第三章:字典和集合
Python 基本上是用大量语法糖包装的字典。
Lalo Martins,早期数字游牧民和 Pythonista
我们在所有的 Python 程序中都使用字典。即使不是直接在我们的代码中,也是间接的,因为dict类型是 Python 实现的基本部分。类和实例属性、模块命名空间和函数关键字参数是内存中由字典表示的核心 Python 构造。__builtins__.__dict__存储所有内置类型、对象和函数。
由于其关键作用,Python 字典经过高度优化,并持续改进。哈希表是 Python 高性能字典背后的引擎。
其他基于哈希表的内置类型是set和frozenset。这些提供比您在其他流行语言中遇到的集合更丰富的 API 和运算符。特别是,Python 集合实现了集合理论中的所有基本操作,如并集、交集、子集测试等。通过它们,我们可以以更声明性的方式表达算法,避免大量嵌套循环和条件语句。
以下是本章的简要概述:
-
用于构建和处理
dicts和映射的现代语法,包括增强的解包和模式匹配 -
映射类型的常见方法
-
丢失键的特殊处理
-
标准库中
dict的变体 -
set和frozenset类型 -
哈希表在集合和字典行为中的影响。
本章的新内容
这第二版中的大部分变化涵盖了与映射类型相关的新功能:
-
“现代字典语法”介绍了增强的解包语法以及合并映射的不同方式,包括自 Python 3.9 起由
dicts支持的|和|=运算符。 -
“使用映射进行模式匹配”演示了自 Python 3.10 起使用
match/case处理映射。 -
“collections.OrderedDict”现在专注于
dict和OrderedDict之间的细微但仍然相关的差异——考虑到自 Python 3.6 起dict保留键插入顺序。 -
由
dict.keys、dict.items和dict.values返回的视图对象的新部分:“字典视图”和“字典视图上的集合操作”。
dict和set的基础实现仍然依赖于哈希表,但dict代码有两个重要的优化,可以节省内存并保留键在dict中的插入顺序。“dict 工作原理的实际后果”和“集合工作原理的实际后果”总结了您需要了解的内容,以便很好地使用它们。
注意
在这第二版中增加了 200 多页后,我将可选部分“集合和字典的内部”移至fluentpython.com伴随网站。更新和扩展的18 页文章包括关于以下内容的解释和图表:
-
哈希表算法和数据结构,从在
set中的使用开始,这更容易理解。 -
保留
dict实例中键插入顺序的内存优化(自 Python 3.6 起)。 -
用于保存实例属性的字典的键共享布局——用户定义对象的
__dict__(自 Python 3.3 起实现的优化)。
现代字典语法
接下来的部分描述了用于构建、解包和处理映射的高级语法特性。其中一些特性在语言中并不新鲜,但对您可能是新的。其他需要 Python 3.9(如|运算符)或 Python 3.10(如match/case)的特性。让我们从其中一个最好且最古老的特性开始。
字典推导式
自 Python 2.7 起,列表推导和生成器表达式的语法已经适应了 dict 推导(以及我们即将讨论的 set 推导)。dictcomp(dict 推导)通过从任何可迭代对象中获取 key:value 对来构建一个 dict 实例。示例 3-1 展示了使用 dict 推导从相同的元组列表构建两个字典的用法。
示例 3-1. dict 推导示例
>>> dial_codes = ![1
... (880, 'Bangladesh'),
... (55, 'Brazil'),
... (86, 'China'),
... (91, 'India'),
... (62, 'Indonesia'),
... (81, 'Japan'),
... (234, 'Nigeria'),
... (92, 'Pakistan'),
... (7, 'Russia'),
... (1, 'United States'),
... ]
>>> country_dial = {country: code for code, country in dial_codes} # ②
>>> country_dial
{'Bangladesh': 880, 'Brazil': 55, 'China': 86, 'India': 91, 'Indonesia': 62, 'Japan': 81, 'Nigeria': 234, 'Pakistan': 92, 'Russia': 7, 'United States': 1} >>> {code: country.upper() # ③
... for country, code in sorted(country_dial.items())
... if code < 70}
{55: 'BRAZIL', 62: 'INDONESIA', 7: 'RUSSIA', 1: 'UNITED STATES'}
①
可以直接将类似 dial_codes 的键值对可迭代对象传递给 dict 构造函数,但是…
②
…在这里我们交换了键值对:country 是键,code 是值。
③
按名称对 country_dial 进行排序,再次反转键值对,将值大写,并使用 code < 70 过滤项。
如果你习惯于列表推导,那么字典推导是一个自然的下一步。如果你不熟悉,那么理解推导语法的传播意味着现在比以往任何时候都更有利可图。
解包映射
PEP 448—额外的解包泛化 自 Python 3.5 以来增强了对映射解包的支持。
首先,我们可以在函数调用中对多个参数应用 **。当键都是字符串且在所有参数中唯一时,这将起作用(因为禁止重复关键字参数):
>>> def dump(**kwargs):
... return kwargs
...
>>> dump(**{'x': 1}, y=2, **{'z': 3})
{'x': 1, 'y': 2, 'z': 3}
第二,** 可以在 dict 字面量内使用——也可以多次使用:
>>> {'a': 0, **{'x': 1}, 'y': 2, **{'z': 3, 'x': 4}}
{'a': 0, 'x': 4, 'y': 2, 'z': 3}
在这种情况下,允许重复的键。后续出现的键会覆盖先前的键—请参见示例中映射到 x 的值。
这种语法也可以用于合并映射,但还有其他方法。请继续阅读。
使用 | 合并映射
Python 3.9 支持使用 | 和 |= 来合并映射。这是有道理的,因为这些也是集合的并运算符。
| 运算符创建一个新的映射:
>>> d1 = {'a': 1, 'b': 3}
>>> d2 = {'a': 2, 'b': 4, 'c': 6}
>>> d1 | d2
{'a': 2, 'b': 4, 'c': 6}
通常,新映射的类型将与左操作数的类型相同—在示例中是 d1,但如果涉及用户定义的类型,则可以是第二个操作数的类型,根据我们在第十六章中探讨的运算符重载规则。
要就地更新现有映射,请使用 |=。继续前面的例子,d1 没有改变,但现在它被改变了:
>>> d1
{'a': 1, 'b': 3}
>>> d1 |= d2
>>> d1
{'a': 2, 'b': 4, 'c': 6}
提示
如果你需要维护能在 Python 3.8 或更早版本上运行的代码,PEP 584—为 dict 添加 Union 运算符 的 “动机” 部分提供了其他合并映射的方法的简要总结。
现在让我们看看模式匹配如何应用于映射。
使用映射进行模式匹配
match/case 语句支持作为映射对象的主题。映射的模式看起来像 dict 字面量,但它们可以匹配 collections.abc.Mapping 的任何实际或虚拟子类的实例。¹
在第二章中,我们只关注了序列模式,但不同类型的模式可以组合和嵌套。由于解构,模式匹配是处理结构化为嵌套映射和序列的记录的强大工具,我们经常需要从 JSON API 和具有半结构化模式的数据库(如 MongoDB、EdgeDB 或 PostgreSQL)中读取这些记录。示例 3-2 演示了这一点。get_creators 中的简单类型提示清楚地表明它接受一个 dict 并返回一个 list。
示例 3-2. creator.py:get_creators() 从媒体记录中提取创作者的名称
def get_creators(record: dict) -> list:
match record:
case {'type': 'book', 'api': 2, 'authors': [*names]}: # ①
return names
case {'type': 'book', 'api': 1, 'author': name}: # ②
return [name]
case {'type': 'book'}: # ③
raise ValueError(f"Invalid 'book' record: {record!r}")
case {'type': 'movie', 'director': name}: # ④
return [name]
case _: # ⑤
raise ValueError(f'Invalid record: {record!r}')
①
匹配任何具有 'type': 'book', 'api' :2 的映射,并且一个 'authors' 键映射到一个序列。将序列中的项作为新的 list 返回。
②
匹配任何具有 'type': 'book', 'api' :1 的映射,并且一个 'author' 键映射到任何对象。将对象放入一个 list 中返回。
③
具有'type': 'book'的任何其他映射都是无效的,引发ValueError。
④
匹配任何具有'type': 'movie'和将'director'键映射到单个对象的映射。返回list中的对象。
⑤
任何其他主题都是无效的,引发ValueError。
示例 3-2 展示了处理半结构化数据(如 JSON 记录)的一些有用实践:
-
包括描述记录类型的字段(例如,
'type': 'movie') -
包括标识模式版本的字段(例如,`‘api’: 2’)以允许公共 API 的未来演变
-
有
case子句来处理特定类型(例如,'book')的无效记录,以及一个全捕捉
现在让我们看看get_creators如何处理一些具体的 doctests:
>>> b1 = dict(api=1, author='Douglas Hofstadter',
... type='book', title='Gödel, Escher, Bach')
>>> get_creators(b1)
['Douglas Hofstadter']
>>> from collections import OrderedDict
>>> b2 = OrderedDict(api=2, type='book',
... title='Python in a Nutshell',
... authors='Martelli Ravenscroft Holden'.split())
>>> get_creators(b2)
['Martelli', 'Ravenscroft', 'Holden']
>>> get_creators({'type': 'book', 'pages': 770})
Traceback (most recent call last):
...
ValueError: Invalid 'book' record: {'type': 'book', 'pages': 770}
>>> get_creators('Spam, spam, spam')
Traceback (most recent call last):
...
ValueError: Invalid record: 'Spam, spam, spam'
注意,模式中键的顺序无关紧要,即使主题是OrderedDict,如b2。
与序列模式相比,映射模式在部分匹配上成功。在 doctests 中,b1和b2主题包括一个在任何'book'模式中都不出现的'title'键,但它们匹配。
不需要使用**extra来匹配额外的键值对,但如果要将它们捕获为dict,可以使用**前缀一个变量。它必须是模式中的最后一个,并且**_是被禁止的,因为它是多余的。一个简单的例子:
>>> food = dict(category='ice cream', flavor='vanilla', cost=199)
>>> match food:
... case {'category': 'ice cream', **details}:
... print(f'Ice cream details: {details}')
...
Ice cream details: {'flavor': 'vanilla', 'cost': 199}
在“缺失键的自动处理”中,我们将研究defaultdict和其他映射,其中通过__getitem__(即,d[key])进行键查找成功,因为缺失项会动态创建。在模式匹配的上下文中,只有在主题已经具有match语句顶部所需键时,匹配才成功。
提示
不会触发缺失键的自动处理,因为模式匹配总是使用d.get(key, sentinel)方法——其中默认的sentinel是一个特殊的标记值,不能出现在用户数据中。
从语法和结构转向,让我们研究映射的 API。
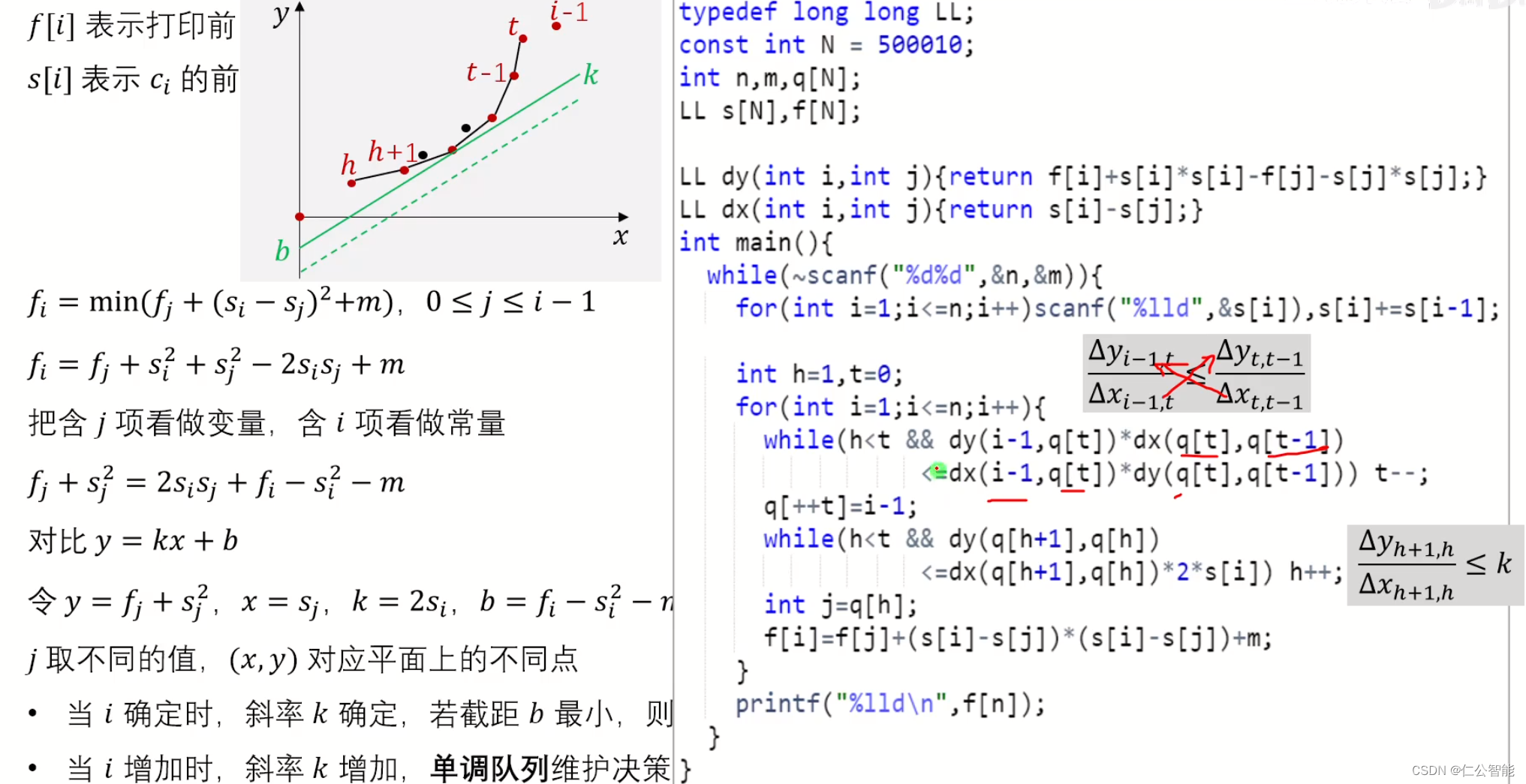
映射类型的标准 API
collections.abc模块提供了描述dict和类似类型接口的Mapping和MutableMapping ABCs。参见图 3-1。
ABCs 的主要价值在于记录和规范映射的标准接口,并作为需要支持广义映射的代码中isinstance测试的标准:
>>> my_dict = {}
>>> isinstance(my_dict, abc.Mapping)
True
>>> isinstance(my_dict, abc.MutableMapping)
True
提示
使用 ABC 进行isinstance通常比检查函数参数是否为具体dict类型更好,因为这样可以使用替代映射类型。我们将在第十三章中详细讨论这个问题。
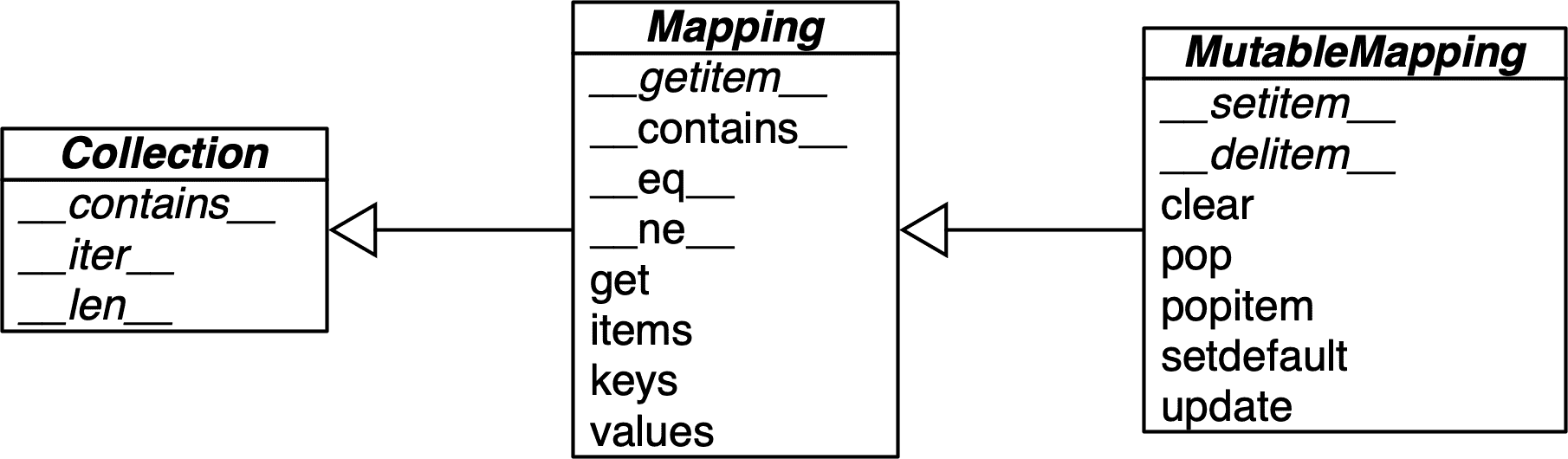
图 3-1。collections.abc中MutableMapping及其超类的简化 UML 类图(继承箭头从子类指向超类;斜体名称是抽象类和抽象方法)。
要实现自定义映射,最好扩展collections.UserDict,或通过组合包装dict,而不是继承这些 ABCs。collections.UserDict类和标准库中的所有具体映射类在其实现中封装了基本的dict,而dict又建立在哈希表上。因此,它们都共享一个限制,即键必须是可哈希的(值不需要是可哈希的,只有键需要是可哈希的)。如果需要复习,下一节会解释。
什么是可哈希的
这里是从Python 术语表中适应的可哈希定义的部分:
如果对象具有永远不会在其生命周期内更改的哈希码(它需要一个
__hash__()方法),并且可以与其他对象进行比较(它需要一个__eq__()方法),则该对象是可哈希的。比较相等的可哈希对象必须具有相同的哈希码。²
数值类型和扁平不可变类型str和bytes都是可哈希的。如果容器类型是不可变的,并且所有包含的对象也是可哈希的,则它们是可哈希的。frozenset始终是可哈希的,因为它包含的每个元素必须根据定义是可哈希的。仅当元组的所有项都是可哈希的时,元组才是可哈希的。参见元组tt、tl和tf:
>>> tt = (1, 2, (30, 40))
>>> hash(tt)
8027212646858338501
>>> tl = (1, 2, [30, 40])
>>> hash(tl)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> tf = (1, 2, frozenset([30, 40]))
>>> hash(tf)
-4118419923444501110
对象的哈希码可能因 Python 版本、机器架构以及出于安全原因添加到哈希计算中的盐而有所不同。³ 正确实现的对象的哈希码仅在一个 Python 进程中保证是恒定的。
默认情况下,用户定义的类型是可哈希的,因为它们的哈希码是它们的id(),并且从object类继承的__eq__()方法只是简单地比较对象 ID。如果一个对象实现了一个考虑其内部状态的自定义__eq__(),那么只有当其__hash__()始终返回相同的哈希码时,它才是可哈希的。实际上,这要求__eq__()和__hash__()只考虑在对象生命周期中永远不会改变的实例属性。
现在让我们回顾 Python 中最常用的映射类型dict、defaultdict和OrderedDict的 API。
常见映射方法概述
映射的基本 API 非常丰富。表 3-1 显示了dict和两个流行变体:defaultdict和OrderedDict的方法,它们都定义在collections模块中。
表 3-1. 映射类型dict、collections.defaultdict和collections.OrderedDict的方法(为简洁起见省略了常见对象方法);可选参数用[…]括起来
| dict | defaultdict | OrderedDict | ||
|---|---|---|---|---|
d.clear() | ● | ● | ● | 移除所有项 |
d.__contains__(k) | ● | ● | ● | k in d |
d.copy() | ● | ● | ● | 浅拷贝 |
d.__copy__() | ● | 支持copy.copy(d) | ||
d.default_factory | ● | __missing__调用的可调用对象,用于设置缺失值^(a) | ||
d.__delitem__(k) | ● | ● | ● | del d[k]—删除键为k的项 |
d.fromkeys(it, [initial]) | ● | ● | ● | 从可迭代对象中的键创建新映射,可选初始值(默认为None) |
d.get(k, [default]) | ● | ● | ● | 获取键为k的项,如果不存在则返回default或None |
d.__getitem__(k) | ● | ● | ● | d[k]—获取键为k的项 |
d.items() | ● | ● | ● | 获取项的视图—(key, value)对 |
d.__iter__() | ● | ● | ● | 获取键的迭代器 |
d.keys() | ● | ● | ● | 获取键的视图 |
d.__len__() | ● | ● | ● | len(d)—项数 |
d.__missing__(k) | ● | 当__getitem__找不到键时调用 | ||
d.move_to_end(k, [last]) | ● | 将k移动到第一个或最后一个位置(默认情况下last为True) | ||
d.__or__(other) | ● | ● | ● | 支持d1 | d2创建新的dict合并d1和d2(Python ≥ 3.9) |
d.__ior__(other) | ● | ● | ● | 支持d1 |= d2更新d1与d2(Python ≥ 3.9) |
d.pop(k, [default]) | ● | ● | ● | 移除并返回键为k的值,如果不存在则返回default或None |
d.popitem() | ● | ● | ● | 移除并返回最后插入的项为(key, value) ^(b) |
d.__reversed__() | ● | ● | ● | 支持reverse(d)—返回从最后插入到第一个插入的键的迭代器 |
d.__ror__(other) | ● | ● | ● | 支持other | dd—反向联合运算符(Python ≥ 3.9)^© |
d.setdefault(k, [default]) | ● | ● | ● | 如果k在d中,则返回d[k];否则设置d[k] = default并返回 |
d.__setitem__(k, v) | ● | ● | ● | d[k] = v—在k处放置v |
d.update(m, [**kwargs]) | ● | ● | ● | 使用映射或(key, value)对的可迭代对象更新d |
d.values() | ● | ● | ● | 获取视图的值 |
^(a) default_factory 不是一个方法,而是在实例化defaultdict时由最终用户设置的可调用属性。^(b) OrderedDict.popitem(last=False) 移除第一个插入的项目(FIFO)。last关键字参数在 Python 3.10b3 中不支持dict或defaultdict。^© 反向运算符在第十六章中有解释。 |
d.update(m) 处理其第一个参数m的方式是鸭子类型的一个典型例子:它首先检查m是否有一个keys方法,如果有,就假定它是一个映射。否则,update()会回退到迭代m,假设其项是(key, value)对。大多数 Python 映射的构造函数在内部使用update()的逻辑,这意味着它们可以从其他映射或从产生(key, value)对的任何可迭代对象初始化。
一种微妙的映射方法是setdefault()。当我们需要就地更新项目的值时,它避免了冗余的键查找。下一节将展示如何使用它。
插入或更新可变值
符合 Python 的失败快速哲学,使用d[k]访问dict时,当k不是现有键时会引发错误。Python 程序员知道,当默认值比处理KeyError更方便时,d.get(k, default)是d[k]的替代方案。然而,当您检索可变值并希望更新它时,有一种更好的方法。
考虑编写一个脚本来索引文本,生成一个映射,其中每个键是一个单词,值是该单词出现的位置列表,如示例 3-3 所示。
示例 3-3. 示例 3-4 处理“Python 之禅”时的部分输出;每行显示一个单词和一对出现的编码为(行号,列号)的列表。
$ python3 index0.py zen.txt
a [(19, 48), (20, 53)]
Although [(11, 1), (16, 1), (18, 1)]
ambiguity [(14, 16)]
and [(15, 23)]
are [(21, 12)]
aren [(10, 15)]
at [(16, 38)]
bad [(19, 50)]
be [(15, 14), (16, 27), (20, 50)]
beats [(11, 23)]
Beautiful [(3, 1)]
better [(3, 14), (4, 13), (5, 11), (6, 12), (7, 9), (8, 11), (17, 8), (18, 25)]
...
