Real-world Anomaly Detection in Surveillance Videos 论文阅读
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Proposed Anomaly Detection Method
- 3.1. Multiple Instance Learning
- 3.2. Deep MIL Ranking Model
- 4. Dataset
- 4.1. Previous datasets
- 4.2. Our dataset
- 5. Experiments
- 5.1. Implementation Details
- 5.2. Comparison with the State-of-the-art
- 5.4. Anomalous Activity Recognition Experiments
- 6. Conclusions
中文标题:真实世界中的监控视频异常检测
文章信息:

原文链接:https://arxiv.org/abs/1801.04264
源码:https://github.com/WaqasSultani/AnomalyDetectionCVPR2018
发表于:CVPR 2018
Abstract
监控视频能够捕捉到各种真实的异常情况。在本文中,我们提出通过利用正常和异常视频来学习异常情况。为了避免在训练视频中注释异常段或剪辑,这是非常耗时的,我们提出通过深度多实例排序框架来学习异常,利用弱标记的训练视频,即训练标签(异常或正常)是在视频级别而不是剪辑级别。在我们的方法中,我们将正常和异常视频视为包,将视频段视为多实例学习(MIL)中的实例,并自动学习一个深度异常排序模型,该模型在异常视频段上预测高异常分数。此外,我们在排序损失函数中引入稀疏性和时间平滑度约束,以更好地在训练期间定位异常。
我们还介绍了一个新的大规模首个数据集,包含128小时的视频。该数据集包括1900个长而未经修剪的真实监控视频,涵盖了13种现实中的异常情况,如斗殴、道路事故、入室盗窃、抢劫等,以及正常活动。该数据集可用于两项任务。首先,进行一组中的所有异常和另一组中的所有正常活动的通用异常检测。其次,用于识别13种异常活动中的每一种。我们的实验结果表明,与最先进的方法相比,我们用于异常检测的MIL方法在异常检测性能上取得了显著改进。我们提供了几种最近的深度学习基线模型在异常活动识别上的结果。这些基线模型的低识别性能表明我们的数据集非常具有挑战性,为未来的工作提供了更多机会。该数据集可在以下链接获取:https://webpages.uncc.edu/cchen62/dataset.html
1. Introduction
