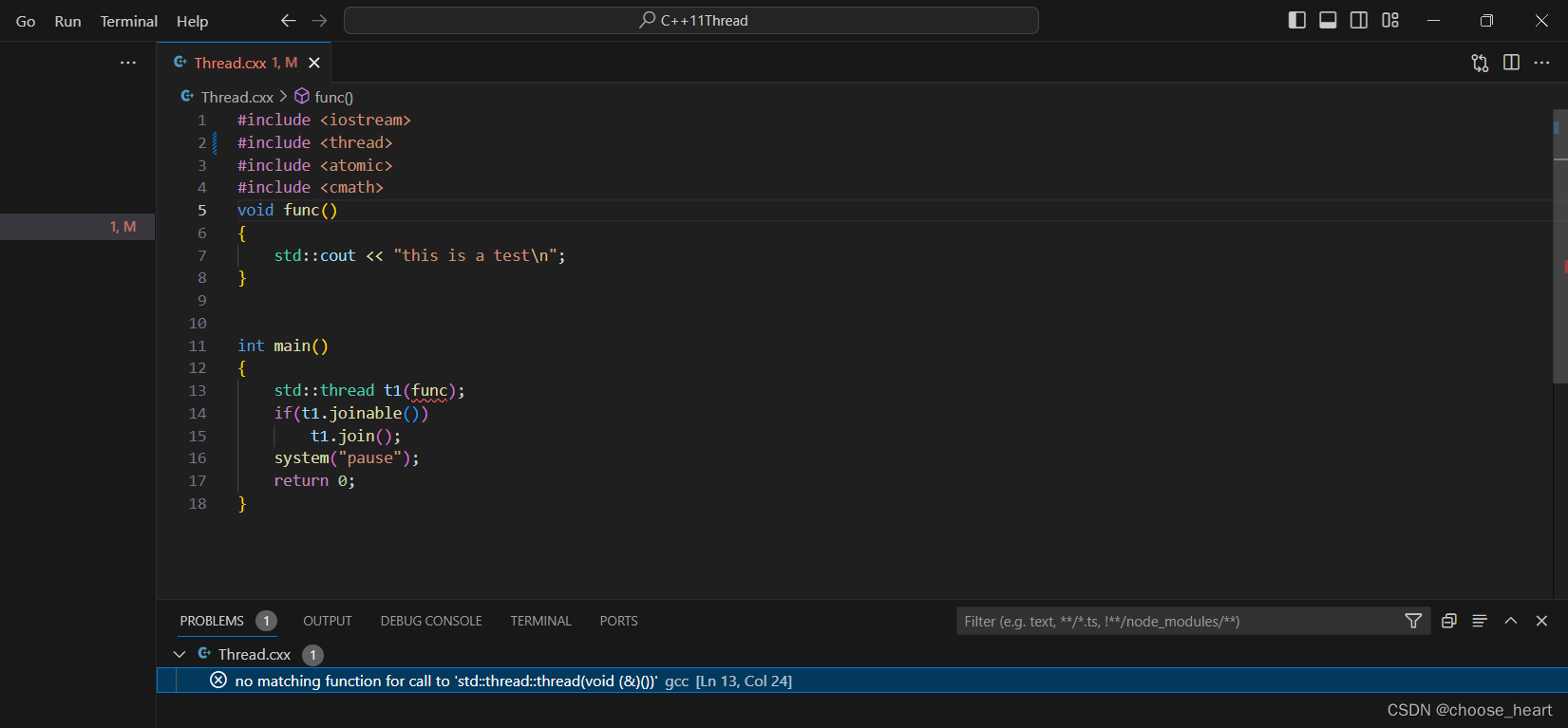
onnx 的架构和 onnx helper 的使用
- 简介
- 一、onnx 的架构
- 二、onnx 实践
- 2.1、 create - linear.onnx
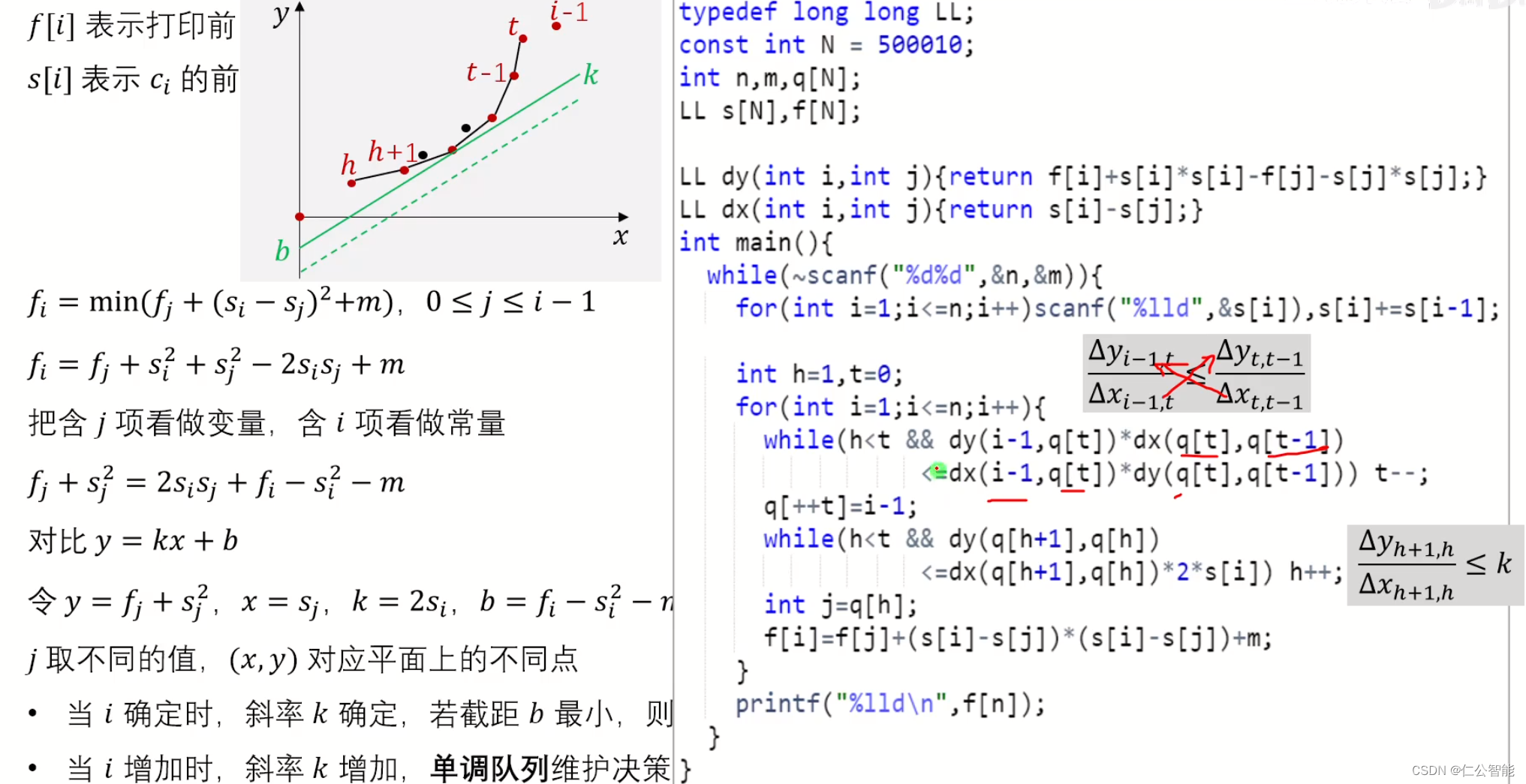
- 2.1.1、要点一:创建节点
- 2.1.2、要点二:创建张量
- 2.1.3、要点三:创建图
- 2.2、 create - onnx.convnet
- 2.3、使用 onnx helper 导出的基本流程总结
- 三、parse onnx
- 3.1、案例一
- 3.2、案例二(带有权重的)
简介
首先来了解一下 学习 onnx 架构和 onnx helper 的使用的目的。
一般模型部署的流程是
前处理+模型推理+后处理,然后c++ 上进行推理。
- 前处理(与tensorRT无关)
- 模型推理(生成的engine交给tensorRT去做前向传播)
- 后处理(与tensorRT无关)
模型推理部分是指利用 tensorRT 的 onnx 解析器编译生成 engine (即转换为tensorRT能看懂的模型)。
1、有些时候我们应该把后处理部分在onnx模型中实现,降低后处理复杂度。
比如说yolov5的后处理中,要借助anchor要做一些乘加的操作,如果我们单独分开在后处理中去做的话,你就会发现你既要准备一个模型,还得专门储存这个模型的anchor的信息,这样代码的复杂度就很高,后处理的逻辑就会非常麻烦。所以把后处理的逻辑尽量得放在模型里面,使得它的tensor很简单通过decode就能实现。然后自己做的后处理性能可能还不够高,如果放到onnx里,tensorRT顺便还能帮你加速一下。
很多时候我们onnx已经导出来了,如果我还想去实现onnx后处理的增加,该怎么做呢? 有两种做法,一种是直接用onnx这个包去操作onnx文件,去增加一些节点是没有问题的,但这个难度系数比较高。第二种做法是可以用pytorch去实现后处理逻辑的代码,把这个后处理专门导出一个onnx,然后再把这个onnx合并到原来的onnx上,这也是实际上我们针对复杂任务专门定制的一个做法。
2、还有些时候我们无法直接用pytorch的export_onnx函数导出onnx,这个时候就要自己构建一个onnx 了。
比如 bevfusion的 spconv 部分,利用 onnx.helper() 自己构建一个onnx,然后再转 tensorrt
这些场景都需要自己理解、解析和构建 onnx。
一、onnx 的架构
首先我们来理解一下 onnx 的架构:ONNX是一种神经网络的格式,采用Protobuf (Protocal Buffer。是Google提出来的一套表示和序列化数据的机制) 二进制形式进行序列化模型。Protobuf会根据用于定义的数据结构来进行序列化存储。我们可以根据官方提供的数据结构信息,去修改或者创建onnx。onnx的各类proto的定义需要看官方文档 (https://github.com/onnx/onnx/tree/main)。这里面的onnx/onnx.in.proto定义了所有onnx的Proto 。
大概 总结 onnx 中的组织结构 如下:
- ModelProto (描述的是整个模型的信息)
— GraphProto (描述的是整个网络的信息)
------ NodeProto (描述的是各个计算节点,比如conv, linear)
------ TensorProto (描述的是tensor的信息,主要包括权重)
------ ValueInfoProto (描述的是input/output信息)
------ AttributeProto (描述的是node节点的各种属性信息)
下面我们根据总结的组织结构信息,来实践创建几个 onnx 。
二、onnx 实践
2.1、 create - linear.onnx
总体程序如下:
import onnx
from onnx import helper
from onnx import TensorProto
def create_onnx():
# 创建ValueProto
a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10])
x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10])
b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10])
y = helper.make_tensor_value_info('y', TensorProto.FLOAT, [10, 10])
# 创建NodeProto
mul = helper.make_node('Mul', ['a', 'x'], 'c', "multiply")
add = helper.make_node('Add', ['c', 'b'], 'y', "add")
# 构建GraphProto
graph = helper.make_graph([mul, add], 'sample-linear', [a, x, b], [y])
# 构建ModelProto
model = helper.make_model(graph)
# 检查model是否有错误
onnx.checker.check_model(model)
