开发的时候第一步就是建表,在创建表的时候,我们需要定义表的字段,每个字段都有一些属性,比如说是否为空,是否允许有默认值,是不是逐渐等。
这些约束字段的属性,可以让字段的值更符合我们的预期,也会为以后的数据查询和更新提供便利。
比如说,我们在定义字段的时候添加了默认值,那在插入数据的时候,如果我们没有主动指定这个字段的值(比如 Java 程序中),数据库就会使用默认值帮我们自动填充。
像在技术派项目中的文章详情表,我们为 id 字段设置了 NOT NULL、AUTO_INCREMENT、COMMENT 等属性。

那接下来,就来一起看看 MySQL 字段的常用属性都有哪些吧。
默认值
默认值(DEFAULT)是指在插入数据的时候,如果没有指定这个字段的值,那就会使用默认值。
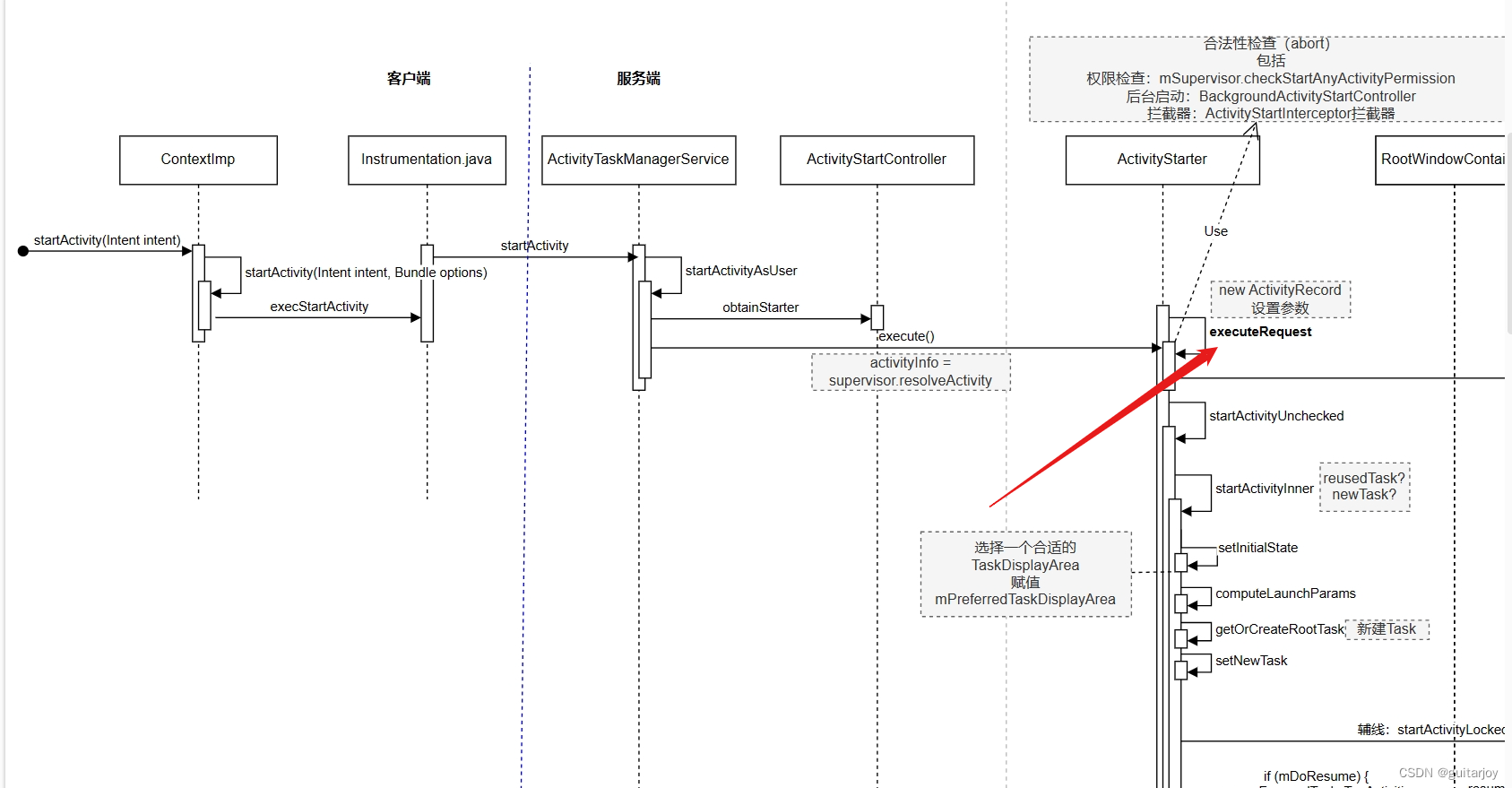
我们创建这样一张表,包含了 varchar、int、datetime 等字段类型,每个字段都设置了默认值。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT '张三',
`age` int(11) DEFAULT 18,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;在插入数据的时候,如果没有指定 name、age、create_time 字段的值,那就会使用默认值。
INSERT INTO `user` (`id`) VALUES (1);
可以看到,插入数据的时候,我们只指定了 id 字段的值,其他字段都省略了,但 MySQL 自动帮我们填充了默认值。
- DEFAULT '张三':指定了 name 字段的默认值为“张三”。
- DEFAULT 18:指定了 age 字段的默认值为 18。
- DEFAULT CURRENT_TIMESTAMP:指定了 create_time 字段的默认值为当前时间。
那假如我们没有指定默认值,又没有主动插入数据,那这个字段的值会是什么呢?
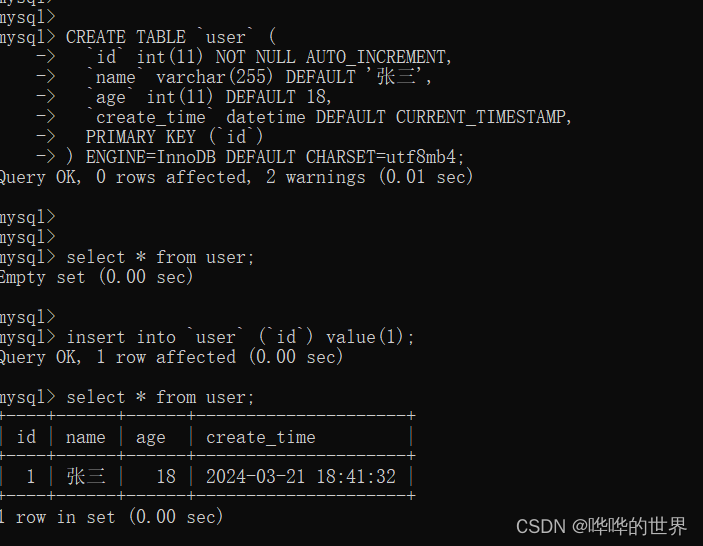
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255),
`age` int(11),