监控摄像头越来越多地被用于公共场所,如街道、十字路口、银行、购物中心等,以提高公共安全。然而,执法机构的监控能力未能跟上步伐。结果是,监控摄像头的利用存在明显的不足,摄像头与人工监控员的比例不合理。视频监控中的一个关键任务是检测异常事件,如交通事故、犯罪活动或非法活动。通常,与正常活动相比,异常事件发生的频率较低。因此,为了减少人力和时间的浪费,开发智能的计算机视觉算法用于自动视频异常检测是迫切需要的。实际异常检测系统的目标是及时地发出信号,指示偏离正常模式的活动,并确定发生异常的时间窗口。因此,异常检测可以被认为是粗粒度的视频理解,它从正常模式中过滤出异常。一旦检测到异常,就可以使用分类技术将其进一步归类为特定活动之一。
针对异常检测的一个小步骤是开发算法来检测特定的异常事件,例如暴力检测器[30]和交通事故检测器[23, 34]。然而,显而易见的是,这些解决方案无法泛化到检测其他异常事件,因此它们在实践中的使用受到限制。
现实世界中的异常事件复杂多样。很难列出所有可能的异常事件。因此,理想情况下,异常检测算法不应依赖于任何关于事件的先验信息。换句话说,异常检测应该在最小监督下完成。基于稀疏编码的方法被认为是实现最先进异常检测结果的代表性方法[28, 41]。这些方法假设视频的初始部分只包含正常事件,因此初始部分用于构建正常事件词典。然后,异常检测的主要思想是,异常事件无法从正常事件词典中准确重构出来。然而,由于被监视摄像头捕获的环境可能随时间发生剧烈变化(例如,一天中的不同时间),因此这些方法对于不同的正常行为产生高误报率。
Motivation and contributions.尽管上述方法很吸引人,但它们基于这样一个假设:任何偏离学习到的正常模式的模式都将被视为异常。然而,这个假设可能不成立,因为很难或不可能定义一个能考虑到所有可能的正常模式/行为的正常事件[9]。更重要的是,正常和异常行为之间的边界通常是模糊的。此外,在现实条件下,同样的行为在不同条件下可能是正常的或异常的行为。因此,有人认为正常和异常事件的训练数据可以帮助异常检测系统学习得更好。在本文中,我们提出了一种使用弱标记训练视频的异常检测算法。也就是说,我们只知道视频级别的标签,即一个视频是正常的还是在某处包含异常,但我们不知道具体位置。这很有趣,因为我们可以通过只分配视频级别的标签来轻松地注释大量视频。为了制定一个弱监督学习方法,我们求助于多实例学习(MIL)[12, 4]。具体地,我们建议通过一个深度MIL框架来学习异常,将正常和异常的监控视频视为袋子,将每个视频的短片段/剪辑视为袋子中的实例。基于训练视频,我们自动学习一个异常排名模型,该模型预测视频中异常段的高异常分数。在测试阶段,一个长而未剪辑的视频被分成片段,并输入到我们的深度网络中,为每个视频段分配异常分数,从而可以检测到异常。总之,本文的贡献如下。
