部说明修改代码,实现以下功能:
《命运》是著名科幻作家倪匡的作品。这里给出《命运》的一个网络版本文件,文件名为“命运. txt”。
问题1 (5分) :在PY301-1. py文件中修改代码,对“命运. txt”文件进行字符频次统计,输出频次最高的中文字符(不包含标点符号)及其频次,字符与频次之间采用英文冒号”:”分隔,示例格式如下:
理:224
问题2 (5分) :在PY301-2. py文件中修改代码,对“命运. txt”文件进行字符频次统计,按照频次由高到低,屏幕输出前10个频次最高的字符,不包含回车符,字符之间无间隔,连续输出,示例格式如下:
理斯卫…(后略,共10个字符)
问题3 (10分) :在PY301-3. py文件中修改代码,对“命运. txt”文件进行字符频次统计,将所有字符按照频次从高到低排序,字符包括中文、标点、英文等符号,但不包含空格和回车。将排序后的字符及频次输出到考生文件夹下,文件名为“命运-频次排序. txt”。字符与频次之间采用英文冒号”:”分隔,各字符之间采用英文逗号”,”分隔,参考CSV格式, 最后无逗号,文件内部示例格式如下:
理:224,斯:120,卫:100
提示:建议使用本机提供的Python集成开发环境IDLE编写、 调试及验证程序。
问题一代码
f= open('命运.txt','r')
txt = f.read()
d = {}
for i in txt:
if i not in ",。?!《》【】“”‘’":
d[i]=d.get(i,0)+1
ls=list(d.items())
ls.sort(key=lambda x :x[1],reverse = True)
print("{}:{}".format(ls[0][0],ls[0][1]))
f.close()
问题二代码
f=open('命运.txt','r')
txt = f.read()
d = {}
for i in txt:
if i not in '\n':
d[i] = d.get(i,0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 此行可以按照词频由高到低排序
for k in range(10):
print(ls[k][0],end='')
f.close()
问题三代码
f = open('命运.txt','r')
fi = open('命运-频次排序.txt','w')
txt = f.read()
d = {}
for i in txt:
if i not in '\n':
d[i] = d.get(i,0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 此行可以按照词频由高到低排序
s = ""
for k in ls:
s+="{}:{}".format(k[0],k[1])+','
fi.write(s[:-1])
f.close()
真题2
1、考生文件夹下存在一个文件PY101.py,请写代码替换横线,不修改其他代码,实现以下功能:
随机选择一一个手机品牌屏幕输出。
提示:建议使用本机提供的Python集成开发环境IDLE编写、调试及验证程序。
代码
import random
brandlist = ['华为','苹果','诺基亚','OPPO','小米']
random.seed(0)
name=brandlist[random.randint(0,4)]
print(name)
2、考生 文件夹下存在一个文件PY102.py,请写代码替换横线,键盘输入一段文本,保存在一个字符串变量txt中,分别用Python内置函数及jieba库中已有函数计算字符串txt的中文字符个数及中文词语个数。注意:中文字符包含中文标点符号。
例如,键盘输入:
俄罗斯举办世界杯
屏幕输出:
中文字符数为8,中文词语数为3。
提示:建议使用本机提供的Python集成开发环境IDLE编写、 调试及验证程序。
代码
import jieba
s = input("请输入一个字符串")
n = len(s)
m = len(jieba.lcut(s))
print("中文字符数为{},中文词语数为{}。".format(n, m))
3、考生文件夹下存在一个文件PY103.py,请写代码替换横线,不修改其他代码,实现以下功能:
某商店出售某品牌运动鞋,每双定价160,1双不打折,2双(含)到4双(含)打九折,5双(含)到9双(含)打八折,10双(含)以上打七折,键盘输入购买数量,屏幕输出总额(保留整数)。示例格式如下:
输入: 1
输出:总额为: 160
提示:建议使用本机提供的Python集成开发环境IDLE编写、调试及验证程序。
代码
n = eval(input("请输入数量:"))
