作者:David Pilato

我们在之前的文章中已经了解了如何丰富 Elasticsearch 本身和 Logstash 中的数据。 但如果我们可以从边缘设备中做到这一点呢? 这将减少 Elasticsearch 要做的工作。 让我们看看如何从具有代理处理器的 Elastic 代理中执行此操作。
Elastic Agent 代理文档说:
Elastic Agent 处理器是轻量级处理组件,可用于解析、过滤、转换和丰富源数据。 例如,你可以使用处理器来:
- 减少导出字段的数量
- 使用附加元数据增强事件
- 执行额外的处理和解码
- 清理数据
这正是我们想要做的,但 Elastic Agent 处理器的限制之一是它无法使用来自 Elasticsearch 或其他自定义数据源的数据来丰富事件。
这意味着我们需要在这里保持非常静态。 我们需要提前知道我们想要用什么来丰富我们的数据。 这不是什么大问题,因为我们随时可以更改代理的配置以在以后添加新的功能。 例如,我们可以将采集管道添加到 Elasticsearch 中,或者将数据从 Elastic Agent 发送到 Logstash 来丰富它。
启动 Elastic 代理
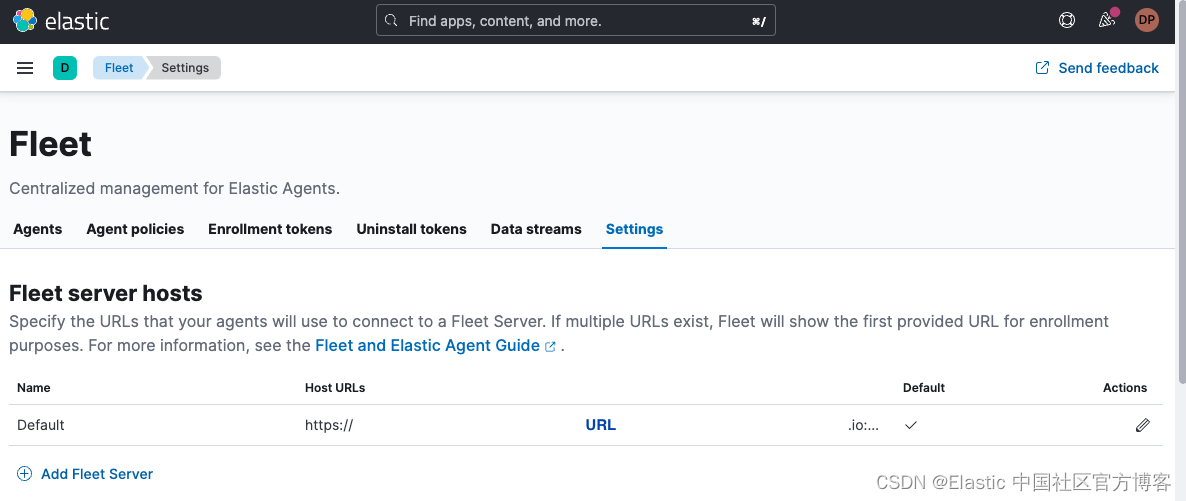
从 Elastic Cloud 运行时,你只需按照说明 enroll 代理或转到 Fleet 控制台并从 “Settings” 选项卡获取 URL:
以及 Enrollment tokens选项卡中的秘密 TOKEN:

由于我想使用 Docker 在本地运行代理,因此我将使用以下命令并将 URL 和 TOKEN 值替换为我的 Fleet 控制台中的值:
docker run \
--env FLEET_ENROLL=1 \
--env FLEET_URL=URL \
--env FLEET_ENROLLMENT_TOKEN=TOKEN \
-v $(pwd)/datadir:/usr/share/elastic-agent/db \
--rm docker.elastic.co/beats/elastic-agent:8.12.0请注意,我将本地目录安装到 /usr/share/elastic-agent/db ,以便我可以在本文后面共享一些内容。 几秒钟后,你应该在 Fleet 控制台中看到你的代理可用:

