目录:sheng的学习笔记-AI目录-CSDN博客
基础知识
构建卷积层时,你要决定过滤器的大小究竟是1×1(原来是1×3,猜测为口误),3×3还是5×5,或者要不要添加池化层。而Inception网络的作用就是代替你来决定,虽然网络架构因此变得更加复杂,但网络表现却非常好
本文用到基础知识
1*1卷积,需要看文章:sheng的学习笔记-AI-Network in Network(NIN)和1*1卷积-CSDN博客
残差网络:sheng的学习笔记-AI-残差网络-Residual Networks (ResNets)-CSDN博客
谷歌 Inception 网络简介
原理
构建卷积层时,你要决定过滤器的大小究竟是1×1,3×3还是5×5,或者要不要添加池化层。而Inception网络的作用就是代替你来决定,虽然网络架构因此变得更加复杂,但网络表现却非常好
这是你28×28×192维度的输入层,Inception网络或Inception层的作用就是代替人工来确定卷积层中的过滤器类型,或者确定是否需要创建卷积层或池化层
如果使用1×1卷积,输出结果会是28×28×#(某个值),假设输出为28×28×64,并且这里只有一个层

如果使用3×3的过滤器,那么输出是28×28×128。然后我们把第二个值堆积到第一个值上,为了匹配维度,我们应用same卷积,输出维度依然是28×28,和输入维度相同,即高度和宽度相同