示例 3-4 是一个次优脚本,用于展示dict.get不是处理缺失键的最佳方式的一个案例。我从亚历克斯·马特利的一个示例中进行了改编。⁴
示例 3-4. index0.py 使用dict.get从索引中获取并更新单词出现列表的脚本(更好的解决方案在示例 3-5 中)
"""Build an index mapping word -> list of occurrences"""
import re
import sys
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
# this is ugly; coded like this to make a point
occurrences = index.get(word, []) # ①
occurrences.append(location) # ②
index[word] = occurrences # ③
# display in alphabetical order
for word in sorted(index, key=str.upper): # ④
print(word, index[word])
①
获取word的出现列表,如果找不到则为[]。
②
将新位置附加到occurrences。
③
将更改后的occurrences放入index字典中;这需要通过index进行第二次搜索。
④
在sorted的key=参数中,我没有调用str.upper,只是传递了对该方法的引用,以便sorted函数可以使用它来对单词进行规范化排序。⁵
示例 3-4 中处理occurrences的三行可以用dict.setdefault替换为一行。示例 3-5 更接近亚历克斯·马特利的代码。
示例 3-5. index.py 使用dict.setdefault从索引中获取并更新单词出现列表的脚本,一行搞定;与示例 3-4 进行对比
"""Build an index mapping word -> list of occurrences"""
import re
import sys
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
index.setdefault(word, []).append(location) # ①
# display in alphabetical order
for word in sorted(index, key=str.upper):
print(word, index[word])
①
获取word的出现列表,如果找不到则将其设置为[];setdefault返回值,因此可以在不需要第二次搜索的情况下进行更新。
换句话说,这行的最终结果是…
my_dict.setdefault(key, []).append(new_value)
…等同于运行…
if key not in my_dict:
my_dict[key] = []
my_dict[key].append(new_value)
…除了后者的代码至少执行两次对key的搜索—如果找不到,则执行三次—而setdefault只需一次查找就可以完成所有操作。
一个相关问题是,在任何查找中处理缺失键(而不仅仅是在插入时)是下一节的主题。
缺失键的自动处理
有时,当搜索缺失的键时返回一些虚构的值是很方便的。有两种主要方法:一种是使用defaultdict而不是普通的dict。另一种是子类化dict或任何其他映射类型,并添加一个__missing__方法。接下来将介绍这两种解决方案。
defaultdict:另一种处理缺失键的方法
一个collections.defaultdict实例在使用d[k]语法搜索缺失键时按需创建具有默认值的项目。示例 3-6 使用defaultdict提供了另一个优雅的解决方案来完成来自示例 3-5 的单词索引任务。
它的工作原理是:在实例化defaultdict时,你提供一个可调用对象,每当__getitem__传递一个不存在的键参数时产生一个默认值。
例如,给定一个创建为dd = defaultdict(list)的defaultdict,如果'new-key'不在dd中,表达式dd['new-key']会执行以下步骤:
-
调用
list()来创建一个新列表。 -
使用
'new-key'作为键将列表插入dd。 -
返回对该列表的引用。
产生默认值的可调用对象保存在名为default_factory的实例属性中。
示例 3-6。index_default.py:使用defaultdict而不是setdefault方法
"""Build an index mapping word -> list of occurrences"""
import collections
import re
import sys
WORD_RE = re.compile(r'\w+')
index = collections.defaultdict(list) # ①
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
index[word].append(location) # ②
# display in alphabetical order
for word in sorted(index, key=str.upper):
print(word, index[word])
①
使用list构造函数创建一个defaultdict作为default_factory。
②
如果word最初不在index中,则调用default_factory来生成缺失值,这种情况下是一个空的list,然后将其分配给index[word]并返回,因此.append(location)操作总是成功的。
如果没有提供default_factory,则对于缺失的键会引发通常的KeyError。
警告
defaultdict的default_factory仅在为__getitem__调用提供默认值时才会被调用,而不会为其他方法调用。例如,如果dd是一个defaultdict,k是一个缺失的键,dd[k]将调用default_factory来创建一个默认值,但dd.get(k)仍然返回None,k in dd为False。
使defaultdict工作的机制是调用default_factory的__missing__特殊方法,这是我们接下来要讨论的一个特性。
__missing__方法
映射处理缺失键的基础是名为__missing__的方法。这个方法在基本的dict类中没有定义,但dict知道它:如果你子类化dict并提供一个__missing__方法,标准的dict.__getitem__将在找不到键时调用它,而不是引发KeyError。
假设你想要一个映射,其中键在查找时被转换为str。一个具体的用例是物联网设备库,其中一个具有通用 I/O 引脚(例如树莓派或 Arduino)的可编程板被表示为一个Board类,具有一个my_board.pins属性,它是物理引脚标识符到引脚软件对象的映射。物理引脚标识符可能只是一个数字或一个字符串,如"A0"或"P9_12"。为了一致性,希望board.pins中的所有键都是字符串,但也方便通过数字查找引脚,例如my_arduino.pin[13],这样初学者在想要闪烁他们的 Arduino 上的 13 号引脚时不会出错。示例 3-7 展示了这样一个映射如何工作。
示例 3-7。当搜索非字符串键时,StrKeyDict0在未找到时将其转换为str
Tests for item retrieval using `d[key]` notation::
>>> d = StrKeyDict0([('2', 'two'), ('4', 'four')])
>>> d['2']
'two'
>>> d[4]
'four'
>>> d[1]
Traceback (most recent call last):
...
KeyError: '1'
Tests for item retrieval using `d.get(key)` notation::
>>> d.get('2')
'two'
>>> d.get(4)
'four'
>>> d.get(1, 'N/A')
'N/A'
Tests for the `in` operator::
>>> 2 in d
True
>>> 1 in d
False
示例 3-8 实现了一个通过前面的 doctests 的StrKeyDict0类。
提示
创建用户定义的映射类型的更好方法是子类化collections.UserDict而不是dict(正如我们将在示例 3-9 中所做的那样)。这里我们子类化dict只是为了展示内置的dict.__getitem__方法支持__missing__。
示例 3-8。StrKeyDict0在查找时将非字符串键转换为str(请参见示例 3-7 中的测试)
class StrKeyDict0(dict): # ①
def __missing__(self, key):
if isinstance(key, str): # ②
raise KeyError(key)
return self[str(key)] # ③
def get(self, key, default=None):
try:
return self[key] # ④
except KeyError:
return default # ⑤
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys() # ⑥
①
StrKeyDict0继承自dict。
②
检查key是否已经是str。如果是,并且它丢失了,那么引发KeyError。
③
从key构建str并查找它。
④
get方法通过使用self[key]符号委托给__getitem__;这给了我们的__missing__发挥作用的机会。
⑤
如果引发KeyError,则__missing__已经失败,因此我们返回default。
⑥
搜索未修改的键(实例可能包含非str键),然后搜索从键构建的str。
花点时间考虑一下为什么在__missing__实现中需要测试isinstance(key, str)。
没有这个测试,我们的__missing__方法对于任何键k——str或非str——都能正常工作,只要str(k)产生一个现有的键。但是如果str(k)不是一个现有的键,我们将会有一个无限递归。在__missing__的最后一行,self[str(key)]会调用__getitem__,传递那个str键,然后会再次调用__missing__。
在这个例子中,__contains__方法也是必需的,因为操作k in d会调用它,但从dict继承的方法不会回退到调用__missing__。在我们的__contains__实现中有一个微妙的细节:我们不是用通常的 Python 方式检查键——k in my_dict——因为str(key) in self会递归调用__contains__。我们通过在self.keys()中明确查找键来避免这种情况。
在 Python 3 中,像k in my_dict.keys()这样的搜索对于非常大的映射也是高效的,因为dict.keys()返回一个视图,类似于集合,正如我们将在“dict 视图上的集合操作”中看到的。然而,请记住,k in my_dict也能完成同样的工作,并且更快,因为它避免了查找属性以找到.keys方法。
我在示例 3-8 中的__contains__方法中有一个特定的原因使用self.keys()。检查未修改的键——key in self.keys()——对于正确性是必要的,因为StrKeyDict0不强制字典中的所有键都必须是str类型。我们这个简单示例的唯一目标是使搜索“更友好”,而不是强制类型。
警告
派生自标准库映射的用户定义类可能会或可能不会在它们的__getitem__、get或__contains__实现中使用__missing__作为回退,如下一节所述。
标准库中对__missing__的不一致使用
考虑以下情况,以及缺失键查找是如何受影响的:
dict子类
一个只实现__missing__而没有其他方法的dict子类。在这种情况下,__missing__只能在d[k]上调用,这将使用从dict继承的__getitem__。
collections.UserDict子类
同样,一个只实现__missing__而没有其他方法的UserDict子类。从UserDict继承的get方法调用__getitem__。这意味着__missing__可能被调用来处理d[k]和d.get(k)的查找。
具有最简单可能的__getitem__的abc.Mapping子类
一个实现了__missing__和所需抽象方法的最小的abc.Mapping子类,包括一个不调用__missing__的__getitem__实现。在这个类中,__missing__方法永远不会被触发。
具有调用__missing__的__getitem__的abc.Mapping子类
一个最小的abc.Mapping子类实现了__missing__和所需的抽象方法,包括调用__missing__的__getitem__的实现。在这个类中,对使用d[k]、d.get(k)和k in d进行的缺失键查找会触发__missing__方法。
在示例代码库中查看missing.py以演示这里描述的场景。
刚才描述的四种情况假设最小实现。如果你的子类实现了__getitem__、get和__contains__,那么你可以根据需要让这些方法使用__missing__或不使用。本节的重点是要表明,在子类化标准库映射时要小心使用__missing__,因为基类默认支持不同的行为。
不要忘记,setdefault和update的行为也受键查找影响。最后,根据你的__missing__的逻辑,你可能需要在__setitem__中实现特殊逻辑,以避免不一致或令人惊讶的行为。我们将在“Subclassing UserDict Instead of dict”中看到一个例子。
到目前为止,我们已经介绍了dict和defaultdict这两种映射类型,但标准库中还有其他映射实现,接下来我们将讨论它们。
dict 的变体
本节概述了标准库中包含的映射类型,除了已在“defaultdict: Another Take on Missing Keys”中介绍的defaultdict。
collections.OrderedDict
自从 Python 3.6 开始,内置的dict也保持了键的有序性,使用OrderedDict的最常见原因是编写与早期 Python 版本向后兼容的代码。话虽如此,Python 的文档列出了dict和OrderedDict之间的一些剩余差异,我在这里引用一下——只重新排列项目以便日常使用:
-
OrderedDict的相等操作检查匹配的顺序。 -
OrderedDict的popitem()方法具有不同的签名。它接受一个可选参数来指定要弹出的项目。 -
OrderedDict有一个move_to_end()方法,可以高效地将一个元素重新定位到末尾。 -
常规的
dict被设计为在映射操作方面非常出色。跟踪插入顺序是次要的。 -
OrderedDict被设计为在重新排序操作方面表现良好。空间效率、迭代速度和更新操作的性能是次要的。 -
从算法上讲,
OrderedDict比dict更擅长处理频繁的重新排序操作。这使得它适用于跟踪最近的访问(例如,在 LRU 缓存中)。
collections.ChainMap
ChainMap实例保存了一个可以作为一个整体搜索的映射列表。查找是按照构造函数调用中出现的顺序在每个输入映射上执行的,并且一旦在这些映射中的一个中找到键,查找就成功了。例如:
>>> d1 = dict(a=1, b=3)
>>> d2 = dict(a=2, b=4, c=6)
>>> from collections import ChainMap
>>> chain = ChainMap(d1, d2)
>>> chain['a']
1
>>> chain['c']
6
ChainMap实例不会复制输入映射,而是保留对它们的引用。对ChainMap的更新或插入只会影响第一个输入映射。继续上一个例子:
>>> chain['c'] = -1
>>> d1
{'a': 1, 'b': 3, 'c': -1}
>>> d2
{'a': 2, 'b': 4, 'c': 6}
ChainMap对于实现具有嵌套作用域的语言的解释器非常有用,其中每个映射表示一个作用域上下文,从最内部的封闭作用域到最外部作用域。collections文档中的“ChainMap objects”部分有几个ChainMap使用示例,包括这个受 Python 变量查找基本规则启发的代码片段:
import builtins
pylookup = ChainMap(locals(), globals(), vars(builtins))
示例 18-14 展示了一个用于实现 Scheme 编程语言子集解释器的ChainMap子类。
collections.Counter
一个为每个键保存整数计数的映射。更新现有键会增加其计数。这可用于计算可散列对象的实例数量或作为多重集(稍后在本节讨论)。Counter 实现了 + 和 - 运算符来组合计数,并提供其他有用的方法,如 most_common([n]),它返回一个按顺序排列的元组列表,其中包含 n 个最常见的项目及其计数;请参阅文档。这里是 Counter 用于计算单词中的字母:
>>> ct = collections.Counter('abracadabra')
>>> ct
Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.update('aaaaazzz')
>>> ct
Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.most_common(3)
[('a', 10), ('z', 3), ('b', 2)]
请注意,'b' 和 'r' 键并列第三,但 ct.most_common(3) 只显示了三个计数。
要将 collections.Counter 用作多重集,假装每个键是集合中的一个元素,计数是该元素在集合中出现的次数。
shelve.Shelf
标准库中的 shelve 模块为字符串键到以 pickle 二进制格式序列化的 Python 对象的映射提供了持久存储。当你意识到 pickle 罐子存放在架子上时,shelve 这个奇怪的名字就有了意义。
shelve.open 模块级函数返回一个 shelve.Shelf 实例——一个简单的键-值 DBM 数据库,由 dbm 模块支持,具有以下特点:
-
shelve.Shelf是abc.MutableMapping的子类,因此它提供了我们期望的映射类型的基本方法。 -
此外,
shelve.Shelf提供了一些其他的 I/O 管理方法,如sync和close。 -
Shelf实例是一个上下文管理器,因此您可以使用with块来确保在使用后关闭它。 -
每当将新值分配给键时,键和值都会被保存。
-
键必须是字符串。
-
值必须是
pickle模块可以序列化的对象。
shelve、dbm 和 pickle 模块的文档提供了更多细节和一些注意事项。
警告
Python 的 pickle 在最简单的情况下很容易使用,但也有一些缺点。在采用涉及 pickle 的任何解决方案之前,请阅读 Ned Batchelder 的“Pickle 的九个缺陷”。在他的帖子中,Ned 提到了其他要考虑的序列化格式。
OrderedDict、ChainMap、Counter 和 Shelf 都可以直接使用,但也可以通过子类化进行自定义。相比之下,UserDict 只是作为一个可扩展的基类。
通过继承 UserDict 而不是 dict 来创建新的映射类型
最好通过扩展 collections.UserDict 来创建新的映射类型,而不是 dict。当我们尝试扩展我们的 StrKeyDict0(来自示例 3-8)以确保将任何添加到映射中的键存储为 str 时,我们意识到这一点。
更好地通过子类化 UserDict 而不是 dict 的主要原因是,内置类型有一些实现快捷方式,最终迫使我们覆盖我们可以从 UserDict 继承而不会出现问题的方法。⁷
请注意,UserDict 不继承自 dict,而是使用组合:它有一个内部的 dict 实例,称为 data,用于保存实际的项目。这避免了在编写特殊方法如 __setitem__ 时出现不必要的递归,并简化了 __contains__ 的编写,与示例 3-8 相比更加简单。
由于 UserDict 的存在,StrKeyDict(示例 3-9)比 StrKeyDict0(示例 3-8)更简洁,但它做得更多:它将所有键都存储为 str,避免了如果实例被构建或更新时包含非字符串键时可能出现的令人不快的情况。
示例 3-9. StrKeyDict 在插入、更新和查找时总是将非字符串键转换为 str。
import collections
class StrKeyDict(collections.UserDict): # ①
def __missing__(self, key): # ②
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data # ③
def __setitem__(self, key, item):
self.data[str(key)] = item # ④
①
StrKeyDict 扩展了 UserDict。
②
__missing__ 与示例 3-8 中的一样。
③
__contains__ 更简单:我们可以假定所有存储的键都是 str,并且可以在 self.data 上进行检查,而不是像在 StrKeyDict0 中那样调用 self.keys()。
④
__setitem__ 将任何 key 转换为 str。当我们可以委托给 self.data 属性时,这种方法更容易被覆盖。
因为 UserDict 扩展了 abc.MutableMapping,使得使 StrKeyDict 成为一个完整的映射的剩余方法都是从 UserDict、MutableMapping 或 Mapping 继承的。尽管后者是抽象基类(ABC),但它们有几个有用的具体方法。以下方法值得注意:
MutableMapping.update
这种强大的方法可以直接调用,但也被 __init__ 用于从其他映射、从 (key, value) 对的可迭代对象和关键字参数加载实例。因为它使用 self[key] = value 来添加项目,所以最终会调用我们的 __setitem__ 实现。
Mapping.get
在 StrKeyDict0(示例 3-8)中,我们不得不编写自己的 get 来返回与 __getitem__ 相同的结果,但在 示例 3-9 中,我们继承了 Mapping.get,它的实现与 StrKeyDict0.get 完全相同(请参阅 Python 源代码)。
提示
安托万·皮特鲁(Antoine Pitrou)撰写了 PEP 455—向 collections 添加一个键转换字典 和一个增强 collections 模块的补丁,其中包括一个 TransformDict,比 StrKeyDict 更通用,并保留提供的键,然后应用转换。PEP 455 在 2015 年 5 月被拒绝—请参阅雷蒙德·赫廷格的 拒绝消息。为了尝试 TransformDict,我从 issue18986 中提取了皮特鲁的补丁,制作成了一个独立的模块(03-dict-set/transformdict.py 在 Fluent Python 第二版代码库 中)。
我们知道有不可变的序列类型,但不可变的映射呢?在标准库中确实没有真正的不可变映射,但有一个替代品可用。接下来是。
不可变映射
