目录
- 摘要
- 介绍
- 1.研究背景和意义
- 2.先前的模型提出了什么方法?解决了什么问题?有什么不足?
- 3.最近的研究提出了什么方法?解决了什么问题?
- 4.最新的研究提出了什么方法?解决了什么问题?有什么不足?我们如何解决的这些不足?
摘要
零样本学习(ZSL)是通过在嵌入空间或特征生成中从已见类别向未见类别转移知识来实现的。然而,基于嵌入的方法存在hubness问题,而基于生成的方法可能包含相当大的偏差。为了解决这些问题,本文提出了一种多个生成对抗网络联合模型(JG-ZSL)。首先,我们将基于生成的模型和基于嵌入的模型相结合,通过将真实样本和合成样本映射到嵌入空间进行分类,建立了一个混合ZSL框架,有效地缓解了数据不平衡的问题。其次,基于原始生成方法模型,引入了一个耦合的GAN来生成语义嵌入,可以在嵌入空间中为未见类别生成语义向量,以减轻映射结果的偏差。最后,采用语义相关的自适应边界中心损失,可以明确地鼓励类内紧凑性和类间可分离性,并且还可以指导耦合的GAN生成具有辨别性和代表性的语义特征。所有对四个标准数据集(CUB、AWA1、AWA2、SUN)的实验表明,所提出的方法是有效的。
介绍
1.研究背景和意义
在研究中,监督分类取得了巨大成功,但在这种分类方法中,每个类别都需要足够的标记训练,并且学习的分类器不能处理未见过的类别。为了解决以上问题,提出了少量/一次性学习、开放集识别、累积学习、类增量和开放世界等方法。然而,在上述方法中,如果在测试阶段出现没有可用标签实例的未见类别,则分类器仍然无法确定它们的类别标签。因此,提出了零样本学习(ZSL)。通过辅助信息,其中包含了已见和未见类别的描述,以及从属于已见类别的训练集中学到的知识,提供了足够的标记实例。ZSL 方法可以为属于未见类别的实例生成预测,尽管已见和未见类别是不重叠的;也就是说,鉴于属于已见类别的标记训练实例,零样本学习旨在学习一个可以对属于未见类别的测试实例进行分类的分类器。从这个定义可以看出,零样本学习的一般思想是将训练实例中包含的知识转移到测试实例分类的任务中。训练和测试实例所涵盖的标签空间是不重叠的。因此,零样本学习是迁移学习的一个子领域。在迁移学习中,源领域和源任务中包含的知识被转移到目标领域,以便在目标任务中学习模型。自从诞生以来,零样本学习(ZSL)已成为机器学习领域的快速发展领域,在计算机视觉、自然语言处理和普适计算等领域都有广泛的应用。
2.先前的模型提出了什么方法?解决了什么问题?有什么不足?
先前针对ZSL的工作主要学习了一个空间嵌入函数来实现分类。根据嵌入空间的选择,基于嵌入的方法可以分为三类:语义空间嵌入方法、视觉空间嵌入方法和公共空间嵌入方法。它们直接估计了视觉特征与其对应属性之间的条件分布或映射关系。语义空间嵌入方法直接将视觉特征映射到语义空间。DeViSE是最具代表性的模型之一;它使用高效的排名损失制定了图像与语义空间之间的线性映射,并在大规模ImageNet数据集上进行了评估。然而,使用语义空间作为嵌入空间意味着视觉特征向量需要投影到语义空间中,这会缩小投影数据点的方差,从而加剧中心问题。为了缓解中心问题,李等人提出了一种新颖的基于深度神经网络的嵌入模型(DEM)。==虽然DEM将CNN子网络的输出视觉特征空间用作嵌入空间,在一定程度上可以缓解中心问题,但是视觉特征流形和语义特征之间的不一致导致了语义差距。==为了解决上述问题,Min等人提出了一个特定领域的嵌入网络(DSEN)模型,考虑了语义一致性问题,并防止语义关系在嵌入空间中被破坏。尽管基于嵌入的方法已经被使用和发展了很长时间,并且是一种非常有竞争力的零样本图像分类方法,但由于已见类和未见类之间训练样本数量的极端不平衡,大多数现有方法仍然存在很大的局限性。
3.最近的研究提出了什么方法?解决了什么问题?