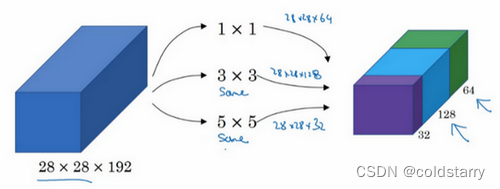
或许你会说,我希望提升网络的表现,用5×5过滤器或许会更好,我们不妨试一下,输出变成28×28×32,我们再次使用same卷积,保持维度不变。
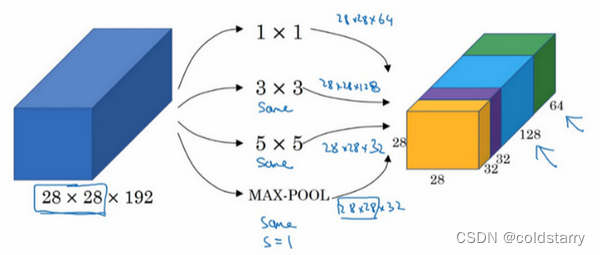
或许你不想要卷积层,那就用池化操作,得到一些不同的输出结果,我们把它也堆积起来,这里的池化输出是28×28×32。为了匹配所有维度,我们需要对最大池化使用padding,它是一种特殊的池化形式,因为如果输入的高度和宽度为28×28,则输出的相应维度也是28×28。然后再进行池化,padding不变,步幅为1
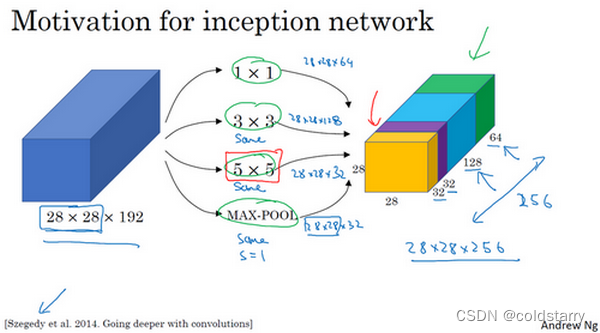
有了这样的Inception模块,你就可以输入某个量,因为它累加了所有数字,这里的最终输出为32+32+128+64=256。Inception模块的输入为28×28×192,输出为28×28×256。基本思想是Inception网络不需要人为决定使用哪个过滤器或者是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合
问题-参数太多
上述的方法,有个问题,参数太多,导致计算量太大