- 我们提出了一种仅利用弱标记训练视频的多实例学习(MIL)解决方案来进行异常检测。我们提出了一种带有稀疏性和平滑性约束的MIL排名损失,用于深度学习网络学习视频段的异常分数。据我们所知,我们是首次在多实例学习的背景下制定了视频异常检测问题。
- 我们引入了一个大规模的视频异常检测数据集,包括1900个真实世界的监控视频,涵盖了13种不同的异常事件和正常活动,这些视频是由监控摄像头捕获的。这是迄今为止最大的数据集,比现有的异常数据集包含的视频数量多15倍以上,总共有128小时的视频。
- 我们在我们的新数据集上的实验结果表明,与最先进的异常检测方法相比,我们提出的方法取得了更优越的性能。
- 我们的数据集也是对未修剪视频上活动识别的一个具有挑战性的基准,这是由于活动的复杂性和类内变化的大量存在。我们提供了基线方法C3D [36]和TCNN [21]在识别13种不同异常活动方面的结果。
2. Related Work
Anomaly detection.异常检测是计算机视觉中最具挑战性和长期存在的问题之一。对于视频监控应用,有几种尝试在视频中检测暴力或攻击行为。Datta等人提出通过利用人的运动和肢体方向来检测人类暴力行为。Kooij等人利用视频和音频数据来检测监控视频中的攻击行为。Gao等人提出了用于在人群视频中检测暴力的暴力流描述符。最近,Mohammadi等人提出了一种基于行为启发式方法的新方法,用于分类暴力和非暴力视频。
除了区分暴力和非暴力模式之外,[38, 7]中的作者提出使用跟踪来建模人的正常运动,并检测与正常运动的偏离作为异常。由于获取可靠轨迹的困难,一些方法避免跟踪,并通过基于直方图的方法[10]、主题建模[20]、运动模式[31]、社交力模型[29]、动态纹理模型的混合[27]、局部时空体积上的隐马尔可夫模型(HMM)[26]和上下文驱动方法[43]来学习全局运动模式。给定正常行为的训练视频,这些方法学习正常运动模式的分布,并将低概率模式检测为异常。
在几个计算机视觉问题中,稀疏表示和字典学习方法取得了成功,[28, 42]的研究人员使用稀疏表示来学习正常行为的字典。在测试期间,具有较大重建误差的模式被视为异常行为。由于深度学习在图像分类中的成功应用,已经提出了几种用于视频动作分类的方法[24, 36]。然而,对于视频,获取用于训练的注释是困难和费时的。
最近,[18,39]使用基于深度学习的自动编码器来学习正常行为的模型,并使用重建损失来检测异常。我们的方法不仅考虑正常行为,还考虑异常行为进行异常检测,仅使用弱标记的训练数据。
Ranking.学习排名是机器学习中的一个活跃研究领域。这些方法主要关注的是提高项目的相对得分,而不是个体得分。Joachims等人[22]提出了Rank-SVM来提高搜索引擎的检索质量。Bergeron等人[8]提出了一种用于解决多实例排名问题的算法,使用连续线性规划,并展示了其在计算化学中的氢抽取问题中的应用。最近,深度排名网络已经在几个计算机视觉应用中使用,并展示了最先进的性能。它们已经用于特征学习[37]、高亮检测[40]、图形交换格式(GIF)生成[17]、人脸检测和验证[32]、人员再识别[13]、地点识别[6]、度量学习和图像检索[16]。所有深度排名方法都需要大量的正负样本注释。