# print(model)
# 保存model
onnx.save(model, "sample-linear.onnx")
return model
if __name__ == "__main__":
model = create_onnx()
程序执行完会出现一个 sample-linear.onnx ,节点图如下。下面我们来看看程序里面的细节。
 )
)
2.1.1、要点一:创建节点
使用 helper.make_node 创建节点 (图中的黑色部分 'Mul','Add' )
我们用下面两句话创建两个节点。
# 创建NodeProto
mul = helper.make_node('Mul', ['a', 'x'], 'c', "multiply")
add = helper.make_node('Add', ['c', 'b'], 'y', "add")
函数对应参数解释:

:op_type :The name of the operator to construct(要构造的运算符的名称)
这里填入的是onnx支持的算子的名称。这个地方是不可以乱写的,比如 不能将 ‘Mul’ 写成 ‘Mul2’,具体的参数查阅在 https://github.com/onnx/onnx/blob/main/docs/Operators.md
:inputs :list of input names(节点输入名称),比如这里 Mul 的输入名字 是 ['a', 'x'] 两个
:outputs : list of output names(节点输出名称)比如这里 Mul 的输出名字 是'c'一个
:name : optional unique identifier for NodeProto(NodeProto的可选唯一标识符)
NodeProto 总结解释:
onnx中的 NodeProto,一般用来定义一个计算节点,比如conv, linear。
(input是repeated类型,意味着是数组)
(output是repeated类型,意味着是数组)
(attribute有一个自己的Proto)
(op_type需要严格根据onnx所提供的Operators写)
2.1.2、要点二:创建张量
helper.make_tensor, helper.make_value_info
一般用来定义网络的 input/output (会根据input/output的type来附加属性)
a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10])
x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10])
b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10])
y = helper.make_tensor_value_info('y', TensorProto.FLOAT, [10, 10])
2.1.3、要点三:创建图
helper.make_graph
# 构建GraphProto
graph = helper.make_graph([mul, add], 'sample-linear', [a, x, b], [y])
:nodes: list of NodeProto
:name (string): graph name
:inputs: list of ValueInfoProto
:outputs: list of ValueInfoProto
GraphProto 总结解释:
一般用来定义一个网络。包括
• input/output
• initializer (在onnx中一般表示权重信息)
• node
(node是repeated,所以是数组)
(initializer是repeated,所以是数组)
(input/output是repeated,所以是数组)
2.2、 create - onnx.convnet
import numpy as np
import onnx
from onnx import numpy_helper
def create_initializer_tensor(
name: str,
tensor_array: np.ndarray,
data_type: onnx.TensorProto = onnx.TensorProto.FLOAT
) -> onnx.TensorProto:
initializer = onnx.helper.make_tensor(
name = name,
data_type = data_type,
dims = tensor_array.shape,
vals = tensor_array.flatten().tolist())
return initializer
def main():
input_batch = 1;
input_channel = 3;
input_height = 64;
input_width = 64;
output_channel = 16;
input_shape = [input_batch, input_channel, input_height, input_width]
output_shape = [input_batch, output_channel, 1, 1]
##########################创建input/output################################