if n>0 and n<=1:
cost=n*160
elif n<=4:
cost=n*160*0.9
elif n<=9:
cost=n*160*0.8
else:
cost=n*160*0.7
cost=int(cost)
print("总额为:",cost)
4、考生文件夹下存在一个文件PY201.py,请写代码替换横线,不修改其他代码,实现以下功能:
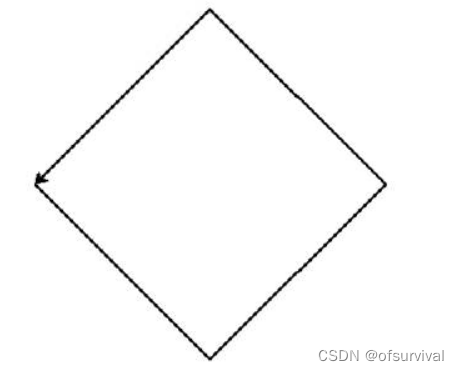
使用turtle库的turtle.fd()函数和turtle. seth()函数绘制一个边长为200的正菱形,菱形4个内角均为90度。
效果如下图所示,箭头与下图严格一致。
提示:建议使用本机提供的Python集成开发环境IDLE编写、调试及验证程序。
代码
import turtle
turtle.pensize(2)
d = -45
for i in range(4):
turtle.seth(d)
d += 90
turtle.fd(200)
5、考生 文件夹下存在一个文件PY202.py,请在该文件中作答,实现以下功能。
键盘输入某班各个同学就业的行业名称,行业名称之间用空格间隔(回车结束输入)。完善Python代码,统计各行业就业的学生数量,按数量从高到低方式输出。例如输入:
交通 金融 计算机 交通 计算机 计算机
输出参考格式如下,其中冒号为英文冒号:
计算机:3
交通:2
金融:1
提示:建议使用本机提供的Python集成开发环境IDLE编写、调试及验证程序。
代码
names=input("请输入各个同学行业名称,行业名称之间用空格间隔(回车结束输入):")
t=names.split()
d = {}
for c in range(len(t)):
d[t[c]]=d.get(t[c],0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 按照数量排序
for k in range(len(ls)):
zy,num=ls[k]
print("{}:{}".format(zy,num))
6、考生文件夹下存在两个Python源文件,分别对应两个问题,请按照文件内说明修改代码,实现以下功能:
下面所示为一套由公司职员随身佩戴的位置传感器采集的数据,文件名称为“sensor.txt”,其内容示例如下:
2016/5/31 0:05, vawelon001, 1, 1
2016/5/31 0:20, earpa001, 1,1
2016/5/31 2:26, earpa001,1, 6
… (略)
第一列是传感器获取数据的时间,第二列是传感器的编号,第三列是传感器所在的楼层,第四列是传感器所在的位置区域编号。
问题1 (10分) :在PY301-1. py文件中修改代码,读入sensor. txt文件中的数据,提取出传感器编号为earpa001的所有数据,将结果输出保存到“earpa001. txt”文件。输出文件格式要求:原数据文件中的每行记录写入新文件中,行尾无空格,无空行。参考格式如下:
2016/5/31 7:11, earpa001,2, 4
2016/5/31 8:02, earpa001,3, 4
2016/5/31 9:22, earpa001,3,4
… (略)
问题2 (10分) :在PY301-2. py文件中修改代码,读入“earpa001. txt” 文件中的数据,统计earpa001对应的职员在各楼层和区域出现的次数,保存到“earpa001_count. txt” 文件,每条记录一 行,位置信息和出现的次数之间用英文半角逗号隔开,行尾无空格,无空行。参考格式如下。
1-1,5
1-4, 3
… (略)
含义如下:
第1行“1-1,5”中1-1表示1楼1号区域,5表示出现5次;
第2行“1-4,3”中1-4表示1楼4号区域,3表示出现3次;
提示:建议使用本机提供的Python集成开发环境IDLE编写、调试及验证程序。
问题一代码
f = open('sensor.txt','r',encoding='utf-8')
fo = open('earpa001.txt','w')
ls = f.readlines()
for line in ls:
lt = line.strip('\n').split(',')
if lt[1] == ' earpa001':
fo.write('{},{},{},{}\n'.format(lt[0],lt[1],lt[2],lt[3]))
f.close()
fo.close()
问题二代码
f = open('earpa001.txt','r',encoding = 'utf-8')
fo = open('earpa001_count.txt','w')