`create_time` datetime,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;在插入数据的时候,我们没有指定 name、age、create_time 字段的值,也没有设置默认值。
INSERT INTO `user` (`id`) VALUES (1);可以看到,此时,MySQL 帮我们填充的值是 NULL。

这就是为什么阿里巴巴开发规约要求我们,在POJO中,要使用包装类型,而不是基本数据类型,因为数据库的查询结构可能是 null,如果使用基本数据类型的画,因为要自动拆箱,会抛出NPE异常。
当然了,DEFAULT 也不能乱用,要根据业务需求来设置默认值,比如说,我们在创建用户表的时候,就不应该为 name 字段设置默认值,因为这样的话,如果用户没有填写名字,MySQL 就会默认填充“张三”,这显然是不合理的。
我们要尽早提示用户填写名字,而不是用默认值填充。
但对于 create_time 字段,我们就可以设置默认值为 CURRENT_TIMESTAMP,这样的话,MySQL 就会自动帮我们填充当前时间,Java 程序就不需要在插入数据的时候,手动填充时间了。
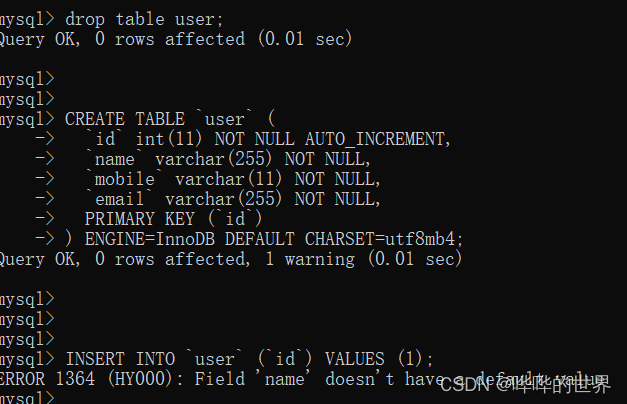
是否允许为空
有时候,我们会希望某个字段的值不能为空,比如说,用户名、手机号、邮箱等,这些字段的值都是必填的。
那我们在创建表的时候,就会明确指定这些字段是 NOT NULL 的。
这样在插入数据的时候,如果我们没有指定 name、mobile、email 字段的值,那 MySQL 就会报错。
虽然我们也会在 Java 程序中对这些字段进行校验,但在数据库层面,也要对字段的值进行约束,这样可以更好地保证数据的完整性。
主键
主键(PRIMARY KEY)是用来唯一标识一条记录的,一个表中只能有一个主键,主键的值不能重复,也不能为 NULL。
主键的指定方式有两种,一种是在字段定义的时候直接跟上 PRIMARY KEY,另一种是在所有字段定义完成后,再通过 PRIMARY KEY(字段)这种方式指定。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
`name` varchar(255) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;或者