添加字段
我们可以使用 add_fields 处理器向文档添加字段。 例如,我们可以在文档中添加 vip 和 name 字段:
processors:
- add_fields:
fields:
vip: true
name: 'David P'使用条件
前面的示例将向每个文档添加 vip 和 name 字段。 显然,我们只想在满足条件时添加字段。 例如,只有当 clientip 字段为 30.156.16.164 时,我们才能添加 vip 和 name 字段:
processors:
- add_fields:
when:
equals:
clientip: '30.156.16.164'
fields:
vip: true
name: 'David P'由于这里有一个网络 IP 地址,因此我们还可以使用 CIDR 表示法,它不比较 “字符串”,而是比较 “网络地址”。 我们正在使用网络处理器条件:
processors:
- add_fields:
when:
network:
clientip: '30.156.16.164'
fields:
vip: true
name: 'David P'使用更多条件
由于我们的条件数量有限,我们可以使用多个 add_fields 处理器根据条件添加字段:
processors:
- add_fields:
when:
network:
clientip: '30.156.16.164'
fields:
vip: true
name: 'David P'
- add_fields:
when:
network:
clientip: '164.85.94.243'
fields:
vip: true
name: 'Philipp K'使用脚本添加字段
我们还可以使用 script processor 来使用 JavaScript 添加字段。 例如,我们可以根据 clientip 字段的值添加 vip 字段:
processors:
- script:
lang: javascript
source: >
function process(event) {
var clientip = event.Get('network.clientip');
if (clientip == '30.156.16.164') {
event.Put('vip', true);
event.Put('name', 'David P');
}
}这里我们内联了脚本,但我们也可以使用包含脚本的文件:
processors:
- script:
lang: javascript
file: /usr/share/elastic-agent/db/enrich.js而 enrich.js 的内容是:
function process(event) {
var clientip = event.Get('network.clientip');
if (clientip == '30.156.16.164') {
event.Put('vip', true);
event.Put('name', 'David P');
}
}还有另一个有趣的选项允许我们从一个目录加载多个脚本:
processors:
- script:
lang: javascript
files:
- /usr/share/elastic-agent/db/dataset.js
- /usr/share/elastic-agent/db/enrich.js我们可以在 dataset.js 中构建 IP 地址和名称之间的映射:
var dataset = {
'30.156.16.164': {'vip': true, 'name': 'David P'},
'164.85.94.243': {'vip': true, 'name': 'Philipp K' },
'50.184.59.162': {'vip': true, 'name': 'Adrienne V' },
'236.212.255.77': {'vip': true, 'name': 'Carly R' },
'16.241.165.21': {'vip': true, 'name': 'Naoise R' },
'246.106.125.113': {'vip': true, 'name': 'Iulia F' },
'81.194.200.150': {'vip': true, 'name': 'Jelena Z' },
'111.237.144.54': {'vip': true, 'name': 'Matt R' }
}我们现在可以修改 enrich.js 脚本以使用此数据集:
function process(event) {
var clientip = event.Get('network.clientip');
if (dataset[clientip]) {
event.Put('vip', dataset[clientip].vip);
event.Put('name', dataset[clientip].name);
}
}结论
我们现在拥有一组三个解决方案来丰富我们的数据:
- 丰富 Elasticsearch 本身的数据
- 加快 Logstash 中的 Elasticsearch 查找速度
- 使用代理处理器丰富边缘数据
第一个解决方案是最灵活的,但它需要一个具有足够资源的集群来处理负载。 第二种解决方案是一个很好的折衷方案,因为它允许你减少 Elasticsearch 的负载,但它要求你拥有 Logstash 集群。 第三种解决方案是最容易实现的解决方案,但也是最静态的解决方案。
我希望你喜欢这一系列的帖子。 如果你有任何疑问,请随时在 Elastic 社区论坛上提问。




![[C语言]——内存函数](https://img-blog.csdnimg.cn/direct/e8e6c78f039044ad8a436cf14e24b8a3.png)