本文简介
点赞 + 收藏 + 关注 = 学会了
声明:请勿使用爬虫技术获取公民隐私数据、±数据以及企业或个人不允许你获取的数据。
本文介绍如何使用 Python 写一只简单的爬虫,作为入门篇,这个程序不会很复杂,但至少可以讲明爬虫是个什么东西。
写一个爬虫程序其实很简单,从整体来看只需3步:
- 发起网络请求,获取网页内容。
- 解析网页的内容。
- 储存数据,或者拿来做数据分析。
但第三步其实已经不属于“爬”这个动作了,所以本文只介绍前2步。至于第三步存储数据,之后会写几篇文章讲讲 Python 如何操作数据库,之后也会介绍 Python 热门的数据分析工具(先画个饼)。
动手操作
十个教爬虫,九个爬豆瓣。注意,本文只是拿豆瓣来举例,你可不要真的24小时一直在爬它呀。
发起网络请求
在 Python 中要发起网络请求,可以使用 requests 。
如果还没安装 requests 可以用以下命令安装
pip install requests
然后引入使用
import requests
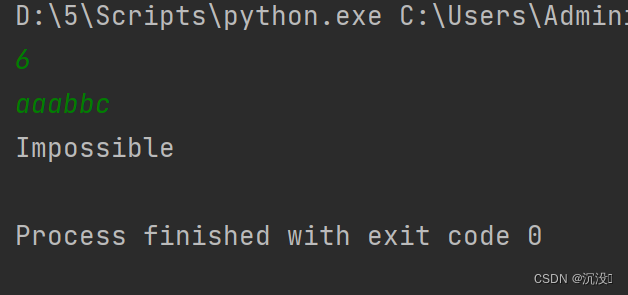
我要获取豆瓣电影Top250的数据,电影Top250的页面地址是 https://movie.douban.com/top250。可以用 get 请求。
res = requests.get("https://movie.douban.com/top250")
print(res)
上面这段代码的意思是通过 requests.get 发起 get 请求,并把结果输出看看。

看到输出结果的状态码是 418,表示豆瓣的服务器不想理你。
出现这种情况的原因是豆瓣只想服务用浏览器访问的用户,你通过写代码的方式来访问它就不想鸟你了。
于是我们可以通过请求头模拟自己是浏览器。打开浏览器,按F12,切换到Network,然后刷新一下页面。之后随便点一个请求,把它的 User-Agent 的值复制下来。

在使用 requests 发起请求时在 headers 里把 User-Agent 的值带上。
# 获取数据
headers = {"User-Agent": "你的 User-Agent"}
res = requests.get("https://movie.douban.com/top250", headers=headers)
print(res)

此时状态码返回 200 证明成功了。
除了 200 可能还有其他状态码是表示成功的,如果要逐一判断是比较麻烦的。requests 的返回值里提供了一个 .ok 的属性帮助我们快速判断响应内容是否获取成功。
# 省略前面的代码...
print(res.ok)
如果 res.ok 返回 Treu 就表示响应成功。
然后我们看看返回的内容是什么,可以查看 .text 。
if (res.ok):
print(res.text)

返回的是这个页面的 HTML 内容。到此,我们获取这个页面的数据已经成功了。接下来要做的就是解析这个页面的数据。
解析网页内容
本文介绍一个很简单的解析网页元素的工具,叫 Beautiful Soup 中文名叫“靓汤”,广东人最爱。
在写本文时,Beautiful Soup 已经出到第4版了。
-
Beautiful Soup官网 -
Beautiful Soup文档
要安装 Beautiful Soup 可以使用下面这条命令。
pip install beautifulsoup4
然后引入使用。我们接回上面的内容
from bs4 import BeautifulSoup
import requests
# 获取数据
headers = {"User-Agent": "你的 User-Agent"}
res = requests.get("https://movie.douban.com/top250", headers=headers).text
print(res)
此时输出的内容是

看红色箭头指向的那句就是电影名了。<span class="title">霸王别姬</span>
这个电影名用 span 标签包裹着,而且它的 class 是 title。
于是我们可以使用 BeautifulSoup 的 findAll 找到所有符合 class 为 title 的 span 元素。
# 省略部分代码
# 把内容丢给 BeautifulSoup 解析
soup = BeautifulSoup(res, "html.parser")
# 使用 findAll 找到所有 class 为 title 的 span 元素
all_films = soup.findAll("span", attrs={"class": "title"})
print(all_films)
输出的结果如下图所示:

这样就把本页符合规则的标签都整理出来了。
BeautifulSoup 第一个参数是要解释的内容,第二个参数 html.parser 是告诉 BeautifulSoup 要解析的是 HTML 内容。
接下来我们可以使用 for 循环把这些标签逐个输出,并使用 .string 属性把标签里的字符串提取出来。
for film_name in all_films:
print(film_name.string)

问题来了,为什么有些电影名前面有斜杠,有些又没有斜杠?

打开网页看源码,电影名的别名是用斜杠分隔的,而且它们都符合 <span class="title"> 这个规则。
所以我们在遍历的时候可以将不含斜杠的电影名提取出来。
for film_name in all_films:
if '/' not in film_name.string:
print(film_name.string)

但这电影数量和Top250的数量相差甚远。原因是我们爬取的这页只展示了25条数据。

如果要爬取250条数据就要先搞清分页时要传什么参数。
点开第2页可以看到url变了。多了个 start=25。

点开第3页发现 start=50 。我们根据这个规则可以写一个遍历方法,将250条数据都拿回来。
具体代码如下:
from bs4 import BeautifulSoup
import requests
# 设置请求头
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"}
# 按规律遍历,请求Top250数据
for start_num in range(0, 250, 25):
res = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
soup = BeautifulSoup(res.text, "html.parser") # 开始解析html
all_films = soup.findAll("span", attrs={"class": "title"}) # 获取所有电影名(含html标签)
for film_name in all_films:
if '/' not in film_name.string:
print(film_name.string)
只需十来行代码就把豆瓣Top250的电影名都拿下了。
总结
python 是很擅长写爬虫的,相关的工具也非常多。本文介绍的属于最简单的一种爬虫,主要给各位工友建立学习信心。
之后会介绍更多爬虫相关的工具。
点赞 + 关注 + 收藏 = 学会了
如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

Python兼职渠道推荐
学的同时助你创收,每天花1-2小时兼职,轻松稿定生活费.
2️⃣国内外Python书籍、文档
① 文档和书籍资料

3️⃣Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

4️⃣Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


上述所有资料 ⚡️ ,朋友们如果有需要的,可以扫描下方👇👇👇二维码免费领取🆓





![[隐私计算实训营学习笔记] 第1讲 数据要素流通](https://img-blog.csdnimg.cn/direct/a13ba60cc0f5489bb77d3d8f815d010e.png#pic_center)