Raft 与 Multi Raft
PingCAP TiKV课程笔记课程链接
数据是以region(也叫Raft Group)为单位进行存储的。一个region默认会有3个副本,存在不同的TiKV Node上。副本中的一个节点为leader。所有的读写流量只走leader,leader定期向follower发送心跳,进行日志复制。
Region内部是一个kv map,按照key排序存储。相邻的region数据紧密相连。一个region的最大size为96M,一旦超出就自动存入新的region。
多个region/raft group就叫multi-raft
Raft 回顾
日志复制:
1. propose: 收到请求, 生成raft log (包含了请求内容以及编号(region#, log_index节点内部的日志编号))
2. append: 将日志存入本地的rocksdb中(专门存raft log),持久化raft log。
3. replicate:向其他follower传播,follower收到后也写入自己本地的rocksdb raft中持久化。
4. 当大多数节点都返回append成功的消息给leader后,leader就发出commited 命令,并且apply到真正的数据库上(把日志取出来,运用,即写到rocksdb kv中)。其他follower在收到commit命令后也将日志转移到自己的apply pool,之后持久化到rocksdb kv.
Leader选举
时间在raft看来是一段一段的term。term内是一段稳定的状态。
当election timeout了,进入选举。
选举成功,变为leader,发送heartbeat timeout。
选举的活锁问题
资料参考:分布式一致性协议之Raft的实现详解-腾讯云开发者社区-腾讯云
leader被选出来,某个其他节点又启动一轮选举
选主过程中,可能出现多个节点同时发起选主的情况,这样导致选票瓜分,无法选出主,在下一轮选举中依旧如此,导致系统状态无法往前推进。Raft通过随机超时解决这个“活锁”问题。
安全性
-
Raft协议中有哪些重要的安全性质?如何保证这些安全性质?
-
选举安全性: Election Safety
-
Follower在一个任期内只投一次票, 只能投任期比自己新,日志至少要和自己一样的candidate
-
必须获得超半数投票成为leader
-
-
日志 Append-Only
-
只有leader有 append entries请求发送权力
-
Leader只可追加log,不可覆盖log
-
一致性检查:每条log包含(term, index)
-
-
日志匹配特性 Log Matching
-
保证日志唯一性,
-
两个不同机器,若分别有(term, index)相同的log,则log内容必须相同
-
两个不同机器,若分别有(term, index)相同的log,该log之前的所有entries也要相同
-
-
Leader 完备性 Leader Completeness
-
Leader必须具备最新提交log
-
Candidate竞选投票时会携带最新提交日志,Follower会用自己的日志和Candidate做比较,如果Follower的日志比Candidate还新,那么拒绝这次投票
-
新:
-
如果Term不同,选择Term值最大的
-
如果Term相同,选择Index值最大的
-
-
-
状态及安全性 State Machines Safety
-
一个log被复制到超半数节点才算提交成功
-
Leader只能提交当前term的日志
-
-
成员变更
成员变更解释
任何一个节点收到了成员变更配置 ConfChange,只要把它持久化了,就可以直接生效,无需和传统日志一样需要先 commit,然后等待 apply 时应用。
保证变更前后的 quorum 存在交集,即保证了整个集群自始至终只会存在一个 leader,以此来保证正确性。Joint Consensus 通过一个中间阶段保证每一步变更的 quorum 比如存在交集
一次读写请求怎么完成
数据的写入