ls = f.readlines()
d = {}
for line in ls:
lt = line.strip('\n').split(',')
key = lt[2]+'-'+lt[3]
d[key] = d.get(key,0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 该语句用于排序
for k in ls:
fo.write('{},{}\n'.format(k[0],k[1]))
f.close()
fo.close()
真题3
1、考生文件夹下存在一个文件PY101.py,请写代替换横线,实现以下功能:
从键盘输入4个数字,各数字采用空格分隔,对应为变量x0,y0,x1,y1。计算两点(x0,y0)和(x1,y1)之间的距离,屏幕输出这个距离,保留2位小数。
例如:键盘输入:0 1 3 5
屏幕输出:5.00
代码
ntxt = input("请输入4个数字(空格分隔):")
nls=ntxt.split( )
x0 = eval(nls[0])
y0 = eval(nls[1])
x1 = eval(nls[2])
y1 = eval(nls[3])
r = pow(pow(x1-x0, 2) + pow(y1-y0, 2), 0.5)
print("{:.2f}".format(r))
2、考生文件夹下存在一个文件PY102.py,请写代码替换横线,不修改其他代码,实现以下功能:
键盘输入一段中文文本,不含标点符号和空格,命名为变量s,采用jieba库对其进行分词,输出该文本中词语的平均长度,保留1位小数。
例如:键盘输入:吃葡萄不吐葡萄皮
屏幕输出:1.
代码
import jieba
txt = input("请输入一段中文文本:")
ls=jieba.lcut(txt)
print("{:.1f}".format(len(txt)/len(ls)))
3、考生文件夹下存在一个文件PY103.py,请写代码替换横线,不修改其他代码,实现以下功能:
键盘输入一个9800到9811之间的正整数n,作为Unicode编码,把n-1、n和n+1三个Unicode编码对应字符按照如下格式要求输出到屏幕:宽度为11个字符,加号字符+填充,居中。
例如:键盘输入:9802
屏幕输出:++++???++++
代码
n = eval(input("请输入一个数字:"))
print("{:+^11}".format(chr(n-1)+chr(n)+chr(n+1)))
4、考生文件夹下存在一个文件PY201.py,请写代码替换横线,不修改其他代码,实现以下功能:
使用turtle库的turtle.fd()函数和turtle.seth()函数绘制一个每方向为100像素长度的十字形,效果如图所示。
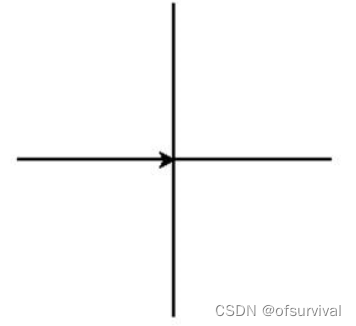
代码
import turtle
for i in range(4):
turtle.fd(100)
turtle.fd(-100)
turtle.seth((i+1)*90)
5、考生文件夹下存在一个文件PY202.py,该文件是本题目的代码提示框架,其中代码可以任意修改。请在该文件中编写代码,以实现如下功能:
键盘输入一组我国高校所对应的学校类型,以空格分隔,共一行,示例格式如下:
综合 理工 综合 综合 综合 师范 理工
统计各类型的数量,从数量多到少的顺序屏幕输出类型及对应数量,以英文冒号分隔,每个类型一行,输出参考格式如下:
综合:4
理工:2
师范:1
代码
txt = input("请输入类型序列: ")
t=txt.split()
d = {}
for i in range(len(t)):
d[t[i]]=d.get(t[i],0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 按照数量排序
for k in ls:
print("{}:{}".format(k[0], k[1]))
6、考生文件夹下存在2个Python源文件和3个文本文件,分别对应两个问题,请按照文件内说明修改代码,实现以下功能:
《论语》是儒家学派的经典著作之一,主要记录了孔子及其弟子言行。这里给出了一个网络版本的《论语》,文件名称为“论语.txt”,其内容采用逐句“原文”与逐句“注释”相结合的形式组织,通过【原文】标记《论语》原文内容,通过【注释】标记《论语》注释内容,具体文件格式框架请参考“论语.txt”文件。