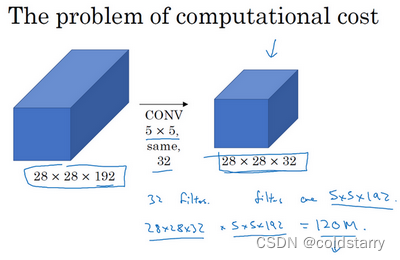
看这个5×5的过滤器,这是一个28×28×192的输入块,执行一个5×5卷积,它有32个过滤器,输出为28×28×32。前一张幻灯片中,我用一个紫色的细长块表示,这里我用一个看起来更普通的蓝色块表示。我们来计算这个28×28×32输出的计算成本,它有32个过滤器,因为输出有32个通道,每个过滤器大小为5×5×192,输出大小为28×28×32,所以你要计算28×28×32个数字。对于输出中的每个数字来说,你都需要执行5×5×192次乘法运算,所以乘法运算的总次数为每个输出值所需要执行的乘法运算次数(5×5×192)乘以输出值个数(28×28×32),把这些数相乘结果等于1.2亿(120422400),计算成本太大
解决方案-使用1*1卷积
1*1卷积的原理,在基础知识中有连接,可以查看
对于输入层,使用1×1卷积把输入值从192个通道减少到16个通道。然后对这个较小层运行5×5卷积,得到最终输出。请注意,输入和输出的维度依然相同,输入是28×28×192,输出是28×28×32,和上一页的相同。但我们要做的就是把左边这个大的输入层压缩成这个较小的的中间层,它只有16个通道,而不是192个
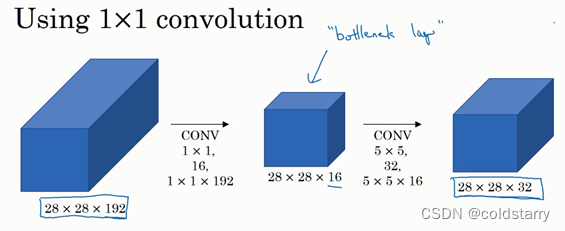