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;第二种方式在复合主键(由两个或更多的字段组合而成)的时候会更加方便,比如说,我们要为学生课程表设置复合主键,就可以这样定义。
CREATE TABLE `student_course` (
`student_id` int(11) NOT NULL,
`course_id` int(11) NOT NULL,
created_time datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`student_id`, `course_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;通过 PRIMARY KEY 关键字后面跟上括号内的多个字段名来实现。
不过,复合主键会创建更复杂的索引,可能会对插入、更新、删除等操作的性能产生影响,另外,在执行联合查询
的时候,因为需要处理复合主键的多个字段,也会使 SQL 查询语句变得复杂。
所以在实际开发中,复合主键的使用频率并不高。
自增
自增(AUTO_INCREMENT)是指在插入数据的时候,如果没有指定这个字段的值,那 MySQL 就会自动帮我们填充一个递增的值。
一般用于类型为整型的主键字段,比如说 int 或 bigint。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;我们来插入几条数据,看看 id 字段的值是怎么填充的。
INSERT INTO `user` (`name`) VALUES ('张三');
INSERT INTO `user` (`name`) VALUES ('张四');
INSERT INTO `user` (`name`) VALUES ('张五');再删除一条数据后插入:
DELETE FROM `user` WHERE `id` = 2;
INSERT INTO `user` (`name`) VALUES ('张六');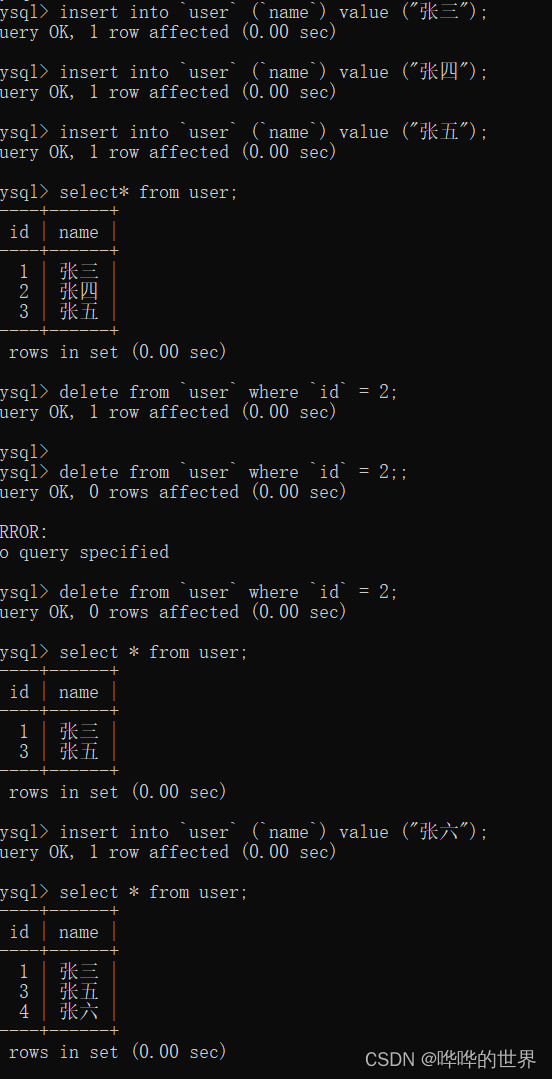
可以看到,每次插入数据的时候,id 都会在以前的最大值上加 1。
注释