标准库提供的映射类型都是可变的,但您可能需要防止用户意外更改映射。再次在硬件编程库中找到一个具体的用例,比如 Pingo,在 “缺失方法” 中提到:board.pins 映射表示设备上的物理 GPIO 引脚。因此,防止意外更新 board.pins 是有用的,因为硬件不能通过软件更改,所以映射的任何更改都会使其与设备的物理现实不一致。
types 模块提供了一个名为 MappingProxyType 的包装类,给定一个映射,它返回一个 mappingproxy 实例,这是原始映射的只读但动态代理。这意味着可以在 mappingproxy 中看到对原始映射的更新,但不能通过它进行更改。参见 示例 3-10 进行简要演示。
示例 3-10. MappingProxyType 从 dict 构建一个只读的 mappingproxy 实例。
>>> from types import MappingProxyType
>>> d = {1: 'A'}
>>> d_proxy = MappingProxyType(d)
>>> d_proxy
mappingproxy({1: 'A'}) >>> d_proxy[1] # ①
'A' >>> d_proxy[2] = 'x' # ②
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'mappingproxy' object does not support item assignment
>>> d[2] = 'B'
>>> d_proxy # ③
mappingproxy({1: 'A', 2: 'B'}) >>> d_proxy[2]
'B' >>>
①
d 中的项目可以通过 d_proxy 看到。
②
不能通过 d_proxy 进行更改。
③
d_proxy 是动态的:d 中的任何更改都会反映出来。
在硬件编程场景中,这个方法在实践中可以这样使用:具体的 Board 子类中的构造函数会用 pin 对象填充一个私有映射,并通过一个实现为 mappingproxy 的公共 .pins 属性将其暴露给 API 的客户端。这样,客户端就无法意外地添加、删除或更改 pin。
接下来,我们将介绍视图—它允许在 dict 上进行高性能操作,而无需不必要地复制数据。
字典视图
dict实例方法.keys()、.values()和.items()返回类dict_keys、dict_values和dict_items的实例,分别。这些字典视图是dict实现中使用的内部数据结构的只读投影。它们避免了等效 Python 2 方法的内存开销,这些方法返回了重复数据的列表,这些数据已经在目标dict中,它们还替换了返回迭代器的旧方法。
示例 3-11 展示了所有字典视图支持的一些基本操作。
示例 3-11。.values()方法返回字典中值的视图
>>> d = dict(a=10, b=20, c=30)
>>> values = d.values()
>>> values
dict_values([10, 20, 30]) # ①
>>> len(values) # ②
3 >>> list(values) # ③
[10, 20, 30] >>> reversed(values) # ④
<dict_reversevalueiterator object at 0x10e9e7310> >>> values[0] # ⑤
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'dict_values' object is not subscriptable
①
视图对象的repr显示其内容。
②
我们可以查询视图的len。
③
视图是可迭代的,因此很容易从中创建列表。
④
视图实现了__reversed__,返回一个自定义迭代器。
⑤
我们不能使用[]从视图中获取单个项目。
视图对象是动态代理。如果源dict被更新,您可以立即通过现有视图看到更改。继续自示例 3-11:
>>> d['z'] = 99
>>> d
{'a': 10, 'b': 20, 'c': 30, 'z': 99}
>>> values
dict_values([10, 20, 30, 99])
类dict_keys、dict_values和dict_items是内部的:它们不通过__builtins__或任何标准库模块可用,即使你获得了其中一个的引用,也不能在 Python 代码中从头开始创建视图:
>>> values_class = type({}.values())
>>> v = values_class()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot create 'dict_values' instances
dict_values类是最简单的字典视图——它只实现了__len__、__iter__和__reversed__特殊方法。除了这些方法,dict_keys和dict_items实现了几个集合方法,几乎和frozenset类一样多。在我们讨论集合之后,我们将在“字典视图上的集合操作”中更多地谈到dict_keys和dict_items。
现在让我们看一些由dict在幕后实现的规则和提示。
dict工作方式的实际后果
Python 的dict的哈希表实现非常高效,但重要的是要了解这种设计的实际影响:
-
键必须是可散列的对象。它们必须实现适当的
__hash__和__eq__方法,如“什么是可散列”中所述。 -
通过键访问项目非常快速。一个
dict可能有数百万个键,但 Python 可以通过计算键的哈希码并推导出哈希表中的索引偏移量直接定位一个键,可能会有少量尝试来找到匹配的条目的开销。 -
键的顺序保留是 CPython 3.6 中
dict更紧凑的内存布局的副作用,在 3.7 中成为官方语言特性。 -
尽管其新的紧凑布局,字典不可避免地具有显着的内存开销。对于容器来说,最紧凑的内部数据结构将是一个指向项目的指针数组。⁸ 相比之下,哈希表需要存储更多的数据,而 Python 需要保持至少三分之一的哈希表行为空以保持高效。
-
为了节省内存,避免在
__init__方法之外创建实例属性。
最后一条关于实例属性的提示来自于 Python 的默认行为是将实例属性存储在一个特殊的__dict__属性中,这是一个附加到每个实例的dict。自从 Python 3.3 实现了PEP 412—Key-Sharing Dictionary以来,一个类的实例可以共享一个与类一起存储的公共哈希表。当__init__返回时,具有相同属性名称的每个新实例的__dict__都共享该公共哈希表。然后,每个实例的__dict__只能保存自己的属性值作为指针的简单数组。在__init__之后添加一个实例属性会强制 Python 为__dict__创建一个新的哈希表,用于该实例的__dict__(这是 Python 3.3 之前所有实例的默认行为)。根据 PEP 412,这种优化可以减少面向对象程序的内存使用量 10%至 20%。
紧凑布局和键共享优化的细节相当复杂。更多信息,请阅读fluentpython.com上的“集合和字典的内部”。
现在让我们深入研究集合。
集合理论
在 Python 中,集合并不新鲜,但仍然有些被低估。set类型及其不可变的姊妹frozenset首次出现在 Python 2.3 标准库中作为模块,并在 Python 2.6 中被提升为内置类型。
注意
在本书中,我使用“集合”一词来指代set和frozenset。当专门讨论set类型,我使用等宽字体:set。
集合是一组唯一对象。一个基本用例是去除重复项:
>>> l = ['spam', 'spam', 'eggs', 'spam', 'bacon', 'eggs']
>>> set(l)
{'eggs', 'spam', 'bacon'}
>>> list(set(l))
['eggs', 'spam', 'bacon']
提示
如果你想去除重复项但又保留每个项目的第一次出现的顺序,你现在可以使用一个普通的dict来实现,就像这样:
>>> dict.fromkeys(l).keys()
dict_keys(['spam', 'eggs', 'bacon'])
>>> list(dict.fromkeys(l).keys())
['spam', 'eggs', 'bacon']
集合元素必须是可散列的。set类型不可散列,因此你不能用嵌套的set实例构建一个set。但是frozenset是可散列的,所以你可以在set中包含frozenset元素。
除了强制唯一性外,集合类型还实现了许多集合操作作为中缀运算符,因此,给定两个集合a和b,a | b返回它们的并集,a & b计算交集,a - b表示差集,a ^ b表示对称差。巧妙地使用集合操作可以减少 Python 程序的行数和执行时间,同时使代码更易于阅读和理解——通过消除循环和条件逻辑。
例如,想象一下你有一个大型的电子邮件地址集合(haystack)和一个较小的地址集合(needles),你需要计算needles在haystack中出现的次数。由于集合交集(&运算符),你可以用一行代码实现这个功能(参见示例 3-12)。
示例 3-12. 计算在一个集合中针的出现次数,两者都是集合类型
found = len(needles & haystack)
没有交集运算符,你将不得不编写示例 3-13 来完成与示例 3-12 相同的任务。
示例 3-13. 计算在一个集合中针的出现次数(与示例 3-12 的结果相同)
found = 0
for n in needles:
if n in haystack:
found += 1
示例 3-12 比示例 3-13 运行速度稍快。另一方面,示例 3-13 适用于任何可迭代对象needles和haystack,而示例 3-12 要求两者都是集合。但是,如果你手头没有集合,你可以随时动态构建它们,就像示例 3-14 中所示。
示例 3-14. 计算在一个集合中针的出现次数;这些行适用于任何可迭代类型
found = len(set(needles) & set(haystack))
# another way:
found = len(set(needles).intersection(haystack))
当然,在构建示例 3-14 中的集合时会有额外的成本,但如果needles或haystack中的一个已经是一个集合,那么示例 3-14 中的替代方案可能比示例 3-13 更便宜。
任何前述示例中的一个都能在haystack中搜索 1,000 个元素,其中包含 10,000,000 个项目,大约需要 0.3 毫秒,即每个元素接近 0.3 微秒。
除了极快的成员测试(由底层哈希表支持),set 和 frozenset 内置类型提供了丰富的 API 来创建新集合或在set的情况下更改现有集合。我们将很快讨论这些操作,但首先让我们谈谈语法。
集合字面量
set字面量的语法—{1},{1, 2}等—看起来与数学符号一样,但有一个重要的例外:没有空set的字面表示,因此我们必须记得写set()。
语法怪癖
不要忘记,要创建一个空的set,应该使用没有参数的构造函数:set()。如果写{},你将创建一个空的dict—在 Python 3 中这一点没有改变。
在 Python 3 中,集合的标准字符串表示总是使用{…}符号,除了空集:
>>> s = {1}
>>> type(s)
<class 'set'>
>>> s
{1}
>>> s.pop()
1
>>> s
set()
字面set语法如{1, 2, 3}比调用构造函数(例如,set([1, 2, 3]))更快且更易读。后一种形式较慢,因为要评估它,Python 必须查找set名称以获取构造函数,然后构建一个列表,最后将其传递给构造函数。相比之下,要处理像{1, 2, 3}这样的字面量,Python 运行一个专门的BUILD_SET字节码。¹⁰
没有特殊的语法来表示frozenset字面量—它们必须通过调用构造函数创建。在 Python 3 中的标准字符串表示看起来像一个frozenset构造函数调用。请注意控制台会话中的输出:
>>> frozenset(range(10))
frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
谈到语法,列表推导的想法也被用来构建集合。
集合推导式
集合推导式(setcomps)在 Python 2.7 中添加,与我们在“dict 推导式”中看到的 dictcomps 一起。示例 3-15 展示了如何。
示例 3-15. 构建一个拉丁-1 字符集,其中 Unicode 名称中包含“SIGN”一词
>>> from unicodedata import name # ①
>>> {chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i),'')} # ②
{'§', '=', '¢', '#', '¤', '<', '¥', 'µ', '×', '$', '¶', '£', '©', '°', '+', '÷', '±', '>', '¬', '®', '%'}
①
从unicodedata导入name函数以获取字符名称。
②
构建字符集,其中字符代码从 32 到 255,名称中包含 'SIGN' 一词。
输出的顺序会因为“什么是可哈希的”中提到的盐哈希而对每个 Python 进程进行更改。
语法问题在一边,现在让我们考虑集合的行为。
集合工作方式的实际后果
set 和 frozenset 类型都是使用哈希表实现的。这会产生以下影响:
-
集合元素必须是可哈希对象。它们必须实现适当的
__hash__和__eq__方法,如“什么是可哈希的”中所述。 -
成员测试非常高效。一个集合可能有数百万个元素,但可以通过计算其哈希码并推导出索引偏移量来直接定位一个元素,可能需要少量尝试来找到匹配的元素或耗尽搜索。
-
与低级数组指针相比,集合具有显着的内存开销—后者更紧凑但搜索超过少量元素时也更慢。
-
元素顺序取决于插入顺序,但并不是以有用或可靠的方式。如果两个元素不同但具有相同的哈希码,则它们的位置取决于哪个元素先添加。
-
向集合添加元素可能会改变现有元素的顺序。这是因为如果哈希表超过三分之二满,算法会变得不那么高效,因此 Python 可能需要在增长时移动和调整表格。当发生这种情况时,元素将被重新插入,它们的相对顺序可能会改变。
详细信息请参见“集合和字典的内部”在fluentpython.com。
现在让我们来看看集合提供的丰富操作。
集合操作
| | | s.difference(it, …) | s 和从可迭代对象 it 构建的所有集合的差集 |
| S ⊆ Z | s <= z | s.__le__(z) | s 是 z 集合的子集 |
费曼学习法的灵感源于理查德·费曼,这位物理学诺贝尔奖得主。

| | | | |
| 数学符号 | Python 运算符 | 方法 | 描述 |
s.intersection(it, …) | s 和从可迭代对象 it 构建的所有集合的交集 | ||
|---|---|---|---|
s -= z | s.__isub__(z) | s 更新为 s 和 z 的差集 | |
| S \ Z | s - z | s.__sub__(z) | s 和 z 的相对补集或差集 |
z ^ s | s.__rxor__(z) | 反转 ^ 运算符 | |
s.difference_update(it, …) | s 更新为 s 和从可迭代对象 it 构建的所有集合的差集 | ||
s &= z | s.__iand__(z) | s 更新为 s 和 z 的交集 | |
s.union(it, …) | s 和从可迭代对象 it 构建的所有集合的并集 | ||
图 3-2 概述了可变和不可变集合上可用的方法。其中许多是重载运算符的特殊方法,如 & 和 >=。表 3-2 显示了在 Python 中具有对应运算符或方法的数学集合运算符。请注意,一些运算符和方法会对目标集合进行就地更改(例如 &=,difference_update 等)。这样的操作在数学集合的理想世界中毫无意义,并且在 frozenset 中未实现。 | |||
s.update(it, …) | s 更新为 s 和从可迭代对象 it 构建的所有集合的并集 | ||
z & s | s.__rand__(z) | 反转 & 运算符 | |
| S ∆ Z | s ^ z | s.__xor__(z) | 对称差集(s & z 的补集) |
| 表 3-2. 数学集合操作:这些方法要么生成新集合,要么在原地更新目标集合(如果可变) | |||
| S ∩ Z = ∅ | s.isdisjoint(z) | s 和 z 互不相交(没有共同元素) | |
s.symmetric_difference(it) | s & set(it) 的补集 | ||
| S ∩ Z | s & z | s.__and__(z) | s 和 z 的交集 |
使用费曼的技巧,你可以在短短20 min内深入理解知识点,而且记忆深刻,难以遗忘。 | |||
s ^= z | s.__ixor__(z) | s 更新为 s 和 z 的对称差集 | |
| S ∪ Z | s | z | s.__or__(z) | s 和 z 的并集 |
| e ∈ S | e in s | s.__contains__(e) | 元素 e 是 s 的成员 |
s.intersection_update(it, …) | s 更新为 s 和从可迭代对象 it 构建的所有集合的交集 | ||
| 数学符号 | Python 运算符 | 方法 | 描述 |
| 表 3-3. 返回布尔值的集合比较运算符和方法 | |||
s.symmetric_difference_update(it, …) | s 更新为 s 和从可迭代对象 it 构建的所有集合的对称差 |
提示
| | | | |
| 表 3-3 列出了集合谓词:返回 True 或 False 的运算符和方法。 |
| — | — | — | — |
|---|---|---|---|
图 3-2. MutableSet 及其来自 collections.abc 的超类的简化 UML 类图(斜体名称为抽象类和抽象方法;为简洁起见省略了反转运算符方法) | |||
z | s | s.__ror__(z) | 反转 | 运算符 | |
z - s | s.__rsub__(z) | 反转 - 运算符 | |
s |= z | s.__ior__(z) | s 更新为 s 和 z 的并集 | |
s.issubset(it) | s 是从可迭代对象 it 构建的集合的子集 | ||
| S ⊂ Z | s < z | s.__lt__(z) | s 是 z 集合的真子集 |
| S ⊇ Z | s >= z | s.__ge__(z) | s 是 z 集合的超集 |
s.issuperset(it) | s 是从可迭代对象 it 构建的集合的超集 | ||
| S ⊃ Z | s > z | s.__gt__(z) | s 是 z 集合的真超集 |
除了从数学集合理论中派生的运算符和方法外,集合类型还实现了其他实用的方法,总结在表 3-4 中。
表 3-4. 额外的集合方法
| 集合 | 冻结集合 | ||
|---|---|---|---|
s.add(e) | ● | 向 s 添加元素 e | |
s.clear() | ● | 移除 s 的所有元素 | |
s.copy() | ● | ● | s 的浅复制 |
s.discard(e) | ● | 如果存在则从 s 中移除元素 e | |
s.__iter__() | ● | ● | 获取 s 的迭代器 |
s.__len__() | ● | ● | len(s) |
s.pop() | ● | 从 s 中移除并返回一个元素,如果 s 为空则引发 KeyError | |
s.remove(e) | ● | 从 s 中移除元素 e,如果 e 不在 s 中则引发 KeyError |
这完成了我们对集合特性的概述。如“字典视图”中承诺的,我们现在将看到两种字典视图类型的行为非常类似于 frozenset。
字典视图上的集合操作
表 3-5 显示了由 dict 方法 .keys() 和 .items() 返回的视图对象与 frozenset 非常相似。
表 3-5. frozenset、dict_keys 和 dict_items 实现的方法
| 冻结集合 | dict_keys | dict_items | 描述 | |
|---|---|---|---|---|
s.__and__(z) | ● | ● | ● | s & z(s 和 z 的交集) |
s.__rand__(z) | ● | ● | ● | 反转 & 运算符 |
s.__contains__() | ● | ● | ● | e in s |
s.copy() | ● | s 的浅复制 | ||
s.difference(it, …) | ● | s 和可迭代对象 it 等的差集 | ||
s.intersection(it, …) | ● | s 和可迭代对象 it 等的交集 | ||
s.isdisjoint(z) | ● | ● | ● | s 和 z 不相交(没有共同元素) |
s.issubset(it) | ● | s 是可迭代对象 it 的子集 | ||
s.issuperset(it) | ● | s 是可迭代对象 it 的超集 | ||
s.__iter__() | ● | ● | ● | 获取 s 的迭代器 |
s.__len__() | ● | ● | ● | len(s) |
s.__or__(z) | ● | ● | ● | s | z(s 和 z 的并集) |
s.__ror__() | ● | ● | ● | 反转 | 运算符 |
s.__reversed__() | ● | ● | 获取 s 的反向迭代器 | |
s.__rsub__(z) | ● | ● | ● | 反转 - 运算符 |
s.__sub__(z) | ● | ● | ● | s - z(s 和 z 之间的差集) |
s.symmetric_difference(it) | ● | s & set(it) 的补集 | ||
s.union(it, …) | ● | s 和可迭代对象 it 等的并集 | ||
s.__xor__() | ● | ● | ● | s ^ z(s 和 z 的对称差集) |
s.__rxor__() | ● | ● | ● | 反转 ^ 运算符 |
特别地,dict_keys 和 dict_items 实现了支持强大的集合运算符 &(交集)、|(并集)、-(差集)和 ^(对称差集)的特殊方法。
例如,使用 & 很容易获得出现在两个字典中的键:
>>> d1 = dict(a=1, b=2, c=3, d=4)
>>> d2 = dict(b=20, d=40, e=50)
>>> d1.keys() & d2.keys()
{'b', 'd'}
请注意 & 的返回值是一个 set。更好的是:字典视图中的集合运算符与 set 实例兼容。看看这个:
>>> s = {'a', 'e', 'i'}
>>> d1.keys() & s
{'a'}
>>> d1.keys() | s
{'a', 'c', 'b', 'd', 'i', 'e'}
警告
一个 dict_items 视图仅在字典中的所有值都是可哈希的情况下才能作为集合使用。尝试在具有不可哈希值的 dict_items 视图上进行集合操作会引发 TypeError: unhashable type 'T',其中 T 是有问题值的类型。
另一方面,dict_keys 视图始终可以用作集合,因为每个键都是可哈希的—按定义。
使用视图和集合运算符将节省大量循环和条件语句,当检查代码中字典内容时,让 Python 在 C 中高效实现为您工作!