看看这个计算成本,应用1×1卷积,过滤器个数为16,每个过滤器大小为1×1×192,这两个维度相匹配(输入通道数与过滤器通道数),28×28×16这个层的计算成本是,输出28×28×192中每个元素都做192次乘法,用1×1×192来表示,相乘结果约等于240万
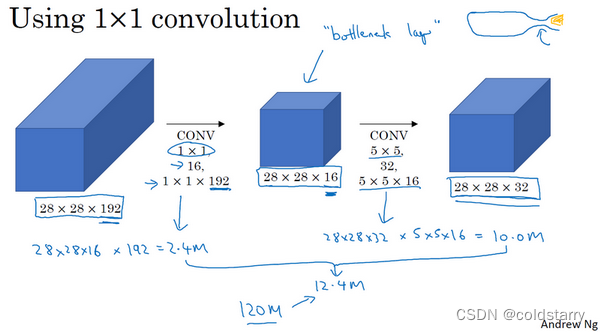
240万只是第一个卷积层的计算成本,第二个卷积层的计算成本:28×28×32,对每个输出值应用一个5×5×16维度的过滤器,计算结果为1000万。
所以所需要乘法运算的总次数是这两层的计算成本之和,也就是1204万,与上一张幻灯片中的值做比较,计算成本从1.2亿下降到了原来的十分之一,即1204万
Inception 网络(Inception network)
Inception模块
Inception模块会将之前层的激活或者输出作为它的输入,作为前提,这是一个28×28×192的输入。例子是:
- 先通过一个1×1的层,再通过一个5×5的层,1×1的层可能有16个通道,而5×5的层输出为28×28×32,共32个通道
- 为了在这个3×3的卷积层中节省运算量,你也可以做相同的操作,这样的话3×3的层将会输出28×28×128
- 通过一个1×1的卷积层,这时就不必在后面再跟一个1×1的层了,这样的话过程就只有一步,假设这个层的输出是28×28×64
