摘要:
1、预处理:颜色标记、词汇提取、字符转换、合约之间的继承关系的提取
2、 使用融合模型进行特征提取(BERT、CNN、BiLSTM)
3、使用node2vec随机游走算法,将合约之间的继承关系作为输入得到合约关系的特征向量。
4、使用特征向量进行缺陷分类
1、研究内容
1.1 多特征融合
将智能合约的语义、视觉和结构多类特征进行融合
多特征融合是一种将不同来源或不同表示的多个特征信息进行组合和整合的方法,比较常见的方法有特征加权、注意力机制以及特征拼接。
- 特征加权是按照不同的权重进行加权求和
- 注意力机制是动态地基于不同的特征或上下文不同的权重或者关注度
- 特征拼接是将多个特征在通道维度上连接在一起,形成一个更高维度的特征表示
- 将自然语言处理和图神经网络的方法结合生成更高质量的节点特征
2、研究方法
基于 BERT、CNN 及 LSTM 构建模型,提出利用语义、视觉和结构内部特征以及继承关系外部特征进行Solidity智能合约缺陷检测的方法。
本文主要是在特征提取阶段提取了包括合约继承结构在内的四种信息:
- 颜色标准
- 词汇提取
- 字符转换
- 特征向量
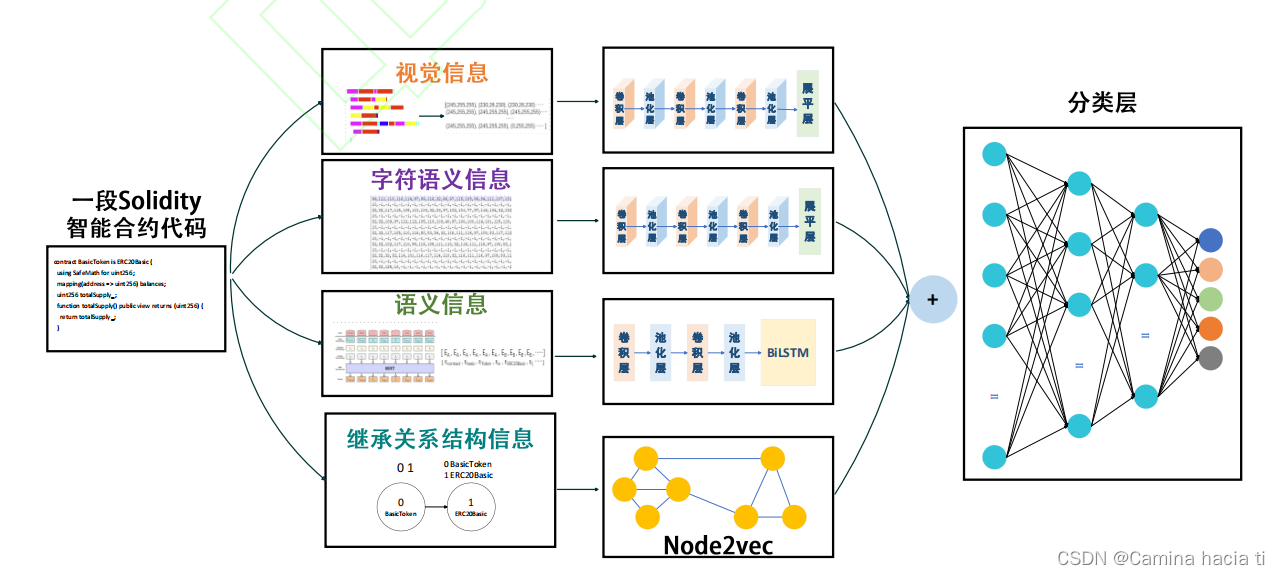
2.1 视觉信息提取
通过表示代码图像可以直观获取视觉信息,比如一些关键字的使用或者各类函数的调用。研究学者将十六进制从字节码映射到RGB颜色码[1]。文章将代码的关键字以及其它部分通过RGB颜色标记转为RGB矩阵并保存,作为CNN的输入。
根据VSCODE软件的显示颜色,将solidity语言分为括号、关键字、计算符、标识符、货币单位、注释以及其它代码,进行颜色标记,截取结果得到代码彩色图像。并进行压缩(128,128)通道3的RGB矩阵。
[1]Hsien-De Huang T T, Kao H Y. R2-d2: Color-inspired co-nvolutional neural network (cnn)-based android malware d-etections[C]//2018 IEEE international conference on big da-ta (big data). IEEE, 2018: 2633-2642.
我们使用CNN(可以用来处理具有类似网格结构的数据的神经网络)来提取特征,用于从输入数据中提取局部特征。
卷积操作:(另外看)
特征图X(h,w,c),h为高度,W表示宽度,C表示通道数。
卷积核 W(FH,FW,c,k),其中 FH 表示核的高度,FW 表示核的宽度,c 表示输入通道数,k 表示输出通道数。
核内的空间位置由 m 和 n 表示,分别对应于核的高度和宽度索引。
输入层为(128,128,3)的RGB矩阵,卷积层拥有64个大小为3的过滤器,最大池化为3,获得64单元的特征信息。
