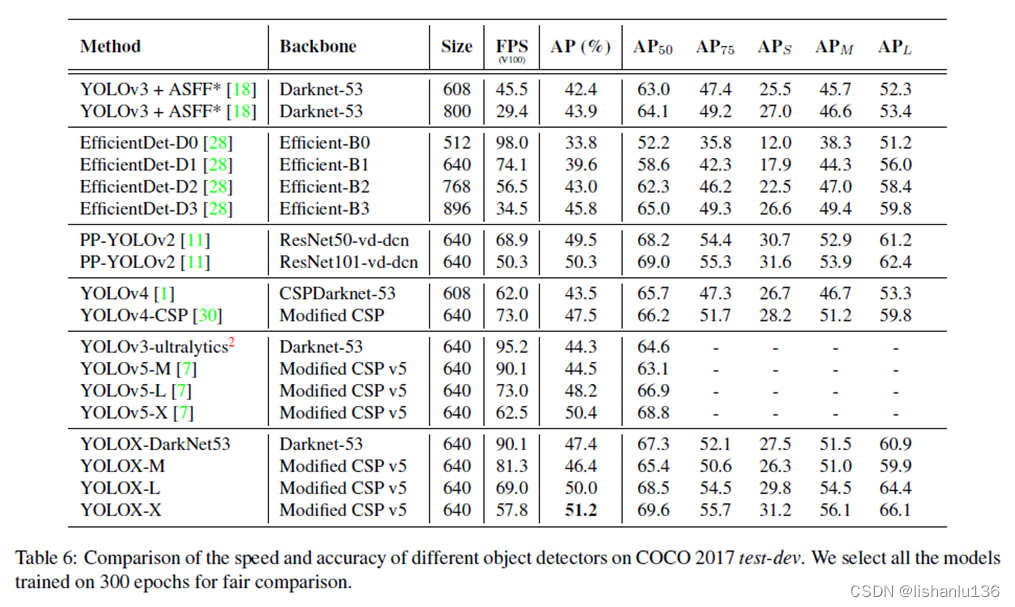
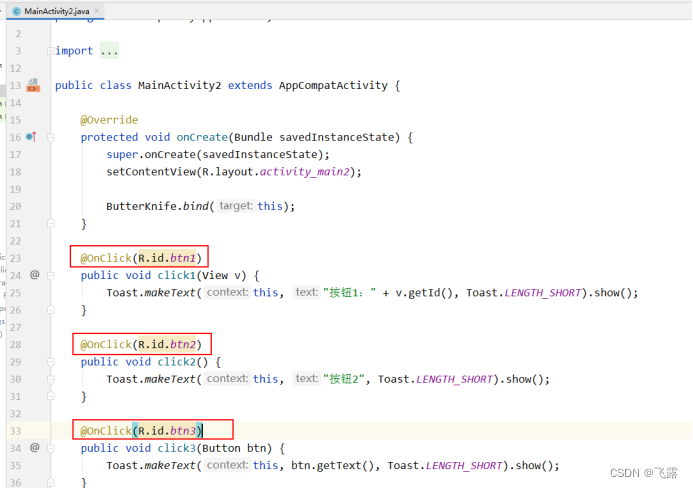
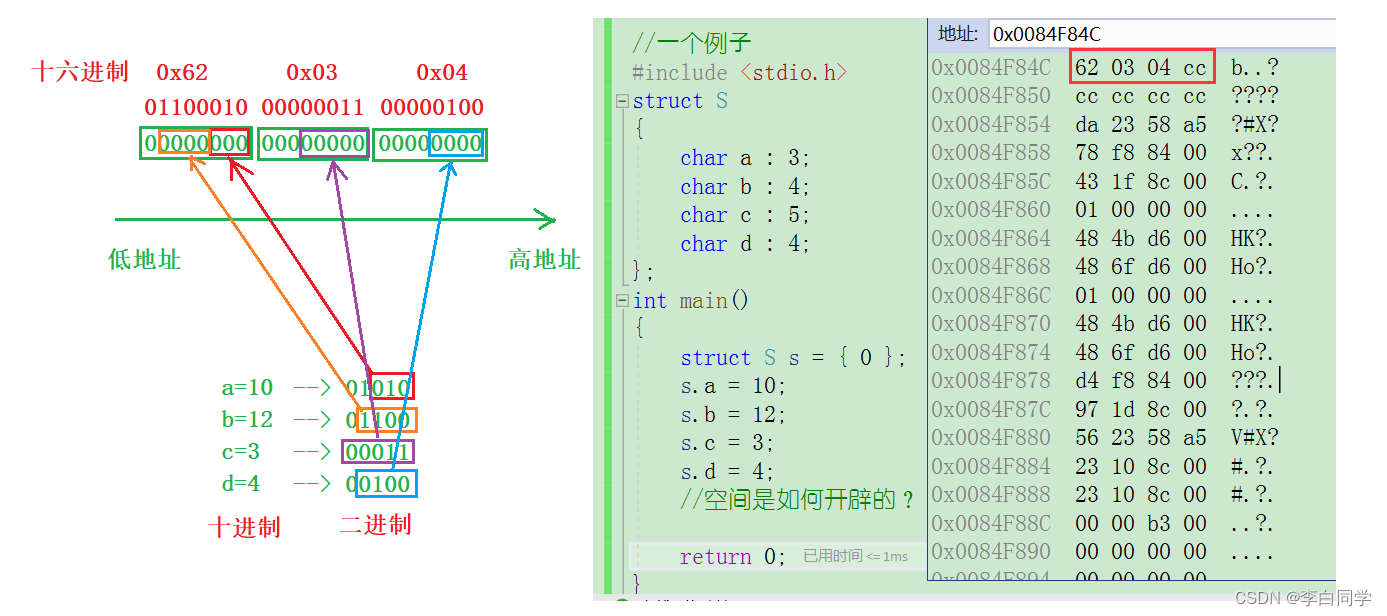
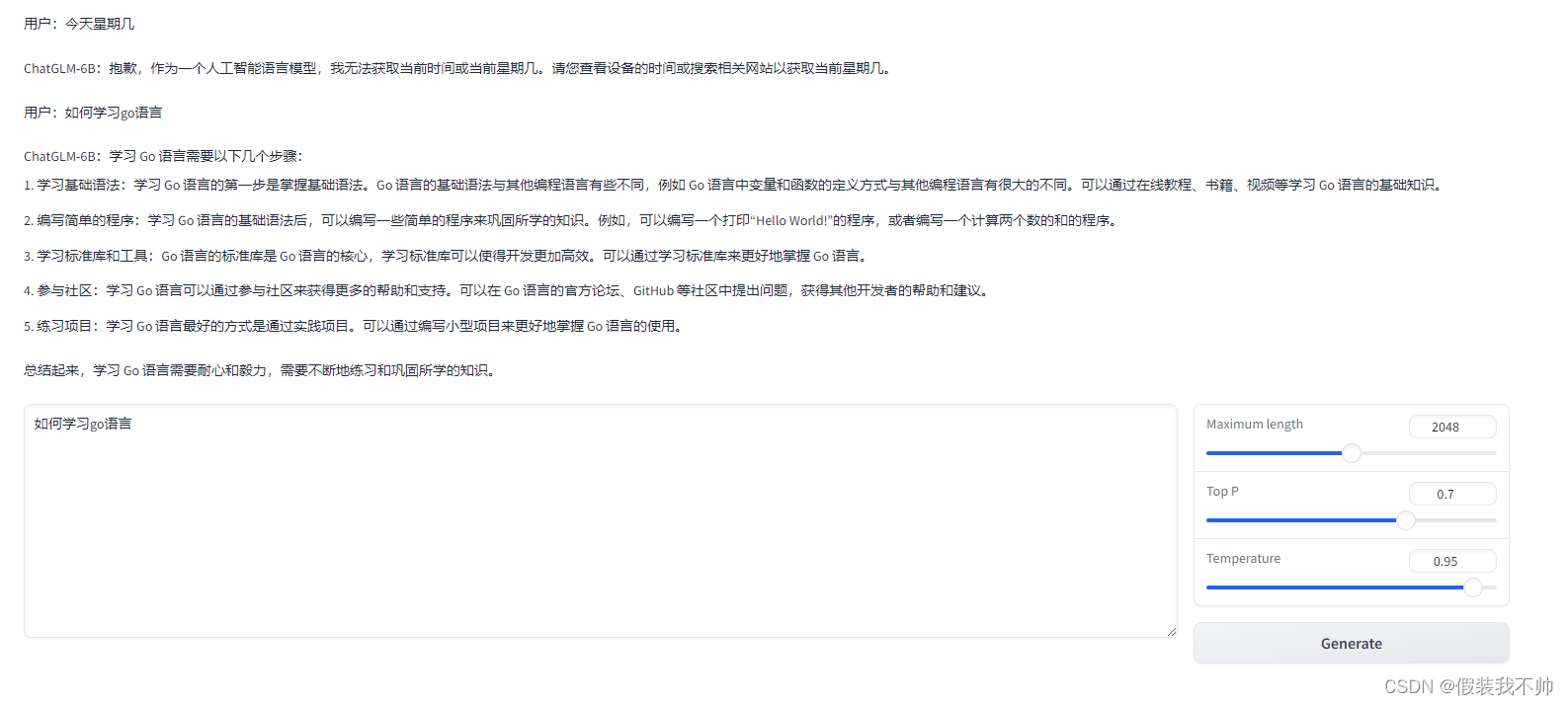
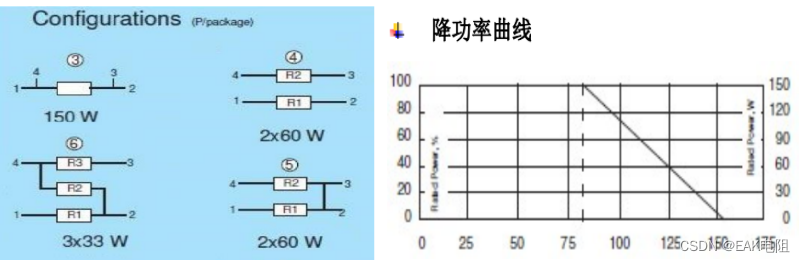
前言
在数字化时代,视觉内容的创造和动态化已成为创意表达和信息传递的重要工具。最近由香港中文大学、腾讯AI Lab联合研发的视频AI模型DynamiCrafter,这一模型能够将静态图像转化为逼真的动态视频,开创了文本到视频生成技术的新纪元。
-
Huggingface模型下载:https://huggingface.co/Doubiiu
-
AI快站模型免费加速下载:https://aifasthub.com/models/Doubiiu