注释(COMMENT)是指在字段定义的时候,可以添加一些描述性的文字,和 Java 中中的双斜杠注释类似。
语法也非常简单,就是在字段定义的后面跟上 COMMENT '注释内容'(建议单引号)。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT '姓名',
`age` int(11) NOT NULL COMMENT '年龄',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;这样的话,我们在查看表结构的时候,就可以看到每个字段的注释了。
SHOW FULL COLUMNS FROM `user`;
注释的作用是让其他人更容易理解这个字段的含义,没啥好说的。
UNIQUE
UNIQUE可以确保一列或几列的组合值在整张表中是唯一的。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`mobile` varchar(11) UNIQUE,
`email` varchar(255),
PRIMARY KEY (`id`)
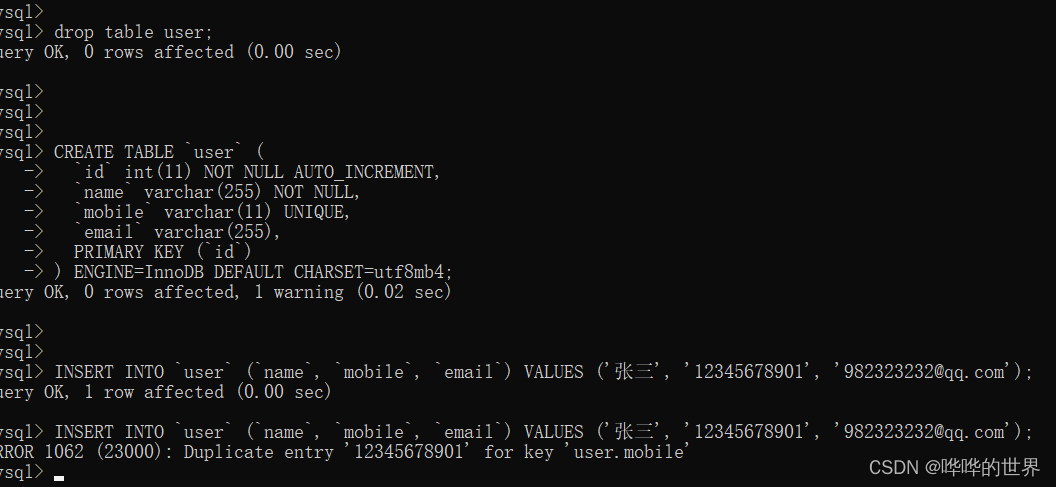
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;这样的话,我们在插入数据的时候,如果 mobile 的值已经存在,MySQL 就会报错。
INSERT INTO `user` (`name`, `mobile`, `email`) VALUES ('张三', '12345678901', '982323232@qq.com');
INSERT INTO `user` (`name`, `mobile`, `email`) VALUES ('张四', '12345678901', 'www.huahua@169.com');等于说在数据库层面就对字段的值进行了唯一性约束,虽然如果一个字段不允许重复的话,在 Java 程序中也会先进行校验。
当然,也可以对过个字段进行唯一性约束,语法和复合主键类似,用 UNIQUE 关键字后面跟上括号内的多个字段名来实现。比如说,我们要为学生课程表设置复合唯一性约束,就可以这样定义。
CREATE TABLE `student_course` (