model_input_name = "input0"
model_output_name = "output0"
input = onnx.helper.make_tensor_value_info(
model_input_name,
onnx.TensorProto.FLOAT,
input_shape)
output = onnx.helper.make_tensor_value_info(
model_output_name,
onnx.TensorProto.FLOAT,
output_shape)
##########################创建第一个conv节点##############################
conv1_output_name = "conv2d_1.output"
conv1_in_ch = input_channel
conv1_out_ch = 32
conv1_kernel = 3
conv1_pads = 1
# 创建conv节点的权重信息
conv1_weight = np.random.rand(conv1_out_ch, conv1_in_ch, conv1_kernel, conv1_kernel)
conv1_bias = np.random.rand(conv1_out_ch)
conv1_weight_name = "conv2d_1.weight"
conv1_weight_initializer = create_initializer_tensor(
name = conv1_weight_name,
tensor_array = conv1_weight,
data_type = onnx.TensorProto.FLOAT)
conv1_bias_name = "conv2d_1.bias"
conv1_bias_initializer = create_initializer_tensor(
name = conv1_bias_name,
tensor_array = conv1_bias,
data_type = onnx.TensorProto.FLOAT)
# 创建conv节点,注意conv节点的输入有3个: input, w, b
conv1_node = onnx.helper.make_node(
name = "conv2d_1",
op_type = "Conv",
inputs = [
model_input_name,
conv1_weight_name,
conv1_bias_name
],
outputs = [conv1_output_name],
kernel_shape = [conv1_kernel, conv1_kernel],
pads = [conv1_pads, conv1_pads, conv1_pads, conv1_pads],
)
##########################创建一个BatchNorm节点###########################
bn1_output_name = "batchNorm1.output"
# 为BN节点添加权重信息
bn1_scale = np.random.rand(conv1_out_ch)
bn1_bias = np.random.rand(conv1_out_ch)
bn1_mean = np.random.rand(conv1_out_ch)
bn1_var = np.random.rand(conv1_out_ch)
# 通过create_initializer_tensor创建权重,方法和创建conv节点一样
bn1_scale_name = "batchNorm1.scale"
bn1_bias_name = "batchNorm1.bias"
bn1_mean_name = "batchNorm1.mean"
bn1_var_name = "batchNorm1.var"
bn1_scale_initializer = create_initializer_tensor(
name = bn1_scale_name,
tensor_array = bn1_scale,
data_type = onnx.TensorProto.FLOAT)
bn1_bias_initializer = create_initializer_tensor(
name = bn1_bias_name,
tensor_array = bn1_bias,
data_type = onnx.TensorProto.FLOAT)
bn1_mean_initializer = create_initializer_tensor(
name = bn1_mean_name,
tensor_array = bn1_mean,
data_type = onnx.TensorProto.FLOAT)
bn1_var_initializer = create_initializer_tensor(
name = bn1_var_name,
tensor_array = bn1_var,
data_type = onnx.TensorProto.FLOAT)
# 创建BN节点,注意BN节点的输入信息有5个: input, scale, bias, mean, var
bn1_node = onnx.helper.make_node(
