Nacos
实际上从设计思想来说 Eureka 和 nacos 是一样的。
后者是Alibaba推出的 一款更强大 功能更丰富的注册中心
你可以理解为Eureka的高配版
技多不压身既然了解了 Eureka, nacos也来学习一下吧!
安装
首先nacos不像eureka 直接pom里面引个依赖就搞定了,它需要单独的安装 总体就几步 安装 配置 启动 访问
在Nacos的GitHub页面,提供有下载链接,可以下载编译好的Nacos服务端或者源代码:
GitHub主页:https://github.com/alibaba/nacos
GitHub的Release下载页:https://github.com/alibaba/nacos/releases
Nacos默认端口是8848
安装到本地目录之后 到bin文件夹下 输入单机模式启动命令:
startup.cmd -m standalone
依赖
首先在项目最外层的pom里面 导入管理依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
然后在具体的服务里导入客户端依赖,然后把eureka注释掉(为什么叫客户端 和eureka同理 每个服务都是nacos的客户)
<!--eureka客户端依赖-->
<!-- <dependency>-->
<!-- <groupId>org.springframework.cloud</groupId>-->
<!-- <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>-->
<!-- </dependency>-->
<!-- nacos客户端依赖包 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
然后我们启动 会发现 已经注册了2个实例 和eureka同理:
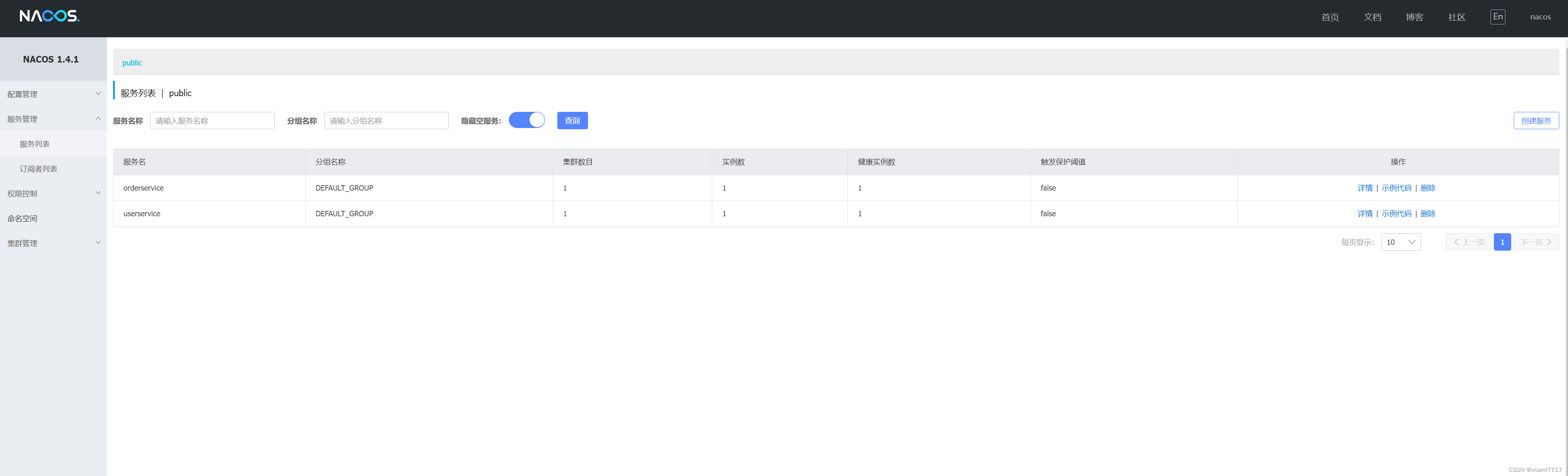
ok 这里就是nacos的基础使用 下面讲两个重要的特性:
服务多级存储模型
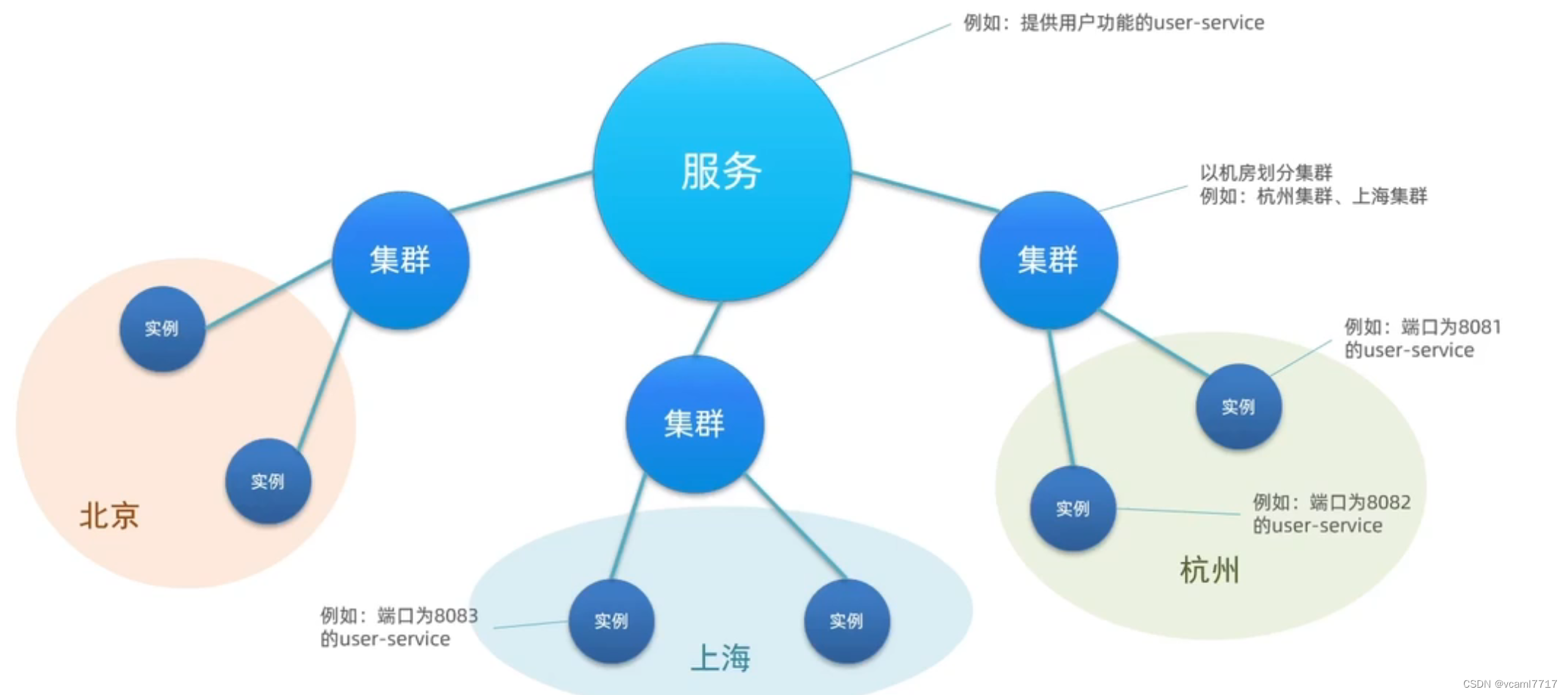
回到上面的例子 服务A 要调用 服务B, 但是在实际的生产环境中,服务B可能有成百上千的实例 而且还不在一个城市 比如深圳机房有100个
广州机房有20个 (异地容灾) 一共120个。
当你的服务A 发送一个请求的时候 注册中心发现有120个实例 根据正常的负载均衡原则 那就120个里面挑一个。
但是 因为异地的那20个是以防不测的 正常情况下你跨城市调会比较慢 我希望是请求过来就优先调 深圳的100个实例 如果这100个全挂了 就去调异地的。