- 再加上池化层
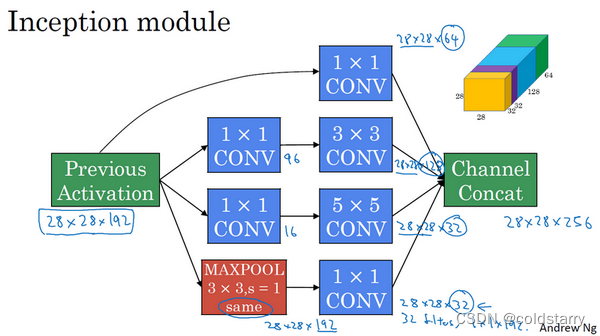
为了能在最后将这些输出都连接起来,我们会使用same类型的padding来池化,使得输出的高和宽依然是28×28,这样才能将它与其他输出连接起来。但注意,如果你进行了最大池化,即便用了same padding,3×3的过滤器,stride为1,其输出将会是28×28×192,其通道数或者说深度与这里的输入(通道数)相同。所以看起来它会有很多通道,我们实际要做的就是再加上一个1×1的卷积层,去进行我们在1×1卷积层的视频里所介绍的操作,将通道的数量缩小,缩小到28×28×32。也就是使用32个维度为1×1×192的过滤器,所以输出的维度其通道数缩小为32。这样就避免了最后输出时,池化层占据所有的通道
Inception 网络
最后,将这些方块全都连接起来。在这过程中,把得到的各个层的通道都加起来,最后得到一个28×28×256的输出。通道连接实际就是之前视频中看到过的,把所有方块连接在一起的操作。这就是一个Inception模块,而Inception网络所做的就是将这些模块都组合到一起