动态化静态图像的长期挑战
长久以来,将静态图像转化为动态视频在计算机视觉领域一直是一个技术难题。传统方法如物理模拟或基于特定参考的技术,虽然在模拟自然场景的随机动态(如云和流体)或特定领域的运动(如人体动作)方面取得了一定进展,但在广泛的视觉内容上的应用受到了限制。

DynamiCrafter的创新与优势
DynamiCrafter模型的推出,突破了这一限制,为开放领域图像的动态化提供了全新的解决方案。通过利用文本到视频扩散模型的运动先验,DynamiCrafter可以根据用户提供的文本提示,将几乎任何类型的静态图像转换成动态内容,极大地拓宽了AI视频生成的应用范围。

这一模型的关键创新在于其双流图像注入机制,包括文本对齐的上下文表示和视觉细节指导。该机制确保了生成的动态内容既逻辑自然又与原图像高度一致,相较于现有方法,展示了显著的优势。DynaCrafter流程:在训练过程中,通过提出的双流图像注入机制随机选择一帧视频作为去噪过程的图像条件,以继承视觉细节并以上下文感知的方式消化输入图像。在推理过程中,模型可以从输入静态图像的噪声条件下生成动画剪辑。

应用前景
DynamiCrafter的开发不仅标志着文本驱动的图像动态化研究的进步,更为电子商务、广告制作、娱乐及教育等领域的内容创作提供了强大的新工具。它使得用户能够轻松创造出富有创意的动态视频内容,无需依赖于复杂的动画制作过程。DynamiCrafter支持以静态图像作为条件,使用文本提示作为动作引导生成约2秒的短视频,包含分辨率为576x1024的16帧画面,让我们看一些官方示例。


开放源代码和未来展望
作为一个开源模型,DynamiCrafter的发布促进了技术的共享和创新。展望未来,随着模型的进一步完善和应用的深入,DynamiCrafter预计将在AI辅助的视觉内容创造领域扮演越来越重要的角色,开启视觉内容生产的新篇章。
模型下载
Huggingface模型下载
https://huggingface.co/Doubiiu
AI快站模型免费加速下载
https://aifasthub.com/models/Doubiiu