所以我们明确一下 nacos里面的集群 就是同在一个地区或者一个机房的多个实例:
配置其实很简单:
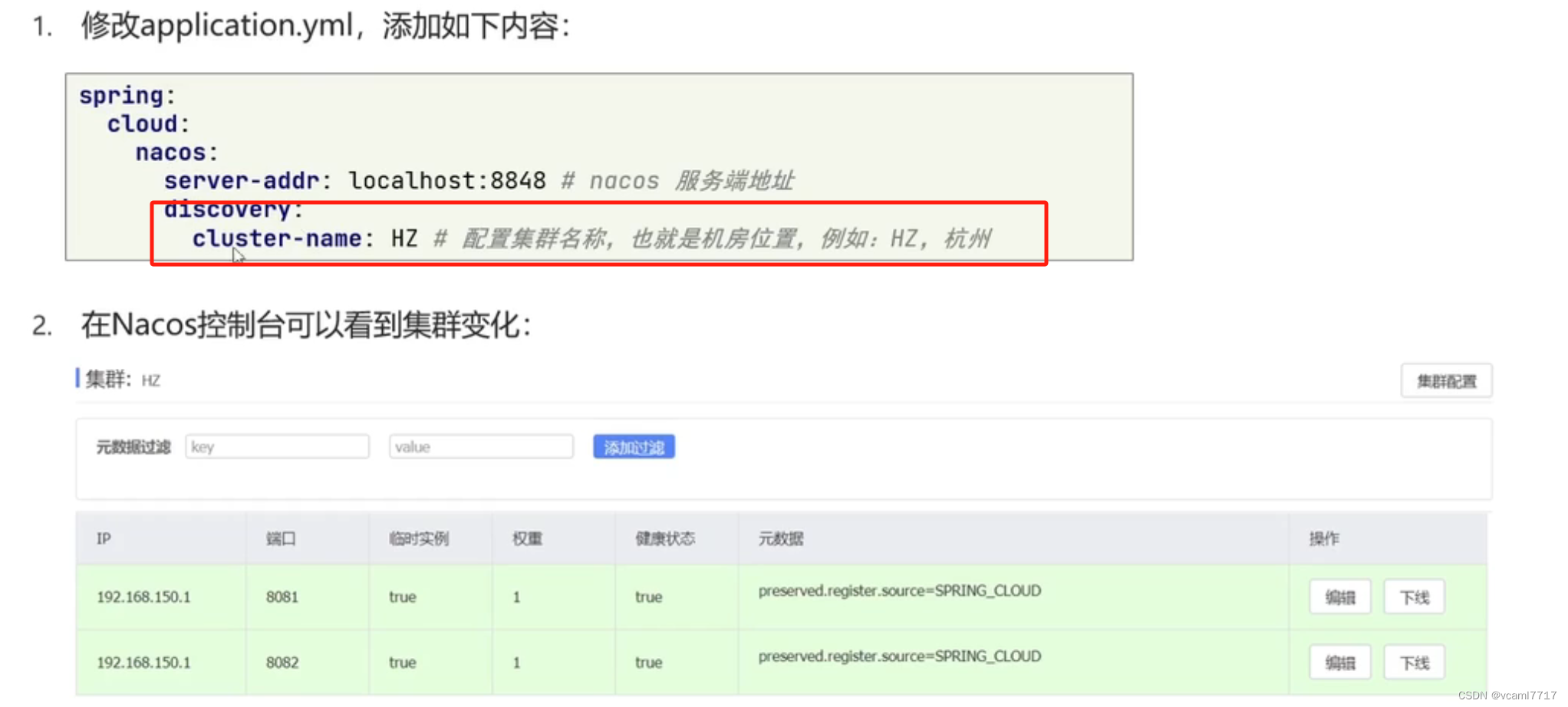
这里的cluster-name 名字我们自定义就好了 你想让它优先调那个集群就选哪个集群。
环境隔离
环境隔离是一个非常重要的特性,刚才的集群隔离是为了负载均衡 和异地容灾, 而环境隔离一般是我们的开发环境 测试环境 生产环境做隔离,如果大家用过Apollo 动态配置的话就很好理解这个概念。
我们在实际工作中 有很多机器是测试环境用的 有很多机器是生产环境用的, 它们之间肯定是严格隔离的! 当一个测试环境服务A去注册中心找服务B的时候 nacos能把生产环境B给你调吗? 肯定是不行的
所以在nacos里面对所有注册给它的实例 要进行第一级划分就是环境划分,比如配置了dev环境的实例都放一起 让它们相互调用