`student_id` int(11) NOT NULL,
`course_id` int(11) NOT NULL,
created_time datetime DEFAULT CURRENT_TIMESTAMP,
UNIQUE (`student_id`, `course_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;也可以为 UNIQUE 约束指定别名,比如说,我们 mobile 字段设置唯一性约束,就可以这样定义。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`mobile` varchar(11),
`email` varchar(255),
PRIMARY KEY (`id`),
UNIQUE `mobile_unique` (`mobile`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;UNIQUE 约束既可以保证数据的唯一性,也可以提高数据检索的效率,因为它会为对应的列创建一个唯一索引。
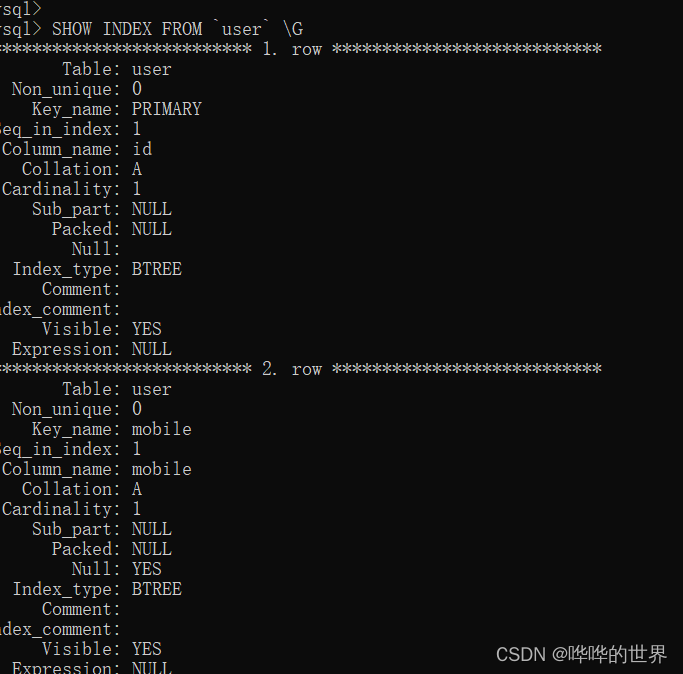
可以通过 SHOW INDEX FROM 表名 来查看索引信息。查看 Non_unique 列的值,可以确认是否为唯一索引(0 表示唯一,1 表示非唯一)
SHOW INDEX FROM `user` \G的确,我们可以看到 mobile 字段的 Non_unique 是 0,也就是唯一索引,索引类型是 BTREE,这是一种高效的索引结构。
不过,与 PRIMARY KEY 不同,UNIQUE 约束允许有 NULL 值。我们来测试一下:
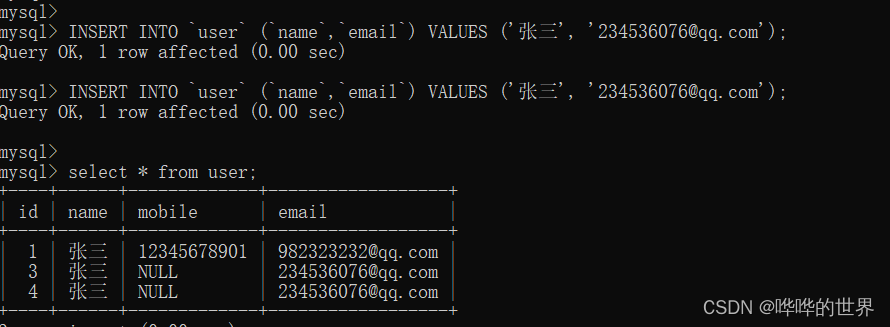
INSERT INTO `user` (`name`,`email`) VALUES ('张三', '234536076@qq.com');
INSERT INTO `user` (`name`,`email`) VALUES ('张三', '234536076@qq.com');我们来看一下结果,果然允许 NULL 值。
既然 UNIQUE 约束是用来保证数据的唯一性的,为什么允许有多个 NULL 值呢?