与现有方法相反,我们将异常检测构建为一个在排名框架中的回归问题,利用正常和异常数据。为了缓解在训练中获取精确的段级标签(即视频中异常部分的时间注释)的困难,我们利用多实例学习,该方法依赖于弱标记数据(即视频级别的标签 - 正常或异常,比时间注释容易得多)来学习异常模型,并在测试期间检测视频段级别的异常。
3. Proposed Anomaly Detection Method
所提出的方法(见图1概述)首先在训练期间将监控视频分成固定数量的段落。这些段落构成了一个包中的实例。利用正(异常)和负(正常)包,我们使用所提出的深度多实例学习排名损失来训练异常检测模型。
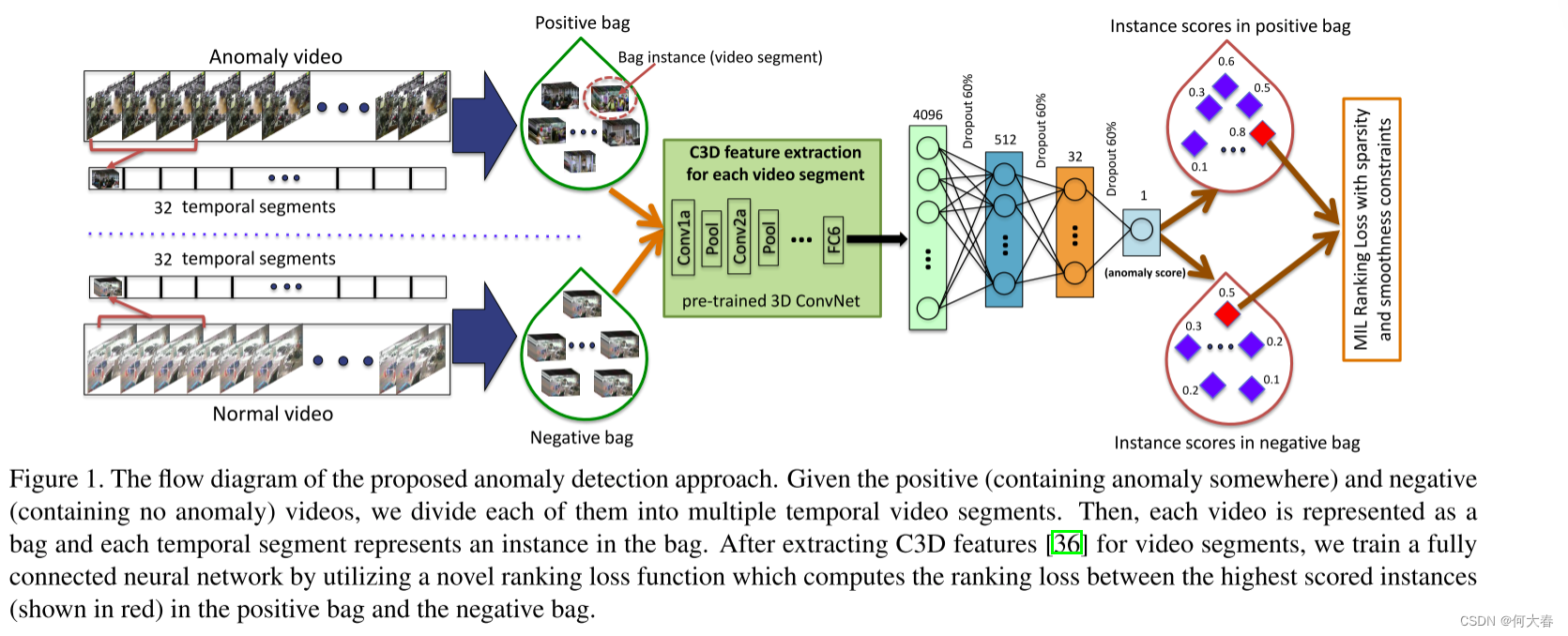
图1. 所提出的异常检测方法的流程图。给定正样本(包含某种异常)和负样本(不包含异常)视频,我们将它们各自分成多个时间视频段。然后,每个视频被表示为一个包,每个时间段表示包中的一个实例。在提取了视频段的C3D特征[36]之后,我们通过利用一种新颖的排序损失函数来训练一个全连接神经网络,该函数计算了正样本包中最高得分实例(显示为红色)与负样本包之间的排名损失。
3.1. Multiple Instance Learning
在使用支持向量机进行标准监督分类问题时,所有正负样本的标签都是可用的,并且分类器是使用以下优化函数学习的:

其中,
1
◯
\textcircled{1}
1◯是hinge损失,
y
i
y_i
yi表示每个样本的标签,
ϕ
(
x
)
\phi(x)
ϕ(x)表示图像块或视频段的特征表示,
b
b
b是偏差,
k
k
k是训练样本的总数,
w
w
w是要学习的分类器。为了学习一个稳健的分类器,需要准确的正负样本注释。在监督异常检测的背景下,分类器需要视频中每个段的时间注释。然而,获取视频的时间注释是耗时且费力的。
多实例学习(MIL)放宽了对准确时间注释的假设。在MIL中,视频中异常事件的精确时间位置是未知的。相反,只需要视频级别的标签来指示整个视频中是否存在异常。包含异常的视频被标记为正样本,而没有任何异常的视频被标记为负样本。然后,我们将一个正样本视频表示为一个正包
B
a
\mathcal{B}_a
Ba,其中不同的时间段形成包中的各个实例(
p
1
p^1
p1,
p
2
p^2
p2,…,
p
m
p^m
pm),其中
m
m
m是包中实例的数量。我们假设这些实例中至少有一个包含异常。类似地,负视频由负包
B
n
\mathcal{B}_n
Bn表示,其中该包中的时间段形成负实例(
n
1