就这样,我们可以结束这一章了。
章节总结
字典是 Python 的基石。多年来,熟悉的 {k1: v1, k2: v2} 文字语法得到了增强,支持使用 **、模式匹配以及 dict 推导式。
除了基本的 dict,标准库还提供了方便、即用即用的专用映射,如 defaultdict、ChainMap 和 Counter,都定义在 collections 模块中。随着新的 dict 实现,OrderedDict 不再像以前那样有用,但应该保留在标准库中以保持向后兼容性,并具有 dict 没有的特定特性,例如在 == 比较中考虑键的顺序。collections 模块中还有 UserDict,一个易于使用的基类,用于创建自定义映射。
大多数映射中可用的两个强大方法是 setdefault 和 update。setdefault 方法可以更新持有可变值的项目,例如在 list 值的 dict 中,避免为相同键进行第二次搜索。update 方法允许从任何其他映射、提供 (key, value) 对的可迭代对象以及关键字参数进行批量插入或覆盖项目。映射构造函数也在内部使用 update,允许实例从映射、可迭代对象或关键字参数初始化。自 Python 3.9 起,我们还可以使用 |= 运算符更新映射,使用 | 运算符从两个映射的并集创建一个新映射。
映射 API 中一个巧妙的钩子是 __missing__ 方法,它允许你自定义当使用 d[k] 语法(调用 __getitem__)时找不到键时发生的情况。
collections.abc 模块提供了 Mapping 和 MutableMapping 抽象基类作为标准接口,对于运行时类型检查非常有用。types 模块中的 MappingProxyType 创建了一个不可变的外观,用于保护不希望意外更改的映射。还有用于 Set 和 MutableSet 的抽象基类。
字典视图是 Python 3 中的一个重要补充,消除了 Python 2 中 .keys()、.values() 和 .items() 方法造成的内存开销,这些方法构建了重复数据的列表,复制了目标 dict 实例中的数据。此外,dict_keys 和 dict_items 类支持 frozenset 的最有用的运算符和方法。
进一步阅读
在 Python 标准库文档中,“collections—Container datatypes” 包括了几种映射类型的示例和实用配方。模块 Lib/collections/init.py 的 Python 源代码是任何想要创建新映射类型或理解现有映射逻辑的人的绝佳参考。David Beazley 和 Brian K. Jones 的 Python Cookbook, 3rd ed.(O’Reilly)第一章有 20 个方便而富有见地的数据结构配方,其中大部分使用 dict 以巧妙的方式。
Greg Gandenberger 主张继续使用 collections.OrderedDict,理由是“显式胜于隐式”,向后兼容性,以及一些工具和库假定 dict 键的顺序是无关紧要的。他的帖子:“Python Dictionaries Are Now Ordered. Keep Using OrderedDict”。
PEP 3106—Revamping dict.keys(), .values() and .items() 是 Guido van Rossum 为 Python 3 提出字典视图功能的地方。在摘要中,他写道这个想法来自于 Java 集合框架。
PyPy是第一个实现 Raymond Hettinger 提出的紧凑字典建议的 Python 解释器,他们在“PyPy 上更快、更节省内存和更有序的字典”中发表了博客,承认 PHP 7 中采用了类似的布局,描述在PHP 的新哈希表实现中。当创作者引用先前的作品时,总是很棒。
在 PyCon 2017 上,Brandon Rhodes 介绍了“字典更强大”,这是他经典动画演示“强大的字典”的续集——包括动画哈希冲突!另一部更加深入的关于 Python dict内部的视频是由 Raymond Hettinger 制作的“现代字典”,他讲述了最初未能向 CPython 核心开发人员推销紧凑字典的经历,他游说了 PyPy 团队,他们采纳了这个想法,这个想法得到了推广,并最终由 INADA Naoki 贡献给了 CPython 3.6,详情请查看Objects/dictobject.c中的 CPython 代码的详细注释和设计文档Objects/dictnotes.txt。
为了向 Python 添加集合的原因在PEP 218—添加内置集合对象类型中有记录。当 PEP 218 被批准时,没有采用特殊的文字语法来表示集合。set文字是为 Python 3 创建的,并与dict和set推导一起回溯到 Python 2.7。在 PyCon 2019 上,我介绍了“集合实践:从 Python 的集合类型中学习”,描述了实际程序中集合的用例,涵盖了它们的 API 设计以及使用位向量而不是哈希表的整数元素的集合类uintset的实现,灵感来自于 Alan Donovan 和 Brian Kernighan 的优秀著作The Go Programming Language第六章中的一个示例(Addison-Wesley)。
IEEE 的Spectrum杂志有一篇关于汉斯·彼得·卢恩的故事,他是一位多产的发明家,他申请了一项关于根据可用成分选择鸡尾酒配方的穿孔卡片盒的专利,以及其他包括…哈希表在内的多样化发明!请参阅“汉斯·彼得·卢恩和哈希算法的诞生”。
¹ 通过调用 ABC 的.register()方法注册的任何类都是虚拟子类,如“ABC 的虚拟子类”中所解释的。如果设置了特定的标记位,通过 Python/C API 实现的类型也是合格的。请参阅Py_TPFLAGS_MAPPING。
² Python 术语表中关于“可散列”的条目使用“哈希值”一词,而不是哈希码。我更喜欢哈希码,因为在映射的上下文中经常讨论这个概念,其中项由键和值组成,因此提到哈希码作为值可能会令人困惑。在本书中,我只使用哈希码。
³ 请参阅PEP 456—安全和可互换的哈希算法以了解安全性问题和采用的解决方案。
⁴ 原始脚本出现在 Martelli 的“重新学习 Python”演示的第 41 页中。他的脚本实际上是dict.setdefault的演示,如我们的示例 3-5 所示。
⁵ 这是将方法作为一等函数使用的示例,是第七章的主题。
⁶ 其中一个库是Pingo.io,目前已不再进行活跃开发。
⁷ 关于子类化dict和其他内置类型的确切问题在“子类化内置类型是棘手的”中有所涵盖。
⁸ 这就是元组的存储方式。
⁹ 除非类有一个__slots__属性,如“使用 slots 节省内存”中所解释的那样。
¹⁰ 这可能很有趣,但并不是非常重要。加速只会在评估集合字面值时发生,而这最多只会发生一次 Python 进程—当模块最初编译时。如果你好奇,可以从dis模块中导入dis函数,并使用它来反汇编set字面值的字节码—例如,dis('{1}')—和set调用—dis('set([1])')。
第四章:Unicode 文本与字节
人类使用文本。计算机使用字节。
Esther Nam 和 Travis Fischer,“Python 中的字符编码和 Unicode”¹
Python 3 引入了人类文本字符串和原始字节序列之间的明显区别。将字节序列隐式转换为 Unicode 文本已经成为过去。本章涉及 Unicode 字符串、二进制序列以及用于在它们之间转换的编码。
根据您在 Python 中的工作类型,您可能认为理解 Unicode 并不重要。这不太可能,但无论如何,无法避免str与byte之间的分歧。作为奖励,您会发现专门的二进制序列类型提供了 Python 2 通用str类型没有的功能。
在本章中,我们将讨论以下主题:
-
字符、代码点和字节表示
-
二进制序列的独特特性:
bytes、bytearray和memoryview -
完整 Unicode 和传统字符集的编码
-
避免和处理编码错误
-
处理文本文件时的最佳实践
-
默认编码陷阱和标准 I/O 问题
-
使用规范化进行安全的 Unicode 文本比较
-
用于规范化、大小写折叠和强制去除变音符号的实用函数
-
使用
locale和pyuca库正确对 Unicode 文本进行排序 -
Unicode 数据库中的字符元数据
-
处理
str和bytes的双模式 API
本章新内容
Python 3 中对 Unicode 的支持是全面且稳定的,因此最值得注意的新增内容是“按名称查找字符”,描述了一种用于搜索 Unicode 数据库的实用程序——这是从命令行查找带圈数字和微笑猫的好方法。
值得一提的一项较小更改是关于 Windows 上的 Unicode 支持,自 Python 3.6 以来更好且更简单,我们将在“注意编码默认值”中看到。
让我们从不那么新颖但基础的概念开始,即字符、代码点和字节。
注意
对于第二版,我扩展了关于struct模块的部分,并在fluentpython.com的伴随网站上发布了在线版本“使用 struct 解析二进制记录”。
在那里,您还会发现“构建多字符表情符号”,描述如何通过组合 Unicode 字符制作国旗、彩虹旗、不同肤色的人以及多样化家庭图标。
字符问题
“字符串”的概念足够简单:字符串是字符序列。问题在于“字符”的定义。
在 2021 年,我们对“字符”的最佳定义是 Unicode 字符。因此,我们从 Python 3 的str中获取的项目是 Unicode 字符,就像在 Python 2 中的unicode对象中获取的项目一样——而不是从 Python 2 的str中获取的原始字节。
Unicode 标准明确将字符的身份与特定字节表示分开:
-
字符的身份——其代码点——是从 0 到 1,114,111(十进制)的数字,在 Unicode 标准中显示为带有“U+”前缀的 4 到 6 位十六进制数字,从 U+0000 到 U+10FFFF。例如,字母 A 的代码点是 U+0041,欧元符号是 U+20AC,音乐符号 G 谱号分配给代码点 U+1D11E。在 Unicode 13.0.0 中,约 13%的有效代码点有字符分配给它们,这是 Python 3.10.0b4 中使用的标准。
-
表示字符的实际字节取决于正在使用的编码。编码是一种将代码点转换为字节序列及其反向转换的算法。字母 A(U+0041)的代码点在 UTF-8 编码中被编码为单个字节
\x41,在 UTF-16LE 编码中被编码为两个字节\x41\x00。另一个例子,UTF-8 需要三个字节—\xe2\x82\xac—来编码欧元符号(U+20AC),但在 UTF-16LE 中,相同的代码点被编码为两个字节:\xac\x20。
从代码点转换为字节是编码;从字节转换为代码点是解码。参见 示例 4-1。
示例 4-1. 编码和解码
>>> s = 'café'
>>> len(s) # ①
4
>>> b = s.encode('utf8') # ②
>>> b
b'caf\xc3\xa9' # ③
>>> len(b) # ④
5
>>> b.decode('utf8') # ⑤
'café'
①
str 'café' 有四个 Unicode 字符。
②
使用 UTF-8 编码将 str 编码为 bytes。
③
bytes 字面量有一个 b 前缀。
④
bytes b 有五个字节(“é”的代码点在 UTF-8 中编码为两个字节)。
⑤
使用 UTF-8 编码将 bytes 解码为 str。
提示
如果你需要一个记忆辅助来帮助区分 .decode() 和 .encode(),说服自己字节序列可以是晦涩的机器核心转储,而 Unicode str 对象是“人类”文本。因此,将 bytes 解码 为 str 以获取可读文本是有意义的,而将 str 编码 为 bytes 用于存储或传输也是有意义的。
尽管 Python 3 的 str 在很大程度上就是 Python 2 的 unicode 类型换了个新名字,但 Python 3 的 bytes 并不仅仅是旧的 str 更名,还有与之密切相关的 bytearray 类型。因此,在进入编码/解码问题之前,值得看一看二进制序列类型。
字节要点
新的二进制序列类型在许多方面与 Python 2 的 str 不同。首先要知道的是,有两种基本的内置二进制序列类型:Python 3 中引入的不可变 bytes 类型和早在 Python 2.6 中添加的可变 bytearray。² Python 文档有时使用通用术语“字节字符串”来指代 bytes 和 bytearray。我避免使用这个令人困惑的术语。
bytes 或 bytearray 中的每个项都是从 0 到 255 的整数,而不是像 Python 2 的 str 中的单个字符字符串。然而,二进制序列的切片始终产生相同类型的二进制序列,包括长度为 1 的切片。参见 示例 4-2。
示例 4-2. 作为 bytes 和 bytearray 的五字节序列
>>> cafe = bytes('café', encoding='utf_8') # ①
>>> cafe
b'caf\xc3\xa9' >>> cafe[0] # ②
99 >>> cafe[:1] # ③
b'c' >>> cafe_arr = bytearray(cafe)
>>> cafe_arr # ④
bytearray(b'caf\xc3\xa9') >>> cafe_arr[-1:] # ⑤
bytearray(b'\xa9')
①
可以从 str 构建 bytes,并给定一个编码。
②
每个项都是 range(256) 中的整数。
③
bytes 的切片也是 bytes ——即使是单个字节的切片。
④
bytearray 没有字面量语法:它们显示为带有 bytes 字面量作为参数的 bytearray()。
⑤
bytearray 的切片也是 bytearray。
警告
my_bytes[0] 检索一个 int,但 my_bytes[:1] 返回长度为 1 的 bytes 序列,这只是因为我们习惯于 Python 的 str 类型,其中 s[0] == s[:1]。对于 Python 中的所有其他序列类型,1 项不等于长度为 1 的切片。
尽管二进制序列实际上是整数序列,但它们的字面值表示反映了 ASCII 文本经常嵌入其中的事实。因此,根据每个字节值的不同,使用四种不同的显示方式:
-
对于十进制代码为 32 到 126 的字节——从空格到
~(波浪号)——使用 ASCII 字符本身。 -
对于制表符、换行符、回车符和
\对应的字节,使用转义序列\t、\n、\r和\\。 -
如果字节序列中同时出现字符串定界符
'和",则整个序列由'定界,并且任何'都会被转义为\'。³ -
对于其他字节值,使用十六进制转义序列(例如,
\x00是空字节)。
这就是为什么在 示例 4-2 中你会看到 b'caf\xc3\xa9':前三个字节 b'caf' 在可打印的 ASCII 范围内,而最后两个不在范围内。
bytes和bytearray都支持除了依赖于 Unicode 数据的格式化方法(format,format_map)和那些依赖于 Unicode 数据的方法(包括casefold,isdecimal,isidentifier,isnumeric,isprintable和encode)之外的所有str方法。这意味着您可以使用熟悉的字符串方法,如endswith,replace,strip,translate,upper等,与二进制序列一起使用——只使用bytes而不是str参数。此外,如果正则表达式是从二进制序列而不是str编译而成,则re模块中的正则表达式函数也适用于二进制序列。自 Python 3.5 以来,%运算符再次适用于二进制序列。⁴
二进制序列有一个str没有的类方法,称为fromhex,它通过解析以空格分隔的十六进制数字对构建二进制序列:
>>> bytes.fromhex('31 4B CE A9')
b'1K\xce\xa9'
构建bytes或bytearray实例的其他方法是使用它们的构造函数,并提供:
-
一个
str和一个encoding关键字参数 -
一个可提供值从 0 到 255 的项目的可迭代对象
-
一个实现缓冲区协议的对象(例如,
bytes,bytearray,memoryview,array.array),它将源对象的字节复制到新创建的二进制序列中
警告
直到 Python 3.5,还可以使用单个整数调用bytes或bytearray来创建一个以空字节初始化的该大小的二进制序列。这个签名在 Python 3.5 中被弃用,并在 Python 3.6 中被移除。请参阅PEP 467—二进制序列的次要 API 改进。
从类似缓冲区的对象构建二进制序列是一个涉及类型转换的低级操作。在示例 4-3 中看到演示。
示例 4-3。从数组的原始数据初始化字节
>>> import array
>>> numbers = array.array('h', [-2, -1, 0, 1, 2]) # ①
>>> octets = bytes(numbers) # ②
>>> octets
b'\xfe\xff\xff\xff\x00\x00\x01\x00\x02\x00' # ③
①
类型码'h'创建一个短整数(16 位)的array。
②
octets保存构成numbers的字节的副本。
③
这是代表 5 个短整数的 10 个字节。
从任何类似缓冲区的源创建bytes或bytearray对象将始终复制字节。相反,memoryview对象允许您在二进制数据结构之间共享内存,正如我们在“内存视图”中看到的那样。
在这对 Python 中二进制序列类型的基本探索之后,让我们看看它们如何转换为/从字符串。
基本编码器/解码器
Python 发行版捆绑了 100 多个编解码器(编码器/解码器),用于文本到字节的转换以及反之。每个编解码器都有一个名称,如'utf_8',通常还有别名,如'utf8','utf-8'和'U8',您可以将其用作函数中的encoding参数,如open(),str.encode(),bytes.decode()等。示例 4-4 展示了相同文本编码为三种不同的字节序列。
示例 4-4。使用三种编解码器对字符串“El Niño”进行编码,生成非常不同的字节序列
>>> for codec in ['latin_1', 'utf_8', 'utf_16']:
... print(codec, 'El Niño'.encode(codec), sep='\t')
...