主要与 NULL 值在 SQL 中的特殊含义有关。在 SQL 中,NULL 代表一个未知值或不存在的值。当我们对数据库设计时使用 UNIQUE 约束时,这个约束确保了所有的非 NULL 值在该列中是唯一的,但是对于 NULL 值的处理则有所不同,因为 NULL 与任何其他值(包括另一个 NULL)都不相等。
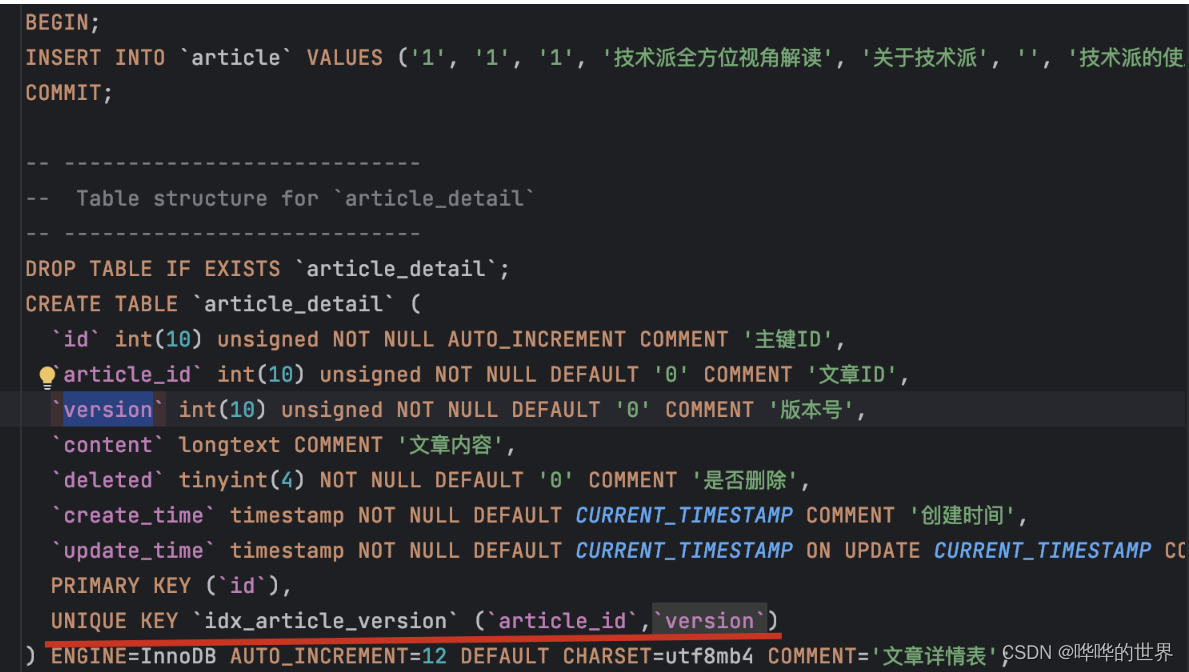
在技术派中的文章详情表,我们为 article_id 和 version 字段设置了唯一性约束,这样的话,就可以保证每篇文章的每个版本都是唯一的。
外键
外键(FOREIGN KEY)是用来建立两个表之间的关联关系的,它指向另一张表的主键。
下面是一个简单的例子,我们创建了两张表,一张是用户表,一张是订单表,用户表的 id 字段是主键,订单表的 user_id 字段是外键,指向用户表的 id 字段。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`mobile` varchar(11) UNIQUE,
`email` varchar(255),
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `order1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`order_no` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
FOREIGN KEY (`user_id`) REFERENCES `user` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;我们先在 user 中插入一条数据:
insert into `user` (`name` , `mobile` ,`email`) values ("张三" , "19203004404" ,"1213232@qq.com");这样的话,我们在插入订单的时候,如果 user_id 指向的用户不存在,MySQL 就会报错。