name = "batchNorm1",
op_type = "BatchNormalization",
inputs = [
conv1_output_name,
bn1_scale_name,
bn1_bias_name,
bn1_mean_name,
bn1_var_name
],
outputs=[bn1_output_name],
)
##########################创建一个ReLU节点###########################
relu1_output_name = "relu1.output"
# 创建ReLU节点,ReLU不需要权重,所以直接make_node就好了
relu1_node = onnx.helper.make_node(
name = "relu1",
op_type = "Relu",
inputs = [bn1_output_name],
outputs = [relu1_output_name],
)
##########################创建一个AveragePool节点####################
avg_pool1_output_name = "avg_pool1.output"
# 创建AvgPool节点,AvgPool不需要权重,所以直接make_node就好了
avg_pool1_node = onnx.helper.make_node(
name = "avg_pool1",
op_type = "GlobalAveragePool",
inputs = [relu1_output_name],
outputs = [avg_pool1_output_name],
)
##########################创建第二个conv节点##############################
# 创建conv节点的属性
conv2_in_ch = conv1_out_ch
conv2_out_ch = output_channel
conv2_kernel = 1
conv2_pads = 0
# 创建conv节点的权重信息
conv2_weight = np.random.rand(conv2_out_ch, conv2_in_ch, conv2_kernel, conv2_kernel)
conv2_bias = np.random.rand(conv2_out_ch)
conv2_weight_name = "conv2d_2.weight"
conv2_weight_initializer = create_initializer_tensor(
name = conv2_weight_name,
tensor_array = conv2_weight,
data_type = onnx.TensorProto.FLOAT)
conv2_bias_name = "conv2d_2.bias"
conv2_bias_initializer = create_initializer_tensor(
name = conv2_bias_name,
tensor_array = conv2_bias,
data_type = onnx.TensorProto.FLOAT)
# 创建conv节点,注意conv节点的输入有3个: input, w, b
conv2_node = onnx.helper.make_node(
name = "conv2d_2",
op_type = "Conv",
inputs = [
avg_pool1_output_name,
conv2_weight_name,
conv2_bias_name
],
outputs = [model_output_name],
kernel_shape = [conv2_kernel, conv2_kernel],
pads = [conv2_pads, conv2_pads, conv2_pads, conv2_pads],
)
##########################创建graph##############################
graph = onnx.helper.make_graph(
name = "sample-convnet",
inputs = [input],
outputs = [output],
nodes = [
conv1_node,
bn1_node,
relu1_node,
avg_pool1_node,
conv2_node],
initializer =[
conv1_weight_initializer,
conv1_bias_initializer,
bn1_scale_initializer,
bn1_bias_initializer,
bn1_mean_initializer,
bn1_var_initializer,
conv2_weight_initializer,
conv2_bias_initializer
],
)
##########################创建model##############################
model = onnx.helper.make_model(graph, producer_name="onnx-sample")
model.opset_import[0].version = 12
##########################验证&保存model##############################