latin_1 b'El Ni\xf1o'
utf_8 b'El Ni\xc3\xb1o'
utf_16 b'\xff\xfeE\x00l\x00 \x00N\x00i\x00\xf1\x00o\x00'
图 4-1 展示了各种编解码器从字符(如字母“A”到 G 大调音符)生成字节的情况。请注意,最后三种编码是可变长度的多字节编码。
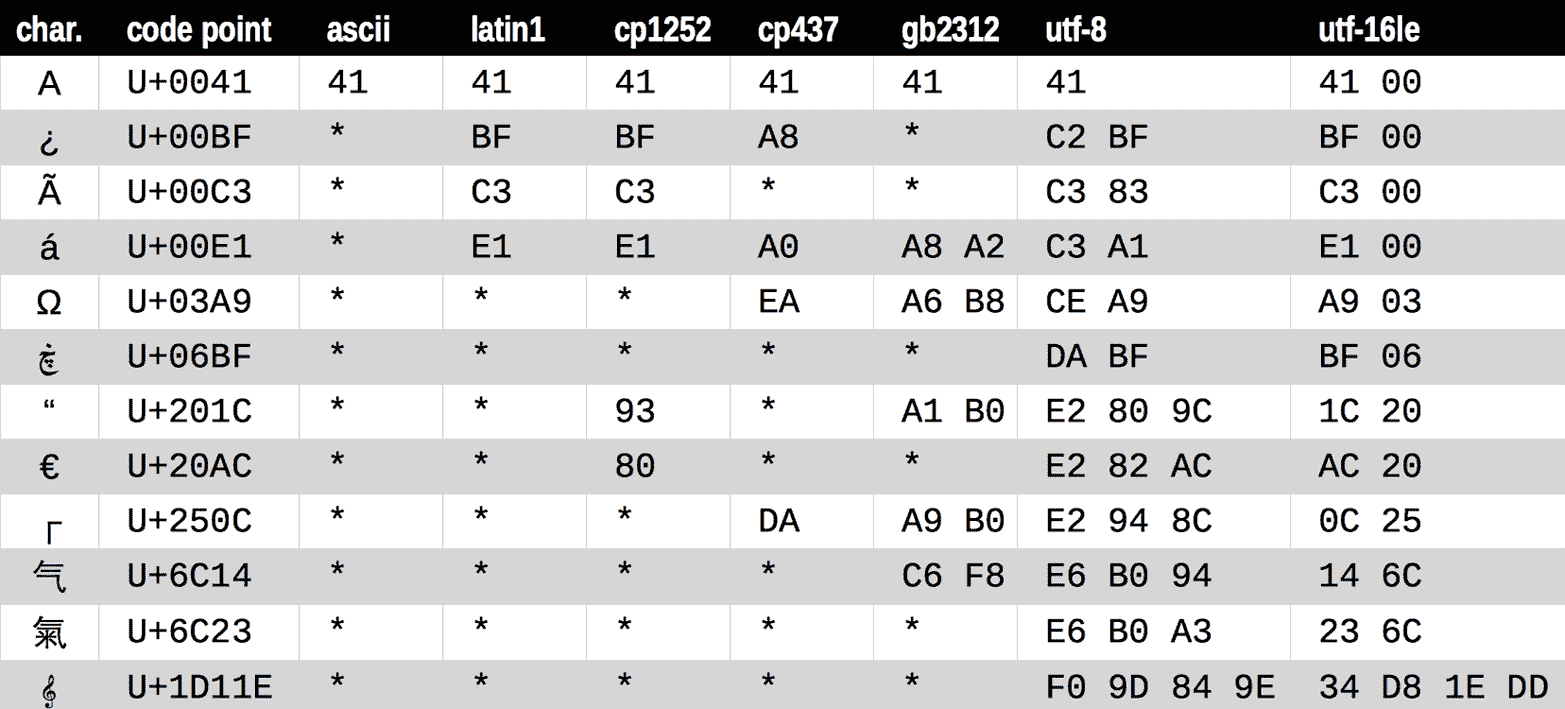
图 4-1。十二个字符,它们的代码点以及它们在 7 种不同编码中的字节表示(星号表示该字符无法在该编码中表示)。
图 4-1 中所有那些星号清楚地表明,一些编码,如 ASCII 甚至多字节 GB2312,无法表示每个 Unicode 字符。然而,UTF 编码被设计用于处理每个 Unicode 代码点。
在图 4-1 中显示的编码被选为代表性样本:
latin1又称iso8859_1
重要,因为它是其他编码的基础,例如cp1252和 Unicode 本身(注意latin1字节值如何出现在cp1252字节和代码点中)。
cp1252
由 Microsoft 创建的有用的latin1超集,添加了诸如弯引号和€(欧元)等有用符号;一些 Windows 应用程序称其为“ANSI”,但它从未是真正的 ANSI 标准。
cp437
IBM PC 的原始字符集,带有绘制框线字符。与latin1不兼容,后者出现得更晚。
gb2312
用于编码中国大陆使用的简体中文汉字的传统标准;亚洲语言的几种广泛部署的多字节编码之一。
utf-8
截至 2021 年 7 月,网络上最常见的 8 位编码远远是 UTF-8,“W³Techs:网站字符编码使用统计”声称 97% 的网站使用 UTF-8,这比我在 2014 年 9 月第一版书中写这段话时的 81.4% 要高。
utf-16le
UTF 16 位编码方案的一种形式;所有 UTF-16 编码通过称为“代理对”的转义序列支持 U+FFFF 之上的代码点。
警告
UTF-16 在 1996 年取代了原始的 16 位 Unicode 1.0 编码——UCS-2。尽管 UCS-2 自上个世纪以来已被弃用,但仍在许多系统中使用,因为它仅支持到 U+FFFF 的代码点。截至 2021 年,超过 57% 的分配代码点在 U+FFFF 以上,包括所有重要的表情符号。
现在完成了对常见编码的概述,我们将转向处理编码和解码操作中的问题。
理解编码/解码问题
尽管存在一个通用的UnicodeError异常,Python 报告的错误通常更具体:要么是UnicodeEncodeError(将str转换为二进制序列时),要么是UnicodeDecodeError(将二进制序列读入str时)。加载 Python 模块时,如果源编码意外,则还可能引发SyntaxError。我们将在接下来的部分展示如何处理所有这些错误。
提示
当遇到 Unicode 错误时,首先要注意异常的确切类型。它是UnicodeEncodeError、UnicodeDecodeError,还是提到编码问题的其他错误(例如SyntaxError)?要解决问题,首先必须理解它。
处理 UnicodeEncodeError
大多数非 UTF 编解码器仅处理 Unicode 字符的一小部分。将文本转换为字节时,如果目标编码中未定义字符,则会引发UnicodeEncodeError,除非通过向编码方法或函数传递errors参数提供了特殊处理。错误处理程序的行为显示在示例 4-5 中。
示例 4-5. 编码为字节:成功和错误处理
>>> city = 'São Paulo'
>>> city.encode('utf_8') # ①
b'S\xc3\xa3o Paulo' >>> city.encode('utf_16')
b'\xff\xfeS\x00\xe3\x00o\x00 \x00P\x00a\x00u\x00l\x00o\x00' >>> city.encode('iso8859_1') # ②
b'S\xe3o Paulo' >>> city.encode('cp437') # ③
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/.../lib/python3.4/encodings/cp437.py", line 12, in encode
return codecs.charmap_encode(input,errors,encoding_map)
UnicodeEncodeError: 'charmap' codec can't encode character '\xe3' in
position 1: character maps to <undefined> >>> city.encode('cp437', errors='ignore') # ④
b'So Paulo' >>> city.encode('cp437', errors='replace') # ⑤
b'S?o Paulo' >>> city.encode('cp437', errors='xmlcharrefreplace') # ⑥
b'São Paulo'
①
UTF 编码处理任何str。
②
iso8859_1也适用于'São Paulo'字符串。
③
cp437 无法编码'ã'(带有波浪符号的“a”)。默认错误处理程序'strict'会引发UnicodeEncodeError。
④
error='ignore'处理程序跳过无法编码的字符;这通常是一个非常糟糕的主意,会导致数据悄悄丢失。
⑤
在编码时,error='replace'用'?'替换无法编码的字符;数据也会丢失,但用户会得到提示有问题的线索。
⑥
'xmlcharrefreplace'用 XML 实体替换无法编码的字符。如果不能使用 UTF,也不能承受数据丢失,这是唯一的选择。
注意
codecs错误处理是可扩展的。您可以通过向codecs.register_error函数传递名称和错误处理函数来为errors参数注册额外的字符串。请参阅the codecs.register_error documentation。
ASCII 是我所知的所有编码的一个常见子集,因此如果文本完全由 ASCII 字符组成,编码应该总是有效的。Python 3.7 添加了一个新的布尔方法str.isascii()来检查您的 Unicode 文本是否是 100% 纯 ASCII。如果是,您应该能够在任何编码中将其编码为字节,而不会引发UnicodeEncodeError。
处理 UnicodeDecodeError
并非每个字节都包含有效的 ASCII 字符,并非每个字节序列都是有效的 UTF-8 或 UTF-16;因此,当您在将二进制序列转换为文本时假定其中一个编码时,如果发现意外字节,则会收到UnicodeDecodeError。
另一方面,许多传统的 8 位编码,如'cp1252'、'iso8859_1'和'koi8_r',能够解码任何字节流,包括随机噪音,而不报告错误。因此,如果您的程序假定了错误的 8 位编码,它将悄悄地解码垃圾数据。
提示
乱码字符被称为 gremlins 或 mojibake(文字化け—日语中的“转换文本”)。
Example 4-6 说明了使用错误的编解码器可能会产生乱码或UnicodeDecodeError。
示例 4-6. 从str解码为字节:成功和错误处理
>>> octets = b'Montr\xe9al' # ①
>>> octets.decode('cp1252') # ②
'Montréal' >>> octets.decode('iso8859_7') # ③
'Montrιal' >>> octets.decode('koi8_r') # ④
'MontrИal' >>> octets.decode('utf_8') # ⑤
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 5:
invalid continuation byte >>> octets.decode('utf_8', errors='replace') # ⑥
'Montr�al'
①
编码为latin1的单词“Montréal”;'\xe9'是“é”的字节。
②
使用 Windows 1252 解码有效,因为它是latin1的超集。
③
ISO-8859-7 用于希腊语,因此'\xe9'字节被错误解释,不会发出错误。
④
KOI8-R 用于俄语。现在'\xe9'代表西里尔字母“И”。
⑤
'utf_8'编解码器检测到octets不是有效的 UTF-8,并引发UnicodeDecodeError。
⑥
使用'replace'错误处理,\xe9会被“�”(代码点 U+FFFD)替换,这是官方的 Unicode REPLACEMENT CHARACTER,用于表示未知字符。
加载具有意外编码的模块时出现 SyntaxError
UTF-8 是 Python 3 的默认源编码,就像 ASCII 是 Python 2 的默认编码一样。如果加载包含非 UTF-8 数据且没有编码声明的 .py 模块,则会收到如下消息:
SyntaxError: Non-UTF-8 code starting with '\xe1' in file ola.py on line
1, but no encoding declared; see https://python.org/dev/peps/pep-0263/
for details
由于 UTF-8 在 GNU/Linux 和 macOS 系统中被广泛部署,一个可能的情况是在 Windows 上用cp1252打开一个 .py 文件。请注意,即使在 Windows 的 Python 中,这种错误也会发生,因为 Python 3 源代码在所有平台上的默认编码都是 UTF-8。
要解决这个问题,在文件顶部添加一个魔术coding注释,如 Example 4-7 所示。
示例 4-7. ola.py:葡萄牙语中的“Hello, World!”
# coding: cp1252
print('Olá, Mundo!')
提示
现在 Python 3 源代码不再限于 ASCII,并且默认使用优秀的 UTF-8 编码,因此对于像'cp1252'这样的遗留编码的源代码,最好的“修复”方法是将它们转换为 UTF-8,并且不再使用coding注释。如果您的编辑器不支持 UTF-8,那么是时候换一个了。
假设您有一个文本文件,无论是源代码还是诗歌,但您不知道其编码。如何检测实际的编码?答案在下一节中。
如何发现字节序列的编码
如何找到字节序列的编码?简短回答:你无法。你必须被告知。
一些通信协议和文件格式,比如 HTTP 和 XML,包含明确告诉我们内容如何编码的头部。你可以确定一些字节流不是 ASCII,因为它们包含超过 127 的字节值,而 UTF-8 和 UTF-16 的构建方式也限制了可能的字节序列。
然而,考虑到人类语言也有其规则和限制,一旦假定一系列字节是人类纯文本,可能可以通过启发式和统计方法来嗅探其编码。例如,如果b'\x00'字节很常见,那么它可能是 16 位或 32 位编码,而不是 8 位方案,因为纯文本中的空字符是错误的。当字节序列b'\x20\x00'经常出现时,更可能是 UTF-16LE 编码中的空格字符(U+0020),而不是晦涩的 U+2000 EN QUAD字符—不管那是什么。
这就是包“Chardet—通用字符编码检测器”是如何工作的,猜测其中的一个支持的 30 多种编码。Chardet是一个你可以在程序中使用的 Python 库,但也包括一个命令行实用程序,chardetect。这是它在本章源文件上报告的内容:
$ chardetect 04-text-byte.asciidoc
04-text-byte.asciidoc: utf-8 with confidence 0.99
尽管编码文本的二进制序列通常不包含其编码的明确提示,但 UTF 格式可能在文本内容前面添加字节顺序标记。接下来将对此进行解释。
BOM:一个有用的小精灵
在示例 4-4 中,你可能已经注意到 UTF-16 编码序列开头有一对额外的字节。这里再次展示:
>>> u16 = 'El Niño'.encode('utf_16')
>>> u16
b'\xff\xfeE\x00l\x00 \x00N\x00i\x00\xf1\x00o\x00'
这些字节是b'\xff\xfe'。这是一个BOM—字节顺序标记—表示进行编码的 Intel CPU 的“小端”字节顺序。
在小端机器上,对于每个代码点,最低有效字节先出现:字母'E',代码点 U+0045(十进制 69),在字节偏移 2 和 3 中编码为69和0:
>>> list(u16)
[255, 254, 69, 0, 108, 0, 32, 0, 78, 0, 105, 0, 241, 0, 111, 0]
在大端 CPU 上,编码会被颠倒;'E'会被编码为0和69。
为了避免混淆,UTF-16 编码在要编码的文本前面加上特殊的不可见字符零宽不换行空格(U+FEFF)。在小端系统上,它被编码为b'\xff\xfe'(十进制 255,254)。因为按设计,Unicode 中没有 U+FFFE 字符,字节序列b'\xff\xfe'必须表示小端编码中的零宽不换行空格,所以编解码器知道要使用哪种字节顺序。
有一种 UTF-16 的变体——UTF-16LE,明确是小端的,另一种是明确是大端的,UTF-16BE。如果使用它们,就不会生成 BOM:
>>> u16le = 'El Niño'.encode('utf_16le')
>>> list(u16le)
[69, 0, 108, 0, 32, 0, 78, 0, 105, 0, 241, 0, 111, 0]
>>> u16be = 'El Niño'.encode('utf_16be')
>>> list(u16be)
[0, 69, 0, 108, 0, 32, 0, 78, 0, 105, 0, 241, 0, 111]
如果存在 BOM,应该由 UTF-16 编解码器过滤,这样你只会得到文件的实际文本内容,而不包括前导的零宽不换行空格。Unicode 标准规定,如果一个文件是 UTF-16 且没有 BOM,应该假定为 UTF-16BE(大端)。然而,Intel x86 架构是小端的,因此在实际中有很多没有 BOM 的小端 UTF-16。
这整个字节序问题只影响使用多字节的编码,比如 UTF-16 和 UTF-32。UTF-8 的一个重要优势是,无论机器的字节序如何,它都会产生相同的字节序列,因此不需要 BOM。然而,一些 Windows 应用程序(特别是记事本)仍然会向 UTF-8 文件添加 BOM—Excel 依赖 BOM 来检测 UTF-8 文件,否则它会假定内容是用 Windows 代码页编码的。Python 的编解码器注册表中称带有 BOM 的 UTF-8 编码为 UTF-8-SIG。UTF-8-SIG 中编码的字符 U+FEFF 是三字节序列b'\xef\xbb\xbf'。因此,如果一个文件以这三个字节开头,很可能是带有 BOM 的 UTF-8 文件。
Caleb 关于 UTF-8-SIG 的提示
技术审查员之一 Caleb Hattingh 建议在读取 UTF-8 文件时始终使用 UTF-8-SIG 编解码器。这是无害的,因为 UTF-8-SIG 可以正确读取带或不带 BOM 的文件,并且不会返回 BOM 本身。在写入时,我建议为了一般的互操作性使用 UTF-8。例如,如果 Python 脚本以 #!/usr/bin/env python3 开头,可以在 Unix 系统中使其可执行。文件的前两个字节必须是 b'#!' 才能正常工作,但 BOM 打破了这个约定。如果有特定要求需要将数据导出到需要 BOM 的应用程序中,请使用 UTF-8-SIG,但请注意 Python 的 编解码器文档 表示:“在 UTF-8 中,不鼓励使用 BOM,通常应避免使用。”
现在我们转向在 Python 3 中处理文本文件。
处理文本文件
处理文本 I/O 的最佳实践是“Unicode 三明治”(图 4-2)。⁵ 这意味着 bytes 应尽早解码为 str(例如,在打开文件进行读取时)。三明治的“馅料”是程序的业务逻辑,在这里文本处理完全在 str 对象上进行。您永远不应该在其他处理过程中进行编码或解码。在输出时,str 应尽可能晚地编码为 bytes。大多数 Web 框架都是这样工作的,当使用它们时我们很少接触 bytes。例如,在 Django 中,您的视图应输出 Unicode str;Django 本身负责将响应编码为 bytes,默认使用 UTF-8。
Python 3 更容易遵循 Unicode 三明治的建议,因为内置的 open() 在读取和写入文本模式文件时进行必要的解码和编码,因此从 my_file.read() 获取的内容并传递给 my_file.write(text) 的都是 str 对象。
因此,使用文本文件似乎很简单。但是,如果依赖默认编码,您将受到影响。
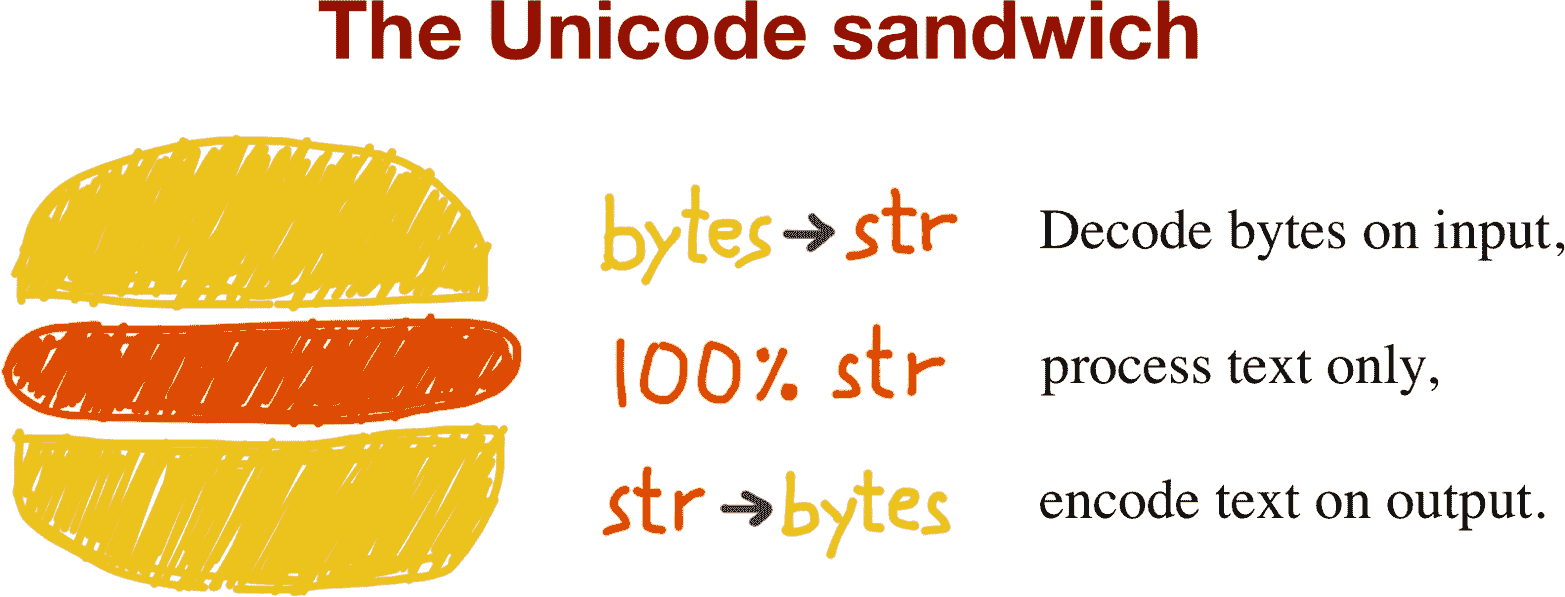
图 4-2. Unicode 三明治:文本处理的当前最佳实践。
考虑 示例 4-8 中的控制台会话。您能发现 bug 吗?