n^1
n1,
n
2
n^2
n2,…,
n
∣
m
n^|m
n∣m)。在负包中,没有任何实例包含异常。由于正实例的确切信息(即实例级别标签)是未知的,因此可以针对每个包中得分最高的实例优化目标函数。
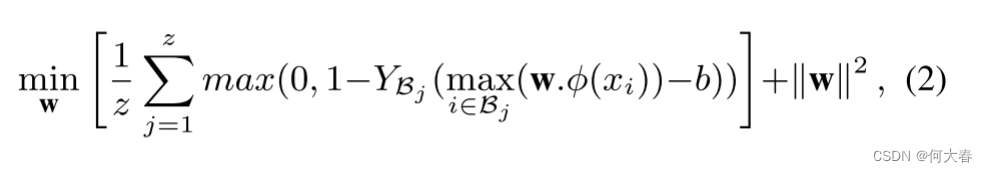
其中,
Y
B
j
Y_{\mathcal{B}_j}
YBj表示包级别标签,
z
z
z表示包的总数,而所有其他变量与公式1中的相同。
3.2. Deep MIL Ranking Model
异常行为很难准确定义[9],因为它相当主观,且因人而异。此外,如何为异常分配1/0标签并不明显。此外,由于异常示例不足,异常检测通常被视为低概率模式检测,而不是分类问题[10, 5, 20, 26, 28, 42, 18, 26]。
在我们提出的方法中,我们将异常检测视为回归问题。我们希望异常视频片段的异常得分高于正常片段。一种直接的方法是使用排名损失,鼓励异常视频片段的得分高于正常片段,例如:

其中,
V
a
\mathcal{V}_a
Va 和
V
n
\mathcal{V}_n
Vn 分别表示异常和正常的视频片段,
f
(
V
a
)
f(\mathcal{V}_a)
f(Va) 和
f
(
V
n
)
f(\mathcal{V}_n)
f(Vn) 分别表示对应的预测得分。如果在训练过程中已知片段级别的标注信息,上述排名函数应该能够很好地发挥作用。
然而,在缺乏视频片段级别标注的情况下,无法使用公式3。相反,我们提出以下多实例排名目标函数:
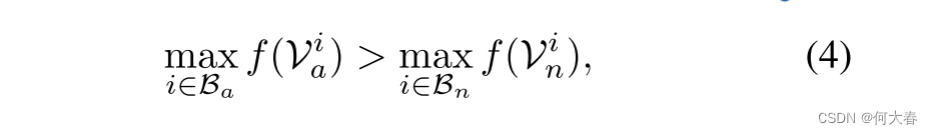
其中,max是针对每个袋中的所有视频片段取得的最大值。我们不是对袋中的每个实例强制进行排名,而是仅对在正袋和负袋中分别具有最高异常分数的两个实例进行排名。在正袋中具有最高异常分数的片段最有可能是真正的正实例(异常片段)。在负袋中具有最高异常分数的片段看起来最类似于异常片段,但实际上是一个正常实例。这个负实例被认为是一个困难的实例,在异常检测中可能会产生误报。通过使用公式4,我们希望在异常分数方面将正实例和负实例远离。因此,我们的排名损失在hinge损失的形式化中被定义为如下所示:
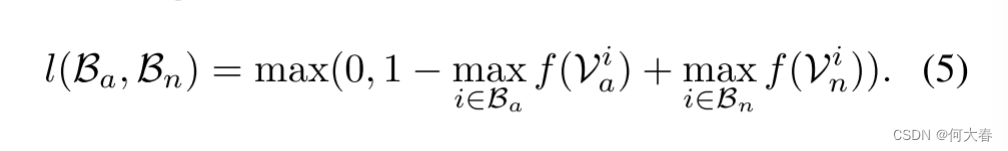
上述损失的一个限制是它忽略了异常视频的基本时间结构。首先,在真实世界的场景中,异常通常只会持续很短的时间。在这种情况下,异常袋中实例(片段)的得分应该是稀疏的,表明只有少数片段可能包含异常。其次,由于视频是一系列片段,因此异常得分应该在视频片段之间平滑变化。因此,我们通过最小化相邻视频片段之间得分的差异来强制实现视频片段之间的时间平滑性。通过在实例得分上结合稀疏性和平滑性约束,损失函数变为:
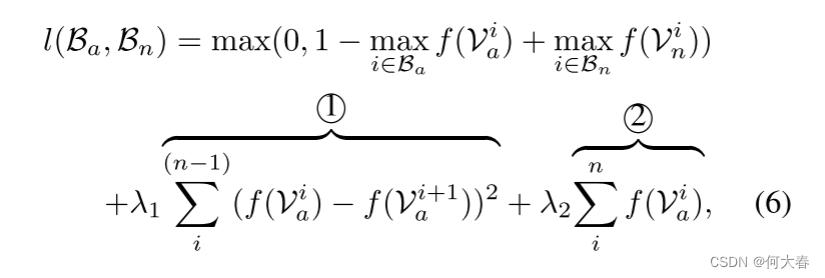