raftstore pool是线程池,接受用户写请求,序列化为日志之后持久化到rocksdb raft,replicate到其他节点,log转移到apply pool(也是一个线程池),最终修改rocksdb kv里的实际内容。
写入成功不代表能够读到,原因在于apply操作的滞后性。
数据的读取
复习快照隔离级别:保证读请求不会出现幻读,并发写请求只有一个生效。
有两个问题:
1. 数据一致性:考虑apply滞后
解决方法: ReadIndex Read, 先记录最近一次提交的编号(ReadIndex),再等待最近一次apply(ApplyIndex)与ReadIndex相等。
2.读取过程中成员变更:考虑leader宕机/成员变更
解决方法:在使用ApplyIndex读取前要先发一次心跳,如果仍然是leader就放心读
改进2的解决方法,避免多次网络操作询问自己是否是leader:
Lease Read: 通过计算绝对不可能变更leader的时间段(上次心跳到不发心跳到election timeout)
Follower Read 分摊leader压力:
follower接到请求,问leader最新commit的log编号CommitIndex,知道了leader提交到哪了。看自己本地的ApplyIndex,如果没赶上就等,直到赶上leader的复制进度CommitIndex。好处是有可能leader提交比follower慢呢,这样follower read就能快点拿到读取结果。
范围搜索
Multi-Raft的调度
相关资料:
思路很清晰的博客系列,以后多多阅读大佬的blog
很好的学习资料: TiKV源码解析multi raft部分
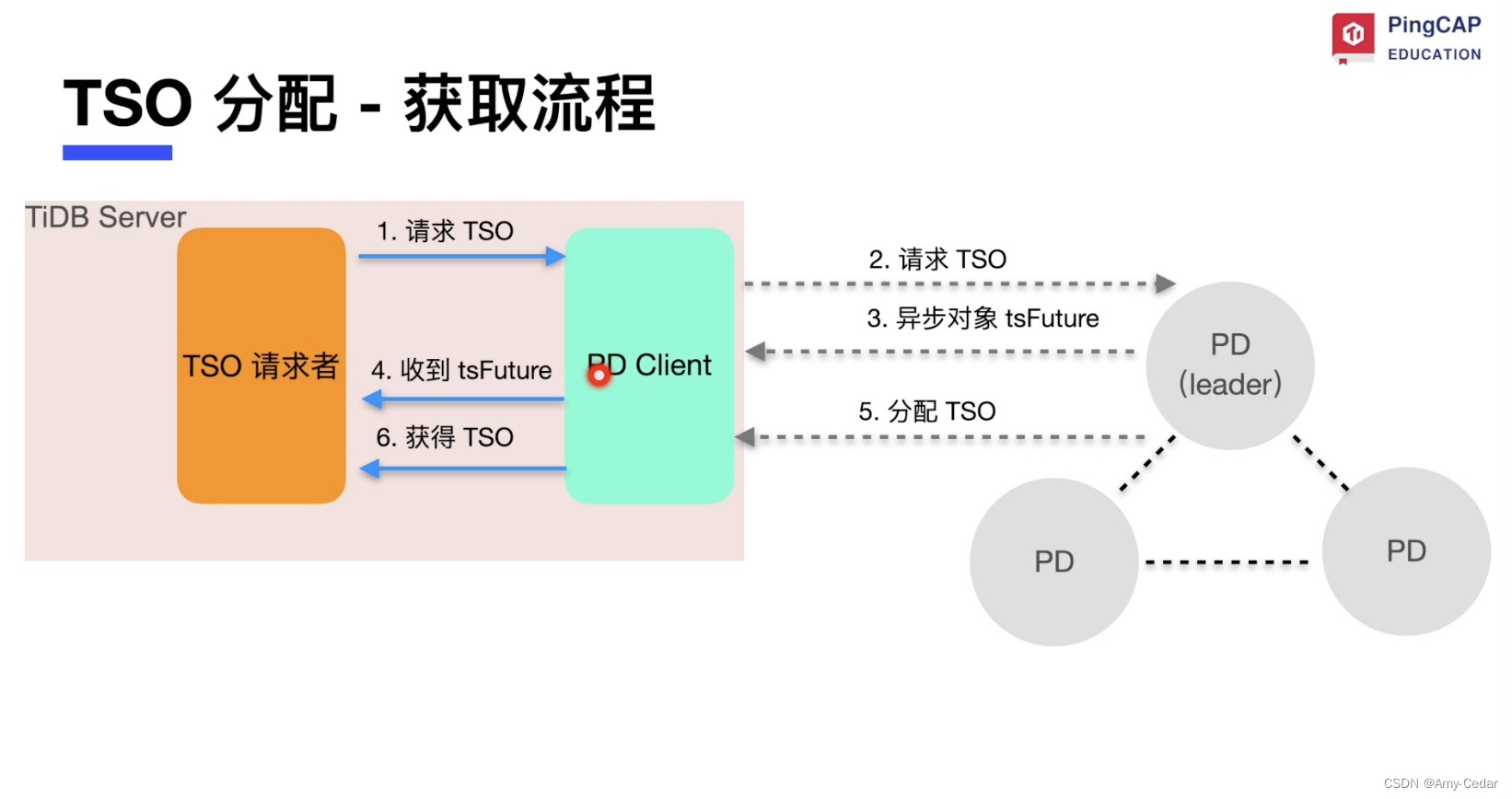
Place Driver
PD的作用是region管理(负责数据副本在region中的调度)和TSO全局时钟的分配。
1. 路由功能:负责查找元数据
2. 给大量高并发的请求分配TSO全局时钟,并保证单调递增
3. 收集集群信息(比如检查热点进行region迁移)
4. 提供label功能支持高可用
数据分区算法:hash/range
Region的定义,这里使用TiKV为例:
message Region {
optional uint64 id = 1 [(gogoproto.nullable) = false];
optional bytes start_key = 2;
optional bytes end_key = 3;
optional RegionEpoch region_epoch = 4;
repeated Peer peers = 5;
}
message RegionEpoch {
optional uint64 conf_ver = 1 [(gogoproto.nullable) = false];
optional uint64 version = 2 [(gogoproto.nullable) = false];
}
message Peer {
optional uint64 id = 1 [(gogoproto.nullable) = false];
optional uint64 store_id = 2 [(gogoproto.nullable) = false];
}比较重要的Raft类型
PeerState
message RaftLocalState {
optional eraftpb.HardState hard_state = 1;
optional uint64 last_index = 2;
}
message RaftApplyState {
optional uint64 applied_index = 1;
optional RaftTruncatedState truncated_state = 2;
}
enum PeerState {
Normal = 0;
Applying = 1;
Tombstone = 2;
}
message RegionLocalState {
optional PeerState state = 1;
optional metapb.Region region = 2;