示例 4-8. 平台编码问题(如果您在自己的计算机上尝试此操作,可能会看到问题,也可能不会)
>>> open('cafe.txt', 'w', encoding='utf_8').write('café')
4
>>> open('cafe.txt').read()
'café'
Bug:我在写入文件时指定了 UTF-8 编码,但在读取文件时未这样做,因此 Python 假定 Windows 默认文件编码为代码页 1252,并且文件中的尾随字节被解码为字符 'é' 而不是 'é'。
我在 Windows 10(版本 18363)上运行了 Python 3.8.1 64 位上的 示例 4-8。在最近的 GNU/Linux 或 macOS 上运行相同的语句完全正常,因为它们的默认编码是 UTF-8,给人一种一切正常的假象。如果在打开文件进行写入时省略了编码参数,将使用区域设置的默认编码,我们将使用相同的编码正确读取文件。但是,这个脚本将根据平台或甚至相同平台中的区域设置生成具有不同字节内容的文件,从而创建兼容性问题。
提示
必须在多台机器上运行或在多个场合上运行的代码绝不能依赖于编码默认值。在打开文本文件时始终传递显式的 encoding= 参数,因为默认值可能会从一台机器变为另一台机器,或者从一天变为另一天。
示例 4-8 中一个有趣的细节是,第一条语句中的 write 函数报告写入了四个字符,但在下一行读取了五个字符。示例 4-9 是 示例 4-8 的扩展版本,解释了这个问题和其他细节。
示例 4-9. 仔细检查在 Windows 上运行的 示例 4-8 中的 bug 以及如何修复它
>>> fp = open('cafe.txt', 'w', encoding='utf_8')
>>> fp # ①
<_io.TextIOWrapper name='cafe.txt' mode='w' encoding='utf_8'> >>> fp.write('café') # ②
4 >>> fp.close()
>>> import os
>>> os.stat('cafe.txt').st_size # ③
5 >>> fp2 = open('cafe.txt')
>>> fp2 # ④
<_io.TextIOWrapper name='cafe.txt' mode='r' encoding='cp1252'> >>> fp2.encoding # ⑤
'cp1252' >>> fp2.read() # ⑥
'café' >>> fp3 = open('cafe.txt', encoding='utf_8') # ⑦
>>> fp3
<_io.TextIOWrapper name='cafe.txt' mode='r' encoding='utf_8'> >>> fp3.read() # ⑧
'café' >>> fp4 = open('cafe.txt', 'rb') # ⑨
>>> fp4 # ⑩
<_io.BufferedReader name='cafe.txt'> >>> fp4.read() ⑪
b'caf\xc3\xa9'
①
默认情况下,open使用文本模式并返回一个具有特定编码的TextIOWrapper对象。
②
TextIOWrapper上的write方法返回写入的 Unicode 字符数。
③
os.stat显示文件有 5 个字节;UTF-8 将'é'编码为 2 个字节,0xc3 和 0xa9。
④
打开一个没有明确编码的文本文件会返回一个TextIOWrapper,其编码设置为来自区域设置的默认值。
⑤
TextIOWrapper对象有一个编码属性,可以进行检查:在这种情况下是cp1252。
⑥
在 Windows 的cp1252编码中,字节 0xc3 是“Ô(带波浪符的 A),0xa9 是版权符号。
⑦
使用正确的编码打开相同的文件。
⑧
预期结果:对于'café'相同的四个 Unicode 字符。
⑨
'rb'标志以二进制模式打开文件进行读取。
⑩
返回的对象是BufferedReader而不是TextIOWrapper。
⑪
读取返回的是字节,符合预期。
提示
除非需要分析文件内容以确定编码,否则不要以二进制模式打开文本文件——即使这样,你应该使用 Chardet 而不是重复造轮子(参见“如何发现字节序列的编码”)。普通代码应该只使用二进制模式打开二进制文件,如光栅图像。
Example 4-9 中的问题涉及依赖默认设置打开文本文件。如下一节所示,有几个来源可以提供这些默认值。
警惕编码默认值
几个设置影响 Python 中 I/O 的编码默认值。查看 Example 4-10 中的default_encodings.py脚本。
Example 4-10. 探索编码默认值
import locale
import sys
expressions = """
locale.getpreferredencoding()
type(my_file)
my_file.encoding
sys.stdout.isatty()
sys.stdout.encoding
sys.stdin.isatty()
sys.stdin.encoding
sys.stderr.isatty()
sys.stderr.encoding
sys.getdefaultencoding()
sys.getfilesystemencoding()
"""
my_file = open('dummy', 'w')
for expression in expressions.split():
value = eval(expression)
print(f'{expression:>30} -> {value!r}')
Example 4-10 在 GNU/Linux(Ubuntu 14.04 至 19.10)和 macOS(10.9 至 10.14)上的输出是相同的,显示UTF-8在这些系统中随处可用:
$ python3 default_encodings.py
locale.getpreferredencoding() -> 'UTF-8'
type(my_file) -> <class '_io.TextIOWrapper'>
my_file.encoding -> 'UTF-8'
sys.stdout.isatty() -> True
sys.stdout.encoding -> 'utf-8'
sys.stdin.isatty() -> True
sys.stdin.encoding -> 'utf-8'
sys.stderr.isatty() -> True
sys.stderr.encoding -> 'utf-8'
sys.getdefaultencoding() -> 'utf-8'
sys.getfilesystemencoding() -> 'utf-8'
然而,在 Windows 上,输出是 Example 4-11。
Example 4-11. Windows 10 PowerShell 上的默认编码(在 cmd.exe 上输出相同)
> chcp # ①
Active code page: 437
> python default_encodings.py # ②
locale.getpreferredencoding() -> 'cp1252' # ③
type(my_file) -> <class '_io.TextIOWrapper'>
my_file.encoding -> 'cp1252' # ④
sys.stdout.isatty() -> True # ⑤
sys.stdout.encoding -> 'utf-8' # ⑥
sys.stdin.isatty() -> True
sys.stdin.encoding -> 'utf-8'
sys.stderr.isatty() -> True
sys.stderr.encoding -> 'utf-8'
sys.getdefaultencoding() -> 'utf-8'
sys.getfilesystemencoding() -> 'utf-8'
①
chcp显示控制台的活动代码页为437。
②
运行default_encodings.py并输出到控制台。
③
locale.getpreferredencoding()是最重要的设置。
④
文本文件默认使用locale.getpreferredencoding()。
⑤
输出将发送到控制台,因此sys.stdout.isatty()为True。
⑥
现在,sys.stdout.encoding与chcp报告的控制台代码页不同!
Windows 本身以及 Python 针对 Windows 的 Unicode 支持在我写这本书的第一版之后变得更好了。示例 4-11 曾经在 Windows 7 上的 Python 3.4 中报告了四种不同的编码。stdout、stdin和stderr的编码曾经与chcp命令报告的活动代码页相同,但现在由于 Python 3.6 中实现的PEP 528—将 Windows 控制台编码更改为 UTF-8,以及cmd.exe中的 PowerShell 中的 Unicode 支持(自 2018 年 10 月的 Windows 1809 起)。⁶ 当stdout写入控制台时,chcp和sys.stdout.encoding说不同的事情是很奇怪的,但现在我们可以在 Windows 上打印 Unicode 字符串而不会出现编码错误——除非用户将输出重定向到文件,正如我们很快将看到的。这并不意味着所有你喜欢的表情符号都会出现在控制台中:这也取决于控制台使用的字体。
另一个变化是PEP 529—将 Windows 文件系统编码更改为 UTF-8,也在 Python 3.6 中实现,将文件系统编码(用于表示目录和文件名称)从微软专有的 MBCS 更改为 UTF-8。
然而,如果示例 4-10 的输出被重定向到文件,就像这样:
Z:\>python default_encodings.py > encodings.log
然后,sys.stdout.isatty()的值变为False,sys.stdout.encoding由locale.getpreferredencoding()设置,在该机器上为'cp1252'—但sys.stdin.encoding和sys.stderr.encoding仍然为utf-8。
提示
在示例 4-12 中,我使用'\N{}'转义来表示 Unicode 文字,其中我们在\N{}内写入字符的官方名称。这样做相当冗长,但明确且安全:如果名称不存在,Python 会引发SyntaxError——比起写一个可能错误的十六进制数,这样做要好得多,但你只能在很久以后才会发现。你可能想要写一个解释字符代码的注释,所以\N{}的冗长是容易接受的。
这意味着像示例 4-12 这样的脚本在打印到控制台时可以正常工作,但在输出被重定向到文件时可能会出现问题。
示例 4-12. stdout_check.py
import sys
from unicodedata import name
print(sys.version)
print()
print('sys.stdout.isatty():', sys.stdout.isatty())
print('sys.stdout.encoding:', sys.stdout.encoding)
print()
test_chars = [
'\N{HORIZONTAL ELLIPSIS}', # exists in cp1252, not in cp437
'\N{INFINITY}', # exists in cp437, not in cp1252
'\N{CIRCLED NUMBER FORTY TWO}', # not in cp437 or in cp1252
]
for char in test_chars:
print(f'Trying to output {name(char)}:')
print(char)
示例 4-12 显示了sys.stdout.isatty()的结果,sys.stdout.encoding的值,以及这三个字符:
-
'…'HORIZONTAL ELLIPSIS—存在于 CP 1252 中,但不存在于 CP 437 中。 -
'∞'INFINITY—存在于 CP 437 中,但不存在于 CP 1252 中。 -
'㊷'CIRCLED NUMBER FORTY TWO—在 CP 1252 或 CP 437 中不存在。
当我在 PowerShell 或cmd.exe上运行stdout_check.py时,它的运行情况如图 4-3 所示。
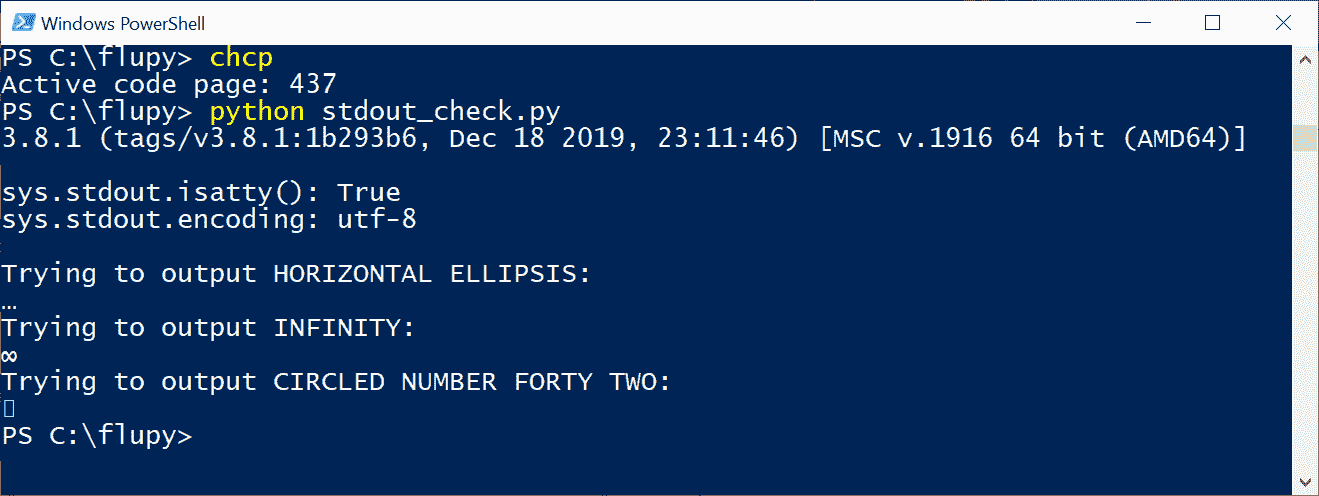
图 4-3. 在 PowerShell 上运行stdout_check.py。
尽管chcp报告活动代码为 437,但sys.stdout.encoding为 UTF-8,因此HORIZONTAL ELLIPSIS和INFINITY都能正确输出。CIRCLED NUMBER FORTY TWO被一个矩形替换,但不会引发错误。可能它被识别为有效字符,但控制台字体没有显示它的字形。
然而,当我将stdout_check.py的输出重定向到文件时,我得到了图 4-4。
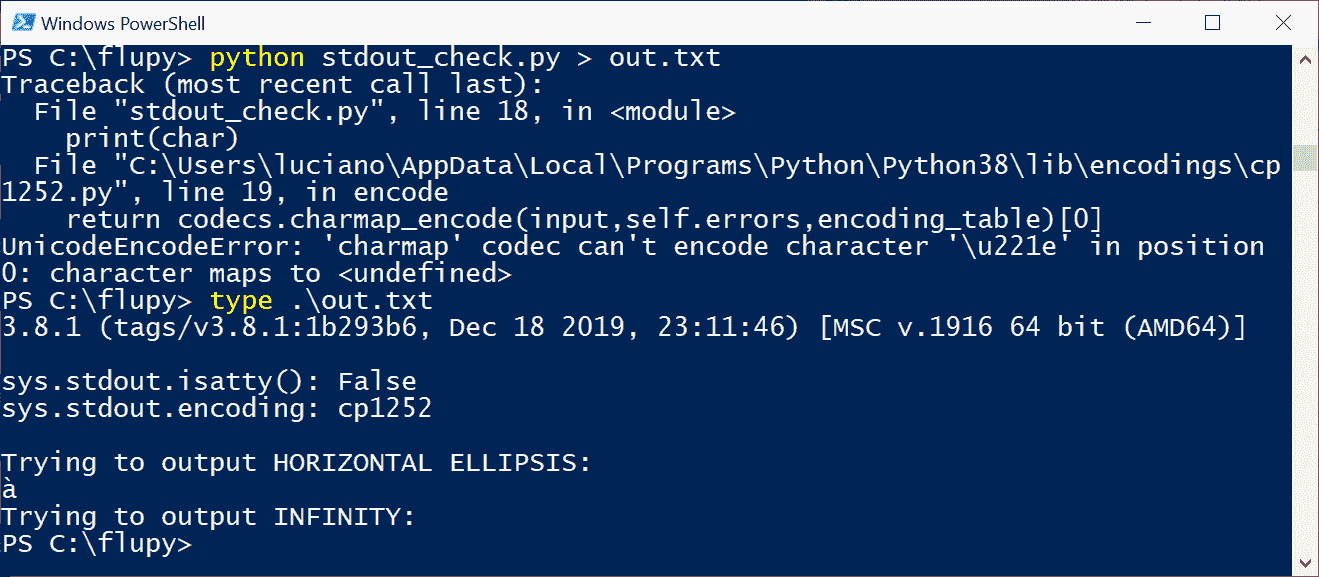
图 4-4. 在 PowerShell 上运行stdout_check.py,重定向输出。
图 4-4 展示的第一个问题是UnicodeEncodeError,提到字符'\u221e',因为sys.stdout.encoding是'cp1252'—一个不包含INFINITY字符的代码页。
使用type命令读取out.txt,或者使用 Windows 编辑器如 VS Code 或 Sublime Text,显示的不是水平省略号,而是'à'(带重音的拉丁小写字母 A)。事实证明,在 CP 1252 中,字节值 0x85 表示'…',但在 CP 437 中,相同的字节值代表'à'。因此,似乎活动代码页确实很重要,但并不是以明智或有用的方式,而是作为糟糕的 Unicode 经历的部分解释。
注意
我使用配置为美国市场的笔记本电脑,运行 Windows 10 OEM 来运行这些实验。为其他国家本地化的 Windows 版本可能具有不同的编码配置。例如,在巴西,Windows 控制台默认使用代码页 850,而不是 437。
为了总结这个令人疯狂的默认编码问题,让我们最后看一下示例 4-11 中的不同编码:
-
如果在打开文件时省略
encoding参数,则默认值由locale.getpreferredencoding()给出(在示例 4-11 中为'cp1252')。 -
在 Python 3.6 之前,
sys.stdout|stdin|stderr的编码是由PYTHONIOENCODING环境变量设置的,现在该变量被忽略,除非PYTHONLEGACYWINDOWSSTDIO设置为非空字符串。否则,标准 I/O 的编码对于交互式 I/O 是 UTF-8,或者如果输出/输入被重定向到/从文件,则由locale.getpreferredencoding()定义。 -
sys.getdefaultencoding()在 Python 中用于二进制数据与str之间的隐式转换。不支持更改此设置。 -
sys.getfilesystemencoding()用于对文件名进行编码/解码(而不是文件内容)。当open()以str参数作为文件名时使用它;如果文件名以bytes参数给出,则不做更改地传递给操作系统 API。
注意
在 GNU/Linux 和 macOS 上,默认情况下,所有这些编码都设置为 UTF-8,已经有好几年了,因此 I/O 处理所有 Unicode 字符。在 Windows 上,不仅在同一系统中使用不同的编码,而且通常是像'cp850'或'cp1252'这样只支持 ASCII 的代码页,还有 127 个额外字符,这些字符在不同编码之间并不相同。因此,Windows 用户更有可能遇到编码错误,除非他们特别小心。
总结一下,最重要的编码设置是由locale.getpreferredencoding()返回的:它是打开文本文件和当sys.stdout/stdin/stderr被重定向到文件时的默认值。然而,文档部分内容如下:
locale.getpreferredencoding(do_setlocale=True)根据用户偏好返回用于文本数据的编码。用户偏好在不同系统上表达方式不同,有些系统可能无法以编程方式获取,因此此函数只返回一个猜测。[…]
因此,关于编码默认值的最佳建议是:不要依赖于它们。
如果您遵循 Unicode 三明治的建议并始终明确指定程序中的编码,您将避免很多痛苦。不幸的是,即使您将您的bytes正确转换为str,Unicode 也是令人头痛的。接下来的两节涵盖了在 ASCII 领域简单的主题,在 Unicode 行星上变得非常复杂的文本规范化(即将文本转换为用于比较的统一表示)和排序。
为了可靠比较而规范化 Unicode
字符串比较变得复杂的原因在于 Unicode 具有组合字符:附加到前一个字符的变音符号和其他标记,在打印时会显示为一个字符。
例如,单词“café”可以用四个或五个代码点组成,但结果看起来完全相同:
>>> s1 = 'café'
>>> s2 = 'cafe\N{COMBINING ACUTE ACCENT}'
>>> s1, s2
('café', 'café')
>>> len(s1), len(s2)
(4, 5)
>>> s1 == s2
False
在“e”后面放置COMBINING ACUTE ACCENT(U+0301)会呈现“é”。在 Unicode 标准中,像'é'和'e\u0301'这样的序列被称为“规范等价物”,应用程序应将它们视为相同。但是 Python 看到两个不同的代码点序列,并认为它们不相等。
解决方案是unicodedata.normalize()。该函数的第一个参数是四个字符串之一:'NFC','NFD','NFKC'和'NFKD'。让我们从前两个开始。
规范化形式 C(NFC)将代码点组合以生成最短等效字符串,而 NFD 将分解,将组合字符扩展为基本字符和单独的组合字符。这两种规范化使比较按预期工作,如下一个示例所示:
>>> from unicodedata import normalize
>>> s1 = 'café'
>>> s2 = 'cafe\N{COMBINING ACUTE ACCENT}'
>>> len(s1), len(s2)
(4, 5)
>>> len(normalize('NFC', s1)), len(normalize('NFC', s2))
(4, 4)
>>> len(normalize('NFD', s1)), len(normalize('NFD', s2))
(5, 5)
>>> normalize('NFC', s1) == normalize('NFC', s2)
True
>>> normalize('NFD', s1) == normalize('NFD', s2)
True
键盘驱动程序通常生成组合字符,因此用户输入的文本默认情况下将是 NFC。但是,为了安全起见,在保存之前最好使用normalize('NFC', user_text)对字符串进行规范化。NFC 也是 W3C 在“全球网络字符模型:字符串匹配和搜索”中推荐的规范化形式。
一些单个字符被 NFC 规范化为另一个单个字符。电阻单位欧姆(Ω)的符号被规范化为希腊大写 omega。它们在视觉上是相同的,但它们比较不相等,因此规范化是必不可少的,以避免意外:
>>> from unicodedata import normalize, name
>>> ohm = '\u2126'
>>> name(ohm)
'OHM SIGN'
>>> ohm_c = normalize('NFC', ohm)
>>> name(ohm_c)
'GREEK CAPITAL LETTER OMEGA'
>>> ohm == ohm_c
False
>>> normalize('NFC', ohm) == normalize('NFC', ohm_c)
True
另外两种规范化形式是 NFKC 和 NFKD,其中字母 K 代表“兼容性”。这些是更强的规范化形式,影响所谓的“兼容性字符”。尽管 Unicode 的一个目标是为每个字符有一个单一的“规范”代码点,但一些字符出现多次是为了与现有标准兼容。例如,MICRO SIGN,µ(U+00B5),被添加到 Unicode 以支持与包括它在内的latin1的往返转换,即使相同的字符是希腊字母表的一部分,具有代码点U+03BC(GREEK SMALL LETTER MU)。因此,微符号被视为“兼容性字符”。
在 NFKC 和 NFKD 形式中,每个兼容字符都被一个或多个字符的“兼容分解”替换,这些字符被认为是“首选”表示,即使存在一些格式损失——理想情况下,格式应该由外部标记负责,而不是 Unicode 的一部分。举例来说,一个半分数'½'(U+00BD)的兼容分解是三个字符的序列'1/2',而微符号'µ'(U+00B5)的兼容分解是小写的希腊字母 mu'μ'(U+03BC)。⁷
下面是 NFKC 在实践中的工作方式:
>>> from unicodedata import normalize, name
>>> half = '\N{VULGAR FRACTION ONE HALF}'
>>> print(half)
½
>>> normalize('NFKC', half)
'1⁄2'
>>> for char in normalize('NFKC', half):
... print(char, name(char), sep='\t')
...