其中,
1
◯
\textcircled{1}
1◯ 表示时间平滑度项,
2
◯
\textcircled{2}
2◯代表稀疏度项。在这个多实例排名损失中,误差从正袋和负袋中得分最高的视频片段进行反向传播。通过对大量正袋和负袋进行训练,我们期望网络将学习一个广义模型,以预测正袋中异常片段的高分(见图8)。最后,我们的完整目标函数为:

其中 W \mathcal{W} W表示模型权重。
Bags Formations.我们将每个视频均匀地分成相等数量的非重叠时间段,并将这些视频片段用作袋实例。对于每个视频片段,我们提取3D卷积特征[36]。我们选择使用这种特征表示是因为它具有计算效率高、在视频动作识别中捕获外观和运动动态能力显著的特点。
4. Dataset
4.1. Previous datasets
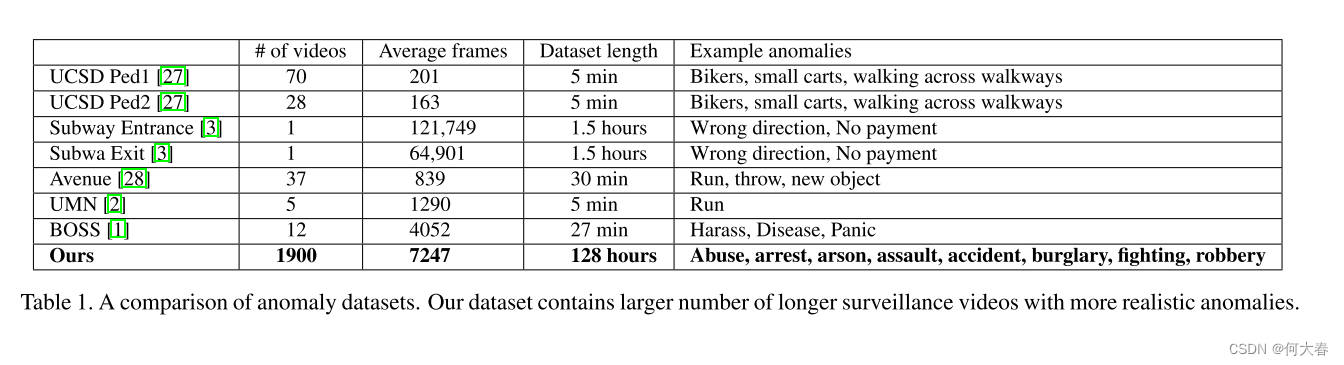
我们简要回顾了现有的视频异常检测数据集。UMN数据集[2]包含五个不同的舞台视频,其中人们在周围走动,一段时间后开始朝不同方向跑动。异常的特征是只有跑步动作。UCSD Ped1和Ped2数据集[27]分别包含70个和28个监控视频。这些视频只在一个位置拍摄。视频中的异常很简单,不反映视频监控中的真实异常,例如人们穿过人行道,非行人实体(滑板者、骑自行车者和轮椅者)在人行道上行走。Avenue数据集[28]包含37个视频。虽然它包含更多的异常,但它们是舞台化的,且在一个地点拍摄。与[27]类似,该数据集中的视频很短,一些异常是不真实的(例如扔纸)。Subway Exit和Subway Entrance数据集[3]各包含一个长的监控视频。这两个视频捕捉到了简单的异常,如朝错误的方向行走和跳过付款。BOSS[1]数据集是从一列火车上安装的监控摄像头收集的。它包含骚扰、患病的人、恐慌情况以及正常视频等异常。所有异常都是由演员表演的。总的来说,用于视频异常检测的先前数据集在视频数量或视频长度方面都很小。异常的变化也有限。此外,一些异常并不真实。
4.2. Our dataset
由于先前数据集的限制,我们构建了一个新的大规模数据集来评估我们的方法。它由长时间未剪辑的监控视频组成,涵盖了13种真实世界的异常,包括滥用、逮捕、纵火、攻击、事故、入室盗窃、爆炸、打斗、抢劫、枪击、偷窃、店铺行窃和破坏。选择这些异常是因为它们对公共安全有重大影响。我们将我们的数据集与先前的异常检测数据集进行了比较,见表1。