INSERT INTO `order1` (`user_id`, `order_no`) VALUES (1, '2024020801');
INSERT INTO `order1` (`user_id`, `order_no`) VALUES (2, '2024020802');
可以看到,user_id 为 2 的订单插入失败了,因为 user_id 为 2 的用户不存在。
Cannot add or update a child row: a foreign key constraint fails (itwanger.order, CONSTRAINT order_ibfk_1 FOREIGN KEY (user_id) REFERENCES user (id))
外键约束可以确保数据的完整性,比如说,我们在删除用户的时候,如果用户有订单,就不允许删除。
DELETE FROM `user` WHERE `id` = 1;
外键是 MySQL 中不可或缺的一部分,它通过确保表之间的数据引用完整性,帮助构建结构化和组织良好的数据库模式。正确使用外键不仅可以保证数据的一致性和准确性,还可以提高数据库操作的效率。
ZEROFILL
ZEROFILL 是指在插入数据的时候,如果字段的值小于字段的长度,MySQL 就会在字段的值前面填充 0。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`money` int(11) ZEROFILL,
`father_money` int(11),
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;我们来插入一条数据,看看 id 字段的值是怎么填充的。
INSERT INTO `user` (`money`, `father_money`) VALUES (1, 1);
可以看到,money 字段的值是 00000000001,而 father_money 字段的值是 1。
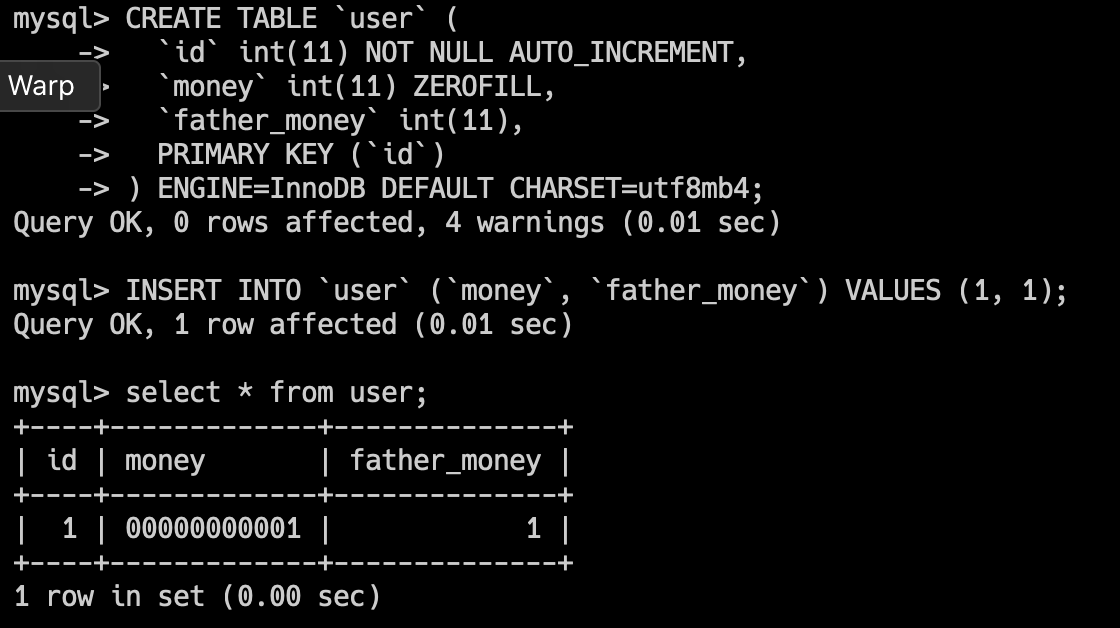
当一个字段被定义为 ZEROFILL 时,MySQL 会自动为该字段的值填充前导零,直到达到该字段定义的宽度。这个属性常常与数值类型的字段一起使用,以确保显示的数值具有固定的宽度,这对于报表和数据展示的格式化非常有用。
特别注意:
- ZEROFILL 属性仅影响数值的显示方式,并不改变存储在数据库中的实际值。例如,无论是否使用 ZEROFILL,数值 123 都存储为 123,只是显示时可能会不同。
- ZEROFILL 填充的零只是为了达到字段定义的显示宽度,它并不影响字段的存储范围或存储大小。
- 当字段被定义为 ZEROFILL 时,MySQL 也会自动将其标记为 UNSIGNED。这是因为前导零填充通常只对正数有意义。
OK,我们通过 show columns from user like 'money'; 来查看一下字段的属性。
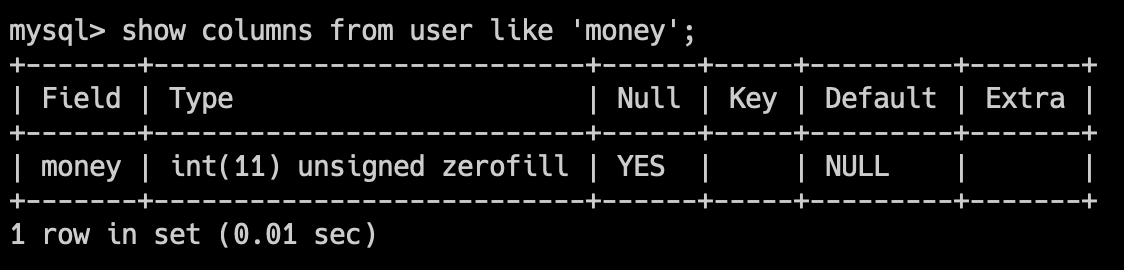
可以看到,money 字段的属性中,有 ZEROFILL 和 UNSIGNED。
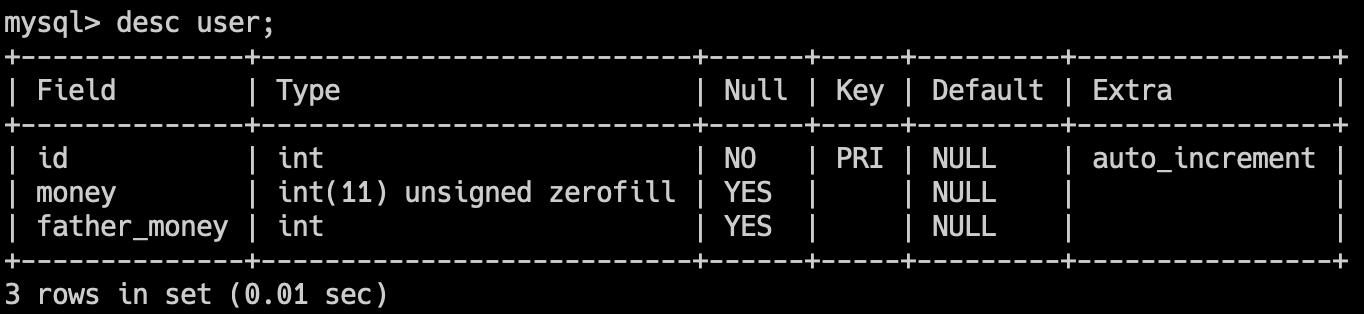
除了通过这种方式,也可以通过 desc table_name 来查看表的结构。
总结
字段的属性设置是 MySQL 表设计中的重要一环,掌握它们是非常有必要的。这次我们依次讲了默认值、是否允许为空、主键、自增、注释、唯一性约束、外键、ZEROFILL 等属性。
这里温馨提示一点,尽量不要使用 MySQL 的关键字,尽管我们可以通过反引号(`)来避免关键字冲突,但这样会使 SQL 语句变得复杂,不利于维护。
尤其是一些关键字和 Java 当中的关键字重合时,很容易出现意料之外的错误。