1 DIGIT ONE
⁄ FRACTION SLASH
2 DIGIT TWO
>>> four_squared = '4²'
>>> normalize('NFKC', four_squared)
'42'
>>> micro = 'µ'
>>> micro_kc = normalize('NFKC', micro)
>>> micro, micro_kc
('µ', 'μ')
>>> ord(micro), ord(micro_kc)
(181, 956)
>>> name(micro), name(micro_kc)
('MICRO SIGN', 'GREEK SMALL LETTER MU')
尽管'1⁄2'是'½'的一个合理替代品,而微符号实际上是一个小写希腊字母 mu,但将'4²'转换为'42'会改变含义。一个应用程序可以将'4²'存储为'4<sup>2</sup>',但normalize函数对格式一无所知。因此,NFKC 或 NFKD 可能会丢失或扭曲信息,但它们可以生成方便的中间表示形式用于搜索和索引。
不幸的是,对于 Unicode 来说,一切总是比起初看起来更加复杂。对于VULGAR FRACTION ONE HALF,NFKC 规范化产生了用FRACTION SLASH连接的 1 和 2,而不是SOLIDUS,即“斜杠”—ASCII 代码十进制 47 的熟悉字符。因此,搜索三字符 ASCII 序列'1/2'将找不到规范化的 Unicode 序列。
警告
NFKC 和 NFKD 规范会导致数据丢失,应仅在特殊情况下如搜索和索引中应用,而不是用于文本的永久存储。
当准备文本进行搜索或索引时,另一个有用的操作是大小写折叠,我们的下一个主题。
大小写折叠
大小写折叠基本上是将所有文本转换为小写,还有一些额外的转换。它由str.casefold()方法支持。
对于只包含 latin1 字符的任何字符串 s,s.casefold() 产生与 s.lower() 相同的结果,只有两个例外——微符号 'µ' 被更改为希腊小写 mu(在大多数字体中看起来相同),德语 Eszett 或 “sharp s”(ß)变为 “ss”:
>>> micro = 'µ'
>>> name(micro)
'MICRO SIGN'
>>> micro_cf = micro.casefold()
>>> name(micro_cf)
'GREEK SMALL LETTER MU'
>>> micro, micro_cf
('µ', 'μ')
>>> eszett = 'ß'
>>> name(eszett)
'LATIN SMALL LETTER SHARP S'
>>> eszett_cf = eszett.casefold()
>>> eszett, eszett_cf
('ß', 'ss')
有将近 300 个代码点,str.casefold() 和 str.lower() 返回不同的结果。
和 Unicode 相关的任何事物一样,大小写折叠是一个困难的问题,有很多语言特殊情况,但 Python 核心团队努力提供了一个解决方案,希望能适用于大多数用户。
在接下来的几节中,我们将利用我们的规范化知识开发实用函数。
用于规范化文本匹配的实用函数
正如我们所见,NFC 和 NFD 是安全的,并允许在 Unicode 字符串之间进行明智的比较。对于大多数应用程序,NFC 是最佳的规范化形式。str.casefold() 是进行不区分大小写比较的方法。
如果您使用多种语言的文本,像 示例 4-13 中的 nfc_equal 和 fold_equal 这样的一对函数对您的工具箱是有用的补充。
示例 4-13. normeq.py: 规范化的 Unicode 字符串比较
"""
Utility functions for normalized Unicode string comparison.
Using Normal Form C, case sensitive:
>>> s1 = 'café'
>>> s2 = 'cafe\u0301'
>>> s1 == s2
False
>>> nfc_equal(s1, s2)
True
>>> nfc_equal('A', 'a')
False
Using Normal Form C with case folding:
>>> s3 = 'Straße'
>>> s4 = 'strasse'
>>> s3 == s4
False
>>> nfc_equal(s3, s4)
False
>>> fold_equal(s3, s4)
True
>>> fold_equal(s1, s2)
True
>>> fold_equal('A', 'a')
True
"""
from unicodedata import normalize
def nfc_equal(str1, str2):
return normalize('NFC', str1) == normalize('NFC', str2)
def fold_equal(str1, str2):
return (normalize('NFC', str1).casefold() ==
normalize('NFC', str2).casefold())
超出 Unicode 标准中的规范化和大小写折叠之外,有时候进行更深层次的转换是有意义的,比如将 'café' 改为 'cafe'。我们将在下一节看到何时以及如何进行。
极端的“规范化”:去除变音符号
谷歌搜索的秘密酱包含许多技巧,但其中一个显然是忽略变音符号(例如,重音符号、锐音符等),至少在某些情况下是这样。去除变音符号并不是一种适当的规范化形式,因为它经常改变单词的含义,并且在搜索时可能产生误报。但它有助于应对生活中的一些事实:人们有时懒惰或无知于正确使用变音符号,拼写规则随时间变化,这意味着重音符号在活语言中来来去去。
除了搜索之外,去除变音符号还可以使 URL 更易读,至少在基于拉丁语言的语言中是这样。看看关于圣保罗市的维基百科文章的 URL:
https://en.wikipedia.org/wiki/S%C3%A3o_Paulo
%C3%A3 部分是 URL 转义的,UTF-8 渲染的单个字母 “ã”(带有波浪符的 “a”)。即使拼写不正确,以下内容也更容易识别:
https://en.wikipedia.org/wiki/Sao_Paulo
要从 str 中移除所有变音符号,可以使用类似 示例 4-14 的函数。
示例 4-14. simplify.py: 用于移除所有组合标记的函数
import unicodedata
import string
def shave_marks(txt):
"""Remove all diacritic marks"""
norm_txt = unicodedata.normalize('NFD', txt) # ①
shaved = ''.join(c for c in norm_txt
if not unicodedata.combining(c)) # ②
return unicodedata.normalize('NFC', shaved) # ③
①
将所有字符分解为基本字符和组合标记。
②
过滤掉所有组合标记。
③
重新组合所有字符。
示例 4-15 展示了几种使用 shave_marks 的方法。
示例 4-15. 使用 shave_marks 的两个示例,来自 示例 4-14
>>> order = '“Herr Voß: • ½ cup of Œtker™ caffè latte • bowl of açaí.”'
>>> shave_marks(order)
'“Herr Voß: • ½ cup of Œtker™ caffe latte • bowl of acai.”' # ①
>>> Greek = 'Ζέφυρος, Zéfiro'
>>> shave_marks(Greek)
'Ζεφυρος, Zefiro' # ②
①
仅字母 “è”、“ç” 和 “í” 被替换。
②
“έ” 和 “é” 都被替换了。
来自 示例 4-14 的函数 shave_marks 运行良好,但也许它做得太过了。通常移除变音符号的原因是将拉丁文本更改为纯 ASCII,但 shave_marks 也会改变非拉丁字符,比如希腊字母,这些字母仅仅通过失去重音就不会变成 ASCII。因此,有必要分析每个基本字符,并仅在基本字符是拉丁字母时才移除附加标记。这就是 示例 4-16 的作用。
示例 4-16. 从拉丁字符中移除组合标记的函数(省略了导入语句,因为这是来自 示例 4-14 的 simplify.py 模块的一部分)
def shave_marks_latin(txt):
"""Remove all diacritic marks from Latin base characters"""
norm_txt = unicodedata.normalize('NFD', txt) # ①
latin_base = False
preserve = []
for c in norm_txt:
if unicodedata.combining(c) and latin_base: # ②
continue # ignore diacritic on Latin base char
preserve.append(c) # ③
# if it isn't a combining char, it's a new base char
if not unicodedata.combining(c): # ④
latin_base = c in string.ascii_letters
shaved = ''.join(preserve)
return unicodedata.normalize('NFC', shaved) # ⑤
①
将所有字符分解为基本字符和组合标记。
②
当基本字符为拉丁字符时,跳过组合标记。
③
否则,保留当前字符。
④
检测新的基本字符,并确定它是否为拉丁字符。
⑤
重新组合所有字符。
更激进的一步是将西方文本中的常见符号(例如,卷曲引号、破折号、项目符号等)替换为ASCII等效符号。这就是示例 4-17 中的asciize函数所做的。
示例 4-17. 将一些西方排版符号转换为 ASCII(此片段也是示例 4-14 中simplify.py的一部分)
single_map = str.maketrans("""‚ƒ„ˆ‹‘’“”•–—˜›""", # ①
"""'f"^<''""---~>""")
multi_map = str.maketrans({ # ②
'€': 'EUR',
'…': '...',
'Æ': 'AE',
'æ': 'ae',
'Œ': 'OE',
'œ': 'oe',
'™': '(TM)',
'‰': '<per mille>',
'†': '**',
'‡': '***',
})
multi_map.update(single_map) # ③
def dewinize(txt):
"""Replace Win1252 symbols with ASCII chars or sequences"""
return txt.translate(multi_map) # ④
def asciize(txt):
no_marks = shave_marks_latin(dewinize(txt)) # ⑤
no_marks = no_marks.replace('ß', 'ss') # ⑥
return unicodedata.normalize('NFKC', no_marks) # ⑦
①
为字符替换构建映射表。
②
为字符到字符串替换构建映射表。
③
合并映射表。
④
dewinize不影响ASCII或latin1文本,只影响cp1252中的 Microsoft 附加内容。
⑤
应用dewinize并移除变音符号。
⑥
用“ss”替换 Eszett(我们这里不使用大小写折叠,因为我们想保留大小写)。
⑦
对具有其兼容性代码点的字符进行 NFKC 规范化以组合字符。
示例 4-18 展示了asciize的使用。
示例 4-18. 使用示例 4-17 中的asciize的两个示例
>>> order = '“Herr Voß: • ½ cup of Œtker™ caffè latte • bowl of açaí.”'
>>> dewinize(order)
'"Herr Voß: - ½ cup of OEtker(TM) caffè latte - bowl of açaí."' # ①
>>> asciize(order)
'"Herr Voss: - 1⁄2 cup of OEtker(TM) caffe latte - bowl of acai."' # ②
①
dewinize替换卷曲引号、项目符号和™(商标符号)。
②
asciize应用dewinize,删除变音符号,并替换'ß'。
警告
不同语言有自己的去除变音符号的规则。例如,德语将'ü'改为'ue'。我们的asciize函数不够精细,因此可能不适合您的语言。但对葡萄牙语来说,它的效果还可以接受。
总结一下,在simplify.py中的函数远远超出了标准规范化,并对文本进行了深度处理,有可能改变其含义。只有您可以决定是否走得这么远,了解目标语言、您的用户以及转换后的文本将如何使用。
这就结束了我们对规范化 Unicode 文本的讨论。
现在让我们来解决 Unicode 排序问题。
对 Unicode 文本进行排序
Python 通过逐个比较每个序列中的项目来对任何类型的序列进行排序。对于字符串,这意味着比较代码点。不幸的是,这对于使用非 ASCII 字符的人来说产生了无法接受的结果。
考虑对在巴西种植的水果列表进行排序:
>>> fruits = ['caju', 'atemoia', 'cajá', 'açaí', 'acerola']
>>> sorted(fruits)
['acerola', 'atemoia', 'açaí', 'caju', 'cajá']
不同区域设置的排序规则不同,但在葡萄牙语和许多使用拉丁字母表的语言中,重音符号和塞迪利亚很少在排序时产生差异。⁸ 因此,“cajá”被排序为“caja”,并且必须位于“caju”之前。
排序后的fruits列表应为:
['açaí', 'acerola', 'atemoia', 'cajá', 'caju']
在 Python 中对非 ASCII 文本进行排序的标准方法是使用locale.strxfrm函数,根据locale模块文档,“将一个字符串转换为可用于区域设置感知比较的字符串”。
要启用locale.strxfrm,您必须首先为您的应用程序设置一个合适的区域设置,并祈祷操作系统支持它。示例 4-19 中的命令序列可能适用于您。
示例 4-19. locale_sort.py:使用locale.strxfrm函数作为排序键
import locale
my_locale = locale.setlocale(locale.LC_COLLATE, 'pt_BR.UTF-8')
print(my_locale)
fruits = ['caju', 'atemoia', 'cajá', 'açaí', 'acerola']
sorted_fruits = sorted(fruits, key=locale.strxfrm)
print(sorted_fruits)
在 GNU/Linux(Ubuntu 19.10)上运行 示例 4-19,安装了 pt_BR.UTF-8 区域设置,我得到了正确的结果:
'pt_BR.UTF-8'
['açaí', 'acerola', 'atemoia', 'cajá', 'caju']
因此,在排序时需要在使用 locale.strxfrm 作为键之前调用 setlocale(LC_COLLATE, «your_locale»)。
不过,还有一些注意事项:
-
因为区域设置是全局的,不建议在库中调用
setlocale。您的应用程序或框架应该在进程启动时设置区域设置,并且不应该在之后更改它。 -
操作系统必须安装区域设置,否则
setlocale会引发locale.Error: unsupported locale setting异常。 -
您必须知道如何拼写区域设置名称。
-
区域设置必须由操作系统的制造商正确实现。我在 Ubuntu 19.10 上成功了,但在 macOS 10.14 上没有成功。在 macOS 上,调用
setlocale(LC_COLLATE, 'pt_BR.UTF-8')返回字符串'pt_BR.UTF-8'而没有任何投诉。但sorted(fruits, key=locale.strxfrm)产生了与sorted(fruits)相同的不正确结果。我还在 macOS 上尝试了fr_FR、es_ES和de_DE区域设置,但locale.strxfrm从未起作用。⁹
因此,标准库提供的国际化排序解决方案有效,但似乎只在 GNU/Linux 上得到很好的支持(也许在 Windows 上也是如此,如果您是专家的话)。即使在那里,它也依赖于区域设置,会带来部署上的麻烦。
幸运的是,有一个更简单的解决方案:pyuca 库,可以在 PyPI 上找到。
使用 Unicode Collation Algorithm 进行排序
James Tauber,多产的 Django 贡献者,一定感受到了痛苦,并创建了 pyuca,这是 Unicode Collation Algorithm(UCA)的纯 Python 实现。示例 4-20 展示了它的易用性。
示例 4-20。使用 pyuca.Collator.sort_key 方法
>>> import pyuca
>>> coll = pyuca.Collator()
>>> fruits = ['caju', 'atemoia', 'cajá', 'açaí', 'acerola']
>>> sorted_fruits = sorted(fruits, key=coll.sort_key)
>>> sorted_fruits
['açaí', 'acerola', 'atemoia', 'cajá', 'caju']
这个方法简单易行,在 GNU/Linux、macOS 和 Windows 上都可以运行,至少在我的小样本中是这样的。
pyuca 不考虑区域设置。如果需要自定义排序,可以向 Collator() 构造函数提供自定义排序表的路径。默认情况下,它使用 allkeys.txt,这是项目捆绑的。这只是 来自 Unicode.org 的默认 Unicode Collation Element Table 的副本。
PyICU:Miro 的 Unicode 排序推荐
(技术审阅员 Miroslav Šedivý 是一位多语言使用者,也是 Unicode 方面的专家。这是他对 pyuca 的评价。)
pyuca 有一个排序算法,不考虑各个语言中的排序顺序。例如,在德语中 Ä 在 A 和 B 之间,而在瑞典语中它在 Z 之后。看看 PyICU,它像区域设置一样工作,而不会更改进程的区域设置。如果您想要在土耳其语中更改 iİ/ıI 的大小写,也需要它。PyICU 包含一个必须编译的扩展,因此在某些系统中安装可能比只是 Python 的 pyuca 更困难。
顺便说一句,那个排序表是组成 Unicode 数据库的许多数据文件之一,我们下一个主题。
Unicode 数据库
Unicode 标准提供了一个完整的数据库,以几个结构化的文本文件的形式存在,其中不仅包括将代码点映射到字符名称的表,还包括有关各个字符及其相关性的元数据。例如,Unicode 数据库记录了字符是否可打印、是否为字母、是否为十进制数字,或者是否为其他数字符号。这就是 str 方法 isalpha、isprintable、isdecimal 和 isnumeric 的工作原理。str.casefold 也使用了来自 Unicode 表的信息。
注意
unicodedata.category(char) 函数从 Unicode 数据库返回 char 的两个字母类别。更高级别的 str 方法更容易使用。例如,label.isalpha() 如果 label 中的每个字符属于以下类别之一,则返回 True:Lm、Lt、Lu、Ll 或 Lo。要了解这些代码的含义,请参阅英文维基百科的 “Unicode 字符属性”文章 中的 “通用类别”。
按名称查找字符
unicodedata 模块包括检索字符元数据的函数,包括 unicodedata.name(),它返回标准中字符的官方名称。图 4-5 展示了该函数的使用。¹⁰

图 4-5. 在 Python 控制台中探索 unicodedata.name()。
您可以使用 name() 函数构建应用程序,让用户可以按名称搜索字符。图 4-6 展示了 cf.py 命令行脚本,它接受一个或多个单词作为参数,并列出具有这些单词在官方 Unicode 名称中的字符。cf.py 的完整源代码在 示例 4-21 中。

图 4-6. 使用 cf.py 查找微笑的猫。
警告
表情符号在各种操作系统和应用程序中的支持差异很大。近年来,macOS 终端提供了最好的表情符号支持,其次是现代 GNU/Linux 图形终端。Windows cmd.exe 和 PowerShell 现在支持 Unicode 输出,但截至我在 2020 年 1 月撰写本节时,它们仍然不显示表情符号——至少不是“开箱即用”。技术评论员莱昂纳多·罗查尔告诉我有一个新的、由微软推出的开源 Windows 终端,它可能比旧的微软控制台具有更好的 Unicode 支持。我还没有时间尝试。
在 示例 4-21 中,请注意 find 函数中的 if 语句,使用 .issubset() 方法快速测试 query 集合中的所有单词是否出现在从字符名称构建的单词列表中。由于 Python 丰富的集合 API,我们不需要嵌套的 for 循环和另一个 if 来实现此检查。
示例 4-21. cf.py:字符查找实用程序
#!/usr/bin/env python3
import sys
import unicodedata
START, END = ord(' '), sys.maxunicode + 1 # ①
def find(*query_words, start=START, end=END): # ②
query = {w.upper() for w in query_words} # ③
for code in range(start, end):
char = chr(code) # ④
name = unicodedata.name(char, None) # ⑤
if name and query.issubset(name.split()): # ⑥
print(f'U+{code:04X}\t{char}\t{name}') # ⑦
def main(words):
if words:
find(*words)
else:
print('Please provide words to find.')