Video collection.为了确保我们数据集的质量,我们培训了十名标注员(具有不同水平的计算机视觉专业知识)来收集数据集。我们使用文本搜索查询(稍作变化,例如“车祸”,“道路事故”)在YouTube1和LiveLeak2上搜索每种异常的视频。为了检索尽可能多的视频,我们还针对每种异常使用了不同语言的文本查询(例如法语、俄语、中文等),感谢Google翻译。我们移除了符合以下任一条件的视频:手动编辑过的、恶作剧视频、非闭路电视摄像头拍摄的、来自新闻报道的、使用手持摄像机拍摄的以及包含汇编内容的视频。我们还丢弃了异常不明确的视频。在上述视频修剪约束条件下,我们收集了950个未编辑的真实世界监控视频,其中包含清晰的异常。使用相同的约束条件,我们收集了950个正常视频,总共构成了我们数据集中的1900个视频。在图2中,我们展示了每种异常一个示例视频的四个帧。

Annotation.对于我们的异常检测方法,训练只需要视频级别的标签。然而,为了评估其在测试视频上的性能,我们需要知道时间注释,即每个测试异常视频中异常事件的开始和结束帧。为此,我们将同一视频分配给多个标注员来标注每个异常的时间范围。最终的时间注释是通过对不同标注员的注释进行平均得到的。经过几个月的密集努力,完整的数据集最终确定。
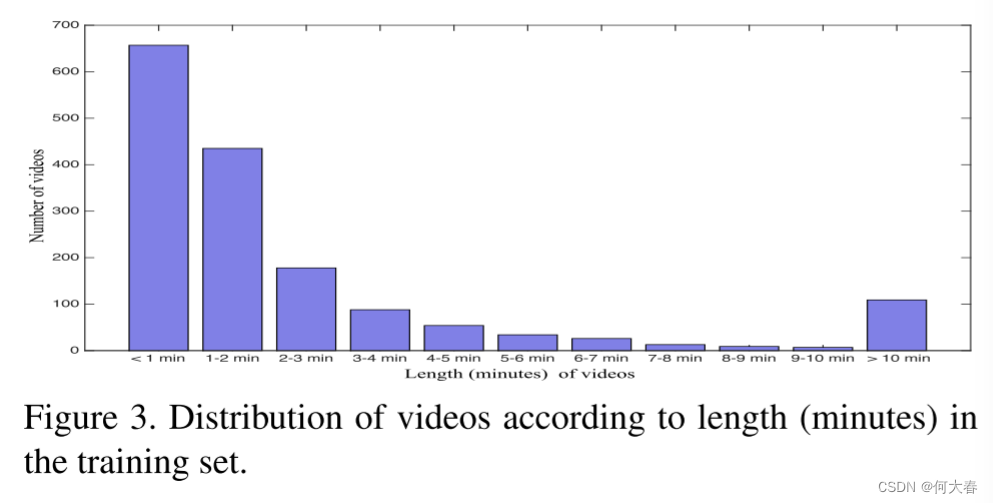
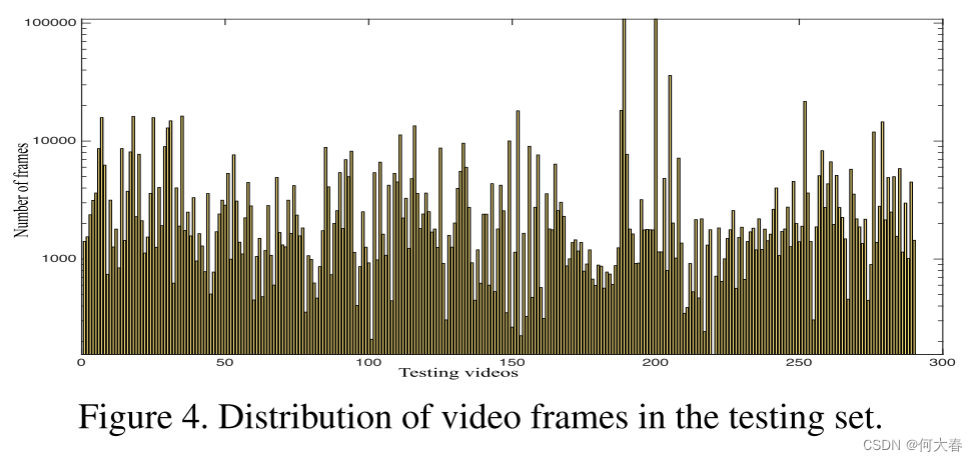
Training and testing sets.我们将数据集分为两部分:训练集包括800个正常视频和810个异常视频(详细信息见表2),测试集包括剩余的150个正常视频和140个异常视频。训练集和测试集中都包含了所有13种异常在视频中不同时间位置的情况。此外,一些视频中可能有多个异常。训练视频的长度分布(以分钟为单位)如图3所示。测试视频中每个视频的帧数和异常百分比分别在图4和图5中呈现。

5. Experiments
5.1. Implementation Details
我们从C3D网络的全连接(FC)层FC6中提取视觉特征。在计算特征之前,我们将每个视频帧的大小调整为240 × 320像素,并将帧速率固定为30 fps。我们对每个16帧的视频剪辑计算C3D特征,然后进行 l 2 l_2 l2归一化。为了获得视频段的特征,我们取该段内所有16帧剪辑特征的平均值。我们将这些特征(4096维)输入到一个3层FC神经网络中。第一个FC层有512个单元,其后是32个单元和1个单元的FC层。在FC层之间使用60%的dropout正则化[33]。我们尝试了更深的网络,但没有观察到更好的检测准确度。我们在第一个和最后一个FC层分别使用ReLU[19]激活和Sigmoid激活,并使用Adagrad[14]优化器,初始学习率为0.001。在MIL排名损失的稀疏性和平滑性约束参数中,为了获得最佳性能,我们将参数设置为 λ 1 λ_1 λ1= λ 2 λ_2 λ2 = 8 × 1 0 − 5 8 × 10^{−5} 8×10−5。