model = onnx.shape_inference.infer_shapes(model)
onnx.checker.check_model(model)
print("Congratulations!! Succeed in creating {}.onnx".format(graph.name))
onnx.save(model, "sample-convnet.onnx")
# 使用onnx.helper创建一个最基本的ConvNet
# input (ch=3, h=64, w=64)
# |
# Conv (in_ch=3, out_ch=32, kernel=3, pads=1)
# |
# BatchNorm
# |
# ReLU
# |
# AvgPool
# |
# Conv (in_ch=32, out_ch=10, kernel=1, pads=0)
# |
# output (ch=10, h=1, w=1)
if __name__ == "__main__":
main()
与案例1不同的地方在
def create_initializer_tensor(
name: str,
tensor_array: np.ndarray,
data_type: onnx.TensorProto = onnx.TensorProto.FLOAT
) -> onnx.TensorProto:
initializer = onnx.helper.make_tensor(
name = name,
data_type = data_type,
dims = tensor_array.shape,
vals = tensor_array.flatten().tolist())
return initializer
这里使用了 onnx.helper.make_tensor()
2.3、使用 onnx helper 导出的基本流程总结
- helper.make_node
- helper.make_tensor
- helper.make_value_info
- helper.make_graph
- helper.make_operatorsetid
- helper.make_model
- onnx.save_model
参考链接
三、parse onnx
下面的案例展示如何使用 python 把 onnx 打印出来
3.1、案例一
import onnx
def main():
model = onnx.load("sample-linear.onnx")
onnx.checker.check_model(model)
graph = model.graph
nodes = graph.node
inputs = graph.input
outputs = graph.output
print("\n**************parse input/output*****************")
for input in inputs:
input_shape = []
for d in input.type.tensor_type.shape.dim:
if d.dim_value == 0:
input_shape.append(None)
else:
input_shape.append(d.dim_value)
print("Input info: \
\n\tname: {} \
\n\tdata Type: {} \
\n\tshape: {}".format(input.name, input.type.tensor_type.elem_type, input_shape))
for output in outputs:
output_shape = []
for d in output.type.tensor_type.shape.dim:
if d.dim_value == 0:
output_shape.append(None)
else:
output_shape.append(d.dim_value)
print("Output info: \
\n\tname: {} \
\n\tdata Type: {} \
\n\tshape: {}".format(input.name, output.type.tensor_type.elem_type, input_shape))
print("\n**************parse node************************")
for node in nodes:
print("node info: \
\n\tname: {} \
\n\top_type: {} \
\n\tinputs: {} \
\n\toutputs: {}".format(node.name, node.op_type, node.input, node.output))
if __name__ == "__main__":
main()
3.2、案例二(带有权重的)
这里有两个 py 文件
parser.py
import onnx
import numpy as np
# 注意,因为weight是以字节的形式存储的,所以要想读,需要转变为float类型
def read_weight(initializer: onnx.TensorProto):
shape = initializer.dims