if __name__ == '__main__':
main(sys.argv[1:])
①
设置搜索的代码点范围的默认值。
②
find 接受 query_words 和可选的关键字参数来限制搜索范围,以便进行测试。
③
将 query_words 转换为大写字符串集合。
④
获取 code 的 Unicode 字符。
⑤
获取字符的名称,如果代码点未分配,则返回 None。
⑥
如果有名称,将其拆分为单词列表,然后检查 query 集合是否是该列表的子集。
⑦
打印出以 U+9999 格式的代码点、字符和其名称的行。
unicodedata 模块还有其他有趣的函数。接下来,我们将看到一些与获取具有数字含义的字符信息相关的函数。
字符的数字含义
unicodedata 模块包括函数,用于检查 Unicode 字符是否表示数字,如果是,则返回其人类的数值,而不是其代码点数。示例 4-22 展示了 unicodedata.name() 和 unicodedata.numeric() 的使用,以及 str 的 .isdecimal() 和 .isnumeric() 方法。
示例 4-22. Unicode 数据库数字字符元数据演示(标注描述输出中的每列)
import unicodedata
import re
re_digit = re.compile(r'\d')
sample = '1\xbc\xb2\u0969\u136b\u216b\u2466\u2480\u3285'
for char in sample:
print(f'U+{ord(char):04x}', # ①
char.center(6), # ②
're_dig' if re_digit.match(char) else '-', # ③
'isdig' if char.isdigit() else '-', # ④
'isnum' if char.isnumeric() else '-', # ⑤
f'{unicodedata.numeric(char):5.2f}', # ⑥
unicodedata.name(char), # ⑦
sep='\t')
①
以U+0000格式的代码点。
②
字符在长度为 6 的str中居中。
③
如果字符匹配r'\d'正则表达式,则显示re_dig。
④
如果char.isdigit()为True,则显示isdig。
⑤
如果char.isnumeric()为True,则显示isnum。
⑥
数值格式化为宽度为 5 和 2 位小数。
⑦
Unicode 字符名称。
运行示例 4-22 会给你图 4-7,如果你的终端字体有所有这些字形。
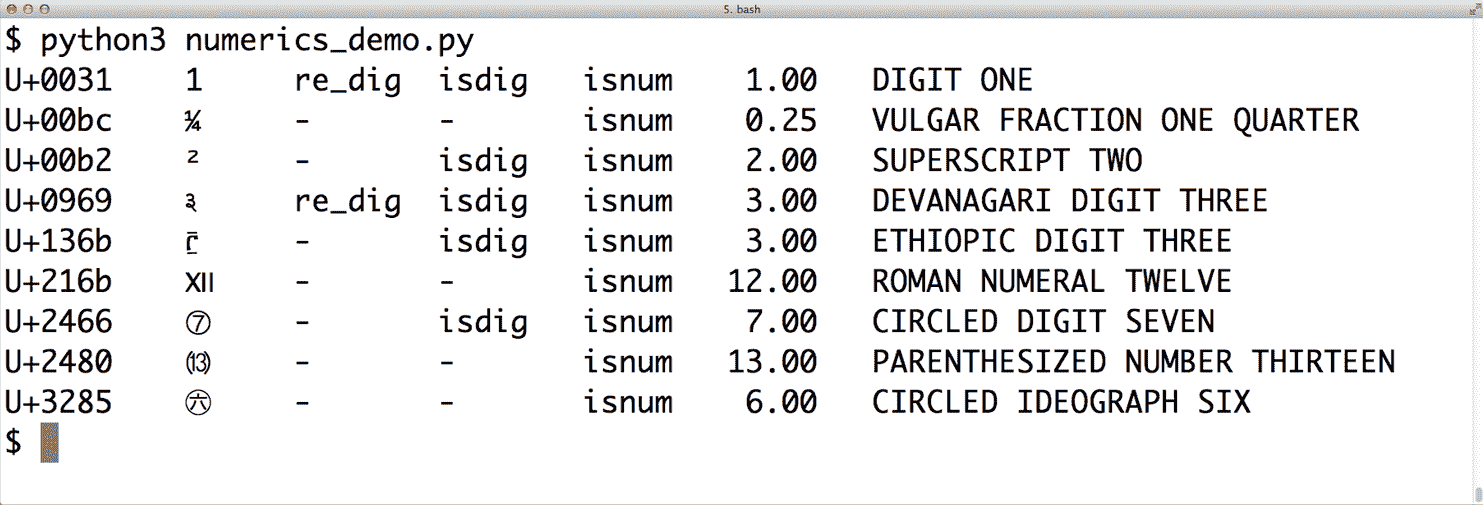
图 4-7. macOS 终端显示数字字符及其元数据;re_dig表示字符匹配正则表达式r'\d'。
图 4-7 的第六列是在字符上调用unicodedata.numeric(char)的结果。它显示 Unicode 知道代表数字的符号的数值。因此,如果你想创建支持泰米尔数字或罗马数字的电子表格应用程序,就去做吧!
图 4-7 显示正则表达式r'\d'匹配数字“1”和梵文数字 3,但不匹配一些其他被isdigit函数视为数字的字符。re模块对 Unicode 的了解不如它本应该的那样深入。PyPI 上提供的新regex模块旨在最终取代re,并提供更好的 Unicode 支持。¹¹我们将在下一节回到re模块。
在本章中,我们使用了几个unicodedata函数,但还有许多我们没有涉及的函数。查看标准库文档中的unicodedata模块。
接下来我们将快速查看双模式 API,提供接受str或bytes参数的函数,并根据类型进行特殊处理。
双模式 str 和 bytes API
Python 标准库有接受str或bytes参数并根据类型表现不同的函数。一些示例可以在re和os模块中找到。
正则表达式中的 str 与 bytes
如果用bytes构建正则表达式,模式如\d和\w只匹配 ASCII 字符;相反,如果这些模式给定为str,它们将匹配 ASCII 之外的 Unicode 数字或字母。示例 4-23 和图 4-8 比较了str和bytes模式如何匹配字母、ASCII 数字、上标和泰米尔数字。
示例 4-23. ramanujan.py:比较简单str和bytes正则表达式的行为
import re
re_numbers_str = re.compile(r'\d+') # ①
re_words_str = re.compile(r'\w+')
re_numbers_bytes = re.compile(rb'\d+') # ②
re_words_bytes = re.compile(rb'\w+')
text_str = ("Ramanujan saw \u0be7\u0bed\u0be8\u0bef" # ③
" as 1729 = 1³ + 12³ = 9³ + 10³.") # ④
text_bytes = text_str.encode('utf_8') # ⑤
print(f'Text\n {text_str!r}')
print('Numbers')
print(' str :', re_numbers_str.findall(text_str)) # ⑥
print(' bytes:', re_numbers_bytes.findall(text_bytes)) # ⑦
print('Words')
print(' str :', re_words_str.findall(text_str)) # ⑧
print(' bytes:', re_words_bytes.findall(text_bytes)) # ⑨
①
前两个正则表达式是str类型。
②
最后两个是bytes类型。
③
Unicode 文本搜索,包含泰米尔数字1729(逻辑行一直延续到右括号标记)。
④
此字符串在编译时与前一个字符串连接(参见“2.4.2. 字符串文字连接”中的Python 语言参考)。
⑤
需要使用bytes正则表达式来搜索bytes字符串。
⑥](#co_unicode_text_versus_bytes_CO15-6)
str模式r'\d+'匹配泰米尔和 ASCII 数字。
⑦
bytes模式rb'\d+'仅匹配数字的 ASCII 字节。
⑧
str模式r'\w+'匹配字母、上标、泰米尔语和 ASCII 数字。
⑨
bytes模式rb'\w+'仅匹配字母和数字的 ASCII 字节。

图 4-8。从示例 4-23 运行 ramanujan.py 的屏幕截图。
示例 4-23 是一个简单的例子,用来说明一个观点:你可以在str和bytes上使用正则表达式,但在第二种情况下,ASCII 范围之外的字节被视为非数字和非单词字符。
对于str正则表达式,有一个re.ASCII标志,使得\w、\W、\b、\B、\d、\D、\s和\S只执行 ASCII 匹配。详细信息请参阅re 模块的文档。
另一个重要的双模块是os。
os函数中的 str 与 bytes
GNU/Linux 内核不支持 Unicode,因此在现实世界中,您可能会发现由字节序列组成的文件名,这些文件名在任何明智的编码方案中都无效,并且无法解码为str。使用各种操作系统的客户端的文件服务器特别容易出现这个问题。
为了解决这个问题,所有接受文件名或路径名的os模块函数都以str或bytes形式接受参数。如果调用这样的函数时使用str参数,参数将自动使用sys.getfilesystemencoding()命名的编解码器进行转换,并且 OS 响应将使用相同的编解码器进行解码。这几乎总是您想要的,符合 Unicode 三明治最佳实践。
但是,如果您必须处理(或者可能修复)无法以这种方式处理的文件名,您可以将bytes参数传递给os函数以获得bytes返回值。这个功能让您可以处理任何文件或路径名,无论您可能遇到多少小精灵。请参阅示例 4-24。
示例 4-24。listdir使用str和bytes参数和结果
>>> os.listdir('.') # ①
['abc.txt', 'digits-of-π.txt'] >>> os.listdir(b'.') # ②
[b'abc.txt', b'digits-of-\xcf\x80.txt']
①
第二个文件名是“digits-of-π.txt”(带有希腊字母π)。
②
给定一个byte参数,listdir以字节形式返回文件名:b'\xcf\x80'是希腊字母π的 UTF-8 编码。
为了帮助处理作为文件名或路径名的str或bytes序列,os模块提供了特殊的编码和解码函数os.fsencode(name_or_path)和os.fsdecode(name_or_path)。自 Python 3.6 起,这两个函数都接受str、bytes或实现os.PathLike接口的对象作为参数。
Unicode 是一个深奥的领域。是时候结束我们对str和bytes的探索了。
章节总结
我们在本章开始时否定了1 个字符 == 1 个字节的概念。随着世界采用 Unicode,我们需要将文本字符串的概念与文件中表示它们的二进制序列分开,而 Python 3 强制执行这种分离。
在简要概述二进制序列数据类型——bytes、bytearray和memoryview后,我们开始了编码和解码,列举了一些重要的编解码器,然后介绍了如何防止或处理由 Python 源文件中错误编码引起的臭名昭著的UnicodeEncodeError、UnicodeDecodeError和SyntaxError。
在没有元数据的情况下考虑编码检测的理论和实践:理论上是不可能的,但实际上 Chardet 软件包对一些流行的编码做得相当不错。然后介绍了字节顺序标记作为 UTF-16 和 UTF-32 文件中唯一常见的编码提示,有时也会在 UTF-8 文件中找到。
在下一节中,我们演示了如何打开文本文件,这是一个简单的任务,除了一个陷阱:当你打开文本文件时,encoding= 关键字参数不是强制的,但应该是。如果你未指定编码,你最终会得到一个在不同平台上不兼容的“纯文本”生成程序,这是由于冲突的默认编码。然后我们揭示了 Python 使用的不同编码设置作为默认值以及如何检测它们。对于 Windows 用户来说,一个令人沮丧的认识是这些设置在同一台机器内往往具有不同的值,并且这些值是相互不兼容的;相比之下,GNU/Linux 和 macOS 用户生活在一个更幸福的地方,UTF-8 几乎是默认编码。
Unicode 提供了多种表示某些字符的方式,因此规范化是文本匹配的先决条件。除了解释规范化和大小写折叠外,我们还提供了一些实用函数,您可以根据自己的需求进行调整,包括像删除所有重音这样的彻底转换。然后我们看到如何通过利用标准的 locale 模块正确对 Unicode 文本进行排序——带有一些注意事项——以及一个不依赖于棘手的 locale 配置的替代方案:外部的 pyuca 包。
我们利用 Unicode 数据库编写了一个命令行实用程序,通过名称搜索字符——感谢 Python 的强大功能,只需 28 行代码。我们还简要介绍了其他 Unicode 元数据,并对一些双模式 API 进行了概述,其中一些函数可以使用 str 或 bytes 参数调用,产生不同的结果。
进一步阅读
Ned Batchelder 在 2012 年 PyCon US 的演讲“实用 Unicode,或者,我如何停止痛苦?”非常出色。Ned 是如此专业,他提供了演讲的完整文本以及幻灯片和视频。
“Python 中的字符编码和 Unicode:如何(╯°□°)╯︵ ┻━┻ 有尊严地处理”(幻灯片,视频)是 Esther Nam 和 Travis Fischer 在 PyCon 2014 上的出色演讲,我在这个章节中找到了这个简洁的题记:“人类使用文本。计算机使用字节。”
Lennart Regebro——本书第一版的技术审查者之一——在短文“澄清 Unicode:什么是 Unicode?”中分享了他的“Unicode 有用的心智模型(UMMU)”。Unicode 是一个复杂的标准,所以 Lennart 的 UMMU 是一个非常有用的起点。
Python 文档中官方的“Unicode HOWTO”从多个不同角度探讨了这个主题,从一个很好的历史介绍,到语法细节,编解码器,正则表达式,文件名,以及 Unicode-aware I/O 的最佳实践(即 Unicode 三明治),每个部分都有大量额外的参考链接。Mark Pilgrim 的精彩书籍Dive into Python 3(Apress)的第四章,“字符串”也提供了 Python 3 中 Unicode 支持的很好介绍。在同一本书中,第十五章描述了 Chardet 库是如何从 Python 2 移植到 Python 3 的,这是一个有价值的案例研究,因为从旧的 str 到新的 bytes 的转换是大多数迁移痛点的原因,这也是一个设计用于检测编码的库的核心关注点。
如果你了解 Python 2 但是对 Python 3 感到陌生,Guido van Rossum 的“Python 3.0 有什么新特性”列出了 15 个要点,总结了发生的变化,并提供了许多链接。Guido 以直率的话语开始:“你所知道的关于二进制数据和 Unicode 的一切都发生了变化。”Armin Ronacher 的博客文章“Python 中 Unicode 的更新指南”深入探讨了 Python 3 中 Unicode 的一些陷阱(Armin 不是 Python 3 的铁粉)。
第三版的Python Cookbook(O’Reilly)中的第二章“字符串和文本”,由大卫·比兹利和布莱恩·K·琼斯编写,包含了几个处理 Unicode 标准化、文本清理以及在字节序列上执行面向文本操作的示例。第五章涵盖了文件和 I/O,并包括“第 5.17 节 写入字节到文本文件”,展示了在任何文本文件下始终存在一个可以在需要时直接访问的二进制流。在后续的食谱中,struct模块被用于“第 6.11 节 读取和写入二进制结构数组”。
尼克·科格兰的“Python 笔记”博客有两篇与本章非常相关的文章:“Python 3 和 ASCII 兼容的二进制协议”和“在 Python 3 中处理文本文件”。强烈推荐。
Python 支持的编码列表可在codecs模块文档中的“标准编码”中找到。如果需要以编程方式获取该列表,请查看随 CPython 源代码提供的/Tools/unicode/listcodecs.py脚本。
书籍Unicode Explained由尤卡·K·科尔佩拉(O’Reilly)和Unicode Demystified由理查德·吉拉姆(Addison-Wesley)撰写,虽然不是针对 Python 的,但在我学习 Unicode 概念时非常有帮助。Programming with Unicode由维克多·斯汀纳自由出版,涵盖了 Unicode 的一般概念,以及主要操作系统和几种编程语言的工具和 API。
W3C 页面“大小写折叠:简介”和“全球网络字符模型:字符串匹配”涵盖了标准化概念,前者是一个简单的介绍,后者是一个以干燥标准语言撰写的工作组说明书—与“Unicode 标准附录#15—Unicode 标准化形式”相同的语调。Unicode.org的“常见问题,标准化”部分更易读,马克·戴维斯的“NFC FAQ”也是如此—他是几个 Unicode 算法的作者,也是本文撰写时 Unicode 联盟的主席。
2016 年,纽约现代艺术博物馆(MoMA)将 1999 年由 NTT DOCOMO 的栗田茂高设计的原始表情符号加入了其收藏品。回顾历史,Emojipedia发表了“关于第一个表情符号集的纠正”,将日本的 SoftBank 归功于已知最早的表情符号集,于 1997 年在手机上部署。SoftBank 的集合是 Unicode 中 90 个表情符号的来源,包括 U+1F4A9(PILE OF POO)。马修·罗森伯格的emojitracker.com是一个实时更新的 Twitter 表情符号使用计数仪表板。在我写这篇文章时,FACE WITH TEARS OF JOY(U+1F602)是 Twitter 上最受欢迎的表情符号,记录的出现次数超过 3,313,667,315 次。
¹ PyCon 2014 演讲“Python 中的字符编码和 Unicode”(幻灯片,视频)的第 12 张幻灯片。
² Python 2.6 和 2.7 也有bytes,但它只是str类型的别名。
³ 小知识:Python 默认使用的 ASCII“单引号”字符实际上在 Unicode 标准中被命名为 APOSTROPHE。真正的单引号是不对称的:左边是 U+2018,右边是 U+2019。
⁴ 在 Python 3.0 到 3.4 中不起作用,给处理二进制数据的开发人员带来了很多痛苦。这种逆转在PEP 461—为 bytes 和 bytearray 添加%格式化中有记录。
⁵ 我第一次看到“Unicode 三明治”这个术语是在 Ned Batchelder 在 2012 年美国 PyCon 大会上的优秀“务实的 Unicode”演讲中。
⁶ 来源:“Windows 命令行:Unicode 和 UTF-8 输出文本缓冲区”。
⁷ 有趣的是,微符号被认为是一个“兼容字符”,但欧姆符号不是。最终结果是 NFC 不会触及微符号,但会将欧姆符号更改为大写希腊字母 omega,而 NFKC 和 NFKD 会将欧姆符号和微符号都更改为希腊字符。
⁸ 重音符号只在两个单词之间唯一的区别是它们时才会影响排序—在这种情况下,带有重音符号的单词会在普通单词之后排序。
⁹ 再次,我找不到解决方案,但发现其他人报告了相同的问题。其中一位技术审阅者 Alex Martelli 在他的 Macintosh 上使用setlocale和locale.strxfrm没有问题,他的 macOS 版本是 10.9。总结:结果可能有所不同。
¹⁰ 那是一张图片—而不是代码清单—因为在我写这篇文章时,O’Reilly 的数字出版工具链对表情符号的支持不佳。
¹¹ 尽管在这个特定样本中,它并不比re更擅长识别数字。