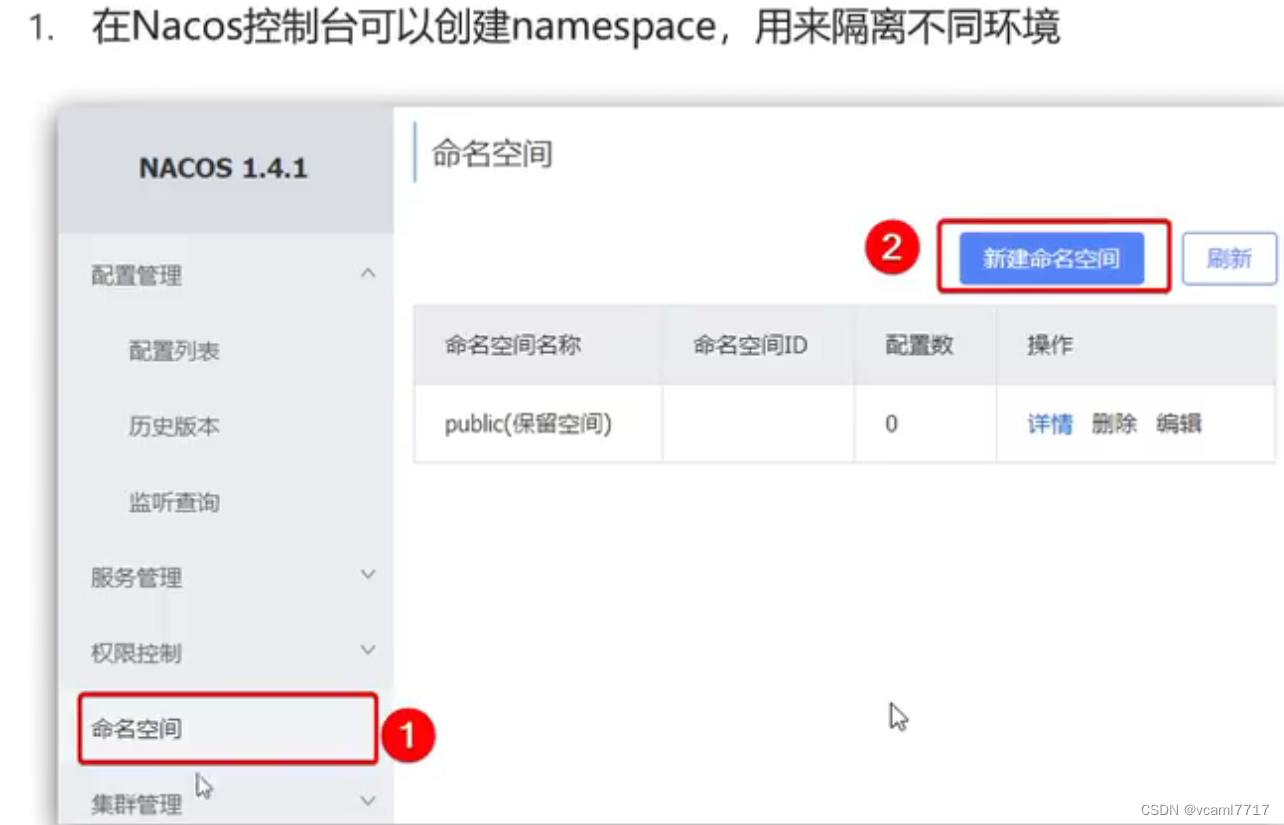
我们可以在nacos的 命名空间 里面创建独立的命名空间 比如dev test pro
再把它的id配置到application.yml就好了:
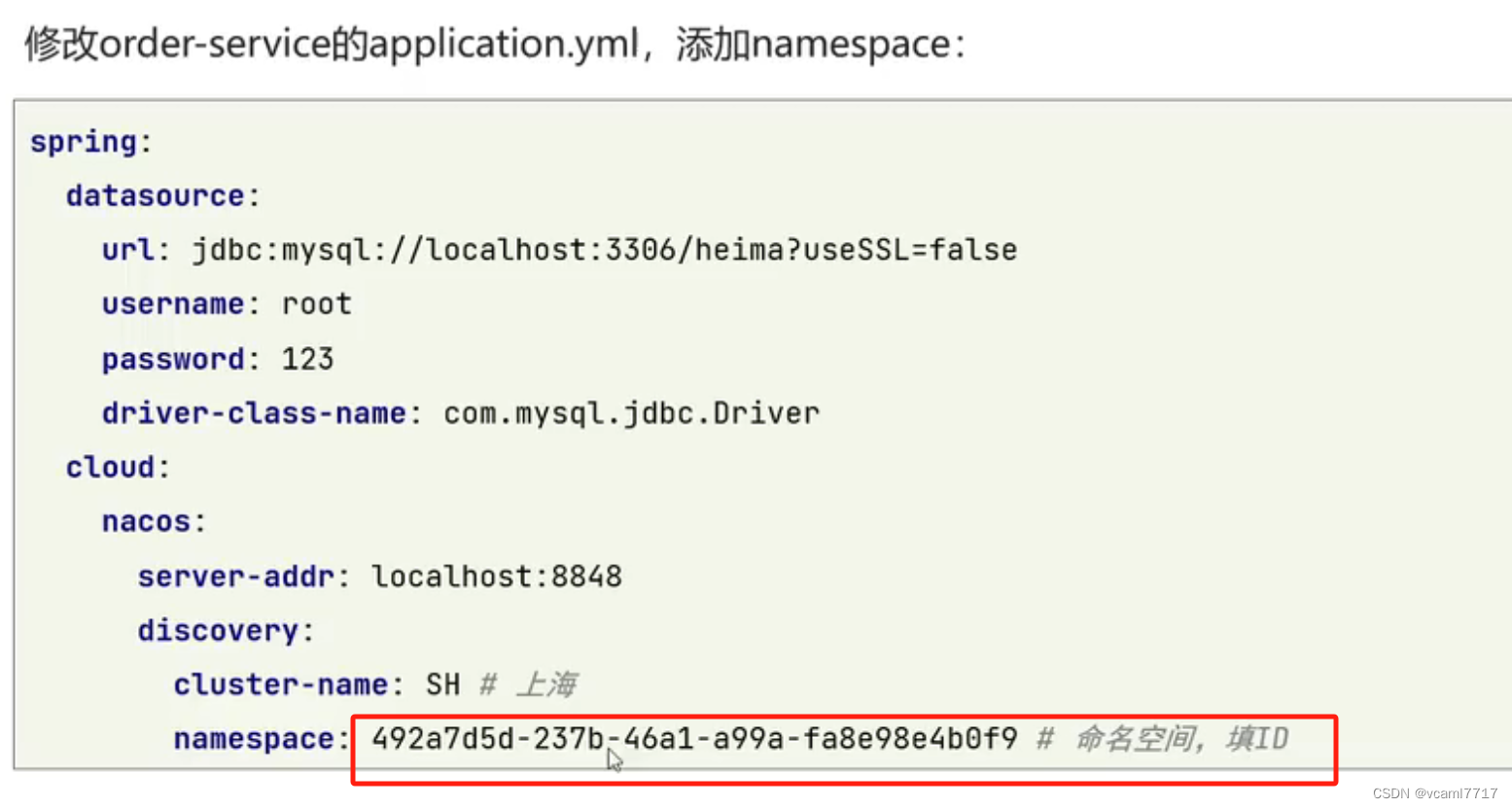
上面的这些对我们开发人员来说最重要的是理解,因为实际工作中 这些配置都是运维搞的 不需要我们手动配这些,重要的是你要知道nacos这些特性 理解这些配置属性名称代表什么 别一看不认识
最后留一个问题 我们说了配置命名空间和集群 就是application.yml加一行配置就可以了。
可问题来了 现在有10万个机器 每个服务器上部署了一个服务 需要配置命名空间和集群
难道让运维一个一个一个 上去改吗。。。。。。。。
这个怎么解决