我们将每个视频分成32个不重叠的段,将每个视频段视为一个袋实例。段数(32)是经验性设置的。我们还尝试了多尺度重叠的时间段,但这并不影响检测准确度。我们随机选择30个正袋和30个负袋作为一个小批量。我们通过Theano [35]上的计算图使用反向模式自动微分来计算梯度。具体地,我们确定损失所依赖的变量集合,为每个变量计算梯度,并通过计算图上的链式规则获得最终梯度。每个视频经过网络,我们得到每个时间段的得分。然后,我们按照公式6和公式7计算损失,并将损失反向传播到整个批处理中。
Evaluation Metric.我们遵循先前关于异常检测的研究[27],使用基于帧的受试者工作特征曲线(ROC曲线)和相应的曲线下面积(AUC)来评估我们方法的性能。我们不使用等误差率(EER)[27],因为它不能正确地衡量异常,特别是当长视频只包含少量异常行为时。
5.2. Comparison with the State-of-the-art
图6是和不同方法的比较
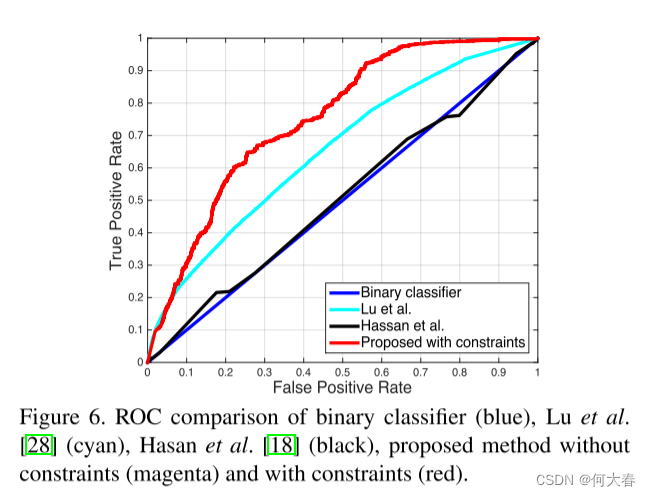
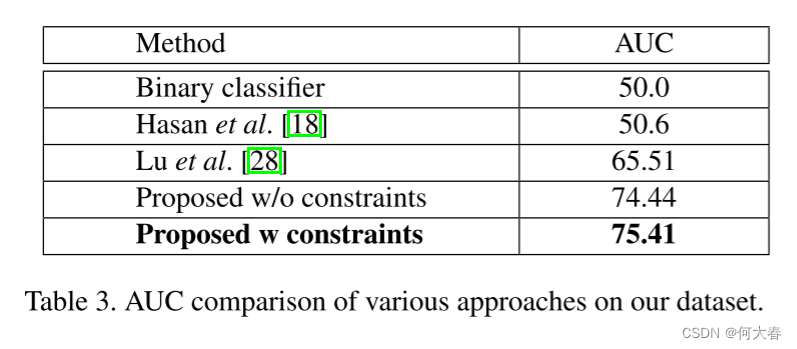
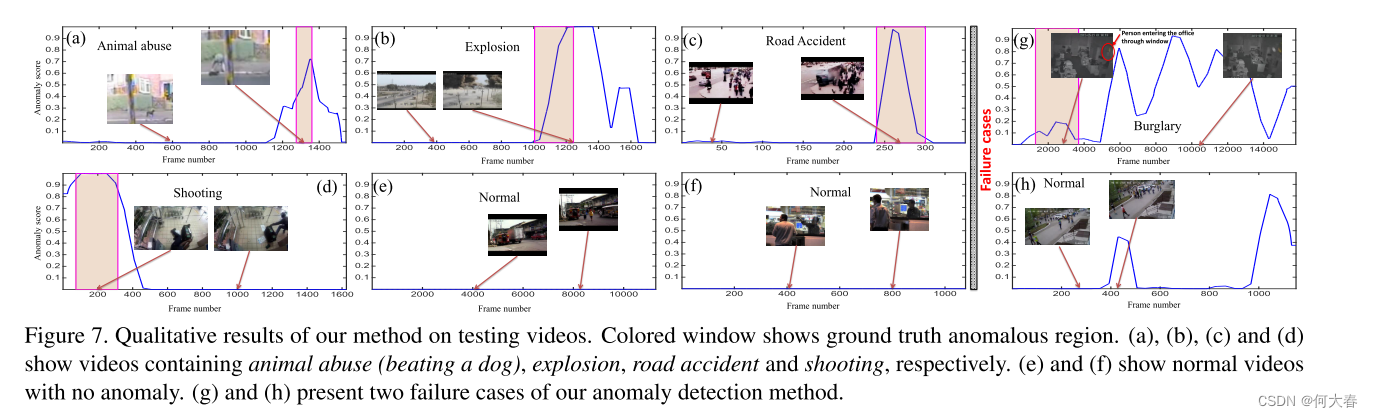
图7. 我们方法在测试视频上的定性结果。彩色窗口显示了地面真实的异常区域。(a)、(b)、©和(d)展示了包含动物虐待(打狗)、爆炸、道路事故和枪击的视频。 (e) 和 (f) 显示了没有异常的正常视频。(g) 和 (h) 展示了我们异常检测方法的两个失败案例。
5.4. Anomalous Activity Recognition Experiments
作者还用这个数据集做了视频异常识别领域的实验
6. Conclusions
我们提出了一种深度学习方法,用于检测监控视频中的真实世界异常事件。
由于这些现实中的异常事件的复杂性,仅使用正常数据可能不够优化异常检测。我们尝试利用正常和异常监控视频。
为了避免在训练视频中进行耗时的异常段的时间注释,我们使用弱标记数据在深度多实例排序框架中学习异常检测的通用模型。为了验证所提出的方法,引入了一个包含各种真实世界异常事件的新的大规模异常数据集。
对该数据集的实验结果表明,我们提出的异常检测方法明显优于基线方法。
此外,我们展示了我们的数据集对于异常活动识别的第二个任务的有用性。
![[uni-app] uni.createAnimation动画在APP端无效问题记录](https://img-blog.csdnimg.cn/direct/08ec8d91dd4e4142a75226e74bacc547.png)






![[Qt学习笔记]Qt实现鼠标点击或移动时改变鼠标的样式以及自定义鼠标样式](https://img-blog.csdnimg.cn/img_convert/ba661779f4a02d1daf7d547dba388f3e.webp?x-oss-process=image/format,png)