在网络的最后几层,通常称为全连接层,在它之后是一个softmax层(编号1)来做出预测,这些分支(编号2)所做的就是通过隐藏层(编号3)来做出预测,所以这其实是一个softmax输出(编号2),这(编号1)也是。这是另一条分支(编号4),它也包含了一个隐藏层,通过一些全连接层,然后有一个softmax来预测,输出结果的标签
你应该把它看做Inception网络的一个细节,它确保了即便是隐藏单元和中间层(编号5)也参与了特征计算,它们也能预测图片的分类。它在Inception网络中,起到一种调整的效果,并且能防止网络发生过拟合。
Inception-v4
v4的整体网络框架以及其中用到的inception-A、B、C block如图4所示,其中用到的stem-block如图5所示。
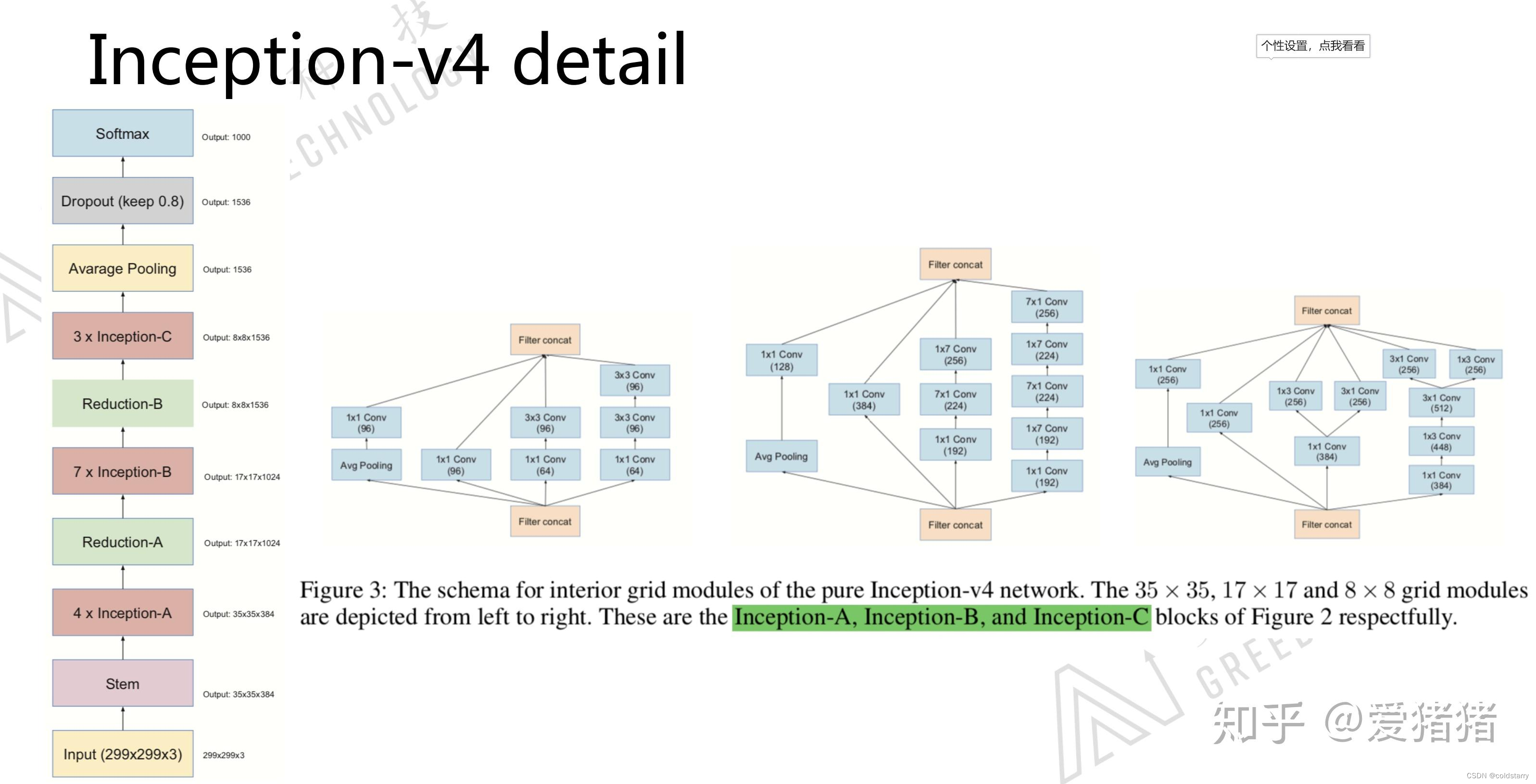
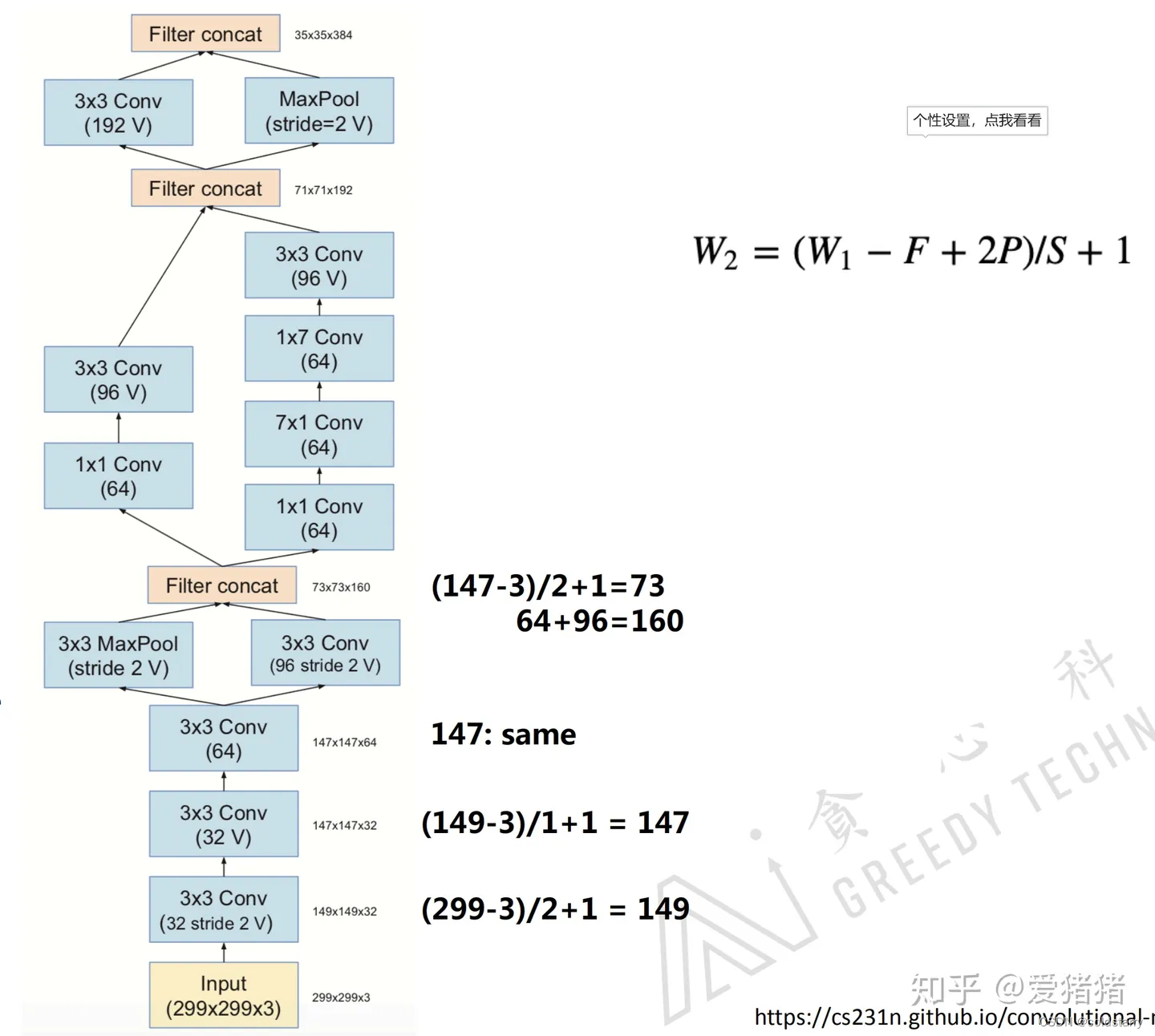
从图4来看,google提出的v4版本中用到的这三个block,从结构上来看,明显可以看出大量使用1*1卷积方法,这样就减少很多参数,从A-boock来看,block的不同通道,不考虑1*1卷积,分别使用了池化,不操作,一层3*3的卷积,两层3*3的卷积,从B-block来看,基本上相当于将A-block里的卷积用卷积核分解来替代,参数数量可以减少为原来的2/kernel-size,我思考这里的原因是,B-block因为比A深,所以为了保证提取复杂特征,所以要设计更加复杂的结构,但是为了减少参数数量在这里就用卷积核分解