2.2 语义信息提取
使用文本特征对其修改可以对图像视觉有一定的改善作用。使用自然语言处理来获得语义信息。使用BERT将源代码映射到词向量,并对每个代码词进行划分。
[21] Wang J, Dong Y. Improve Visual Question Answering Ba-sed On Text Feature Extraction[C]//Journal of Physics: Co-nference Series. IOP Publishing, 2021, 1856(1): 012025.
[22] Jiang Zhou, Jiang Murong, Zhao Chunna, et al. Improve Image Question and Answer Accuracy by Using Text Feature Enhanceme-nt and Attention Mechanism[J]. 2019.
(江邹, 蒋慕蓉, 赵春娜, 等. 利用文本特征增强与注意力机制提高图像问答准确率[J]. 计算机科学与应用, 2019, 9: 2403.)
文中选择利用 CNN 将语义信息进行识别和提取,得到关键特征的短序列,再放入BiLSTM 模型中获得所需要的 64 单位语义特征输出。此处选用的 CNN 是由Relu 作为激活函数的两个卷积层和池化层组成。
2.3 字符语义信息提取
源代码的字符语义信息是其基本表达含义的方式,通过获取 Solidity 源代码的另一种语义特征能够在漏洞检测方面有帮助。将每个合约转换为字符型矩阵,具体来说就是将合约的每个字符转换为便于识别的 ASCII 码,在空余的部分利用“-1”值进行填充,以保证每个字符矩阵的大小都统一。
最终使用(100,300,1)作为矩阵的大小。
为了从较大的矩阵中提取到更有效的特征,CNN 的卷积层与池化层选用了三对,其中激活函数仍旧选用Relu,在最后将卷积层的输出进行展平以得到所需要的 64 单位的一维数组
2.4 结构信息提取
智能合约代码树CCTree的提出。
[26] Huang Y, Zhang T, Fang S, et al. Deep Smart Contract I-ntent Detection[J]. arXiv preprint arXiv:2211.10724, 2022.
CCTree 通过拆分和重组智能合约源代码生成的树状图数据结构。
- 第一层为根层,代表整个合约内容;
- 第二层为合约层,代表智能合约中的合约类,包括合约、接口、库和抽象合约类的类型;
- 第三层为叶子节点,存储合约类中的函数、事件、修饰符和构造函数等关键字的代码片段。
在 CCTree的第二层合约层中,合约之间会有一个或多个继承关系,合约的继承可能会导致缺陷的出现,因此需要提取合约之间的继承信息。