data = np.frombuffer(initializer.raw_data, dtype=np.float32).reshape(shape)
print("\n**************parse weight data******************")
print("initializer info: \
\n\tname: {} \
\n\tdata: \n{}".format(initializer.name, data))
def parse_onnx(model: onnx.ModelProto):
graph = model.graph
initializers = graph.initializer
nodes = graph.node
inputs = graph.input
outputs = graph.output
print("\n**************parse input/output*****************")
for input in inputs:
input_shape = []
for d in input.type.tensor_type.shape.dim:
if d.dim_value == 0:
input_shape.append(None)
else:
input_shape.append(d.dim_value)
print("Input info: \
\n\tname: {} \
\n\tdata Type: {} \
\n\tshape: {}".format(input.name, input.type.tensor_type.elem_type, input_shape))
for output in outputs:
output_shape = []
for d in output.type.tensor_type.shape.dim:
if d.dim_value == 0:
output_shape.append(None)
else:
output_shape.append(d.dim_value)
print("Output info: \
\n\tname: {} \
\n\tdata Type: {} \
\n\tshape: {}".format(input.name, output.type.tensor_type.elem_type, input_shape))
print("\n**************parse node************************")
for node in nodes:
print("node info: \
\n\tname: {} \
\n\top_type: {} \
\n\tinputs: {} \
\n\toutputs: {}".format(node.name, node.op_type, node.input, node.output))
print("\n**************parse initializer*****************")
for initializer in initializers:
print("initializer info: \
\n\tname: {} \
\n\tdata_type: {} \
\n\tshape: {}".format(initializer.name, initializer.data_type, initializer.dims))
parse_onnx_cbr.py
import torch
import torch.nn as nn
import torch.onnx
import onnx
from parser import parse_onnx
from parser import read_weight
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)
self.bn1 = nn.BatchNorm2d(num_features=16)
self.act1 = nn.LeakyReLU()
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.act1(x)
return x
def export_norm_onnx():
input = torch.rand(1, 3, 5, 5)
model = Model()
model.eval()
file = "sample-cbr.onnx"
torch.onnx.export(
model = model,
args = (input,),
f = file,
input_names = ["input0"],
output_names = ["output0"],
opset_version = 15)
print("Finished normal onnx export")
def main():
export_norm_onnx()
model = onnx.load_model("sample-cbr.onnx")
parse_onnx(model)
initializers = model.graph.initializer
for item in initializers:
read_weight(item)
if __name__ == "__main__":
main()
sample-cbr.onnx 模型下载地址