Inception-ResNet-v2
这个网络结构与v4的整体框架相似,但其中用的block中用残差连接的思想替代了复杂的结构,两个网络框架的对比如图6所示
残差网络的细节,在基础知识中有连接
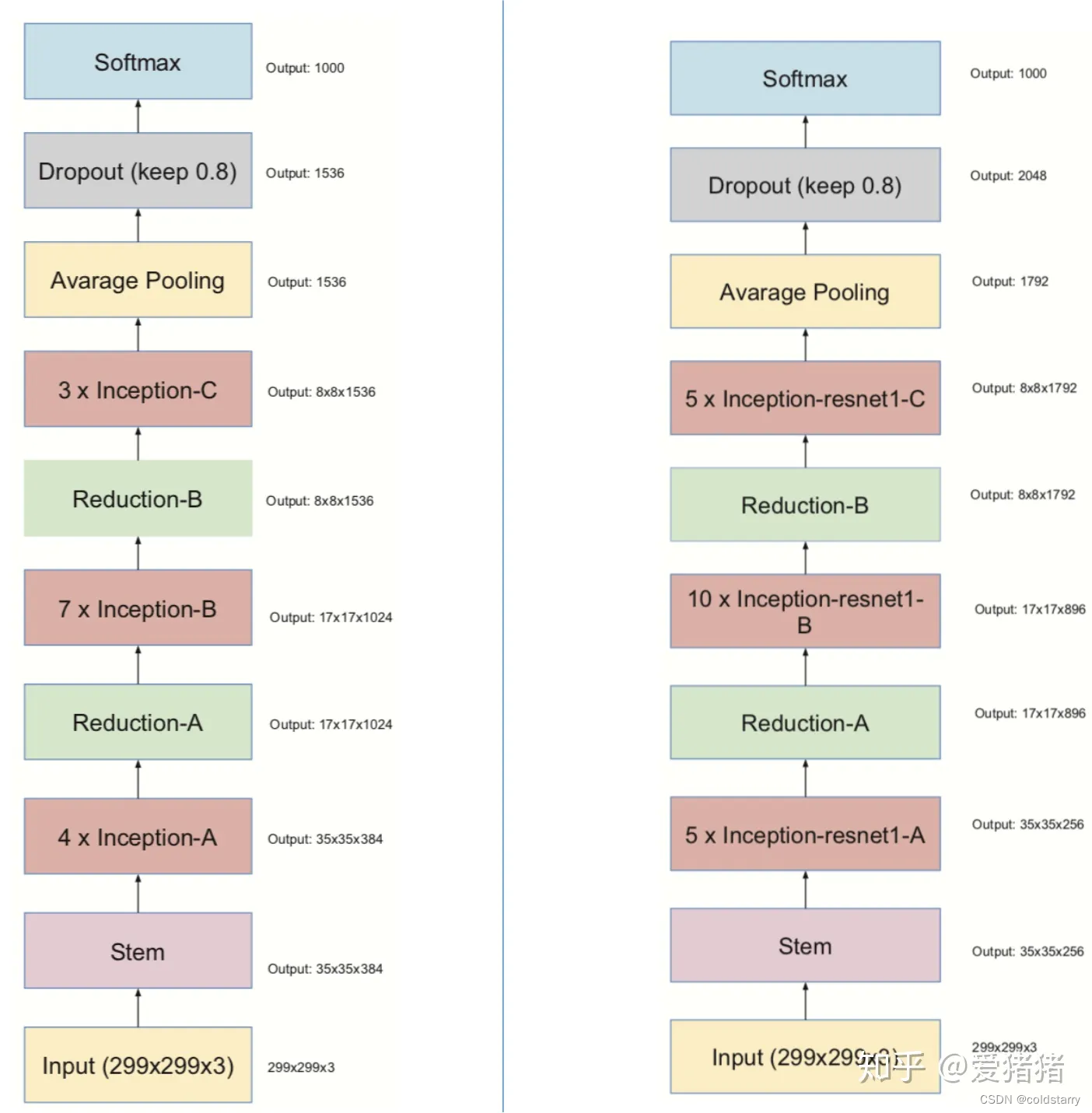
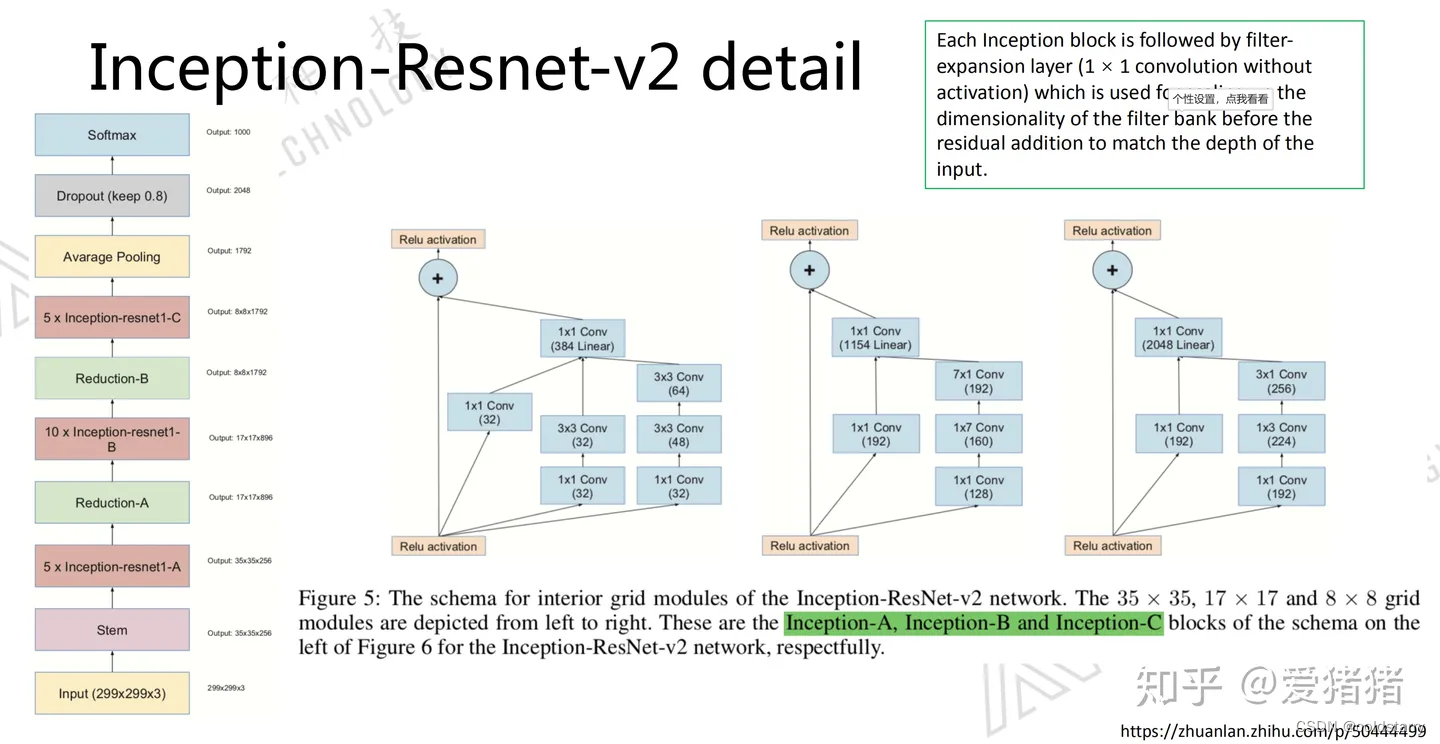
从图7来看,Inception ResNet v2版本里用的block,可以看出,几个block深度不同,结构的复杂程度却是相似的,而v4的block随着深度的增加,block在变得越来越复杂,随之而来,Inception ResNet v2里面用到的参数就很少了。
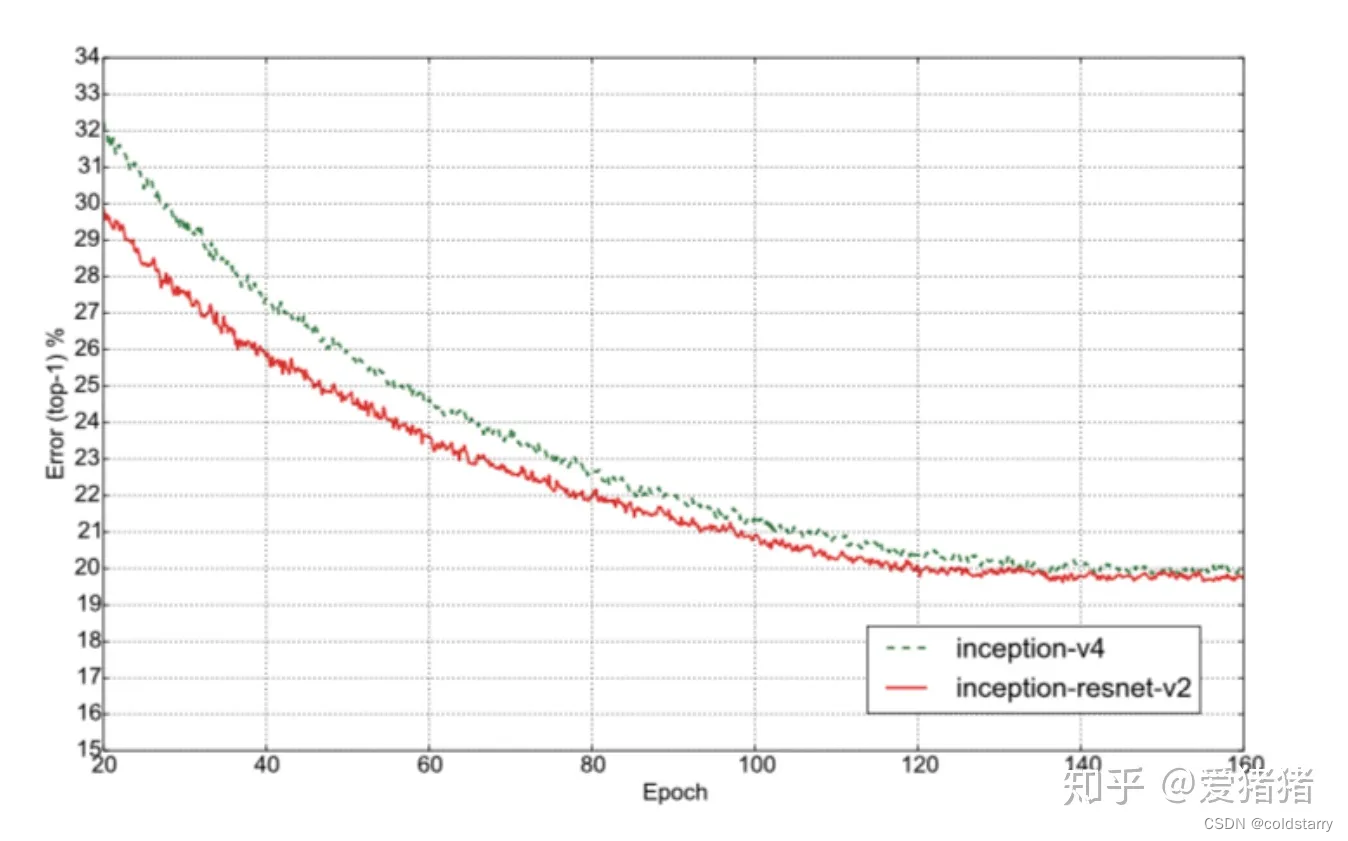
Inception v4 VS Inception ResNet v2
从图8两者对比效果来看,还是残差神经网络更胜一筹
参考文章:
Inception-ResNet卷积神经网络 - 知乎
吴恩达深度学习的视频








![[C语言]——内存函数](https://img-blog.csdnimg.cn/direct/e8e6c78f039044ad8a436cf14e24b8a3.png)