提取继承关系具体做法如下: - 提取关键词Is. is前表示继承合约,后表示被继承合约。
- 同一个地址中的每个合约都当作图的节点,而合约之间的继承关系作为图的边,由继承合约指向被继承合约,将它们记录在文件中。
使用到逻辑回归模型
结构信息由节点以及其边的图结构组成,在获得智能合约的多个图结构信息以后,将它们放入 node2vec 模型中进行处理。具有直接链接关系的两个节点,即距离近的节点具有相似的嵌入向量,这样可以让合约之间的继承关系更加紧密,并获得更高质量的向量值。每个合约节点在经过 embedding 后都会得到一个 64 单位的向量输出
3、检测模型

四类64单元进行拼接得到256单元特征,进入全连接层降为64维,再进入全连接层以及dropout层组成的分类器(50%),激活函数为softmax
4、实验
操作系统为 64 位Windows 10,CPU 是因特尔酷睿 i7-10700k,GPU为 RTX 5000,内存大小 32GB。开发和运行环境为 Python 3.8,开发工具使用的是Pycharm 2018.2。
4.1 数据集
从XBlock获取源码结合BSCSCS(区块链智能合约安全检测平台)构建的。
数据集地址
从中选取3680份代码,1680有缺陷,2000无缺陷。
为防止类别不平衡的问题出现,将数值溢出漏洞类别剔除,占有比例低的类别进行合并作为新的漏洞类别,根据数据集新分类的 4 类缺陷名称见下表。

V:视觉特征
C:字符语义特征
S:语义特性
T:结构特征
4.2 结果分析
4.2.1 Q1
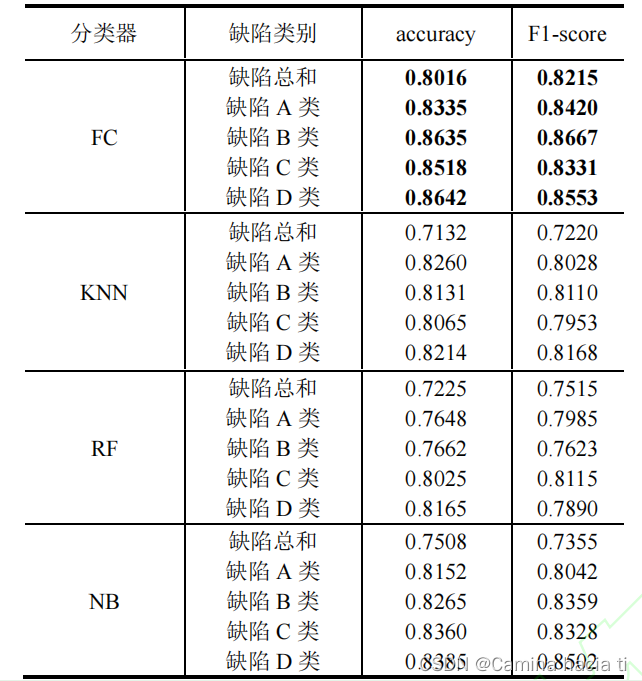
与现有分类器进行对比,FC分类器(基于完全连接层分类器)效果较好,选择它作为后续缺陷检测实验的分类器。
4.2.2 Q2
分别融合多类特征:
VS视觉语义融合
VT视觉结构融合
VC视觉字符语义融合
ST语义结构融合
CT字符语义结构融合
VCT视觉字符语义结构融合
VST视觉语义结构融合
结果如下:

- VS与VST大致持平,较优秀
- CT略低于VS和VST
- ST和VC水平较差
- 其它模型性能不好
从模型性能下降的幅度推断,字符语义特征会略微降低模型的性能,语义特征对缺陷检测的贡献更大,推测原因是语义特征更能最大限度地保留智能合约的布局及缺陷信息,进而影响模型缺陷检测的性能。从整体上来看,视觉语义特征融合而成的 VS 拥有更优秀的检测能力,值得进一步研究和应用。
4.2.3 Q3
与现有工具比较:L-GCN模型和RFR模型

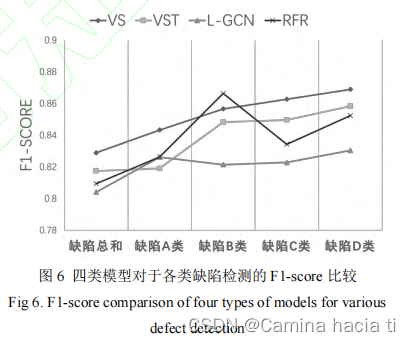
VS 的准确率和 F1 分数都优于其余三种模型,整体上看本文的模型平均提升了 3%~12%。
![[论文笔记] ChatDev:Communicative Agents for Software Development](https://img-blog.csdnimg.cn/img_convert/9b6a113ee0043b16bdde0622000a4bf1.png)







![[flask] flask的基本介绍、flask快速搭建项目并运行](https://img-blog.csdnimg.cn/direct/d6f7b3304e684a45aa14e1b68f15917b.png)