问题1(10分):在PY301-1.py文件中修改代码,提取“论语.txt”文件中的原文内容,输出保存到考生文件夹下,文件名为“论语-原文.txt”。具体要求:仅保留“论语.txt”文件中所有【原文】标签下面的内容,不保留标签,并去掉每行行首空格及行尾空格,无空行。原文小括号及内部数字是源文件中注释项的标记,请保留。示例输出文件格式请参考“论语-原文-输出示例.txt”文件。注意:示例输出文件帮助考生了解输出格式,不作它用。
问题2(10分):在PY301-2.py文件中修改代码,对“论语-原文.txt”或“论语.txt”文件进一步提纯,去掉每行文字中所有小括号及内部数字,保存为“论文-提纯原文.txt”文件。示例输出文件格式请参考“论语-提纯原文-输出示例.txt”文件。注意:示例输出文件帮助考生了解输出格式,不作它用。
问题一代码
fi = open("论语.txt", 'r')
fo = open("论语-原文.txt", 'w')
flag = False
for line in fi:
if '【原文】' in line:
flag = True
continue
if '【注释】' in line:
flag = False
line = line.strip(" \n")
if flag == True:
if line:
fo.write(line+'\n')
fi.close()
fo.close()
问题二代码
fi = open("论语-原文.txt", 'r')
fo = open("论语-提纯原文.txt", 'w')
for line in fi:
for i in range(23):
line=line.replace('('+str(i)+')','')
fo.write(line)
fi.close()
fo.close()
真题4
1、考生文件夹下存在一个文件PY101.py,请写代码替换横线,不修改其他代码,实现以下功能:
键盘输入字符串s,按要求把s输出到屏幕,格式要求:宽度为20个字符,等号字符=填充,居中对齐。如果输入字符串超过20位,则全部输出。
例如:键盘输入字符串s为"PYTHON",屏幕输出=PYTHON=
代码
s = input("请输入一个字符串:")
print("{:=^20}".format(s))
2、考生文件夹下存在一个文件PY102.py,请写代码替换横线,不修改其他代码,实现以下功能:
根据斐波那契数列的定义,F(0)=0,F(1)=1,F(n)=F(n-1)+F(n-2)(n>=2),输出不大于100的序列元素。
例如:屏幕输出实例为:
0,1,1,2,3,…(略)
代码
a, b = 0, 1
while a<=100:
print(a, end=',')
a, b = b,a+b
3、考生文件夹下存在一个文件PY103.py,请写代码替换横线,不修改其他代码,实现以下功能:
键盘输入一句话,用jieba分词后,将切分的词组按照在原话中逆序输出到屏幕上,词组中间没有空格。示例如下:
输入:
我爱妈妈
输出:
妈妈爱我
代码
import jieba
txt = input("请输入一段中文文本:")
ls=jieba.lcut(txt)
for i in ls[::-1]:
print(i,end='')
4、考生文件夹下存在一个文件PY201.py,请写代码替换横线,不修改其他代码,实现以下功能:
使用turtle库的turtle.fd()函数和turtle.seth()函数绘制一个等边三角形,边长为200像素,效果如下图所示。
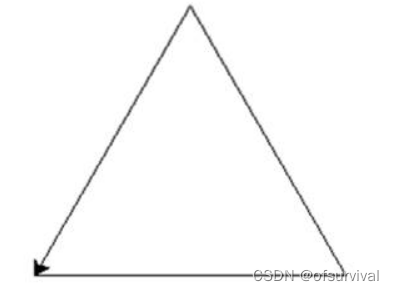
代码
import turtle as t
for i in range(3):
t.seth(i*120)
t.fd(200)
5、考生文件夹下存在一个文件PY202.py,该文件是本题目的代码提示框架,其中代码可以任意修改。请在该文件中编写代码,以实现如下功能:
键盘输入小明学习的课程名称及考分等信息,信息间采用空格分隔,每个课程一行,空行回车结束录入,示例格式如下:
数学 90
语文 95
英语 86
物理 84
生物 87
屏幕输出得分最高的课程及成绩,得分最低的课程及成绩,以及平均分(保留2位小数)。
注意,其中逗号为英文逗号,格式如下:
最高分课程是语文 95,最低分课程是物理 84,平均分是88.40
代码
data = input() # 课程名 考分
ls = data.split()
min_score=int(ls[1])
min_name = ls[0]
max_score=int(ls[1])
max_name = ls[0]
n = 0
sum = 0
while data:
n+=1
lt = data.split()
if min_score > int(lt[1]):
min_score = int(lt[1])
min_name = lt[0]
if max_score < int(lt[1]):