最近的研究主要集中在利用生成模型合成图像特征,生成方法已成为一个热门的研究课题。这些方法属于基于数据增强的范畴。这一类方法的基本假设是,从已见类学习到的类内样本交叉关系可以应用于未见类。一旦从已见类中建模和学习了样本间的交叉关系,就可以将其应用于未见类的未标记样本,从而生成新样本,并将无监督学习转化为使用合成新样本的有监督学习。根据不同的生成模型,现有的基于生成的方法主要包括基于GAN的方法、基于VAE的方法和基于正态流的方法。基于正态流的方法通过将简单分布映射到复杂分布来构建复杂分布,允许进行精确的似然计算,同时具有高效的可并行化能力,但由于架构的特殊性,尚未得到广泛研究。大多数基于VAE的方法都是单向对齐的。这种方法捕获了视觉特征的低维潜在特征,然后通过解码和重构公式实现生成的伪视觉特征与语义属性之间的单向对齐。
SE-GZSL采用了基于VAE的结构,生成模型由概率编码器和条件解码器组成。同时,引入了反馈驱动机制,可以提高生成器的可靠性。尽管VAE能够稳定地生成伪视觉特征以有效地避免模式崩溃,但生成的伪视觉特征中包含的语义信息非常有限。为了克服上述问题,提出了基于GAN的方法;这种方法在模型训练后能够生成高质量的伪视觉特征。VERMA等人提出了一种基于类属性条件设置的元学习模型ZSML。发生器模块和带有分类器的鉴别器模块与元学习代理相关联,模型只需输入少量可见类样本即可训练。Xian等人利用生成对抗网络基于语义特征进行分类,并利用高斯噪声生成未见视觉特征,将零样本学习问题转化为有监督分类问题。基于生成的方法的结果优于基于嵌入的方法,并且目前也是主流方法。
4.最新的研究提出了什么方法?解决了什么问题?有什么不足?我们如何解决的这些不足?
在2022年的最新工作中,嵌入式和生成式方法都得到了进一步的探索和更新。徐等人提出了一种名为视觉基础语义嵌入模型(VGSE)的模型,该模型从已见类中学习视觉聚类,并通过建立已见和未见类之间的关系来自动预测每个类别的语义嵌入,给定了无监督的外部知识源。在生成式方法方面,为了生成高质量和多样化的图像特征,于等人提出了一种新的生成模型,该模型添加了一个语义约束模块,并引入了欧氏距离损失来约束特征生成。尽管上述方法可以解决零样本学习存在的问题,但也引入了一个新问题:基于生成的方法的先前工作仅使用一个生成对抗网络来模拟未见类的视觉特征,并忽略了这些生成特征在映射空间中的分布。这可能使得生成特征的语义映射点更接近语义空间中已见类的语义原型,导致最终的分类结果仍然对已见类存在偏见。
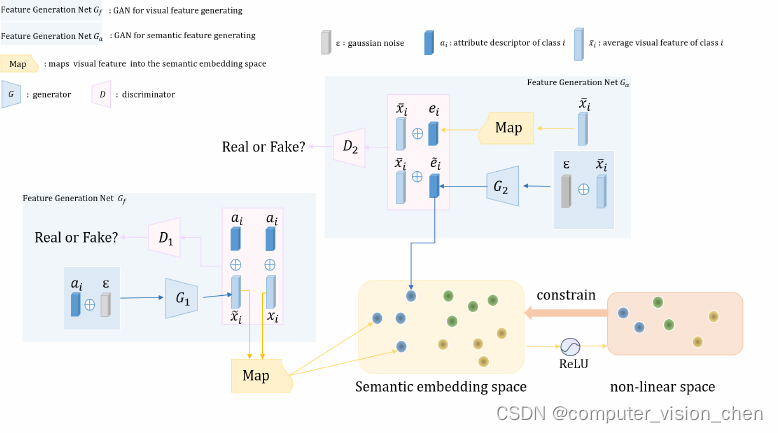
为了兼顾两者的优点并解决上述新问题,我们首先提出了一个混合模型,该模型可以实现基于空间嵌入和基于生成的方法。
其次,我们引入了一个生成对抗网络,用于在嵌入空间中模拟未见类特征的映射点。尽管多个GAN级联的模型在监督学习中已经被充分验证和使用,但尚未应用于零样本学习。在本文中,我们首次引入了多级GAN堆栈结构,以优化数据不平衡问题。
第三,我们为耦合的GAN提出了一个语义相关的自适应边缘中心损失。该损失可以鼓励类内紧密度和类间可分离性,并实现耦合的GAN能够更好地生成具有代表性和差异性的语义特征。
我们在四个基准数据集上评估了我们的方法,实验结果表明,我们的方法与其他方法相比具有竞争力。本文的贡献总结如下:
- 提出了一个混合模型,即联合生成对抗网络(JG-ZSL),将基于嵌入的方法和基于生成的方法结合起来,以提高模型的敏感性和特异性。
- 引入了一种用于生成语义特征的GAN,以在嵌入空间中生成映射点,该点可以为语义空间中的未见类生成语义向量,从而减轻映射结果的偏见。
- 设计了语义相关的自适应边缘中心损失(SEMC-loss)用于语义生成的GAN,以确保生成的映射点不偏向其他类别,并实现整个模型更好地区分不同类别。
- 我们在四个基准数据集上评估了我们的模型,实验结果表明,我们提出的方法可以实现高准确性。