}Raft硬状态:1. 当前任期号 2. 已投票给候选人ID 3. 日志索引
LocalState last index指最后一个Log Index
SnapShot:
pub enum SnapState {
Relax,
Generating(Receiver<Snapshot>),
Applying(Arc<AtomicUsize>),
ApplyAborted,
}在Raft算法中,快照(Snapshot)的处理是对系统性能和响应时间非常重要的一个方面。因为快照操作涉及到将当前状态机的状态持久化存储,这可能包括大量的数据,因此通常是耗时的操作。为了确保快照处理不会阻塞整个Raft线程,需要采用一些策略来优化这个过程。
`PeerStorage`的快照状态管理(`SnapState`枚举)就是这种优化的一个例子。这里的策略包括:
- **Relax**: 表示没有快照操作正在进行,系统处于正常状态。
- **Generating(Receiver<Snapshot>)**: 表示快照正在生成中。此状态使用`Receiver<Snapshot>`来异步接收生成的快照数据。这允许快照生成过程在后台进行,不会阻塞主Raft进程。
- **Applying(Arc<AtomicUsize>)**: 表示快照正在应用中。快照应用是一个将快照数据加载到状态机中的过程,这同样可能是一个耗时操作。通过使用`Arc<AtomicUsize>`,可以在不同线程中安全地共享和管理快照的应用状态,同时允许这个过程异步执行。
- **ApplyAborted**: 表示快照应用过程被中断或放弃。这可能发生在系统决定放弃当前的快照应用过程,可能是因为接收到了一个更新的快照,或者因为其他原因需要停止当前的快照应用。
Peer
Peer里完成propose, ready等操作
command类型:
1. 只读,如果leader在lease有效期内,就能直接提供local read。
2. transfer read: 是否follower有足够新的log
3. Change Peer调用RawNode
propose之前会将callback(回调)存到PendingCmd里面,以便后续完成propose返回客户端
handle_raft_ready:负责将entries写入storage,发送messages, apply committed_entries以及advance
Multi Raft
对于一个store需要管理多个region副本
region_peers: HashMap<u64, Peer>
RawNode tick函数驱动Raft,需要注册一个Raft Tick
tick回调回进行 on_raft_ready的处理:
- Store 会遍历所有的 ready Peers,调用 handle_raft_ready_append,我们会使用一个 WriteBatch 来处理所有的 ready append 数据,同时保存相关的结果。
- 如果 WriteBatch 成功,会依次调用 post_raft_ready_append,这里主要用来处理Follower 的消息发送(Leader 的消息已经在 handle_raft_ready_append 里面完成)。
- 然后,Store 会依次调用 handle_raft_ready_apply,apply 相关 committed entries,然后调用 on_ready_result 处理最后的结果。
Server:
对网络IO的处理,TiKV网络层,封装 message (header + body),编码
流程和socket网络接口有点像:
1. bind 端口,生成一个用于交互的对象
2. 使用TcpStream和客户端交互
3. TcpStream处理回调
对于受到的message,都有对应的处理线程
模模糊糊理解了一些!继续学习






![[音视频学习笔记]六、自制音视频播放器Part1 -新版本ffmpeg,Qt +VS2022,都什么年代了还在写传统播放器?](https://img-blog.csdnimg.cn/direct/907f577e470b46b4ac076d71cea7dbee.png)