max_score = int(lt[1])
max_name = lt[0]
sum+=int(lt[1])
data = input()
avg = sum/n
print("最高分课程是{} {}, 最低分课程是{} {}, 平均分是{:.2f}".format(max_name,max_score,min_name,min_score,avg))
6、考生文件夹下存在三个Python源文件,分别对应三个问题,请按照文件内说明修改代码,实现以下功能:
二千多年前希腊的天文学家希巴克斯命名十二星座,它们是水瓶座、双鱼座、白羊座、金牛座、双子座、巨蟹座、狮子座、处女座、天秤座、天蝎座、射手座、摩羯座。给出一个CSV文件(PY301-SunSign.csv),内容示例如下:
序号,星座,开始月日,结束月日,Unicode
1,水瓶座,120,218,9810
2,双色座,219,320,9811
3,白羊座,321,419,9800
4,金牛座,420,520,9801
5,双子座,521,621,9802
…(略)
以第1行为例,120表示1月20日,218表示2月18日,9810是Unicode码。
问题1(5分):在PY301-1.py文件中修改代码,读入CSV文件中数据,获得用户输入。根据用户输入的星座名称,输出此星座的出生日期范围。
参考输入和输出示例格式如下:
请输入星座中文名称(例如,双子座):双子座
双子座的生日位于521-621之间
问题2(10分):在PY301-2.py文件中修改代码,读入CSV文件中数据,获得用户输入。用户键盘输入一组范围是1-12的整数作为序号,序号间采用空格分隔,以回车结束。屏幕输出这些序号对应的星座的名称、字符编码以及出生日期范围,每个星座的信息一行。本次屏幕显示完成后,重新回到输入序号的状态。
参考输入和输出示例格式如下:
请输入星座序号(例如,5):5 10
双子座(9802)的生日是5月21日至6月21日之间
天蝎座(9807)的生日是10月24日至11月22日之间
请输入星座序号(例如,5):
问题3(5分):在问题2的基础上,在PY301-3.py文件中修改代码,对键盘输入的每个序号做合法性处理。如果输入的数字不合法,请输出“输入星座编号有误!”,継纹输出后续信息,然后重新回到输入序号的状态。
参考输入和输出示例格式如下:
请输入星座序号(例如,5):5 14 11
双子座(9802)的生日是5月21日至6月21日之间
输入星座序号有误!
射手座(9808)的生日是11月23日至12月21日之间
请输入星座序号(例如,5):
问题一代码
f = open('PY301-SunSign.csv','r')
ls = []
s = input('请输入星座中文名称(例如,双子座):')
for line in f.readlines():
ls = line.strip('\n').split(',')
if ls[1] == s:
print("{}的生日位于{}-{}之间".format(ls[1],ls[2],ls[3]))
f.close()
问题二代码
f = open('PY301-SunSign.csv','r')
ls = []
ls = f.readlines()
while True:
s = input('请输入星座序号(例如,5):')
for i in s.split():
for line in ls:
lt = line.strip('\n').split(',')
if i == lt[0]:
print("{}({})的生日是{}月{}日至{}月{}日之间".format(lt[1],lt[4],lt[2][:-2],lt[2][-2:],lt[3][:-2],lt[3][-2:]))
f.close()
问题三代码
f = open('PY301-SunSign.csv','r')
ls = []
ls = f.readlines()
while True:
s = input('请输入星座序号(例如,5):')
for i in s.split():
if 0<int(i)<13:
flag = True
else:
flag = False
for line in ls:
lt = line.strip('\n').split(',')
if i == lt[0]:
print("{}({})的生日是{}月{}日至{}月{}日之间".format(lt[1],lt[4],lt[2][:-2],lt[2][-2:],lt[3][:-2],lt[3][-2:]))
break
if flag == False:
print("输入星座序号有误!")
f.close()
真题来源:小黑课堂计算机二级python题库